Establishing the Process of Spatial Informatization Using Data from Social Network Services
10
0
0
전체 글
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
수치
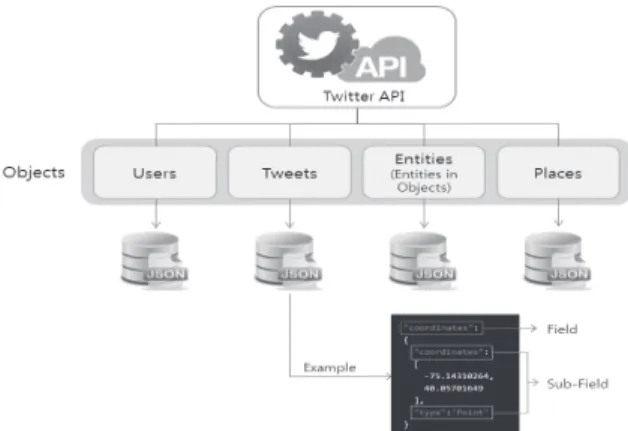
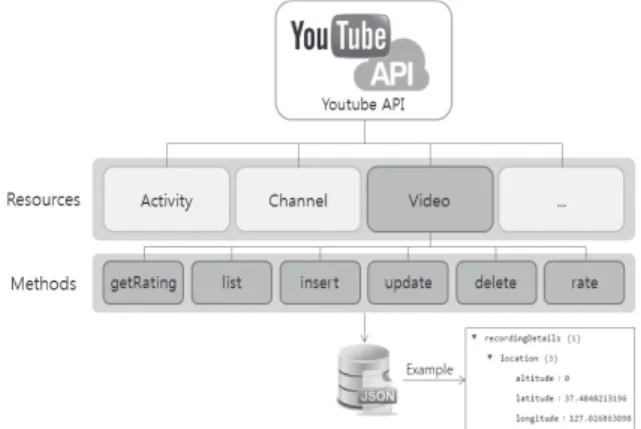

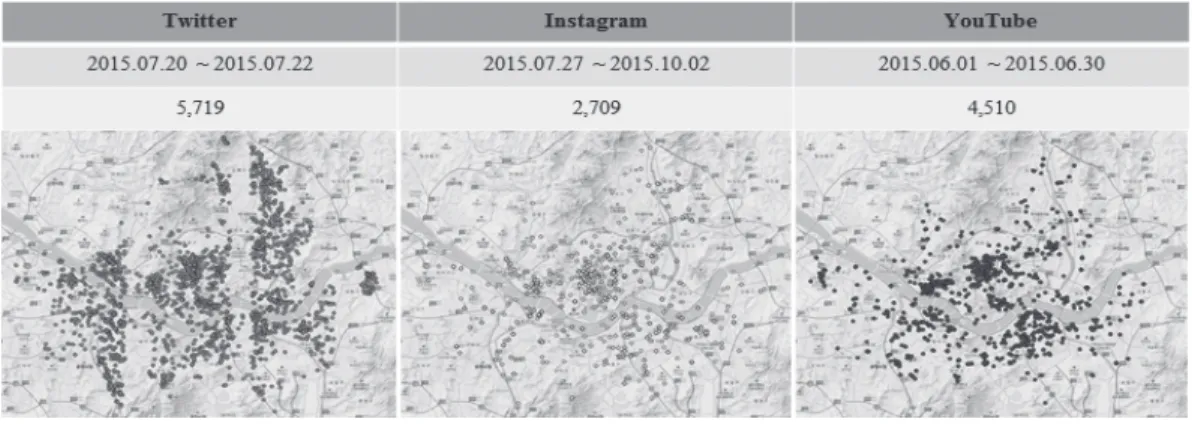
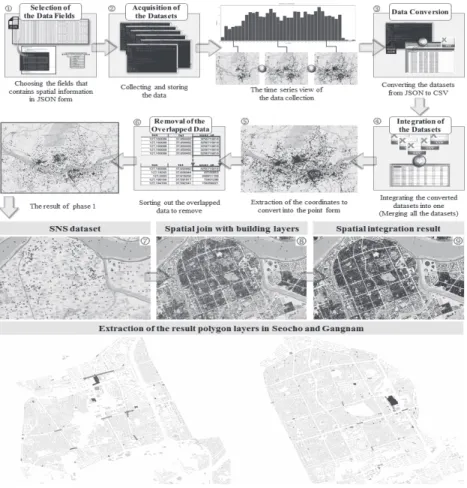
+2
관련 문서
Data sampled at the scan interval is recorded in the internal memory as measured data for each specified data type (display data and event data).. Measured value at
- Click the Icon of Record Log Data from Equipment Selection Menu (Log Data Record mode ON – shall be identified Log Data saved or not during on moment of escape
1 John Owen, Justification by Faith Alone, in The Works of John Owen, ed. John Bolt, trans. Scott Clark, "Do This and Live: Christ's Active Obedience as the
While taking into account of the interference and channel fading in heterogeneous network, data transmission process is relevant to the
Process data in registers using a number of data processing instructions which are not slowed down by memory access. Store results from registers
From the results of the linear cutting tests, the effects of the process parameters on the kerfwidth and characteristics of the cut section, including
The data from the questionnaire survey were analyzed to prove the effects of Myung Power Therapy on such scales of the relaxation of pain as improvement
§ Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and
