한국정보통신학회논문지 Vol. 25, No. 4: 523~529, Apr. 2021
FPN(Feature Pyramid Network)을 이용한 고지서 양식 인식
김대진1·황치곤2·윤창표3*
Recognition of Bill Form using Feature Pyramid Network
Dae-Jin Kim
1· Chi-Gon Hwang
2· Chang-Pyo Yoon
3*1
Assistant Professor, Institute for Image & Cultural Contents, Dongguk University, Seoul, 04626 Korea
2
Invited Professor, Dept. of Computer Engineering, IIT, Kwangwoon University, Seoul, 01897 Korea
3*
Assistant Professor, Dept. Of Computer & Mobile Convergence, GyeongGi University of Science and Technology, Siheung-si, 15073 Korea
요 약
4차산업 혁명 시대를 맞아, 기술의 변화가 다양한 분야에 적용되고 있다. 고지서 분야에서도 자동화, 디지털화, 데 이터관리가 되고 있다. 사회에서 유통되는 고지서의 형태는 수만 가지 이상이며, 이를 자동화, 디지털화, 데이터관리 를 위해서는 고지서 인식이 필수적이다. 현재 다양한 고지서들을 관리하기 위해서 OCR(Optical Character Recognition) 기술을 활용한다. 이때, 정확도를 높이기 위해, 먼저 고지서 양식을 인식하면, OCR 인식 시 더 높은 인 식률을 가질 수 있다. 본 논문에서는 고지서 양식을 구분하기 위해 인덱스로 사용할 수 있는 로고를 객체 인식하였으 며, 이때 로고의 크기가 전체 고지서 대비 작으므로 딥러닝 기술 중 FPN(Feature Pyramid Network)을 작은 객체 검출 에 활용하였다. 결과적으로, 제안하는 알고리즘을 통해서 자원 낭비를 줄이고, OCR 인식 정확도를 높일 수 있었다.
ABSTRACT
In the era of the Fourth Industrial Revolution, technological changes are being applied in various fields. Automation digitization and data management are also in the field of bills. There are more than tens of thousands of forms of bills circulating in society and bill recognition is essential for automation, digitization and data management. Currently in order to manage various bills, OCR technology is used for character recognition. In this time, we can increase the accuracy, when firstly recognize the form of the bill and secondly recognize bills. In this paper, a logo that can be used as an index to classify the form of the bill was recognized as an object. At this time, since the size of the logo is smaller than that of the entire bill, FPN was used for Small Object Detection among deep learning technologies. As a result, it was possible to reduce resource waste and increase the accuracy of OCR recognition through the proposed algorithm.
키워드
: 고지서 양식, FPN, 작은 객체 검출, 딥러닝, OCR
Keywords
: Bill form, Feature pyramid network, Small object detection, Deep learning, Optical character recognition
Received 29 January 2021, Revised 24 February 2021, Accepted 8 March 2021
* Corresponding Author Chang-Pyo Yoon(E-mail:[email protected], Tel:+82-31-496-6410)
Assistant Professor, Dept. Of Computer & Mobile Convergence, GyeongGi University of Science and Technology, Siheung-si, 15073 Korea
Open Access
http://doi.org/10.6109/jkiice.2021.25.4.523
print ISSN: 2234-4772 online ISSN: 2288-4165Ⅰ. 서 론
최근 과학기술의 발전에 따라 금융, 핀테크 등 다양한 산업에 빠르게 변화를 일으키고 있으며, 이러한 변화를 4차 산업혁명으로 비유되고 있다. 이런 ICT 기술의 혁 신은 정보 통신을 기반으로 기존의 금융업 등과 융합하 여 새로운 서비스 형태로 변화하고 있다. 특히 금융과 ICT 기술의 결합은 결제 시장의 변화를 가져왔고, 국내 시장도 카카오페이, 네이버페이, 삼성페이 등이 지급 결 제 시장을 선도하고 있다.
이러한 변화는 지방세 및 각종 공과금 고지서 등과 같 은 과금 분야에 새로운 방향을 제시하고 있다. 정부에서 도 새로운 온라인 수납체계를 위해 ‘스마트 고지서’와 같은 발전 방향을 지향하고 있다[1]. 이러한 변화에도 불구하고, 모든 고지서 양식이 통일되지 않고, 그 수는 너무나도 다양하므로 자동화, 디지털화, 데이터관리를 위한 방안이 필요하다. 본 논문에서는 오프라인으로 발 행된 다양한 고지서들을 작은객체검출(Small Object Detection)을 통해서 고지서 양식을 인식함으로써, OCR (Optical Character Recognition) 적용 시 리소스 낭비를 줄이고, 인식 정확도를 높일 수 있는 연구를 진행하였다.
기존의 객체 인식은 크게 2가지 방식으로 나누어진 다. 첫째, Two Stage Detector의 기술로 R-CNN[2], Fast R-CNN[3], Faster R-CNN[4], SPP-Net[5], R-FCN[6] 등 이 속한다. 선택적 검색에 의한 지역검출 및 예측과 관 심 영역(ROI)의 분류에 의해서 해당 객체의 구분을 하 는 방식이다. 둘째, One Stage Detector의 기술로 YOLO[7], YOLOv3[8], RetinaNet[9], SSD(Single Shot Detector)[10] 등이 속한다. 이는 관심 영역과 객체 구분 은 한 단계에서 진행하는 방식이다. 이들의 장점은 아래 와 같다.
-. Two Stage Detector : 정확도 부분 비교 우위 -. One Stage Detector : 속도 부분 비교 우위
각각의 방식은 적용 사업 모델에 따라 선택을 하면 된다.
본 모델의 경우는 속도의 이점을 가져가기 위해서 One Stage Detector를 사용하였고, 정확도를 높이기 위 해 FPN(Feature Pyramid Network)의 기술을 이용하였 다. 제안하는 모델은 이미지 인식을 통해서 고지서를 구 분하는 기술이기 때문에 고지서를 구분할 수 있는 작은 객체에 대한 인식이 중요하다. 기존의 Detector 기술은
CNN(Convolution Neural Network)과 Pooling을 기반 으로 객체 검출을 하므로 작은 객체 검출이 안 되는 경 우가 많다. 이 부분을 개선하기 위해서 FPN을 이용하여 고지서 인식의 성능을 높였다.
본 논문에서는 고지서 양식을 먼저 인식함으로써 고 지서 인식의 속도와 정확도를 높일 수 있는 알고리즘에 관하여 연구하였다. 2장에서는 기존 객체 인식에 대표 적인 YOLOv3를 이용하여 고지서 양식 인식에 적용하 였고, 이를 적용했을 때의 문제점들을 알아본다. 3장에 서는 객체 인식률을 높일 수 있는 FPN을 적용하여 문제 점 개선 방안을 연구하였다. 4장에서는 제안한 알고리 즘을 기반으로 고지서 양식 인식을 구현해 보고, 5장에 서 결론을 지었다.
Ⅱ. 본 론
2.1. 고지서 구분 환경
Fig. 1 Bill Environment
그림 1과 같은 고지서들을 구분하기 위해서 1차적으 로 고지서 양식의 구분이 필수적이다. 고지서 내용을 인 식하기 위해서 OCR 엔진을 통해 인식하는 것이 필요하 다. 그러나 고지서 내용 분석을 위해 고지서 전체를 인 식하면, 입력 영상의 상태에 따라서 인식의 정확도, 리 소스 문제 등이 발생할 수 있다. 이런 문제 등을 개선하 기 위해 고지서 양식 구분을 먼저 진행함으로써, 리소스 및 인식률 개선에 도움이 될 수 있다.
고지서 인식을 위해 스캔을 하거나, 사진으로 촬영하
는 경우 고지서의 해상도는 약 1600x2200 정도 된다. 전
체 이미지의 글자 인식 시 OCR 엔진을 통해서 5~10초
의 시간이 소요된다. 또한, 입력 이미지의 상태에 따라
화질 개선, 좌표이동 등의 영상처리가 같이 동반되었을
때, 인식률을 더 높일 수 있다. 이 부분까지 고려한다면,
더욱 많은 리소스와 인식 소요 시간이 소요 된다.
따라서 고지서 양식을 먼저 인식함으로써 성능을 개 선할 수 있다. 고지서 인식의 절차를 보면 그림 2와 같 다. 먼저 스캔이나, 카메라로부터 이미지를 입력받고, 원하는 정보의 정확한 좌표정보를 얻기 위해서 이미지 크기를 고정한다. 본 논문에서는 입력 이미지를 1600x 2200으로 크기변환 한다. 변환된 이미지로부터 글자인 식의 정확도를 높이기 위해 화질 개선을 적용한다. 이후 대표가 되는 고지서의 로고를 인식함으로써 고지서 양 식을 인식한다. 인식된 고지서 양식은 미리 저장된 필수 인식 요소의 좌표 부분에 대해서만 OCR 인식을 진행한 다. 데이터베이스화할 때 필요 글자만 처리하면 되기 때 문에 해당 고지서의 지정된 좌표를 이용하면 효율적이다.
고지서 양식 인식을 할 때 중요한 요소는 로고를 통한 고지서 구분이다. 고지서마다 고유의 로고가 있으므로 구분 시 인덱스(Index)로 사용할 수 있다. 그러나 1600x 2200의 이미지 중 로고가 차지하는 해상도는 약 100x100 정도밖에 되지 않기 때문에 Small Object Detection이 핵심 기술이다. 기존의 Object Detection 중 서비스 개발 시 속도와 정확도를 모두 만족시킬 수 있는 One Stage
Model 중 대표적인 YOLOv3를 이용하여 Object Detection 을 할 수 있다.
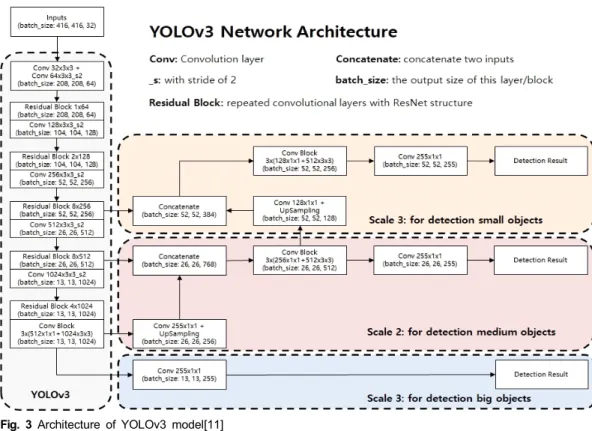
2.2. YOLOv3를 이용한 Small Object Detection Darknet-53을 Backbone[8]으로 하고 Head를 YOLOv3 로 하여 Object Detection을 할 수 있다. 그림 3은 해당
Fig. 3 Architecture of YOLOv3 model[11]
Fig. 2 Bill Recognition Process
모델 구조를 나타낸다.
일반적으로 사용되는 Backbone에서는 Convolution Layer가 적용된다. Stride2를 사용한 Max Pooling 및 Convolution 연산은 다운 샘플링한 Feature Map에 적용 된다. Pooling과 Convolution을 통해서 객체에 대한 의 미 있는 정보들을 모으고, 객체 검출 시 유용하게 사용 할 수 있다. 그러나, Feature Map의 공간 해상도(Spatial Resolution)가 감소하기 때문에 Small Object를 검출할 때 검출률이 낮을 수 있다. 반면, Small Object를 검출하 기 위해서 공간 해상도가 큰 네트워크 레이어에서 Object Detection을 하는 경우 의미 있는 정보들이 부족 할 수 있다. Small Object를 검출하기 위해서 수용영역 정보를 가진 Feature Map과 공간 해상도와는 서로 Trade Off가 필수적인 문제로 발생한다.
Fig. 4 Trade-off between high receptive field and high spatial resolution
그림 4에서는 이 Trade Off에 대하여 자세히 보여준 다. Layer가 진행될수록 의미 있는 정보를 가질 수 있으 나, Small Object에 대한 자세한 정보를 상실할 수 있어, 인식률이 떨어질 수 있다.
그러나 기존의 Backbone에서 YOLOv3를 Head를 가 지고 Small Object를 검출하는 경우 여전히 Trade Off 문제를 해결하는 데는 문제점을 가지고 있으므로 이를 개선하는 방향이 필수적이다.
Ⅲ. 제안하는 고지서 인식
3.1. FPN(Feature Pyramid Network)
신경망을 통과하고 나면 단계별로 Feature Map들을 생성한다. 상위 레이어로부터 Feature들을 통합(Merge)
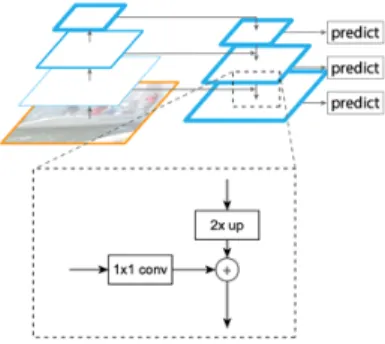
한 후 Object Detection을 진행한다. 그림 5와 같이 상위 레이어에서 뽑은 Feature Map과 하위 레이어에서 추출 된 Feature Map들의 정보들을 기반으로 Small Object에 대한 인식률을 높일 수 있다. 이때 각각의 레이어로부터 뽑은 Feature Map들을 통합하는 방식은 그림 6과 같다.
Fig. 6 Nearest Neighbor Upsampling
CNN을 기본 아키텍처로 가져가는 모델의 경우 각각 의 레이어를 통과하게 되면 해상도가 2배씩 작아질 수 있다. 따라서 상위 Feature Map과 하위 Feature Map을 합쳐주기 위해서 해상도를 통일시켜야 한다. 본 논문에 서는 최근접이웃보간법(Nearest Neighbor Upsampling) 방법을 이용하여 상위 Feature Map의 해상도를 2배씩 조정하였다.
이후 하위 Feature Map에 1x1 Convolution을 수행하 여 상위 Feature Map과 같은 채널 수를 가지도록 한다.
해상도와 채널 수를 모두 통일한 후 두 Feature Map을 Elementwise 덧셈을 통해서 새로운 Feature Map을 구성 하고 여기서 Object Detection을 적용 한다.
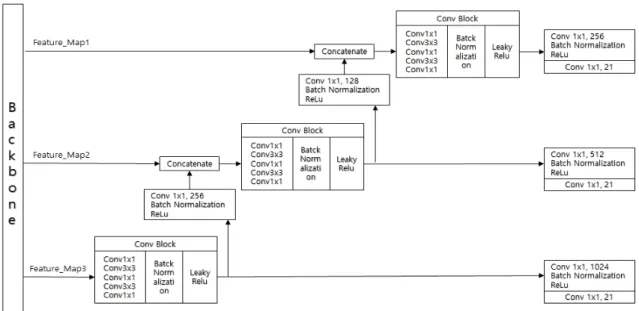
그림 7에서는 Head에서 사용된 FPN을 통하여 Feature Map을 통합하는 모델을 보여준다.
Feature_Map3에서는 상위단계에서 의미 있는 정보 를 가지기는 하나, Small Object에 대한 정보는 여전히
Fig. 5 Feature Pyramid Network[12]
검출이 안 될 수 있다. 반면, 상위단계의 정보와 하위단 계의 정보가 결합된 Feature_Map1에서는 Small Object 에 대한 검출이 가능하다.
이후 여러 단계의 Feature Map을 구성을 통해서 Object Detection을 한 후에는 Bounding Box 예측을 진 행한다. Head Detector가 이미지 크기의 개연성을 가지 기 위해서 Fully Connected Network를 사용하기보다는 Fully Convolution Network를 사용하여 어떠한 크기의 이미지가 입력되더라도 검출할 수 있도록 한다.
3.2. NMS(Non-Maximum Suppression)
Detector의 Head 출력은 같은 Ground Truth에 대해 서로 겹치는 Bounding Box를 생성한다. 따라서, 최종 검출하기 전에 겹친 Bounding Box를 제거하고 필터링 해야 한다. NMS는 중복된 Bounding Box를 제거하려는 방법이다. NMS는 실제로 존재하는 대상과 같은 예측값 을 가지기 위해 적용한다.
Object Detection 알고리즘의 선천적 불완전성으로 인해 실제 위치 주변에 여러 감지 그룹이 생성된다[13].
NMS는 이상적인 개체의 실제 위치에 해당하는 그룹 당 하나만 탐지한다. 그림 8에서는 고지서 인식에서 NMS 를 적용한 효과를 보여 준다.
Fig. 8 Effect of Applying NMS
Ⅳ. 시스템 구현 결과
4.1. 시스템 구현환경
기존의 One Stage Model 중 대표적인 YOLOv3를 이
용한 고지서 양식 인식과 YOLOv3+FPN을 적용했을 때
의 인식률을 비교하기 위해서 고지서 양식 20가지와 양
식별 200개의 Scan 이미지를 사용하였다. 각 양식의 좌
표정보를 표준화하기 위해서, 이미지의 크기 1600x2200
으로 크기변환을 하였으며, 각 양식에 필수 인식 좌표정
보를 미리 데이터베이스화했다. 필수 인식 좌표정보에
사용되는 것은 이름, 주소, 납부금액, 납부자 번호, 수납
은행, 납기 기간, 납부기한 후 연체료 정보를 사용하였
다. 인식 엔진 장비는 OS가 64bit Windows 10에
Intel(R) core(TM) i5-7500 [email protected], 메모리는
24Gbyte를 사용하였으며, YOLOv3를 이용한 객체 검
Fig. 7 Head of Detector(FPN)출 시 GPU를 사용하였고, Graphic Card는 RTX2080TI 를 사용하였다. YOLOv3 구현 시 Darknet[14]을 사용하 여 구현하였으며, 개발 언어는 Python을 사용하였다.
4.2. 데이터 학습 과정
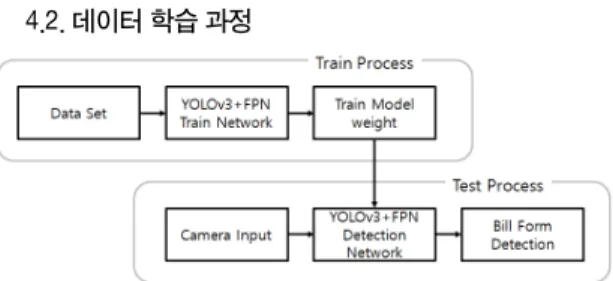
Fig. 9 Object Train & Detection Processing using YOLOv3+FPN
본 논문에서 YOLOv3+FPN을 이용한 객체 학습 및 검출과정은 그림 9와 같다. 고지서 내에 검출해야 할 객 체를 20가지로 Class를 구성하였으며, YOLOv3+FPN 의 Custom Object 학습 방법을 통해서 20가지 고지서 로고 객체를 학습하였다[15].
4.3. 시스템 성능 비교
Table. 1 Algorithm ComparisonMethods mAP(%)
YOLOv3 71.41
YOLOv3+FPN 98.89
표 1에서는 기존 YOLOv3 알고리즘과 제안한 YOLOv3+FPN 알고리즘의 인식률 성능 비교를 하였다.
YOLOv3에서도 Scale 1, 2단계에서는 Small Object에 대한 검출이 이루어지지 않아, 비교단계에서 배제하였 고, Scale 3단계에 대해서만 성능 비교하였다. 또한, YOLOv3+FPN에서도 검출 성능이 가장 좋은 Feature_
Map1 단계만 성능 비교를 하였다. 정답을 맞춘 판정 기준 은 APIoU=.75 이며, 기준 신뢰도(Confidence Threshold) 를 0.7로 하였다. 이 기준으로 실험한 결과 YOLOv3+FPN 알고리즘에서 더 좋은 결과를 보였다. 여기서 mAP (Mean Average Precision)는 각 클래스에 대한 AP (Average Precision)의 평균값을 나타내며, IOU(Intersection Over Union)는 Object Detector가 실제 Ground Truth와 예측결과(Prediction)가 얼마나 정확히 겹치는지를 계산 한 값이다. 만약 mAP가 99%이상이 되면 상용화가 가능
한 수준이 될 것으로 판단된다.
Ⅴ. 결 론
본 논문에서는 고지서 양식 인식을 통해서 OCR 대상 이 되는 고지서 인식 성능 최적화를 목표로 한다. 고지 서 양식을 구분하기 위해 인덱스로 사용할 수 있는 로고 를 인식하였으며, 이때 로고의 크기가 전체 고지서 대비 작으므로 Small Object Detection 기술이 필수적이다.
본 논문에서는 FPN을 통해서 기존의 Object Detection 보다 고지서 인식의 정확도 높일 수 있었다. 추후 인식 정확도를 높이기 위해서 다른 Backbone을 사용하거나, Head 부분을 교체하여 실험했을 때 더 좋은 결과가 나 오는지에 대한 추가 연구가 필요하다.
1차적으로 고지서 양식에 대한 구분이 정확하면, OCR을 통해 인지해야 할 항목이 줄어들고, 이를 통해서 리소스 낭비를 줄이며, OCR 인식 정확도를 높일 수 있 다. 또한, 고지서의 특징상 과금과 연계할 수 있으므로, 최근에 오픈된 Open Banking API를 통해서 과금 자동 납부까지 연동할 수 있는 장점이 있다. 이들 기술을 연 동하여 사용자가 핸드폰으로 찍어서 바로 과금과 연결 하는 서비스와 연동 한다면, 사용자 편의성을 더욱 높일 수 있다. 따라서 제안하는 알고리즘을 통해서 정확도 높 고, 고효율의 고지서 과금 시스템을 만들 수 있다.
References
[ 1 ] S. B. Lim and S. M. Cha, “A Study on Promotion Plan of Local Taxpayer Convenience through ICT Technologies - Focus on Intelligent Tax Bill in Gyeonggi Local Government,” Korea Association of Tax and Acccounting, vol. 49, no. 0, pp. 95-116, 2016.
[ 2 ] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 580-587, 2014.
[ 3 ] R. Girshick, “Fast r-cnn,” Proceedings of the IEEE international conference on computer vision, pp. 1440-1448, 2015.
[ 4 ] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn:
Towards real-time object detection with region proposal
networks,” Advances in neural information processing systems, pp. 91-99, 2015.
[ 5 ] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 9, pp. 1904-1916, 2015.
[ 6 ] J. Dai, Y. Li, Y, K. He, and J. Sun, “R-fcn: Object detection via region-based fully convolutional networks,” Advances in neural information processing systems, pp. 379-387, 2016.
[ 7 ] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” In:
Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779-788, 2016.
[ 8 ] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
[ 9 ] T. Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár,
“Focal loss for dense object detection,” Proceedings of the IEEE international conference on computer vision, pp.
2980-2988, 2017.
[10] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y.
Fu, and A. C. Berg, “Ssd: Single shot multibox detector,”
European conference on computer vision, Springer, pp.
21-37, 2016.
[11] Y. Gao, “A One-stage Detector for Extremely-small Objects Based on Feature Pyramid Network,” University essay from KTH/Skolan för elektroteknik och datavetenskap (EECS), 2020.
[12] T. Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S.
Belongie, “Feature pyramid networks for object detection,”
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 1, pp. 936-944, 2017.
[13] R. Rothe, M. Guillaumin, and L. V. Gool, “Non-maximum suppression for object detection by passing messages between windows,” Asian Conference on Computer Vision, Springer, pp. 290-306, 2014.
[14] Darknet: Open source neural networks in C [Internet].
Available: http://pjreddie.com/darknet/.
[15] Darknet Custom Object Train [Internet]. Available:
https://github.com/AlexeyAB/darknet#how-to-train-to-dete ct-your-custom-objects.
김대진(Dae-Jin Kim)
1998년 대진대학교 전자공학과 (공학사) 2000년 대진대학교 전자공학과 (공학석사) 2010년 대진대학교 전기전자통신공학과 (공학박사) 2017년~현 재: 동국대학교 영상문화콘텐츠연구원 교수
※관심분야:코덱, 멀티미디어 플랫폼, 콘텐츠 DNA, 워터마크, 딥러닝 등
황치곤(Chi-Gon Hwang)
2012년 광운대학교 컴퓨터과학과 (공학박사) 2006년~2015년:(주)인찬 연구원
2016년~2018년: 경민대학교 인터넷정보과 교수
2019년~현 재: 광운대학교 정보과학교육원 컴퓨터공학과 교수
※관심분야:모바일 클라우드, 온톨로지, 기계학습, NLP
윤창표(Chang-Pyo Yoon)
1998년 광운대학교 전자계산학과 (이학사) 2001년 광운대학교 컴퓨터과학과 (공학석사) 2012년 광운대학교 컴퓨터과학과 (공학박사)
2012년~현 재: 경기과학기술대학교 컴퓨터모바일융합과 교수
※관심분야:기계학습, 모바일 시스템, 네트워크 보안, 무선 네트워크