1. 서 론
1)
ICT (Information and Communications Tech- nologies)는 창조경제의 기반이며 BMW로 대변되 는 Big Data, Mobile, Wearable이 최근에 많이 화 두가 되고 있다. 여기에서는 주로 빅데이터에 대 해서 언급할 계획이다. 사실 빅데이터 분석의 본 질은 그리 새로운 것은 아니다. 빅데이터 분석은 통계라는 학문을 출발점으로 하며, 인류가 통계를 활용한 역사는 매우 오래되었기 때문이다. 하지만 IT 기술의 발전, 그리고 관련된 시스템의 보급으 로 데이터의 종류 및 축적량이 방대해지자, R&D 분야 및 제조 , 금융 등 다양한 산업 종사자들로 하 여금 이 방대한 데이터들을 효율적으로 활용할 수 있다면, 그들이 안고 있는 문제 해결에 큰 도움이 될 수 있을 것이라는 생각을 들게 했다. 기존의 통 계 기술에 방대한 데이터를 수집, 관리, 처리하는 기술이 더해진 것이 오늘날의 빅데이터 분석 기술 의 핵심적인 특징이다 . 빅데이터에 대해서 2001년 에 Doug Laney란 애널리스트가 처음으로 3가지
주 저자(E-mail: [email protected])
의 V로 정의하였다[4].
먼저, 데이터의 거대한 용량 측면에서의 Volume 이다. 최근에는 일반기업에서도 테라바이트(TB)~
페타바이트(PB)급 규모의 데이터를 다루는 경우가 증가하고 있으며, 특히 미국 기업의 1/3 이상이 10 TB 이상의 데이터를 확보/분석하고 있다고 한다.
두 번째로 데이터의 다양한 형태 측면에서의 Variety이다. 일반적으로 데이터라고 하면 숫자를 의미하는 경우가 많지만, 오늘날에는 크기와 내용 이 제 각각인 통일되지 않은 구조의 비정형 데이 터가 90% 이상을 차지하고 있다.
마지막으로, 데이터의 빠른 생성 속도 측면의 Velocity이다. 데이터 생성 후 유통, 활용되기까지 소요시간이 수 시간~수 주 단위에서 최근에는 분, 초 이하로 짧아져서 거의 실시간으로 활용되는 추 세이다. 다시 한 번 더 빅데이터 분석을 정의해보 면 빅데이터 분석이란 비정형 데이터가 포함된 방 대한 대용량 데이터를 분석하여 의미 있는 패턴이 나 결과를 도출해내는 기술이다. 기존의 통계적인 데이터 분석의 결과는 Global Optimum이 될 수가 없었다. 왜냐하면 숫자로 표현되는 정형 데이터 이 외에도 빙산의 안 보이는 수면 아래의 모습처
화학산업에서의 빅데이터 분석 기술
이 창 송⋅이 호 경† LG화학 기술연구원 중앙연구소
Big Data Analytics in Chemical Industries
Changsong Lee and Ho Kyung Lee
† Corporate R&D, LG Chem Research ParkAbstract: 데이터의 축적량 및 처리 기술의 발전으로 오늘날 빅데이터 기술은 다양한 산업에 걸쳐 활발히 활용되고 있다. 가격 경쟁력 이외에 품질 및 수율의 차별화가 요구되는 제조업의 경우에도 예외가 아니다. 여기에서는 화학 산업의 제조 공정에 대한 빅데이터 적용 사례로서 불량 원인 분석을 통한 품질개선, 생산성 향상, 예측모델 기반 최적 화, 그리고 에너지 절감 사례를 다루고자 한다.
Keywords: big data, analytics, 품질, 생산성, 예측, 에너지절감
럼 엄청난 비정형 데이터가 숨어 있었기 때문이 다. 오늘날의 데이터 분석은 이러한 비정형 데이 터를 되도록 많이 수집하고 정형화시킴으로써 데 이터 분석의 결과가 조금 더 Global Optimum에 가까이 갈 수 있도록 돕고 있다.
이러한 빅데이터 기술은 제조, 금융, HR, 마케 팅, 유통, 재무, 환경, 통신, 의료 등 다양한 분야에 서 도입 및 본격적인 적용을 하고 있으며, 회사의 모든 활동 분야에서 적용될 수 있다[5].
특히 제조업 분야에서도 빅데이터 기술 활용을 통한 이익 창출 기회가 많음을 인식하고 대기업을 중심으로 적극적인 도입 및 활용을 하고 있는 상 태이다[6].
제조업의 경우, 품질 및 수율을 향상시키는 것 이 매우 중요하며, 대기업들의 경우 기술적으로는 이미 상당한 수준에 도달해 있는 경우가 많으나, 기업 간 상품의 동질화 (commoditization)가 진행 되면서, 제품의 차별성이 떨어지고, 가격 경쟁 이 외의 요소로 시장 경쟁력을 유지하는 것이 쉽지 않은 고질적인 문제가 있다. 이와 같은 한계의 극 복을 위하여 90년대 말부터 6시그마 등의 혁신을
통해 가시적인 성과를 달성해 왔지만, 향후에는 샘플링 데이터가 아닌, 전수 데이터에 가까운 엄 청난 양의 정보를 활용할 수 있는 빅데이터 기술 없이는 계속되는 경쟁에서 생존할 수 없는 상황이 되었다.
2. 빅데이터 적용 사례
국내 기업에서도 제조공정 내에 구축된 빅데이 터 인프라의 활용을 통해 공정 및 품질 혁신을 지
*출처 : 3V, Doug Laney, Technology View (2001) Figure 1. 빅데이터기술의 3요소.
Figure 2. 정형/반정형/비정형 데이터.
*출처 : Entrue World 2014
Figure 3. 회사에서의 빅데이터 적용 분야.
Figure 4. 화학산업 제조공정에서의 빅데이터 분석.
Figure 5. 제조공정의 빅데이터 분석 방법론.
속적으로 진행하고 있으며, 크게 Figure 4의 그림 과 같이 4가지의 영역에서 가시적인 성과들을 이 루어내고 있다. 본문에서는 이러한 4가지의 품질 개선, 생산성향상, 예측 기반 최적화 모델, 그리고 에너지 절감 사례에 대해 빅데이터 기술을 적용하 여 성과를 창출한 사례를 소개한다.
Figure 5는 제조 현장에서의 다양한 Data Ware- house에서 수집되는 대용량의 정형 데이터 뿐만 아니라 현장 수기 데이터 , 도면, 품질 측정 이미지 데이터 등의 비정형 데이터를 수집하고 여러 고급 통계 이론의 분석을 통해 핵심 영향 인자의 도출, 이러한 도출된 영향 인자를 이용하여 다변량 모형 화하는 단계, 그리고 최종적으로 현장개선을 위한 최적조건을 도출하는 제조공정에서의 빅데이터 분석방법론을 설명하고 있다.
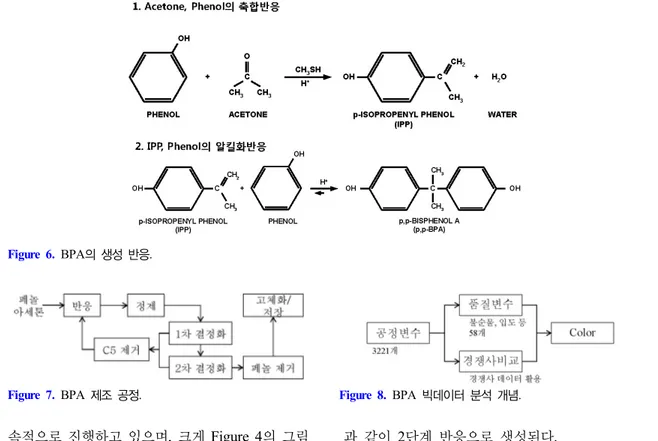
2.1. Bisphenol-A(BPA) 품질 개선 사례
BPA는 Phenol 2 몰과 Acetone 1 몰의 반응으 로 생성되며, Bisphenol-A 또는 2,2 bis(4-hydrox- yphenyl) propane으로 명명된다. BPA는 Figure 6
과 같이 2단계 반응으로 생성된다.
BPA 공정을 간략화하면 Figure 7과 같다. 페놀 과 아세톤을 촉매 조건 하에 반응하면 BPA가 생 성되며, 여러 부반응들로 인하여 불순물들이 양산 되므로, 이를 1차적으로 정제하고, 불순물 제거 및 순수한 결정 생성을 위하여 두 번의 연속되는 결 정화 공정을 거친다. 이 과정에서 결정화 용액으 로 쓰는 모액(Mother Liquor)에서 C5 (Pentane)를 회수하여 Phenol이 대부분인 액상으로 변환한 후 다시 반응 공정으로 회수하게 된다. 결정화를 거 친 BPA는 고온 공정에서 페놀을 최종적으로 제거 한 후 고체화 과정을 거쳐 제품화 된다.
BPA의 핵심 품질은 Color로서, 고온 안정성을 대변하는 Index이다. 최종 제품의 255 ℃, 10 min 후의 APHA Color 측정값으로 고온 안정성을 판 단하고 있다.
2014년부터 BPA Color 개선 활동을 진행하였 으며, 빅데이터 방법론을 적극적으로 활용하였다.
1차적으로 불순물, 입도 등의 품질변수를 활용한 Color의 통계적 모형화 및 경쟁사 데이터와의 비
Figure 6. BPA의 생성 반응.
Figure 7. BPA 제조 공정. Figure 8. BPA 빅데이터 분석 개념.
교, 분석을 통하여, 핵심적인 품질변수를 도출하였 으며, 2차적으로 3221개의 공정변수를 활용한 핵 심 품질변수의 통계적 모형화로 공정 개선 방향을 결정하였다.
2.1.1. 핵심 품질변수 파악
1차적으로 품질변수 데이터를 활용하여, 주성 분 분석(Principal Component Analysis, PCA)[1]
을 진행하였으며, 불순물 및 입도의 변화가 Color 변동의 핵심 인자임을 파악하였다. 분석 결과, 불 순물의 양이 많을수록, 입도가 작을수록 Color가 악화됨을 알 수 있다. 입도의 증가의 경우 설비 개 선이 필요하였기 때문에, 불순물 쪽을 집중하여 분석을 진행하기로 하였다.
전체 불순물이 증가하면 품질이 나빠지는 관계 를 보이기 때문에, 개별 불순물 중 Color와 상관성
주목할 것은 Color와 상관성이 큰 불순물들인 데, E와 F가 다른 불순물들에 비해 압도적으로 큰 상관성을 나타냈다. 일반적으로 E와 F는 생성 mechanism이 유사한 불순물들로, Color와의 상호 연관성이 나타날 수 있는 여지가 충분하였다.
2.1.2. 공정 모형화 및 개선 결과
공정변수와 도출된 불순물(E와 F)의 상관 관계 파악을 위하여, 3221개의 BPA 공정 온라인 변수 4년치(1 min sampling)를 수집, 분석하였다. 이렇 게 분석할 경우, 데이터의 개수는 약 67.7억 개가 된다.
1차적으로 각각의 공정 별로 불순물 E와 F를 Y로 하는 다변량 회귀 모형화(부분최소 자승법, Partial Least-Squares, PLS)[2]를 진행해 보았다. 그 결과는 Figure 10과 같다.
결정화 공정의 모형화 계수가 가장 큼에 착안하 여, 결정화 공정의 변수를 활용하여 주성분 분석 (PCA)을 진행하였다.
주성분 분석 결과, 결정화 투입 냉매인 C5 유량 의 최적화가 필요함을 분석하였다. 냉매의 투입량 으로 결정화의 과포화도를 제어하는데, 최적화되 지 못한 과포화도 제어는 불순물의 증가로 이어지 게 됨을 파악하였다.
이 결과에 기반하여, C5 유량 최적화를 진행하 였으며, 그 결과 Figure 11과 같이 평균 36%의 Color 개선을 확인할 수 있었다.
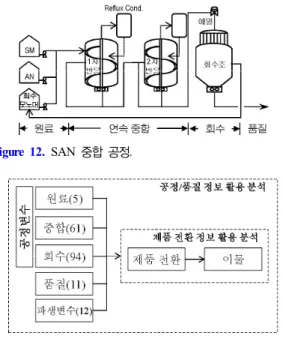
2.2. SAN 생산성 개선 사례
SAN (Styrene-Acrylonitrile)은 Figure 12와 같은 연속식 중합 반응으로 제조한다. Styrene Monomer (SM)와 AN (Acrylonitrile)을 Feed로 쓰며 두 번의 연속 중합 반응으로 1번 반응기에서 60%, 2번 반 응기에서 80%의 전환율로 생산한다. 미반응 모노 머들은 회수하여 Feed로 재투입한다.
Figure 9. Color의 핵심 불순물 파악.
Figure 10. 공정별 다변량 회귀 모형화 결과.
Figure 11. Color의 개선.
SAN은 고질적으로 이물이 문제 시 되었다. SAN 의 이물은 일반적으로 AN 간 공중합으로 생성된 물질이 회수조에서 탄화되면서 나타나는 것으로 알려져 있지만 , 실제 데이터로 확인한 바는 없었 다. SAN의 이물은 연속 운전이 증가하면 할수록 많아지는 경향이며, 생산이 힘들 정도로 많아지면 Shut-down하여 평균 5일의 cleaning 작업을 진행 한 후 재생산하므로, 연속 운전을 길게하면 할수 록 생산성이 높아지게 된다.
제품 전환이 많은 연속식 중합 반응인 SAN의 이물 영향 인자 파악 및 개선을 위하여 Figure 13 과 같은 개념으로 빅데이터 방법론을 적용하였다.
먼저 제품 전환이 많은 생산이므로 제품 전환 시의 이물 변동 관계를 분석하였으며 , 이 결과를 기반으로 원료, 중합, 회수의 160개 공정 변수와 23개의 품질 및 기타 파생변수(원료 비율 등)에서 이물 증가량이 촉진되는 조건 분석을 진행하였다.
2.2.1. 제품 전환 시의 이물 변동 분석 대상으로 한 SAN 공정은 11개의 제품을 생산 하고 있으며, 특정 제품군 전환 케이스에서 이물 급증이 확인되었다. Figure 14에서와 같이 A제품
군에서 B제품군으로 전환되면, 언제나 이물이 증 가하는 경향을 보이는데, A 제품군은 모두 AN 함 량이 높은 특징이, B 제품군은 AN 함량이 낮은 특징이 확인되었다.
이 결과에 기반하여, 4년 데이터 전체를 대상으 로 AN 함량이 높은 제품군에서 낮은 제품군으로 전환된 케이스들을 추출하여, 제품 전환 시의 이 물 증가량을 모두 데이터화하였으며, 이렇게 데이 터화한 세트를 대상으로 공정, 품질, 기타 파생변 수 183개를 대상으로 다변량 회귀 모형화를 진행 하였다.
2.2.2. 공정 모형화 및 개선 결과
공정, 품질 및 기타 파생변수들과 이물 악화 제 품 전환 케이스의 이물 증가량 간의 다변량 모형 화를 진행하였으며, 대상으로 한 변수의 개수는 모두 183개, 데이터 개수로는 4년, 1 min sampling 으로 약 680만 개에 해당하였다.
그 결과, Figure 15의 그래프와 같이 Reflux Condenser의 온도 변동이 이물 증가량의 핵심 인 자로 분석되었으며, 온도가 높을 때, 기상에서 AN 간의 공중합이 가속화되는 것으로 가설을 예상할 수 있었다.
이에 Figure 16과 같이 Reflux Condenser의 저 온 운전으로 결과를 검증하였으며, 방법은 반응기 에서 Reflux Condenser로의 Vent양을 최소화하여,
Figure 12. SAN 중합 공정.
Figure 13. SAN 빅데이터 분석의 개념.
Figure 14. 제품 전환 시의 이물 변동.
Figure 15. Reflux Condenser 온도의 영향.
온도를 낮게 유지/운전하는 것이었다.
이러한 개선안의 적용 결과, 14년 평균 41일 수 준이던 연속 운전 일수가 59일 수준으로 평균 18 일 증가 추세를 보이고 있으며, 연간 Shut-down 회수 3회 감소로, 약 4.7억의 생산성 개선 효과를 기대할 수 있을 것으로 예상한다.
2.3. NBR Mooney Viscosity 예측 모델 개발 NBR (Nitrile Butadiene Rubber) 공정은 Figure 18과 같이 BD (Butadiene)와 AN (Acrylonitrile)의 연속 중합 반응을 통해 얻어진다 . NBR의 핵심 품질 은 Mooney Viscosity (이하 MV)인데, 실시간으로 온라인 측정이 불가한 품질이고 , 원료의 투입부터 반응 이후 MV의 Sampling 및 측정까지 약 10 h 지 연이 발생하는 공정 특성 상 , 품질의 Spec-out이 발 생할 경우, 즉각적인 운전 대처가 어렵다.
이러한 문제를 해결하기 위하여, Figure 19와 같은 procedure를 통해 MV 예측 모델 개발을 진 행하였다. 73개 공정 변수 1년치, 1 min sampling 데이터 380만 개를 수집하여, MV에 대한 1차 회 귀 모형화를 진행하였으며, 이를 통해 8개의 핵심 변수를 추출하였다. 8개의 핵심 변수와 품질 변수 추가 모형화 , Stepwise 회귀 분석 및 교호 작용 분 석[3]을 추가 진행하여, 11개의 핵심 변수를 MV
영향 인자로 최종 판단하여, R
20.78 수준의 MV 예측 모델을 개발하였다.
개발한 MV 예측 모델을 활용하여, 실시간으로 MV를 예측한 결과는 Figure 20과 같다. 1개월의 생산 데이터에 대해 예측해 본 결과, R
20.71 수준 의 예측 성능을 나타내었으며, 향후 이 모델의 적 절한 업데이트 및 적용을 통해 NBR MV 품질의 실시간 관리가 가능할 것으로 예상한다.
2.4. Polycarbonate (PC) 에너지 절감 사례 PC는 BPA를 모노머로 포스겐과 중합 반응하여 생산하는 고기능 폴리머 제품으로, 포스겐 반응, 주 반응, 원심분리 공정을 통해 바다로 방류되어서는 안 되는 성분들의 처리가 필요하다. 이러한 성분들
Figure 16. 핵심 공정변수의 개선 방향.
Figure 17. 운전 일수 증가.
Figure 18. NBR 중합 공정.
Figure 19. MV 예측 모델의 개발.
Figure 20. MV 예측 모델의 검증.
의 처리를 위하여 Figure 21의 점선 테두리와 같은 Waste Water Treatment 공정이 운전된다.
이 폐수 처리 공정의 핵심은 정제탑의 최적 운 전이다. 하지만, 정제탑으로 유입되는 성분의 함량 을 정확히 알 수 없고, 성분을 알 수 있게 된다고 하더라도, Aspen plus와 같은 Tool로 모사가 쉽지 않은 문제가 있다. 현장에서는 이러한 문제 때문 에, 성분의 제거(정제탑 상부로 증류함)를 위한 과 다한 마진의 Steam을 투입하고 있었으며, 이로 인 한 에너지 절감이 요구되었기 때문에 빅데이터 분 석으로 문제에 접근하여 보았다.
일반적으로 성분의 변동에 따라 정제탑 Feed 온도가 변화하게 되므로, Feed 온도 변동에 영향 을 주는 인자를 Figure 22와 같은 방법으로 분석 하여 보았다. 공정변수와 가공변수를 합하여 255 개 변수(1년치, 1 min sampling, 1.3억 개)를 대상 으로 하였다.
여기서 각각의 성분 예측 값은 에너지 수지식을 이용하여 예측한 값을 사용하였다.
다변량 회귀 모형화 결과, Feed 온도를 변화시 키는 특정 성분이 확인되었으며, Feed 온도와 특 정 성분의 유입량 증가에 따른 폐수 비열 변동 간 의 관계는 Figure 23과 같다.
본 결과에 기반하여, 향후 폐수의 비열 변화 모니 터링을 통한 Steam 최적화가 가능할 것으로 판단되 며, 이를 통한 에너지 절감 효과를 기대하고 있다.
3. 결 론
본 논문에서는 국내 화학회사의 빅데이터를 활 용한 성과 창출 사례를 소개하였다.
BPA의 경우 1차적으로 상관분석 기술을 통해 Color 품질에 영향을 주는 매개 품질변수를 도출 하고, 2차적으로 다변량 회귀 모형화 기술을 활용 하여, 매개 품질변수를 설명하는 공정변수를 가려 낸 다음 정성, 정량적인 개선 방향을 결정하여 현 장 적용하였다. 공정변수 분석 시, 대상으로 한 변 수의 개수는 3221개로, 전체 데이터 개수로 하면 약 67.7억 개의 방대한 사이즈의 데이터였다.
SAN의 경우 이물 영향 인자를 찾기 위해, 이물 이 악화되는 제품 전환 케이스에 기반하여 데이터 세트를 새로 변환한 다음, 183개의 공정, 품질, 파 생변수를 대상으로 다변량 회귀 모형화를 하여, 이물 증가에 영향을 주는 핵심 변수를 도출, 개선 하였다.
NBR의 Mooney Viscosity는 실시간 모니터링 이 힘든 핵심 품질이며, 이 부분의 해소를 위하여 예측기반 최적화 모델을 개발 적용하여, 실시간 모니터링이 가능할 수 있도록 진행 중이다.
폐수 성분의 분리를 위하여 과도한 마진으로 운 전 중이던 PC의 폐수 처리 공정의 핵심 인자 파악 을 위하여 빅데이터 기술을 적용하였으며, 적용 결과, 핵심 성분의 도출이 가능하였고, 향후, 도출 된 인자의 모니터링을 통한 실시간 에너지 최적화 가능성을 검토 예정에 있다.
국내 화학회사에서는 소개한 기초소재사업 부
Figure 21. Polycarbonate 제조 공정.
Figure 22. PC 빅데이터 분석의 개념.
Figure 23. 폐수의 비열과 Feed 온도 상관성.
기대하고 있다 .
참 고 문 헌
1. Multi-and Megavariate Data Analysis, Basic Principles and Applications, 3rd ed., L. Eriksson
4. 빅데이터: 산업 지각변동의 진원, CEO Infor- mation 851호, 삼성경제연구소.
5. IT 시대의 대세는 ‘빅데이터’다, Humantech Vol. 1, 한국산업기술진흥원.
6. 빅데이터에 대한 기대와 현실, LG Business Insight 2012-10-17, LG경제연구원.
이 창 송
1996∼2002 경희대학교 화학공학과 (학사)
2002∼2004 포항공과대학교 화학공학과 (석사)
2004∼2005 포항공과대학교 연구원 2005∼현재 LG화학 중앙연구소 과장
이 호 경
1986∼1990 연세대학교 화학공학과(학사) 1990∼1995 포항공과대학교 화학공학과
(공학박사)
1996∼1998 Purdue University 박사 후 연구원
2000∼2001 포항공과대학교 화학공학과 연구교수
2001∼현재 LG화학 중앙연구소 연구위원