Addressing the New User Problem of Recommender Systems Based on Word Embedding Learning and Skip-gram Modelling
1)
전체 글
1)
수치
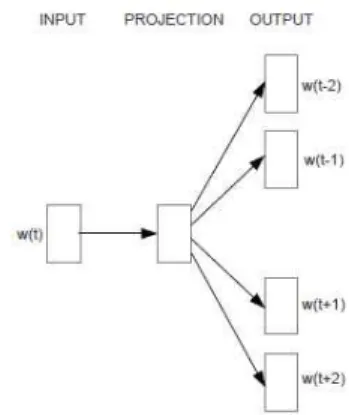


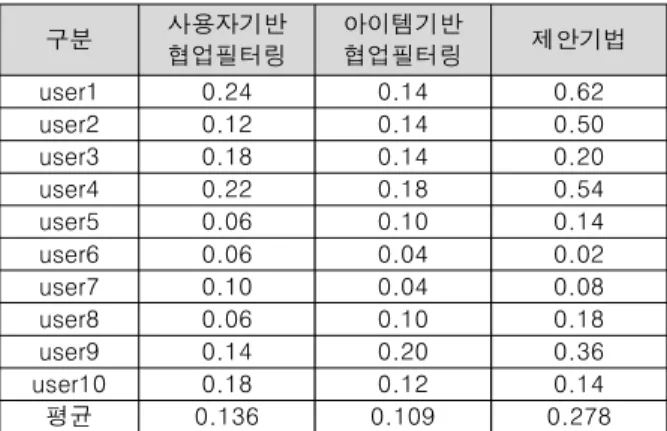
관련 문서
In Chapter 3, by establishing teaching and learning plans based on famous paintings for children of the fifth to sixth grade of elementary school, the
The purpose of this study is to analyze the effects of word- recording on learning vocabulary, reading and listening of English. control groups to answer
This study examined the achievement, satisfaction and interest of an English grammar class based on flipped learning in order to find out the effect of
The result based on the students’ survey showed that the majority of students had rarely experienced learning punctuation, and even the experienced
결과적으로 문제 기반 학습은 문제 기반 학습(Problem Based Learning)과 프로젝트 기반 학습(Project-Based Learning)의 두 가지 의미를 갖는다. 2) 교육과정 통합,
We also propose the new method for recovering root forms using machine learning techniques like Naïve Bayes models in order to solve the latter problem..
1 John Owen, Justification by Faith Alone, in The Works of John Owen, ed. John Bolt, trans. Scott Clark, "Do This and Live: Christ's Active Obedience as the
Essentially, the method entails determining the number of bits for embedding secret data by examining the difference values of the neighboring pixels based on
