논문 2012-50-6-17
8K UHD(7680×4320) H.264/AVC 부호화기를 위한
4×4블럭단위 보간 필터 및 SAD트리 기반 부화소 움직임 추정 엔진 설계
( A Design of Fractional Motion Estimation Engine with 4×4 Block Unit of Interpolator & SAD Tree for 8K UHD H.264/AVC Encoder )
이 경 호*, 공 진 흥***
( Kyung-Ho Leeⓒ and Jin-Hyeung Kong )
요 약
본 연구에서는 8K UHD(7680×4320) 영상을 실시간 부호화하기 위한 4×4 블록 부화소 움직임추정기를 제안한다. 연산처리 성능을 향상시키기 위해 보간 연산을 4×4 블록 단위로 병렬화시켰으며, 병렬 보간 연산에서 필요한 메모리 대역폭을 확장하기 위해 10×10개의 메모리 어레이를 가진 2D 캐쉬 버퍼 구조를 설계하였다. 그리고 2D 캐쉬 버퍼는 검색영역 간 재사용 기법을 적용하여 참조화소의 중복저장을 최소화하였으며, 4×4 블록 병렬 보간 필터는 3단(수평·수직 1/2부화소, 대각선 1/2부화소, 1/4 부화소) 평면 보간 연산 파이프라인 구조로 설계하여 연산회로를 고속화시켰다. 0.13um 공정에서 시뮬레이션한 결과, 436.5K게 이트의 4×4 블록 부화소 움직임추정기는 동작주파수 187MHz에서 8K UHD급 동영상을 초당 30프레임으로 실시간 처리하는 성능을 보였다.
Abstract
In this paper, we proposed a 4×4 block parallel architecture of interpolation for high-performance H.264/AVC Fractional Motion Estimation in 8K UHD(7680×4320) video real time processing. To improve throughput, we design 4×4 block parallel interpolation. For supplying the 10×10 reference data for interpolation, we design 2D cache buffer which consists of the 10×10 memory arrays. We minimize redundant storage of the reference pixel by applying the Search Area Stripe Reuse scheme(SASR), and implement high-speed plane interpolator with 3-stage pipeline(Horizontal·Vertical 1/2 interpolation, Diagonal 1/2 interpolation, 1/4 interpolation). The proposed architecture was simulated in 0.13um standard cell library. The gate count is 436.5Kgates. The proposed H.264/AVC Fractional Motion Estimation can support 8K UHD at 30 frames per second by running at 187MHz.
Keywords: H.264/AVC, Fractional motion estimation, 4×4 Block Parallel, 2D Cache buffer, Pipeline
* 정회원, ** 평생회원, 광운대학교 컴퓨터공학과 (Department of Computer Engineering, Kwangwoon University)
※ 본 연구는 지식경제부 및 IDEC플랫폼 센터의 지원 과 산업융합원천기술개발사업의 일환으로 수행하였 음.(10039173 융복합 혁신반도체 기술개발)
ⓒ Corresponding Author(E-mail: [email protected]) 접수일자 2013년3월15일, 수정완료일 2013년5월16일
Ⅰ. 서 론
다양한 멀티미디어 및 통신 분야에서 요구하는 높은 압축률을 지원하기 위해 H.264/AVC[1]는 가변블록크기 움직임추정, 1/4부화소 움직임추정, 4×4 정수기반 DCT, 블록현상 제거필터, 문맥적응 이진 산술부호화 등의 다
양한 부호화 기술을 통해 기존 영상압축표준 대비 압축 성능을 2배 이상 향상시켰으나, 추가된 부호화 기술들 은 메모리 접근과 연산량을 증가시키기 때문에 실시간 구현에 가장 큰 걸림돌이 되고 있다. 이런 다양한 기술 중 부화소 움직임추정은 동작의 유/무에 따라서 2∼
6dB의 영상압축 화질을 개선하고 20∼30%의 비트레이 트 개선효과를 가지는 블록으로 전체 인코딩 시간의 40%를 차지하는 부호화기의 주요 병목구간이다[2]. 따라 서 연산량을 해결하기 위한 부화소 움직임추정의 하드 웨어 아키텍처 연구는 부화소 연산구조를 병렬화하여 연산처리성능을 향상시키는 연구와 부화소 검색점과 가 변블록의 Type 개수를 줄여 연산량을 감소시키는 연구 로 나누어 진행되고 있다[3∼11].
먼저 부화소 연산구조를 병렬화하는 연구는 6-Tap FIR 필터를 병렬화하여 다수의 보간화소를 생성하여 연산처리 성능을 높였다. 13개의 6-Tap FIR 필터를 병 렬화하여 4화소 부화소 보간 연산 연구(Separate 1-D FIR 보간 필터구조)는 4×4 블록 보간 화소 생성 시 인 접 보간 화소 간 재사용하여 수평 1/2부화소를 생성하 는 1-D FIR 보간 필터와 수직과 대각선 1/2부화소를 생성하는 1-D FIR 보간 필터가 각각 병렬 연산한다
[3][4]. 수평 1/2부화소를 생성할 때 사용한 참조 화소를
수직·대각선 1/2부화소를 생성할 때 재사용하여 입력지 연시간을 감소시켰으며, 또한 수평 1/2부화소 생성 결 과를 대각선 1/2부화소 생성에 재사용하였다. 그러나 4 화소 부화소 보간 연산 연구는 대각선 1/2부화소 보간 연산에 따른 연산지연시간과 4×1라인단위로 보간 화소 를 생성하는 병렬성의 제한 때문에 고해상도(720P) 영 상의 실시간 처리까지만 가능한 연산처리성능을 갖는 다. 이 같은 성능을 개선하고자 16화소 부화소 보간 연 산 연구[5][6]는 매크로블록 내에서 2개의 8×1라인단위 또는 16×1라인단위의 보간 연산을 처리하여 기존 Separate 1-D FIR 보간 필터구조에 비해 연산처리단위 를 4배로 증가시켜 Full HD(1080P)영상을 실시간 처리 하였다. 그러나 라인단위의 보간 연산에 따른 연산지연 시간과 병렬화된 연산회로의 복잡도로 인해 Separate 1-D FIR 보간 필터구조[4]에 비해 면적이 2배로 늘어났 으며, 동작주파수가 1.5배로 증가하여 전력소모가 커지 는 문제점을 보이고 있다. 부화소 검색점과 가변블록의 Type 개수를 줄이는 연구는 H.264/AVC의 부화소 움직 임 추정에 대한 49개의 검색점과 7Type 가변블록크기 의 탐색을 일부 생략하여 연산량을 감소시켰다. 검색점 감소를 위해 Joint Model(JM)에 사용된 2-Step 탐색
알고리즘은 전체 49개 검색점 중에서 17개 검색점만 탐 색하여 연산량을 65%로 감소시켰다[7]. 다이아몬드 탐색
알고리즘[8∼9]는 2-Step보다 8개의 검색점을 줄였으며,
인접 블록의 움직임 벡터를 이용하여 현재 블록의 움직 임 벡터를 예측한 논문[10]은 6개의 검색점만을 탐색하여 연산량을 최소화 시켰다. 이렇게 추정 연산에 대한 연 산량은 줄였지만 오히려 연산 단계가 2단계로 변경되어 연산지연시간이 증가하는 문제를 얻게 되었다. 마지막 으로 가변블록을 줄여 연산량을 감소시키는 연구[11]는 가변블록을 8×8블록크기로 고정하여 매크로블록의 모 드를 결정한다. 따라서 연산량은 1/7로 줄였으나, 가변 블록크기별 MVcost가 반영되지 않은 매크로블록 모드 결정으로 인해 JM레퍼런스 대비 0.1∼3.9dB 정도 화질 저하가 발생한다. 화질 저하를 최소화하면서 가변블록 Type를 줄인 연구[6]은 4가지 블록크기(8×8, 16×8, 8×16, 16×16)에서 2개의 블록크기 선택하여 JM과 화질차이를 0.2dB이내로 줄이면서 연산량도 2/7로 감소시켰다.
본 논문에서는 UHD(3840×2160) 영상에 대한 H.264/AVC 부화소 움직임 추정을 실시간 처리하기 위 해 4×4블록 2D 캐쉬 버퍼, 4×4 블록 병렬 보간 필터와 PU연산기를 제안한다. 제안하는 2D 캐쉬 버퍼는 기존 라인단위의 데이터 입력에 의한 입력레이턴시 발생을 줄이고 4×4 블록단위 보간 연산구조에서 요구되는 참 조 화소를 실시간으로 공급하도록 설계했고, 움직임 벡 터에 따른 중복적인 참조메모리 검색을 최소화하기 위 해 검색영역 간 재사용 기법을 사용하였다. 4×4 블록 병렬 보간 필터는 4×1, 8×1, 16×1의 라인단위의 연산지 연이 없도록 4×4 블록단위의 부화소를 생성할 수 있도 록 3단 평면 보간 연산구조로 설계하였다. 3단 평면 보 간 연산구조는 수평 및 수직 1/2부화소를 생성하는 1단 평면 FIR 필터, 대각선 1/2부화소를 생성하는 2단 평면 FIR 필터, 그리고 마지막 1/4부화소를 생성하는 3단 평 면 Bilinear 필터의 3단 파이프라인 구조로 연산지연시 간을 최소화하여 연산처리성능을 향상시켰다. PU연산 기는 49개의 부화소 검색점을 동시에 탐색할 수 있도록 4×4 PU를 기본 모듈로 하여 7x7개 어레이 형태로 설계 하여 절대차분 합 연산을 고속화하였다.
본 논문의 구성은 Ⅱ장에서 기존의 부화소 움직임 추 정과 4×4블록 병렬 부화소 움직임 추정에 대해 기술하 였다. Ⅲ장에서는 4×4블록 병렬 부화소 움직임 추정기 의 구조와 동작을 설계하였고, Ⅳ장에서는 새로운 아키 텍쳐의 성능을 다른 연구결과와 비교하며, 마지막으로
Ⅴ장에서는 결론을 맺는다.
그림 2. 부화소움직임 추정의 탐색 과정 Fig. 2. Process of fractional motion estimation.
그림 3. 4화소단위 부화소움직임 추정의 탐색 과정 Fig. 3. Process of 4 pixel unit fractional motion estimation.
Ⅱ. H.264/AVC 4×4 블록 부화소 움직임추정
H.264/AVC의 부화소 움직임 추정은 시간적 중복성 을 이용하여 가장 오차가 적은 위치를 한 픽셀 미만의 1/4부화소 단위까지 탐색하여 움직임벡터를 구한다.
H.264/AVC의 표준 참조모델인 JM은 그림 1과 같이 1/2부화소 단위의 9개 검색점에 대해 매크로블록의 절 대차분이 최소가 되는 위치를 구하고, 1/4부화소 단위 의 9개 검색점에 대해 매크로블록의 절대차분합이 최소 가 되는 위치를 구하는 2단계 부화소 움직임 추정을 수 행한다.
먼저 1단 탐색은 정수화소 움직임추정에서 받은 정 수화소 움직임 벡터 주변의 9개의 1/2부화소 검색점(상,
그림 1. 2 단계 부화소 움직임 추정 탐색 알고리즘 Fig. 1. 2-Step Subpixel ME search algorithm.
상·좌, 상·우, 중·좌, 중, 중·우, 하·좌, 하, 하·우)에 대해 매크로블록의 절대차분이 최소가 되는 검색점을 찾는 다. 6개의 참조화소를 입력받아 보간 연산을 통해 1/2부 화소를 생성하며, 1/2부화소 보간 연산을 16회 반복수 행하여 4×4블록 1/2부화소를 생성한다. 4×4블록 1/2부 화소 생성과정을 16회 반복하여 매크로블록 1/2부화소 를 생성하고. 9개의 1/2부화소 검색점의 매크로블록 1/2 부화소와 현재 매크로블록의 절대차분이 최소가 되는 검색점을 구한다. 2단 탐색은 1단 탐색에서 선택된 최 소 검색점 9개의 1/4부화소 검색점에 대해 매크로블록 의 절대차분이 최소가 되는 검색점을 찾는다. 1단 탐색 에서 선택된 최소 검색점을 기준하여 상, 하, 좌, 우, 대 각선의 1/4부화소를 탐색하게 된다. 1단 탐색에서 생성 된 1/2부화소 2개 또는 1/2부화소 1개와 정수화소 1개 를 입력받아 Bilinear연산을 통해 1/4부화소를 생성한 다. 이 과정을 16회 반복수행하여 4×4 블록 1/4부화소 를 생성한다. 그리고 4×4블록 1/4부화소 생성과정을 16 회 반복하여 매크로블록 1/4부화소를 생성하고, 9개의 1/4부화소 검색점의 매크로블록 1/4부화소와 현재 매크 로블록의 절대차분이 최소가 되는 검색점을 구한다. 이 와 같이 부화소움직임추정은 그림 2와 같이 2단 탐색과 정을 가변 블록 7개 모드에 대해 반복수행하여 가변블 록에 대한 최적 모드와 검색점을 찾는다.
4화소 단위 부화소 움직임 추정 연구[4]는 보간 연산
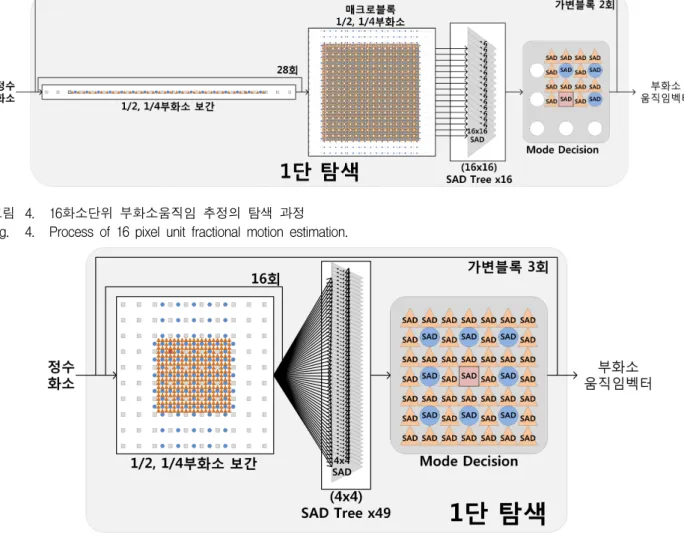
그림 4. 16화소단위 부화소움직임 추정의 탐색 과정 Fig. 4. Process of 16 pixel unit fractional motion estimation.
그림 5. 4×4 블록 부화소움직임 추정의 탐색 과정 Fig. 5. Process of 4×4 block fractional motion estimation.
단위를 4화소의 라인단위로 병렬화하여 4×4블록 부화 소 생성하며, 1/2부화소 생성과 1/4부화소 생성을 2단계 로 나누어 17개의 검색점 중 매크로블록의 절대차분합 이 최소가 되는 위치를 탐색한다. 1단 탐색은 정수화소 움직임추정에서 받은 정수화소 움직임 벡터 주변의 9개 의 1/2부화소 검색점에 대해 매크로블록의 절대차분이 최소가 되는 검색점을 찾는다. 4개의 정수화소를 입력 받아 보간 연산을 통해 16개의 1/2부화소를 생성하며, 1/2부화소 보간 연산을 10회 반복수행하여 4×4블록 1/2 부화소를 생성한다. 9개의 1/2부화소 검색점의 4×4블록 1/2부화소와 현재 4×4블록의 절대차분을 구하고, 4×4블 록 1/2부화소 생성 및 탐색과정을 16회 반복하여 매크 로블록 1/2부화소에 해당하는 절대차분이 최소가 되는 검색점을 구한다. 2단 탐색은 1단 탐색에서 선택된 최 소 검색점 주변 9개의 1/4부화소 검색점에 대해 매크로 블록의 절대차분이 최소가 되는 검색점을 찾는다. 1단
탐색에서 선택된 최소 검색점을 기준하여 5개의 정수화 소와 23개 1/2부화소를 입력받아 보간 연산을 통해 46 개의 1/4부화소를 생성한다. 9개의 1/4부화소 검색점의 4×4블록 1/4부화소와 현재 4×4블록의 절대차분을 구하 고, 4×4블록 1/4부화소 생성 및 탐색과정을 16회 반복 하여 매크로블록 1/4부화소에 해당하는 절대차분이 최 소가 되는 검색점을 구한다. 이와 같이 4화소 부화소움 직임추정은 그림 3와 같이 2단 탐색과정을 가변 블록 7 개 모드에 대해 반복수행하여 가변블록에 대한 최적 모 드와 검색점을 찾으며, 기존 부화소 움직임 추정에서 검색점과 1/2부화소 보간에서의 루프를 제거하였다.
16화소 단위 부화소 움직임 추정 연구[6]는 보간 연산 단위를 16화소의 라인단위로 병렬화하여 1/2부화소와 1/4부화소 동시에 생성하고, 16개의 검색점 중 매크로 블록의 절대차분합이 최소가 되는 위치를 탐색한다. 22 개의 정수화소를 입력받아 보간 연산을 통해 50개의
1/2부화소와 143개의 1/4부화소를 생성하며, 부화소 보 간 연산을 28회 반복수행하여 매크로블록 1/2부화소와 매크로블록 1/4부화소를 생성한다. 16개의 1/2·1/4부화 소 검색점의 매크로블록 1/2·1/4부화소와 현재 매크로 블록의 절대차분이 최소가 되는 검색점을 구한다. 이와 같이 16화소 부화소움직임추정은 그림 4와 같이 1단 탐 색과정을 가변 블록 2개 모드에 대해 반복수행하여 가 변블록에 대한 최적 모드와 검색점을 찾으며, 4화소 단 위 부화소 움직임 추정 연구에서 4×4블록 단위에 대한 루프를 제거하였다.
제안하는 4×4블록 부화소 움직임 추정은 부화소 보 간 연산 단위를 4×4 블록화소 단위로 확장하여 연산처 리성능을 높이고 보간 연산과 탐색지점을 병렬 처리하 여 1단 탐색을 수행한다. 그리고 제안하는 4×4블록 부 화소 움직임 추정은 매크로블록 1/2⦁1/4부화소를 생 성하는 루프를 변경하였으며, 보간 연산 과정에서 사용 되는 참조화소들을 공유하여 메모리 검색량을 줄이고 자 하였다. 먼저 수평·수직 1/2부화소 보간 연산은 10×10개의 참조화소를 공유한다. 10×10개의 참조화소 를 5×10개의 보간 연산하여 5×10개의 수평 1/2부화소 를 구하고, 10×10개의 참조화소 중 6×10개의 참조화소 를 6×5개의 보간 연산하여 6×5개의 수직 1/2부화소를 구한다. 대각선 1/2부화소 보간은 5×10개의 수평 1/2부 화소를 5×5개의 보간 연산하여 5×5개의 대각선 1/2부 화소를 구한다. 1/4부화소 보간은 6×6개의 정수화소와 앞서 구한 수평·수직·대각선 1/2부화소를 보간 연산하 여 280개의 1/4부화소를 생성한다. 105개의 1/2부화소 와 280개의 1/4부화소를 가지고 7×7검색점을 탐색하여 매크로블록 1/2⦁1/4부화소와 현재 매크로블록의 절대 차분이 최소가 되는 검색점을 구한다. 따라서 기존의 16화소 부화소 움직임 추정에 비해 더 많은 검색점을 탐색하여 기존 보다 정확히 절대차분이 최소가 되는 점을 탐색한다.
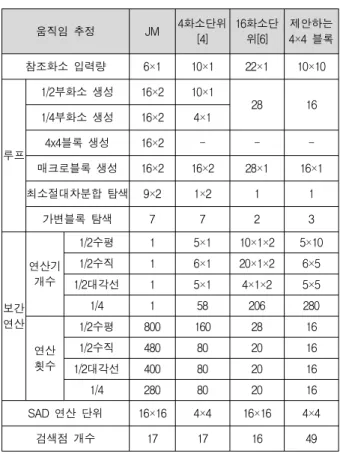
표 1은 지원하는 매크로블록을 처리하는 부화소 움 직임 추정 연구에 관해 참조화소 입력량, 루프, 검색점 개수, 보간 연산의 연산기 개수와 보간 연산의 연산 횟 수를 비교 분석하였다. 참조화소 입력량은 JM은 1개의 부화소를 생성하기 위해 6x1개의 정수화소가 필요로 하 며, 4화소 단위의 부화소 움직임추정은 4개의 부화소를 생성하기 위해 10x1개의 정수화소가 필요로 한다. 마찬 가지로 16화소 단위의 부화소 움직임 추정은 16개의 부 화소를 생성하기 위해 22x1개의 정수화소가 필요로 하 며, 4x4블록 단위의 부화소 움직임추정은 4x4개의 부화
움직임 추정 JM 4화소단위
[4]
16화소단 위[6]
제안하는 4×4 블록
참조화소 입력량 6×1 10×1 22×1 10×10
루프
1/2부화소 생성 16×2 10×1
28 16
1/4부화소 생성 16×2 4×1
4x4블록 생성 16×2 - - -
매크로블록 생성 16×2 16×2 28×1 16×1
최소절대차분합 탐색 9×2 1×2 1 1
가변블록 탐색 7 7 2 3
보간 연산
연산기 개수
1/2수평 1 5×1 10×1×2 5×10
1/2수직 1 6×1 20×1×2 6×5
1/2대각선 1 5×1 4×1×2 5×5
1/4 1 58 206 280
연산 횟수
1/2수평 800 160 28 16
1/2수직 480 80 20 16
1/2대각선 400 80 20 16
1/4 280 80 20 16
SAD 연산 단위 16×16 4×4 16×16 4×4
검색점 개수 17 17 16 49
표 1. 제안구조의 연산성능 비교
Table 1. Computation performance of proposed architecture.
소를 생성하기 위해 10x10개의 정수화소가 필요로 한 다. JM의 부화소 움직임 추정은 1/2부화소 생성, 1/4부 화소 생성, 4x4블록 생성, 매크로블록 생성, 최소절대차 분합 탐색, 가변블록 탐색과정을 순환한다. 그에 비해 4 화소 단위의 부화소 움직임추정은 4x4블록 생성과정을 줄였다. 16화소 단위의 부화소 움직임추정은 1/2⦁1/4부 화소를 동시에 생성하고, 4x4블록 생성과정을 줄이며, 최소절대차분합 탐색과정도 줄였다. 4x4블록 단위의 부 화소 움직임추정은 1/2⦁1/4부화소를 동시에 생성하고, 4x4블록 생성과정을 줄이며, 최소절대차분합 탐색과정 도 줄였으며, 16화소 단위의 부화소 움직임추정에 비해 매크로블록 생성과정에 대한 루프를 줄였다. 보간연산 을 살펴보면 제안하는 4x4블록 부화소 움직임 추정은 16화소 단위의 부화소 움직임추정에 비해 연산기 개수 는 1.4배 증가하였으나 연산횟수를 14% 줄였다. SAD연 산을 살펴보면 JM과 16화소 단위의 부화소 움직임추정 은 매크로블록 단위로 절대차분합을 비교하며, 4화소 단위의 부화소 움직임추정과 제안하는 4x4블록 단위의 부화소 움직임추정은 4×4화소 단위로 절대차분합을 비 교한다. 검색점 개수를 비교하면 기존연구는 17개 이하 의 검색점을 비교하지만 제안하는 4x4블록 부화소 움직
임 추정은 49개의 검색점을 탐색함으로써 보다 정확히 절대차분이 최소가 되는 점을 탐색한다.
Ⅲ. 4×4블록 부화소 움직임추정기 아키텍처
1. 부화소 움직임추정기 아키텍처 설계
제안된 4×4블록 부화소 움직임추정기는 그림 6과 같 이 2D 캐쉬 버퍼, 4×4 블록 병렬 보간 필터, PU연산기 로 구성하였다. 2D 캐쉬 버퍼는 4×4 블록단위 보간 연 산에 필요한 참조 화소(10×10 화소)를 공급하는 버퍼이 다. 2D 캐쉬 버퍼는 움직임 벡터에 따른 중복적인 참조 메모리 검색을 최소화하기 위하여 검색영역 간 재사용 기법[12]을 사용하여 외부메모리에 대한 중복검색을 1회 로 감소시킬 수 있다. 또한 2D 캐쉬 버퍼는 4×4 블록 단위 보간 연산에 사용되는 참조 화소(10×10 화소)를 공급하기 위해 병렬 출력이 가능한 메모리 어레이 구조 로 설계되어 보간 연산기와 1:1로 연결된다. 4×4블록 보 간 연산기는 수평·수직·대각선 1/2부화소와 1/4부화소 를 생성하기 위해 3단 보간 연산 파이프라인 구조를 갖 는다. 1단계에서는 수평·수직 1/2부화소 보간 FIR 필터, 2단계에서는 대각선 1/2부화소 보간 FIR 필터, 3단계에 서는 1/4부화소 보간 Bilinear 필터로 구성되어 파이프 라인 동작으로 처리성능을 높이고자 하였다. PU연산기 는 1/2부화소탐색과 1/4부화소탐색의 49개 검색점에 대 한 탐색방법을 구현하고자 절대 차분 연산하는 4×4 Processing Unit(PU)를 49개로 병렬화하여 49개 검색점 에 대한 비교를 한 번에 처리가능하게 함으로써 연산 처리량을 높였다. 모드는 각 4×4 PU에서 처리된 COST 를 해당 가변블록의 개수만큼 합해서 블록에 대한 COST값을 비교하고 결정된 움직임벡터를 출력하는 동 작을 한다. 마지막으로 Multiplex보상기는 움직임탐색 과정과 동일한 보간 연산 과정을 수행하는 복호화기의 움직임보상과정을 처리할 수 있다.
그림 6. 부화소 움직임추정의 제안구조 Fig. 6. Proposed fractional motion estimation
architecture.
2. 2D 캐쉬 버퍼
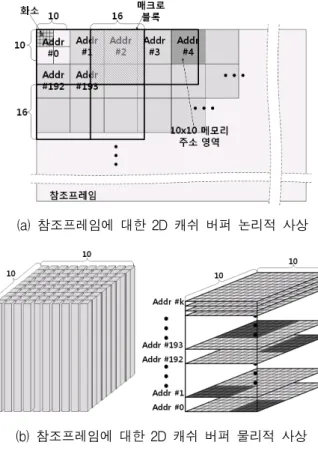
2D 캐쉬 버퍼는 매크로블록에 따라 검색영역이 이동 할 때마다 매크로블록(16×16) 크기의 데이터를 저장하고, 4×4 블록단위 보간 연산을 위해 10×10 화소 크기의 데이 터를 출력한다. 부화소 움직임 추정은 매크로블록단위로 수행되지만 가변블록크기를 지원하기 용이하도록 최소 블록인 4×4블록 단위로 나누어 처리된다. 4×4블록 단위 의 부화소 움직임 추정은 10×10개의 참조화소를 2D 캐쉬 버퍼에 16회 요구하기 때문에 1회 저장되는 매크로블록 단위가 아닌 그림 7 (a)와 같이 참조 프레임을 10×10 정 수화소 단위로 분할하고 그림 7 (b)와 같이 10×10개의 메 모리 어레이에 구성하여 저장하였다. 이에 따라 보간 연
(a) 참조프레임에 대한 2D 캐쉬 버퍼 논리적 사상
(b) 참조프레임에 대한 2D 캐쉬 버퍼 물리적 사상 그림 7. 참조프레임에 대한 2D 캐쉬 버퍼 사상 Fig. 7. 2D Cache buffer mapping on reference frame.
그림 8. 2D 캐쉬 버퍼의 4가지 주소 형태 Fig. 8. 4 type address of 2D Cache buffer.
산에 필요한 10×10개의 참조화소를 동시에 검색하기에 효과적인 구조를 갖는다. 그러나 2D 캐쉬 버퍼는 매크로 블록 단위로 저장된 외부메모리의 메모리 사상과 적합하 지 않아 최소 4개의 쓰기 주소를 갖는다.
2D 캐쉬 버퍼는 움직임벡터에 따라 보간 연산에 필 요한 10×10 정수화소를 4×4 블록 보간 필터에 공급한 다. 그림 8와 같이 움직임벡터에 따라 2D 캐쉬 버퍼 읽 기 주소는 4가지 주소형태(➀-동일주소, ➁-좌우분할 주소, ➂-상하분할 주소, ➃-4분할 주소)를 갖는다. 그 림 9 (a)에서와 같이 4분할 주소를 갖는 경우에는 그림 9 (b)와 같이 10×10 어레이 메모리에 데이터를 요청하 고 그림 9 (c)와 같이 정렬된 데이터가 2D 캐쉬 버퍼에 출력된다. 따라서 4분할주소를 갖는 경우 2D 캐쉬 버퍼 는 그림 9 (d)와 같이 데이터를 재정렬해야 하는 과정 이 필요하며, 그림 10과 같이 2D 캐쉬 버퍼는 2D 메모 리 어레이와 양방향 순환버퍼로 구성된다.
(a) 참조 블록 (b) 메모리 어레이
(c) 정렬되지 않은 출력 (b) 정렬된 출력 그림 9. 참조블록 재정렬 과정
Fig. 9. Reordering of reference block.
그림 10. 2D 캐쉬 버퍼의 구조
Fig. 10. 2D Cache architecture and address.
그림 11. 양방향 순환버퍼의 동작
Fig. 11. Bi-directional circular buffer operation.
양방향 순환 버퍼는 2D 메모리 어레이의 주소가 분할 주소를 갖는 경우 10×10개의 참조화소를 재정렬하여 보 간 필터에 전달한다. 그림 11은 양방향 순환버퍼의 동작 을 나타내고 있다. 2D 메모리 어레이의 읽기주소에 따라 가로·세로·대각선 방향으로 정렬시켜 보간 연산기가 요 구하는 형태로 참조화소들을 재정렬한다.
3. 4×4블록 보간 연산기
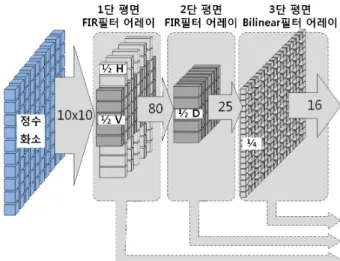
4×4 부화소 보간 연산기는 2D 캐쉬 버퍼로부터 보간 연산을 위해 필요한 10×10개의 참조화소를 입력받아 19×19개 부화소를 생성한다. 그림 12는 3단 파이프라인 으로 동작하는 4×4 블록 보간 연산기의 구조를 보여준 다. 각 단계의 입출력을 살펴보면 평면형태의 부화소가 생성됨을 알 수 있다. 첫 번째 단계에서 10×10 정수화 소를 입력받아 5×10개의 수평 1/2부화소와 6×5개의 수 직 1/2부화소를 동시에 생성한다. 두 번째 단계에서 첫 번째 단계에서 생성한 5×10개의 수평 1/2부화소를 입력
그림 12. 4×4 블록 보간 연산기 Fig. 12. 4×4 block interpolator.
(a)수평 및 수직 FIR연산
(b)대각선 FIR연산
(c) 1/4 Bilinear연산 그림 13. 보간 연산 구성
Fig. 13. Configuration of Interpolation.
받아 5×5개의 대각선 1/2부화소를 생성한다. 마지막으 로 세 번째 단계에서 앞 서 생성한 1/2화소들과 정수화 소들을 입력받아 280개의 1/4 화소들을 생성한다.
각 단계에서의 연산기 구조를 살펴보면 그림 13과 같 다. 1단 평면 FIR 필터 어레이는 수평·수직 1/2부화소 를 동시에 생성할 수 있도록 수평 6-Tap FIR 필터를 5×10어레이 형태로 구성하고 수직 6-Tap FIR 필터를 6×5어레이 형태로 배치하여 5×10개의 수평 방향 1/2화 소와 6×5개의 수직 방향 1/2화소를 생성한다. 2단 평면 FIR 필터 어레이는 대각선 1/2부화소를 생성하는 수직 6-Tap FIR 필터를 5×5어레이로 구성하여 대각선방향 의 1/2화소 5×5개를 생성한다. 마지막 3단 평면 Bilinear 필터는 19×19어레이 구조에서 1/2부화소 위치 에 해당하는 필터를 배제하고 Bilinear 필터를 구성하여 앞 서 생성한 1/2화소들과 정수화소들을 입력받아 1/4 화소들을 생성하도록 설계하였다.
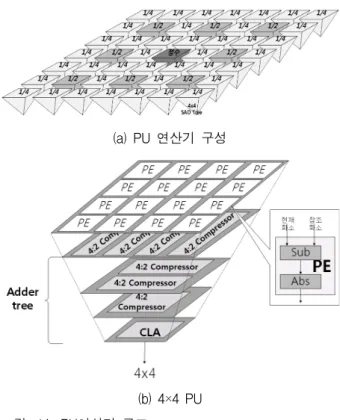
4. PU(Processing Unit) 연산기
제안된 PU연산기의 구조는 49개 검색점을 동시에 탐 색할 수 있도록 4×4 PU를 7×7 어레이 형태로 배치하여 입력 받은 정수화소블록과 부화소참조블록에 대해 절대 차분의 합을 구한다. 4×4 PU는 그림 16과 같이 절대 차 분 연산부와 Adder Tree연산부로 구성된다. 특히
(a) PU 연산기 구성
(b) 4×4 PU 그림 14. PU연산기 구조
Fig. 14. Architecture of PU.
Adder Tree는 4:2 압축기와 Carry Lookahead Adder (CLA)를 통해 절대차분 합 연산을 고속화하였다.
Ⅳ. 실험 및 분석
본 논문에서 제안한 고속 부화소 탐색 알고리즘을 검 증하기 위해 표 2와 같이 QCIF영상부터 Full-HD영상 까지 총 18개의 영상 시퀀스를 사용하였다. 정화소 움 직임 추정은 전역 탐색 방법을 이용하였으며 탐색 범위 는 32, 참조 프레임은 1장, GOP는 IPPP..., QP값을 22, 26, 30, 34으로 설정하여 실험을 진행하고, 실험결과는 영상간의 압축률을 나타내는 BDBR(Bjontegaard Delta Bit-Rate)과 화질을 나타내는 BDPSNR(Bjontegaard Delta PSNR)을 이용하여 성능을 나타내었다. 제안한 3-Type 가변블록 크기의 성능 비교를 위해서 표 3과 같이 7-Type 가변블록과 3-Type가변블록을 비교하였
영상
해상도 프레임수 실험
영상 QCIF
(176×144) 100 akiyo foreman mother_daughter coastguard mobile_qcif stefan CIF
(352×288) 200 akiyo bridge-far foreman bridge-close coastguard mobile Full HD
(1920×1080) 200 station rush_hour pedestrian_area sunflower riverbed blue_sky
표 2. 실험영상
Table 2. Test sequence.
영상크기 QP
7-Type 제안하는(3-Type) 평균이득 Bitrate PSNR Bitrate PSNRBDPSNR
[%]
BDBR [dB]
QCIF (176×144)
22 815,736 39.70 805,910 39.68
-0.020 0.330 26 523,822 36.35 523,626 36.33
30 320,125 33.17 321,189 33.15 34 181,182 30.27 181,964 30.26
CIF (352×288)
22 2,727,834 39.81 2,667,610 39.80
0.016 -0.195 26 1,488,419 36.99 1,472,253 36.98
30 863,200 34.31 861,615 34.30 34 484,544 31.87 486,308 31.86
FHD (1920×1080
22 20,853,046 35.45 20,030,799 35.47
0.098 -2.777 26 11,108,557 33.92 10,807,345 33.93
30 6,606,715 32.21 6,493,251 32.21 34 3,857,998 30.39 3,813,040 30.40
표 3. 다양한 해상도에 대한 성능 비교
Table 3. Performance comparisons of various resolution
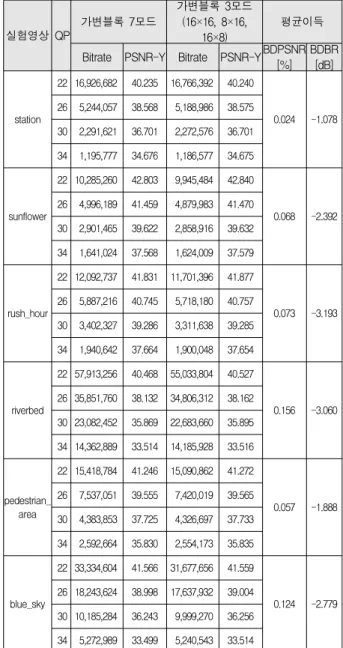
다. 그 결과 3-Type 가변블록은 7Type 가변블록과 비 교하여 QCIF영상에서만 PSNR차이는 최대 0.02dB이고 Bitrate는 최대 0.33% 늘어났지만 CIF와 Full-HD영상 시퀀스에서는 PSNR과 Bitrate에서 더 좋은 결과를 얻 었으며, 탐색지점의 수는 3/7으로 감소시킬 수 있었다.
특히 Full-HD 영상 시퀀스에서는 표 4와 같이 최저 모 든 영상에서 화질저하는 거의 없이 Bitrate를 약 1~3%
가 감소되었다.
제안된 4×4 블록 부화소 움직임 추정기를 0.13um 공 정에서 시뮬레이션하여 표 5에 기존 연구와 비교하였 다. 먼저 메모리 대역폭을 매크로블록당 검색 사이클로 비교해보면 연구[6]는 인접한 서브블록 여러 개를 통합 하여 가져오는 Unified Pixel Block Loading을 사용해
실험영상 QP
가변블록 7모드
가변블록 3모드 (16×16, 8×16,
16×8)
평균이득
Bitrate PSNR-Y Bitrate PSNR-YBDPSNR [%]
BDBR [dB]
station
22 16,926,682 40.235 16,766,392 40.240
0.024 -1.078 26 5,244,057 38.568 5,188,986 38.575
30 2,291,621 36.701 2,272,576 36.701 34 1,195,777 34.676 1,186,577 34.675
sunflower
22 10,285,260 42.803 9,945,484 42.840
0.068 -2.392 26 4,996,189 41.459 4,879,983 41.470
30 2,901,465 39.622 2,858,916 39.632 34 1,641,024 37.568 1,624,009 37.579
rush_hour
22 12,092,737 41.831 11,701,396 41.877
0.073 -3.193 26 5,887,216 40.745 5,718,180 40.757
30 3,402,327 39.286 3,311,638 39.285 34 1,940,642 37.664 1,900,048 37.654
riverbed
22 57,913,256 40.468 55,033,804 40.527
0.156 -3.060 26 35,851,760 38.132 34,806,312 38.162
30 23,082,452 35.869 22,683,660 35.895 34 14,362,889 33.514 14,185,928 33.516
pedestrian_
area
22 15,418,784 41.246 15,090,862 41.272
0.057 -1.888 26 7,537,051 39.555 7,420,019 39.565
30 4,383,853 37.725 4,326,697 37.733 34 2,592,664 35.830 2,554,173 35.835
blue_sky
22 33,334,604 41.566 31,677,656 41.559
0.124 -2.779 26 18,243,624 38.998 17,637,932 39.004
30 10,185,284 36.243 9,999,270 36.256 34 5,272,989 33.499 5,240,543 33.514
표 4. Full-HD영상 시퀀스의 성능 비교
Table 4. Performance comparisons of Full-HD resolution.
아키텍처 4화소단위[4] 16화소단위[6] 제안하는 4×4 블록
메 모 리
접근기법 - Unified Pixel
Block Loading Search Area Stripe Reuse
크기(KBytes) n/a n/a 205
구성(개) n/a 22×1 10×10
검색횟수
(사이클) 160 56 48
가변블록
모드 7 Type 2 Type
(16×8, 8×8) 3 Type (16×16, 16×8, 8×16)
보간단위 4화소 16화소 16화소
PU 9 96 49
매크로블록당
처리사이클수 1600 224 48
공정(um) 0.18um 0.18um 0.13um
면적(gates) 401k 976.5k 436.5k
동작주파수
(MHz) 106 145 200
처리해상도 1280×720 4096x4096 7680×4320 실시간
부호화 성능 HD
@30fps 4k×4k SHV
@60fps 8K UHD
@30fps JM대비
화질감소 - ~0.2dB ~0.02dB
표 5. 기존 부화소 움직임추정 성능비교
Table 5. Performance comparison for fractional motion estimation.
연구[4]에 비해 검색 사이클을 56회로 줄였다. 제안하는 2D 캐쉬 버퍼는 수평/수직 검색영역 간 참조화소를 모 두 저장해 외부 메모리에 대한 접근을 1회로 줄이고, 모든 참조화소를 한번에 검색이 가능하도록 10×10 메 모리 어레이 구조를 적용하여 대역폭이 5배로 증가되고 검색 사이클 수가 15.2%로 감소되어 짧은 검색 사이클 과 높은 대역폭을 제공할 수 있다. 그다음 보간 연산 단 위로 비교해보면 연구[6]는 기존 연구[4]에 비해 4배의 처 리량으로 검색점 16개에 대해 병렬 탐색하여 매크로블 록당 224사이클이 소요된다. 제안하는 4×4블록 부화소 움직임 추정기는 연구[6]와 비슷한 보간 연산단위단위를 갖지만 부화소생성과 부화소 탐색이 연속적으로 이루어 져 매크로블록 당 처리사이클이 연구[9]의 비해 4배 빠 른 연산처리성능(Throughput)을 보이고 있다. 또한 연 구[6]와의 면적을 게이트 수로 비교해 본 결과 부화소 움직임추정기의 크기는 436.5k로 1/2로 감소된 결과이 다.
Ⅴ. 결 론
본 연구에서는 H.264/AVC 4×4 블록 움직임 추정기 를 제안하여 8K UHD(7680×4320) 영상을 실시간 처리 하고자 하였다. 연산처리성능을 향상시키고자 보간 연
산을 4×4 블록단위로 병렬화하는 아키텍처를 설계하여 매 사이클 마다 4×4 블록 보간 화소를 생성하였으며, 49개 검색점을 동시에 탐색하는 1단 탐색 PU연산기를 설계하였다. 4×4 블록단위 보간 연산구조에서 요구되는 참조 화소를 공급하기 위해 2D 캐쉬 버퍼를 제안하였 고, 외부메모리에 대한 검색을 줄이고자 검색영역 간 재사용 기법을 사용하였다. 제안된 4×4 블록 부화소 움 직임 추정기 구조를 0.13um공정에서 시뮬레이션한 결 과, 게이트 수는 436.5K게이트이며, 최대 동작주파수는 200MHz이다. 이 같은 결과는 16화소 부화소 움직임 추 정 연구에 비해 면적을 1/2로 줄였으며, 187MHz에서 8K UHD 영상을 30fps로 실시간 처리함을 보였다.
REFERENCES
[1] Draft ITU-T Recommendation and Final Draft International Standard of Joint Video Specification, ITU-T Recommendation H.264 and ISO/IEC14496-10 AVC, Joint Video Team, May 2003.
[2] Tung-Chien Chen, Yu-Han Chen, Chuan-Yung Tsai and Liang-Gee Chen, “Low power and power aware fractional motion estimation of H.264/AVC for mobile applications”, IEEE International Symp. on Circuits and Systems, pp. 5331-5334, Island of Kos, Greece, May 2006.
[3] Jin Soo Kim, Kwang Woo Lee, Myung Hoon Sunwoo, “Novel fractional pixel motion estimation algorithm using motion prediction and fast search pattern”, IEEE International Conference on Multimedia and Expo, pp.
821-824, Hannover, Germany, June 2008.
[4] Tung-Chien Chen, Shao-Yi Chien, Yu-Wen Huang, Chen-Han Tsai, Ching-Yeh Chen, To-Wei Chen, Liang-Gee Chen, “Analysis and architecture design of an HDTV720p 30 frames H.264/AVC encoder”, IEEE Transactions on Circuits and Systems for Video Technology, Vol.
16, pp. 673-688, 2006.
[5] Changqi Yang, Satoshi Goto, Takeshi Ikenaga,
“High performance VLSI architecture of fractional motion estimation in H.264 for HDTV”, IEEE International Symp. on Circuits and Systems, pp. 2605-2608, Island of Kos, Greece, May 2006.
[6] Yiqing HUANG, Qin LIU, Takeshi IKENAGA,
“Highly parallel fractional motion estimation engine for Super Hi-Vision 4k×4k@60fps”, IEEE International Workshop on Multimedia Signal
Processing, pp. 1-6, Rio De Janeiro, Brazil, Oct.
2009.
[7] Joint Video Team Reference Software JM12.4 Available:
http://bs.hhi.de/~suehring/tml/download/
[8] Tung-Chien Chen, Yu-Wen Huang, Liang-Gee Chen, “Fully utilized and reusable architecture for fractional motion estimation of H.264/AVC”, IEEE International Conference on Acoustics, Speech, and Signal Processing, vol. 5, pp. 9-12, Montreal, Quebec, Canada. May 2004.
[9] 조성현, 이종화, “고속 부화소 움직임 추정을 위한 중심 지향적 십자 다이아몬드 탐색 알고리즘”, 전 자공학회논문지 제46권 SD편, 제2호, 78-84쪽, 2009년 2월
[10] Y.-J. Wang, C.-C. Cheng, and T.-S. Chang, “A fast algorithm and its VLSI architecture for fractional motion estimation for H.264/MPEG-4 AVC video coding”, IEEE Transactions on Circuits and Systems for Video Technology, Vol.
17, pp. 578-583, 2007.
[11] Tung-Chien Chen, Yu-Han Chen, Chuan-Yung Tsai, Liang-Gee Chen, “Low power and power aware fractional motion estimation of H.264AVC for mobile applications”, IEEE International Symp. on Circuits and Systems, pp. 1-4, Island of Kos, Greece, May 2006.
[12] Jen-Chieh Tuan, Tian-Sheuan Chang, Chein-Wei Jen, “On the data reuse and memory bandwidth analysis for full-search block-matching VLSI architecture”, IEEE Transactions on Circuits and Systems for Video Technology, Vol.12, pp.
61-72, Jan 2002.
저 자 소 개 이 경 호(학생회원)
2004년 광운대학교 정보통신 공학과 학사 졸업.
2006년 광운대학교 컴퓨터공학과 석사 졸업.
2006년~현재 광운대학교 컴퓨터 공학과 박사과정
<주관심분야 : 영상신호처리, SoC설계, VLSI, Embedded System>
공 진 흥(평생회원)
1980년 서울대학교 전자공학과 학사 졸업.
1982년 한국과학기술원 전기 및 전자공학과 석사 졸업.
1989년 텍사스주립대학교 컴퓨터공학과 박사 졸업.
<주관심분야 : 영상신호처리, SoC설계, VLSI, Embedded System>

![Table 5. Performance comparison for fractional motion estimation. 연구 [4] 에 비해 검색 사이클을 56회로 줄였다](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5071987.559916/10.892.83.429.208.609/table-performance-comparison-fractional-motion-estimation-사이클을-줄였다.webp)
