2019, 30
(2)
,349–363
영상에서 패치기반 CNN 모형을 이용한 잡음제거
†
ᄒ
ᅥ광해
1
· 임동훈2
12경상대학교 정보통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2019ᄂ ᅧ ᆫ 2ᄋ ᅯ ᆯ 6ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 3ᄋ ᅯ ᆯ 4ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 3ᄋ ᅯ ᆯ 10ᄋ ᅵ ᆯ
요 약
ᄋ ᅧ
ᆼᄉ ᅡ ᆼᄋ ᅦᄉ ᅥ ᄌ ᅡ ᆸᄋ ᅳ ᆷ ᄌ ᅦᄀ ᅥᄂ ᅳ ᆫ ᄑ ᅢᄐ ᅥ ᆫᄋ ᅵ ᆫᄉ ᅵ ᆨ, ᄋ ᅧ ᆼᄉ ᅡ ᆼᄋ ᅡ ᆸᄎ ᅮ ᆨ, ᄋ ᅦᄌ ᅵᄀ ᅥ ᆷᄎ ᅮ ᆯ, ᄋ ᅧ ᆼᄉ ᅡ ᆼᄇ ᅮ ᆫ ᄒ ᅡ ᆯᄀ ᅪ ᄀ ᅡ ᇀᄋ ᅳ ᆫ ᄋ ᅧ ᆼᄉ ᅡ ᆼᄎ ᅥᄅ ᅵ ᄇ ᅮ ᆫ ᄋ ᅣᄋ ᅴ ᄌ ᅥ ᆫᄎ ᅥᄅ ᅵᄀ ᅪ ᄌ ᅥ
ᆼᄋ ᅳᄅ ᅩ ᄃ ᅩᄌ ᅥ ᆫᄒ ᅡ ᆯ ᄆ ᅡ ᆫᄒ ᅡ ᆫ ᄀ ᅡᄎ ᅵᄀ ᅡ ᄋ ᅵ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄃ ᅵ ᆸᄅ ᅥᄂ ᅵ ᆼᄋ ᅴ convolutional neural network (CNN) ᄆ ᅩ ᄒ ᅧ
ᆼᄋ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄌ ᅡ ᆸᄋ ᅳ ᆷ ᄌ ᅦᄀ ᅥ ᄒ ᅡᄀ ᅩᄌ ᅡ ᄒ ᅡ ᆫᄃ ᅡ. CNN ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆫ ᄋ ᅧ ᆼᄉ ᅡ ᆼᄋ ᅵ ᆫᄉ ᅵ ᆨ, ᄆ ᅮ ᆯ ᄎ ᅦᄋ ᅵ ᆫᄉ ᅵ ᆨ, ᄋ ᅥ ᆯᄀ ᅮ ᆯᄋ ᅵ ᆫᄉ ᅵ ᆨᄀ ᅪ ᄀ ᅡ ᇀᄋ ᅳ ᆫ ᄏ ᅥ ᆷᄑ ᅲᄐ ᅥ ᄇ ᅵ ᄌ
ᅥ ᆫ ᄆ ᅮ ᆫ ᄌ ᅦᄋ ᅦᄉ ᅥ ᄌ ᅩ ᇂᄋ ᅳ ᆫ ᄉ ᅥ ᆼᄂ ᅳ ᆼᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅵᄀ ᅩ ᄋ ᅵ ᆻᄋ ᅳᄂ ᅡ ᄌ ᅡ ᆸᄋ ᅳ ᆷ ᄌ ᅦᄀ ᅥᄋ ᅦ ᄃ ᅢᄒ ᅢᄉ ᅥᄂ ᅳ ᆫ ᄀ ᅳ ᄌ ᅮ ᆼ ᄋ ᅭᄉ ᅥ ᆼᄋ ᅦ ᄇ ᅵᄎ ᅮᄋ ᅥ ᄋ ᅡᄌ ᅵ ᆨᄁ ᅡᄌ ᅵ ᄋ ᅧ ᆫᄀ ᅮᄀ ᅡ ᄃ ᅥ ᆯ ᄋ
ᅵᄅ ᅮᄋ ᅥᄌ ᅧ ᆻᄃ ᅡ. ᄌ ᅵ ᄀ ᅳ ᆷ ᄁ ᅡᄌ ᅵ ᄋ ᅧ ᆼᄉ ᅡ ᆼᄋ ᅦᄉ ᅥ ᄌ ᅡ ᆸᄋ ᅳ ᆷ ᄌ ᅦᄀ ᅥᄂ ᅳ ᆫ ᄐ ᅳ ᆨᄌ ᅥ ᆼᄒ ᅡ ᆫ ᄇ ᅮ ᆫ ᄑ ᅩ ᄐ ᅳ ᆨᄉ ᅥ ᆼᄋ ᅳ ᆯ ᄀ ᅡ ᆽᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡᄂ ᅳ ᆫ ᄀ ᅡᄌ ᅥ ᆼ ᄒ ᅡᄋ ᅦᄉ ᅥ ᄉ ᅥ ᆯᄀ ᅨ ᄃ ᅬ ᆫ ᄀ ᅩ ᄋ
ᅲᄒ ᅡ ᆫ ᄑ ᅵ ᆯᄐ ᅥᄅ ᅳ ᆯ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄋ ᅵ ᄀ ᅧ ᆼᄋ ᅮ ᄀ ᅡᄌ ᅥ ᆼᄋ ᅳ ᆯ ᄆ ᅡ ᆫᄌ ᅩ ᆨ ᄒ ᅡᄌ ᅵ ᄋ ᅡ ᆭᄂ ᅳ ᆫ ᄑ ᅵ ᆯᄐ ᅥᄅ ᅳ ᆯ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅧ ᆼᄋ ᅮ ᄉ ᅥ ᆼᄂ ᅳ ᆼ ᄋ ᅵ ᄒ ᅧ ᆫᄌ ᅥᄒ ᅵ ᄄ ᅥ ᆯᄋ ᅥᄌ ᅵ ᄂ
ᅳ ᆫ ᄀ ᅧ ᆼᄒ ᅣ ᆼᄋ ᅵ ᄋ ᅵ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄌ ᅡ ᆸᄋ ᅳ ᆷ ᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄉ ᅡᄌ ᅥ ᆫᄌ ᅥ ᆼᄇ ᅩ ᄋ ᅥ ᆹᄋ ᅵ ᄉ ᅡᄋ ᅭ ᆼ ᄀ ᅡᄂ ᅳ ᆼ ᄒ ᅡ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅳᄅ ᅩ ᄋ ᅧ ᆼᄉ ᅡ ᆼᄋ ᅴ ᄌ ᅡ ᆨᄋ ᅳ ᆫ ᄇ ᅳ ᆯᄅ ᅩ ᆨᄋ ᅵ ᆫ ᄑ
ᅢᄎ ᅵ (patch) ᄉ ᅡ ᆼᄋ ᅦᄉ ᅥ CNNᄋ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄀ ᅩ, ᄌ ᅮ ᆼᄎ ᅥ ᆸᄃ ᅬ ᆫ ᄑ ᅢᄎ ᅵ (overlapped patches)ᄋ ᅦᄉ ᅥ ᄒ ᅢᄃ ᅡ ᆼ ᄑ ᅵ ᆨᄉ ᅦ ᆯᄃ ᅳ ᆯ ᄋ ᅴ ᄀ ᅡᄌ ᅮ ᆼ ᄑ ᅧ
ᆼᄀ ᅲ ᆫᄋ ᅳ ᆯ ᄀ ᅮᄒ ᅡᄋ ᅧ ᄌ ᅡ ᆸᄋ ᅳ ᆷ ᄌ ᅦᄀ ᅥ ᄋ ᅧ ᆼᄉ ᅡ ᆼᄋ ᅳ ᆯ ᄋ ᅥ ᆮᄂ ᅳ ᆫ ᄃ ᅡ. CNNᄋ ᅦᄉ ᅥ ᄆ ᅢᄀ ᅢᄇ ᅧ ᆫᄉ ᅮ ᄎ ᅬᄌ ᅥ ᆨᄒ ᅪᄂ ᅳ ᆫ ᄌ ᅡ ᆸᄋ ᅳ ᆷ ᄃ ᅦᄋ ᅵᄐ ᅥᄋ ᅦ ᄌ ᅥ ᆨᄋ ᅳ ᆼᄅ ᅧ ᆨᄋ ᅵ ᄌ ᅩ ᇂᄋ ᅳ ᆫ Adam ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷᄋ ᅳ ᆯ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡ ᆫᄃ ᅡ. ᄋ ᅧ ᆼᄉ ᅡ ᆼᄉ ᅵ ᆯᄒ ᅥ ᆷᄋ ᅳ ᆫ ᄀ ᅡᄋ ᅮᄉ ᅵᄋ ᅡ ᆫ ᄌ ᅡ ᆸᄋ ᅳ ᆷᄋ ᅧ ᆼᄉ ᅡ ᆼᄀ ᅪ ᄋ ᅵ ᆷᄑ ᅥ ᆯᄉ ᅳ ᄌ ᅡ ᆸᄋ ᅳ ᆷᄋ ᅧ ᆼᄉ ᅡ ᆼ ᄆ ᅩᄃ ᅮᄅ ᅳ ᆯ ᄀ ᅩᄅ ᅧᄒ ᅡᄋ ᅧ ᆻᄀ ᅩ ᄉ ᅵ
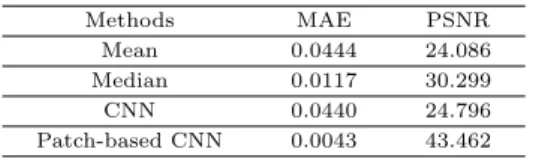
ᆯᄒ ᅥ ᆷᄀ ᅧ ᆯᄀ ᅪ, ᄑ ᅢᄎ ᅵᄀ ᅵᄇ ᅡ ᆫ CNN ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆫ ᄃ ᅡᄅ ᅳ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄇ ᅩᄃ ᅡ ᄌ ᅩ ᇂᄋ ᅳ ᆫ ᄒ ᅪᄌ ᅵ ᆯᄋ ᅴ ᄋ ᅧ ᆼᄉ ᅡ ᆼᄋ ᅳ ᆯ ᄃ ᅩᄎ ᅮ ᆯ ᄒ ᅡᄋ ᅧ ᆻᄀ ᅩ ᄄ ᅩᄒ ᅡ ᆫ MAE (mean absolute error)ᄋ ᅪ PSNR (peak signal-to-noise ratio) ᄆ ᅧ ᆫᄋ ᅦᄉ ᅥᄃ ᅩ ᄌ ᅩ ᇂᄋ ᅳ ᆫ ᄉ ᅥ ᆼᄂ ᅳ ᆼᄋ ᅳ ᆯ ᄌ ᅵᄂ ᅵ ᆷᄋ ᅳ ᆯ ᄋ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄋ ᅥ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄃ ᅵ ᆸᄅ ᅥᄂ ᅵ ᆼ, ᄌ ᅡ ᆸᄋ ᅳ ᆷᄋ ᅧ ᆼᄉ ᅡ ᆼ, ᄌ ᅡ ᆸᄋ ᅳ ᆷ ᄌ ᅦᄀ ᅥ, convolutional neural network.
1. 서론 ᄒ
ᅧᆫ대사회는과학기술의 발달로 인하여 스마트 폰카메라, CCTV, DSLR (digital single-lens reflex), ᄌ
ᅡ동차 블랙박스 등과 같은디지털 영상기기가 보편화됨에 따라 실생활에서 디지털 영상들을자주 접하 ᄀ
ᅩ 있다. 이와 같은과학기술의 발전에도 불구하고 일반적으로 영상의 전송 및 저장하는과정에서 잡음 (noise)이 첨가되어 영상의 질을 저하시킨다. 영상에서 잡음은 디테일 성분과 같이 고주파성분에 해당 ᄃ
ᅬ어 잡음만을제거하는것은 쉽지 않다.
여
ᆼ상에서 존재하는 대표적인 잡음으로는 가우시안 잡음 (Gaussian noise)과 임펄스 잡음 (impulse noise)두 가지 형태의 잡음이 있다. 각각의 잡음을제거하기 위해 고안된고유한 필터들이 존재하고 있 ᄃ
ᅡ. 평균과관련된필터들은가우시안 잡음을제거하는데 주로 사용되고 중앙값과 관련된필터들은 임 퍼
ᆯ스 잡음을제거하는데 사용되고 있다 (Kumar와 Kumar, 2015). 이러한 필터들은잡음이 섞이지 않 ᄋ
ᅳᆫ 픽셀에 대해서도 균일하게 적용되어 그 결과 윤곽선과 같은 중요한 영상 정보를 동시에 열화 (blur- ring)시키는단점을갖고 있다 (Chan 등, 2005; Kim 등, 2015).
†
ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ 2017ᄂ ᅧ ᆫᄃ ᅩ ᄌ ᅥ ᆼᄇ ᅮᄌ ᅢᄋ ᅯ ᆫ (ᄀ ᅭᄋ ᅲ ᆨ ᄀ ᅪᄒ ᅡ ᆨᄀ ᅵᄉ ᅮ ᆯ ᄇ ᅮ)ᄋ ᅳᄅ ᅩ ᄒ ᅡ ᆫᄀ ᅮ ᆨᄋ ᅧ ᆫᄀ ᅮᄌ ᅢᄃ ᅡ ᆫᄋ ᅴ ᄌ ᅵᄋ ᅯ ᆫᄋ ᅳ ᆯ ᄇ ᅡ ᆮᄋ ᅡ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬ ᆫ ᄀ
ᅵᄎ ᅩᄋ ᅧ ᆫᄀ ᅮᄉ ᅡᄋ ᅥ ᆸᄋ ᅵ ᆷ.(NRF-2017R1E1A1A03071057).
1
(52828) ᄀ ᅧ ᆼᄂ ᅡ ᆷ ᄌ ᅵ ᆫᄌ ᅮᄉ ᅵ ᄌ ᅵ ᆫᄌ ᅮᄃ ᅢᄅ ᅩ 501, ᄀ ᅧ ᆼᄉ ᅡ ᆼᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ ᄒ ᅡ ᆨᄇ ᅮᄌ ᅩ ᆯᄋ ᅥ ᆸ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (52828) ᄀ ᅧ ᆼᄂ ᅡ ᆷ ᄌ ᅵ ᆫᄌ ᅮᄉ ᅵ ᄌ ᅵ ᆫᄌ ᅮᄃ ᅢᄅ ᅩ 501, ᄀ ᅧ ᆼᄉ ᅡ ᆼᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ ᄆ ᅵ ᆾ RINS.
E-mail: [email protected]
ᄎ
ᅬ근에 딥러닝 (deep learning)은 컴퓨터 비전 (computer vision), 언어인식 (speech recognition), ᄌ
ᅡ연어 처리 (natural language processing)를 포함한 다양한 인공지능 분야에서 우수한 성능을 보이 ᄀ
ᅩ 있다 (Deng 와 Yu, 2014; Lee, 2017). 딥러닝 (deep learning) 모형 중하나인 convolutional neu- ral network (CNN)은영상인식 (image recognition), 물체인식 (object recognition) 그리고 얼굴인식 (face recognition) 등시각관련 처리를위해 주요한 역할을하고 있다 (Lee 와 Seok, 2018; Sharma 등, 2018).
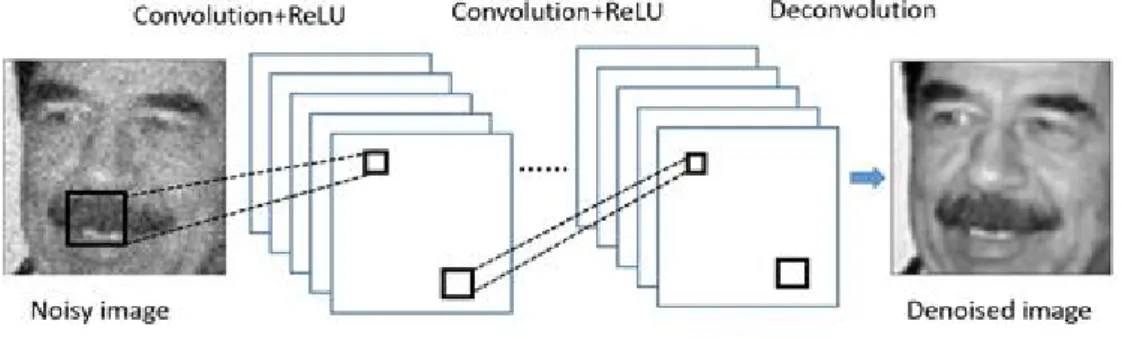
보
ᆫ 논문에서는 CNN 모형을이용하여 영상의 잡음 특성과 분포에 관계없이 사용가능한 잡음제거 방 버
ᆸ을 제안하고자 한다. 지금까지 CNN 모형을 이용한 잡음제거는 몇몇 연구를 제외하고는거의 이루 ᄋ
ᅥ지지 않았다. 기존의 CNN 모형에서 매개변수 최적화는주로 전체영상에서 기존의 SGD (stochastic gradient descent)알고리즘에 의해 이루어져왔다 (Koga 등, 2018). 그러나 SGD 기법은단순하고 구 ᄒ
ᅧᆫ하기 쉬우나 실제 적용에는비효율적이다 (Robbins와 Monro, 1951).
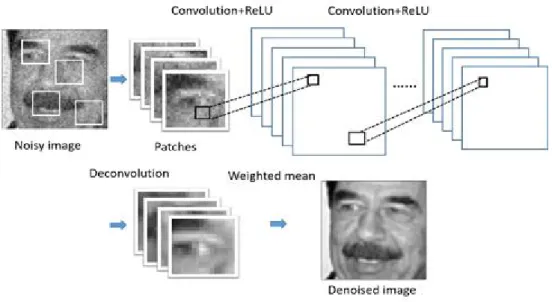
보
ᆫ 논문에서는 중요한 영상 정보를보존하면서 잡음을효과적으로 제거하기 위해 전체영상을작은 윈 ᄃ
ᅩ우인 패치 (patch)들로 나눈후 패치 상에서 CNN 모형을 적용하고자 한다. 최종적으로 복원영상은 주
ᆼ첩된패치 (overlapped patches)에서 해당 픽셀들의 가중평균 (weighted average)에 의해 얻어진다.
ᄋ
ᅧ기서 매개변수 갱신은잡음데이터에 적응력이 좋은 Adam (adaptive moment estimation)알고리즘 ᄋ
ᅦ 의해 이루어진다 (Kingma와 Ba, 2015).
ᄇ
ᅩᆫ 논문에서는제안된패치기반 CNN 모형의 성능을 평가하기 위해 기존의 CNN 모형, 평균 필터, 주
ᆼ앙값 필터와 다양한 잡음비율에 따라 MAE (mean absolute error)와 PSNR (peak signal-to-noise ratio)을 통한 정량적인 비교와 직접 눈으로 평가하는정성적인 비교를수행한다.
보
ᆫ 논문은다음과 같이 구성되어 있다. 제 2 장에서는 본 논문과관련 연구에 대해 논의하고 제 3 장 ᄋ
ᅦ서는 CNN모형을이용한 잡음제거 방법에 대해 논의한다. 제 4 장에서는 영상에서 잡음제거 방법들 ᄀ
ᅡᆫ의 정성적인 비교와 MAE, PSNR 척도 하에서 정량적인 비교를 수행하고 제 5 장에서 결론을 맺는 ᄃ
ᅡ.
2. 관련연구
2.1. 잡음모형 x
x
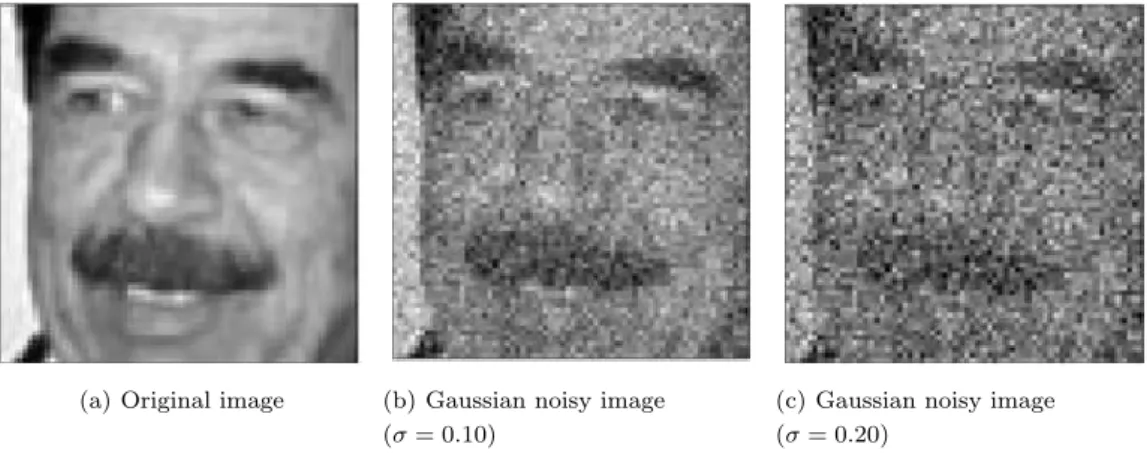
x ∈ RRRm×n 와 yyy ∈ RRRm×n을각각 원영상과 잡음영상이라 할 때 가우시안 잡음모형 (Gaussian noise model)은다음과 같다.
y y
y = xxx + σ × zzz, (2.1) ᄋ
ᅧ기서 zzz는평균이 0이고 표준편차가 1인 표준정규 분포 즉, N (0, 1)을갖는확률변수를나타낸다. 그 ᄅ
ᅵ고 σ는표준편차로서 잡음의 정도를나타낸다.
ᄌ ᅡ
ᆸ음비율 p인 임펄스 잡음모형 (impulse noise model)은다음과 같다.
y y y =
x x
x : with probability 1 − p η
η
η : with probability p,
(2.2)
ᄋ
ᅧ기서 ηηη은 픽셀값이 0 또는 255인 잡음을나타난다.
2.2. CNN 모형 여
ᆼ상에서 CNN 모형은 컨볼루션 (convolution)과 풀링 (pooling) 과정 후 완전 연결 계층 (fully- connected layer)을 통해 영상 분류 (classification)한다. 신경망의 계층이 깊어질수록 객체 고유의 고
ᄉ
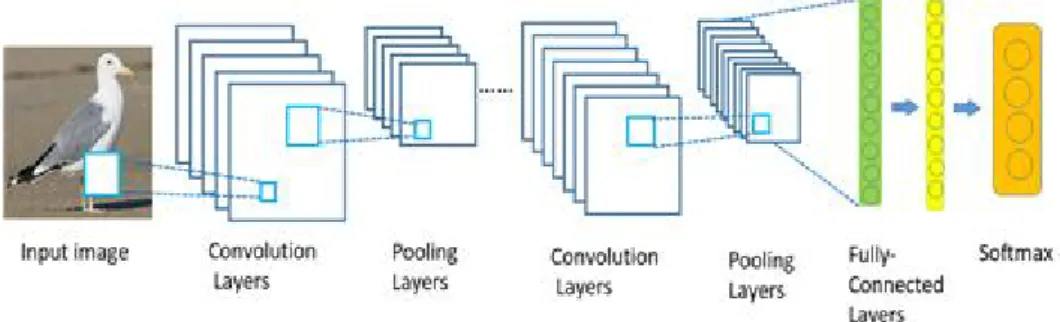
ᅮ준 특징 (high-level feature)을추출한다. Figure 2.1은새 (bird)의 영상인식을위한 CNN의 구조를 ᄇ
ᅩ여주고 있다.
Figure 2.1 CNN architecture for bird recognition
Figure 2.1의 컨볼루션과 풀링 계층에서 영상 특징 추출 및 영상 축소 후 이를바탕으로완전 연결 계 ᄎ
ᅳ
ᆼ을 통해 영상 분류를수행한다. 흔히 컨볼루션 수행 후에 비선형 연산 (nonlinearity)을위해 비선형 ᄒ
ᅡᆷ수인 ReLU (rectified linear unit) 함수, tanh 함수, 시그모이드 (sigmoid) 함수를 적용한다. 풀링 ᄀ
ᅵ법에는맥스 풀링 (max pooling), 평균 풀링 (average pooling) 등이 있고 주로 맥스 풀링을많이 사 ᄋ
ᅭ
ᆼ한다. 완전 연결 계층은 이전 계층에서 모든뉴런은다음 층에서 모든뉴런과 연결되어 있는전통적 ᄋ
ᅵᆫ 다층퍼셉트론 (multi-layer perception)이다. 마지막으로 출력층에서 다중 분류는소프트맥스 함수 (softmax function)를사용한다.
CNN모형에서 학습의 목적은 손실함수 (loss function)를최소로 하는최적의 매개변수를찾는것이 ᄃ
ᅡ. 많이 사용하는매개변수 최적화 방법에 대해 살펴보고자 한다.
2.2.1. SGD (stochastic gradient descent) 소
ᆫ실함수 L(Θ)에 대해서 갱신할 매개변수를 Θ로 표현할 때 t번째 반복시 매개변수 Θt은 t + 1번째 ᄋ
ᅴ 매개변수 Θt+1로 갱신된다. 이를 식으로 표현하면 식 (2.3)과 같다.
Θt+1= Θt− α∂L(Θ)
∂Θt
, (2.3)
ᄋ
ᅧ기서 α는학습율을나타내며 0.01이나 0.001 등의 값으로 미리 정해져 있다. SGD는가장 단순한 최 ᄌ
ᅥᆨ화 방법이나 지역 최적점 (local minimum)에 갇혀 전역 최적점 (global minimum)을찾지 못하는경 ᄋ
ᅮ가 있고 또한, 손실 함수가 비등방성 함수(anisotropy function)일 때에서는탐색 경로가 매우 비효율 ᄌ
ᅥᆨ이다 (Goodfellow 등, 2016).
2.2.2. Adagrad (adaptive gradient)
Adagrad는 개별 매개변수에 대해 적응적 (adaptive)으로 학습률을조정하면서 학습을 진행하는 방 버
ᆸ이다. 즉, 드문매개변수 (infrequent parameter)에 대해서는 학습률을 크게 하고 빈번한 매개변수 (frequent parameter)에 대해서는 학습률을 작게 하여 갱신하는 방법이다. 이를 식으로 나타내면 식 (2.4)과 식 (2.5)과 같다.
Θt+1= Θt− α 1
√ht
∂L(Θ)
∂Θt
, (2.4)
ht= ht−1+ (∂L(Θ)
∂Θt
)2, (2.5)
ᄋ
ᅧ기서 갱신의 크기는기울기에 고정 학습률 α과 1/√
ht을 곱한 값이다. 그리고 ht는기존기울기의 제 고
ᆸ을지속적으로 합한 값이다 (Duchi 등, 2011).
2.2.3. RMSprop (root mean squared propagation)
RMSProp은 Adagrad의 단점을 해결하기 위한 방법으로 ht을 합이 아니라 감소평균 (decaying mean)을 이용하여 가중치를 주는 방법이다. 이럴 경우 ht는 무한정 커지지 않으면서 과거의 기울기 저
ᆼ보를 서서히 잊고 새로운 기울기 정보를 크게 반영하게 된다. 이를 식으로 표현하면 식 (2.6)과 식 (2.7)과 같다.
Θt+1= Θt− α 1
√ht+ ϵ
∂L(Θ)
∂Θt
, (2.6)
ht= νht−1+ (1 − ν)(∂L(Θ)
∂Θt
)2, (2.7)
ᄋ
ᅧ기서 ν는기존영향을감소시키는계수로 0.999 같은값을사용하게 되며 ϵ은 ht가극소로 작아져 0으 ᄅ
ᅩ 가게 되는 것을 막아주는값으로 보통 10−8을사용하게된다 (Hinton, 2012; Tieleman와 Hinton, 2012).
2.2.4. Adam (adaptive moment estimation)
Adam은 Adagrad와 RMSProp의 장점을합친 최적화 방법이다. Adam은 Adagrad와 유사하게 학 ᄉ
ᅳ
ᆸ이 진행되며 계산된기울기의 지수 평균을저장하며, RMSProp와 유사하게 기울기의 제곱값의 지수 펴
ᆼ균을저장한다. 기울기의 지수 평균과 기울기의 제곱 값의 지수 평균은 식으로 표현하면 식 (2.8)-식 (2.10)과 같다.
Θt+1= Θt− α 1
pht/(1 − νt) + ϵ( mt
1 − µt), (2.8)
ht= νht−1+ (1 − ν)(∂L(Θ)
∂Θt
)2, (2.9)
mt= µmt−1+ (1 − µ)∂L(Θ)
∂Θt
, (2.10)
ᄋ
ᅧ기서 µ는이전의 매개변수 갱신값의 영향력을감소시키는계수이다. 여기서 1 − µt와 1 − νt는값이 ᄀ
ᅡ지는편차를보정해주는보정치이다.
Adam은구현하기 쉽고, 계산상 효율적이며, 적은메모리를차지하고, 또한 잡음데이터와 sparse 데 ᄋ
ᅵ터를갖는 문제에 적응력이 매우 뛰어나다 (Kingma와 Ba, 2015).