2016년 12월
듀얼모드 배치·쿼리분석을 제공하는
빅데이터 플랫폼 핵심 기술 개발
Development of Big Data Platform
for Dual Mode Batch·Query Analytics
16ZS1400-01-1111P
듀
얼
모
드
배
치
·
쿼
리
분
석
을
제
공
하
는
빅
데
이
터
플
랫
폼
핵
심
기
술
개
발
한국전자통신연구원
2 0 1 6 · 12 ·2016년 12월
듀얼모드 배치·쿼리분석을 제공하는
빅데이터 플랫폼 핵심 기술 개발
Development of Big Data Platform
for Dual Mode Batch·Query Analytics
16ZS1400-01-1111P
듀
얼
모
드
배
치
·
쿼
리
분
석
을
제
공
하
는
빅
데
이
터
플
랫
폼
핵
심
기
술
개
발
한국전자통신연구원
2 0 1 6 · 12 ·인 사 말 씀
디지털 정보량이 기하급수적으로 증가함에 따라, 데이터를 넓은 영역에서
활용하려는 시도들이 발생하고 있으며, 수많은 데이터를 어떻게
활용하는지의 여부, 즉 방대한 데이터를 통한 새로운 가치 창출이 기업뿐
아니라 국가의 경쟁력 강화와 직결되는 시대로 접어들고 있습니다. 그러나
활용이 가능할 정도로 충분한 데이터의 수집 자체의 문제뿐 아니라 이를
쉽고 빠르게 다룰 수 있는 기술 자체가 충분히 발전하지 못하는 어려움으로,
가치 창출을 위한 빅데이터의 활성화가 저하되는 문제가 발생하고 있습니다.
“듀얼모드 배치∙쿼리 분석을 제공하는 빅데이터 플랫폼 핵심 기술 개발”
사업은 빅데이터 2.0 시대를 위한 한계점 대비 극복 요구 기술 개발의
일환으로, 페타바이트급 이상 정형/비정형 빅데이터 데이터 웨어하우스
운영시스템에서 질의 기반의 인터랙티브 분석과 배치 기반의 심층 분석을
동시에 지원하는 빅데이터 분석 소프트웨어 핵심기술 개발을 목표로,
맵리듀스 내장형 분산 질의 엔진, 배치/온라인 듀얼모드 분산 데이터 처리
기술 및 운영/분석 통합 파일시스템을 개발하였습니다.
본 사업을 통하여 빅데이터 분야의 고위험/고수익형 미래 기술을 확보하고,
글로벌 수준의 빅데이터 플랫폼 기술 확보를 통한 글로벌 빅데이터 시장
진출의 교두보를 확보할 수 있을 것으로 기대하고 있으며, 본 연구 결과가
ETRI SW∙콘텐츠 연구소의 빅데이터 및 관련 기술 확보와 대한민국 SW 산업
발전에 초석이 되기를 기대하며, 참여 연구원들께 감사의 마음을 전합니다.
2016년 12월
제 출 문
본 연구 보고서는 주요 사업인 "듀얼모드 배치·쿼리분석을 제공하는
빅데이터 플랫폼 핵심 기술 개발"의 결과로서, 본 과제에 참여한 아래의
연구팀이 작성한 것입니다.
2016 년 12 월
연구책임자 : 책임연구원 원종호 (데이터플랫폼연구실)
연구참여자 : 책임연구원 박경 (빅데이터인텔리전스연구부)
책임연구원 김성수 (데이터플랫폼연구실)
선임연구원 정문영 (데이터플랫폼연구실)
선임연구원 송혜원 (데이터플랫폼연구실)
선임연구원 이태휘 (데이터플랫폼연구실)
책임연구원 허성진 (데이터플랫폼연구실)
책임연구원 남택용 (데이터플랫폼연구실)
책임연구원 이미영 (데이터플랫폼연구실)
책임연구원 김창수 (데이터플랫폼연구실)
책임연구원 이훈순 (데이터플랫폼연구실)
책임연구원 이명철 (데이터플랫폼연구실)
책임연구원 김영균 (고성능컴퓨팅연구부)
책임연구원 이상민 (스토리지시스템연구실)
책임연구원 김홍연 (스토리지시스템연구실)
책임연구원 진기성 (스토리지시스템연구실)
책임연구원 김영철 (스토리지시스템연구실)
책임연구원 김재열 (스토리지시스템연구실)
책임연구원 박정숙 (스토리지시스템연구실)
책임연구원 차명훈 (스토리지시스템연구실)
선임연구원 이상민 (스토리지시스템연구실)
연구원 박준영 (스토리지시스템연구실)
요 약 문
Ⅰ. 제 목
듀얼모드 배치·쿼리 분석을 제공하는 빅데이터 플랫폼 핵심 기술 개발 (2014.1.1 ~ 2016.12.31)Ⅱ. 연구목적 및 중요성
¡
오픈 소스 소프트웨어 프레임워크인 아파치 하둡은 빅데이터에 대한 디지털 비즈니스 욕구가 커짐에 따라, 기업 조직 내에서 큰 지지를 얻고 있음¡
빅데이터1.0에서는 기업 내 프로젝트들이 급증함에 따라, 지속적이고 빠르게 확장되는 하둡 시스템의 기능들을 조직의 의사결정에 필요한 분석 요구사항에 매핑하는 것은 데이터 과학자 및 분석 리더에게는 복잡한 작업임¡
이러한 일괄처리 중심인 맵리듀스 기반 빅데이터1.0의 주요한 단점을 해결하기 위해, 스파크 SQL, 스파크 ML 등과 같은 인메모리 데이터처리를 기반으로 하고 있는 아파치 스파크 프로젝트가 진행되고 있음¡
빅데이터2.0 실현을 위해서는 두 가지 주요한 연구 도전과제가 있음 - (분석처리기술) 배치형과 인터랙티브형으로 양분된 분석 기술을 기능적으로 결합한 빅데이터 분석 소프트웨어 플랫폼 개발 - (저장관리기술) 운영계/분석계의 스토리지를 통합 운영/분석 가능한 유니파이드 빅데이터 스토리지 시스템 소프트웨어 기술 개발¡
본 사업에서는 세계 최고 수준의 질의 분석 성능(세계 최고 대비), MR 분석 성능(하이브 대비), 파일처리 성능(HDFS)과의 비교를 통해 개발 기술의 우수성이 객관적으로 입증될 수 있도록 성과 목표를 도출함Ⅲ. 연구내용 및 범위
¡
(연구목표) 페타바이트급 이상 정형/비정형 빅데이터 통합 분석을 위해 부하인지형 유니파이드 빅데이터 분산 파일 시스템을 기반으로 인터랙티브 분석과 MR 기반 심층 분석을 동시에 지원하는 분산 쿼리 엔진 개발¡
애드혹(Ad-hoc) 질의와 맵리듀스 기반 심층 분석 질의를 제공하는 MR 내장형 분산 질의 엔진 기술 개발¡
DAG(Directed Acyclic Graph) 기반 동적 데이터 처리 및 데이터 공유를 제공하는배치/온라인 듀얼모드 분산 데이터 처리 기술 개발 ¡ 파이프라인 데이터 공유를 제공하는 운영계/분석계 통합 유니파이드 빅데이터 분산 파일 시스템 기술 개발 ¡ 연차별 연구개발 범위
l
1차년도: 운영/분석계 스토리지 공유 및 듀얼모드 분석 엔진 설계l
2차년도: 워크로드 인지형 스토리지 및 듀얼모드 분석 엔진 핵심 기술 개발l
3차년도: 유니파이드 분산 파일 시스템 및 듀얼모드 분석 엔진 통합 기술 개발Ⅳ. 연구목표 달성도
(달성 요인) 질의처리 최적화를 통한 데이터 처리 성능 개선 ¡ MR 분석 성능: Hive 대비 31배(103% 목표 달성) (달성 요인) 개선된 분산 실행(DAG기반 실행엔진)을 통한 배치처리 성능 향상 ¡ 파일 데이터 처리 성능: 21,000 creates/sec(105% 목표 달성) (달성 요인) 저수준 메타데이터 입출력 프로토콜 및 고속 캐시 기술을 통한 파일 데이터 처리 성능 향상 ¡ 데이터 입출력 간섭률: 10%(100% 목표 달성) (달성 요인) 워크로드 인지형 입출력 제어 및 제로카피 기술을 통한 간섭률 최소화 ¡ 특허 출원 (국내/국제): 15건(10건/5건)[출원중(2건/2건) 포함](125% 목표 달성) ¡ 논문 (비SCI/SCI): 30건 (27건/3건)(500% 목표 달성)
연구개발결과의 우수성
¡ (통합분석 원천기술 경쟁력 확보) 글로벌 벤더 중심으로 형성되는 데이터 웨어하우스 시장에 대응하여, 배치처리와 온라인처리를 통합 지원하는 SQL 온 하둡 시스템의 독창적인 연구 결과 도출을 통한 기술 경쟁력 확보 ¡ (표준 SQL 지원/처리속도 개선) 하둡과의 연동을 보다 빠른 성능을 내면서도 ANSI-SQL을 그대로 이용할 수 있는 DAG기반 질의처리 엔진 제공 [세계최고 대비 1.3 배 처리속도 개선] ¡ (맵리듀스기반 배치 처리속도 개선) 워크로드기반 데이터 파티셔닝 및 컬럼셋을 적용하여, 대용량 빅데이터의 통계분석을 위한 빠른 맵리듀스기반 배치 처리 성능을제공 [하이브 대비 31 배 처리속도 개선] ¡ (유니파이드 빅데이터 파일 시스템 플랫폼 원천기술 확보) 운영계와 분석계에서 생산되는 데이터의 통합 관리와 분석을 지원하기 위한 유니파이드 빅데이터 파일 시스템 플랫폼 핵심 원천기술 확보 [파일 메타데이터 처리 성능: 21,000 creates/sec 달성] ¡ (운영/분석 통합형 입출력 간섭 제어 핵심 기술) 운영계/분석계 데이터 접근 우선권, 데이터 접근 일관성, 상호간의 성능 간섭에 대한 효율적인 제어 기술 등 빅데이터 스토리지의 핵심 도전 기술 확보 [데이터 입출력 간섭률: 10% 달성]
Ⅴ. 활용계획 및 파급효과
¡ 듀얼모드 빅데이터 분석 플랫폼을 신용카드사 감성 분석, 기업 평판 관리 시스템 등에 활용해 나감으로써, 빅데이터 데이터 웨어하우스 플랫폼 국내시장 창출 ¡ 또한, 보건/복지/의료 분야등과 같은, 공공 정부의 데이터 공유 및 활용 분야에 적용을 통해 성과 확산 ¡ 기계학습, 배치분석등과 같은 빅데이터 분석 응용시스템의 하부 빅데이터 운영 및 분석용 파일 시스템으로 활용 ¡ 국내 분산 파일시스템 사업화 또는 서비스 구축 경험이 있는 업체를 대상으로 유니파이드 빅데이터 파일시스템 기술을 조기 확산 유도 ¡ 빅데이터 운영/분석/응용계의 일원화를 통해, 빅데이터 플랫폼에 대한 기존 투자비 대비 40% 이상 절감 효과 예상ABSTRACT
Ⅰ. TITLE
Development of Big Data Platform for Dual Mode Batch · Query Analytics (2014.1.1 ~ 2016.12.31)
Ⅱ. THE OBJECTIVES AND IMPORTANCE
¡ The open-source software framework known as Apache Hadoop has gained sizable acceptance in organizations, spurred on by the growing digital business appetite for Big Data.
¡ In Big Data1.0 era, mapping the continuing rapid expansion of Hadoop system capabilities to the analytic needs of the organization as projects proliferate has become a complex process for data scientists and analytics leaders.
¡ In order to overcome the major limitations of the MapReduce-based Big Data1.0, several projects, such as Spark, have developed several components (Spark SQL, Spark ML and others) which are based on in-memory data processing technology. ¡ To realize the Big Data2.0 era, there are two key research challenges:
- (Analytic Processing Technology) Development of the Big Data Analytic Platform, which can support interactive analytics as well as batch analytics. - (Storage Management Technology) Development of the Unified Big Data Storage System, which can support the integrated operational/analytical storage in terms of operational and analytical use cases.
¡
In this project, we setup the key performance indicators as follows:- The performance of world-class query processing (compared to the best in the world)
- The performance of the MR-based analytical processing (compared to the Hive) - The performance of file processing (compared to the HDFS)
Ⅲ. SCOPE OF THE STUDY
¡ Research GoalDevelopment of a workload-aware unified Big Data distributed file system and a distributed query engine which supports interactive analytics as well as MR-based deep analytics for petabyte-scale structured/unstructured analytics ¡ Development of MR-embedded distributed query processing engine technology, which
supports ad-hoc queries and MapReduce-based queries for deep analytics
¡ Development of DAG (Directed Acyclic Graph)-based batch/online dual-mode distributed data processing technology which supports dynamic data processing and data sharing
¡ Development of unified Big Data distributed file system technology which supports pipelined data sharing in integrated operational and analytical systems
¡ R&D scope by year
l 1st year: Design of operational/analytic storage sharing technology and
dual-mode analytics engine
l 3rd year: Development of the technology for integrating the unified Big Data
distributed file system with the dual-mode analytics engine
Ⅳ. RESULTS
¡ Performance of query processing (TPC-H): 1.3X over the best in the world
(Key Factors) Performance improvement of data processing throughout the query optimization
¡ Performance of MR-based analytics: 31X over the HIVE
(Key Factors) Performance improvement for batch processing using the improved distributed execution in the DAG-based execution engine
¡ Performance of file data processing: 21,000 creates/sec
(Key Factors) Performance improvement for file data processing using the low-level metadata I/O protocol and high-speed caching technology
¡ Data I/O interference rate: 10%
(Key Factors) Minimization of the data interference ratio throughout the workload-aware I/O controller and zero-copy technology
¡ Patents (Domestic/International): 15 (8/3, 2/2[in progress]) ¡ Papers (Non-SCI/SCI): 30 (27/3)
Ⅴ. PRACTICES AND RIPPLE EFFECTS
¡ Creating a new domestic market for Big Data DW platform by exploiting the dual-mode Big Data analytic platform to various analytic purposes, such as, sentimental analysis and reputation management in credit card companies
¡ Propagating research results through applying to public data sharing and utilization fields in the government, such as, health, welfare, and medical fields in Korea
¡ Utilizing as a file system for operational and analytical use cases in Big Data analytics applications, such as, machine learning, batch-analytics and so on ¡ Leading to the early spread of the unified Big Data file system technology for
companies that have experience in commercializing domestic services or products ¡ Expecting to save more than 40% of the investment budgets in Big Data platform through the integration of Big Data operational, analytical and application systems
목 차
제 1 장 서 론 ... 1
제 1 절 연구 목표 및 연구 범위 ... 1
1. 개요 ... 1
2. 연구 목표 ... 6
3. 연구 범위 ... 8
제 2 절 국내외 관련 기술의 현황 ... 10
1. 국내 기술동향 및 수준 ... 10
2. 국외 기술동향 및 수준 ... 11
제 2 장 주요 연구 성과 ... 14
제 1 절 연구동향 ... 14
1. SQL 온 하둡 연구동향 ... 14
2. 데이터 웨어하우스 연구동향 ... 14
3. 파일 시스템 연구 동향 ... 15
제 2 절 연차별 연구 내용 ... 16
1. 1 차년도(2014 년) ... 16
2. 2 차년도(2015 년) ... 16
3. 3 차년도(2016 년) ... 17
제 3 절 연구 추진 체계 및 실적 ... 19
1. 연구 추진 체계 ... 19
2. 연구 추진 실적 ... 21
3. 정량적 달성도 ... 23
제 4 절 연구 목표 수준의 타당성 ... 25
1. 성과 목표 개요 ... 25
2. 설정근거 ... 25
제 3 장 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 기술 개발 ... 26
제 1 절 연구 범위의 요약 ... 26
1. 연구 목표 ... 26
2. 연차별 연구 개발 내용 ... 28
3. 연구 결과 요약 ... 31
제 2 절 세부 추진 내용 ... 32
1. 듀얼모드 빅데이터 분석 플랫폼 요구사항 분석 및 전체 구조 설계
... 32
2. MR 내장형 분산 쿼리 엔진 설계 ... 38
3. 배치/온라인 듀얼모드 분산 데이터 처리 기술 설계 ... 44
4. DAG 기반 분산 질의 플랜/파티셔닝 기술 ... 47
5. 데이터 워크로드 인지형 질의 처리 기술 ... 51
6. MR 내장형 질의 및 질의 최적화 기술 ... 54
7. 듀얼모드 분석 프레임워크 연동 기술 ... 66
8. 의료데이터 기반 빅데이터 분석 시범서비스 개발 ... 71
9. 배치/온라인 듀얼모드 분석 플랫폼 시험 및 성능평가 ... 74
제 4 장 유니파이드 빅데이터 분산 파일 시스템 기술 개발 ... 78
제 1 절 연구 범위의 요약 ... 78
1. 연구 목표 ... 78
2. 연차별 연구 개발 내용 ... 82
3. 연구 결과 요약 ... 84
제 2 절 세부 추진 내용 ... 86
1. 유니파이드 빅데이터 파일 시스템 요구사항 분석 ... 86
2. 유니파이드 빅데이터 파일 시스템 구조 설계 ... 88
3. 분석계 특화형 스토리지 입출력 인터페이스 기술 ... 92
5. 메타데이터 처리 가속 기술 ... 111
6. 입출력 간섭 제어 기술 ... 122
7. 제로카피 입출력 가속 기술 ... 135
제 5 장 공동연구 추진실적 ... 144
제 1 절 하둡 기반의 바이오 그래프 관리 기술 개발 ... 144
1. 수행기관: 한국과학기술정보연구원(KISTI) ... 144
2. 연구 목표 ... 144
3. 연구 내용 ... 144
4. 세부 연구 내용 ... 144
제 2 절 표준 의료 빅데이터기반 의료 데이터 웨어하우스 구축 ... 152
1. 수행기관: ㈜ 누스코 ... 152
2. 연구 목표 ... 152
3. 연구 내용 ... 152
4. 세부 연구 내용 ... 152
제 6 장 연구 개발 결과의 활용계획 ... 155
제 1 절 연구 성과 우수성 ... 155
1. 성과 확산 계획 ... 156
2. 실용성 및 경쟁력 ... 157
제 2 절 성과 활용 방안 ... 158
제 3 절 파급효과 ... 161
1.
유니파이드 파일 시스템 핵심 인프라 기술로 활용 ... 161
2. 기존 하둡 플랫폼의 확장성 한계 극복에 관한 연구에 활용 ... 162
3. 엑사스케일급 유니파이드 빅데이터 파일 시스템 연구에 활용 . 163
제 4 절 기업화 추진 방향 ... 164
1. 추진 전략 ... 164
2. 추진 계획 ... 165
제 7 장 결 론 ... 167
참고문헌 ... 169
약어표 ... 170
표 목차
표 1. 국내외 기술 개발현황 ... 4
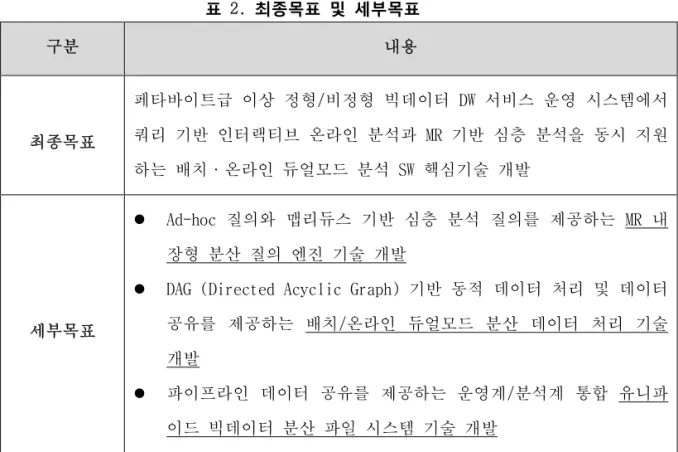
표 2. 최종목표 및 세부목표 ... 7
표 3. 국내 빅데이터 및 파일 시스템 관련 기업 및 기술현황 ... 10
표 4. 국외 빅데이터 관련 기업 및 기술 현황 ... 12
표 5. 위탁 과제 추진 실적 ... 20
표 6. 최종년도 성과지표에 대한 계획 대비 실적 ... 21
표 7. 정량 연구 실적 개요 ... 23
표 8. 배치/온라인 듀얼모드 빅데이터 분석 플랫폼의 요구사항 ... 34
표 9. 트랜스포머 지원 휴리스틱 ... 57
표 10. 빅데이터 분산 파일 시스템의 요구사항 ... 87
표 11. 분석계 인터페이스 리스트 ... 95
표 12. 분석계 인터페이스 호환성 및 성능 시험 환경 ... 97
표 13. 분석계 인터페이스 호환성 검증 결과 ... 99
표 14. 스냅샷 기능 정의 ... 102
표 15. 저수준 메타데이터 입출력 프로토콜 ... 112
표 16. 저수준 메타데이터 입출력 인터페이스 ... 118
표 17. 연구성과의 종합적 우수성 ... 155
그림 목차
그림 1. 빅데이터 분석과 활용 ... 2
그림 2. 빅데이터 분석도구 시장 규모 전망 ... 2
그림 3. 빅데이터 지향 한계점 대비 극복 요구 기술 ... 3
그림 4. 연구목표 및 연구내용 ... 6
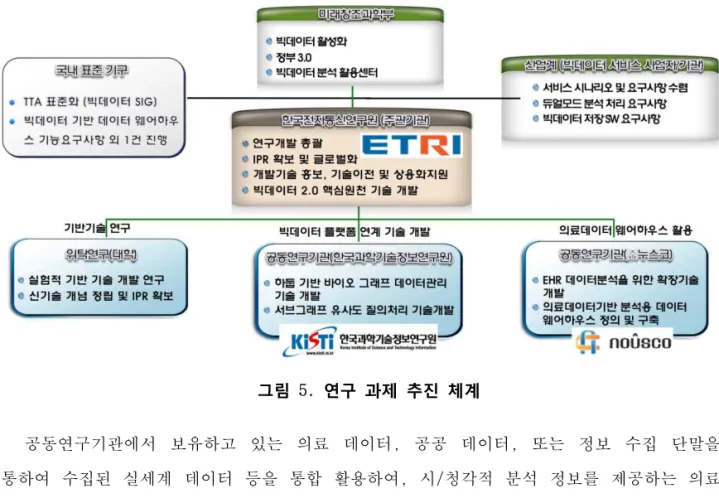
그림 5. 연구 과제 추진 체계 ... 19
그림 6. 공인 시험성적서 1 면... 24
그림 7. 배치 온라인 듀얼모드 분산 질의 엔진 기술 개념도 ... 26
그림 8. 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 기술 개발 개요
... 28
그림 9. KIWI 구조와 사용자 분류 ... 32
그림 10. 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 구조도 ... 35
그림 11. 확장연산자 생성 문법 ... 39
그림 12. 확장연산자 생성 및 실행 예 ... 40
그림 13. 질의 처리 과정 ... 40
그림 14. 논리적 질의 실행 계획 예시 ... 42
그림 15. MR 확장연산자가 통합된 질의 실행 계획 예시 ... 43
그림 16. 분산 데이터 기반 질의 처리를 위한 KIWI 분산 시스템 구조
도 ... 44
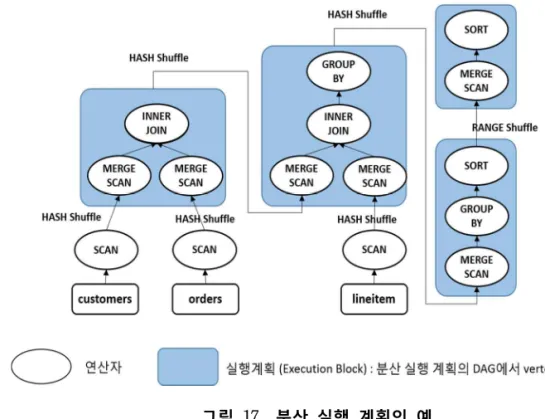
그림 17. 분산 실행 계획의 예 ... 47
그림 18. 질의 블록 스케줄링 및 파티셔닝 개념 ... 48
그림 19. 자원할당 및 실행과정 ... 49
그림 20. 워크로드 인지 및 모델링 과정 ... 51
그림 21. 질의 컬럼셋을 이용한 질의 처리 과정 ... 53
그림 23. 초기 질의 실행 계획 생성 ... 57
그림 24. 조인 그래프 구축 ... 59
그림 25. 질의 워크로드 기반 질의 가속화 블록 세부 모듈 구성 .... 61
그림 26. 질의 워크로드 분석 모듈의 컬럼셋 추출 과정 ... 63
그림 27. 질의의 워크로드 파티션 후보 ... 64
그림 28. 파티션 테이블에 대한 질의 처리 과정 ... 65
그림 29. 분석 어플리케이션 연동 블록의 구조와 질의 처리 흐름도 . 66
그림 30. 분석 어플리케이션 제플린과 KIWI 연동을 위한 인터페이스 68
그림 31. 동적 프레임워크 연동 구성 ... 69
그림 32. 의료데이터 기반 빅데이터 분석 시범 서비스 ... 71
그림 33. 질병 관계도 기반 검사수치 분석 ... 72
그림 34. 자동화 시험환경 구축 ... 74
그림 35. TPC-H 벤치마크 성능 평가 결과 ... 76
그림 36. TPC-DS Derived 벤치마크 성능 평가 결과(단위: 초) ... 77
그림 37. 유니파이드 빅데이터 분산 파일 시스템 개발 목표 ... 78
그림 38. 운영계 분석계 파이프라인 데이터 공유 개념도 ... 79
그림 39. 운영 분석을 동시 지원하는 유니파이드 스토리지 개념도 .. 83
그림 40. 유니파이드 빅데이터 파일 시스템 사용자 분류 ... 86
그림 41. 유니파이드 빅데이터 파일 시스템 구조 ... 88
그림 42. 시스템 블록 및 연차별 개발 현황 ... 89
그림 43. 분석계 인터페이스 계층 구조 ... 92
그림 44. 분석계 입출력 클래스 다이어그램 ... 94
그림 45. 분석계 인터페이스와 파일 시스템의 JNI 연동 구조 ... 96
그림 46. 분석계 인터페이스 호환성 및 성능 시험 형상 ... 97
그림 47. Jenkins 기반 분석계 인터페이스 호환성 검증 도구 ... 99
그림 48. 분석계 인터페이스 데이터 처리 성능 검증 결과 ... 100
그림 49. 시계열 볼륨을 이용한 사용자 시나리오 ... 101
그림 50. 시계열 볼륨 유니트 구조 ... 103
그림 51. 유니파이드 파일 시스템 데이터 변경 회피 기법 ... 105
그림 52. 신규 디렉토리 생성 플로우 ... 106
그림 53. 시계열 볼륨의 디렉토리 삭제 흐름 ... 107
그림 54. 데이터 변경 회피의 전체 시나리오 ... 108
그림 55. 시계열 볼륨 기반 R WordCloud 분석 시험 ... 109
그림 56. 시계열 볼륨 적용에 따른 성능 변화 측정 ... 110
그림 57. 저수준 메타데이터 처리 유니트의 구조 ... 111
그림 58. 저수준 메타데이터 프로토콜 처리 흐름 ... 114
그림 59. 메타데이터 캐시를 지원하는 프로세스 구조 ... 115
그림 60. 메타데이터 캐시 처리 구조 ... 116
그림 61. 저수준 메타데이터 처리 기술에 의한 자원 활용율 ... 119
그림 62. 메타데이터 처리 규모 비교 ... 120
그림 63. 메타데이터 처리 성능 비교 ... 121
그림 64. 운영계/분석계 입출력 간섭 현상 시뮬레이션 시험 환경 .. 123
그림 65. 서비스별 시스템 자원의 활용률 측정 결과 그래프 ... 124
그림 66. 선제적 선반입 기반 입출력 처리 개념 ... 126
그림 67. 선제적 선반입 지원 시스템 블록 구조 ... 127
그림 68. 선제적 선반입 기반 읽기 연산 과정 ... 128
그림 69. 독립적인 입출력 경로 관리 기반 시스템 구조 ... 130
그림 70. 입출력 간섭 제어에 따른 디스크 입출력 처리량 ... 132
그림 71. 운영계 분석계 입출력 간섭 테스트베드 및 시험 환경 .... 133
그림 72. 분석계 TPC-H 전체 수행 시간 ... 134
그림 73. 운영계 FileBench 입출력 응답시간(Latency) ... 135
그림 75. Layout Aware Hybrid I/O 처리 구조 ... 137
그림 76. 데이터 위치인지 기반 시스템 블록 구조 ... 138
그림 77. 데이터 위치인지 입출력 처리 구조 ... 140
그림 78. BIG-FS 통합 디스크 입출력 처리량 그래프 ... 141
그림 79. BIG-FS 통합 네트워크 처리량 그래프... 142
그림 80. 분석계의 입출력 간섭률 비교 그래프 ... 142
그림 81. 운영계의 입출력 간섭률 비교 그래프 ... 143
그림 82. 필터링 검증 프레임워크 절차 ... 145
그림 83. 성능 실험 결과 ... 147
그림 84. 경로 기반 그램 시그니쳐를 사용한 역리스트 구축 ... 148
그림 85. 맵리듀스 기반의 유사도 기반 그래프 질의 처리 병렬화 .. 149
그림 86. 다중데이터 구조 사용 개념도 ... 150
그림 87. 병원 정보 시스템 처리 흐름 ... 153
그림 88. 병원정보 시스템 구성도 ... 153
그림 89. 국제 표준 의료용어서비스 연계 구성도 ... 154
그림 90. 유니파이드 빅데이터 파일 시스템의 제품 경쟁력 ... 164
제 1 장 서 론
제 1 절 연구 목표 및 연구 범위
1. 개요
빅데이터 플랫폼은 방대한 데이터를 수집, 저장, 관리하는 데이터 플랫폼이며, 정형/비정 형/스트리밍 데이터와 같이 다양한 종류의 데이터에 대한 스토리지 관리, SQL 질의 처리를 하나의 플랫폼을 통해 수행할 수 있는 소프트웨어 아키텍처를 의미함 가. 연구배경 ¡ 2010년 100억 개에서 2020년 7조개 이상의 무선 단말로 연결된 사물인터넷(IoT) 시대에 따른 천문학적 규모 데이터 발생 ¡ 이러한 폭발적으로 증가하는 데이터로 인해, 데이터 웨어하우스 구축과 관리가 기업의 효과적인 의사 결정을 위해 중요한 문제로 대두됨 ¡ 국가적 차원에서도 자본과 노동보다는 이러한 빅데이터 플랫폼을 잘 구축하고 분석에 활용할 수 있는가에 의해 국가 경쟁력이 좌우되는 시대가 도래 ¡ 지식 기반 경제를 넘어서 대용량 지식 정보를 바탕으로 빠르게 분석하고, 예측함으로써 빅데이터의 분석을 통해 새로운 가치를 창출 ¡ 최근 들어 빅데이터 분석 및 사물인터넷(IoT)을 통해 유수 제조업 기업들이 뛰어난 통찰력(Insight)을 확보하고 있으며 이는 제조업을 보다 지능화하는데 크게 공헌하고 있는 것으로 나타남 ¡ 빅데이터 분석 도구는 가치 사슬 측면에서는 빅데이터 유형에 따른 데이터 관리, 빅데이터 분석, 빅데이터 활용을 위한 애플리케이션의 3단계 제품으로 구분할 수출처: 인공지능, 빅데이터 관련 유망산업별 국내·외 기술 개발/시장 전망 실태 분석(2016) 그림 1. 빅데이터 분석과 활용 그림 2. 빅데이터 분석도구 시장 규모 전망 ¡ 2015년에 국내 빅데이터 시장은 세계 시장 대비 1.56%인 2,770억원(1,053원/USD 기준 비교)의 미미한 수준에 머물렀으나, 2021년까지 최대 1.7%까지 상승할 것으로 예상 [출처: KISTI 마켓리포트 2016-44] ¡ 국내 빅데이터 시장은 2015년 2,770억원, 2021년에는 12,274억원에 이르기까지
연평균 26.4%의 성장률을 보이고 있고, 2번째 시장인 분석도구 시장은 2015년 691억 원, 2021년 2,003억 원에 이르기까지 연평균 17.7%의 성장률을 보이고 있는 추세 [출처: KISTI 마켓리포트 2016-44] 그림 3. 빅데이터 지향 한계점 대비 극복 요구 기술 ¡ 일괄 처리 중심인 빅데이터 1.0의 주요한 한계는 SQL과 같은 대화형 분석도구가 없었다는 점, 단순 맵리듀스(MapReduce) 분산 처리 패턴만으로 복잡한 데이터 마이닝 등의 연산 구성이 어려움이 존재했음 ¡ 또한, 빅데이터 1.0의 저장관리 측면에서도 비효율적인 운영계/분석계 스토리지 분리, 비표준 I/O 인터페이스, 단일 고장점으로 인한 고가용성 제공 기능이 취약 ¡ 이러한 단점을 극복하기 위해, 데이터 분석 시 대화형 분석을 제공할 수 있는 SQL 인터페이스/질의처리 기술, 효율적인 분산처리 기술, 운영계와 분석계를 통합하고 표준/비표준 통합 I/O를 통해 이기종 데이터 웨어하우스(DW)를 통합할 수 있는 파일 시스템 개발이 요구됨
기술 개발을 수행함 n (분석처리기술) 배치형과 인터랙티브형으로 양분된 분석 기술을 기능적으로 결합한 빅데이터 분석 소프트웨어 플랫폼 개발 n (저장관리기술) 운영계/분석계의 스토리지를 통합 운영/분석 가능한 유니파이드 빅데이터 스토리지 시스템 소프트웨어 기술 개발 ¡ 국내외 관련 기술 개발은 디스크기반 기술과 메인메모리기반 기술로 구분되고,
호튼웍스(Hortonworks), 이엠씨(EMC), 클라우데라(Cloudera),
데이터브릭스(Databricks), 페이스북(Facebook) 등에서 기술 개발을 진행하고 있으며, 국내에서는 그루터(Gruter)가 오픈 소스인 아파치 타조를 통해 기술 개발을 진행 ¡ 소셜과 모바일이 만들어가는 클라우드와 사물들이 서로 연결되는 사물인터넷 시대에 배치 또는 실시간 질의 분석이 필요한 빅데이터의 양이 2020년까지 약 44,000 엑사바이트로 엄청난 증가 추세 ¡ 데이터 증가 추세가 스토리지 시스템의 용량 증가 속도보다 빠를 것으로 예상됨에 따라 보다 대용량의 데이터를 저장 및 관리하기 위한 빅데이터 파일 스토리지에 대한 기술 개발이 절실 표 1. 국내외 기술 개발현황 구분 Hortonworks Stinger (Hive on Tez)
Gruter Tajo EMC Pivotal
HAWQ Cloudera Impala Databricks SparkSQL Facebook Presto
기반 분류 Disk Based Memory Based
질의 언어 HiveQL SQL-2003 SQL-92 SQL-92 SQL-92 SQL-92 리소스 대비 대용량 처리 여부 ○ ○ ○ △ (디스크 기반 조인, 집계 지원) × ×
간단 질의 응답
시간 Moderate Low Low Very Low Very Low Very Low
질의 처리 내고장성 지원 여부 ○ ○ ○ × ○ × DAG 기반 실행 계획 여부 ○ ○ × × ○ ○ 분석 라이브러리 지원 여부 × × ○ (MADlib) × △ (Spark MLlib, GraphX 연동) × 참고버전 2.1.0 (2016/06) 0.11.3 (2016/05) 2.0.1 (2016/10) 2.7.0 (2016/10) 2.0.2 (2016/11) 0.157 (2016/11)
2. 연구 목표
페타바이트급 이상 정형/비정형 빅데이터 통합 분석을 위해 부하인지형 유니파이드 빅데이 터 분산 파일 시스템을 기반으로 인터랙티브 분석과 MR 기반 심층 분석을 동시에 지원하는 분산 쿼리 엔진 개발 그림 4. 연구목표 및 연구내용 최종목표를 달성하기 위해, 아래 세 가지 세부목표를 설정하여 연구를 진행 n MR 내장형 분산 질의 엔진 기술 개발 n 배치/온라인 듀얼모드 분산 데이터 처리 기술 개발 n 유니파이드 빅데이터 분산 파일 시스템 기술 개발표 2. 최종목표 및 세부목표 구분 내용 최종목표 페타바이트급 이상 정형/비정형 빅데이터 DW 서비스 운영 시스템에서 쿼리 기반 인터랙티브 온라인 분석과 MR 기반 심층 분석을 동시 지원 하는 배치·온라인 듀얼모드 분석 SW 핵심기술 개발 세부목표 l Ad-hoc 질의와 맵리듀스 기반 심층 분석 질의를 제공하는 MR 내 장형 분산 질의 엔진 기술 개발
l DAG (Directed Acyclic Graph) 기반 동적 데이터 처리 및 데이터
공유를 제공하는 배치/온라인 듀얼모드 분산 데이터 처리 기술 개발
l 파이프라인 데이터 공유를 제공하는 운영계/분석계 통합 유니파
3. 연구 범위
가. MR 내장형 분산 질의 엔진 기술 개발 <정의> Ad-hoc 질의와 MR 기반 심층 분석 질의를 제공하는 MR 내장형 분산 질의 엔진 기술 <세부 연구내용> Ÿ SQL/MR 기반 통합 데이터 처리 인터페이스 기술 Ÿ MR 내장 SQL 최적화 기술 Ÿ 확장형 분석 연산 및 저장 데이터 모델링 기술 Ÿ MR 내장 SQL 의 Batch/On-line 듀얼모드 실행 기술 나. 배치/온라인 듀얼모드 분산 데이터 처리 기술 개발 <정의> DAG 기반 동적 데이터 처리 및 데이터 공유를 제공하는 배치/온라인 듀얼모드 분산 데이터 처리 기술 <세부 연구내용> Ÿ DAG 기반 데이터 처리 인터페이스 기술 Ÿ 배치/온라인 처리를 위한 태스크간 데이터 공유/전달 기술 Ÿ 배치/온라인 처리를 위한 동적 데이터 처리 환경 구성 기술 다. 유니파이드 빅데이터 분산 파일 시스템 기술 개발 <정의> 파이프라인 데이터 공유를 제공하는 운영계/분석계/응용계 통합 분산 파일 시스템 기술 <세부 연구내용>Ÿ 운영계/분석계 입출력 성능 간섭 처리 기술 (입출력 및 캐시 스케줄링 기술)
Ÿ 운영계/분석계 데이터 변경/접근 회피 기술 (볼륨/디렉토리/파일 스냅샷기술)
제 2 절 국내외 관련 기술의 현황
1. 국내 기술동향 및 수준
¡ 하둡 공개 SW를 기반으로 솔루션 사업을 추진하는 중소 전문기업(클라우드웨어, 그루터, 모비젠 등)이 국내시장을 개척 중이나, 공개SW 활용 측면에만 집중, 글로벌 기업과의 경쟁은 어려운 현실 ¡ 국가 R&D를 통해 인메모리 데이터베이스, 소셜 이슈 분석, 클라우드 스토리지 SW 등 관련 요소기술 개발이 진행 중이나 투자가 부족한 현황 ¡ 국내 대표적인 검색포털 회사인 네이버는 이용자들이 민간기술과 공공기관의 데이터를 분석하여 활용할 수 있도록 빅데이터 포털인 “데이터 랩 (DATA LAB)”의 베타 버전을 2016년 1월 오픈 ¡ 주관기관인 한국전자통신연구원은 국가 R&D를 통해 클라우드 스토리지 SW(GLORY-FS) 원천 기술을 개발하여 국내 서비스 사업자(SK텔레콤, LGU+, KT)등의 상용 서비스 기술로 보급 표 3. 국내 빅데이터 및 파일 시스템 관련 기업 및 기술현황 회사명 빅데이터 기술 현황 강점분야 넥스알Ÿ 하둡 기반의 빅데이터 분석 플랫폼(NDAP: NexR Data Analytics Platform) 솔루션 개발 Ÿ 빅데이터 분석 솔루션(RHive) 구축 및 상용 버전으로 ‘Enterprise RHive’ 제작중 대용량데이터 병렬처리 야인소프트 Ÿ 와이즈넛과 투비소프트와 협력을 통한 빅데이터 제품 서비스 개발 추진 Ÿ 인메모리 기반의 OLAP 솔루션인 ‘옥타곤 EOS" 출시 기업용 OLAP 그루터 Ÿ 소셜 빅데이터 분석 및 데이터 제공 서비스, 빅데이터 플랫폼 제공 서비스 구축 소셜 데이터 분석플랫폼
데이터 스트림즈 Ÿ 데이터 통합 및 품질 관리 부분에 주력 Ÿ 비정형 분석등 신규 기술 개발 추진 중 데이터통합관리 알티베이스 Ÿ 테라급 대용량 데이터와 그에 따른 쿼리 동시 처리속도 향상, 고성능 데이터 관리 기술 개발 인메모리DB 솔트룩스 Ÿ 시맨틱 분야의 핵심 기술 확보로 해외시장 공략 Ÿ 비정형 빅데이터 분석 및 시맨틱 솔루션 전문기업 Ÿ 기업/통신/금융 빅데이터 분석에 활용중 빅데이터 분석, 시맨틱 다음소프트 Ÿ 자연어처리기술과 방대한 언어자원을 기반으로 소셜미디어 등 대용량 텍스트 분석 서비스 제공 자연어처리 모비젠 Ÿ 공개SW 및 인메모리 DB기반 솔루션 빅데이터 플랫폼 구축 U2N Ÿ 페타바이트급 대규모 분산 파일 시스템 기술 개발 파일 스토리지
2. 국외 기술동향 및 수준
¡ 하둡 에코 시스템의 영향력 증대에 따라 빅데이터 처리/분석을 위한 하둡 전문 기업이 등장하여 상용 하둡 배포판 주도권 경쟁을 시작(클라우데라, 호튼웍스, MapR) n IDC의 “기업의 하둡 도입 동향” 보고서에 의하면 조사 응답 기업의 32%가 하둡 도입, 31%는 12개월 이내 도입 예정(CIO 뉴스, 2013.11.4.)¡ 글로벌 엔터프라이즈SW 기업인 IBM, 오라클(Oracle), SAP 등은 기존 RDBMS 및 DW 환경(BI 시장)을 확장하면서, 하둡 에코시스템(eco-system) 결합으로 비정형 빅데이터 처리를 수용하는 전략 추진
¡ EMC는 빅데이터 특화 솔루션인 데이터 레이크(Data Lake)와 NAS 아이실론(Isilon) 제품을 결합하여 데이터 종류와 관계없이 대규모 데이터를 수용하고 저장, 분석, 처리할 수 있는 통합된 데이터 저장소를 지원
스플렁크(Splunk)와 같은 플랫폼을 지원하는 스토리지 공급하고 있으며, 특히 하둡에 대해서는 NFS 커넥터를 제공해 NAS에 저장된 데이터를 즉시 분석 가능한 전략을 추진 표 4. 국외 빅데이터 관련 기업 및 기술 현황 빅데이터 기술 개발 추진 현황 강점분야 EMC Ÿ 빅데이터 토털 솔루션 확보를 위해 데이터 저장, 관리, 분석관련 다수업체 인수 Ÿ EMC 애널리스트랩을 운영하여 데이터 과학자 육성 Ÿ EMC Greenplum: 단일 어플라이언스 내에서 정형/비정형 데이터의 seamless 상호연계 처리/분산병렬처리 기반 빅데이터 분석, 시맨틱 IBM Ÿ 지난 5년간 140억 달러 이상을 투자하여 분석용 데이터 저장관리업체 (네티자), 데이터 통합 업체(에센셜), 분석 솔루션 업체(코그너스) 등 비즈니스 분석 관련업체 인수 Ÿ 자사 빅데이터 솔루션 강화 및 빅데이터 기반의 스마트 플래닛 프로젝트 진행
Ÿ 아파치 스파크(Apache Spark)를 IBM의 Big Data Analytics(BDA)와 상용 플랫폼에 통합하기로 함 (2015. 6) 데이터 통합, 저장관리 오라클 Ÿ 세계적인 DB업체, 하이페리온사를 인수로 분석기술 확보 Ÿ 오라클 빅데이터 어플라이언스 제품 출시 Ÿ 자사 하드웨어 및 오픈 소스 소프트웨어(R, 하둡 등)와 자체 개발한 전용 소프트웨어가 통합 대용량데이터 저장관리 SAP Ÿ 메모리 기반 DB 어플라이언스(HANA) 출시 Ÿ BI 소프트웨어, 플랫폼을 제공하는 비즈니스 오브젝트사 인수 기업용 인메모리 OLAP
HP Ÿ BI 솔루션 업체 버티카, 기업용 검색엔진 업체 오토노미를 인수하여 빅데이터 분석 시장에 진입 Ÿ 버티카: 실시간/대용량/고급 분석의 대용량 병렬처리 가능 Ÿ 오토노미: 의미기반 데이터 분석 솔루션 Autonomy 비정형데이터 분석 구글
Ÿ 대용량 데이터 처리 기술 발표: GFS(Google File System 2003년), 맵리듀스(MapReduce, 2004년), 빅테이블(BigTable, 2006년) Ÿ 빅쿼리(BigQuery) 서비스 공개: 이용자들이 빅데이터를 구글 클라우드상에 업로드하면 신속하게 분석해 주는 서비스 공개(2011년11월) Ÿ 예측 분석 솔루션: 구글 검색 로그나 과제 데이터를 기반으로 기계학습 및 통계처리 기법을 적용하여 앞으로 일어날 일을 예측하는 다양한 프레딕션(Prediction) API 공개(2010년) 빅데이터 기술
아마존 Ÿ 아마존 웹서비스: S3, EC2, Queue 서비스(SQS), DynamoDB, Elastic
MapReduce 등 서비스 제공 빅데이터 플랫폼 서비스 MS Ÿ Windows Azure와 윈도 서버 플랫폼용 아파치 하둡 개발 계획 Ÿ 하둡 기술 전문업체 ‘호튼웍스’와 협력 대용량데이터 저장관리 및 분석기술
제 2 장 주요 연구 성과
제 1 절 연구동향
1. SQL 온 하둡 연구동향
¡ SQL 온 하둡 기술은 크게 클라우데라, 호튼웍스, 맵알테크놀리지스가 접근하는 네이티브(native) 하둡 기반 시스템 계열과 IBM, 오라클, 테라데이터 등의 업체들이 출시하는 관계형 데이터베이스와 하둡을 연계한 하이브리드 시스템 계열로 기술 진화를 해 나가고 있음 ¡ 클라우데라는 데이터 웨어하우스 온 하둡 패키지 전략 일환으로 2013년 초 임팔라(Impala)를 발표한 후, 아파치 인큐베이터 프로젝트로 진행중(2016. 11) ¡ 맵알테크놀로지스는 페타바이트 규모에서 안정적인 인터랙티브 SQL 분석을 제공하는 하둡을 위한 오픈 소스, 저지연(low-latency) 쿼리 엔진인 아파치 드릴 (Apache Drill) 1.0을 출시(2015. 6) ¡ 네이티브 하둡 기반 시스템은 클라우데라, 호튼웍스가 기술경쟁을 벌이고 있지만, 엔터프라이즈 프로덕션 진입은 아직 본격적이지 않음(개념검증 단계나 기술평가에 머물러 있음) ¡ 벡터와이즈(Vectorwise)사는 하둡과 연동할 수 있는 병렬 처리 기술을 적용한 VectorH를 소개함(2016. 7)2. 데이터 웨어하우스 연구동향
¡ 데이터 웨어하우스 시장에서는 테라데이타, 오라클, IBM 등 DB 업체들이 경쟁하던 전통 데이터 웨어하우스(DW) 솔루션 시장 경쟁구도에 아마존 웹서비스(AWS)와 빅데이터 및 하둡 전문업체 클라우데라, 맵알테크놀로지스가 가세('2015년 DW 및 데이터 관리 솔루션 매직쿼드런트 보고서', 2015.02)¡ 테라데이타는 ‘테라데이타 통합데이터아키텍처(UDA)’의 하둡과 데이터베이스 간 양방향 쿼리를 지원하기 위한 쿼리그리드(QueryGrid): 데이터베이스 투 프레스토 소프트웨어 발표(2015.06)
¡ 구글의 BigQuery, AWS의 Redshift와 같은 클라우드상의 하둡 분석 플랫폼을 제공하는 MPP 데이터 웨어하우스가 급속히 성장해 나가고 있음(2016. 03)
3. 파일 시스템 연구 동향
가. 운영계 파일 시스템 연구 동향¡ 클라우드 컴퓨팅 사업자, 빅데이터 분석, 슈퍼컴퓨팅 등에서 페타스케일 스토리지 구축 사례가 증가하고 있으며, 인텔, 아파치, 레드햇 등은 공개 SW 기반 페타스케일급 분산 파일 시스템을 개발 및 배포(Lustre, Hadoop, Gluster, Ceph 등) ¡ 국내의 경우 인터넷 포털, 클라우드, 통신사업자 등에서 페타스케일급 스토리지
구축 사례가 증가하고 있으며, NHN, 다음커뮤니케이션즈, 한국전자통신연구원은 페타스케일 분산 파일 시스템을 자체 개발하여 자사 서비스에 활용 또는 기술 보급(OwFS, Tenth, GLORY-FS)
나. 분석계 파일 시스템 연구 동향 ¡ 전세계 빅데이터 분석 도메인에서는 공개SW인 하둡 프레임 상위에 각종 분석을 위한 에코시스템들을 탑재하는 것이 산업계 표준처럼 인식되고 있으며, 이러한 분석 도구들의 데이터 저장 및 관리를 위해 HDFS를 주도적으로 사용 ¡ Lustre, Ceph의 경우 자사의 파일 시스템과 하둡을 연동하기 위한 플러그인 기술을 일부 제공하고 있으나 아직까지는 프로토타입 단계임
제 2 절 연차별 연구 내용
1. 1 차년도(2014 년)
가. 연구개발 목표: 운영/분석계 스토리지 공유 및 듀얼모드 분석 엔진 설계 나. 연구개발 내용 ¡ 배치/쿼리 타스크 분할 및 듀얼 분석 구조 설계 - DAG 기반 분산 데이터 처리 엔진 기술 - 사용자 정의 태스크 스케줄링 기술 ¡ MR 내장형 분산 쿼리 엔진 설계 - 통합 인터페이스 지원 기술 및 통합 질의 처리 엔진 기술 - 메타데이터 저장소 기술 ¡ 운영/분석을 동시 지원하는 공유 스토리지 구성 기술 개발 - 페타바이트 분산 파일 시스템 기반 분석계 통합 구성/운영 기술 ¡ 분석계 특화형 스토리지 입출력 인터페이스 기술 개발 - 분석계 특성을 고려한 페타바이트 분산 파일 시스템 인터페이스 기술2. 2 차년도(2015 년)
가. 연구개발 목표: 워크로드 인지형 스토리지 및 듀얼모드 분석 엔진 핵심 기술 개발 나. 연구개발 내용 ¡ 데이터 워크로드 인지형 질의 처리 기술 개발 - 데이터 워크로드 모델링 및 인지 기술 - 워크로드 기반 듀얼모드 질의 최적화 기술 ¡ DAG 기반 분산 질의 플랜/파티셔닝 기술 개발- DAG 기반 질의 플랜 생성 및 최적화 기술 - 질의 블록 스케줄링 및 파티셔닝 기술 ¡ 운영/분석계 동시 데이터 입출력을 처리하는 분산 파일 시스템 기술 개발 - 운영/분석 응용이 혼재된 상태에서 입출력 간섭 제어를 위한 캐시 및 입출력 스케쥴러 기술 - 분석용 데이터 일관성 유지를 위한 데이터 변경 회피 Pinpoint 스냅샷 기술
3. 3 차년도(2016 년)
가. 연구개발 목표: 유니파이드 분산 파일 시스템 및 듀얼모드 분석 엔진 통합 기술 개발 나. 연구개발 내용 ¡ 듀얼모드 분석 프레임워크 기술 개발 - 분석 어플리케이션 연동 기술 - 동적 프레임워크 구성 기술 ¡ MR 내장형 질의 및 질의 최적화 기술 개발 - I/O 비용 기반 분산 실행 계획 최적화 기술 - MR 내장을 위한 확장 연산자 생성 및 처리 기술 ¡ Zero-Copy 입출력 가속 기술 - 유니파이드 빅데이터 스토리지의 성능 향상을 위한 입출력 가속 기술 - 운영/분석 입출력 간섭 제어를 위한 입출력 스케쥴러 확장 기술 - 운영계/분석계 동시 운영 시 성능 간섭 해소를 위한 입출력 스케쥴러 확장 기술 총년도 연구목표 달성을 위해, 빅데이터 분석 플랫폼 기술과 빅데이터 분산 파일 시스템 기술과 같이 크게 두 가지 핵심 기술로 구분하여 연구개발을 진행하였다. 본 보고서에서는기술하고, 4 장에서는 유니파이드 빅데이터 분산 파일 시스템(BIG-FS) 연구 결과를 기술한 다.
l KIWI: 배치/온라인 듀얼모드 빅데이터 분석 플랫폼
제 3 절 연구 추진 체계 및 실적
1. 연구 추진 체계
정부출연연구기관 융합 연구의 일환으로 한국과학기술정보연구원(KISTI) 과학데이터기술연구실과 다음의 공동 연구를 추진하였다. n 과학기술 빅데이터 분석을 위한 병렬 알고리즘 개발 (1차년도) n 하둡 기반 대규모 그래프 데이터 관리 기술 개발 (2, 3차년도) 또한, 중소기업 협업을 위해 의료 데이터 전문 기업(㈜누스코)과의 협력을 통한 표준 의료 데이터(EHR: Electronic Health Record)를 기반 의료 빅데이터 데이터 웨어하우스를 구축하여 빅데이터 분석 시범 서비스 개발에 활용하였다.데이터 웨어하우스 시범 서비스 구축 등을 통하여 과제 결과물에 대한 활용도 재고하였다. 의료데이터기반 빅데이터 분석 시범서비스를 개발을 위해, 공동연구기관 (㈜ 누스코)에서 구축한 의료데이터기반 분석용 데이터 웨어하우스를 활용하였다. 빅데이터 플랫폼 개발에 필요한 기반 기술에 대한 선행 연구는 동명대학교, 호서대학교, 한국외국어대학교와 같은 대학들의 위탁연구를 통해 진행하였다. 표 5. 위탁 과제 추진 실적 과 제 명 수행기관 과제내용 수행연도 맵리듀스 처리 가속화를 위한 타스크 스케쥴링 알고리즘 연구 동명대 맵리듀스 처리를 가속화하기 위한 기반 알고리즘 연구 및 병렬처리 기법 연구 1차년도 GPU 클러스터 환경에 최적화된 맵리듀스 프레임워크 연구 동명대 GPU 클러스터의 환경 특성에 따른 맵리듀스 프레임워크 개발 및 GPU 제약조건 회피 알고리즘 연구 2차년도 하둡 기반 데이터 웨어하우스에서의 반정형 데이터 처리 선행 연구 호서대 하둡 기반 데이터 웨어하우스에서 반정형 데이터의 저장, 인덱싱, 구조 질의 처리 및 최적화 기술 연구 2차년도 GPU 기반 대규모 데이터 관계 고속 분석 및 가시화 도구 동명대 GPU의 병렬 처리 특성을 활용한 데이터 처리 프레임워크 및 가시화 기술 연구 3차년도 대용량 반정형 데이터 처리 성능 향상을 위한 분산 처리 최적화 기술 연구 호서대 대용량 반정형 데이터의 구조 질의 처리 최적화, 인덱싱, 메모리 활용 및 점진적 처리 기술 연구 3차년도 분산 처리 기반 확장성 있는 선호도 질의 처리 방법 한국외대 하둡 기반 데이터 웨어하우스에서의 선호도 질의 처리 알고리즘 연구 3차년도
주관기관에서 수행한 빅데이터 플랫폼에 대한 성능 시험은 공인시험인증 (KTL)을 통해 진행하였으며, 단위기능에 대한 시험은 시험 자동화 환경 구축을 통해 시험을 진행하였다.
2. 연구 추진 실적
가. 최종년도(2016 년) 성과지표에 대한 계획 대비 실적 표 6. 최종년도 성과지표에 대한 계획 대비 실적 성과 지표 계획 실적 달성도 내용 쿼리 분석(TPC-H) 주1) 세계최고 대비 1.3배 1.3배 100% 목표 달성 MR 분석 성능 주2) 하이브 대비 30배 31배 103% 목표 초과 달성 파일 데이터 처리 성능 주3) 20,000 creates/sec 21,000 creates/sec 105% 목표 초과 달성 데이터 입출력 간섭률 주4) 10% 10% 100% 목표 달성 특허(국내/국제) 12건 (6건/6건) 15건 [(8건/3건) 출원, (2건/2건) 출원 중] 125% 목표 초과 달성 논문(비SCI/SCI) 6건 (4건/2건) 30건 (27건/3건) 500% 목표 초과 달성 주1) TPC-H 벤치마크: 의사 결정 지원 시스템을 대상으로 대량의 데이터에 대한 복합적 애드혹(ad-hoc) 질의를 위한 TPC-H 벤치마크 주2) MR 분석 성능: 하둡 클러스터 환경에서 동일한 데이터셋에 대하여, 하이브 질의 성능과의 상대 성능 비교 주3) 파일 메타데이터 처리 성능: 대규모 빅데이터 분석 및 레거시(legacy) 서비스에서 요구되는 메타데이터의 처리 성능을 측정 주4) 데이터 입출력 간섭률: 운영계와 분석계 데이터 서비스가 동시에 실행될 때, 각 데이터 입출력 간의 성능 간섭 비율을 측정나. 목표 달성현황 개요 ¡ 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 기술 개발 - 표준 SQL 인터페이스를 통한 인터랙티브 질의와 맵리듀스 배치 기반 심층 분석 질의를 동시에 제공하는 빅데이터 처리 소프트웨어 개발 - 인터랙티브 질의(TPC-H) 세계최고 대비 1.3 배 성능 달성 (달성 요인) 질의처리 최적화를 통한 데이터 처리 성능 개선 - 심층 분석 질의 하이브 대비 31 배 성능 달성 (달성 요인) 개선된 분산 처리(DAG 기반 실행엔진)를 통한 배치처리 성능 향상 ¡ 유니파이드 빅데이터 분산 파일 시스템 기술 개발 - 운영계와 분석계를 동시에 지원하는 빅데이터 분산 파일 시스템 개발 - 파일 메타데이터 처리 21,000 Creates/Sec 성능 달성 (달성 요인) 저수준 메타데이터 입출력 프로토콜 및 고속 캐시 기술 개발 - 데이터 입출력 간섭률 10% 달성 (달성 요인) 워크로드 인지형 입출력 제어 및 제로 카피 기술 개발 ¡ 의료데이터기반 빅데이터 분석 시범서비스 개발 - 듀얼모드 빅데이터 분석 플랫폼을 활용한 의료데이터 기반 분석 서비스 개발 - 질병 관계도 기반 검사 수치 분석, 지역별 질병 분포 분석, 질병 원인 분석, 데이터 분석 및 가시화 기능 제공
3. 정량적 달성도
¡ 정량 연구 실적 개요 (상세내용은 부록 참조) 표 7. 정량 연구 실적 개요 분류 논문 특허 국내 국외 국내 국외 발표 게재 발표 게재 출원중 출원 등록 출원중 출원 등록 건수 10 5 11 4 2 8 0 2 3 0 분류 프로그램 기술문서 표준 기고서 시제품 기술이전 고용창출 및 인력양성 신규채용 인력양성 연구인력 생산인력 건수 20 146 2 2 0 1 0 0제 4 절 연구 목표 수준의 타당성
1. 성과 목표 개요
빅데이터 플랫폼 우수 성과 목표를 위한 성능 지표를 설정하고, 기술 준비도(TRL) 기술 개발 단계 중, "주요 기능에 대한 개념 정립 단계(2단계)"를 시작으로 하고, "유사 운용 환경에서 모델 또는 시제품 성능 시연(5단계)"를 종료 시점으로 설정하였음2. 설정근거
세계 최고 수준의 질의 분석 성능(세계 최고 대비), MR 분석 성능(하이브 대비), 파일처리 성능(HDFS)과의 비교를 통해 개발 기술의 우수성이 객관적으로 입증될 수 있도록 성과 목표를 도출함제 3 장 배치/온라인 듀얼모드 빅데이터 분석
플랫폼 기술 개발
제 1 절 연구 범위의 요약
1. 연구 목표
배치/온라인 듀얼모드 빅데이터 분석 플랫폼 기술의 목표는 표준 SQL 인터페이스를 통한 인터랙티브 질의와 MR 배치 기반 심층 분석 질의를 동시에 제공하는 빅데이터 처리 소프트웨어 핵심 기술을 개발하는 것이다. 그림 7. 배치 온라인 듀얼모드 분산 질의 엔진 기술 개념도배치/온라인 듀얼모드 빅데이터 분석 플랫폼(코드명 KIWI: Key Impact on data Warehouse Infrastructure)의 핵심적인 특징은 다음과 같다.
n 배치/온라인 질의 동시 지원 - 장시간 실행해야 하는 배치 질의 처리를 위해 질의를 수행하는 클러스터 노드에 하드웨어/소프트웨어 결함 발생 시 전체 질의 처리를 재실행하지 않도록 내고장성 제공 - 일부 태스크가 실패하더라도 동적으로 태스크를 다시 스케줄링 하여 결함이 있거나 처리가 비정상적으로 느린 노드의 존재 여부에 무관하게 질의를 정상 처리 - 온라인 질의 처리 시 데이터 규모에 따라 질의 응답 시간이 달라지나, 단순 집계 연산 등 간단한 질의에 대해서는 낮은 응답 시간을 제공 n 질의 실행 계획 최적화 - 사용자가 질의 처리 과정에 대한 고민 없이 질의를 작성하여 수행하더라도 효율적인 실행 계획을 생성하여 배치/온라인 방식으로 처리 - 클러스터 자원 활용을 높여 처리 시간을 줄이기 위해 조인, 집계 연산 등 주요 연산을 분산 처리하도록 최적화된 실행 계획을 생성 n 호환성 및 확장성 - 사용자 편의 및 하둡 에코시스템과의 연동을 위해 다양한 호환성 및 확장성 제공 - 질의 언어: ANSI SQL 표준 준수 (SQL 온 하둡 시스템 고유 확장 부분 제외) - 원격 접속 호환: JDBC 드라이버 지원
- 다양한 파일 형식 지원: RowFile, RCFile, ORCFile 등
- 새로 출현한 파일 형식 혹은 사용자 고유 파일 형식 사용을 위해 파일 형식
및 입/출력 메소드 추가 기능을 제공
- 임의의 연산을 사용할 수 있도록 사용자 정의 함수 (user-defined function)
2. 연차별 연구 개발 내용
배치/온라인 듀얼모드 빅데이터 분석 플랫폼 기술 개발은 1차년도 인터랙티브 질의와 배치 기반 심층 분석 질의를 동시에 제공하는 MR 내장형 분산 듀얼모드 분석 엔진 설계, 2차년도 데이터 워크로드 인지형 듀얼모드 분석 엔진 핵심 기술 개발, 3차년도 듀얼모드 분석 엔진 통합 기술 개발로 진행되었다. 1차년도에는 MR 내장형 분산 질의 엔진 배치/온라인 듀얼모드 분산 데이터 처리 엔진의 핵심 내용을 설계하고, 1차년도 설계 내용을 바탕으로 2차년도에는 데이터 워크로드 인지형 질의 처리 기술과 DAG 기반 분산 질의 플랜/파티셔닝 기술을 확장 설계하고 개발하였다. 3차년도에는 2차년도 개발한 기술을 기반으로 MR 내장형 질의 처리 인터페이스를 설계하고 분산 질의 처리 엔진을 개발하였으며, I/O 비용 기반 분산 실행 계획을 최적화하여 분산 질의 처리 엔진의 성능을 향상시켰다. 또한, 배치/온라인 듀얼모드 분석 기술의 활용을 위해 분석 어플리케이션 연동 기술과 동적 분석 프레임워크 구성 기술을 개발하고 통합하였다. 그림 8. 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 기술 개발 개요가. 1 차년도(2014) 개발 내용 및 범위 n MR 내장형 분산 쿼리 엔진 - 배치/온라인 질의를 동시 지원하는 통합 인터페이스 기술 - 표준 ANSI SQL 질의를 지원하는 분산 처리 기술 - 비용 기반 질의 실행 계획 최적화 기술 n 배치/온라인 듀얼모드 분산 데이터 처리 기술 - 클러스터 자원 활용을 높여 처리 시간을 줄이기 위해 조인, 집계 연산 등 주요 연산을 DAG 기반 분산 질의로 변경 분할하여 분산 처리하도록 최적화된 실행 계획 생성 기술 - 물리적 질의 실행 계획을 태스크 단위로 나누어 분산 처리하는 분산 실행 및 자원 할당 기술 - 분산 데이터를 효율적으로 관리하기 위한 메타데이터 저장소 기술 - 질의를 수행하는 노드에 대한 장애 탐지 및 내고장성 보장 기술 나. 2 차년도(2015) 개발 내용 및 범위 n 데이터 워크로드 인지형 질의 처리 기술 - 질의 워크로드 이력 관리 및 분석 기술 - 질의 워크로드 기반 질의 컬럼셋 구축 기술 및 연관 정보 매핑 기술 - 질의 컬럼세트 기반 질의 처리 및 실행 기술 n DAG 기반 분산 질의 플랜/파티셔닝 기술 - 노드의 자원 모니터링 및 자원 관리/할당 기술 - DAG 기반 실행 계획 스케줄링 기술 및 태스크 파티셔닝 기술 - 클러스터 내 컨테이너 배치 및 분할된 태스크 실행 및 결과 처리 기술
다. 3 차년도(2016) 개발 내용 및 범위 n 듀얼모드 분석 프레임워크 연동 기술 - 듀얼모드 빅데이터 분석 플랫폼과 분석 어플리케이션의 연동 기술 - 분석 어플리케이션 연동을 위한 질의 처리 인터페이스 및 분석 결과 가시화 인터프리터 기술 - 하둡과 Yarn 의 연동을 통한 자원 할당 및 멀티 질의 스케줄링을 지원하는 동적 프레임워크 구성 기술 n MR 내장형 질의 및 질의 최적화 기술 - MR 내장을 위한 확장연산자 생성 및 처리 기술 - I/O 비용 기반 분산 실행 계획 최적화 기술 - 데이터 파티션과 질의 컬럼셋을 이용한 질의 워크로드 기반 질의 가속화 기술
3. 연구 결과 요약
가. 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 기술의 연구 산출물 산출물 건수 비고 프로그램 등록 13 특허 국제(출원/출원중/등록) 1/1/0 국내(출원/출원중/등록) 5/1/0 논문 SCI/비SCI 3/24 표준 국내 2 (빅데이터WG) TTA 시제품 듀얼모드 빅데이터 분석 엔진 실험 시제품 1 나. 정량적 연구 목표 달성도 성과지표 (주요성능 Spec) 단위 세계최고수준 기술 개발 목표치 달성 결과 쿼리 분석(TPC-H) QphH@30GB주5) 979.7 1285.5 1.31배 MR 분석 총 수행시간(초) 3289.49 103.54 31.77배주5) QphH@Size(TPC-H Composite Query per Hour): TPC-H 벤치마크에서 성능 측면과 처리량 측면을 동시에 고려한 측정 단위. Size는 TPC-H Benchmark에 사용된 데이터베이 스의 크기로 1GB, 10GB, 30GB, 100GB, 300GB, 1000GB, 3000GB, 10000GB의 몇 가지 지정된 크기를 명시함.
제 2 절 세부 추진 내용
1. 듀얼모드 빅데이터 분석 플랫폼 요구사항 분석 및 전체 구조 설계
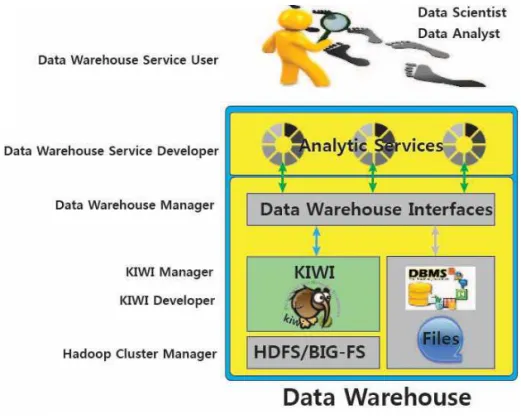
가. 시스템 특성 및 사용자 정의 빅데이터 분석을 위한 데이터 웨어하우스는 하둡 클러스터 환경에서 심층 분석과 인터랙티브 분석을 제공하는 배치/온라인 듀얼모드 빅데이터 분석 플랫폼(KIWI)과 DBMS 및 분산 파일 시스템과 통합되어 구축된다. <그림 9>는 KIWI의 간략한 구조 및 각 레이어에서의 KIWI 사용자를 보여주고 있다. 빅데이터 분석을 위한 서비스(Analytic Services)는 데이터 웨어하우스에서 제공하는 인터페이스를 사용하여 데이터 웨어하우스 서비스 개발자에 의해 개발되며, 데이터 과학자 및 데이터 분석가와 같은 데이터 웨어하우스 서비스 사용자에 의해 사용된다.다음은 배치/온라인 듀얼모드 빅데이터 분석 플랫폼(KIWI)의 사용자를 정의한 것이다.
n 하둡 클러스터 관리자: 하둡 클러스터 관리자는 KIWI가 설치되고 운영되는 하둡
클러스터를 구성하고 관리하는 역할을 수행하며, KIWI가 하둡 클러스터에서 운영되기 위한 요구사항을 제시하는 KIWI 사용자이다.
n KIWI 개발자 (KIWI Developer): KIWI 개발자는 KIWI의 기능을 정의하고, 정의된
기능을 설계하고 구현하는 실제 KIWI를 개발하는 KIWI 사용자이다.
n KIWI 관리자 (KIWI Manager): KIWI 관리자는 KIWI 개발자가 개발한 KIWI를 하둡
클러스터에 설치 및 운영하기 위한 요구 사항을 제시하는 KIWI 사용자이다.
n 데이터 웨어하우스 관리자 (Data Warehouse Manager): 데이터 웨어하우스 관리자는
KIWI를 사용하여 데이터 웨어하우스를 구축하기 위해 요구되는 사항을 제시하는 KIWI 사용자이다.
n 데이터 웨어하우스 서비스 개발자 (Data Warehouse Service Developer): 데이터
웨어하우스 서비스 개발자는 데이터 웨어하우스 서비스 사용자, 즉 데이터 분석가 또는 데이터 과학자 등의 최종 사용자가 요구하는 빅데이터 분석 서비스를 개발하기 위해 요구되는 사항을 제시하는 KIWI 사용자이다.
n 데이터 웨어하우스 서비스 사용자 (Data Warehouse Service User, End User): 데이터
웨어하우스 서비스 사용자는 KIWI와 직접적인 관련은 없으나, 빅데이터 분석을 위하여 데이터 웨어하우스의 서비스를 사용하는 데이터 분석가 또는 데이터 과학자 등의 최종 사용자로, 데이터 웨어하우스 서비스 개발자에 의해 개발되는 데이터 웨어하우스 서비스의 요구사항을 제시함으로써, 데이터 웨어하우스 서비스 개발자가 서비스 개발을 위해 KIWI에 요구되는 사항을 제시할 수 있도록 하는 사용자이다.
나. 사용자 및 시스템 요구사항 정의 배치/온라인 듀얼모드 빅데이터 분석 플랫폼에 필요한 사용자 요구사항과 시스템 구조 정의에 필요한 시스템 요구사항을 정의하였고, 이를 분류한 결과는 <표 6 >과 같다. 표 8. 배치/온라인 듀얼모드 빅데이터 분석 플랫폼의 요구사항 분류 사용자 요구사항 시스템 요구사항 기능 Ÿ KIWI 관리자: 7개 Ÿ KIWI 개발자: 18개 Ÿ 데이터 웨어하우스 관리자: 9개 Ÿ 데이터 웨어하우스 서비스 개발자: 11개 Ÿ 시스템 설치/운영: 14개 Ÿ 데이터 적재 및 관리: 21개 Ÿ 질의 처리 및 관리: 10개 Ÿ 유틸리티: 1개 비기능 Ÿ 클러스터 관리자: 1개 Ÿ KIWI 관리자: 1개 Ÿ KIWI 개발자: 4개 Ÿ 데이터 웨어하우스 서비스 개발자: 4개 Ÿ 데이터 웨어하우스 서비스 사용자: 2개 Ÿ 성능 요구사항: 4개 Ÿ 설계 요구사항: 1개 Ÿ 시스템 특성 요구사항: 3개 Ÿ 인터페이스 요구사항: 4개 총 계 57개 58개
다. 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 구조 설계 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 요구사항으로부터 도출해 낸 기능에 따라 <그림 10>과 같은 구조를 설계하였다. 그림 10. 배치/온라인 듀얼모드 빅데이터 분석 플랫폼 구조도 배치/온라인 듀얼모드 빅데이터 분석 플랫폼을 구성하는 주요 블록과 그 내용은 다음과 같다. n 듀얼모드 인터페이스