딥러닝에 의한 라이다 반사강도로부터 엄밀정사영상 생성
True Orthoimage Generation from
LiDAR Intensity Using Deep Learning
신영하1) · 형성웅2)·이동천3)
Shin, Young Ha· Hyung, Sung Woong· Lee, Dong-Cheon
Abstract
During last decades numerous studies generating orthoimage have been carried out. Traditional methods require exterior orientation parameters of aerial images and precise 3D object modeling data and DTM (Digital Terrain Model) to detect and recover occlusion areas. Furthermore, it is challenging task to automate the complicated process. In this paper, we proposed a new concept of true orthoimage generation using DL (Deep Learning). DL is rapidly used in wide range of fields. In particular, GAN (Generative Adversarial Network) is one of the DL models for various tasks in imaging processing and computer vision. The generator tries to produce results similar to the real images, while discriminator judges fake and real images until the results are satisfied. Such mutually adversarial mechanism improves quality of the results. Experiments were performed using GAN-based Pix2Pix model by utilizing IR (Infrared) orthoimages, intensity from LiDAR data provided by the German Society for Photogrammetry, Remote Sensing and Geoinformation (DGPF) through the ISPRS (International Society for Photogrammetry and Remote Sensing). Two approaches were implemented: (1) One- step training with intensity data and high resolution orthoimages, (2) Recursive training with intensity data and color-coded low resolution intensity images for progressive enhancement of the results. Two methods provided similar quality based on FID (Fréchet Inception Distance) measures. However, if quality of the input data is close to the target image, better results could be obtained by increasing epoch. This paper is an early experimental study for feasibility of DL-based true orthoimage generation and further improvement would be necessary.
Keywords : LiDAR Intensity, True Orthoimage, Deep Learning, GAN
초 록
정사영상 생성을 위한 많은 연구들이 진행되어 왔다. 기존의 방법은 정사영상을 제작할 경우, 폐색지역을 탐지하 고 복원하기 위해 항공영상의 외부표정요소와 정밀 3D 객체 모델링 데이터가 필요하며, 일련의 복잡한 과정을 자 동화하는 것은 어렵다. 본 논문에서는 기존의 방법에서 탈피하여 딥러닝(DL)을 이용하여 엄밀정사영상을 제작하 는 새로운 방법을 제안하였다. 딥러닝은 여러 분야에서 더욱 급속하게 활용되고 있으며, 최근 생성적 적대 신경망 (GAN)은 영상처리 및 컴퓨터비전 분야에서 많은 관심의 대상이다. GAN을 구성하는 생성망은 실제 영상과 유사 한 결과가 생성되도록 학습을 수행하고, 판별망은 생성망의 결과가 실제 영상으로 판단될 때까지 반복적으로 수행 한다. 본 논문에서 독일 사진측량, 원격탐사 및 공간정보학회(DGPF)가 구축하고 국제 사진측량 및 원격탐사학회 (ISPRS)가 제공하는 데이터 셋 중에서 라이다 반사강도 데이터와 적외선 정사영상을 GAN기반의 Pix2Pix 모델 학 습에 사용하여 엄밀정사영상을 생성하는 두 가지 방법을 제안하였다. 첫 번째 방법은 라이다 반사강도영상을 입력 하고 고해상도의 정사영상을 목적영상으로 사용하여 학습하는 방식이고, 두 번째 방법에서도 입력영상은 첫 번째 방법과 같이 라이다 반사강도영상이지만 목적영상은 라이다 점군집 데이터에 칼라를 지정한 저해상도의 영상을 이용하여 재귀적으로 학습하여 점진적으로 화질을 개선하는 방법이다. 두 가지 방법으로 생성된 정사영상을 FID (Fréchet Inception Distance)를 이용하여 정량적 수치로 비교하면 큰 차이는 없었지만, 입력영상과 목적영상의 품 질이 유사할수록, 학습 수행 시 epoch를 증가시키면 우수한 결과를 얻을 수 있었다. 본 논문은 딥러닝으로 엄밀정 사영상 생성 가능성을 확인하기 위한 초기단계의 실험적 연구로서 향후 보완 및 개선할 사항을 파악할 수 있었다.
핵심어 : 라이다 반사강도, 엄밀정사영상, 딥러닝, 생성적 적대 신경망 Received 2020. 07. 22, Revised 2020. 08. 13, Accepted 2020. 08. 26
1) Dept. of Environment, Energy & Geoinformatics, Undergraduate student, Sejong University, Korea (E-mail: [email protected]) 2) Dept. of Environment, Energy & Geoinformatics, Undergraduate student, Sejong University, Korea (E-mail: [email protected])
3) Corresponding Author, Member, Professor, Dept. of Environment, Energy & Geoinformatics, Sejong University, Korea (E-mail: [email protected])
https://doi.org/10.7848/ksgpc.2020.38.4.363 Original article
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://
1. 서 론
최근 인공신경망은 기존의 방법에서 탈피한 새로운 기술로 여러 분야에서 급속도로 활용되고 있다. 영상과 밀접한 관련 이 있는 신경망인 CNN (Convolutional Neural Network) 기반 의 GAN (Generative Adversarial Network)은 많은 관심을 받 고 있다. CNN은 LeCun (1989)에 의해 소개된 이후 딥러닝의 기 초가 마련되었다(Behnke, 2003; Simard et al., 2003). 더욱 고도 화된 GAN은 다양한 목적으로 활용되고 있다. GAN에 관련된 논문이 2018년에만 11,800여편이 발표되었다(Gui et al., 2020).
Mirza and Osindero (2014)가 소개한 학습 과정에서 잠재 변수(latent variable)를 추가한 CGAN (Conditional GAN), Radford et al. (2015)가 제시한 생성망(generator)과 판별 망(discriminator)에 CNN 구조를 도입한 DCGAN (Deep Convolutional GAN), Arjovsky et al. (2017)는 Wasserstein 거리 를 이용한 손실함수를 사용하는 WGAN (Wasserstein GAN) 등이 있다. Sajjadi et al. (2017)는 사실적인 질감 표현과 화질 개선을 위한 연구를 수행하였고, Demir and Unal (2018)은 영 상복원 방법을 소개하였다. Yarlagadda et al. (2018)는 항공영 상에서 불필요한 객체 탐지와 위치를 확인할 수 있는 방법 소 개하였으며, Bashmal et al. (2018)은 객체의 불변특성(invariant feature)을 적용한 학습에 의한 Siamese-GAN 모델을 연구하였 다. Wang et al. (2019)은 라이다 데이터의 분류를 수행하였고, Väänänen (2019)은 점군집 데이터에 발생하는 폐색지역 제거 방법을 연구하였다. Victoria et al. (2020)는 픽셀 단위의 객체 분류와 영상의 채색 방법을 제안하였다. Demiray et al. (2020) 는 DEM (Digital Elevation Model)의 해상도를 개선하기 위한 D-SRGAN(DEM-Super Resolution GAN) 모델을 제시하였고, Panagiotou et al. (2020)는 단일 영상을 이용한 GAN 기반의 DEM 생성 알고리즘을 소개하였다.
기존의 정사영상 생성에 관련된 연구로는 Amhar et al.
(1998)는 DBM (Digital Building Model)과 DTM (Digital Terrain Model)으로부터 ZI-buffer 기법으로 폐색지역을 탐지 하고 중복영상을 이용하여 복원하였다. Habib et al. (2007)은 DSM (Digital Surface Model)과 DBM에서 건물의 높이값을 추 출하여 정밀정사영상을 생성하기 위해 adaptive radial sweep 방 법과 spiral sweep 방법으로 폐색지역의 탐지 효율성을 증가시 켰다. Lee (2008)는 항공 LiDAR 데이터, 항공사진, GPS 데이터 등 다차원 공간정보를 활용한 실감정사영상 제작을 위하여 인 접 영상을 이용한 adjacent fill 기법을 사용하여 폐색지역을 보 정하는 방법을 제안하였다. Kim and Um (2015)은 항공영상으 로부터 고밀도의 점군집 데이터를 추출하여 DSM을 생성하고
정사영상을 생성하였다. Yoo and Lee (2016)는 객체기반의 정사 영상을 생성하기 위하여 건물의 상부구조물에서 발생하는 왜 곡 및 폐색지역까지도 탐색하고 복원하여 정밀정사영상을 생 성하는 방법을 제시하였는데 LoD (Level of Detail)가 높은 3차 원 건물 모델이나 매우 정밀한 외부표정 요소를 필요로 하는 등 의 여러 절차와 자료가 필요하다. Kim et al. (2017)은 정사영상 을 생성하는 소프트웨어들의 결과를 비교하여 수치표면모델이 아닌 3차원 메시를 이용한 정사영상이 기복변위를 효과적으로 제거함을 확인하였다.
그러므로 기존의 방법으로 엄밀정사영상을 생성하기 위해서 는 정확한 외부표정요소를 구하기 위하여 항공삼각측량을 수 행해야 하며 폐색지역을 탐지하기 위해서는 높은 LoD의 3차원 건물 모델 데이터가 요구된다. 또한, 중복 촬영된 여러 영상으로 부터 폐색지역을 복원할 수 있는 영상을 선택하여야 하는 여러 단계의 복잡한 과정이 요구되며, 이러한 일련의 과정을 자동화 하는 것은 어렵다. 본 논문은 기존의 방법과 다른 라이다 반사 강도(intensity)를 딥러닝의 학습 데이터로 사용하는 방안을 제 시하고자 한다. 연구를 위해 Isola et al. (2017)가 제안한 Pix2Pix 를 사용하여 반사강도 데이터로부터 엄밀정사영상을 생성하는 것을 두 가지 방법으로 진행하였다: (1) 반사강도영상과 목적영 상인 정사영상을 사용하여 딥러닝 모델을 한번 학습하는 방법, (2) 반사강도영상과 목적영상을 단계별로 서로 다르게 사용하 여 딥러닝 모델을 재귀적으로 학습하는 방법.
연구를 위해 ISPRS에서 제공하는 Vaihingen 지역의 라이다 데이터로부터 반사강도영상을 생성하고, 인공신경망에 의해 자 연 컬러영상을 재현하여 학습 데이터로 사용하여 최종적으로 연구를 진행하였다.
2. Pix2Pix 모델
2.1 Pix2Pix
GAN은 Goodfellow et al. (2014)에 의해 처음 개발되었으며, GAN의 구조는 결과를 생성하는 생성망과 이를 구별하는 판별 망으로 구성되어 있다. 임의의 데이터가 생성망에 입력되어 학 습을 수행한다. 판별망에서는 영상과 해당되는 라벨을 학습하 여 판별값을 도출한다. 본 연구에서 사용하는 Pix2Pix는 입력 영상과 목적영상이 한 쌍으로 입력되어 학습을 수행한다. 영상 의 변환은 입력영상과 목적영상 간의 관계를 형태나 특성을 이 용하여 학습하며, GAN이 소개되기 전, 기존의 영상변환이나 생성에 특화된 CNN 알고리즘들은 특정 목적이나 용도에만 적 용이 가능한 알고리즘을 가지고 설계되어 범용성이 적었다. 또 한, CNN의 손실함수의 경우 유클리드 거리를 최소화하는 방
향으로 진행하기 때문에 최종 결과가 정확하지 않았다. Isola et al. (2017)는 기존의 GAN을 개선한 방법인 Pix2Pix를 개발하 였으며, 목적에 따라 데이터 셋을 다양하게 구성하여 여러 형 태의 향상된 결과물의 생성이 가능하여 범용성이 확대되었다 (목표 영상을 통한 영상 합성, 윤곽선을 사용한 물체 복원, 영 상 채색 등).
Pix2Pix는 CGAN을 기반으로 설계되었다(Fig. 1 참조). CNN 의 특성적 구조를 적용하여 생성망과 판별망을 구성하였다.
Pix2Pix의 학습 성과를 판단하기 위한 오차함수는 Eqs. (1) to (3)과 같다(Isola et al., 2017). Pix2Pix는 over-shooting을 방지 하고 지역적 최소값이 0에 수렴하도록 가변적 학습률을 적용 하고 있다.
Fig. 1. CGAN architecture
(1) (2) (3) where, LcGAN is adversarial loss, which learns high-frequency content, LL1 is reconstruction loss, which learns low-frequency content, G is output of generator, D is output of discriminator, x is input image, y is target (real) image, z is random noise, λ is weight variable, and G* is total error.
2.2 U-Net 기반의 생성망
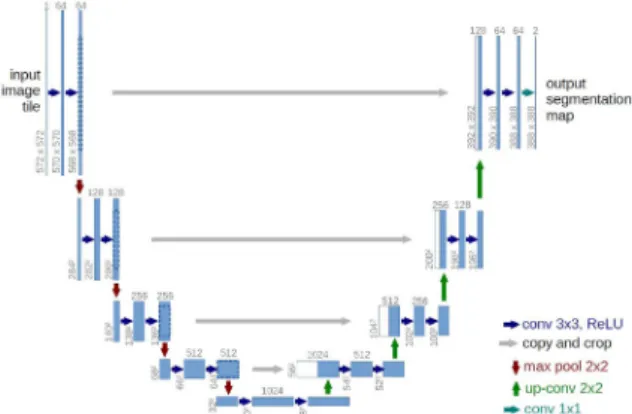
Pix2Pix의 생성망은 일반적인 GAN의 생성망의 구조와 다르 다. 입력과 출력이 영상이므로 크기가 축소되고 확대될 수 있 는 encoder-decoder 구조이다. 이러한 구조로 인하여 영상이 축 소될 경우 정보 손실이 발생한다. 그러므로 이를 방지하기 위해 U-Net 구조로 생성망이 설계되었다. U-Net은 저차원과 고차원 의 정보를 모두 사용하여 영상의 특징을 추출하기에 효율적인 구조이다(Fig. 2 참조). 이러한 특성은 외곽선 추출, 객체 검출 등 영상을 특정한 형태로 변화시키는데 유리하다.
Skip connection 기법을 적용하여 upsampling 수행 시, 이전 단계의 pooling layer와 연계된다(Shelhamer et al., 2017). 이와 같은 방식의 upsampling은 정보가 손실되기 전의 특징을 이용
할 수 있기 때문에 정보 손실이 감소되어 정확한 위치에 영상 이 생성된다.
Fig. 2. U-Net architecture (Ronneberger et al., 2015)
2.3 PatchGAN 기반의 판별망
PatchGAN은 Li and Wand (2016)가 제안한 MGANs (Markovian Generative Adversarial Networks)과 유사하지만 일반적인 GAN 과 다르게 PatchGAN은 영상을 여러 개의 패치로 나누어 각 부 분마다 학습을 수행하고 최종적으로 모든 값들의 평균을 출력 한다. 영상의 픽셀들 사이의 연관성은 거리에 반비례하므로 상 호연관성이 낮은 독립적인 패치 단위로 계산을 할 경우, 더욱 사실적 영상이 생성된다. 또한 전체 영상 대신에 패치 단위로 처리하기 때문에 파라미터의 개수가 감소되어 연산 속도가 빠 르고, 여러 종류의 영상에 적용할 수 있는 장점이 있다.
3. 실험 방법
3.1 실험 데이터
실험에 사용한 데이터는 ISPRS의 “도심지역 분류와 3D 건 물 재현을 위한 시범 프로젝트”(Rottensteiner et al, 2013)의 일 환으로 독일 Vaihingen 지역에 대해 구축한 공간정보 데이터 셋 이며, German Society for Photogrammetry, Remote Sensing &
Geoinformatics가 제공하고 있다(Cramer, 2010). Vaihingen 데 이터 셋에서 DL 모델의 학습(training)과 시험(test)을 위해 적 외선 정사영상(IR-R-G 밴드)과 라이다 반사강도 데이터를 사 용하였다. GSD (Ground Sample Distance) 0.09m의 정사영상 을 33개 지역으로 분할하여 제공하고 있으며, 라이다 데이터 의 GSD는 0.50m 이다. 사용 좌표계는 EPSG:32632 (WGS 84/
UTM zone 32N)로 구성되어 있다. Fig. 3은 33개 지역 중에서 본 연구에 사용한 4개 지역에 대한 영상과 반사강도 데이터를 보여주고 있다.
3.2 학습 데이터 생성
Vaihingen 데이터 셋은 적외선 정사영상을 제공하므로 Fig.
4의 인공신경망을 이용하여 동일한 해상도의 자연 컬러영상 (natural color image)으로 변환하였다. 일반적으로 적외선 영상 을 자연 컬러영상으로 변환하는 분광변환식을 이용하지만, 센 서마다 특정 컬러에 대한 민감도가 다르므로 분광변환식을 적 용하는 것은 한계가 있다. 본 연구에서는 Fig. 4와 같은 밴드조 합 원리를 적용한 인공신경망(ANN)을 구성하여 밴드별 조합 계수의 미세조정에 의해 더욱 자연스러운 컬러영상을 생성했 다(Hyung et al., 2020).
Fig. 4. ANN for IR to RGB image conversion
본 연구에서 제안하는 두 가지 학습 방법은 서론에서 설명한 바와 같으며, 방법 1은 영상 품질의 차이가 크게 나는 라이다 데 이터로부터 생성한 단일 밴드의 반사강도영상과 광학 영상으 로부터 생성된 RGB 밴드의 정사영상을 입력영상과 목적영상 으로 하여 학습하는 것이다. 방법 2는 방법 1의 영상 품질 차이 가 학습 결과 저하에 영향을 주는 것으로 판단하여 세 번의 단 계적 학습을 수행하여 단일 밴드인 반사강도영상에 먼저 색상 을 입히고 학습한다면 최종적으로 더 나은 결과영상을 보일 것 으로 예상하여 수행하였다.
학습에 필요한 반사강도영상은 IDW (Inverse Distance Weighting) 보간법으로 재배열(resampling)하여 생성하였 다. 자연 컬러로 변환된 영상과 공간 해상도는 동일하지만, 품 질이 낮다. 그 이유는 방사 해상도가 낮으며, 비행 방향과 라 이다 스캐닝 패턴에 의해 줄무늬 노이즈(stripe noise)가 발생 하지만 딥러닝 기법으로 화질을 개선할 수 있다(Shin et al., 2020). 또한, 방법 2의 재귀적 DL 모델의 학습을 위해 IDW 보간법으로 입력영상인 반사강도영상과 동일한 품질의 컬러 목적영상을 생성했다. Fig. 5(a)는 적외선 영상이 인공신경망 에 의해 변환된 자연컬러영상이다. Fig. 5(b)는 IDW 보간법 Area 1 Area 2 Area 3 Area 4
(a) IR image
(b) LiDAR intensity data Fig. 3. Datasets for experiments
Area 1 Area 2 Area 3 Area 4
을 적용하여 라이다 반사강도 데이터를 래스터화하여 생성 된 반사강도영상이고, Fig. 5(c)는 라이다 데이터를 자연 컬 러화하고 Fig. 5(b)와 동일한 방법의 보간법으로 래스터화한 영상이다.
라이다 데이터는 3차원 좌표와 반사강도에 대한 데이터는 제공하지만, 컬러 정보는 포함되지 않는다. 그러므로 점군집을 컬러화하기 위해 라이다 점군집의 분석과 처리를 위한 파이 썬 라이브러리인 Pdal의 filters.colorization 함수를 사용하여 적외선 영상으로부터 변환된 자연컬러영상을 라이다 데이터 에 각각의 점군집에 해당하는 RGB 값을 이식하였다. Fig. 5(b) 와 Fig. 5(c)에 사용한 IDW 보간법은 Laspy 파이썬 라이브러 리를 사용하여 포인트의 좌표를 추출하였고 QGIS를 이용하 여 래스터화했다.
(a) IR image to
RGB image (b) Rasterized intensity image from
point clouds
(c) Rasterized RGB image from point
clouds Fig. 5. Training data sets
Pix2Pix 모델에서 학습하기에 적합한 형태인 입력영상과 목 적영상을 학습 데이터로 사용하기 위해 한 쌍으로 구성하였다.
또한, 학습에 필요한 데이터의 수량을 증가시키기 위해 Fig. 6에 서 보여주는 것처럼 종횡방향으로 50% 중복하여 256X256 크 기의 영상으로 분할하였다. 학습을 위해 선정한 Vaihingen 데이 터는 4개 지역으로 구성하였고 분할한 총 1023장의 영상 중에 서 800장(75%)은 학습용, 223장(25%)은 시험용으로 구분하여 사용하였다(Table 1 참조).
(a) Partitioning
with 50% overlap (b) Partitioned
input image (c) Partitioned target image Fig. 6. Data partitioning
Table 1. Number of datasets before and after partitioning
Data Data
ratio Before
partition After partition
Training 75% 3 800
Test 25% 1 223
Total 100% 4 1023
3.3 딥러닝 모델 학습
Ubuntu 18.04 환경에서 Pytorch 라이브러리를 사용하여 Pix2Pix 모델 학습을 수행하였다. 본 연구에서 제안한 두 가 지 방법은 Fig. 7에서 보여주고 있다. 방법 1(Fig. 8 참조)은 반 사강도영상과 자연컬러영상을 사용하여 학습을 수행하고, 방 법 2(Fig. 9 참조)는 재귀적으로 학습(recursive training)에 기반 한 방법이다. 초기 단계에서는 반사강도영상과 래스터화한 자 연컬러영상을 학습시키고, 중간 단계에서는 초기 단계의 결과 영상과 래스터화한 자연컬러영상을 학습시킨다. 최종 단계에서 는 중간 단계의 결과영상과 적외선영상을 인공신경망을 사용 하여 변환한 자연컬러영상을 학습시켰다.
Table 2. Hyper-parameter setting
Hyper-parameter Value
Batch size 1
Initial learning rate 0.002 Learning rate policy Linear Number of epoch
/ Number of epoch decay
Method 1 – case 2 300 Method 1 – case 1 100 Method 2 – each step
딥러닝의 효율은 하이퍼 파라미터와 같은 학습 환경에 영향을 받으므로 본 연구에서는 Pix2Pix 모델이 제시한 초기 설정 값으 로 하이퍼 파라미터를 적용하였다. 모든 학습은 초기 학습률을 0.002로 설정하였고 number of epoch 이후의 학습에서 각 number of epoch decay 횟수만큼 0.002에서 0이 될 때까지 학습률을 선형 적으로 감소시키면서 진행한다. 방법 1은 세단계로 구성된 방법 2와 달리 하나의 단계로 학습하므로 하이퍼 파라미터의 epoch 횟 수를 같게 적용할 경우 누적 epoch에 차이가 생긴다. 그러므로 하 이퍼 파라미터의 number of epoch와 number of epoch decay를 방 법 1의 경우 2는 300씩으로 설정하고 방법 1의 경우 1과 방법 2의 각 단계에서는 100씩으로 설정한다. 그러므로 방법 1의 경우 2와 방법 2 전체 단계의 총 epoch 횟수는 600으로 같다.
4. 결과 및 분석
4.1 평가 측정
GAN을 평가하기 위해서는 정성적인 방법과 정량적인 방법 이 있다. 정성적인 방법에는 검사자가 보기에 사실처럼 보이는 지 확인하는 AMT (Amazon Mechanical Turk), 직접 시각적으 로 비교 분석하는 것 등이 있지만 검사자의 주관적인 판단이나 동기 부여에 영향을 받기 때문에 결과 공정성에 한계가 있다.
Salimans et al. (2016)는 IS (Inception Score)를 사용하여 GAN 에서 생성된 영상을 정량적으로 평가하는 방법을 제시하였으 며 생성 영상과 목적 영상을 모두 사용하여 평가하지 않고 학 습된 Inception-V3 모델에 생성 영상을 입력해 평가하므로 실 제 생성 영상의 품질을 측정하기에 한계가 있을 수 있는 단점 이 있지만, 영상 품질에 대한 정성적인 방법인 AMT의 결과 정 확도에 상관관계가 있음을 확인하였다. FID (Fréchet Inception Distance)는 IS의 단점을 보완하기 위해 생성 영상과 목적 영상 사이의 fréchet distance를 계산하는 Heusel et al. (2017)이 고안 한 방법이다. 따라서 본 논문에서는 GAN의 생성 영상을 보다 객관적으로 판단하기 위해 정량적으로 측정하는 방법인 FID 를 사용하여 평가한다.
4.1.1 FID 점수
FID(Eq. 4)는 목적 영상과 생성 영상의 가우시안 확률 분포간 의 거리 차이이므로 FID가 작을수록 품질이 좋은 영상 셋이다.
(4) where, ( )is feature average and covariance of target
image, ( )is feature average and covariance of generate image.
4.2 학습 및 시험 결과
4.2.1 방법별 학습 과정에 대한 예시
Fig. 8과 Fig. 9는 제안한 방법에 본 연구에서 수행한 사용되 는 학습 데이터인 입력영상과 목적영상 및 결과 영상의 예를 방 법별과 단계별로 보여주고 있다. Fig. 8은 방법 1의 구조로 흑백 의 반사강도영상과 자연컬러의 정사영상을 이용하여 학습하지 만 Fig. 8(a)은 방법 2의 단계별 epoch 횟수와 같게 200회로 학 습하였고 Fig. 8(b)은 단계별 누적 epoch 횟수와 같게 600회로 학습하는 예시이다.
Input: Intensity
image(IDW) Target:
Orthoimage(real) Output:
Generated image (a) First case (epoch 200)
Input: Intensity
image(IDW) Target:
Orthoimage(real) Output:
Generated image (b) Second case (epoch 600)
Fig. 8. Examples of training process from method 1 Fig. 7. Workflow of proposed approach
Input: Intensity
image(IDW) Target:
Orthoimage(IDW) Output:
Generated image 1 (a) First step (epoch 200)
Input:
Generated image 1 Target:
Orthoimage(IDW) Output:
Generated image 2 (b) Second step (epoch 200)
Input:
Generated image 2 Target:
Orthoimage(real) Output:
Generated image 3 (c) Third step (epoch 200)
Fig. 9. Examples of training process from method 2
Fig. 9는 방법 2의 구조로 흑백의 반사강도영상과 자연 컬 러 정사영상을 단계적으로 학습한다. Fig. 9(a)는 동일한 품질 의 반사강도영상과 RGB 정사영상을 이용해서 흑백 반사강도 영상에 색을 입히도록 영상을 생성하는 첫 번째 단계를 나타 낸다. Fig. 9(b)는 첫 번째 단계에서 생성된 영상을 입력 영상, RGB 정사영상을 목적 영상으로 이용해서 한 번 더 학습한다.
Fig. 9(c)는 최종적으로 두 번째 단계에서 생성된 영상을 입력 영상으로 한 후, 방법 1에서 사용한 RGB 정사영상을 목적 영 상으로 하고 결과 영상을 생성하는 예시이다.
4.2.2 FID 비교
Fig. 10. FID score graph
Fig. 10은 학습 데이터(800장)와 시험 데이터(223장)로부터 2 가지 방법을 경우와 단계별로 나눠 계산한 FID 점수의 평균을 그래프로 나타낸 것이다. FID 점수는 낮을수록 목적영상과 생 성영상의 차이가 없는 것을 나타내며 학습 방법별로 유의미한 정보를 얻을 수 있었다. 첫 번째로, 입력영상과 목적영상의 품질 차이에서 오는 결과영상의 생성 수준이다. 방법 1의 경우 1과 방 법 2의 단계 1의 학습 epoch 횟수는 200회로 같지만, 방법 1의 경우 1은 입력 영상과 목적영상간의 품질 차이가 크고 방법 2의 단계 1은 품질이 동일하다. 품질 차이에 따른 FID 점수 차이 는 학습 데이터로부터 생성한 영상은 약 75 정도로 수치 차이가 나고 시험 데이터로부터 생성한 영상은 약 48 정도로 수치 차이 가 난다. 동일한 품질의 영상 데이터를 사용하여 학습하면 더 향상된 수준의 영상을 생성할 수 있다. 또한, 영상 품질 차이에 따른 과적합(overfitting)의 모습을 보이는데, 같은 모델에서 입 력영상과 목적영상의 품질이 같으면 학습과 시험 데이터로부터 생성된 영상 간의 FID 점수의 차이가 약 105 정도이고 품질 차 이가 있으면 약 80 정도이다. 정리하면 Pix2Pix 모델에서 입력영 상과 목적영상의 품질이 같을수록 학습을 더 잘 수행한다는 것 이고 이에 따른 과적합의 문제가 생긴다.
두 번째로, 본 논문에서 제시하는 방법 2의 학습 과정은 단 일 밴드인 반사강도영상과 RGB 밴드인 정사영상 간의 품질 차 이가 학습 결과에 영향을 미친다고 판단하여 단계적으로 품질 을 향상 시키고 학습하였지만, 직접적으로 학습한 방법과 비교 하여 생성영상에 대한 FID 점수가 거의 같으며 차이가 없었다.
오히려 방법 1의 경우 1과 경우 2를 비교하면 epoch 횟수가 학습 수준에 지대한 영향을 보인다는 것을 확인할 수 있다.
4.2.3 시각적 비교
학습 결과(Fig. 11 참조)와 학습된 모델(trained model)에 시 험 영상을 입력한 결과(Fig. 12 참조)를 분석하였다. 엄밀정사영 상의 품질을 정량적으로 수치화하여 FID 점수를 이용하여 평 가하였지만, 한계가 있으므로 보다 세부적인 평가를 위해 결과 영상과 목적영상을 시각적으로 비교 분석하였다. 이를 위하여 학습 방법에 따른 결과를 건물, 도로 및 수목지역으로 구별하 여 선정하였다. 다만, 방법 1의 경우 1은 누적 epoch 횟수에 차 이가 있고 방법 2의 단계별 결과는 중간 과정이므로 시각적 비 교에서 생략했다.
학습 결과를 분석하면 건물의 경우 전체적인 건물의 형태와 세부 객체 측면에서 방법 1에 비해 방법 2의 결과가 다소 우수 하다고 판단된다. 도로와 수목지역은 두 가지 방법에 의한 결과 가 유사하다.
시험 데이터를 학습된 모델에 입력하여 생성된 결과 영상을
Fig. 12. Results of test data
Building Road Vegetation
Method 1
Method 2
Target Image
Building Road Vegetation
Method 1
Method 2
Target Image
Fig. 11. Results of training data
분석하였다. 딥러닝의 특성상 시험 데이터의 결과는 학습 결과 에 비해 생성 품질이 저하된다. Fig. 12에서 건물의 경우, 방법 1 과 2의 결과가 모두 목적영상과 유사하지 않다. 도로의 경우는 방법 1의 결과가 방법 2보다 다소 우수하다. 시험 데이터에 의한 결과는 재귀적 학습 과정에서 이전 단계의 결과가 미흡하면 저 하된 품질의 결과물이 생성되어 다음 단계의 모델 학습에 사용 되므로 최종 결과에 부정적인 영향을 줄 수 있다. 또한, 항공영 상의 촬영 시기와 라이다 데이터의 획득 시기가 서로 다른 경우 지형지물에 변화가 발생할 수 있으므로(예: 이동하는 차량, 건 축물 및 시설물의 시간적 변화) 결과에 영향을 주는 요인이 될 수 있다. 연구에 사용한 딥러닝 모델인 Pix2Pix는 모든 방법의 학습 데이터와 시험 데이터의 결과영상에서 라이다 반사강도영 상의 화질을 저하시키는 줄무늬 노이즈를 효과적으로 제거하 여 영상의 품질이 향상됨을 확인하였다.
(a) Generated orthoimage
mosaick (b) Real orthoimage Fig. 13. Comparison of generated orthoimage mosaick and
real orthoimage
Fig. 13은 FID 점수가 다른 방법에 비해 우수하게 나온 방법 1의 경우 2의 학습 데이터로부터 생성된 영상을 사용하여 모자 이크를 수행하고 원본 정사영상과 비교하였다. ISPRS에서 제공 되어 본 논문에서 목적영상으로 활용한 Fig. 13(b)은 정밀한 3 차원 형상을 사용하지 못해서 생긴 정사영상의 외곽선 오류를 눈에 띄게 확인할 수 있는데 Fig. 13(a)에서는 외곽선 오류가 많 이 삭제되었다. 이는 외곽선 오류가 있는 지역의 범위가 다른 지 역 보다 작기 때문에 무시되어 학습된 결과라고 판단된다. 하지 만 Fig. 13(a)은 딥러닝의 메모리 문제와 효율적인 학습을 위해 256X256영상으로 분할하여 학습하고 지역적으로 영상을 생성 한 후 모자이크하여 만든 영상이기 때문에 접합선이 생기고 접 합된 영상간의 불연속적인 형태를 보인다.
5. 결론 및 향후 연구
본 연구에서 제안한 딥러닝을 적용하여 라이다 반사강도영
상을 이용하여 엄밀정사영상을 생성하는 연구를 수행한 결과, 다음과 같은 결론을 얻을 수 있었다.
(1) 정사영상은 공간정보의 중요한 성과물이지만 기존의 방 법으로는 제작이 어렵고 복잡하다. 특히 고층 건물이 밀 집한 도심지역에서는 왜곡 보정과 폐색지역 복원을 위해 세밀도(LoD)가 높은 건물모델 데이터가 요구된다. 그러 므로 정사투영에 의해 획득된 라이다 데이터로부터 딥러 닝 기법으로 효율적으로 엄밀정사영상을 생성할 수 있는 방법을 제시하였다.
(2) 딥러닝은 많은 수량의 데이터와 학습 시간이 소요되고 지 역적 특성에 따라 서로 상이한 결과를 얻게 되므로 다양 한 학습 데이터와 라벨 데이터(목적영상)를 특화하고 학 습에 사용하여 사전학습 모델(pre-trained model)을 제공 하여 활용성과 범용성을 확대할 필요가 있다.
(3) Pix2Pix는 반사강도영상에 발생하는 노이즈를 효과적으 로 감소시키는 장점이 있으므로 고품질 영상으로 개선하 는 방법으로 사용 할 수 있다. 그러나 본 논문은 소량의 데 이터를 학습에 사용하였으므로 만족할 만한 성과를 얻 지 못했지만, 딥러닝에 의한 정밀정사영상 생성 가능성을 확인하였다.
(4) 본 연구에서 제시한 재귀적 학습은 방법론적으로는 우수 하지만 여러 조건이 만족될 때만 상승효과가 향상될 것으 로 사료된다. 이를 위해 다양한 학습 조건(epoch, batch 크 기 및 정규화 방법 등)에 따른 최적화가 필요하다. 또한, 학 습에 사용한 영상에는 다양한 객체(건물, 수목, 도로, 자 동차 등)이 혼재되어 학습 객체의 일관성이 결여되어 있 으므로 객체별로 구분하여 학습을 수행하면 결과가 향 상될 것으로 사료된다.
(5) 정사영상 제작에서 건물에 비해 도로와 수목은 기복 변 위나 폐색지역이 적게 나타나므로 추후 연구에서는 건물 객체에 대한 딥러닝을 수행하여 건물 외의 지역은 일반 광학영상으로, 건물 지역은 딥러닝을 통해 생성한 영상 을 조합한다면 효율적인 정사영상 생성이 가능할 것으로 사료된다.
(6) Pix2Pix 모델은 입력영상과 목적영상의 품질 차이가 학 습에 영향을 미친다는 것을 확인할 수 있다. 그러므로 라 이다 데이터 취득 시 점밀도를 광학영상 수준의 GSD만 큼 취득 할 수 있다면 더욱 향상된 결과를 얻을 수 있는 학습이 가능할 것으로 판단된다.
& Remote Sensing, Vol. 73, No. 1, pp. 25-36.
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Klambauer, G., and Hochreiter, S. (2017), GANs trained by a two time-scale update rule converge to a Nash equilibrium, arXiv:1706.08500v6.
Hyung, S., Shin, Y., and Lee, D.C. (2020), Artificial neural network for IR image to true color image conversion, Proceedings of Korean Society of Surveying, Geodesy, Photogrammetry &
Cartography-2020, 2-3 July, Seoul, Korea, pp. 212-217. (in Korean with English abstract)
Isola, P., Zhu, J.Y., Zhou, T., and Efros, A. (2017), Image-to- image translation with conditional adversarial networks, IEEE Conference on Computer Vision and Pattern Recognition-2017, 21-26 July, Honolulu, HI, USA, pp. 1125–1134.
Kim, E., Choi, H., and Park, J. (2017), Analysis of applicability of orthophoto using 3d mesh on aerial image with large file size, Journal of the Korean Society of Surveying, Geodesy, Photogrammetry and Cartography, Vol. 35, No. 3, pp. 155-166.
Kim, J. and Um, D. (2015), High quality ortho-image production using the high resolution DMC aerial image, Journal of the Korean Society of Surveying, Geodesy, Photogrammetry and Cartography, Vol. 33, No. 1, pp. 11-21.
LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W., and Jackel, L.D. (1989), Backpropagation applied to handwritten zip code recognition, Neural Computation, Vol.
4, No. 1, pp. 541-551.
Lee, H. (2008), Producing true orthophoto using multi- dimensional spatial information, Journal of the Korean Society of Surveying, Geodesy, Photogrammetry and Cartography, Vol. 26, No. 3, pp. 241-253.
Li, C. and Wand, M. (2016), Precomputed real-time texture synthesis with markovian generative adversarial networks, European Conference on Computer Vision-2016, 11-14 October, Amsterdam, The Netherlands, pp. 702-716.
Mirza, M. and Osindero, S. (2014), Conditional generative adversarial nets, arXiv:1411.1784.
Panagiotou, E., Chochlakis, G., Grammatikopoulos, L., and Charou, E. (2020), Generating elevation surface from a single RGB remotely sensed image using deep learning, Remote Sensing, Vol. 12, No. 12.
Radford, A., Metz, L., and Chintala, S. (2015), Unsupervised representation learning with deep convolutional generative
감사의 글
이 논문은 2018년도 정부(교육부)의 재원으로 한국 연구재단의 지원을 받아 수행된 기초연구사업임(No.
2018R1D1A1B07048732). The Vaihingen data set was provided by the German Society for Photogrammetry, Remote Sensing and Geoinformation (DGPF) [Cramer, 2010]: http://www.ifp.
uni-stuttgart.de/dgpf/DKEP-Allg.html.
References
Amhar, F., Jansa, J., and Ries, C. (1998), The generation of true orthophotos using a 3d building model in conjunction with a conventional DTM, International Archives of Photogrammetry and Remote Sensing, Vol. 32, pp. 16-22.
Arjovsky, M., Chintala, S., and Bottou, L. (2017), Wasserstein generative adversarial networks, International Conference on Machine Learning-2017, 6-11 August, Sydney, Australia, pp.
214-223.
Bashmal, L., Bazi, Y., AlHichri, H., AlRahhal, M., Ammour, N., and Alajlan, N. (2018), Siamese-GAN: Learning invariant representations for aerial vehicle image categorization, Remote Sensing, Vol. 10, No. 2, pp. 351.
Behnke, S. (2003), Hierarchical Neural Networks for Image Interpretation, Springer-Verlag, Berlin, Germany.
Cramer, M. (2010), The DGPF test on digital aerial camera evaluation – Overview and test design. Photogrammetrie, Fernerkundung, Geoinformation, Vol. 2, pp. 73–82.
Demir, U. and Unal, G. (2018), Patch-Based image inpainting with generative adversarial networks, arXiv:1803.07422v1.
Demiray, B., Sit, M., and Demir, I. (2020), D-SRGAN: DEM super-resolution with generative adversarial networks, arXiv:2004.04788v2.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde- Farley, D., Ozair, S., Courville, A., and Bengio, Y. (2014), Generative adversarial nets, Neural Information Processing Systems, pp. 2672-2680.
Gui, J., Sun, Z., Wen, Y., Tao, D., and Ye, J. (2020), A review on generative adversarial networks: algorithms, theory, and applications, arXiv:2001.06937v1.
Habib, A., Kim, E.M., and Kim, C.J. (2007), New methodologies for true orthophoto generation, Photogrammetric Engineering
adversarial networks, arXiv:1511.06434.
Ronneberger, O., Fischer, P., and Brox, T. (2015), U-Net:
Convolutional networks for biomedical image segmentation, Medical Image Computing and Computer-Assisted Intervention, pp. 234-241.
Rottensteiner, F., Sohn, G., Gerke, M., and Wegner, J. (2013), ISPRS test project on urban classification and 3D building reconstruction, http://www2.isprs.org/tl_files/isprs/wg34/docs/
ComplexScenes_revision_v4.pdf (last date accessed: 6 April 2018).
Sajjadi, M., Scholkopf, B., and Hirsch, M. (2017), Enhancenet:
Single image super-resolution through automated texture synthesis, The IEEE International Conference on Computer Vision-2017, 22-29 October, Venice, Italy, pp. 4501-4510.
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., and Chen, X. (2016), Improved Techniques for Training GANs, arXiv:1606.03498v1.
Shelhamer, E., Long, J., and Darrell, T. (2017), Fully convolutional networks for semantic segmentation, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 39, No. 4, pp.
640-651.
Simard, P., Steinkraus, D., and Platt, J. (2003), Best practices for convolutional neural networks applied to visual document analysis, International Conference on Document Analysis and Recognition-2003, 3-6 August, Edinburgh, Scotland, UK, pp.
958-963.
Väänänen, P. (2019), Removing 3D Point Cloud Occlusion Artifacts with Generative Adversarial Networks, PhD thesis, Department of Computer Science, University of Helsinki, Helsinki, Finland, 56p.
Wang, A., Li, Y., Jiang, K., Zhao, L., and Iwahori, Y. (2019), Lidar data classification algorithm based on generative adversarial network, IEEE International Geoscience and Remote Sensing Symposium, pp. 2487-2490.
Yarlagadda, S., Güera, D., Bestagini, P., Zhu, F., Tubaro, S., and Delp, E. (2018), Satellite image forgery detection and localization using GAN and one-class classifier, Electronic Imaging, Vol. 2018, No. 7, pp. 214-1–214-9.
Yoo, E. and Lee D.C. (2016), True orthoimage generation by mutual recovery of occlusion areas, GIScience & Remote Sensing, Vol. 53, No. 2, pp. 227-246.