Performance Analysis of Adaptive Partition Cache Replacement using Various Monitoring Ratios for Non-volatile Memory Systems
1)
전체 글
1)
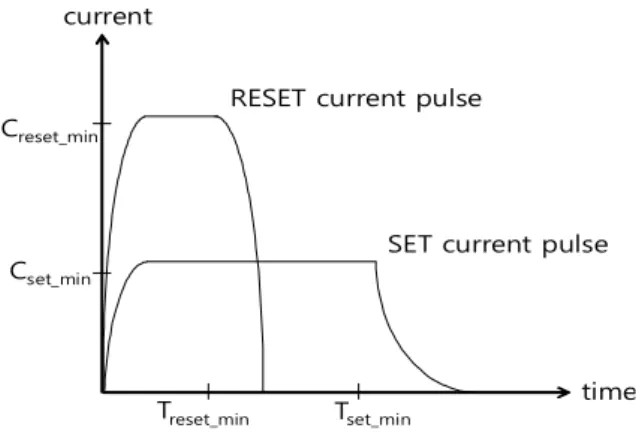
수치
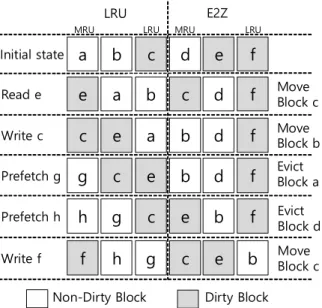
![Fig. 4. The proposed writeback-aware cache replacement policy 블록의 히트율을 높인다[17]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5316122.384555/4.892.103.795.157.447/proposed-writeback-aware-replacement-policy-블록의-히트율을-높인다.webp)
관련 문서
In this paper, an adaptive pedestrian detection algorithm using the fusion of CCTV and IR camera is proposed.. One of the drawbacks of the pedestrian
The objective of this research is to propose a method for evaluating service reliability based on service processes using fuzzy failure mode effects analysis (FMEA) and grey
It is expected to be used for forecasting and analysis of precipitation structure and characteristics of mesoscale system causing heavy rainfall using the
Dissolutionprofiles of fluconazolesolid dispersion (SD) prepared by solvent method using various ratios of fluconazole/copovidone K- 28at pH1.2
I Kourti and MacGregor: Process analysis, monitoring and diagnosis, using multivariate projection methods (paper 31). I MacGregor and Kourti: Statistical process control
inconsistency problem) : 주기억장치에 있는 블록의 내용과 캐시 라인에 적재된 블록의 내용이 서로 달라지는 문제. 캐시
“With the MySQL Query Analyzer, we were able to identify and analyze problematic SQL code, and triple our database performance. More importantly, we were able to accomplish
In order to further boost the performance of NMF, we propose a novel algorithm in this paper, called Dual graph-regularized Constrained Nonnegative Matrix Factorization

