저작자표시-비영리-변경금지 2.0 대한민국 이용자는 아래의 조건을 따르는 경우에 한하여 자유롭게 l 이 저작물을 복제, 배포, 전송, 전시, 공연 및 방송할 수 있습니다. 다음과 같은 조건을 따라야 합니다: l 귀하는, 이 저작물의 재이용이나 배포의 경우, 이 저작물에 적용된 이용허락조건 을 명확하게 나타내어야 합니다. l 저작권자로부터 별도의 허가를 받으면 이러한 조건들은 적용되지 않습니다. 저작권법에 따른 이용자의 권리는 위의 내용에 의하여 영향을 받지 않습니다. 이것은 이용허락규약(Legal Code)을 이해하기 쉽게 요약한 것입니다. Disclaimer 저작자표시. 귀하는 원저작자를 표시하여야 합니다. 비영리. 귀하는 이 저작물을 영리 목적으로 이용할 수 없습니다. 변경금지. 귀하는 이 저작물을 개작, 변형 또는 가공할 수 없습니다.
이학 석사학위 논문
보상과 관련된 복측해마의 신경신호
아 주 대 학 교 대 학 원
의생명과학과/신경과학전공
보상과 관련된 복측해마의 신경신호
지도교수 정 민 환
이 논문을 이학 석사학위 논문으로 제출함.
2011년 2월
아 주 대 학 교 대 학 원
의생명과학과/신경과학전공
이 성 현
이성현의 이학 석사학위 논문을 인준함.
심사위원장 백 은 주 인
심 사 위 원 정 민 환 인
심 사 위 원 김 병 곤 인
아 주 대 학 교 대 학 원
2010년 12월 23일
감사의 글
실험실에 들어온 지 어느덧 3년의 시간이 흘렀다. ‘지각인생’이란 짧은 글을 쓴 손석희 교수와 같이 나의 인생도 다른 사람들에 비하면 지각인생일 수도 있 을 것이다. 학부 10년과 석사 3년의 시간은 남들의 시선에는 불안했나보다. 체력 은 점점 떨어지고 머리는 점점 둔해지지만 가장 무서운 건 열정을 잃어버린 것 이었다. 하지만 논문을 준비하면서 내 안에서 없어졌던 열정들을 다시 한 번 느 낄 수 있어서 나에게는 의미 있는 시간들이었다. 이 논문을 준비하기까지 여러 가지로 가르쳐 주시고 지도해주신 싸부님과 지도위원으로 조언을 해주신 백은주 교수님, 김병곤 교수님께 감사드린다. 또한 3년간 동고동락하며 많은 도움을 준 실험실 식구들-허쌤, 정욱형님, 호석선배, 현정이, 종원형님, 지은선배, 지현선배, 정훈형님, 수현선배, 신애선배, 막내고운, 자영-에게 감사드린다. 특히 내 친구이 자 나의 사수이기에 무서웠던(?) 현정이, Matlab을 하나하나 가르쳐주고 분석에 대한 맛을 보게 해준 호석 선배, 언제나 든든한 버팀목이 되어준 사랑하는 정훈 형님, 내 옆에서 나를 웃게(?) 해주는 신애 선배, 막내로서 여러 가지 힘든 일을 잘 감당해준 고운이까지... 너무너무 좋은 사람들과 함께여서 행복하다. 그리고 언제나 물심양면으로 묵묵히 응원해주시는 사랑하는 부모님과 내 동 생 선진이, 너무도 부족한대도 한결같은 마음으로 사랑해주시고 아껴주신 사랑하 는 영의 아버지인 목사님과 영의 어머니인 사모님, 내 동생들인 지현이와 준석 이, 그리고 든든한 기도의 지원군이 되어준 끝까지 함께 걸어갈 하늘의 별 식구 들, 또한 런던임마누엘 식구들에게 감사의 마음을 전한다. 무엇보다 아직 고칠 것이 많은 나를 사랑해주고 옆에서 힘이 되어준 사랑하는 보령이에게 감사와 사 랑의 마음을 전한다. 끝으로, 이 모든 것이 합력하여 선을 이룰 수 있도록 이끄시고 인도해주시 고 지금도 여전한 사랑으로 기다리고 계시는 사랑하는 하나님께 이 모든 영광을 돌린다.1 -- 국문요약 --
보상에 관련된 복측해마의 신경신호
기억과 학습에 관여하는 것으로 알려진 해마는 공간적 정보를 처리한다고 알려져 있다. 해마는 해부학적으로 암몬각과 치아이랑으로 이루어져 있으며 특히 암몬각은 4개의 부위로 이루어져 있다. 이 중에 가장 많이 연구된 부분은 CA1이 다. 해마는 크게 두 부분으로 나눌 수 있는데 배측해마와 복측해마로 나눌 수 있 다. 이 두 부위는 다른 역할을 하는 것으로 알려져 있다. 최근 들어 해마와 보상 의 연관성에 대한 연구가 많이 이루어지고 있으나 정확한 연관관계가 밝혀지지 않았다. 그래서 본 실험에서 복측해마에 초점을 맞추어 복측해마의 보상에 대한 신경신호를 연구하였다.Dual-assignment with hold task를 사용하여 쥐의 행동실험을 했으며, 행동 분석을 통해 쥐가 강화학습이론(reinforcement learning theory)에 맞게 행동함을 나타내었다. 그리고 행동 구간을 나눠서 분석한 결과, 현재 시행에서 보상에 대 한 소리신호가 주어지는 Conditional Stimulus(CS)구간과 보상으로 물이 나오는 Reward(Rw)구간에서 반응하는 신경세포들이 가장 많이 나타났다. 이것을 통해 복측해마가 보상에 대하여 반응함을 알 수 있다. 그리고 보상에 대한 가치를 표 상하는지 여부를 분석했다. 그 결과, CS구간에서는 선택했을 때에 받을 수 있는 예상가치인 chosen value가 강하게 나타났지만 Rw 구간에서는 현저하게 낮아짐 을 볼 수 있었다. 이것은 CS구간에서 선택한 것에 대한 보상의 가치가 표상되지 만 Rw 구간에서는 이미 보상을 얻은 후이기 때문에 더 이상 보상의 가치는 의 미가 없어지게 된다. 그래서 Rw에서는 chosen value가 줄어들었다고 사료된다. 위의 결과를 통해, 복측해마의 신경세포들이 보상에 대하여 반응하고 보상 에 대한 가치를 표상함을 알 수 있다. 핵심어 : 복측해마, 보상, 가치, 선택, 강화학습, CA1 - ii - i
-차 례
국문요약 ………···………· i 차례 ………···………· ii 그림 차례 ………···………·· iii 표 차례 ………···………·· iv Ⅰ. 서론 ………···………···· 1 Ⅱ. 실험방법 ···‥··· 2 A. 실험동물 ··· 2 B. 행동실험 ··· 2 C. 전극장치 ··· 4 D. 동물시술 ··· 4 E. 신경활성도 측정 ··· 6 F. 뇌조직 처리 ‥···‥···· 6 G. 통계학적 분석 …··· 6 1. 다중회귀분석 ‥···‥··· 62. 강화학습 모델(stack probability model) ···…···· 7
Ⅲ. 결과 ··· 9 A. 신경세포의 분류 및 분석 ··‥··· 9 B. 행동분석 ···‥··· 9 C. 선택(choice)과 보상(reward)에 대한 신경신호 ‥··· 12 D. 가치(value)에 대한 신경활성도 ‥···‥··· 16 Ⅳ. 고찰 ···‥··· 21 Ⅴ. 결론 ···‥··· 22 참고문헌 ··· 23 ABSTRACT ···‥···‥··· 25
3
-그림 차례
Fig. 1. Behavioral task ···‥··· 3 Fig. 2. Recording sites ···‥···‥·‥··· 5 Fig. 3. Effects of past choices and their outcomes on animal's current
choice ···‥···‥·‥···10 Fig. 4. Performance of animals ·‥··‥···‥···‥··· 11 Fig. 5. Neural signals for choice and its outcome in the current and previous trials 13 Fig. 6. Neural signals for choice outcome ··· 14 Fig. 7. An example neuron that modulated its activity according to choice outcome ··· 15 Fig. 8. Neural signals for decision value and chosen value ···‥···‥·‥·‥ 18 Fig. 9. High resolution plot for chosen value signals ··‥···‥·…·‥·‥‥·…19
-표 차례
1
-Ⅰ. 서론
해마(hippocampus)는 수많은 연구를 통해 기억과 학습에 관여한다고 알려 져 있다. 그리고 위치세포(place cell, O'keefe and Conway, 1978; McNaughton 등, 2006)를 가지고 있어서 장소에 대한 정보를 처리할 때 중요한 역할을 한다고 한다. 이러한 해마는 해부학적으로 크게 두 부분으로 나눌 수 있다. 암몬각 (cornu ammonis)이라고 불리우는 부분과 치아이랑(dentate gyrus)이라고 불리우 는 부분이다. 특히 암몬각의 경우는 CA1부터 CA4까지 나뉘며 많은 연구가 CA1 과 CA3에 집중되어 있다.
해마는 ‘C'자 모양으로 위치하고 있으며 위의 부분을 배측해마(dorsal hippocampus)로, 아래의 부분을 복측해마(ventral hippocampus)로 나눌 수 있다. 위치적인 것만 다른 것이 아니라 배측해마와 복측해마는 반응하는 역할도 다르 다고 알려져 있다.(Jung 등, 1994) 배측해마는 위치세포가 많이 분배되어 있어서 공간적 정보(spatial information)를 처리한다고 알려져 있다.(O'keefe and Nadel, 1978) 이와 다르게, 복측해마는 편도체(amygdala)와 연결되어 공포, 감정 등 감 정적인 정보를 처리한다고 알려져 있다.(Jung 등, 1994) 배측해마는 공간적 정보 를 처리하기 때문에 어떤 목표(goal)를 주고 그 곳에 도달했을 때 보상을 주어서 위치세포들이 어떻게 반응하고 관여하는지에 대한 연구가 진행되기도 했 다.(Mallot 등, 2002; Wiener 등, 2003; Dudchenko 등, 2007; Redish 등, 2010) 그 러나 복측해마의 경우에는 배측해마에 비해 깊은 곳에 위치해 있고 일반적으로 알려진대로 공포와 두려움과 같은 감정과 연관된 곳으로 알려졌기 때문에 배측 해마와 같은 연구를 진행한 경우는 찾아보기 힘들다. 본 실험에서는 배측해마와 다른 역할을 하는 복측해마가 보상학습에 어떻게 반응하는지에 대하여 그 결과를 알아보며, 과연 보상에 대하여 어떻게 가치를 계 산하는지 알아보고자 한다.
Ⅱ. 실험방법
A. 실험동물 300∼340g의 SD(Sprague-dawley) 수컷 쥐 4마리를 사용하였다. 실험 전에 쥐가 낯선 환경에 쉽게 적응할 수 있도록 7일 동안 핸들링(handling)을 시켰다. 그리고 본격적인 실험을 할 때, 먹이는 충분히 주되 물 박탈을 실시하여 보상 (reward)에 대한 반응이 지속적으로 나타날 수 있는 상태로 만들었다. B. 행동 실험행동을 할 수 있는 8자 미로(maze)를 만들었다.(Fig. 1.) Dual-assignment with hold task로 행동실험을 진행하였다. 지연구간(D, Fig. 1.)에 쥐를 놓고 쥐가 움직이면서 센서(photo-sensor)를 건드리는 동시에 2초의 지연시간(delay time) 이 주어지게 된다. 지연시간이 끝나게 되면 쥐의 행동을 막았던 올려져있던 다리 가 내려오게 되고 쥐는 앞으로 움직이게 된다. 이후 양 갈래 길에서 쥐는 왼쪽이 나 오른쪽을 선택하게 되고 CS 구역에 설치되어 있는 센서를 쥐가 지나가게 되 면 소리신호가 1초간 주어지게 된다. 물이 나올 경우에는 9kHz의 소리신호가 주 어지게 되고, 물이 나오지 않을 경우에는 1kHz의 소리가 주어지게 된다. 일부 쥐 에게는 이와 반대로 물이 나올 때는 1kHz를 주고, 물이 나오지 않을 때는 9kHz 의 소리 신호를 주었다. 쥐가 오른쪽이나 왼쪽을 선택해서 움직였을 때 각각 40 ㎕의 물이 보상(reward)으로 주어진다. 이 때, 물은 비율(ratio)이 다르게 주어지 는데, 0.12:0.72나 0.63:0.21의 비율로 물이 나오게 된다. 또한 이와 반대의 비율도 물이 나오게 된다. 위의 실험방법에서는 물이 양쪽 모두 나올 수 있고 한 쪽만 물이 나올 수도 있고 양쪽 모두 안 나올 수도 있다. 이 세 가지 경우를 분석에 적용하였다. 물을 먹거나 먹지 않은 쥐는 원래의 출발점으로 되돌아오게 된다. 이것이 한 시행(trial)의 행동과제(task)이다. 각각의 비율이 매 블록(block)마다 주어지며 모두 4블록을 하되 한 블록 당 40±5회 정도로 한다.
2
-Fig. 1. Behavior task. A) This task is divided into 6 stages, delay(D), go(G), A(approach), CS(conditional stimulus), Rw(reward) and Rt(return), in the each trial. Both of blue point is the location of reward. B) 3-dimensional maze.
-C. 전극장치
폴리아미드(polyamide)로 절연된 같은 길이의 니크롬선(nichrome) 2가닥을 손으로 합쳐 놓은 후 반으로 접어서 4가닥으로 만든 후 교반기(stirrer)를 이용하 여 꼬은 후 열풍기(heat gun, HL 1910E, Steinel)를 사용하여 1분 45초 동안 골 고루 가열한 후 식혀서 테트로드(tetrode)를 만들었다. 시술하기 전에 테트로드를 전극장치(microdrive, Neuralynx, Tucson, AZ)의 12개의 튜브에 넣은 후 금 용액 (gold solution)으로 테트로드의 말단 부위를 2㎂의 전기자극으로 코팅하고 임피 던스(impedance)를 0.2 ∼ 0.5mΩ으로 내렸다. 12개의 테트로드를 EIB(electrode interface board)의 구멍에 각각 넣은 후 금핀(gold pin)으로 고정시킨다.
D. 동물 시술
먼저 엔토발(pentobarbital sodium, 50mg/kg)을 복강에 주사하여 마취시킨 다. 머리 부분의 털을 제거한 후 피부를 둘러싸고 있는 피부를 잘라내고 입체정 위기구(stereotaxic apparatus, Kopf)를 사용하여 쥐를 고정하고 시술을 시행하였 다. 두개골이 나올 때까지 피부를 제거하고 치과용 드릴(bur)을 이용하여 두개골 을 뚫는다. 구멍을 뚫은 후 경막(dura mater)과 연막(pia mater)을 제거한 후 전 극장치에 있는 12개의 테트로드를 뇌에 직접 삽입한다. 본 실험의 삽입 목표 부 위는 전측은 -5.8mm, 외측은 ±5.2mm, 복측은 7.0∼7.6mm다.(Fig. 2.) 테트로드를 삽입한 후 본왁스(bone-wax)로 구멍 난 부위를 막고, 치과용 시멘트를 이용하여 머리에 전극장치가 단단히 고정되도록 하였다. 시술 후 항생제(Tardomyocel comp Ⅲ, 0.01ml/100g)와 진통제(Fenylbutazone, 0.01ml/100g)를 주사하고 일주일 정도의 회복기간을 주었다.
4
-Fig. 2. Recording sites. The photomicrograph shows a coronal section of the brain that was stained with cresyl violet. The marking lesions, ventral hippocampus, is shown (yellow arrow).
-E. 신경활성도 측정
쥐의 뇌에서 나오는 신경세포들의 신호를 수집하기 위해 Cheetah 시스템 (Neuralynx, Tucson, AZ)을 사용하였다. 쥐의 머리에 고정된 전극장치에 있는 EIB(electrode interface board)와 헤드스테이지(headstage)를 통해 들어온 신호는 10000배 증폭이 되며, 파형은 600∼6000Hz로 여과되었다. 테트로드가 4개의 가닥 으로 되어 있으며 12개의 튜브에 각각 집어넣어 신호를 수집하기 때문에 48개의 채널을 통해 신호가 수집되고 저장된다. 저장된 자료를 토대로 Mclust(written by A. David Redish, 2003)라는 프로그램을 사용하여 수집된 신호 중 신경활성 도 신호를 분리했다. F. 뇌조직 처리 전극이 정확하게 목표에 들어갔는지 확인하기 위해 실험이 끝난 후 Urethane(0.3ml/100g)로 영구마취한 후 쥐의 뇌를 꺼내기 위해 관류(perfusion)를 시행한다. 먼저 12개의 전극 중 6개를 임의로 골라 전기자극을 30㎂로 20초 동안 줘서 뇌에 인위적 손상을 가한다. 그리고 배를 가르고 심장에 바늘을 꽂아서 PB(Phosphate buffer)용액(0.1M)을 주입하여 쥐의 혈액을 제거한다. 그 후 4% 파라포름알데히드(paraformaldehyde) 용액을 넣어서 조직을 굳힌다. 모든 과정이 끝난 후 쥐의 머리를 자르고 뇌를 꺼낸다. 뇌를 꺼내면 파라포름알데히드 용액이 담긴 병에 2∼3일 동안 뇌를 보관한 다음, 뇌의 수분을 제거하기 위해 30% 설탕 (sucrose) 용액에 2∼3일 정도 담가둔다. 그 후 동결절편기(cryostat)를 이용하여 40㎛두께로 잘라 절편을 만들어서 크레실 바이올렛 용액(cresyl violet)으로 염색 하여 확인한다. G. 통계학적 분석
1. 다중회귀분석(Multiple linear regression)
신경활성도(neural activity)가 쥐의 행동 정보(behaviour factor)에 의해 어떻게 조절되는지 분석하기 위해 다중회귀분석을 사용하였다.
6
-S(t) = a0 + a1·C(t) + a2·R(t) + a3·X(t) + a4·C(t-1) + a5·R(t-1) +
a6·X(t-1) + a7·C(t-2) + a8·R(t-2) + a9·X(t-2) + ε(t)
(Model 1)
S(t)는 신경세포 발화율(spike discharge rate)을 나타내며, a0~a9는 회귀계수
(regression coefficients)를 의미한다. 또한 C(t), R(t), X(t)는 각각 현재의 선택 (choice)과 그에 따른 보상(reward), 그리고 상호작용(interaction, C(t)×R(t))을 뜻 하며 t는 시행(trial)을 말한다. 또한 ε(t)는 오류항(error term)을 의미한다.
가치에 대한 정보를 계산하기 위해 또 다른 식을 사용하였다.
S(t) = S(t) = a0 + a1·C(t) + a2·R(t) + a3·X(t) + a4·ΔQ(t) +
a5·Qc(t)+ A(t) + ε(t) (Model 2)
ΔQ(t)는 QL - QR을 의미하며 QL과 QR은 왼쪽이나 오른쪽 선택에 대한 가
치(action value)다. ΔQ(t)는 결정에 대한 가치(decision value)이고, Qc(t)는 선택 했을 때 받을 수 있는 가치(chosen value)를 말한다. 그리고 A(t)는 auto regression term(A(t) = a6S(t-1) + a7S(t-2) + a8S(t-3))이다. 이것은 식2(Model
2)에서 C와 R과 X를 계산하는 과정 중에 발생한 중복된 부분(correlation)을 제 거하여 보정하는 역할을 한다.
2. 강화학습 모델(stack probability model)
본 실험의 행동결과를 분석하기 위해 행동모델을 사용하여 설명하고자 하 였다. Dual-assignment with hold task를 통해 학습된 쥐의 행동이 강화학습 모 델(Reinforcement learning model)을 잘 구현했는지 확인하고자 stack probability model을 사용하였다. 이 모델은 다음과 같은 식으로 설명할 수 있다.
-쥐가 이전과 같은 방향으로 간다면, Q(t+1) = (1-α)·Q(t) + α/X(t)·r(t) (Model 3) 쥐가 다른 방향으로 갔다면, Q(t+1) = Q(t) (Model 4) 으로 수식화할 수 있다. Q(t)는 행동에 대한 기대가치를 말하며, α는 쥐의 학습율(learning rate)이다. 그리고 X(t)는 선택하지 않은 곳에 생기게 되는 가치, r(t)는 현재 받을 수 있는 보상을 의미한다. 그리고 X(t)도 역시 수식으로 표현할 수 있다. 쥐가 같은 방향으로 간다면, X(t+1) = 1 (Model 5) 쥐가 다른 방향으로 간다면, X(t+1) = 1+X(t)·(1-Q(t)) (Model 6) 이상으로 수식화할 수 있다. 쥐가 같은 방향으로 가게 되면 선택한 곳의 가 치는 1로 표현되며 가지 않은 곳은 식-6(Model 6)의 수식으로 계산될 수 있다. 이 모델은 쥐가 선택한 것 뿐만 아니라 선택하지 않은 것에 대한 가치도 계산함 을 의미한다. 결론적으로 쥐가 얻을 수 있는 가치는 V(t) = Q(t)·X(t) (Model 7) 식-7(Model 7)과 같이 선택한 곳의 가치와 선택하지 않은 곳의 가치를 곱 한 값이 새로운 가치값이 되겠다.
8
-Ⅲ. 결과
A. 신경세포의 분류 및 분석
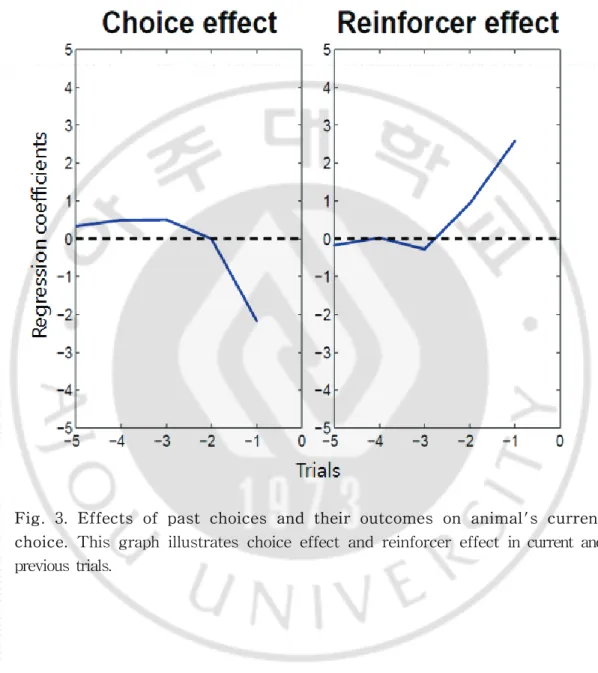
쥐 4마리로 16일 동안 실험했으며 모두 34개의 신경세포를 얻었다. 이 중 추체세포(pyramidal neuron)와 사이신경세포(inter neuron)를 구별하기 위해 각 세포의 발화율을 분석하였다. 그 결과, 발화율(firing rate) < 3Hz, 스파이크 폭 (spike width) > 0.3ms 인 경우에 해당하는 것은 추체세포로 구분하였다. 그 외 의 경우에는 모두 사이신경세포로 정하였다. 그 결과, 총 34개의 신경세포 중 추 체세포는 22개, 사이신경세포는 12개로 분류할 수 있었다. B. 행동 분석 4마리의 쥐가 행동을 할 때 선택과 보상에 대하여 얼마나 잘 행동했는지 알아보기 위해 과거 5번째의 시행부터 현재까지의 choice effect와 reinforcer effect를 분석하였다. 그림 3(Fig. 3.)을 보면, choice effect의 값이 현재 시행 (trial)으로 갈수록 (-)값을 나타냈다. 이것은 과거의 선택과 다른 방향을 선택할 확률이 높음을 알 수 있다. 또한 reinforcer effect를 보면, 현재 횟수(trial)로 갈 수록 (+)값으로 올라감을 알 수 있다. 이것은 reinforcer에 의해 쥐의 행동이 영 향을 받아 reinforcer가 있는 방향으로 갈 확률이 높다는 것을 의미한다. 두 가지 를 종합해보면, 쥐들의 행동을 분석해 볼 때 과거의 선택과 보상이 현재의 행동 에 영향을 미침을 알 수 있다.
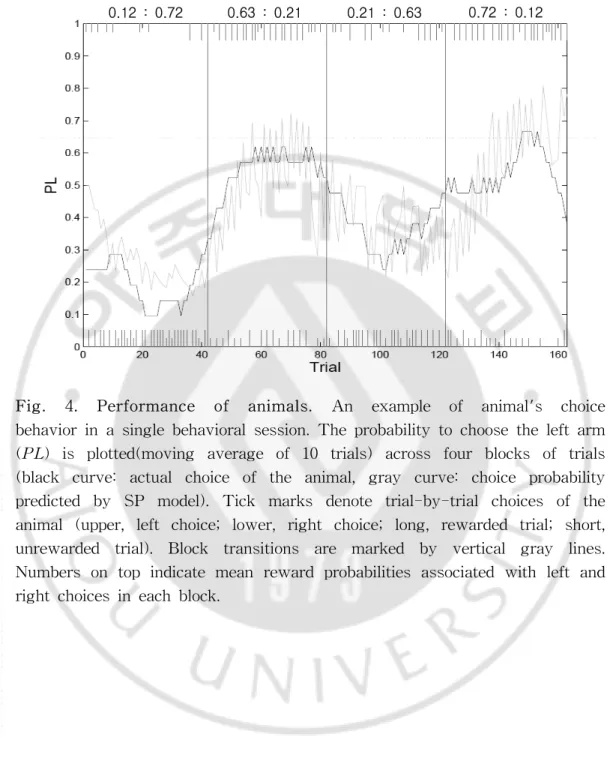
또한 그림 4(Fig. 4.)를 보면, 4가지의 블록(block)에 따라 비율(ratio)의 변화 를 주었다. 비율이 변함에 따라 실제로 쥐가 선택하는 방향이 변하게 됨을 알 수 있다. 그리고 이와 더불어 강화학습 모델(reinforcement learning model)에 의해 예측되어진 선택의 비율(choice probability)도 실제의 선택과 비슷한 양상으로 변하게 됨을 보여준다. 곧 강화학습 모델대로 쥐가 실제 행동했음을 말할 수 있 다.
8 9
-Fig. 3. Effects of past choices and their outcomes on animal's current choice. This graph illustrates choice effect and reinforcer effect in current and previous trials.
10
-Fig. 4. Performance of animals. An example of animal's choice behavior in a single behavioral session. The probability to choose the left arm (PL) is plotted(moving average of 10 trials) across four blocks of trials (black curve: actual choice of the animal, gray curve: choice probability predicted by SP model). Tick marks denote trial-by-trial choices of the animal (upper, left choice; lower, right choice; long, rewarded trial; short, unrewarded trial). Block transitions are marked by vertical gray lines. Numbers on top indicate mean reward probabilities associated with left and right choices in each block.
11
C. 선택(choice)과 보상(reward)에 대한 신경신호
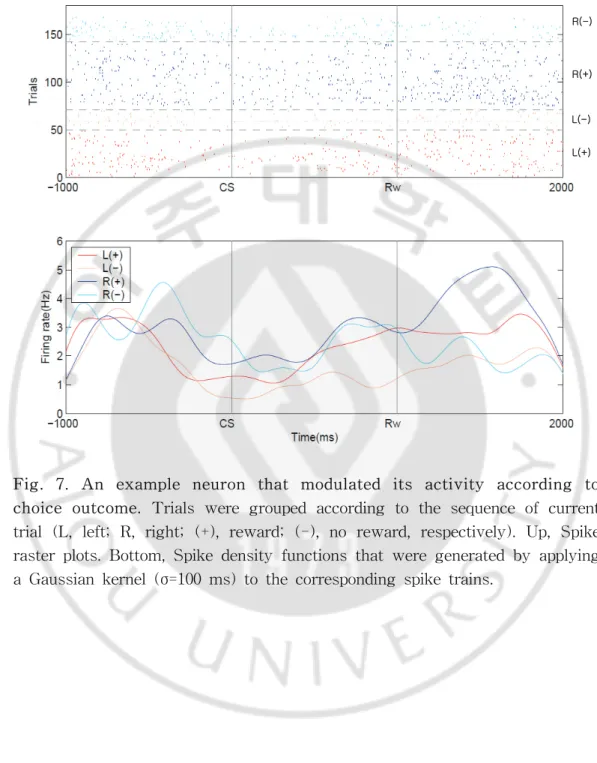
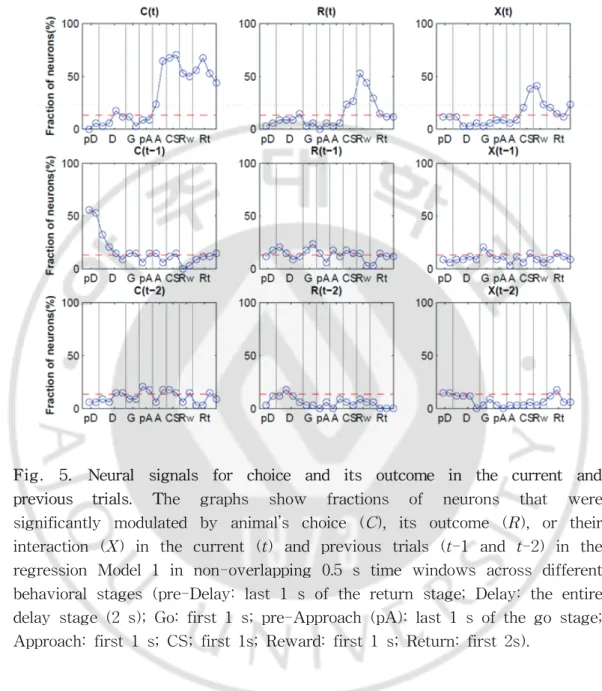
그림1(Fig. 1.)을 보면, 쥐의 행동양상을 7단계로 구분했다. D(delay)는 지 연시간이 주어지는 구간을 말하며, G(go)는 지연시간 후 움직이는 구간, A(approach)는 선택하는 구간, CS(conditional stimulus)는 소리신호가 주어지는 구간, Rw(reward)는 보상을 받는 구간, Rt(return)은 다시 되돌아가는 구간을 말 한다. 각 구간에서 신경활성도가 쥐의 행동에 따라 어떻게 달라지는지 알기 위해 위의 식-1(Model. 1.)을 사용하여 다중회귀분석을 하였다. 그림 5(Fig. 5.)를 보면, 현재의 선택(C(t))을 고려할 때 A구간에서 급격하게 증가하여 CS구간에서 최고 값을 나타냄을 알 수 있다. 또한 현재의 보상(R(t))에 대한 값을 보면, 보상이 나 오는 구간(Rw)에서 가장 높은 값을 나타냄을 알 수 있다. 이것을 더 자세히 보기 위하여 CS가 나오기 전 1초부터 보상이 나온 후 1 초까지의 시간을 따로 분리하여 신경신호를 분석하였다.(Fig. 6.) CS구간을 지나 면서 각 행동에 따라 반응하는 세포의 수의 백분율을 나타낸 Fraction of Neurons(FON)이 증가하게 되고 Rw 구간에서 최고조를 이루는 것을 다시 한 번 확인할 수 있다. 또한 쥐가 선택한 이후 보상을 얻은 경우와 얻지 못한 경우를 비교하여 어 떻게 신경신호들이 다르게 반응하는지 알기 위해 보상을 얻은 것과 얻지 않은 것을 구분하여 분석하였다.(Fig. 7.) 하나의 신경신호를 따로 분석하여 더 자세하 게 보면, CS 구간 1초 전부터 보면, 4개의 신호가 거의 비슷하게 나타나는 것을 볼 수 있다. 하지만 CS 구간에 가까이 갈수록 선택하는 방향에 따라 신경신호들 이 나뉘는 것을 볼 수 있다. 오른쪽과 왼쪽의 선택에 따라 나눠진 신호는 Rw구 간에서는 보상을 받은 것과 받지 않은 것으로 다시 나뉜다. 오른쪽을 선택한 것 을 보면, Rw 구간에서 보상을 받았을 때 증가하는 양상을 보이지만 보상을 받지 않았을 때는 감소하는 것을 확인하였다. 또한 왼쪽을 선택한 경우에도 보상을 받 지 않았을 때보다 보상을 받았을 때 더 크게 신경신호들이 증가함을 알 수 있다. 이것을 종합하여 보면, 복측해마의 신경세포들이 보상과 관련됨을 알 수 있다.
12
-Fig. 5. Neural signals for choice and its outcome in the current and previous trials. The graphs show fractions of neurons that were significantly modulated by animal’s choice (C), its outcome (R), or their interaction (X) in the current (t) and previous trials (t-1 and t-2) in the regression Model 1 in non-overlapping 0.5 s time windows across different behavioral stages (pre-Delay: last 1 s of the return stage; Delay: the entire delay stage (2 s); Go: first 1 s; pre-Approach (pA): last 1 s of the go stage; Approach: first 1 s; CS; first 1s; Reward: first 1 s; Return: first 2s).
-Fig. 6. Neural signals for choice outcome. The fraction of neurons that significantly modulated their activity according to the current choice outcome [Rw(t)] is plotted at a higher temporal resolution (500 ms moving window advanced in steps of 100 ms).
14
-Fig. 7. An example neuron that modulated its activity according to choice outcome. Trials were grouped according to the sequence of current trial (L, left; R, right; (+), reward; (-), no reward, respectively). Up, Spike raster plots. Bottom, Spike density functions that were generated by applying a Gaussian kernel (σ=100 ms) to the corresponding spike trains.
15
-R(-)
R(+)
L(-) L(+)
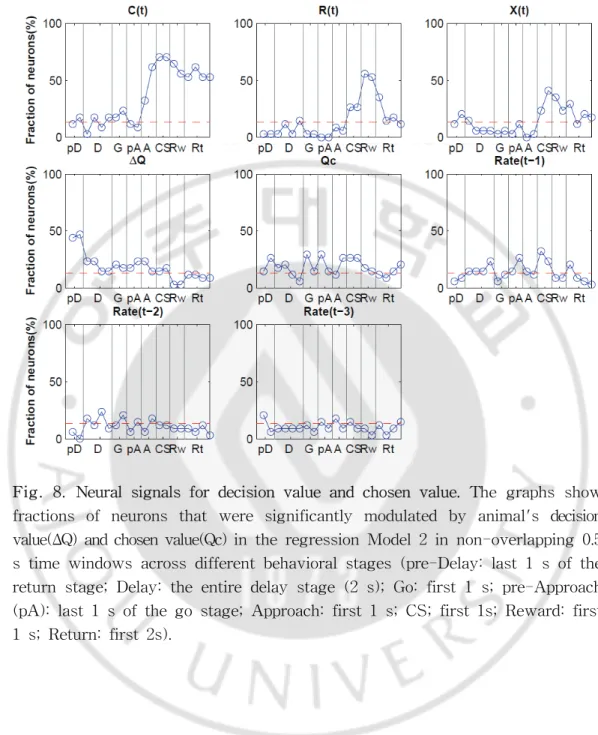
D. 가치(value)에 대한 신경활성도 현재의 선택(C(t))과 보상(R(t)) 그리고 이 둘 간의 상호관계(X(t))와 더불어 가치가 얼마나 표상되는지 알아보기 위해 행동에 대한 가치(action value)의 차 (ΔQ)와 선택한 것의 가치(Qc)를 식-2(Model 2)를 사용하여 다중회귀분석을 통해 분석하였다.(Fig. 8.) 선택에 의한 보상의 가치를 나타내는 Qc를 보면, A(approach)구간에서 증가한 것이 CS구간까지 계속 유지됨을 알 수 있다. 그러 나 Rw구간에서는 Qc를 인코딩(encoding)하는 신경세포들의 수가 감소함을 볼 수 있다. 이것을 더 자세히 보기 위해 CS 구간 1초 전부터 Rw가 나온 후 1초까지의 시간을 따로 분리하여 분석하였다.(Fig. 9.) 그림 9를 보면 그림 8과 유사한 결과 를 확인할 수 있다. CS구간에서 증가한 Qc의 FON(Fraction of Neurons)은 Rw 구간에 이르러 점점 줄어드는 것을 볼 수 있다. 곧 복측해마의 신경세포가 CS가 나오기 전부터 이미 가치에 대한 결과를 가지고 선택을 하는 것을 의미한다. 또 한 Rw 구간에서 Qc가 줄어드는 것은 이미 보상을 받은 후이기 때문에 더 이상 가치를 예측하는 신호가 의미가 없어서 줄어드는 것을 확인할 수 있다.
또한 표 1(table. 1.)에서 모든 세포(all neurons)를 보면, 34개의 신경세포의
Qc를 계산했을 때 CS 1초의 구간에서 Qc가 나타난 신경세포가 9개 (26%)(p_value<0.05)로 나타났다. 이는 유의한 결과다. 스파이크(spike)가 100개 이상인 신경세포만 구별하여 결과를 도출하였을 때도 역시 마찬가지로 8개(29%, p-value<0.05)로 나타났으며 이 값 역시 유의하다. 이와 같이 Rw 1초 구간도 동 일한 방법으로 분석했을 때, Rw 1초의 경우에는 CS 1초보다는 값이 감소함을 알 수 있다. 모든 세포의 경우와 마찬가지로 추체세포도 Qc와 ΔQ를 분석했다. 여기서도 Qc가 CS구간에서는 5개(22%, p-value<0.05)로 유의하며, Rw구간에서 는 2개(9%, p-value>0.05)개로 유의하지 않은 결과가 나타났다. 신경활성도가 100개 이상인 경우를 분석했는데 모든 신경세포를 분석한 결과와 유사하게 나타 났다. 이를 토대로 봤을 때, 복측해마의 신경세포들은 CS가 나오기 전부터 Qc를 인코딩하는 신경세포 수가 증가하기 시작하여 CS 구간까지 이어지고 Rw 구간에
16
-서 감소함을 확인하였다. 곧 복측해마가 보상을 받기 전에 보상을 얼마나 얻을지 가치에 대하여 미리 예측하는 신호가 있음을 확인하였다.
-Fig. 8. Neural signals for decision value and chosen value. The graphs show fractions of neurons that were significantly modulated by animal's decision value(ΔQ) and chosen value(Qc) in the regression Model 2 in non-overlapping 0.5 s time windows across different behavioral stages (pre-Delay: last 1 s of the return stage; Delay: the entire delay stage (2 s); Go: first 1 s; pre-Approach (pA): last 1 s of the go stage; Approach: first 1 s; CS; first 1s; Reward: first 1 s; Return: first 2s).
18
-Fig. 9. High resolution plot for chosen value signals. The fraction of neurons that significantly modulated their activity according to the chosen value is plotted at a higher temporal resolution (500 ms moving window adv anced in steps of 100 ms).
-T able. 1. Numbers of chosen value(Qc) and decision value(ΔQ) encoding neurons.
20
-Ⅳ. 고찰
기존의 연구는 배측해마에 집중되어 있고, 더군다나 보상이나 강화학습에 관하여는 더욱 그러하다. 배측해마와 복측해마가 다른 역할을 한다는 사실은 알 려졌는데 보상에 관하여 어떻게 다르게 반응하는지 알아보았다. 쥐의 행동실험 결과를 보면, 그림 3(Fig 3.)를 통해 쥐가 보상에 의해 움직 임을 알 수 있다. (t-3)의 시행까지는 choice effect와 reinforcer effect는 별다른 변화를 보이지 않는다. 그러다가 (t-2)부터 값은 변하게 되었다. 이것은 쥐의 행 동에 보상이 관여하며 과거의 선택과 보상이 현재의 행동에 영향을 줌을 확인할 수 있다. 또한 그림 4(Fig. 4.)를 통해 강화학습이론(Reinforcement learning theory)으로 쥐의 행동을 설명할 수 있는데 과거에 먹은 보상에 따라 현재의 선 택이 영향을 받음을 말한다. 실제 쥐가 얻을 수 있는 가치와 보상을 얻기 전에 나타나는 기대치의 값이 비슷한 것으로 나온다는 것은 쥐가 강화학습이론을 잘 따른다는 것을 의미한다. 이것은 그림 5(Fig. 5.)을 보면 더 분명히 알 수 있다. 현재 실시된 시행의 CS와 Rw 구간에서 가장 많은 신경세포가 반응하는 결과를 통해 보상에 대하여 복측해마가 관여하고 있음을 알 수 있다. 특히 보상과 관련하여 보상에 대한 기 대치를 분석했다. CS구간에서는 Qc(chosen value)가 유의하게 나타나지만 Rw구 간에서는 CS구간에 비해 현저히 낮게 나타남을 알 수 있다. 이러한 결과는 모든 세포 뿐만 아니라 추체세포에서 더욱 뚜렷이 나타나고 있다. 이것은 CS구간에서 이후에 나올 보상에 대하여 복측해마에서 가치를 표상함을 의미한다. 이렇게 표 상된 가치값으로 앞으로 나올 보상에 대하여 예측을 한다. 그리고 Rw에서는 이 미 선택을 한 이후에 얻어지는 결과값이기 때문에 보상에 대한 가치의 의미가 감소한다. 결국 CS구간보다는 Qc가 낮게 나타났다. 이러한 결과를 통해 복측해 마의 신경세포들이 보상과 관여하고 있으며 그와 더불어 보상에 대한 가치도 함 께 조절함을 알 수 있다. 21-Ⅴ. 결론
쥐의 행동 분석 결과 쥐는 강화학습 이론에 충실한 행동을 보여주었다. 이 것은 보상에 대하여 반응함을 의미한다. 또한 현재 시행에서 CS 구간과 Rw 구 간에서 신경세포들의 신경활성도가 급격하게 증가하는 것을 통해 복측해마의 신 경세포들이 보상과 연관되었음을 의미하여 이것은 CS구간에서 이미 표상함을 알 수 있다. 곧 복측해마의 신경세포는 가치에 대한 신호(value signal)를 가지고 있 다고 사료된다.22
-참고문헌
1. Ainge JA, Tamosiunaite M, Woergoetter F, and Dudchenko PA. :
Hippocampal CA1 place cells encode intended destination on a maze with multiple choice points. J Neurosci 27 : 9769-9449, 2007
2. Hölscher C, Jacob W, Mallot HA. : Reward modulates neuronal activity in the hippocampus of the rat. Beh Brain Research 142 : 181-191, 2003
3. Huh NJ, Jo SH, Kim HS : Model-based reinforment learning under concurrent schedules of reinforcement in rodents. Learn. Mem 16 : 315-323, 2009
4. Jung MW, Wiener SI, McNaughton BL. : Comparison of spatial firing characteristics of units in dorsal and ventral hippocampus of the rat. J Neurosci 14 : 7347-7356, 1994
5. Kim HS, Sul JH, Huh NJ, Lee DY and Jung MW : Role of striatum in updating values of chosen actions. J Neurosci 25 : 14701-14712, 2009
6. Kim SM, Frank LM. : Hippocampal Lesions Impair Rapid Learning of a Continuous Spatial Alternation Task. PLoS One 4 : e5494, 2009
7. Levita L, Muzzio IA. : Role of the hippocampus in goal-oriented tasks requiring retrieval of spatial versus non-spatial information. Neurobiol of learn and mem 93 : 581-588, 2010
8. Matthijs A.A. Meer vd, Johnson A, Schmitzer-Torbert NC, and Redish AD : Triple Dissociation of Information Processing in Dorsal Striatum, Ventral Striatum, and Hippocampus on a Learned Spatial Decision Task. Neuron 67 : 25-32, 2010
-9. Maurer AP, Cowen SL, Burke SN, Barnes CA, McNaughton BL. : Phase precession in hippocampal interneurons showing strong functional coupling to individual pyramidal cells. J Neurosci 26 : 13485-13492, 2006
10. O'Keefe J, Conway DH. : Hippocampal place units in the freely moving rat: why they fire where they fire. Exp Brain Res 14 : 573-590, 1978 11. Sebastien R, Anton S, Jagdish P, Gyorgy B : Distinct representations and theta dynamics in dorsal and ventral hippocampus. J Neurosci 30 :
1777-1787, 2010
12. Sul JH, Kim HS, Huh NJ, Lee DY and Jung MW : Distint Roles of rodent orbitofrontal and medial prefrontal cortex in decision making. Neuron 66 : 449-460, 2010
13. Sylvia W, Emin A, Cindy CC, Varun S, Anne CS, Emery B, Wendy AS : Trial outcome and associative learning signals in the monkey hippocampus. Neuron 61 : 930-940, 2009
14. Tabuchi E, Mulder A.B, and Wiener S.I. : Reward Value Invariant Place Responses and Reward Site Associated Activity in Hippocampal Neurons of Behaving Rats. Hippocampus 13 : 117-132, 2003
24
ABSTRACT
-Reward-related Neural Activity in Ventral Hippocampus
Sung Hyun Lee
Department of Biomedical Sciences The Graduate School, Ajou University
(Supervised by Professor Min Whan Jung)
Hippocampus is well-known for its relation to memory and learning. Hippocampus anatomically consists of cornu ammonis and dentate gyrus; cornu ammonis consists of four parts. Among these parts, the most studied part is CA1. Hippocampus also can be divided into dorsal hippocampus and ventral hippocampus as they play different roles. Although the study on the relationship between hippocampus and reward has recently gained a considerable amount of attention, the relationship is still not clear. Thus, in this study, neural signals of hippocampus related to reward were analyzed, particularly focusing on ventral hippocampus.
Behavioral task of this study was the dual-assignment with hold task. Behavioral analysis indicated that the animal's choice behavior is well accounted by the reinforcement learning theory. Moreover, when neural signals were examined, reward-related neural signals were the strongest during the Conditional Stimulus period(CS), during which choice outcome was revealed by auditory signal, and Reward period(Rw), during which water
-reward was delivered, in current trial. These results indicate that ventral hippocampus processes reward-related information.
We also examined whether ventral hippocampal neurons encode value-related information. Strong chosen value signals were found in the CS period, but not in the Rw period. This is probably because the value of chosen goal is processed as soon as choice outcome is revealed during the CS period. To conclude, neurons of ventral hippocampus encode neural signal for reward as well as value.




![Fig. 6. Neural signals for choice outcome. The fraction of neurons that significantly modulated their activity according to the current choice outcome [Rw(t)] is plotted at a higher temporal resolution (500 ms moving wind](https://thumb-ap.123doks.com/thumbv2/123dokinfo/4689173.3687/24.808.104.713.110.881/fraction-significantly-modulated-activity-according-plotted-temporal-resolution.webp)