논문 2014-51-5-16
시각 주의와 영상 분할을 이용한 관심 객체 자동 검출 기법
( Automatic Detection of Objects-of-Interest using Visual Attention and Image Segmentation )
신 도 경*, 문 영 식***
( Do Kyung Shin and Young Shik Moonⓒ)
요 약
본 논문에서는 일반적인 자연 영상에서 관심 객체를 자동으로 검출하기 위한 방법을 제안한다. 영상에서의 관심 객체는 사 람에 따라서 주관적으로 판단되며, 일반적으로 사람의 시각은 관심 객체에 초점이 맞춰지게 된다. 관심 객체의 자동 검출을 위 한 첫 번째 단계로서 사람의 시각 인지기반의 돌출 맵을 이용하여 관심 객체의 후보 영역을 검출한다. 검출된 후보영역은 객 체에 대한 대략적인 위치 정보를 가지고 있지만 관심 객체를 정확하게 분할하지 못하는 문제점이 존재한다. 따라서 두 번째 단계에서 영상의 색상과 에지를 고려한 그래프 기반의 영상 분할 기법과 객체 영역의 세선화(skeletonization)를 결합함으로써 정확한 객체 영역을 자동으로 검출한다. 본 논문에서는 제안하는 방법과 기존 방법들의 성능을 비교하기 위해서 정확률 (precision), 재현율(recall) 그리고 정밀도(accuracy)를 계산하였다. 그 결과, 제안하는 방법은 미 검출(under detection) 및 과 검출(over detection)에 대한 문제점을 줄임으로써 기존 방법보다 더 향상된 결과를 보인다.
Abstract
This paper proposes a method of detecting object of interest(OOI) in general natural images. OOI is subjectively estimated by human in images. The vision of human, in general, might focus on OOI. As the first step for automatic detection of OOI, candidate regions of OOI are detected by using a saliency map based on the human visual perception. A saliency map locates an approximate OOI, but there is a problem that they are not accurately segmented. In order to address this problem, in the second step, an exact object region is automatically detected by combining graph-based image segmentation and skeletonization. In this paper, we calculate the precision, recall and accuracy to compare the performance of the proposed method to existing methods. In experimental results, the proposed method has achieved better performance than existing methods by reducing the problems such as under detection and over detection.
Keywords: Object of Interest(OOI), visual attention, saliency map, automatic segmentation
* 학생회원, ** 평생회원, 한양대학교 컴퓨터공학과 (Dept. of Computer Science and Engineering, Hanyang University)
ⓒ Corresponding Author(E-mail: [email protected])
※ 이 논문은 2012년도 정부(교육과학기술부)의 재원으 로 한국연구재단의 지원을 받아 수행된 연구임(No.
2012002464).
접수일자: 2013년12월10일, 수정일자: 2014년3월21일 수정완료: 2014년 4월29일
Ⅰ. 서 론
일반적인 자연 영상에서 관심 객체 (OOI : Object of Interest) 검출 기법의 자동화는 영상과 비디오의 내용 분석, 객체 추적, 영상 감시, 영상 검색 등과 같은 응용 프로그램에서 중요한 연구 분야이다. 임의의 영상이 주 어졌을 때, 관심 객체는 사람에 따라서 주관적으로 판 단되지만 일반적으로 영상을 획득할 때에는 관심 객체
에 초점을 맞추게 된다. 관심 객체를 자동으로 검출하 기 위한 기존 연구 방법 중에서 전경과 배경에 대한 모 델을 추정하기 위한 방법으로 에너지 최소화 (energy minimization) 기법을 이용한 기법[1, 2], 그래프 에너지 최소화를 이용한 기법[3, 4], 가우시안 혼합 모델 (Gaussian mixture models)을 이용한 기법[5, 6], 커널 밀 도 (kernel densities)[7], 고정 소수점[8], 그래프 컷 [9~11]
등을 이용한 기법 등이 있다. 이와 같은 반복 에너지 최 소화 과정에서의 문제점은 각 하위영역(sub-region)에 대한 반복적인 모델 추정 단계에서 일반적으로 초기 분 할이 부정확하기 때문에 관심 객체의 자동분할에 대한 정확도가 낮아진다. 또한 에너지 최소화 기반의 여러 기법 들 중에서 그래프 컷은 반복적인 객체 분할을 위 해서 가장 강력한 최적의 방법으로 잘 알려져 있다. 하 지만 그래프 컷 알고리즘은 모든 분할 영역들 간의 최 소 비용 컷(minimum-cost cut)을 추정하기 위해서 반 드시 사용자에 의해서 객체에 대한 시드 위치(seed position) 정보를 제공 받아야 되는 제약 사항을 가지고 있다. 이와 같은 문제점을 단순화하기 위해서 Rother et al.[3]이 제안한 확장 그래프 컷 기법은 사용자가 관심 객체 영역에 대하여 사각형 박스로 지정을 하면서 사용 자 상호작용을 단순화하였지만 이 방법 또한 분할에 대 한 성능을 사용자의 지정에 의존도가 매우 높다는 문제 점이 존재한다. 또한 자동화 된 응용 시스템을 위해서 는 사용자 상호 작용은 객체 분할 단계에서 제외 되어 야만 한다. 따라서 최근에는 자동으로 객체를 분할하기 위해서 인간의 시각 시스템 (human visual system)[12~
14]을 기반으로 영상 내의 두드러진 영역(saliency region)을 검출하는 여러 시각 주의 방법들[15~33]이 존재 한다. 시각 주의 (visual attention)는 장면에서 가장 중 요한 정보를 빠르고 손쉽게 검색 할 수 있는 능력으로 써 시각적 시스템에 의해 이미지 내의 다른 부분 보다 시각적으로 큰 관심을 끌 수 있는 영역으로 간주되기 때문에 돌출(salient)영역이라고 한다. 기존 시각 주의에 대한 접근은 크게 상향식(bottom-up)[15~27, 36~37]
방법과 하향식(top-down)[28~33] 방법으로 나뉠 수 있다. 상향식 접근 방법은 장면에서 주변의 다른 영역에 비해 현저하 게 두드러지는 영역을 검출하기 위해서 밝기(intensity), 색상(Color), 방향(Orientation), 질감(Texture), 대비 (contrast), 모션(motion) 등의 하위 수준(low-level) 정 보를 이용하는 방식이고, 하향식 접근 방법은 장면 또
는 객체들 간의 관계를 사전에 유추하여 선지식(prior knowledge)으로 이용하는 방식이다. 본 논문에서는 Li[21]가 제안한 상향식 주의 기반의 돌출 맵을 이용한 다. 일반적으로 상향식 기반의 돌출 맵(Saliency map) 은 하위 수준 정보 이외에도 다중 스케일(multi-scale)
[19], 자기 정보(self-information)[27], 중심-주변 연산 (center-surround operation)[17~18], 또는 그래프 기반 랜 덤 워크(random walk)[16] 등의 다중 특징 정보에 의해 서 계산된다.
기존의 시각 주의를 기반으로 한 방법들 중에서, Liu et al.[17]은 다중 스케일 대비 (multi-scale contrast), 중 앙-주변 히스토그램 (center-surround histogram), 그리 고 색상 공간 분포 등의 특징 정보의 집합으로 부터 얻 어진 돌출 맵과 CRF(Conditional Random Field)를 결 합하여 효과적으로 객체를 검출하는 방법을 제안 하였 다. Achanta et al.[19]는 주파수 영역에서 색상과 밝기 정보를 결합한 특징 정보로 부터 검출된 돌출 영역과 Mean-shift 알고리즘을 결합한 방법을 제안 하였다. 이 방법은 색상과 밝기 정보의 하위수준 특징 정보를 이용 하여 돌출 맵을 생성함으로써 빠르고 쉽게 구현이 가능 하다는 장점을 가지고 있지만 반면에 에지(edge)와 경 계(boundary)에 대한 특징 정보를 포함하지 않기 때문 에 객체의 경계를 정확하게 검출하지 못하는 단점이 존 재한다. Xie et al.[22]는 중간-주변 (center-surround) 원 칙을 기반으로 하위 수준과 중간 수준(mid level)를 이 용하여 베이지안 돌출 모델을 생성하고, 그래프 컷을 이용하여 관심 객체를 검출하는 방법을 제안하였다. 이 방법은 관심 영역이 돌출 영역 주변에 존재하지 않거 나, 너무 큰 영역으로 분산 되어 있는 경우에 객체가 정 확하게 검출되지 못하는 단점이 존재한다. Jung et al.[11, 37]은 돌출 맵으로부터 객체 영역과 배경 영역에 대 한 각각의 시드 맵(seed map)을 생성 한 후, 시드 맵과 그래프 컷을 결합하여 자동으로 관심 객체를 검출하는 방법을 제안하였다. 기존의 그래프 컷 기법은 사용자가 객체와 배경에 대한 영역에 대한 지정이 필요한 사용자 의존도가 높다는 문제점이 존재하였다. 이 방법은 돌출 맵으로부터 시드 위치에 대한 정보를 자동으로 추출함 으로써 사용자의 지정이 없이 자동으로 객체를 효율적 으로 검출 할 수 있다. Fu et al.[23]는 Jung의 방법과 같 이, 기존의 그래프 컷 기법이 사용자에 의해 수동으로 객체를 분할해야 되는 문제점을 개선하기 위해 돌출 맵
ⓐ입력 이미지
ⓑ 분할 맵 생성
ⓒ 시각 집중 맵 생성 ⓓ Otsu 이진화 및 세선화
ⓔ 분할 맵과 세선화 ⓕ 관심 객체 검출
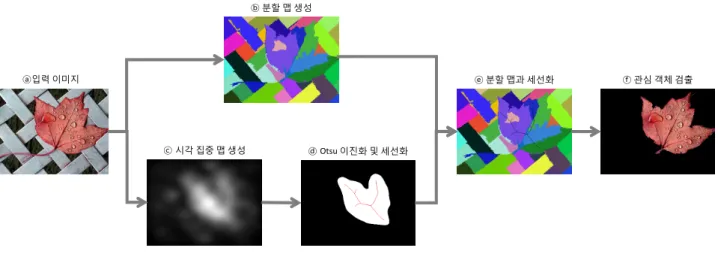
그림 1. 제안하는 방법의 흐름도
Fig. 1. Overall flowchart of the proposed method.
과 그래프 컷을 결합하여 자동으로 관심 객체를 검출하 는 방법을 제안하였다. 다중 해상도 프레임워크 (multi-resolution framework)에 의해 자동적으로 배경 과 객체에 대한 각 레이블을 얻은 후 이 정보로부터 배 경과 객체에 대한 시드 위치 정보를 추출함으로써 자동 으로 그래프 컷을 수행 하여 객체를 검출하는 방법이 다. 이 두 방법은 사용자의 의존도가 높았던 그래프 컷 에 대한 단점을 보완함으로써 효율적으로 객체를 자동 으로 검출 할 수 있는 장점이 존재함과 동시에 사용자 가 지정하는 기존 방식보다 정확도가 낮다는 단점이 존 재한다. Han et al.[26]은 에지, 색상, 밝기 등의 특징 정 보로부터 얻어진 돌출 맵과 Mean-Shift 분할 알고리즘 (Mean-Shift Segmentation, MSS)을 결합하여 자동으 로 객체를 검출하는 방법을제안함으로써 객체 검출의 정확도를 높였다. 하지만 이 방법은 객체 분할을 위해 서 고정된 임계 값(threshold value)을 사용하기 때문에 다양한 영상 특성에 따른 적응적인 임계 값 추정이 필 요하다.
이와 같은 시각 주의는 컴퓨터 비전 시스템 이외에도 생리학, 심리학, 신경 시스템 등의 다양한 분야에서 연 구되어 왔다. 또한 자동으로 이미지 자르기[30], 영상 디 스플레이가 되는 소형기기[31], 이미지/비디오의 압축, 광 고 디자인[32], 이미지 검색 브라우징 등에서 시각 주의 기반의 많은 응용 시스템이 사용되고 있다. 최근에는 시각적인 관심뿐만 아니라 객체 인식, 객체 추적, 객체 검출을 하기 위한 연구[33~37]에서도 시각 주의가 응용 되고 있으며, 이와 같은 응용 분야를 위해서 객체의 자
동 검출에 대한 연구가 필요하다.
따라서 본 논문에서는 완전 자동화 시스템을 구축하 기 위해서 Li[21]가 제안한 상향식 주의를 기반의 돌출 맵을 이용함으로써 영상에서 두드러진 영역인 관심 객 체 후보 영역을 검출한다. 이때 얻어진 돌출 영역은 영 상에서 다른 영역과 비교 했을 때 고유한 특징을 가지 며, 일반적으로 돌출 영역이 영상내의 관심 객체와 높 은 연관성이 있는 것을 볼 수 있다. 이를 이용함으로써 관심 객체가 항상 영상의 중심에 존재한다는 가정[8]에 대한 기존 방법의 문제점을 해결 할 수 있다. 하지만 돌 출 영역에 대한 정보는 관심 객체의 위치 및 후보 영역 을 검출 할 수 있지만 배경을 포함하지 않는 관심 객체 의 정확한 분할이 불가능 하다. 따라서 본 논문에서는 Pedro F.[38]가 제안한 그래프 기반 영상 분할 기법을 결 합함으로써 자동으로 관심 객체를 검출하는 방법을 제 안하고자 한다.
Ⅱ. 제안하는 방법
영상에서 객체를 자동으로 인식하기 위해서는 객체 에 대한 분할(segmentation)은 필수적이다. 본 논문에서 는 입력된 영상에서 관심 객체를 자동으로 검출하기 위 해서 인간의 시각 특징을 기반으로 한 시각 주의 모델 (visual attention model)을 이용하여 관심 객체 영역을 검출한다. 인간의 시각 시스템은 미리 습득한 객체의 크기, 모양, 색상 등의 정보를 통해서 물체를 인식한다.
또한 인간의 시각은 주변과의 밝기 차, 색상 차가 큰 영
입력 영상에 대한 세가지 특징 맵의 생성 Hypercomplex퓨리에 변환 스펙트럼 스케일 공간 생성 대응되는 시각 집붕 맵의 생성 및 최종 시각 집중 맵의 선택
그림 2. HFT를 이용한 돌출 맵 생성
Fig. 2. The saliency may creation by using the Hypercomplex Fourier Transform (HFT).
역, 윤관선 등에 대한 특징이 강한 영역 또는 객체에 초 점이 먼저 맞춰지게 되며 이것을 시각 주의(visual attention)라고 한다. 따라서 시각 주의 모델은 인간의 시각 시스템의 특징을 모방하여 인간 시각계의 정보처 리와 유사한 연산을 통해서 입력 영상에 대한 특징 영 역을 검출한다. 일반적으로 영상 내에서의 시각 주의 영역은 항상 일정한 위치에 존재하지 않기 때문에 자동 으로 검출하는 것은 어렵다. 따라서 본 논문에서는 영 상으로부터 관심객체를 자동으로 검출하기 위해서, 첫 번째 단계에서 입력 영상에서 인간의 시각이 집중되는 영역을 관심객체 후보 영역으로 가정하고, Li[21]가 제안 한 HFT(Hypercomplex Fourier Transform) 기반의 돌 출 맵을 생성함으로써 관심 객체 후보영역을 검출한다.
두 번째 단계에서는 배경으로부터 관심 객체의 정확한 영역을 분리하기 위해서 입력 영상에 대한 색상과 에지 에 대한 연결성 정보를 고려한 영상 분할 기법[38]을 이 용하여 영상분할 맵을 생성한다. 세 번째 단계에서는, 검출된 관심객체 후보 영역에 대해서 세선화 알고리즘 을 적용함으로써, 배경 영역을 효과적으로 제거하고, 관 심객체 영역만을 나타내는 골격 정보를 추출한다. 최종 적으로, 추출된 객체의 골격 특징 정보와 영상분할 맵 을 결합함으로써 입력 영상으로부터 관심 객체를 자동 으로 검출한다. 그림 1은 제안하는 방법의 흐름도를 보 여준다.
1. 돌출 맵을 이용한 관심 영역(ROI) 검출
가. 다중 특징 맵의 다차원 행렬 표현
일반적인 이산 푸리에 변환 (discrete fourier transform)의 입력은 실수 값으로 이루어진 행렬 형태 이다. 만약 다차원 행렬(hypercomplex matrix) 내에 하 나 이상의 특징을 결합 한다면, 각 요소는 하나의 벡터 를 의미하고 다차원 행렬은 벡터 필드(vector field) 이 다. 다차원 행렬은 색상, 밝기, 모션 정보 등과 같은 여 러 개의 특징 정보를 결합하기 위한 표현 방법이다.
[39]는 입력 다차원 행렬을 다음 수식 (1)과 같이 정의 한다.
(1) 수식 (1)에서의 ∼ 는 가중치를 의미하며, 은 모션, 는 밝기, 와 는 색상에 관한 특징 맵들을 의미한다. 정지영상으로부터 두드러진 영역(salient region)을 검출하기 위해서는 모션 정보를 필요로 하지 않기 때문에, 3개의 특징들만 이용하며, 수식 (2)-(4)에 의해 얻어진다.
(2)
(3)
(4) 위의 수식에서 r, g, b는 입력 칼라 영상의 각 red, green, blue 채널을 의미하며, ,
, ,
이다. 이들 세 가지 특징맵들은 입력 영 상의 보색 컬러 공간(opponent color space)으로 구성된 다. 세 가지 특징 맵들은 그림 2의 단계 1에서 보여준 다. 본 논문에서는 정지 영상을 사용하기 때문에 모션 정보를 제외한 밝기와 색상 정보만을 사용하였다. 따라 서 모션 정보에 해당되는 가중치는 으로 설정함 으로써 모션 정보를 제외하였으며, 밝기와 색상 정보에 대한 가중치는 로 설정하였 다. 입력영상은 식(1)에 의거하여 다차원 행렬로 정의될 수 있으며, 이에 대한 다차원 푸리에 변환 (hypercomplex fourier transform)은 식 (5)와 같이 극 좌표 형식(polar form)으로 재 정의될 수 있다.
∥ ∥ (5) 수식 (5)의 ∥∥는 다차원 행렬의 각 요소를 의미 한다. 는 의 주파수 도메인으로 고려 될 수 있으며, 그것의 진폭 스펙트럼(amplitude spectrum) 인 , 위상 스펙트럼(phase spectrum) 인 , 그리고 고유 축 스펙트럼(eigenaxis spectrum)인 는 수식 (6)-(8)과 같이 정의된다.
∥ ∥ (6)
tan
∥ ∥
(7)
∥ ∥
(8)
수식(8)에서의 는 사원수 행렬(quaternion matrix)이다. 위의 수식으로 정의된 세 개의 스펙트럼은 그림 2의 단계 2에서 보여준다. 본 단계에서 정의된 진 폭 스펙트럼은 영상에 대한 중요한 정보를 포함한다.
일정하게 반복되는 패턴들은 스케일을 사용함으로써 블 러링된 진폭 스펙트럼에 의해 제거된다. 하지만 필터의 스케일이 너무 작거나 너무 크면 반복되는 패턴을 완전 히 제거하지 못하거나, 돌출 영역의 가장자리만 주요 부분으로 검출이 되는 문제점이 존재한다. 따라서 가우 시안 커널(gaussian kernel)의 적당한 스케일을 결정하 는 것은 매우 중요한 문제이다. 이때, 작은 사이즈의 커 널은 크게 두드러지는 영역을 검출하기 위해 필요하고,
큰 사이즈의 커널은 텍스처가 존재하는 부분과 작게 두 드러지는 영역을 검출하기 위해 필요하다. 이 두 가지 의 경우를 모두 만족시키기 위해서 스펙트럼 크기 공간 (Spectrum Scale-Space)을 이용하여 위의 수식 (6)에서 얻어진 에 대하여 각 다른 사이즈로 정의된 커 널을 적용함으로써 수식 (9)와 같이 를 얻을 수 있다.
(9) 가우시안 커널의 는 수식 (10)과 같이 정의된다.
(10)
수식 (9)에서 는 커널 사이즈 파라미터로써,
⋯ 이고, 는 입력 영상의 사이즈에 의해
⌈logmin⌉ 으로 정의된다. 이때
는 입력 영상의 사이즈를 의미하며, 으로 정의한다. 이와 같이, 진폭 스펙트럼 가 각 커 널에 의해 블러가 되며, 위상 스펙트럼 그리고 고유축 스펙트럼 은 적용하지 않고 유지한다.
이 결과는 그림 2의 단계 3에 보여준다. 본 단계에서 각 커널 크기에 따른 돌출 맵(saliency map)은 수식 (11)에 의해 정의된다.
∥ ∥ (11) 수식 (11)에서의 는 고정된 크기의 가우시안 커널을 의미하며, 본 논문에서는 × 크기의 가우시안 커널 을 사용하였다. 결과적으로, 그림 2의 단계 4와 같이 돌 출 맵들의 집합를 얻을 수 있다.
나. HFT 기반의 돌출 맵 생성
본 단계에서는 입력 영상에 존재하는 관심객체의 크 기가 일정하지 않기 때문에, 돌출 맵 집합에서 관 심객체의 크기에 적합한 특정한 스케일의 돌출 맵을 결 정 한다. 적합한 스케일을 결정하기 위한 기준은 수식 (12)와 같다.
arg
min (12)
수식 (12)에서
log 는 의 엔트로
피를 정의하는 수식이다. 엔트로피를 사용할 수 있는 이유는 돌출 맵은 확률 맵(probability map)으로 간주될 수 있기 때문에, 바람직한 돌출 맵에서의 관심객체 영 역은 높은 값이 할당되고, 돌출 맵의 나머지 부분은 대 체적으로 낮은 값이 할당되어 억제 된다. 본 단계에서 는 적당한 스케일 를 선택하기 위해서 HFT에서는
가 주어졌을 때 인접 경계 방법을 사용함으로써 인접 영역에서 강한 신호를 갖는 돌출 맵을 선택한다.
따라서 파라미터 는 각 후보 돌출 맵을 위해 정의된 다. ∙ 이고, 여기에서의
는 와 동일한 사이즈의 2D 가우시안 마스크이다.
사용된 마스크의 사이즈는 이고,
이다. 또한 은 모든 픽셀 값의 합을 1로 하기 위해서 정규화 된 를 사용한다. 2D 엔 트로피와 , 는 다음 수식 (13)과 같이 정의된다.
arg
min (13)
다. 관심 객체 후보 영역 검출
첫 번째 단계에서 생성된 돌출 맵의 결과는 그림 1-
ⓒ 와 같다. 돌출 맵은 인간의 시각이 집중되는 영역의 위치와 그 위치에 대한 시각 집중의 정도를 ∼ 사 이의 크기 값으로 표현이 되며, 1에 가까울수록 시각 집중의 정도가 큰 것으로 볼 수 있다. 따라서 본 단계에 서는 관심 객체를 추출하기 위한 전 처리 단계로서 Otsu가 제안한 이진화 기법을 적용하여 관심 객체 후보 영역을 검출한다. 그림 1-ⓓ 는 이진화를 통한 관심 객 체 검출 결과를 보여준다. 하지만 본 결과는 객체뿐만 아니라 배경의 일부가 함께 검출이 됨으로써 객체를 정 확하게 검출하지 못하는 문제점이 존재한다.
2. 돌출 맵을 이용한 관심 영역(ROI) 검출 돌출 맵의 이진화는 영상에서의 관심 객체 영역에 대 한 대략적인 위치와 영역을 검출 할 수 있다. 하지만 관 심 객체를 정확하게 분할하지 못한다는 문제점이 있다.
따라서 본 단계에서는 이와 같은 문제점을 해결하기 위 해서 Pedro F.[38]가 제안한 영상의 색상과 에지를 고려 한 그래프 기반 영상 분할 기법을 사용한다. 이 영상 분 할 기법은 영역 간에 존재하는 에지의 가중치 값을 계 산하여 두 영역 사이의 경계를 결정함으로써 영역 분할
에 좋은 성능을 보인다.
가. 그래프 기반의 객체 분할
영상 분할을 위해 각 정점들(vertices) 의 집합
와 인접한 정점들의 쌍을 연결하는 에지들
∈ 으로 구성된 그래프 를 생성한 다. 이때, 각 에지 ∈ 는 대응되는 가중치
를 가지며, 가중치 값은 인접한 와 사이의 비유사도(dissimilarity)에 대한 양의 정수 값을 갖는다.
그래프기반의 영역 분할 는 그래프 ′ ′에 서 하나의 연결된 영역을 위해 대응되는 각 영역
∈ 내의 의 분할된 부분이며, ′⊆ 이다. 즉, 에서 에지의 부분집합에 의해 분할이 발생한다. 분할의 정확도를 높이기 위해서 동일한 영역 내의 두 개의 정 점 사이에서 에지는 상대적으로 낮은 가중치 값을 가지 고, 다른 영역에서의 정점 사이의 에지들은 상대적으로 높은 가중치 값을 갖는다. 입력 영상에서 분할된 두 영 역 사이의 경계를 결정하기 위해서 두 영역 내의 이웃 하는 요소들의 경계를 따라 비유사도를 측정한다. 따라 서 로컬 영역들 간의 차이를 비교함으로써 데이터의 로 컬 특징들의 관계에 적응적인 결과를 얻을 수 있다. 이 를 위하여 수식 (14)의 최소 신장 트리 (MST, Minimum Spanning Tree)를 이용하여 부분집합
⊆ 의 최대 가중치를 구함으로써 각 요소들의 로컬 차이를 구한다.
∈ max (14) 또한 두 영역을 연결하는 에지의 최소 가중치 값은 두 영역 사이의 차이 값을 의미하며 이는 식 (15)에 의 해 계산된다.
∈ min∈ ∈ (15) 이때, ∞ 라면, 과 사이에 연결 된 에지가 없는 것으로 판단한다.
수식 (16)과 같이 만약 두 영역 사이의 차 가
과 중에 하나 이상보다 크다면, 두 영 역간의 경계선이 존재하는 것으로 판단되어 영역을 분 할한다. 임계치(threshold) 함수는 두 영역 사이의 차가 최소 로컬 차보다 크게 하기 위해 사용될 수 있다.
i f (16) 수식(16)에서의 최소 로컬의 차는 다음 수식 (17)과 같이 나타낸다.
min
(17) 임계치 함수 은 두 영역 사이의 경계를 결정짓기 위해 로컬의 차이 값보다 커야 되기 때문에 두 영역 사 이의 차이를 위한 크기를 조절한다.
는 데이터의 로컬 특징을 추정하기에 좋지 않 기 때문에 작은 영역으로 분할하는데 어려움이 존재한 다. 따라서 분할 영역의 크기에 따라서 임계 값을 결정 하기 위해서 수식 (18)의 수식을 이용한다.
(18)
수식 (18)에서 는 의 크기를 의미하고, 는 상 수 파마미터를 의미하며 의 크기를 결정한다. 최소 영역은 이웃하는 영역 사이의 차가 큰 경우에만 분할 영역으로 결정된다. 본 논문에서는 를 400으로 설정하 여 모든 영상에 동일하게 적용하였다.
이와 같은 방법을 통해서 영역이 더 이상 분할되거나 합쳐질 수 없을 때까지 이 과정을 반복 수행한다.
본 단계를 통해서 그림 1-ⓑ와 같이 영상 분할 맵이 생성된다. 본 논문에서 사용한 영상 분할 기법은 영상 의 색상과 에지를 고려함으로써 객체의 경계에 따른 영 역 간 분할에 좋은 성능을 보인다. 하지만 영상 분할 기 법은 영역간의 경계를 중심으로 분할은 가능하지만 관 심 객체에 대한 판별과 검출이 불가능하다. 따라서 관 심 객체의 영역에 대한 판별을 위해 첫 번째 단계에서 의 돌출 맵으로 부터 얻어진 객체 후보 영역에 대한 정 보와의 결합이 필요하다.
Pseude code for Zhang-suen Thinning Input: A binary image
Output: The skeleton after thinning
1 Let A(P) be the number of 01 patterns in the order set P2...P9
2 Let B(P) be the number of non-zero neighbors of P
3 Do until image is stable (i.e. no changes made)
4 Sub-iteration 1 : 5 Delete P from image if : 6 a) 2 <= B(P) <= 6
7 b) A(P) = 1 8 c) P2 * P4 * P6 = 1 9 d) P4 * P6 * P8 = 1 10 sub-iteration 2 : 11 a) and b) above 12 c’) P2 * P4 * P8 = 1
13 d’) P2 * P4 * P6 = 1
나. 관심 객체의 세선화
제안하는 방법의 첫 번째 단계에서는 돌출 맵으로 부 터 검출된 관심 객체 후보 영역의 대부분이 객체 뿐만 아니라 배경 영역을 함께 포함하고 있기 때문에 정확한 객체를 검출을 하지 못하는 문제점이 존재한다. 하지만 검출된 관심 객체 후보 영역에서의 배경 영역은 대체로 객체를 중심으로 외곽선에 존재한다는 특징을 갖는다.
따라서 객체 영역을 정확하게 판별하기 위해서 첫 번째 단계에서 생성한 관심객체 후보 영역에 관한 이진화 영 상에 대해서 세선화(skeletonization) 알고리즘을 적용하
(a) (b) (c) (d)
그림 3. 영역 분할 맵과 세선화의 결과 (a)(c) 입력 영상,
(b)(d) 영역분할 맵과 세선화의 결합 영상 Fig. 3. The results of region segmentation map and
skeletonization (a)(c) input image, (b)(d) the overlapped images of region segmentation map and skeletonization.
여 관심객체 영역의 골격 정보를 검출한다. 세선화 기 법은 이진화된 영상에서 골격을 찾는 영상처리 기법으 로써 문자인식, 지문인식, 물체인식 등의 특징 추출을 위한 알고리즘이다. 세선화 검출 시에 관심객체 영역 검출의 정확도를 높이기 위한 전 처리 과정으로써 생성 된 이진화 영상에 대해서 침식(erosion) 모폴로지 (morphology) 연산을 적용하여 배경 영역에서 세선화 가 검출될 가능성을 낮춘다. 검출된 골격은 관심 객체 의 중심 뼈대로서 객체의 중심점을 지나는 주요 특징 점으로 간주될 수 있으며, 객체의 영역 내에서의 위치 정보를 포함한다. 또한 객체의 테두리 영역 밖에 존재 하는 배경 영역에서는 세선화가 검출될 확률이 낮기 때 문에 배경 영역을 효과적으로 제거할 수 있다. 본 논문 에서는 Zhang-Suen 알고리즘 [14]을 이용하여 관심 객 체 후보 영역으로부터 세선화를 검출한다. 이 알고리즘 은 두개의 부분 반복 구조를 갖는다. 마지막 단계에서 는 에지와 색상을 기반으로 한 영역 분할 맵으로부터 객체 후보 영역에서 검출된 골격의 위치 정보를 포함하 는 영역을 관심 객체 영역으로 검출한다. 그림 3(b), 그 림 3(d)는 그림 3(a)와 그림 3(c)의 입력 영상에 대한 영역 분할 맵과 세선화를 결합한 결과를 시각적으로 표 현한 결과이다.
Ⅲ. 실험 결과
본 논문에서는 실험을 위해서 Liu et al.[17]의 자연 영 상 데이터베이스에서 500장의 영상을 테스트 데이터로 사용한다. 실험에 사용된 각 영상의 사이즈는 동일하지 않으며, 평균적으로 300×400의 사이즈를 갖는다. 또한 테스트 영상은 표지판, 사물, 사람, 동물, 꽃 등과 같이 영상마다 대체로 하나의 두드러진 객체를 포함하고 있 으며, 객체의 위치와 크기도 다양하다.
그림 4는 제안하는 방법의 각 단계에 대한 결과를 보 여준다. 그림 4(a)의 입력 영상에 대해서, 4(b)는 HFT 돌출 맵 결과, 4(c)는 영역별로 분할한 결과, 4(d)는 돌 출 맵에 대한 Otsu 이진화 결과, 4(e)는 4(d)의 결과에 서 침식연산 결과 및 세선화 결과를 보여주며, 4(f)는 본 논문에서 제안한 방법을 이용하여 최종 관심 객체를 검출한 결과를 보여준다. 그림 5는 관심 객체 검출을 위해서 돌출 맵을 이용한 기존 방법과 본 논문에서 제 안하는 방법의 결과를 비교하여 보여준다. 본 논문에서
비교한 기존 방법들은 모두 돌출 맵을 기반으로 하여 관심 객체를 자동으로 검출하는 기법들이다.
그림 5(a)는 실험에 사용된 입력 영상이며, 그림 5(b) 는 Liu et al. 이 제안한 방법으로 다중 스케일 대비 (multi-scale contrast), 중앙-주변 히스토그램(center- surround histogram), 그리고 색공간 분포 등의 특징 정보의 집합으로 부터 얻어진 돌출 맵과 CRF (Conditional Random Field)를 이용한 관심 객체 분할 결과이다. 그림 5(c)는Achanta et al. 이 제안한 방법으 로 주파수 영역에서 색상과 밝기 정보를 결합한 특징 정보로 부터 검출된 돌출 영역과 Mean-shift 알고리즘 을 이용한 관심 객체 분할 결과이다. 그림 5(d)는 Xie et al. 이 제안한 방법으로 중간-주변 (center-surround) 기법을 기반으로 낮은(low) 신호와 중간(mid) 신호로 부터 베이지안 모델을 생성함으로써 돌출 맵을 생성하 고, 그래프 컷을 이용하여 관심 객체를 분할한 결과이 다. 그림 5(e)는 본 논문 에서 제안하는 방법을 적용한 관심 객체 분할 결과를 보여준다. 그림 5(f)는 입력 영 상에 대한 정답(ground-truth) 영상으로써 기존 방법들 과 제안하는 방법에 따른 관심 객체 검출 결과에 대한 정성적인 평가 및 정량적인 평가를 위해서 사용된다.
그림 5에서 기존 방법들을 이용하여 관심객체 영역 검 출한 결과를 보면, 관심 객체의 일부분이 검출이 되지 않는 미검출(under-extracted)된 영역이 발생하거나 관 심 객체 이외의 영역이 함께 검출되는 과검출 (over-extracted)된 영역이 나타나는 것을 볼 수 있다.
기존 방법들과 비교하여, 제안하는 방법은 관심 객체 영역이 정답 영상과 비교하였을 때 유사하게 검출되는 것을 확인 할 수 있다. 제안하는 방법의 결과가 기존 방 법들에 비해 관심 객체 영역 검출에 대한 정확도가 높 지만, 제안하는 방법 또한 미검출 영역과 과검출 영역 이 존재하는 경우가 발생한다.
그림 6과 그림 7은 제안하는 방법에서 미검출된 영역 이 발생한 경우의 결과와 과검출된 영역이 발생한 경우 의 결과를 보여준다. 그림 6의 결과를 보면, 사람의 시 각으로 판단 할 때는 동일한 객체 영역으로 인지를 할 수 있지만 객체의 색상과 밝기 값이 객체 주변과 더 유 사함을 보이거나 동일한 색상의 객체지만 명암의 차이 가 큰 경우에 동일한 객체로 인지를 하지 못함으로써 미검출 영역이 발생하는 것을 볼 수 있다.
또한 그림 7의 결과를 보면, 하나의 객체가 아닌 여
(a) (b) (c) (d) (e) (f) 그림 4. 제안하는 방법의 각 단계별 결과 및 관심 객체 검출 결과
(a) 입력 영상 (b) HFT의 결과 (c) 영상 분할의 결과 (d) HFT의 Otsu 이진화 결과
(e) 이진화 결과에 대한 침식 연산 및 세선화 결과 (f) 제안하는 방법을 이용한 관심 객체 검출 결과 Fig. 4. The result of per step of the proposed method and detection of OOI (a) input images (b) the results of HFT
(c) the results of image segmentation (d) the results of Otsu’s thresholding in HFT (e) the results of erosion morphology and skeletonization in binary images (f) the results of detection of OOI using the proposed method.
(a) (b) (c) (d) (e) (f) 그림 5. 기존 방법과 제안하는 방법의 관심 객체 검출 결과 비교
(a) 입력 영상 (b) [17]의 결과 (c) [19]의 결과 (d) [22]의 결과
(e) 제안하는 방법의 결과 (f) 관심 객체에 대한 정답 (ground-truth) 영상 Fig. 5. Performance comparison of existing methods and the proposed method.
(a) input images (b) the results of [17] (c) the results of [19] (d) the results of [22]
(e) the results of proposed method (f) ground-truth images of OOI.
그림 6. 제안하는 방법의 결과에서 미검출된 영역이 존 재하는 경우의 예 (a) 입력 영상 (b) 관심 객체 에 대한 정답 영상 (c) 미검출된 영역을 포함한 결과 영상
Fig. 6. In the result of the proposed method, an example of case that under-extracted regions exist, (a) input images, (b) ground-truth images of OOI, (c) the result images including under-extracted regions.
러 개의 객체가 관심 객체인 경우에 세선화 검출 단계에 서 이를 하나의 객체로 인식하여 객체와 객체 사이의 영 역이 함께 검출되는 경우, 시각적으로 판단했을 때의 관 심 객체 영역과 정답 영상의 관심 객체의 영역의 판 단차 이가 큰 경우, 객체에 초점을 맞춰서 배경이 흐려졌을 때 객체와 밀접하게 연결되어 있는 또 다른 객체도 선명하 게 나온 경우 등에서 관심 객체 영역으로 잘못 판단하여 과검출이 되는 경우가 발생하는 것을 볼 수 있다.
라서 본 논문에서는 미검출된 결과와 과검출된 결과를 모두 고려한 정량적인 평가를 위해서, 검출한 관심 객 체 영역에 대한 정확률(precision)과 재현율(recall)을 계 산하고, 이를 이용하여 정밀도(accuracy)를 계산한다.
정확률은 검출된 객체 영역에 대하여 정답 영역이 속하 는 정도를 의미하고, 재현율은 정답 객체 영역에 대하 여 검출된 객체 영역이 속하는 정도를 의미한다. 하지 만 이 측정 방법은 각각 미검출 영역과 과검출 영역이 발생함에 따른 오류를 포함하고 있다. 미검출 영역에 대한 오류는 검출된 객체 영역이 정답 영역에 비해 작
그림 7. 제안하는 방법의 결과에서 과검출된 영역이 발 생한 경우의 예 (a) 입력 영상 (b) 관심 객체에 대한 정답 영상 (c) 과검출된 영역을 포함한 결 과 영상
Fig. 7. In the result of the proposed method, an example of case that over-extracted regions exist, (a) input images, (b) ground-truth images of OOI, (c) the result images including over-extracted regions.
은 영역으로 검출된 경우에 발생하고, 과검출 영역에 대한 오류는 검출된 객체 영역이 정답 영상보다 더 많 은 영역을 포함하고 있는 경우에 발생한다.
따라서 정밀도는 정확률과 재현율에서 발생하는 오 류의 정도를 고려하여 정답 영상에 대한 검출된 객체 영역에 대한 정밀도를 측정한다. 본 논문에서 사용된 정확률과 재현율 그리고 정밀도에 대한 계산 방법은 다 음 식(19)-식(23)와 같다.
P r
∩
× (19)
∩
× (20)
max
× (21)
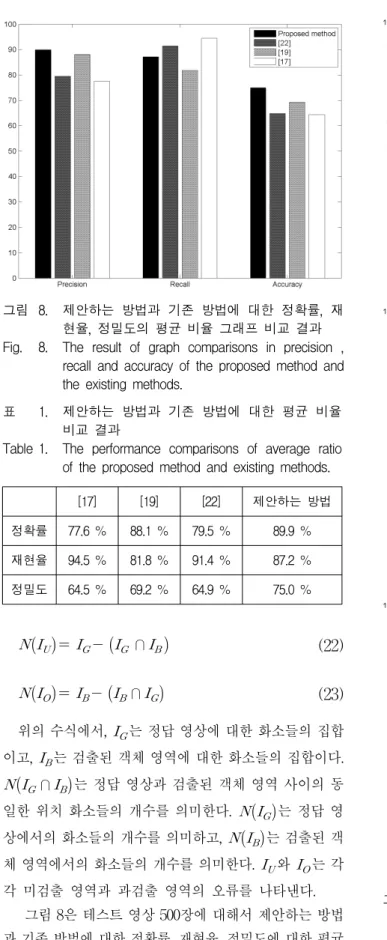
그림 8. 제안하는 방법과 기존 방법에 대한 정확률, 재 현율, 정밀도의 평균 비율 그래프 비교 결과 Fig. 8. The result of graph comparisons in precision ,
recall and accuracy of the proposed method and the existing methods.
[17] [19] [22] 제안하는 방법 정확률 77.6 % 88.1 % 79.5 % 89.9 % 재현율 94.5 % 81.8 % 91.4 % 87.2 % 정밀도 64.5 % 69.2 % 64.9 % 75.0 % 표 1. 제안하는 방법과 기존 방법에 대한 평균 비율
비교 결과
Table 1. The performance comparisons of average ratio of the proposed method and existing methods.
∩ (22)
∩ (23) 위의 수식에서, 는 정답 영상에 대한 화소들의 집합 이고, 는 검출된 객체 영역에 대한 화소들의 집합이다.
∩는 정답 영상과 검출된 객체 영역 사이의 동 일한 위치 화소들의 개수를 의미한다. 는 정답 영 상에서의 화소들의 개수를 의미하고, 는 검출된 객 체 영역에서의 화소들의 개수를 의미한다. 와 는 각 각 미검출 영역과 과검출 영역의 오류를 나타낸다.
그림 8은 테스트 영상 500장에 대해서 제안하는 방법 과 기존 방법에 대한 정확률, 재현율, 정밀도에 대한 평균 비율에 대한 그래프를 보여준다. 그림 9는 테스트 영상 500장에 대하여 제안하는 방법과 기존 방법들[17, 19, 22]의
그림 9. 테스트 영상 500장에 대한 각 정확률, 재현율, 정밀도의 내림차순 결과 그래프 (a) 정확률, (b) 재현율, (c) 정밀도
Fig. 9. The result of descending order graph of precision, each recall and precision about 500 test images (a) precision (b) recall (c) accuracy.
정확률, 재현율, 그리고 정밀도에 대한 측정 결과를 내림 차순으로 정렬한 결과를 보여준다. 그림 9(a), (b), (c)에 서 축은 테스트 영상의 개수를 의미하고, 축은 각각 정확률, 재현율, 정밀도에 대한 비율을 나타낸다. 그림 9(a)의 정확률의 경우, 제안하는 방법이 기존 방법에 비 해 높은 것을 볼 수 있으며, 기존의 방법 중에서는 [19]의 방법이 가장 높은 결과를 보이고, [17]의 방법이 가장 낮 은 결과를 보인다. 반면에, 그림 9(b)의 재현율의 결과는 정확률과는 반대의 양상이 나타나고 있음을 알 수 있다.
기존 방법 중에서 정확률이 가장 높았던 [19]의 방법이 가장 낮은 결과를 보이고, 가장 낮았던 [17]의 방법이 가 장 높은 결과를 보이는 것을 볼 수 있다. 또한 제안하는 방법은 세 번째로 높은 비율을 보이고 있다. 실험 결과, 정확률에서 높은 비율을 나타냈던 경우에는 재현율에서 는 낮은 비율로 나타나고, 정확률에서 낮은 비율을 보였 던 경우에는 재현율이 높은 비율로 나타났다. 이와 같이 정확률의 경우에는 미검출 오류가 발생할 가능성이 존재 하고, 재현율의 경우에는 과검출 오류가 발생할 가능성이 존재한다. 따라서 수식 (21)-(23)를 이용하여 미검출과 과검출에 대한 오류를 모두 고려한 정밀도를 계산하고, 그 결과는 그림 9(c)에 보여 진다.
또한 표 1은 각 평균 비율에 대한 정량적 수치로 비 교하여 보여준다. 제안하는 방법의 정밀도가 75.0%, [17]의 방법이 64.5%, [19]의 방법이 69.2%, [22]의 방법 이 64.9%로써, 제안하는 방법이 기존 방법들에 비해 평균적으로 각각 16.3%, 8.4%, 15.6% 향상된 결과를 보여주고 있다.
Ⅳ. 결 론
본 논문에서는 일반적인 자연 영상에서 자동으로 관 심 객체를 검출하기 위해서 사람의 시각 인지 시스템과 유사한 방법으로 검출된 두드러진 영역에 대한 정보와 영역 분할 정보를 이용한 검출 기법을 제안하였다. 실 험 결과, 제안하는 방법은 기존의 자동 관심 객체 검출 방법에 비해서 언더 검출 및 오버 검출에 대한 문제점 을 보안함으로써 평균 정밀도가 약 13.4% 향상된 성능 을 보였다. 하지만 본 논문에서 제안하는 방법이 재현 율에서 다소 낮은 비율을 보이는 것을 확인하였다. 따 라서 향후 과검출에 대한 오류를 줄임으로써 정밀도를 보다 높일 수 있는 연구가 필요하다.
REFERENCES
[1] S. C. Zhu and A. Yuille, “Taratorin, Magnetic Information Storage Technology, Region competition: Unifying snakes, region growing, and bayes/mdl for multiband image segmentation,” IEEE Transaction on Pattern Recognition and Machine Intelligence, vol. 18, no 9, pp. 884–900, August 1996.
[2] M. Rousson, T. Brox, and R. Deriche, “Active unsupervised texture segmentation on a diffusion based feature space.” In Proc. of IEEE Conference on Computer Vision and Pattern Recognition, vol 2, pp. 699–704, Madison, Wisconsin, June 2003.
[3] C. Rother, V. Kolmogorov, and A. Blake.
“grabcut–interactive foreground extraction using iterated graph cuts,“ ACM Transactions on Graphics (SIG-GRAPH’04), pp. 309–314, 2004.
[4] Y. Boykov and V. Kolmogorov, “An Experimental Comparison of Min-Cut/Max-Flow Algorithms for Energy Minimization in Vision,”
IEEE Transaction Pattern Analysis and Machine Intelligence, vol. 26, no. 9, Sept. 2004
[5] N. Paragios and R. Deriche. “Geodesic active regions and level set methods for supervised texture segmentation,” International Journal of Computer Vision, pp. 223–247, 2002.
[6] A. Blake, C. Rother, M. Brown, P. P´erez, and P. Torr, “Interactive image segmentation using an adaptive gaussian mixture mrf model,” In Proc. of the 8th European Conference on Computer Vision, pp. 428–441, 2004.
[7] M. Rousson, T. Brox, and R. Deriche, “Active unsupervised texture segmentation on a diffusion based feature space.” In Proc. of IEEE Conference on Computer Vision and Pattern Recognition, vol. 2, pp. 699–704, June 2003.
[8] G. Hua, Z. Liu, Z. Zhang, and Y Wu. Automatic segmentation of objects of interest from an image. Technical Report 2006-10, Microsoft Research, Redmond, WA, January 2006.
[9] Y. Boykov and M. Jolly, “Interactive graph cuts for optimal boundary & region segmentation of objects in ND images,” in Proc. of IEEE Conference on Computer Vision and Pattern Recognition, vol. I, pp. 105-112, July 2001.
[10] Y. Boykov and G. Funka-Lea, “Graph cuts and efficient nd image segmentation,” International Journal of Computer Vision, vol. 70, no. 2, pp.