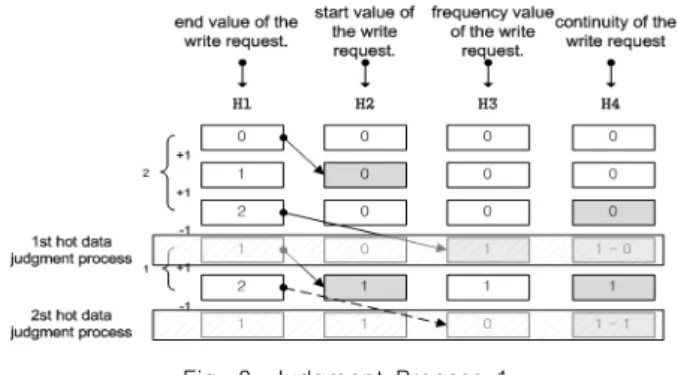
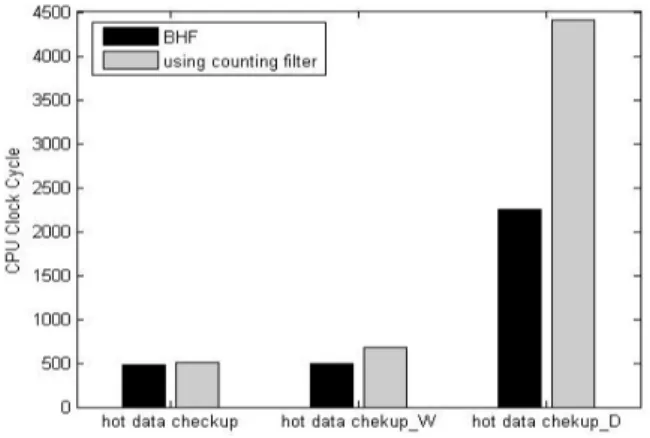
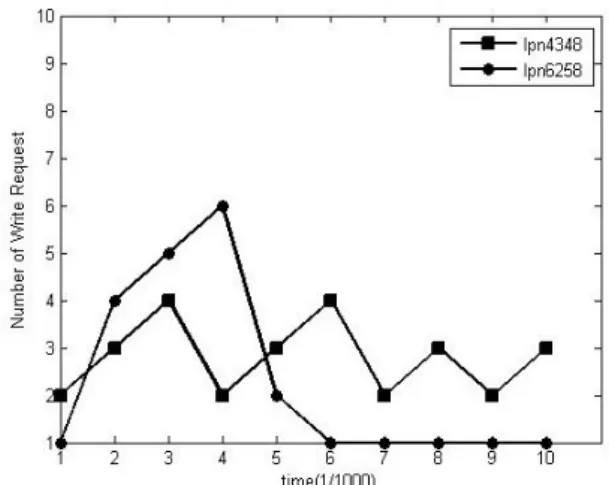
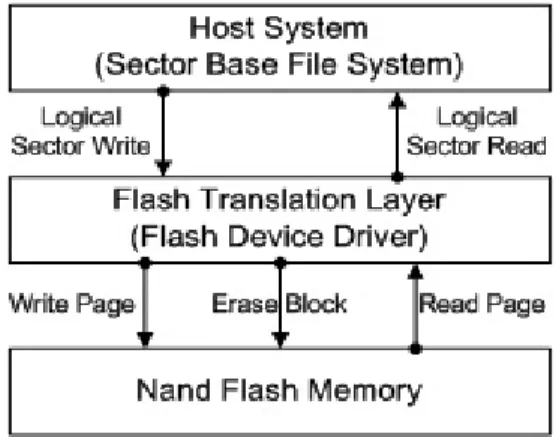
Hot Data Verification Method Considering Continuity and Frequency of Write Requests Using Counting Filter
1)
전체 글
1)
수치
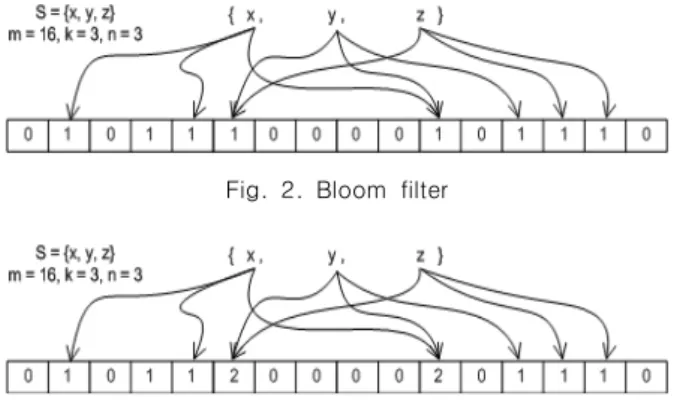
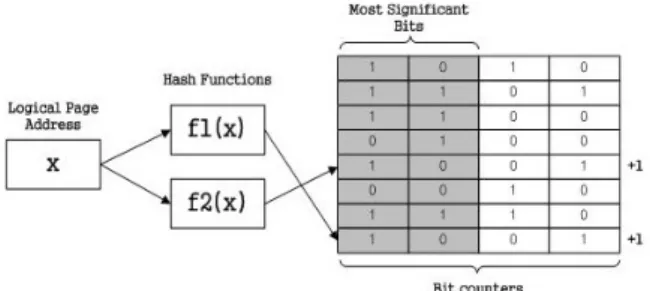
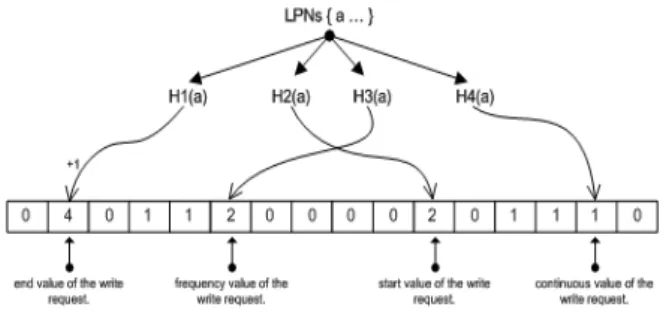
관련 문서
Based on the results of root cause analysis, the following corrective action to mitigate the erosion and corrosion damage at hot leg check valve were
Hot embossing is a technique of imprinting nanostructures on a substrate (polymer) using a master mold (silicon tool).. Master/mold
핵심주제어 부도예측 혼합주기 자료 신용위험 모니터링
limited evidence). Panel a) For hot extremes, the evidence is mostly drawn from changes in metrics based on daily maximum temperatures; regional studies using other
The field measurement were conducted to examine thermal environment and energy consumption in greenhouses model with hot-air heating system. Then the
(1) The sheet hot-rolled at lower hot-rolling temperature and higher reduction rate revels many cracks at the edge of the hot-rolled sheet in Mg-Al-Zn
저작권법에 따른 이용자의 권리는 위의 내용에 의하여 영향을 받지 않습니다.. 이것은 이용허락규약 (Legal Code) 을 이해하기
In this study, sequential solvent fractions of hot water extract and 70% ethanol extract were prepared from domestic (Imsil region) and foreign (Chile