1. Introduction
Information regarding land cover (LC) changes over time is essential for studying the functional and morpho-functional changes occurring in the global ecological, meteorological, and hydrological environments (Chen et al., 2015; Feddema et al., 2005;
Son and Kim, 2018).
Remote sensing has long been recognized as an effective tool for broad-scale LC mapping and as an effective tool for generating LC maps needed to understand human activity and the biogeographical diversity of the land surface (Chen et al., 2015; Zhang and Roy, 2017). As a result, a number of LC products, such as global-scale maps based on remote sensing data, have been developed with broad-scale resolution
Land Cover Classification Map of Northeast Asia Using GOCI Data
Sanghun Son
1)· Jinsoo Kim
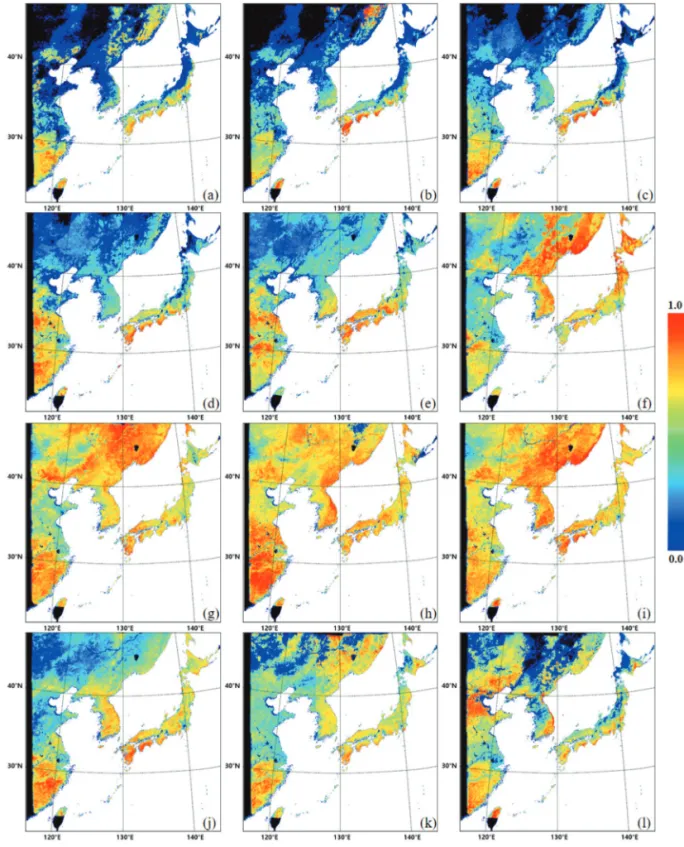
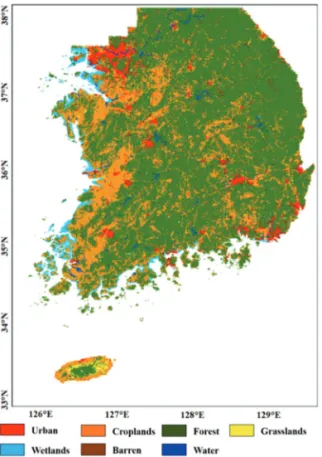
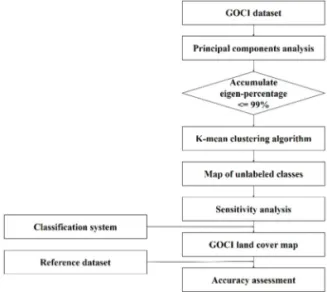
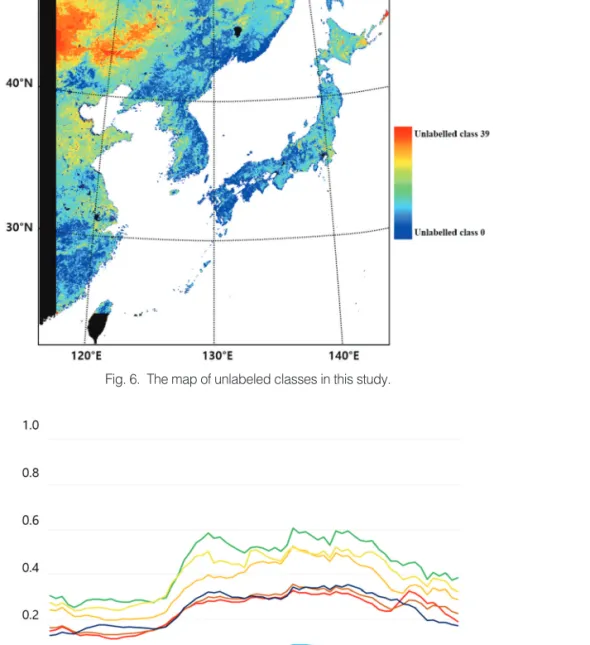
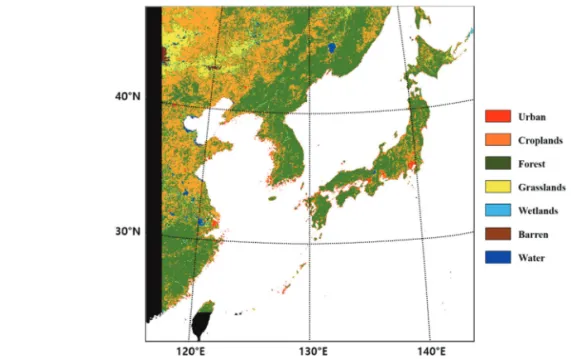
2)†Abstract: Land cover (LC) is an important factor in socioeconomic and environmental studies. According to various studies, a number of LC maps, including global land cover (GLC) datasets, are made using polar orbit satellite data. Due to the insufficiencies of reference datasets in Northeast Asia, several LC maps display discrepancies in that region. In this paper, we performed a feasibility assessment of LC mapping using Geostationary Ocean Color Imager (GOCI) data over Northeast Asia. To produce the LC map, the GOCI normalized difference vegetation index (NDVI) was used as an input dataset and a level-2 LC map of South Korea was used as a reference dataset to evaluate the LC map. In this paper, 7 LC types (urban, croplands, forest, grasslands, wetlands, barren, and water) were defined to reflect Northeast Asian LC. The LC map was produced via principal component analysis (PCA) with K-means clustering, and a sensitivity analysis was performed. The overall accuracy was calculated to be 77.94%. Furthermore, to assess the accuracy of the LC map not only in South Korea but also in Northeast Asia, 6 GLC datasets (IGBP, UMD, GLC2000, GlobCover2009, MCD12Q1, GlobeLand30) were used as comparison datasets. The accuracy scores for the 6 GLC datasets were calculated to be 59.41%, 56.82%, 60.97%, 51.71%, 70.24%, and 72.80%, respectively. Therefore, the first attempt to produce the LC map using geostationary satellite data is considered to be acceptable.
Key Words: Land cover, Feasibility, Principal component analysis, K-means clustering, Overall accuracy Korean Journal of Remote Sensing, Vol.35, No.1, 2019, pp.83~92
https://doi.org/10.7780/kjrs.2019.35.1.6 ISSN 1225-6161 ( Print )
ISSN 2287-9307 (Online)
Article
Received January 31, 2019; Revised February 11, 2019; Accepted February 12, 2019; Published online February 18, 2019
1)
Master Student, Division of Earth Environmental System Science, Pukyong National University
2)
Assistant Professor, Department of Spatial Information Engineering, Pukyong National University
†