1. 서론
1.1 연구의 배경 및 목적
경제 및 인구 성장이 주원인이 되어 나타난 산업화 시대부 터 이어진 인위적 온실가스 배출량은 지속적으로 증가했고, 이산화탄소, 메탄, 아산화질소의 대기 중 농도는 현시대에 가 장 높은 수준을 보이고 있다. 온실가스로 인해 전 세계적으로 100년간 기온이 0.89°C 상승하였으며, 특히 우리나라는 같은 기간동안 평균기온이 1.8°C 상승하여 세계 평균의 2배를 상회 하고 있는 실정이다. 따라서 전산업에 걸쳐 온실가스 감축 및 친환경 기술개발의 중요성이 증가하고 있다.
이에 따라 환경부에서는 탄소배출량을 측정하기 위해 “탄 소성적표지”제도를 운영하여 제품별로 전과정평가(Life Cycle Assessment, LCA)를 수행하고 있다. 하지만 건설 사 업을 종합적으로 평가하기 위한 LCA 분석은 아직 미흡한 실 정이다. 그 이유는 건설 분야는 제조분야와는 달리, 같은 시
방(specification)을 가진 시설물이라 할지라도 프로젝트의 여 건에 따라 다양한 자재, 장비 등 자원들이 투입되며 이러한 자원들의 양과 종류가 다르기 때문에, 각각의 시설물을 지을 때 발생하는 환경부하량을 사전에 정확히 측정하는 것이 쉽 지 않기 때문이다(Kim et al., 2017).
국토해양부는 ‘시설물별 탄소배출량 산정 가이드라인’을 발 표하여 SOC시설물의 탄소배출량을 평가하고 친환경 건설의 기반을 마련하고자 하였다. 도로, 철도 및 건축물을 대상으로 전과정에서의 환경부하 산정방법을 제시함으로써 환경영향 을 산정하고 관리가 가능하다는 점에서 의미가 있다. 하지만 내역서, 수량산출서 등의 상세한 설계자료를 활용해야하기 때문에 실시설계가 완료된 이후 적용이 가능하다는 한계점이 있다. 실시설계가 완료되기 이전인 초기단계에서 설계의 자 유도가 높기 때문에 환경 친화적 의사결정에 큰 영향을 끼칠 수 있다. 이와 같이 프로젝트 초기단계는 환경부하량의 절감 가능성에 큰 영향을 미친다는 것을 감안한다면, 효과적인 의 사결정을 지원할 수 있는 시스템을 초기에 구축하고 활용하 는 것이 중요하다.
이에 본 연구에서는 문헌조사를 통해 인공신경망의 이론적 내용을 고찰하고 선행연구를 분석하여 건설분야에서의 환경 부하량 추정 연구의 시사점 및 한계점을 도출한다. 더불어 국
PSC Beam교 환경부하량 추정을 위한 인공신경망 모델 적용 연구
김의왕1·윤원건*·김경주1
1중앙대학교 사회기반시스템공학부
Application of Artificial Neural Network Model
for Environmental Load Estimation of Pre-Stressed Concrete Beam Bridge
Kim, Eu Wang
1, Yun, Won Gun
*, Kim, Kyong Ju
11Department of Civil Engineering, Chung-Ang University
Abstract :
Considering that earlier stage of construction project has a great influence on the possibility of lowering of environmental load, it is important to build and utilize system that can support effective decision making at the initial stage of the project. In this study, we constructed an environmental load estimation model that can be used at the early stage of the project using basic design factors. The model was constructed by using the artificial neural network to estimate environmental load by applying to planning stage (ANN-1), basic design stage (ANN-2). The result of test, shows that average of absolute measuring efficiency and standard deviation of ANN-1 and ANN-2 were 11.19% / 5.30% and 9.59% / 3.09% each. This result indicates that the model using the input variables extended with the project progress has high reliability and it is considered to be effective in decision support at the initial design stage of the project.
Keywords :
Environmental Load, Life Cycle Assessment, PSC Beam, Artificial Neural Network
* Corresponding author: Yun, Won Gun, Department of Civil Engineering, Chung-Ang University, Seoul 06974, Korea E-mail: [email protected]
Received May 30, 2018: revised - accepted June 27, 2018
내 국도 건설에서 일반적으로 많이 활용되는 Pre-Stressed Concrete (PSC) Beam교를 대상으로 건설사업의 기획단계·
기본설계단계에서의 환경부하량 추정을 위해 인공신경망 (Artificial Neural Network, ANN)을 이용한 산정 방법을 제 시하여 한계점을 보완할 수 있는 대안으로 제시하고자 한다.
또한, 사업초기 설계단계 업무가 진행됨에 따라 얻을 수 있 는 가용정보를 활용함에 있어 사업이 구체화될수록 더 많은 확정된 정보를 활용할 수 있으므로 더욱 정확한 추정모델을 구축할 수 있다. 특히, 사업의 단계별로 활용할 수 있는 가용 정보를 정의하여 각 단계별로 환경부하량을 추정할 수 있는 두 가지 모델을 구축하고, 추정모델의 성능은 실제사례를 적 용하여 실제 환경부하량과 추정모델의 추정값을 비교분석하 며, 기존 방법론들과의 결과 차이를 검증하였다.
2. 예비적 고찰 2.1 LCA의 개념
ISO 14040의 정의에 따르면 전과정평가(LCA)는 제품시스 템의 전생애주기에 대해 투입물, 산출물 및 잠재적인 환경영 향을 종합하고 평가하는 기법이다(ISO 14040, 2006). 건설에 서의 전과정평가는 자재생산, 수송, 시공, 운영 및 유지관리, 해체 및 폐기과정까지 전과정에서의 투입물과 산출물에 대해 잠재적인 환경영향을 평가한다. 즉, 전과정평가는 도로시설 물을 대상으로 환경영향의 피해를 줄이고 부정적 영향의 가능 성을 미연에 방지할 수 있는 실용적인 도구로 활용가능하다.
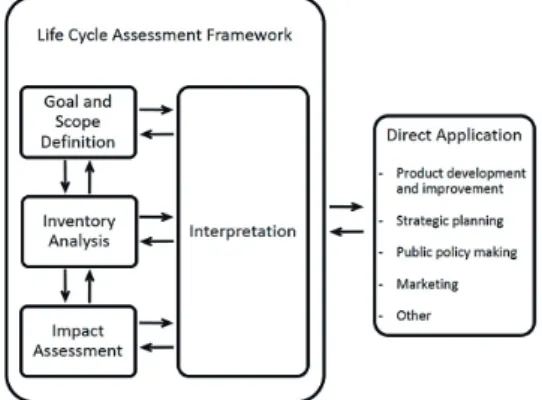
Fig. 1. Life Cycle Assessment Process (ISO 14040, 2006)
2.1.1 LCA 프로세스
국제표준화기구 ISO 14040에서 제시하는 LCA 수행 프로 세스는 <Fig. 1>과 같이 4단계로 목적 및 범위 설정(Goal and Scope Definition), 목록분석(Inventory Analysis), 영향평가 (Impact Assessment), 결과해석(Interpretation)으로 구성된다.
2.1.2 전과정 목록
전과정목록은 제품시스템의 전과정에 걸친 투입물 및 산출
물을 정량화하기 위해 목록화한 데이터이다. 투입물은 에너 지, 물, 천연자원 등을 포함하며, 산출물은 대기, 수계, 토지 에 대한 오염물이다(Crawford, 2011). 투입물과 산출물의 정 량화방법으로는 개별적산법(Process Analysis), 산업연관분 석법(Input-Output Analysis), 혼합법(Hybrid method)으로 구분된다.
개별적산법은 제품과 공정에 대한 상세한 정보의 조합을 통해 제품시스템의 환경부하량과 연계된 영향에 대해 산출하 는 방법이다. 이 방법은 상세한 정보를 활용하여 구축되는 만 큼 높은 정확도를 가지나, 많은 시간과 비용이 소요된다는 측 면이 있다. 반면, 산업연관분석법은 제품이나 공정에 있어서 다양하고 복잡한 자원요구량 및 오염물질 배출량을 추정하기 위해 산업연관표를 기반으로 경제부문별 상호간의 연관성을 통해 분석하는 방법이다. 개별적산법은 각 개별적 제품에 대 한 분석은 불명확하며, 산업연관표상에 없는 항목은 분석이 불가능하다. 반면, 개별적산법은 투입되는 물질의 종류 및 양 을 부문별로 상세하게 목록분석을 수행하기 때문에 정량적인 평가가 가능한 장점이 있다. 각각의 방법은 명확한 장단점을 가지므로 두 가지를 혼합한 혼합법에 관한 연구도 수행되었다.
본 연구는 PSC Beam교에 대해 신속하고 정확하게 환경부 하량 추정할 수 있는 모델을 구축하고자 하므로 기본 데이터 베이스가 신뢰성을 갖는 것이 무엇보다도 중요하다. 따라서 본 연구에서는 결과의 정확성이 높은 개별적산법 방식을 기 반으로 PSC Beam교의 환경부하량을 분석하고 사례 데이터 베이스를 구축한다.
2.2 연구동향
2.2.1 건설분야 기계학습기법 적용 현황
기계학습기법은 정의된 문제를 해결하는 추론방식으로, 원 인과 결과의 상관관계가 복잡하며 정형화하기 어려운 규칙 을 갖는 문제영역에 대해 효율적으로 추론할 수 있다. 이러 한 기계학습기법의 특징으로 인해서 국내외 건설분야에서 도 인공신경망, 사례기반추론(Case based reasoning, CBR), 회귀모델 등을 통한 문제해결 연구가 다수 수행되었다. 일반 적으로 기계학습을 활용한 문제해결은 건설산업에서 일반화 된 지식을 기반으로 해결하기 어려운 문제에 대해 명확한 솔 루션을 제공할 수 있다. 교량 시설물을 대상으로는 개략공사 비, 일정, 공사물량, 이산화탄소 발생량 등에 대한 예측을 위 해서 주로 과거 교량의 목적값과 연관성이 있는 교량의 요소 를 입력변수로 활용하여 예측모델을 구축하는 방식을 따르고 있다. 건설분야에 적용된 모델로는 주로 선형회귀모델(Trost
& Garold, 2003; Lowe et al., 2006; Sonmez, 2008), CBR 모델(Kim, 2010; Koo et al., 2011; Kim et al., 2013; Moon et al., 2013; Kim et al., 2016), 인공신경망모델(Gunaydin et
al., 2004; Han et al., 2011; Elazouni et al., 2014) 등이 있다.
건설분야에서 CBR기법을 활용한 연구동향을 살펴보면 건 축 및 토목시설물을 대상으로 공사물량, 개략공사비, 이산 화탄소 발생량 등을 추정하여 신뢰도가 높은 추정모델을 개 발하는 연구들이 지속적으로 수행되었는데, 이러한 연구들 은 건설산업에서 효과적인 의사결정을 지원하는데 기여하였 다. CBR은 구축이 쉽고 빠르며 결과도출까지의 과정이 명 확한 장점이 있으며, 모델의 신뢰성을 향상시키기 위해 검색 (Retrieval), 보정(Adaptation) 과정에서 통계적 기법이나 기 계학습 기법을 도입하는 추세이다. 하지만 데이터베이스에 모든 유형의 사례가 있어야만 우수한 성능을 가지며, 저장되 지 않은 사례에 적용 시 다소 신뢰도가 떨어지는 한계점이 있 다. 반면에 인공신경망의 경우 일반적으로 은닉층의 수와 노 드 수가 많아질수록 신경망모델의 성능이 좋아지는 경향이 있으므로 적절한 파라미터를 적용한 다층인공신경망을 활용 한다면 우수한 성능을 갖는 모델을 구축할 수 있다.
본 연구에서 활용하는 데이터베이스는 구성이 매우 다양 하며 범위가 넓기 때문에 입력변수와 환경부하량 간의 상관 성을 규명하기 쉽지 않다. 또한 본 연구의 목적은 기획단계 뿐만 아니라 기본설계단계에도 활용할 수 있도록 최대 확장 된 입력변수를 활용한 모델을 구축하고자한다. 따라서 PSC Beam교의 기획단계 및 기본설계단계에서 발생하는 설계정 보와 환경부하량의 상관관계을 학습하여 입력값과 출력값의 사이의 복잡한 상관관계 규명하는데 장점을 가진 인공신경망 이 적합할 것으로 판단하였다.
2.2.2 건설분야 전과정평가 방법론 적용 현황 전과정평가를 적용하여 시설물에 대한 환경부하량을 산정 하고 분석한 연구는 국내외에서 다수 수행되었다. Park et al. (2003)은 고속도로를 대상으로 자재 생산, 시공, 유지, 보 수 및 철거, 재활용의 4개 단계에 대해 산업연관분석법을 활 용하여 각 사업수행단계에서의 에너지 소비량을 정량화하여 환경부하량을 산정하였다. Wang et al. (2014)는 설계가 완 료된 중국의 고속도로건설 프로젝트에서 지하철, 도로 포장, 교량, 터널을 대상으로 원자재 생산, 운송, 현장 시공까지 단 계를 고려하여 이산화탄소 배출량을 산정하였다. 또한 활용 가능 한 LCI DB의 부족으로 인해서 산업연관분석법을 활용 한 연구가 주로 수행되었다(Lee & Yang, 2009; Moon et al., 2013; Jeong et al., 2015). Kang and Park (2013)은 공법선 정을 위해 굴착작업 시 발생하는 환경오염물질 배출량을 산 출하고 환경오염물질별 환경비용을 환산하여 토공사에 대한 환경경제성을 평가하였며, 건설장비에 대해 환경부하량을 6 대 환경영향범주로 산출하고 장비선정에 대한 개선 방안을 제시하였다.
환경성 평가제도로는 해외에서는 BE2ST-in-Highways,
Envision, GreenLITES, Greenroads, I-LAST, INVEST와 같이 SOC 프로젝트를 대상으로 한 환경성 평가제도가 개발 되었다. 특히 GreenLITES 인증제는 설계, 시공, 유지보수, 운영뿐만 아니라 프로젝트의 기획단계까지 평가되어 환경성 인증이 수행된다. 국내에서는 환경친화적인 건축물 건설 유 도 및 건축물 전 과정의 환경영향을 최소화하기 위해 친환경 건축물 인증제도(Green Building)가 시행되고 있다. 또한 건 축물 에너지소비총량제와 같이 사용자 측면에서 에너지 사 용량을 절감하기 위한 제도가 시행되고 있으나, 그 대상을 난 방, 냉방, 급탕, 조명, 환기 등의 운영단계로 한정하고 있다.
건설분야에서 환경성을 평가한 연구동향을 살펴보았을 때, 주로 건축분야 시설물(교육시설, 주거시설, 오피스빌딩 등)을 대상으로 산업연관분석법을 활용한 연구에 집중된 측면이 있 다. 또한 이산화탄소배출량 추정에 적용하기 위한 연구도 수 행되었지만, 건설공사는 대기, 수계 및 토양에 대한 오염 배 출물 뿐만 아니라 인간의 건강 등에 대한 생태학적 영향을 미 칠 수 있다.
따라서 교량의 건설로부터 발생한 환경영향은 그 원인이 다원적이며 복합적이기 때문에 전과정 관점을 기초로 다양한 요소를 고려한 종합적인 평가가 필요하다. 또한 환경부하량 을 줄이기 위한 활동의 일환으로, 효과적인 대안선택을 위해 서 프로젝트 초기단계에서 환경부하량을 추정할 수 있는 방 법에 대한 연구가 필요하다.
3. 데이터베이스 구축 및 입력변수 선정 3.1 환경부하량 데이터베이스 구축
3.1.1 대상 시설물
국토교통부의 ‘도로 교량 및 터널 현황정보시스템’에서 제 공하는 도로 교량 현황조서에 따르면 최근 10년(2006~2016) 사이에 준공된 교량 중 PSC Beam교가 2997개로 전체의 34.4%에 해당한다. 따라서 본 연구에서는 PSC Beam교를 대 상으로, 데이터베이스 구축을 위해 PSC Beam교에 대한 설 계보고서, 내역서, 수량산출서, 도면, 단가산출서 등의 설계 자료를 수집하여 각 사례에 대한 환경부하량을 분석하였다.
본 연구에서는 건설프로젝트 초기의 정보를 활용하여 환경 부하량을 추정하기 위한 모델을 구축하고자하기 때문에 가용 정보를 명확하게 규명하여 모델학습에 활용하고자 하였다.
첫째로, 기획단계는 사업의 예산 설정 및 공사비 타당성을 검 토하는 단계로 환경부하량 추정시 가용할 수 있는 정보가 매 우 제한적이다. 이 단계에서 가용할 수 있는 정보는 노선, 연 장, 차로수, 폭원 등의 기본적인 사항을 활용하여 환경부하량 의 추정이 가능한 모델의 개발이 가능할 것이다. 둘째, 기본 설계단계는 구조물의 부위별 공사비 추정, 설계 대안 평가를
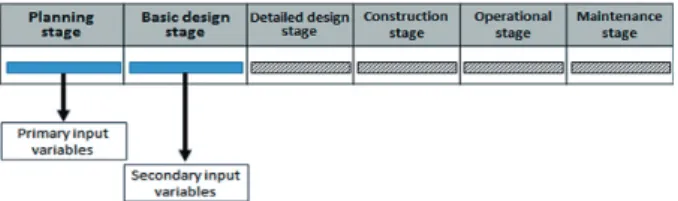
수행하는 단계로써 기획단계에 비해서 구조물 부위별 구체적 제원에 대한 정보를 활용할 수 있다. 이와 같이 상세한 가용 정보를 바탕으로 환경부하량의 추정이 가능한 모델의 개발이 가능할 것이다. 이와 같이 각 단계별로 가용정보의 수준이 다 르기 때문에, 본 연구에서는 2개의 모델로 구분하고 입력변 수 또한 <Fig. 2>와 같이 단계별로 1차, 2차로 구분하였다.
Fig. 2. Classification of input variables by project stage
3.1.2 환경부하량 산정 범위
전과정평가(Life Cycle Assessment, LCA)는 제품의 전과 정에서 발생하는 환경부하 및 잠재적인 환경영향을 분석하는 도구로써, 대상 공정, 활동의 전과정에 투입, 소모되고 배출 되는 에너지 및 물질의 양을 정량화 하여 환경에 미치는 영향 을 평가한다. 본 연구에서는 각 사례에 대한 환경부하량 분석 은 건설의 전생애 중 투입된 자재와 건설장비의 에너지 이용 을 통해 소비된 자원을 정량화 할 수 있는 건설단계만을 고려 하였다.
또한 온실가스 배출량에만 국한되지 않고 종합적인 환경 영향 평가를 위하여 국제 규격인 ISO 14040-44의 LCA분 석에 대한 기본적인 규칙을 준수하고 동시에 환경부의 한 국형 환경영향평가지수 방법론을 기반으로 8대 영향범주 로 환경부하량을 분석하였다. 8대 영향범주는 자원고갈 (Abiotic Resources Depletion, ARD), 산성화(Acidification,
AD), 부영양화(Eutrophication, EU), 지구온난화(Global Warming, GW), 오존층파괴(Ozone Depletion, OD), 광화학 산화물생성(Photochemical Oxidant Creation, POC), 생태 계독성(Terrestrial Eco-Toxicity, TET), 인체독성(Human Toxicity, HT)으로 구성된다. 본 연구에서는 환경부하 산정 시 8대 영향범주의 영향평가를 통해 Eco-point 단위로 환산 된 가중화값을 산정하여 제시하였다.
3.1.3 환경부하량 데이터베이스 구축
분석을 위한 기초자료로 2000∼2009년 사이에 준공된 PSC Beam교의 실적데이터를 기반으로 168개의 PSC Beam 교 사례의 설계자료를 수집하였다. 수집된 168개 사례의 수 량내역서 및 단가산출서를 수집하고, EBS프로그램을 이용하 여 사례별 소요자원을 집계하였으며, 산출된 사례별 소요자 원량과 LCI DB를 연계하는 개별적산법을 통해 환경부하량을 산출하였다. 여기서 LCI DB란 제품 기능단위의 생산에 필요 한 원자재의 채취 및 소재/부품가공, 수송 제품사용, 폐기(제 품 시스템 전과정)까지의 제품 시스템으로 투입되는 자원의 양과 제품시스템에서 환경으로 버려지는 배출물, 폐기물의 발생량을 목록화한 데이터로서 LCA를 수행하는데 기초데이 터로 활용된다(Yun et al., 2017).
본 연구에 적용한 LCI DB는 국가 DB, 국내 DB, 해외 DB, 자체구축 DB 등이며, 주요용도 및 기능단위를 고려 고려하여 레미콘, 시멘트, 철근 등 교량에 활용되는 건설자재에 적용 할 수 있는 29종의 DB를 적용하였다. 이후 선정된 교량의 경 간수, 경간길이, 연장, 폭원, 상부면적, 사업구간, 발주청, 행 정구역, 준공년도, 가설위치, 차로수, 기초형식, 교대높이, 교 각높이, 옹벽유무, 경간당 Beam 개수, 강관말뚝길이, 공사비 등 시설물 기본정보와 산출된 환경부하량을 집계하여 데이터 베이스를 구축하였다.
Table 1. Constructed database status (a)-(b) Feature
Number of cases
Feature
Number of cases
Feature
Number of cases
Feature
Number of cases
Feature
Number of cases
Length (m)
below 50 68
Width (m)
below 10 6
Number of lanes
below 3 23
Construction location
Onshore 90
Administrative district
Seoul·
Gyeonggi 14
51∼100 28 11∼20 19 4 122 River-bed 78 Gangwon 20
101∼150 42 21∼30 134 5 10
- -
Chungcheong 60
151∼200 8 more
than 31 9 6 10 Chungcheong 31
201∼250 14
- -
more
than 7 3 Gyeongsang 43
more than
251 8 - - - -
Number of spans
1 68
Span length
25m 8
type of foundation
Direct 43
2 11 30m 90 Pile 58
3 30 35m 70 Hybrid 67
4 25
- - -
- - -
- -
5 9
more than
6 25
Total 168 Total 168
a) Data Status of quantitative variable b) Data Status of qualitative variable
3.1.4 데이터베이스 현황
구축된 데이터베이스의 현황은 다음 <Table 1>과 같다.
168건의 차로수 현황은 4차로 교량 72%(123개)로 가장 많았 으며, 2차로 교량 10%(17개), 6차로 교량 6%(10개), 5차로 교 량 6%(10개), 1차로 교량 2%(4개), 7차로 교량 1%(2개) 순으 로 나타났다. 경간수에 따른 현황은 단경간 44%(70개), 3경 간 19%(30개), 4경간 15%(24개), 2경간 7%(11개), 5경간 5%(8 개), 6경간 이상은 10%(16개)로 나타났다. 경간장은 25m 4.8%(8개), 30m 54%(90개), 35m 42%(70개)이다. 가설위치 현황은 육상 54%(92개), 하상 46%(78개)로 구성되며, 기초형 식은 직접기초 26%(45개), 말뚝기초 34%(58개), 직접 및 말 뚝 기초가 혼합되어 있는 형식 39%(67개)로 구성되었다. 행 정구역은 서울·경기도 8%(14개), 강원도 12%(20개), 충청도 36%(61개), 전라도 18%(31개), 경상도 26%(44개)로 나타났 다. 경간장, 기초형식, 행정구역, 가설위치는 비교적 고르게 분포됐으나 차로수와 경간수는 다수의 데이터가 4차로 및 단 경간에 편향된 특성을 갖는 것으로 분석되었다.
3.2 입력변수 선정
Dataset에서 입력변수와 출력변수의 상관관계를 규명하 고, 이를 기반으로 모델을 구축하기 때문에 해결하고자 하는 대상을 명확하게 정의해야한다. 다양한 변수들의 조합으로 다중공선성이 발생하면 신경망의 학습효과가 저하되는 경향이 있기 때문에 다중공선성을 유발시키는 변수는 제거해야한다.
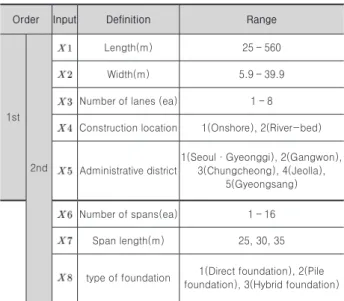
본 연구에서는 환경부하량에 영향을 미치는 요인들을 설계 도서 및 기존연구를 분석하여 기획단계, 기본설계단계에서 확보할 수 있는 가용정보를 바탕으로 영향요인으로 활용할 수 있는 입력변수를 정의하였다. 최종 확정된 단계별 입력변 수는 다음 <Table 2>와 같다.
Table 2. Detailed information of input values each stage
Order Input Definition Range
1st
2nd
Length(m) 25 – 560
Width(m) 5.9 – 39.9
Number of lanes (ea) 1 – 8
Construction location 1(Onshore), 2(River-bed)
Administrative district
1(Seoul·Gyeonggi), 2(Gangwon), 3(Chungcheong), 4(Jeolla),
5(Gyeongsang)
Number of spans(ea) 1 – 16
Span length(m) 25, 30, 35
type of foundation 1(Direct foundation), 2(Pile foundation), 3(Hybrid foundation)
3.3 상부면적 원단위분석
본 연구에서 구축한 환경부하량 데이터베이스 중에서 검 증사례 DB를 제외한 160개의 사례를 활용하여 Beam교의 상 부면적당 PSC 환경부하량 원단위(Eco-point/상부면적(m2)) 를 산정하였다. 범주별 환경부하량 원단위 및 합계는 다음
<Table 3>과 같다.
Table 3. Basic Units of environmental Load by impact category
Basic Units of environmental (Eco-point/upper area(m
2))
ARD AD EU GW OD POC TET HT Total
0.0535 0.0025 0.0026 0.0812 0.0008 0.0162 0.0027 0.0137 0.1732
4. 인공신경망을 활용한 추정 모델 4.1 신경망 구조 구축
본 연구의 인공신경망 모델은 상용 소프트웨어인 Mathworks사의 MATLAB 2016a 툴박스를 튜닝하여 신경망 모델을 구축하였다. 신경망모델의 구조는 다층인공신경망으 로써 <Fig. 3>과 같이 입력층 개수 1개, 은닉층 개수 l개, 출력 층 개수 1개로 구성된다.
Fig. 3. Diagram of ANN model for environmental load estimation
일반적으로 과소한 노드 수를 적용하면 학습과정에서 큰 오차를 유발하여 신경망의 성능이 떨어질 수 있다. 반면 과다 한 노드 수를 적용하면 적은 학습오차를 가질 수 있으나 오버 피팅 이슈로 인한 일반화 오류가 클 수 있다(Huang, 2003).
이와 같은 이유로 적절한 노드 수를 선택하기 위해 여러 개의 노드 수를 고려한 시행착오법으로 실험한다. 우선 선정된 입 력변수는 정량변수와 정성변수로 구성되며, 원시데이터의 스 펙트럼이 넓기 때문에 스케일링 과정 없이는 충분한 학습효 과를 얻기 위해서는 가중치를 정규화 할 필요가 있다. 따라서 다음 식(1)과 같이 최대-최소 정규화의 과정을 거쳐 0∼1사 이의 값으로 스케일링하여 입력층에 적용한다.
(1)
이후 순전파 연산 과정을 통해 출력값이 도출하며, 은닉 층과 출력층에서의 활성화 함수는 시그모이드 전이 함수 (Sigmoid transfer function)를 사용한다.
4.2 파라미터 선정
역전파 인공신경망은 입력측, 출력층 및 은닉층의 구조와 학습률, 학습 횟수와 같은 파라미터에 따라 학습효율 및 성능 이 크게 변화하기 때문에 모델의 성능을 결정하는 파라미터 를 적절하게 설정해야 한다.
따라서 신경망의 학습과정에서 필요한 파라미터는 다음 과 같이 설정한다. 초기가중치는 랜덤으로 부여하며 학습횟 수(epoch)는 1000, 학습률은 0.01~0.001, 모멘텀은 0.5~0.9 로 고려한다. 이후 은닉층의 노드 개수를 결정해야하는데, Huang (2003)은 데이터베이스의 개수를 기준으로 최상의 성 능을 갖는 은닉층의 노드 수를 결정할 수 있는 식을 다음과 같이 제안하였다.
(2)
은닉층의 개수은 1개이므로 m값은 1이며, Training set으 로 130개를 이용하기로 했으므로 식(2)를 통해 을 산출했을 때 6.58이 도출된다. 따라서 본 연구에서는 앞서 도출된 6.58 개의 은닉층의 노드수를 기준으로, 1~15개를 고려하여 시행 착오법을 통해 파라미터를 결정한다.
4.3 인공신경망의 학습
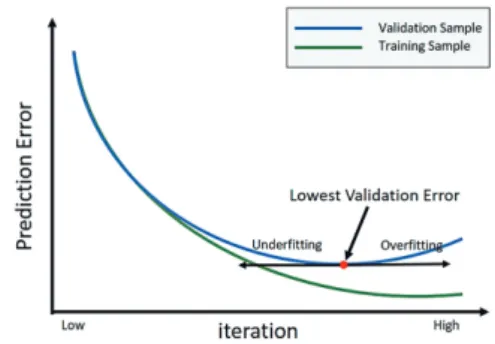
우수한 성능을 갖는 인공신경망 모델을 구축하기 위해서 는 최적의 신경망 구조와 파라미터를 선정하는 것이 무엇보 다도 중요하다. 따라서 본 연구에서는 학습방법은 오차역전 파 알고리즘(Back-propagation)을 이용하며 학습규칙은 일 반적으로 널리 이용되는 Levenberg-Marquardt 방식을 활 용한다. 또한 모델 학습과정에서 발생할 수 있는 오버피팅을 억제하기 위해 조기종료(Early stopping), 교차검증(Cross validation)의 방법을 적용한다.
우선 학습용, 검증용, 테스트용 데이터셋을 구성해야 한
다. Suthaharan (2015)에 의하면 감독학습에서 Training, Validation, Test set의 구성은 일반적으로 80:20, 90:10, 70:30, 60:20:20 등의 비율로 활용되며 데이터베이스의 특 성에 따라서 선택적인 비율 적용이 가능하다. 따라서 기존 연구의 모델과 비교분석하기 위해서 총 168개의 데이터베이 스 중에서 Test set은 8개(4.76%)로 선정하였으며, 데이터 셋의 구성비율을 고려하여 Training set은 130개(77.38%), Validation set은 30개(17.86%)로 나누어 활용한다. Training set은 모델의 튜닝 및 학습을 위해서 활용되며, 데이터베이스 의 특성이 포괄적으로 반영되고 편향되지 않도록 구성하는 것이 중요하다. 따라서 구축된 데이터를 기반으로 각 속성별 로 모든 스펙트럼이 Training set에 포함되도록 구성한다.
학습과정에서 Training set과 Validation set에 대한 성 능평가는 매개변수의 미소한 변화를 반영하기 위해 손실함 수를 적용한다. 본 연구에서는 손실함수로써 일반적으로 쓰 이는 평균제곱오차(Mean squared error, MSE)를 이용하 며, 최적 파라미터 탐색을 위한 과정에서는 정확도를 나타내 는 Validation set의 절대평균오차율(Mean Absolute Error, MAE)이 최소가 되는 파라미터를 탐색한다. 이때 Validation set은 Training set을 통해서 학습중인 모델이 오버피팅 혹은 언더피팅 상태인지 확인하면서 최적의 학습점인지 평가한다.
즉, 오차를 최소화하는 인공신경망의 구조와 파라미터를 결정 하며 이후 Test set을 활용하여 최종 결정된 모델을 검증한다.
조기종료 과정에서는 Validation set을 통해서 오버피팅을 감지하며, 오버피팅이 발생하기 이전의 시점을 적정한 반복 회수로 판단하고 학습을 종료한다. 조기종료의 개요도는 다 음 <Fig. 4>와 같다.
Fig. 4. Concept of learning process applying early stopping
학습방법은 매 시험마다 Training set과 Validation set 의 구성이 무작위로 설정하는 교차검증 방식으로 진행한 다. 학습을 통해 산출된 연결가중치인 를 신경망에 적용하 고 Validation set에 적용하여 평균제곱오차(Mean Squared Error, MSE)가 가장 낮을 때의 가중치를 취하며 그 식은 다음 식(3)과 같다.
(3)
이와 같은 방법으로 환경부하량 추정모델을 구축하였으며, 신경망 구조, 학습방법, 최적 파라미터 탐색방법, 성능평가방 법, 데이터 구성 등 환경부하량 추정모델의 상세정보를 요약 하면 <Table 4>와 같다.
Table 4. Details of ANN model
Type Transfer function Method of learning
Multi-layer neuralnetwork
Sigmoid transfer
function Back-propagation
Algorithm of learning Parameter search Performance evaluation
Levenberg-
Marquardt(LM) Trial and error method Mean sqared error(MSE)
Epoch Learning rate Momentum
1000 0.01-0.001 0.5-0.9
Number of training data Number of validation
data Number of test data
130 (77.38%) 30 (17.86%) 8 (4.76%)5. 환경부하량 추정 모델의 적용 5.1 모델 학습결과
ANN-1 모델의 경우 5개의 입력변수를 활용하고 은닉층의 노드수를 1~15까지 고려하여 시행착오법을 통해 학습을 진 행하였다. 또한 조기종료 방법을 적용하여 Validation set의
평균제곱오차가 최소가 되는 지점에서 학습을 중단하도록 하 였다.
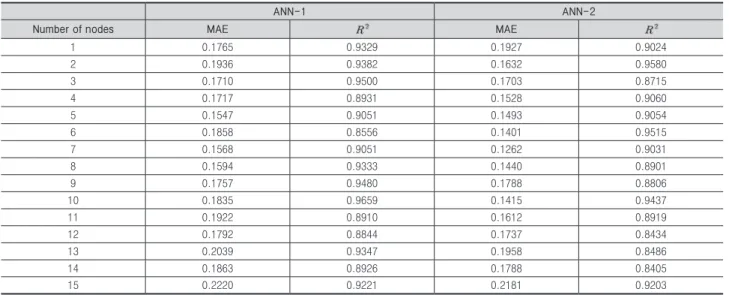
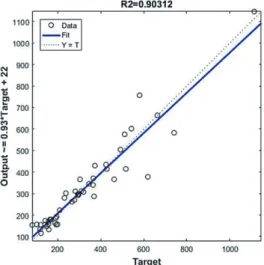
<Table 5>는 은닉층 노드가 1~15개일 경우 Validation set 에 대한 절대평균오차율 및 값을 나타내고 있다. ANN-1의 경우 노드의 개수가 5개 일 때 0.1547로 가장 우수한 절대평 균오차율을 가지며 값은 0.9051로 나타났다. 또한 ANN-2의 경우 노드의 개수가 7개 일 때 Validation set에 대해 0.1282 로 가장 우수한 절대평균오차율을 가지며 값은 0.9031로 나 타났다. 다음 <Fig. 5-6>은 ANN-1 및 ANN-2모델이 환경 부하량 실제값 대비 추정값이 과도하게 혹은 과소하게 추정 했는지를 나타내고 있으며, 두 모델 모두 Validation set에 대 해 목표값과 추정된 환경부하량 값이 매우 근사하다는 것을 나타내고 있다. Training set 뿐만 아니라 Validation set에 대해서도 우수한 성능을 갖는 점으로 미루어봤을 때, 학습과 정에서 오버피팅이 발생하지 않았으며 범용성을 갖는 모델인 것으로 판단된다.
5.2 환경부하량 추정모델 사례적용
본 연구에서 제시한 추정모델의 신뢰도를 평가하기 위하여 유사한 입력정보를 활용한 기존연구의 GA-based CBR모델, 원단위산정방법과 비교분석을 수행하였다. ANN-1, ANN- 2 모델의 정확도를 분석하기 위하여 8개의 4차로 사례로 이 루어진 Test set을 활용하였다. Test set은 추정결과의 신뢰 성 확보를 위하여 입력변수의 속성값이 편향되지 않으며 다 양하게 분포되도록 구성하였다.
첫번째로 GA-CBR1모델과 ANN-1모델과 비교분석을 수 행하였다. 다음의 <Table 6-7>은 검증사례별 실제 환경부하 량과 추정된 환경부하량과의 오차율을 나타내고 있다. GA- CBR1의 경우 절대평균오차율은 14.21%이며, 표준편차는 5.11%, 오차범위는 -24.41%에서 +16.59%로 나타났다. 또한
Table 5. MAE and value of Validation set according to the number of nodes of hidden layer
ANN-1 ANN-2
Number of nodes MAE MAE
1 0.1765 0.9329 0.1927 0.9024
2 0.1936 0.9382 0.1632 0.9580
3 0.1710 0.9500 0.1703 0.8715
4 0.1717 0.8931 0.1528 0.9060
5 0.1547 0.9051 0.1493 0.9054
6 0.1858 0.8556 0.1401 0.9515
7 0.1568 0.9051 0.1262 0.9031
8 0.1594 0.9333 0.1440 0.8901
9 0.1757 0.9480 0.1788 0.8806
10 0.1835 0.9659 0.1415 0.9437
11 0.1922 0.8910 0.1612 0.8919
12 0.1792 0.8844 0.1737 0.8434
13 0.2039 0.9347 0.1958 0.8486
14 0.1863 0.8926 0.1788 0.8405
15 0.2220 0.9221 0.2181 0.9203
Fig. 5. Predicted versus actual values of ANN-1 validation set Fig. 6. Predicted versus actual values of ANN-2 validation set
Table 6. ANN-1 model environmental load estimation results
Case Actual environmental load (Eco-point)
ANN-1 CBR l Basic Units
(Eco-point/upper area(m
2)) Estimated value
(Eco-point) Error Estimated value
(Eco-point) Error Estimated value
(Eco-point) Error
1 2.20E+02 1.78E+02 -23.26% 1.66E+02 -24.41% 1.30.E+02 -40.97%
2 2.59.E+02 2.73E+02 4.94% 2.88E+02 11.07% 3.53.E+02 35.85%
3 2.44.E+02 2.69E+02 9.48% 2.64E+02 8.42% 3.23.E+02 32.60%
4 3.03.E+02 3.27E+02 7.41% 3.54E+02 16.59% 4.31.E+02 42.11%
5 2.38.E+02 2.08E+02 -14.44% 2.66E+02 11.93% 2.81.E+02 18.08%
6 1.28.E+03 1.18E+03 -8.51% 1.39E+03 9.26% 1.41.E+03 10.80%
7 6.10.E+02 5.43E+02 -12.23% 6.89E+02 13.02% 8.71.E+02 42.88%
8 2.13.E+02 2.34E+02 9.26% 1.71E+02 -19.32% 1.60.E+02 -24.80%
Mean absolute error
11.19% 14.21% 31.01%Standard deviation
5.30% 5.11% 11.20%Maximum Error
23.26% 24.41% 42.88%Minimum Error
4.94% 8.42% 10.80%Table 7. ANN-2 model environmental load estimation results
Case Actual environmental load (Eco-point)
ANN-2 CBR ll
Estimated value
(Eco-point) Error Estimated value
(Eco-point) Error
1 2.20E+02 1.93E+02 -12.31% 1.83E+02 -16.51%
2 2.59.E+02 2.94E+02 13.46% 2.89.E+02 11.38%
3 2.44.E+02 2.64E+02 8.21% 2.64.E+02 8.25%
4 3.03.E+02 3.40E+02 12.17% 3.42.E+02 12.72%
5 2.38.E+02 2.48E+02 4.38% 2.65E+02 11.29%
6 1.28.E+03 1.12E+03 -11.89% 1.15E+03 -9.93%
7 6.10.E+02 5.70E+02 -6.45% 6.38E+02 4.65%
8 2.13.E+02 2.29E+02 7.81% 1.86.E+02 -12.56%
Mean absolute error
9.59% 10.91%Standard deviation
3.09% 3.26%Maximum Error
13.46% 16.51%Minimum Error
4.38% 4.65%원단위산정방법은 절대평균오차율은 31.01%이며, 표준편차 는 11.20%, 오차범위는 -40.97%에서 +42.88%로 나타났다.
그리고 ANN-1모델의 절대평균오차율은 11.19%이며, 표준편 차는 5.30%, 오차범위는 –23.26%에서 +9.46%로 나타났다.
GA-CBR1과 비교했을 때 절대평균오차율이 더 적은 것으로 나타났다.
반면에 GA-CBR2의 절대평균오차율은 10.91%이며, 표준 편차는 3.26%, 오차범위는 –16.51%에서 +12.72%로 나타났 다. 그리고 ANN-2모델의 8개 검증사례에 대한 절대평균오 차율은 9.56%, 표준편차는 3.09%, 오차범위는 –12.31%에서 +13.46%로 나타났다. ANN-2모델 또한 GA-CBR2와 비교 했을 때 절대평균오차율 및 표준편차가 더 적은 것으로 나타 났다.
ANN-1보다 ANN-2 모델이 더욱 우수한 정확도를 갖는 다는 점으로 미루어 보았을 때, 2차에서 확장된 입력변수가 환경부하량과의 상관성이 있으며 입력변수로 활용할만한 가 치가 있다는 것을 의미한다. 환경부하량 추정에 관한 구체 적인 기준은 없지만, AACE (American Association of Cost Engineering)의 단계별 예산평가분류표의 Class 4, 5단계 를 살펴보면 기획단계 및 기본설계단계에 구축하고자 하는 모델의 목표신뢰도를 각각 ±25%, ±15%로 제시하고 있다 (Christensen & Dysert, 2005). 이와 같은 기준을 참조하여 환경부하량 추정 모델의 추정범위와 비교한 결과, 기획단계 에서의 환경부하 추정 목표범위인 ±25%와 기본설계단계에 서의 추정 목표범위인 ±15%에 ANN-1, ANN-2모델 모두 정확도 목표범위를 충족하는 것으로 나타났다.
6. 결론
본 연구에서는 LCI DB를 활용하여 구축한 데이터베이스를 기반으로 도로건설 프로젝트 기획단계 및 기본설계단계에서 PSC Beam교의 시공단계에서 발생하는 환경부하량을 신속 하고 정확하게 평가하기 위하여 인공신경망을 활용한 환경부 하량 추정모델을 구축하였다. 2000∼2009년 사이에 준공된 PSC Beam교의 실적데이터에 개별적산법을 적용하여 168개 사례의 환경부하량을 분석하여 데이터베이스를 구축하였다.
또한 복잡하고 다양한 스펙트럼을 가진 데이터베이스의 특징 을 고려해서 인공신경망을 활용하여 입력값-출력값 사이의 상관관계를 분석하고자 하였다. LM알고리즘과 시행착오법 을 통해 최적의 신경망의 구조 및 파라미터를 결정하여 최종 모델을 확정하였다. 이후 확정된 ANN-1, ANN-2모델에 대 해 사례적용으로 성능을 검증하였으며, 기존연구의 결과물인 GA-CBR모델과 비교하여 신뢰도를 평가하였다.
본 연구를 통해 도출한 결론은 다음과 같다. 첫째, 건설프 로젝트의 기획단계·기본설계단계에서의 가용정보를 분석
하고 각 단계별로 모델을 구축하였다. 입력변수는 환경부하 량에 영향을 미치는 요인들을 설계도서 및 선행연구를 참조 하여 도출하였고 사업단계에 따른 가용정보 수준에 맞춰 두 개의 인공신경망모델 ANN-1 및 ANN-2를 구축하였다. 또 한 Validation set의 오차가 최소가 되는 최적의 파라미터를 탐색하기 위해 1개부터 15개의 은닉층 노드를 대상으로 시행 착오법을 통해 신경망의 구조와 파라미터를 결정하였다. 이 때 오버피팅을 방지하기 위해 교차검증 및 조기종료 방법을 활용하였으며, 두 모델 모두 Validation set에 대해서 절대평 균오차율이 15.47%, 12.62%로 나타났으며 값이 0.9 이상으 로 실제값과 추정값 사이에 높은 상관성을 갖는 것으로 분석 되었다. 학습과정에서 오버피팅이 발생하지 않았기 때문에 Validation set에 대해서도 적용이 가능하며 범용성을 갖는 것으로 판단된다.
둘째, 8개의 검증사례를 적용하여 구축된 모델의 신뢰도를 검증한 결과, ANN-1, ANN-2모델의 절대평균오차율과 표 준편차는 각각 11.19% / 5.30% 및 9.59% / 3.09%로 높은 신 뢰성을 갖는 것으로 나타났다. 또한 ANN-2 모델이 더욱 우 수한 정확도를 갖는다는 점을 감안할 때 확장된 2차 입력변 수는 환경부하량과 상관성이 있는 것으로 확인가능하다.
셋째, 사례적용을 통한 검증결과로 미루어 봤을 때 사전에 설정한 정확도 목표범위를 만족하며, 적절한 정확도와 신뢰 도를 가지므로 각 단계에서 개략적인 환경부하량 추정에 적 용하기에 적합한 것으로 판단된다.
본 연구를 통해 도출된 결과물은 PSC Beam교 프로젝트의 초기단계에서 제한된 시설물 가용정보들만을 활용하여 신속 하고 정확하게 시공단계에서 발생하는 환경부하량 추정이 가 능하기 때문에, 효과적으로 다양한 건설 대안 비교가 가능하 다. 따라서 본 연구에서 제시하는 모델은 건설 프로젝트 초기 단계에서 기초적인 가용정보만을 활용하여 신속하고 정확하 게 환경부하량을 추정하고 합리적인 의사결정을 지원할 수 있을 것으로 기대된다. 후행연구에서는 4차로 교량뿐만 아니 라 다양한 규격의 사례에 대해서도 검증해야 할 것이며, 또한 프로젝트 초기에 적용할 수 있도록 환경부하량과 상관성을 가지는 입력변수를 추가적으로 분석할 필요가 있다.
감사의 글
본 연구는 국토교통부 건설기술연구사업의 연구비지원 (17SCIP-C085707-04)에 의해 수행되었습니다.
References
Association for the Advancement of Cost Engineering (AACE) (2011). “Cost estimate classification system- as applied in engineering, procurement, and construction for the process industries.” 2(18), R-97.
Christensen, P., and Dysert, L. R. (2005). “Cost Estimate Classification System. as Applied in Engineering, Procurement, and Construction for the Process Industries.” AACE International Recommended Practices.
Crawford, R. H. (2011). “Life cycle assessment in the built environment.” Spon Press.
Elazouni, A. M., Ali, A. E., and Abdel-Razek, R.
H. (2005). “Estimating the Acceptability of New Formwork Systems Using Neural Networks.” Journal of Construction Engineering and Management, 131(1), pp. 33–41.
Gunaydin, H. M.,, and Dogan, S. Z. (2004). “A neural network approach for early cost estimation of structural systems of buildings.” International Journal of Project Management, 22, pp. 595–602.
Han, H., Kim, J. H., Yoon, J. H., and Seo, J. W. (2011).
“Road Construction Cost Estimation Model in the Planning Phase Using Artificial Neural Network.”
Journal of the Korean Society of Civil Engineering, KSCE, 31(6), pp. 829-837.
Huang, G. (2003). “Learning capability and storage capacity of two-hidden-layer feedforward networks.” IEEE Trans. Neural Networks, 14(2), pp.
274-281.
ISO (2006). “Environmental Management-Life Cycle Assessment-Principles and Framework.” ISO:
Geneva, Switzerland.
Jeong, K., Ji, C., Hong, T., and Park, H. S. (2015). “A model for predicting the environmental impacts of educational facilities in the project planning phase.”
Journal of cleaner production, 107, pp. 538-549.
Kang, M., and Park, H. (2013). “A Study of the Combination Method for Earthwork Equipments Using the Environmental Loads and Costs.” Journal of the Korean Society of Civil Engineering, KSCE, 33(3), pp. 1215-1224.
Kim, B. S. (2010). “The approximate cost estimating model for railway bridge project in the planning
phase using CBR method.” Journal of the Korean Society of Civil Engineering, KSCE,, 15(7), pp. 1149- 1159.
Kim, K. J., Yun, W. G., Cho, N., and Ha, J. (2017).
“Life cycle assessment based environmental impact estimation model for pre-stressed concrete beam bridge in the early design phase.” Environmental Impact Assessment Review, 64, pp. 47-56.
Kim, M., Moon, H., and Kang, L. (2013). “Development of an Approximate Cost Estimating Model for Bridge Construction Project using CBR Method.”
Korean Journal of Construction Engineering and Management, KICEM, 14(3), pp. 42-52.
Koo, C., Hong, T., and Hyun, C. (2011). “The development of a construction cost prediction model with improved prediction capacity using the advanced CBR approach.” Expert Systems with Applications, 38(7), pp. 8597-8606.
Lee, K., and Yang J. (2009). “A Study on the Functional Unit Estimation of Energy Consumption and Carbon Dioxide Emission in the Construction Materials.”
Journal of the Architectural Institute of Korea Planning & Design, 25(6), pp. 43-50.
Lowe, D. J., Emsley, M. W., and Harding, A. (2006).
“Predicting construction cost using multiple regression techniques.” Journal of Construction Engineering and Management, 132(7), pp. 750-758.
Moon, H., Hyun, C., and Hong, T. (2014). “Prediction Model of CO2 Emission for Residential Buildings in South Korea.” Journal of Management in Engineering, 30(3), pp. 04014001 : 1-04014001 : 7.
Park, K., Hwang, Y., Seo, S., and Seo, H. (2003).
“Quantitative Assessment of Environmental Impacts on Life Cycle of Highways.” Journal of Construction Engineering and Management, 129(1), pp. 25-31.
Suthaharan, S. (2015). “Machine Learning Models and Algorithms for Big Data Classification.” Springer.
Sonmez, R. (2008). “Parametric range estimating of building costs using regression models and bootstrap.” Journal of Construction Engineering and Management, 134(12), pp. 1011–1016.
Trost, S. M., and Oberlender, G. D. (2003). “Predicting Accuracy of Early Cost Estimates Using Factor analysis and Multivariate Regression.” Journal of construction engineering and management, 129(2),
pp. 198-204.
Wang, X., Duan, Z., Wu, L., and Yanga, D. (2015).
“Estimation of carbon dioxide emission in highway construction: a case study in southwest region of China.” Journal of Cleaner Production, 103, pp. 705- 714.
Woo, J. (2011). “Sustainable Optimum Design Evaluation System Development by Environmental and Economical Efficiency of Life Cycle of the Apartment Houses.” Ph.D. thesis, Hanyang University.
Yun, W. G., Ha, J. K., and Kim, K. J. (2017). “An Analysis of the Characteristics of Standard Work and Design Information on Estimating Environmental Loads of PSC Beam Bridge in the Design Phase.”
Journal of the Korean Society of Civil Engineering, KSCE, 37(4), pp. 705-716.
요약 :
건설사업 초기단계가 환경부하량의 절감 가능성에 큰 영향을 미친다는 것을 감안한다면, 효과적인 의사결정을 지원할 수 있 는 시스템을 초기에 구축하고 활용하는 것이 중요하다. 이에 본 연구에서는 기본적인 설계 요인들을 고려하여 초기 설계단계에서 활용될 수 있는 환경부하량 산정 모델을 구축하였다. 이 모델은 인공신경망 기법을 활용하고 설계단계 업무가 진행됨에 따라 얻을 수 있는 가용정보 수준을 고려하여 기획단계 적용 모델(ANN-1)과 기본 설계단계 적용 모델(ANN-2)로 구분하여 환경부하량을 산정하도록 구축되었다. 모델의 실험결과 ANN-1, ANN-2모델의 절대평균오차율과 표준편차는 각각 11.19% / 5.30% 및 9.59%
/ 3.09%로 높은 신뢰성을 갖는 것으로 나타났다. 본 모델은 프로젝트 초기단계별 기초적인 가용정보만을 활용하여 신속하고 정확 하게 환경부하량을 추정하고 합리적인 의사결정을 지원할 수 있을 것으로 기대된다.
키워드 :