논문 2012-49SD-8-10
고성능 H.264/AVC 디블로킹 필터를 위한
4-병렬 스케줄링 아키텍처
( A 4-parallel Scheduling Architecture for High-performance H.264/AVC
Deblocking Filter )
고 병 수
*, 공 진 흥
***( Byung Soo Ko and Jin-Hyeung Kong )
요 약 본 연구에서는 Quad FHD의 고해상도 동영상을 실시간 처리하는 고성능 H.264/AVC 디블로킹필터를 설계하였다. 연산처리 성능을 향상시키기 위해 라인에지필터 16개를 4개의 블록에지필터로 병렬 설계하였으며, 내부버퍼 크기와 연산 사이클을 줄이 기 위해 H.264/AVC 디블로킹 필터 순서를 4단 병렬 지그재그 스캔 순서로 스케줄링하였다. 그리고 블록에지필터 연산 간 1사 이클의 지연시간을 두어 데이터 충돌을 방지하고, 블록에지필터 간 내부버퍼를 인터리빙 버퍼로 구현하여 내부버퍼 크기를 줄 였다. 0.18um 공정에서 시뮬레이션한 결과, 최대 동작주파수가 90MHz이며, 게이트 수는 140.16 Kgates이다. 제안하는 H.264/AVC 디블로킹필터는 동작주파수 90MHz에서 Quad FHD급 동영상(3840×2160)을 초당 113.17프레임으로 실시간 처리가 가능한 결과이다. Abstract
In this paer, we proposed a parallel architecture of line & block edge filter for high-performance H.264/AVC deblocking filter for Quad Full High Definition(Quad FHD) video real time processing. To improve throughput, we designed 4-parallel block edge filter with 16 line edge filter. To reduce internal buffer size and processing cycle, we scheduled 4-parallel zig-zag scan order as deblocking filtering order. To avoid data conflicts we placed 1 delay cycle between block edge filtering. We implemented interleaving buffer, as internal buffer of block edge filter, to sharing buffer for reducing buffer size. The proposed architecture was simulated in 0.18um standard cell library. The maximum operation frequency is 108MHz. The gate count is 140.16Kgates. The proposed H.264/AVC deblocking filter can support Quad FHD at 113.17 frames per second by running at 90MHz.
Keywords : H.264/AVC, deblocking filter, block & edge filter, parallel architecture, zig-zag scan order
*
정회원, ** 평생회원, 광운대학교 컴퓨터공학과
(Department of Computer Engineering, Kwangwoon University) ※ 본 논문은 2010년도 광운대학교 교내학술연구비 지 원으로 수행되었고, 지식경제부 출연금으로 ETRI SW-SoC융합 R&BD센터에서 수행한 시스템반도체 설계인력양성사업의 연구결과이며, 지식경제부가 지원하는 멀티미디어 모바일 SoC 핵심기술개발사 업(10039173)을 통해 개발된 결과임을 밝힙니다. 접수일자: 2012년4월25일, 수정완료일: 2012년7월17일 Ⅰ. 서 론
현재 비디오 응용 기술은 Super Hi-Vision[1], Quad Full High Definition(Quad FHD) LCD(3840×2160)와 같이 Full HD(1920×1080)를 넘어선 초고해상도 영상의 실시간 처리를 요구하고 있다. 이러한 초고해상도의 비 디오 데이터를 방송, 통신을 통해 전송하기 위해서는 데이터 압축 성능이 높은 동영상 압축 기술이 필요하
며, 현존하는 비디오 코덱 중 H.264/AVC가 부호화효율 이 가장 뛰어난 것으로 평가받고 있다[2]. H.264/AVC 복호화 과정에서 블록현상을 제거하여 화질을 향상시키는 디블록킹필터는 복호화 복원 영상의 화질을 PSNR에서 평균 9%정도 개선시킨다[3]. 그러나 이러한 화질개선을 위한 디블로킹필터의 연산량은 복호 화기의 전체 연산량의 36∼43%를 차지한다[4]. 따라서 Full HD급 이상 고해상도 동영상을 실시간 복호화를 위해 디블로킹필터의 고속 아키텍처 구현에 대한 많은 연구가 진행 중이다[5~14]. 디블로킹필터의 고속 아키텍처 구현에 대한 연구들 은 경계 필터링의 연산을 병렬화하여 연산처리성능을 개선시키는 연구[9~14]와 경계 필터링의 연산순서를 최 적화하여 내부버퍼크기와 연산 사이클을 줄이는 연구 [5~14] 로 진행된다. H.264/AVC 표준 필터링 순서로 경계 필터링을 처리하는 연구[5]는 라인에지필터 1개로 수평 경계 필터링과 수직경계 필터링을 처리하였다. 필터링 할 때 마다 경계에 인접한 화소들을 외부메모리로부터 검색 및 저장하여 외부메모리 접근이 많다. 외부메모리 접근을 줄이기 위해 수직경계 필터링 된 매크로블록을 내부버퍼에 저장하여 수평경계 필터링 할 때 재사용하 는 연구[6]가 진행되었다. 그러나 매크로블록을 내부버퍼 에 저장하기 때문에 내부버퍼가 커지는 문제가 있다. 그래서 내부버퍼의 크기를 줄이기 위해 필터링하는 순 서를 매크로블록의 수직경계 필터링 후 수평경계 필터 링하던 것에서 4x4블록의 좌(左), 우(右), 상(上), 하(下) 경계 필터링하는 것으로 변경하였다[7~8]. 그 결과 경계 필터링 간 지연시간을 매크로블록 단위에서 블록단위로 줄였으며, 내부버퍼의 크기를 매크로 블록(4×4블록 16 개)에서 인접된 4×4블록 4개로 감소시켰다. 그러나 라 인에지필터 1개를 사용하는 연구들[5~8]은 매크로블록을 필터링하기 위한 연산 사이클이 길어 Full HD 영상을 실시간 처리하기 위해 100MHz이상의 고주파수를 필요 로 한다. 그래서 Full HD급 이상의 고해상도 동영상을 실시간 처리하고자 다수의 라인에지필터가 경계에 대한 필터 연산을 병렬 처리하는 연구가 진행되었다[9~14]. 라 인에지필터 2개를 수직 경계 필터링과 수평 경계 필터 링에 각각 할당하여 병렬 처리하는 연구[9]는 라인에지 필터 1개를 사용한 연구에 비해 매크로블록 당 연산 사 이클을 절반 이하로 감소시켰다. 그러나 수직경계 필터 링과 수평경계 필터링 간 데이터종속성(Dependency)으 로 인해 2사이클의 지연시간(Latency)이 발생하였다. 라인에지필터 2개가 4개의 4×4블록열 경계에 대해 홀 수블록열 경계와 짝수블록열 경계로 나누어 지그재그 스캔 순서로 처리하는 연구[10]는 경계필터링 간 지연시 간을 1사이클로 줄였다. 라인에지필터 8개를 수직 경계 필터링에 4개 할당하고 수평 경계필터링에 4개 할당한 연구[11]는 기존 수직 경계필터링과 수평 경계필터링에 병렬 처리하는 연구[9]와 필터 순서는 같지만 연산 성능 이 4배 증가하여 Full-HD 영상을 더 낮은 동작주파수 로 실시간 처리한다. 라인에지필터 16개를 수직 경계필 터링에 8개 할당하고 수평 경계필터링에 8개 할당한 연 구[12, 14]는 병행 처리 성능이 향상되어 Quad FHD 이상 의 고해상도를 실시간 처리한다. 더블-크로스 필터링 순서로 처리하는 연구[12]는 수직/수평경계 필터링에 대 한 데이터 종속성을 최소로 하여 지연시간을 줄여 연산 처리성능을 높였다. 그러나 필터링 과정에서 발생되는 중간 데이터가 많아 내부버퍼가 커지는 단점이 있다. 수직/수평 경계 필터링의 2단 병렬 순서로 처리하는 연 구[14]는 매크로블록을 상(上) 16×8블록과 하(下) 16×8블 록으로 나누어 수직에지필터(VF)와 수평에지필터(HF) 를 각각 할당하고 래스터 스캔순서로 필터링하였다. 그 러나 수평경계필터링이 상(上)블록이 처리된 후 하(下) 블록이 처리되어야 하는 데이터 종속성으로 인해 하 (下)블록의 에지필터의 동작이 지연된다. 따라서 병렬성 은 높으나, 처리성능의 향상에는 한계가 있다. 이와 같 이 라인에지필터 16개를 사용하여 병렬 고속화 시킨 연 구들[12, 14]은 데이터 종속성에 의한 지연시간, 제어의 복 잡도로 인해 Quad FHD 이상의 고해상도를 실시간 처 리하는 데 동작주파수가 높거나, 내부버퍼의 크기가 큰 한계를 갖는다. 본 연구에서는 Quad FHD영상을 실시간 처리하기 위해 라인에지필터 16개를 사용하여 4개의 블록 경계를 동시에 필터링하도록 처리성능을 향상시켰고, 4단 병렬 지그재그 스캔 순서로 스케줄링하여 수직/수평경계 필 터링에 대한 데이터 종속성을 최소로 하여 지연시간을 줄여 연산처리성능을 높였다. 그리고 홀수 블록열 경계 필터링과 짝수 블록열 경계 필터링의 지연시간이 다른 점을 이용하여 블록에지필터의 내부버퍼를 인터리빙 (Interleaving) 방식으로 공유하여 내부버퍼의 크기를 줄였다. 제안하는 디블로킹필터는 블록에지필터의 입력 버퍼, 블록에지필터, 내부버퍼로 구성된다. 지그재그 스
캔 필터링을 처리하기 위해 블록에지필터의 입력버퍼를 수직/수평 출력이 가능한 4×4픽셀 어레이 구조로 설계 하였으며, 경계에 인접한 2개의 4×4블록을 필터링하도 록 라인에지필터 4개를 묶어 블록에지필터로 구현하여 연산처리성능을 높였다. 그리고 마지막으로 내부버퍼를 2개의 블록에지필터가 하나의 버퍼를 인터리빙하도록 연결구조를 설계하여 내부버퍼의 크기를 줄였다. 본 논문 구성은 II장에서 디블로킹필터링 순서에 대 한 최적화 연구에 대해 비교 분석하여 4단 병렬 지그재 그 스캔 순서를 제안하고, III장에서 4단 병렬 디블로킹 필터의 구조와 동작에 대해 설명하며, IV장에서 본 연 구의 시뮬레이션 결과를 다른 연구와 비교하며, V장에 서는 결론으로 마무리하였다. Ⅱ. 디블로킹필터 순서 및 병렬 최적화 디블로킹필터의 고속 아키텍처 구현에 대한 연구들 은 그림 1과 같이 필터링 순서를 제안하였다. 그림 1에 서 블록경계에 표기된 기울어진 영문자(SF, RF, DZ, ZF, VF, HF)는 필터이름이고, 아래첨자로 표기된 숫 자는 병행 처리하는 필터번호, 그리고 위첨자로 표기된 숫자는 필터링 순서이다. 그림 1에서 (a)∼(d)는 블록에 지필터 1개가 사이클 당 1개 경계를 필터링하며, 매크 로블록 내 32개 경계를 필터링하는데 32사이클이 걸린 다. 표준 필터링 순서를 따르는 (a)의 연구[5]는 경계필 터(SF)가 필터링할 때 마다 외부메모리로부터 경계에 인접한 화소들을 검색하여 필터링하고 다시 저장한다. 따라서 내부버퍼는 없고, 외부메모리 접근이 많다. 래스 터 주사 순서로 필터링하는 (b)의 연구[6]는 경계 필터링 이 끝난 4×4 블록을 다음 경계 필터링 할 때 재사용하 여 외부메모리 접근을 줄였다. 그러나 수직경계 필터링 된 매크로블록(4×4 블록 16개)을 내부 버퍼에 저장하여 수평경계 필터링할 때 재사용하므로 내부버퍼 크기가 크다. 내부버퍼 크기를 줄이기 위해 (c)와 (d)는 필터링 순서를 매크로블록의 수직경계 필터링 후 수평경계 필 터링하던 것에서 4×4블록의 좌(左), 우(右), 상(上), 하 (下) 경계 필터링하는 것으로 변경하였다[7~8]. 이중 지 그재그 스캔 순서로 필터링하는 (c)의 연구[7]는 {B1, B2, B5, B6} 4개 4×4블록들을 경계필터(DZ)가 “Z”가 이중으로 겹쳐진 모습으로 필터링한다. (c)의 블록에지 스케줄링에 따르면 처음 21번째 필터링 사이클 동안 B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 SF 1 1 SF 12 SF 13 SF 1 4 SF 1 5 SF 16 SF 17 SF 1 8 SF 1 9 SF 110 SF 1 11 SF 112 SF 13 SF1 4 SF 15 SF 16 SF117 SF118 SF119 SF120 SF121 SF122 SF123 SF124 SF125 SF126 SF127 SF128 SF129 SF130 SF131 SF132 (a) 표준 필터링 순서[5]
(a) Standard filtering
order[5] B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 RF 11 RF 15 RF 1 9 RF 1 13 RF 12 RF 16 RF 110 RF 1 14 RF 13 RF 17 RF 111 RF 1 15 RF 14 RF 18 RF 112 RF 1 16 RF117 RF121 RF125 RF129 RF118 RF122 RF126 RF130 RF119 RF123 RF127 RF131 RF120 RF124 RF128 RF132 (b) 래스터 주사 순서[6]
(b) Raster scan order[6]
B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 DZ 11 DZ 12 DZ 117 DZ 118 DZ 13 DZ 14 DZ 119 DZ 120 DZ 17 DZ 18 DZ 123 DZ 124 DZ 111 DZ 112 DZ 127 DZ 128 DZ15 DZ19 DZ113 DZ115 DZ16 DZ110 DZ114 DZ116 DZ121 DZ125 DZ129 DZ131 DZ122 DZ126 DZ130 DZ132 (c) 이중 지그재그 스캔 순서[7]
(c) Double zig-zag scan
order[7] B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 ZF 11 ZF 19 ZF 117 ZF 125 ZF 12 ZF 110 ZF 118 ZF 126 ZF 14 ZF 112 ZF 120 ZF 128 ZF 16 ZF 114 ZF 122 ZF 130 ZF13 ZF15 ZF17 ZF18 ZF111 ZF113 ZF115 ZF116 ZF119 ZF121 ZF123 ZF124 ZF127 ZF129 ZF131 ZF132 (d) 지그재그 스캔 순서[8]
(d) Zig-zag scan order[8]
B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 VF 11 VF 15 VF 19 VF 113 VF 12 VF 16 VF 110 VF 114 VF 13 VF 17 VF 111 VF 115 VF 14 VF 18 VF 112 VF 116 HF13 HF14 HF15 HF16 HF17 HF18 HF19 HF110 HF111 HF112 HF113 HF114 HF115 HF116 HF117 HF118 (e) 수직/수평 경계 필터 링의 병렬 순서[9,11,13]
(e) Parallel order for Vertical/Horizontal Filtering[9,11,13] B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 ZF 11 ZF 22 ZF 19 ZF 210 ZF 12 ZF 23 ZF 110 ZF 211 ZF 14 ZF 25 ZF 112 ZF 213 ZF 16 ZF 27 ZF 114 ZF 215 ZF13 ZF15 ZF17 ZF18 ZF24 ZF26 ZF28 ZF29 ZF111 ZF113 ZF115 ZF116 ZF212 ZF214 ZF216 ZF217 (f) 2단 병렬 지그재그 스 캔 순서[10] (f) 2-parallel zig-zag scan orader[10] B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 VF 11 VF 21 VF 15 VF 25 VF 12 VF 22 VF 16 VF 26 VF 13 VF 23 VF 17 VF 27 VF 14 VF 24 VF 18 VF 28 HF14 HF24 HF16 HF26 HF15 HF25 HF17 HF27 HF18 HF28 HF110 HF210 HF19 HF29 HF111 HF211 (g) 더블-크로스 필터 순 서[12] (g) Double-cross processing order[12] B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 VF 11 VF 15 VF 26 VF 210 VF 12 VF 16 VF 27 VF 211 VF 13 VF 17 VF 28 VF 212 VF 14 VF 18 VF 29 VF 213 HF13 HF14 HF15 HF16 HF17 HF18 HF19 HF110 HF28 HF29 HF210 HF211 HF212 HF213 HF214 HF215 (h) 수직/수평 경계 필터 링의 2단 병렬 순서[14]
(h) 2-Parallel order for Vertical/Horizontal
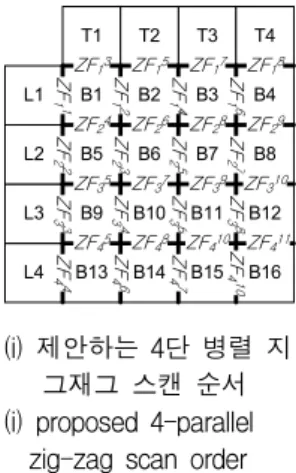
B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 ZF 11 ZF 22 ZF 33 ZF 44 ZF 12 ZF 23 ZF 34 ZF 46 ZF 14 ZF 25 ZF 36 ZF 47 ZF 16 ZF 27 ZF 38 ZF 410 ZF13 ZF15 ZF17 ZF18 ZF24 ZF26 ZF28 ZF29 ZF35 ZF37 ZF39 ZF310 ZF45 ZF48 ZF410 ZF411 (i) 제안하는 4단 병렬 지 그재그 스캔 순서 (i) proposed 4-parallel zig-zag scan order 그림 1. H.264/AVC 디블로킹필터 순서
Fig. 1. H.264/AVC deblocking filtering order.
{B5, B6, B7, B8, B9, B13} 6개 4×4블록들의 필터링 중 간 데이터들은 내부버퍼에 저장되어 있어야 한다. 따라 서 전체 32 필터링 사이클 동안 6개 이하의 블록 필터 링 중간 데이터들을 저장 및 검색할 수 있도록 내부버 퍼 관리가 요구된다. 지그재그 스캔 순서로 필터링하는 (d)의 연구[8]는 {B1, B2, B3, B4} 4개 4×4블록들을 경 계필터(ZF)가 지그재그 스캔 순서로 필터링한다. 같은 방법으로 (d)의 스케줄링을 실행할 때 처음 11번째 필 터링 사이클 동안 {B1, B2, B3, B4} 4개 4x4블록의 필 터링 중간 데이터들이 내부버퍼에 저장되어야 한다. 따 라서 (d)의 스케줄링에서 내부버퍼 관리가 필요한 최대 버퍼의 크기는 4개 4×4블록들이다. 이와 같이 (c)와 (d) 는 경계 필터링 간 지연시간을 매크로블록 단위에서 블 록단위로 줄여 내부버퍼 크기를 (b)에 비해 60%이상 줄일 수 있다. (e), (f)는 블록에지필터 2개가 사이클 당 2개 경계를 필터링하며, 매크로블록 내 32개 경계를 필 터링하는데 17∼18 필터링 사이클이 걸린다. 수직/수평 경계 필터링을 병렬 처리하는 (e)의 연구[9, 11, 13]는 수직 경계만 필터링하는 에지필터(VF)와 수평경계만 필터링 하는 에지필터(HF)가 각각 래스터 스캔순서로 필터링 한다. 수직경계 필터링이 끝난 후 수평경계 필터링이 가능한 데이터 종속성으로 인해 수직에지필터(VF)와 수평에지필터(HF) 간에는 2사이클의 지연시간이 발생 한다. 따라서 (e)의 연구는 32개 경계를 필터링 하는데 18 필터링 사이클이 걸린다. (e)의 스케줄링에서 모든 4×4블록의 상(上)수평경계 필터링과 하(下)수평경계 필 터링사이에는 4사이클의 지연시간이 발생한다. 수평경 계 필터링의 지연시간으로 인해 4개의 4×4 블록들의 필 터링 중간 데이터들은 내부버퍼에 저장되며, (e)의 스케 줄링에서 필요한 내부버퍼의 최대 크기는 4×4블록 4개 이다. 2단 병렬 지그재그 스캔 순서로 필터링하는 (f)의 연구[10]는 블록에지필터 ZF1와 블록에지필터 ZF2가 4×4블록들을 지그재그 스캔 순서로 필터링한다. 4×4블 록의 상(上)수평경계 필터링 후 하(下)수평경계 필터링 하는 데이터 종속성으로 의해 블록에지필터 ZF1와 블 록에지필터 ZF2사이에는 1사이클의 지연시간이 필요하 다. 따라서 (f)의 연구는 32개 경계를 필터링 하는데 17 필터링 사이클이 걸린다. (f)의 스케줄링에서 {B5, B6, B7, B8} 4개 4×4블록들의 상(上)수평경계 필터링과 하 (下)수평경계 필터링 사이에는 7 필터링 사이클의 지연 시간이 발생한다. 따라서 {B5, B6, B7, B8} 4개 4×4블록 들의 필터링 중간 데이터들은 지연시간동안 내부버퍼에 저장되며, 내부버퍼의 최대 크기는 4×4블록 4개이다. (g)∼(i)는 블록에지필터 4개가 사이클 당 4개 경계를 필터링하며, 매크로블록 내 32개 경계를 필터링하는데 11∼15 필터링 사이클이 걸린다. 더블-크로스 필터 순 서로 처리하는 (g)의 연구[12]는 첫 번째 수직에지필터 (VF1)이 {B1, B2, B3, B4} 4개 4×4블록들과 {B9, B10, B11, B12} 4개 4×4블록들을 래스터 스캔순서로 필터링 하고, 두 번째 수직에지필터(VF2)가 {B5, B6, B7, B8} 4 개 4×4블록들과 {B13, B14, B15, B16} 4개 4×4블록들을 래스터 스캔순서로 필터링한다. 그리고 수평에지필터 (HF1)이 {B1, B5, B9, B13} 4개 4×4블록들과 {B3, B7, B11, B15} 4개 4×4블록들을 “Z”형태로 필터링하고, 수 평에지필터(HF2)가 {B2, B6, B10, B14} 4개 4×4블록들 과 {B4, B8, B12, B16} 4개 4×4블록들을 “Z”형태로 필 터링한다. 그런데 (g)의 스케줄링에서 처음 6번째 필터 링 사이클 동안 {B3, B4, B7, B8} 4개 4×4블록들의 필 터링 중간 데이터들은 내부버퍼에 저장된다. 따라서 (g) 의 연구는 최대 4×4블록 4개를 내부버퍼에 저장해야 한 다. (h)의 연구[14]는 매크로블록을 상(上) 16×8블록과 하 (下) 16×8블록으로 나누어 수직에지필터(VF)와 수평에 지필터(HF)를 각각 할당하고 래스터 스캔순서로 필터 링하였다. 첫 번째 수직에지필터(VF2)가 B5 4×4블록의 상(上)수평경계 필터링을 처리해야 두 번째 수직에지필 터(VF2)는 하(下)수평경계 필터링을 처리하므로 두 에 지필터 간에는 5 필터링 사이클이라는 지연시간을 갖는 다. 그래서 (h)의 연구는 두 에지필터 간 지연시간으로 인해 32개 경계를 필터링하는데 15 필터링 사이클이 걸
Block Cycle 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 입력 데이터 L1 B1 L2 B2 B5 T1 B6 L3 B9 B3 B10 L4 B13 T2 B7 B14 B4 B11 T3 B8 B15 T4 B12 L5 B16 B17 L6 B17 B18 B19 L7 T5 B20 B21 T6 L8 B22 B23 T7 B24 T8 버 퍼 연 산 버 퍼 ZF1 P L1 |B1 T1 |B2 T2 |B3 T3 T4 L5 |B17 T5 T6 Q B1 B2 B1| B3 B2| B4 B3| |B4 B17 B18 B17| |B18 ZF2 P L2 |B5 B1- |B6 B2- |B7 B3- B4| L6 |B19 B17- B18-Q B5 B6 B5| B7 B6| B8 B7| |B8 B19 B20 B19| |B20 ZF3 P L3 |B9 B5- |B10 B6- |B11 B7- B8| L7 |B21 T7 T8 Q B9 B10 B9| B11 B10| B12 B11| |B12 B21 B22 B21| |B22 ZF4 P L4 |B13 B9- |B14 B10- |B15 B11- B12| L8 |B23 B21- B22-Q B13 B14 B13| B15 B14| B16 B15| |B16 B23 B24 B23| |B24 내부 버퍼 1 |B2 |B6 |B3 |B7 |B4 |B8 |B18 |B20 2 |B10 |B14 |B11 |B15 |B12 |B16 |B21 |B22 블록 경계 필터 연산 ZF1 X O O O O O O O O O O O X X X X ZF2 X X O O O O O O O O O O O X X X ZF3 X X X O O O O O O O O O O O X X ZF4 X X X X O O O O O O O O O O O X 출력 데이터 L1| L2| L3| T1_ L4| B1_ T2_ B5_ B2_ B9_ B13-T3_ B6_ T4_ B3_ B10_ B14- B4-B7_ L5| B8-B11_ B15-L6| T5_ L7| B12-B16| T6_ L8| B17_ B19-T7_ B18_ B20-T8_ B21_ B23-B22_
B24-|A: 좌수직 경계 필터링된 데이터, A|: 우수직 경계 필터링된 데이터, A-: 상수평 경계 필터링된 데이터, A_: 하수평 경계 필터링 데이터
표 2. 제안된 아키텍처에 따른 데이터 흐름 및 동작
Table 2. Data flow for proposed architecture.
디블로킹
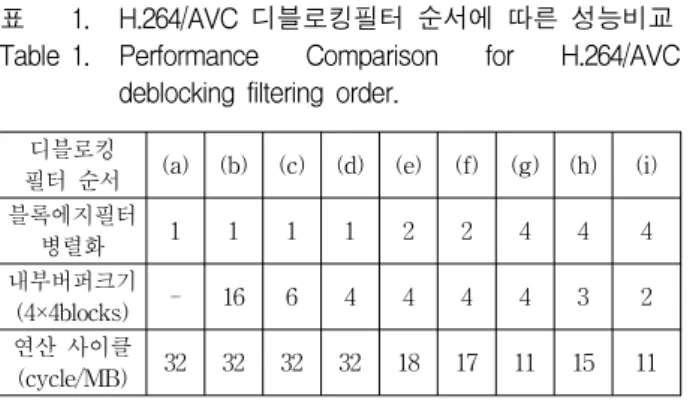
필터 순서 (a) (b) (c) (d) (e) (f) (g) (h) (i) 블록에지필터 병렬화 1 1 1 1 2 2 4 4 4 내부버퍼크기 (4×4blocks) - 16 6 4 4 4 4 3 2 연산 사이클 (cycle/MB) 32 32 32 32 18 17 11 15 11 표 1. H.264/AVC 디블로킹필터 순서에 따른 성능비교
Table 1. Performance Comparison for H.264/AVC
deblocking filtering order.
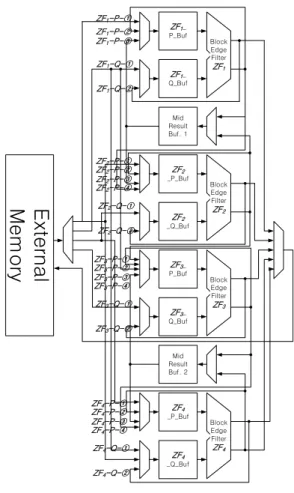
린다. 제안하는 4단 병렬 지그재그 스캔 순서 (i)는 지 그재그로 스캔하는 에지필터(ZF) 4개가 각각 1사이클 의 지연시간을 두고 필터링을 한다. 그래서 (i)의 연구 는 각 에지필터 간 지연시간으로 인해 32개 경계를 필 터링하는데 11 필터링 사이클이 걸린다. (i)의 스케줄링 에서 {B1, B5, B9, B13} 4×4블록을 제외한 나머지 블록 에서 수직경계 필터링 간 1 필터링 사이클 씩 지연시간 이 발생한다. 홀수 필터링 사이클에 첫 번째 에지필터 (ZF1)와 세 번째 에지필터(ZF3)가 내부버퍼에 1개 4×4 블록을 저장하고, 짝수 필터링 사이클에 두 번째 에지 필터(ZF2)와 네 번째 에지필터(ZF4)가 내부버퍼에 1개 4×4블록을 저장한다. 이를 이용하여 내부버퍼를 인터리 빙(Interleaving)하면 내부버퍼를 2개로 줄일 수 있다. 표 1은 그림 1의 디블로킹필터 순서에 따른 내부 버퍼 크기, 연산 사이클을 비교하고 있다. 디블로킹 필터 순 서에 따라 내부 버퍼의 크기가 작아지고 병렬화에 따라 연산 사이클도 줄었음을 확인할 수 있다. Ⅲ. H.264/AVC 디블로킹필터 아키텍처 설계 1. H.264/AVC 디블로킹필터의 구조 및 동작 제안하는 H.264/AVC 디블로킹필터는 그림 2의 순서 에 따라 휘도 화소와 색차 화소를 필터링한다. 블록에 지필터 ZF1∼ZF4가 P, Q버퍼에 4×4블록 데이터를 저 장하여 필터링하고, 지연시간이 발생하는 4×4블록들은 내부버퍼에 저장하였다가 필터링한다. 따라서 제안하는 H.264/AVC 디블로킹필터는 4개의 경계를 동시에 필터 링하는 4-병렬 블록에지필터, 순서에 따라 경계에 인접 한 4×4 블록을 선택, 저장하는 MUX와 P, Q버퍼, 지연 시간동안 4×4 블록을 저장하는 내부버퍼로 그림 3과 같 이 구성된다. 그리고 그림 2의 순서에 따라 4×4블록들
B13 B14 B15 B16 B9 B10 B11 B12 B7 B8 B3 B4 T3 T4 L4 L3 B5 B6 B1 B2 L2 L1 T1 T2 ZF 1 1 ZF 2 2 ZF 3 3 ZF 4 4 ZF 1 2 ZF 2 3 ZF 3 4 ZF 4 6 ZF 1 4 ZF 2 5 ZF 3 6 ZF 4 7 ZF 1 6 ZF 2 7 ZF 3 8 ZF 4 10 ZF13 ZF15 ZF17 ZF18 ZF24 ZF26 ZF28 ZF29 ZF35 ZF37 ZF39 ZF310 ZF45 ZF48 ZF410 ZF411 B19 B20 B17 B18 T5 T6 L6 L5 ZF 1 9 ZF 2 10 ZF 1 10 ZF 2 11 ZF111 ZF112 ZF212 ZF213 B23 B24 B21 B22 T7 T8 L8 L7 ZF 3 11 ZF 4 12 ZF 3 12 ZF 4 13 ZF313 ZF314 ZF414 ZF415 그림 2. 제안하는 H.264/AVC 디블로킹필터 순서
Fig. 2. Proposed H.264/AVC deblocking filtering order.
을 내부버퍼에 표 2와 같이 저장하고 필터링한다. 먼저 첫 번째 사이클에 외부메모리로부터 입력된 “L1”블록과 “B1”블록을 블록에지필터 ZF1의 P, Q버퍼에 각각 저장 하고, 다음 사이클에 수직경계 필터링한다. 따라서 블록 에지필터 ZF1의 P, Q 버퍼 MUX는 입력으로 ZF1 -P-①과 ZF1-Q-①을 선택하여 블록에지필터 ZF1의 P, Q 버퍼에 “L1”, “B1”블록을 저장한다. 두 번째 사이클에는 블록에지필터 ZF1가 “L1”, “B1”블록을 수직경계 필터 링한다. 따라서 우수직 경계필터링된 “L1|”블록은 외부 메모리로 출력되고, 좌수직 경계필터링된 “|B1”블록은 블록에지필터 ZF1의 P버퍼에 저장된다. 외부메모리로 부터 입력된 “B2”블록은 블록에지필터 ZF1의 Q버퍼에 저장된다. 따라서 블록에지필터 ZF1의 P, Q버퍼 MUX 는 입력으로 ZF1-P-②, ZF1-Q-①을 선택한다. 두 번 째 사이클에 블록에지필터 ZF2는 외부메모리로부터 입 력된 “L2”, “B5”블록을 P, Q버퍼에 저장한다. 따라서 블록에지필터 ZF2의 P, Q버퍼 MUX는 입력으로 ZF1-P-①, ZF1-Q-①을 선택한다. 세 번째 사이클에는 블록에지필터 ZF1, ZF2가 수직경계 필터링한다. 그리고 블록에지필터 ZF1에서 우수직 경계 필터링된 “B1|”블 록은 블록에지필터 ZF1의 Q버퍼에 저장되고, 좌수직 경계 필터링된 “|B2”블록은 내부버퍼에 저장된다. 그리 고 외부메모리로부터 입력된 “T1”블록을 블록에지필터 ZF1의 P버퍼에 저장한다. 따라서 블록에지필터 ZF1의 P, Q버퍼 MUX는 입력으로 ZF1-P-①, ZF1-Q-②를 선택한다. 블록에지필터 ZF2에서 우수직 경계 필터링된 “L2|”블록은 외부메모리로 출력되고, 좌수직 경계 필터 링된 “|B5”블록은 블록에지필터 ZF2의 P버퍼에 저장된 다. 그리고 외부메모리로부터 입력된 “B6”블록은 블록 에지필터 ZF2의 Q버퍼에 저장된다. 따라서 블록에지필 터 ZF2의 P, Q버퍼 MUX는 입력으로 ZF2-P-②, ZF2-Q-①을 선택한다. 두 번째 사이클에 블록에지필터 ZF1_ Q_Buf ZF1_ P_Buf Block Edge Filter ZF1 ZF2 _Q_Buf ZF2 _P_Buf Block Edge Filter ZF2 Mid Result Buf. 1 ZF3_ Q_Buf ZF3_ P_Buf Block Edge Filter ZF3 ZF4 _Q_Buf ZF4 _P_Buf Block Edge Filter ZF4 Mid Result Buf. 2 ZF1-P-① ZF1-Q-① ZF1-P-② ZF1-P-③ ZF1-Q-② ZF2-P-① ZF2-P-② ZF2-P-③ ZF2-P-④
External
Me
m
o
ry
ZF2-Q-① ZF2-Q-② ZF3-P-① ZF3-P-② ZF3-P-③ ZF3-P-④ ZF3-Q-① ZF3-Q-② ZF4-P-① ZF4-P-② ZF4-P-③ ZF4-P-④ ZF4-Q-① ZF4-Q-② 그림 3. H.264/AVC 디블로킹필터 구조Fig. 3. H.264/AVC Deblocking Filter Architecture.
ZF3는 외부메모리로부터 입력된 “L3”, “B9”블록을 P, Q버퍼에 저장한다. 따라서 블록에지필터 ZF3의 P, Q버 퍼 MUX는 입력으로 ZF3-P-①, ZF3-Q-①을 선택한 다. 네 번째 사이클에 블록에지필터 ZF1는 수평경계 필 터링하고, 블록에지필터 ZF2, ZF3는 수직경계 필터링을 한다. 따라서 하수직필터링된 “T1_”블록은 외부메모리 로 저장되고, 상수직필터링된 “B1-”블록은 블록에지필 터 ZF2의 P버퍼에 저장된다. 그리고 좌수직필터링된 “|B2”블록과 외부메모리로부터 입력된 “B3”블록은 블록 에지필터 ZF1의 P, Q버퍼에 저장된다. 따라서 블록에 지필터 ZF1의 P, Q버퍼 MUX는 입력으로 ZF1-P-③, ZF1-Q-①을 선택한다. 블록에지필터 ZF2에서 좌수직 경계 필터링된 “B5|”블록은 블록에지필터 ZF2의 Q버퍼 에 저장되고, 우수직 경계 필터링된 “|B6”블록은 내부버 퍼에 저장된다. 앞서 상수평 경계 필터링 “B1-”는 블록 에지필터 ZF2의 P버퍼에 저장되기 때문에, 블록에지필 터 ZF2의 P, Q버퍼 MUX는 입력으로 ZF2-P-④, ZF2-Q-②를 선택한다. 그리고 네 번째 사이클에 블록
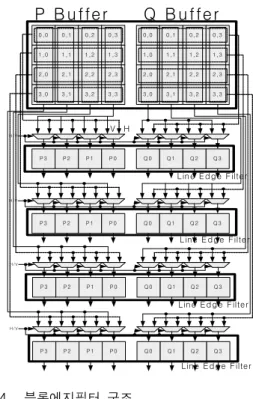
에지필터 ZF4는 외부메모리로부터 입력된 “L4”, “B13” 블록을 P, Q버퍼에 저장한다. 따라서 블록에지필터 ZF4 의 P, Q버퍼 MUX는 입력으로 ZF4-P-①, ZF4-Q-① 을 선택한다. 이와 같이 블록에지필터 ZF1, ZF2, ZF3, ZF4는 구조가 비슷하며, 제어 또한 비슷하다. 다만 블 록에지필터 간 차이점은 상수평 경계필터링한 블록을 하수평 경계 필터링하기 위한 데이터패스가 블록에지필 터 ZF2, ZF3, ZF4에 존재하는 것이다. 2. 에지필터의 구조 및 동작 그림 4와 같이 4-병렬 라인에지필터와 수평/수직 입 력 MUX로 블록에지필터를 구성하여 경계에 인접한 4×4블록의 수직 경계 필터링 또는 수평 경계 필터링을 처리하도록 설계하였다. 그리고 수직 경계 필터링을 위 해 P버퍼와 Q버퍼의 {(0,0)∼(0,3), (1,0)∼(1,3), (2,0)∼ (2,3), (3,0)∼(3,3)} 출력부와 라인에지필터의 {P3∼P0, Q3∼Q0} 입력 MUX를 연결하고, 수평 경계 필터링을 위해 P버퍼와 Q버퍼의 {(0,0)∼(3,0), (0,1)∼(3,1), (0,2) ∼(3,2), (3,0)∼(3,3)}출력부와 라인에지필터의 {P3∼P0, Q3∼Q0} 입력 MUX를 연결하였다. 그리고 라인에지 필터의 입력 MUX 선택에 따라 수직방향과 수평 방향 의 데이터 추출이 가능하도록 하였다. 0 ,0 0 ,1 0,2 0,3 1 ,0 1 ,1 1,2 1,3 2 ,0 2 ,1 2,2 2,3 3 ,0 3 ,1 3,2 3,3 0,0 0 ,1 0 ,2 0,3 1,0 1 ,1 1 ,2 1,3 2,0 2 ,1 2 ,2 2,3 3,0 3 ,1 3 ,2 3,3 P 3 P 2 P 1 P 0 Q 0 Q 1 Q 2 Q 3 H /V P 3 P 2 P 1 P 0 Q 0 Q 1 Q 2 Q 3 H /V P 3 P2 P 1 P0 Q 0 Q 1 Q 2 Q 3 H /V P 3 P2 P 1 P0 Q 0 Q 1 Q 2 Q 3 H /V P B uffer Q B uffer L ine E d g e F ilter Line E dg e Filter L ine E d g e F ilter Line E d g e Filter H V 그림 4. 블록에지필터 구조
Fig. 4. Block Edge Filter Architecture.
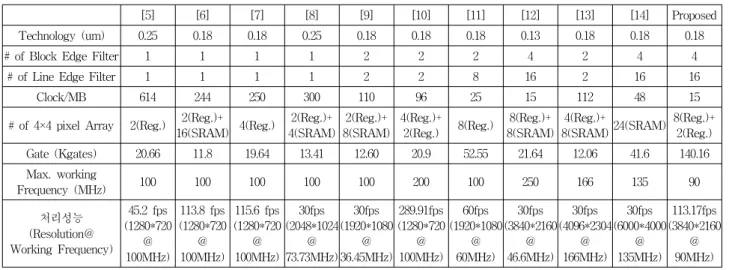
Ⅳ. 실험 및 고찰 제안된 H.264/AVC 디블로킹필터를 0.18um공정에서 시뮬레이션하여 표 3에 기존 연구와 비교하였다. 데이 터 처리성능(Throughput)을 라인에지필터의 병렬성에 따라 비교하면, 라인에지필터 1개가 사용된 연구[5~8]는 매크로블록 1개를 필터링하는데 최소 244사이클이 필요 하다. 라인에지필터 2개가 병렬 처리하는 연구는 매크 로블록 1개를 필터링하는데 최소 96사이클이 소요되며, 라인에지필터 8개가 병렬 처리하는 연구[11]는 매크로블 록 1개를 필터링하는데 25사이클이 소요된다. 라인에지 필터 16개를 사용하는 연구들은 처리하는 순서에 따라 매크로블록 1개를 필터링하는데 15사이클[12], 48사이클 [14]이 걸리며, 제안하는 구조에서는 15사이클이 소요된 다. H.264/AVC 디블로킹필터의 연산 및 내부버퍼는 SRAM과 레지스터로 나뉘어 구현된다. 표준 필터링 순 서로 처리하는 연구[5]는 재사용 없이 연산버퍼만 필요 하며, 4×4블록데이터 2개를 저장하는 레지스터가 사용 된다. 래스터 주사 순서로 처리하는 연구[6]는 연산버퍼 가 없다. 다만 이전 경계 필터링에 사용된 데이터를 재 사용하기 위해 4×4블록데이터 1개를 저장하는 레지스 터가 사용되고, 수평/수직 데이터 변환을 위한 버퍼로 4×4블록데이터 1개를 저장하는 레지스터가 사용되었다. 그리고 내부버퍼로 4×4 블록 데이터 16개를 저장하는 SRAM이 사용되었다. 이중 지그재그 스캔 순서로 처리 하는 연구[7]는 연산버퍼로 4×4블록데이터 2개를 저장 하는 레지스터가 사용되고, 내부버퍼로 4×4블록데이터 2개를 저장하는 레지스터가 사용되었다. 지그재그 스캔 순서 처리하는 연구[8]는 연산버퍼로 4×4블록데이터 2개 를 저장하는 레지스터가 사용되고, 내부버퍼로 4×4블록 데이터 4개를 저장하는 SRAM이 사용되었다. 수직/수 평 경계필터링을 병렬로 나누어 처리하는 연구[9]는 연 산버퍼가 없다. 다만 수직/수평 정렬하는 버퍼로 4×4블 록데이터 2개를 저장하는 레지스터가 사용되고, 내부버 퍼로 4×4블록데이터 8개를 저장하는 SRAM이 사용되 었다. 2단 병렬 지그재그 스캔순서로 처리하는 연구[10] 는 블록에지필터 2개를 병렬처리하기 위해 연산버퍼로 4×4블록데이터 4개를 저장하는 레지스터가 사용되었다. 그리고 내부버퍼로 4×4블록데이터 2개를 저장하는 레 지스터가 사용되었다. 수직/수평 경계필터링을 병렬로 나누어 처리하는 연구[11]는 연산버퍼로 4×4블록데이터
[5] [6] [7] [8] [9] [10] [11] [12] [13] [14] Proposed Technology (um) 0.25 0.18 0.18 0.25 0.18 0.18 0.18 0.13 0.18 0.18 0.18
# of Block Edge Filter 1 1 1 1 2 2 2 4 2 4 4
# of Line Edge Filter 1 1 1 1 2 2 8 16 2 16 16
Clock/MB 614 244 250 300 110 96 25 15 112 48 15
# of 4×4 pixel Array 2(Reg.) 2(Reg.)+
16(SRAM) 4(Reg.) 2(Reg.)+ 4(SRAM) 2(Reg.)+ 8(SRAM) 4(Reg.)+ 2(Reg.) 8(Reg.) 8(Reg.)+ 8(SRAM) 4(Reg.)+ 8(SRAM)24(SRAM) 8(Reg.)+ 2(Reg.) Gate (Kgates) 20.66 11.8 19.64 13.41 12.60 20.9 52.55 21.64 12.06 41.6 140.16 Max. working Frequency (MHz) 100 100 100 100 100 200 100 250 166 135 90 처리성능 (Resolution@ Working Frequency) 45.2 fps (1280*720 @ 100MHz) 113.8 fps (1280*720 @ 100MHz) 115.6 fps (1280*720 @ 100MHz) 30fps (2048*1024 @ 73.73MHz) 30fps (1920*1080 @ 36.45MHz) 289.91fps (1280*720 @ 100MHz) 60fps (1920*1080 @ 60MHz) 30fps (3840*2160 @ 46.6MHz) 30fps (4096*2304 @ 166MHz) 30fps (6000*4000 @ 135MHz) 113.17fps (3840*2160 @ 90MHz) 표 3. 기존 디블로킹필터 성능비교
Table 3. Performance comparison for Deblocking Filter.
3개를 저장하는 레지스터가 사용되고, 내부버퍼로 4×4 블록데이터 5개를 저장하는 레지스터가 사용된다. 더블 -크로스 필터 순서로 처리하는 연구[12]는 연산버퍼로 4×4블록데이터 8개를 저장하는 레지스터가 사용되고, 내부버퍼로 4×4블록데이터 8개를 저장하는 SRAM이 사용되었다. 수직/수평 경계필터링을 병렬로 나누어 처 리하는 연구[13]는 연산버퍼는 없고, 수직/수평 정렬하는 버퍼로 4×4블록데이터 2개를 저장하는 레지스터가 사 용되었다. 그리고 내부버퍼로 4×4블록데이터 8개를 저 장하는 SRAM과 4×4블록데이터 2개를 저장하는 레지 스터가 사용되었다. 수직/수평 경계필터링을 2단 병렬 순서로 처리하는 연구[14]는 연산버퍼는 없고, 수직/수평 정렬하는 버퍼로 4×4블록데이터 4개를 저장하는 레지 스터가 사용되었다. 그리고 내부버퍼로 4×4블록데이터 8개를 저장하는 SRAM이 사용되었다. 제안하는 구조에 서는 연산버퍼로 4×4블록데이터 8개를 저장하는 레지 스터가 사용되었으며, 내부버퍼로 4×4블록데이터 2개를 저장하는 레지스터가 사용되었다. 즉 본 연구는 연산병 렬화로 연산버퍼의 개수는 늘었지만, 내부버퍼를 인터 리빙 버퍼로 구현하여 버퍼 크기가 작다. 각 연구들의 게이트 수를 비교하면, 라인에지필터의 개수가 1∼2개 [5~10]일 때에는 20Kgates이내로 작다. 라인에지필터가 8 개[11]로 늘어나면 게이트 수도 52.55Kgates로 증가하며, 라인에지필터가 16개인 기존 연구의 게이트 수는 21.6Kgates[12]과 41.6Kgates[14]이다. 이와 같은 결과는 제안하는 구조의 게이트수 140.16 Kgates에 비해 작은 결과이다. 그러나 내부버퍼가 레지스터로 구현된 본 연 구와 SRAM으로 구현된 타 연구와 비교하면 실제로 구 현되는 면적은 오히려 제안하는 구조가 작다. H.264/AVC 디블로킹 필터들의 최대 동작주파수를 살 펴보면, 대다수의 연구들은 100∼200MHz이며, 제안하 는 구조의 최대 동작주파수 90MHz이다. 그리고 H.264/AVC 디블로킹 필터들의 처리성능을 살펴보면, 라인에지필터 1개를 사용하는 연구들[5~8]은 HD 영상을 실시간 처리한다. 라인에지필터가 2개인 연구들[9~10, 13] 은 Full HD 영상을 실시간 처리하기 위해 100MHz이내 의 동작주파수를 요구하며, Quad FHD급 동영상을 실 시간 처리하기 위해 150MHz넘는 동작주파수를 필요로 한다[13]. 라인에지필터가 8개인 연구[11]는 Full HD 영상 을 실시간 처리하지만 Quad FHD급 동영상을 실시간 처리하지 못한다. 그리고 라인에지필터가 16개인 연구 들[12, 14]은 Quad FHD급 이상의 고해상도 영상을 실시 간 처리하지만, 제안하는 구조보다 높은 동작 주파수를 갖기 때문에 전력소모가 많은 문제를 갖는다. 제안하는 H.264/AVC 디블로킹필터는 동작주파수 90MHz에서 Quad FHD급 동영상을 초당 113프레임으로 처리하며, 낮은 주파수로 Quad FHD급 동영상을 실시간 처리하여 기존 연구보다 전력소모가 적다. Ⅴ. 결 론 본 연구에서는 Quad FHD의 고해상도 동영상을 실 시간 처리하는 고성능 저전력 H.264/AVC 디블로킹필 터를 설계하고자 하였다. 고성능 H.264/AVC 디블로킹
필터 구현하기 위해 라인에지필터 16개를 4개의 블록에 지필터로 병렬 설계하여 처리성능을 높였다. 그리고 H.264/AVC 디블로킹 필터 순서를 4단 병렬 지그재그 스캔 순서로 스케줄링하여 내부버퍼 크기와 연산 사이 클을 줄였다. 그리고 블록에지필터 연산 간 1사이클의 지연시간을 두어 데이터 충돌을 방지하고 블록에지필터 간 내부버퍼를 인터리빙 버퍼로 구현함으로써 내부버퍼 의 크기를 줄였다. 0.18um 공정에서 시뮬레이션한 결과, 최대 동작주파수가 90MHz이며, 게이트 수는 140.16 Kgates이다. 제안하는 H.264/AVC 디블로킹필터는 동 작주파수 90MHz에서 Quad FHD급 동영상(3840×2160) 을 초당 113.17프레임으로 실시간 처리하며, 낮은 동작 주파수로 Quad FHD의 고해상도를 실시간 처리하여 기 존 연구보다 전력소모가 적다. 참 고 문 헌 [1] http://www.nhk.or.jp/digital/en/superhivision/ [2] A. Joch, F. Kossentini, H. Schwarz, T. Wiegand,
and G. J. Sullivan,“Performance comparison of video coding standards using Lagragian coder control,” in Proc. IEEE Int. Conf. Image
Processing (ICIP’02), 2002, pp. 501–504.
[3] P. List, A. Joch, J. Lainema, G. Bjontegaard, and M. Karczewicz, “Adaptive deblocking Filter”,
IEEE Trans, Circuits System for Video Technology, vol. 13, no, 7, pp.614-619, 2003. 7.
[4] M. Horowitz, A. Joch, F. Kossentini, and A. Hallapuro, “H.Z64/AVC Baseline Profile Decoder Complexity Analysis”, IEEE Trans. on Circuits
and Syst. Video Technol., vol. 13, no.7, pp.704-716. July 2003.
[5] Y. W. Huang, T. W. Chen, B. Y. Hsieh, T. C.Wang, T. H. Chang, and L. G. Chen, “Architecture design for de-blocking filter in H.264/JVT/AVC,” in Proc. IEEE Conf. Multimedia Expo, 2003, pp. 693–-696., 2003
[6] Shih-Chien Chang, Wen-Hsiao Peng, Shih-Hao Wang, and Tihao Chiang, “A platform based bus-interleaved architecture for de-blocking filter in H.264/MPEG-4 AVC”, IEEE. Transactions on
Consumer Electronics, Vol. 51, pp. 249-255, 2005
[7] Tsu-Ming Liu, Wen-Ping Lee, Ting-An Lin and Chen-Yi Lee, “A memory-efficient deblocking filter for H.264AVC video coding”, IEEE Int'l
Symposium on Circuit and Systems, 2005.
[8] Chao-Chung Cheng, Tian-Sheuan Chang and Kun-Bin Lee, “An In-Place Architecture for the Deblocking Filter in H.264/AVC” ,IEEE
Transactions on Circuits and Systems, Vol. 53,
NO. 7, 2006. 7.
[9] Sebastián López, Felix Tobajas, Gustavo M. Callicó, Pedro A. Perez, Valentin de Armas, Jose F. López, and Roberto Sarmiento, “A Novel High Performance Architecture for H.264/AVC Deblocking Filtering”, ETRI Journal, vol.29, no.3, pp.396-398., 2007. 6.
[10] 이성만, 박태근, “H.264/AVC를 위한 디블록킹 필 터의 효율적인 VLSI 구조”, 2008년 7월 전자공학 회 논문지 제 45 권 SD 편 제 7 호, p. 52-60, 2008. 7.
[11] Chung-Ming Chen and Chung-Ho Chen, “Configurable VLSI Architecture for Deblocking Filter in H.264/AVC”, IEEE Trans. VLSI systems, vol. 16, no. 8, pp. 1072-1082, 2008. 8.
[12] Tsung-Han Tsai and Yu-Nan Pan, “High efficient H.264/AVC deblocking filter architecture for real-time QFHD,” IEEE Trans. Consumer
Electronics, vol. 55, no. 4, Nov. 2009.
[13] Muhammad Nadeem, Stephan Wong, Georgi Kuzmanov, Ahsan Shabbir, “A High-throughput, Area-efficient Hardware Accelerator for Adaptive Deblocking Filter in H.264/AVC,” IEEE/ACM/IFIP 7th Workshop on Embedded Systems for Real-Time Multimedia, pp. 18-27, 2009.
[14] Cheng-Hao Chen, Chih-Hao Chang, Kuan-Hung Chen, “High-throughput de-blocking filter accelerator for high-resolution H.264/AVC/SVC decoding,” In Proc. International Symposium on Next-Generation Electronics (ISNE), pp. 211-214, Nov. 2010.
저 자 소 개 고 병 수(정회원) 2003년 광운대학교 컴퓨터공학과 학사 졸업. 2005년 광운대학교 컴퓨터공학과 석사 졸업. 2005년~현재 광운대학교 컴퓨터공학과 박사과정 <주관심분야 : 영상신호처리 SoC 설계,
Embedded Computing System 설계>
공 진 흥(평생회원)-교신저자 1980년 서울대학교 전자공학과 학사 졸업. 1982년 한국과학기술원 전기 및 전자공학과 석사 졸업. 1989년 텍사스주립대학교 컴퓨터공학과 박사 졸업. 1989년~현재 광운대학교 컴퓨터공학과 교수 <주관심분야 : 영상신호처리 SoC 설계,