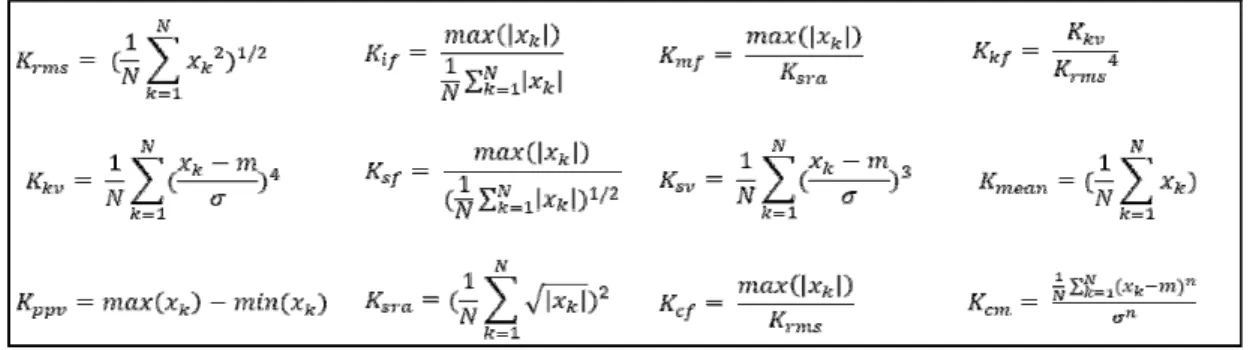*준회원, 울산대학교 전기공학부
**정회원, 울산대학교 전기공학부
***정회원, 울산대학교 전기공학부(교신저자)
접수일자: 2018년 1월 29일, 수정완료: 2018년 3월 2일 게재확정일자: 2018년 4월 6일
Received: 29 January, 2018 / Revised: 2 March, 2018 Accepted: 6 April, 2018
***Corresponding Author: [email protected]
Dept. of Electrical Electronic Engineering, University of Ulsan, Korea
https://doi.org/10.7236/JIIBC.2018.18.2.185
JIIBC 2018-2-23
딥 러닝 및 서포트 벡터 머신기반 센서 고장 검출 기법
Sensor Fault Detection Scheme based on Deep Learning and Support Vector Machine
양재완*, 이영두**, 구인수***
Jae-Wan Yang*, Young-Doo Lee**, In-Soo Koo***
요 약 최근 산업현장에서 기계의 자동화가 크게 가속화됨에 따라 자동화 기계의 관리 및 유지보수에 대한 중요성이 갈수록 커지고 있다. 자동화 기계에 부착된 센서의 고장이 발생할 경우 기계가 오동작함으로써 공정라인 운용에 막대 한 피해가 발생할 수 있다. 이를 막기 위해 센서의 상태를 모니터링하고 고장의 진단 및 분류를 하는 것이 필요하다.
본 논문에서는 센서에서 발생하는 대표적인 고장 유형인 erratic fault, drift fault, hard-over fault, spike fault, stuck fault를 기계학습 알고리즘인 SVM과 CNN을 적용하여 검출하고 분류하였다. SVM의 학습 및 테스트를 위해 데이터 샘플들로부터 시간영역 통계 특징들을 추출하고 최적의 특징을 찾기 위해 유전 알고리즘(genetic algorithm)을 적용하 였다. Multi-class를 분류하기 위해 multi-layer SVM을 구성하여 센서 고장을 분류하였다. CNN에 대해서는 데이터 샘플들을 사용하여 학습시키고 성능을 높이기 위해 앙상블 기법을 적용하였다. 시뮬레이션 결과를 통해 유전 알고리즘 에 의해 선별된 특징들을 사용한 SVM의 분류 결과는 모든 특징이 사용된 SVM 분류기 보다는 성능이 향상되었으나 전반적으로 CNN의 성능이 SVM보다 우수한 것을 확인할 수 있었다.
Abstract As machines have been automated in the field of industries in recent years, it is a paramount importance to manage and maintain the automation machines. When a fault occurs in sensors attached to the machine, the machine may malfunction and further, a huge damage will be caused in the process line. To prevent the situation, the fault of sensors should be monitored, diagnosed and classified in a proper way. In the paper, we propose a sensor fault detection scheme based on SVM and CNN to detect and classify typical sensor errors such as erratic, drift, hard-over, spike, and stuck faults. Time-domain statistical features are utilized for the learning and testing in the proposed scheme, and the genetic algorithm is utilized to select the subset of optimal features. To classify multiple sensor faults, a multi-layer SVM is utilized, and ensemble technique is used for CNN. As a result, the SVM that utilizes a subset of features selected by the genetic algorithm provides better performance than the SVM that utilizes all the features. However, the performance of CNN is superior to that of the SVM.
Key Words : Sensor fault diagnosis, Support vector machine, Genetic algorithm, Multi-layer support vector machine, Convolution neural network, Ensemble
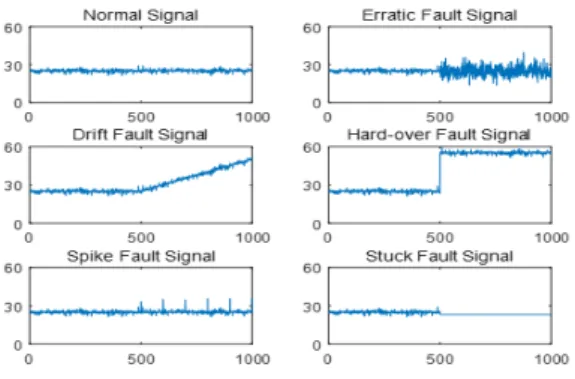
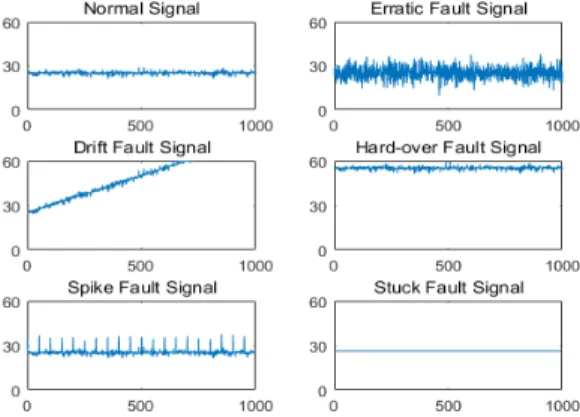
그림 1. 정상신호와 5가지 유형의 센서고장신호들
Fig. 1. Noraml signal and 5 types of sensor fault signals
Ⅰ. 서 론
최근 디지털 변환 및 기계기구 구동 기술들의 급격한 발전에 힘입어 산업 현장에서 사용되는 기계들의 자동화 및 무인화가 가속화되고 있다. 자동화된 생산 공정라인 을 최대의 효율로 가동시키기 위해서는 공정에서 사용되 는 장비들이 오작동 없이 지속적으로 동작해야한다. 이 러한 이유로 자동화 기계들의 관리와 유지보수에 대한 관심이 커지고 있으며 관련된 연구 또한 활발히 이루어 지고 있다[1-3]. 최근 4차 산업혁명의 핵심기술인 인공지 능 기술과 접목되어 단순한 공정을 반복하는 작업에서 고도의 기술을 필요로 하는 작업으로 빠르게 변화하면서 자동화 기기뿐만 아니라 기기에 부착되는 센서의 중요성 도 더욱 커지고 있다. 자동화 시스템은 일반적으로 자동 화 기계에 부착된 다양한 센서들로부터 수집된 데이터를 기반으로 자동화 기계의 구동상태 및 제어량을 파악하고 이를 바탕으로 작업 속도와 양을 조정한다. 따라서 센서 에 이상이 생길 시 공장라인 운영에 치명적인 문제가 발 생 할 수 있으며 이를 막기 위해 센서 고장을 감지하는 시스템이 필수적이다.
센서의 고장은 센서의 종류 및 모델에 따라 다르게 나 타날 수 있다[4-7]. 예를 들어 참고문헌[4]에서는 gas sensor를 사용해서 bias, impact, cyclic, drift, stuck, erratic와 같은 고장 유형을 확인하였다. 참고문헌[6]에서 는 bias, drifting, precision degradation, gain, complete failure, noise, constant with noise의 고장 유형을 검출하 는데 accelerometers가 사용되었다. 본 연구에서는 erratic, drift, hard-over, spike, stuck 5가지 아날로그 센 서의 대표적인 고장유형들을 자동화 기계의 기본적인 센 서들 중 하나인 온도센서로부터 산출되는 데이터를 기반 으로 센서 고장 검출을 수행하였다.
고장의 검출 및 분류를 위하여 주어진 모델을 기반으 로 다양한 신호 분석 및 처리기법들이 사용되어 왔으며 모델의 복잡도가 높아지면서 퍼지 이론들을 이용하여 고 장상태 진단을 하기도 하였다[8-9]. 최근에는 SVM(support vector machine) 그리고 NN(neural network) 같은 지능 형 분류기법이 고장진단에 사용되고 있다[10-11]. SVM의 분류 성능은 고장 데이터로부터 추출한 입력 데이터 특 징들의 종류에 영향을 받을 뿐만 아니라 추출된 특징의 선택에 따라서도 달라진다. 따라서 성능을 높이기 위해 유전 알고리즘과 같은 최적화 기법이 SVM에 사용되기
도 한다[10]. NN의 한 종류인 CNN(convolution neural network)은 convolution 개념을 NN에 적용하여 분류 성 능이 증가하도록 만드는 데이터 패턴을 학습하고 이를 바탕으로 분류기의 성능을 최대화한다. CNN은 이미지 분류, 패턴 인식과 같은 분야에서 매우 좋은 성능을 보여 주었다.
본 논문에서는 erratic, drift, hard-over, spike, stuck 의 총 5가지 센서 고장유형들을 SVM과 CNN으로 분류 한 진단 결과를 분석 및 기술하였다. SVM의 입력은 시 간영역 데이터로부터 추출한 특징을 사용하였고 최적의 특징을 선정하기 위해 유전 알고리즘이 사용되었다.
SVM의 분류 성능을 CNN과 비교하기 위해 다중 클래스 분류가 가능한 multi-layer SVM을 구성하였다. CNN을 사용한 고장 검출 및 분류에서는 성능 향상을 위하여 앙 상블(ensemble)기법을 사용하였다.
Ⅱ. 센서 고장 데이터와 특징추출
본 논문에서는 센서 고장 감지 및 분류를 위해 참고문 헌[12]에서 활용된 데이터를 사용하였다. 데이터는 TC1047/TC1047A Precision Temperature-to-Voltage Converter로부터 측정 되었으며, 정상신호와 5가지 고장 유형들을 사용하였다[12]. 표 1은 상기 5가지 고장유형들 을 나타낸다.
Normal, erratic fault, drift fault, hard-over fault, spike fault, stuck fault는 각각 100개의 데이터 샘플로 구성되었고 그림 1, 그림 5, 그림 6에 나타낸 것처럼 고장 발생 지점(0, 500, 0∼1000)에 따라 6가지 신호 유형을 포
표 2. SVM에서 사용된 개의 데이터 포인트 로부터 추출된 시간 영역 통계적 특징
Table 2. The time-domain statistical features extracted from the N data points used in the SVM 함하는 600개의 데이터 샘플들이 본 논문에서 사용되었
다. 하나의 데이터 샘플은 1,000개의 데이터 포인트를 가 지고 있으며, 고장발생 지점에 따른 데이터 집합은 6*100*1000으로 표현할 수 있다. SVM과 CNN의 학습과 테스트를 위해 고장 유형별로 20개의 데이터 샘플들은 학습에 나머지 80개는 테스트에 사용되었다.
Fault type Fault description
1 : Erratic fault 센서 출력에 노이즈가 급격히 증가함 2 : Drift fault 센서 출력이 계속해서 감소하거나
증가하는 현상
3 : Hard-over fault 센서 출력이 한계치를 넘어서 biased되는 현상
4 : Spike fault 센서 출력이 일정 간격으로 갑작스럽게 spike되는 현상
5 : Stuck fault 센서로부터 고정된 출력이 나오는 현상
표 1. 센서 데이터 고장 유형 및 특징
Table 1. Sensor data fault type and characteristics
일반적으로 SVM의 분류 성능을 높이기 위해 데이터 자체를 입력으로 사용하기보다 데이터로부터 특징을 추 출하여 사용하는데, 시간영역 통계 특징들이 많이 사용 되어왔고 좋은 결과를 보여주었다[11-12]. 본 논문에서는 측정된 센서 출력 신호로부터 특징들을 추출하고 이것을 SVM의 입력으로 사용하였다. 표 2는 사용된 시간영역 통계 특징들을 나타내며 다음과 같다. RMS(root mean squrare), KV(kurtosis value), PPV(peak-to-peak value), IF(impulse factor), SF(shape factor), SRA(square root of the amplitude), MF(margin factor), SV(skewness value), CF(crest factor), KF(kurtosis factor), Mean, CM(central moment, n=5)[12]. 위에서 언급
한 RMS부터 CM까지 12가지 특징에 차례대로 1부터 12 까지 번호를 부여하여 특징을 구분하는데 사용하였다.
Ⅲ. SVM 기반 센서고장진단
SVM은 Vapnik에 의해 개발되었으며 주로 지도 학습 에 의한 패턴인식분야에서 사용되었으나 최근 음성인식, 영상인식, 뇌 신호처리, 금융데이터 분석 등 다양한 분야 에 적용되어 우수한 성능을 보여주고 있다[11-13].
SVM은 두 개의 클래스를 가진 학습 데이터들을 구분 하기 위해 결정경계와 가장 인접한 서포트 벡터를 이용 하여 두 범주 사이의 거리를 최대화시키는 최적의 초평 면을 찾는 이진 분류기법으로 본 논문에서 센서 고장 진 단을 위해 사용되었다. 그림 2는 두 개의 클래스를 선형 으로 분류하는 예를 보여주며, 최적의 초평면은 식은 다 음과 같이 표현된다.
(1)
w는 초평면의 가중치, 는 센서 데이터로부터 추출된 특 징벡터 그리고 b는 절편을 의미한다.
그림 2에서 Class1은 normal, Class2를 나머지 5가지 고장유형으로 학습시킬 경우의 예를 표현하였다. normal 센서 데이터로부터 추출한 특징들은 초평면 H1 아래쪽 에 속할 것이고 고장 유형 데이터로부터 추출된 특징들 은 초평면 H2 위쪽에 포함될 것이다. 이를 표현하면 식 (2)와 같이 나타낼 수 있다.
x Kernel
function 0 1 2 3 4 5
500
Linear 1, 2, 4, 6, 8, 10, 12 1, 2, 3, 6, 8, 9, 11 3, 5, 6, 11, 12 1, 3, 6, 7, 8, 9, 10 2, 5, 6, 7, 8, 11 1, 2, 3, 4, 5, 6, 8, 9, 10, 12 RBF 4, 5, 10 4, 5, 7, 8 1, 7, 8, 9, 12 3, 4, 5, 7, 8, 9 1, 2, 4, 7 1, 2, 3, 4, 8, 10 Polynomial 1, 4, 6, 7, 10 1, 2, 6, 8, 10, 12 2, 4, 5, 7, 9, 12 1, 2, 3, 5, 8, 10, 12 1, 2, 4, 7, 9, 10 2, 3, 4, 11
0 ∼ 1000
Linear 2, 3, 4, 11 1, 5, 7 1, 2, 3, 4, 6, 7, 8, 10, 12
1, 2, 4, 8, 9,
10, 11, 12 1, 3, 4, 5, 7, 11 1, 2, 3, 4, 5, 6, 8, 9, 10, 11, 12 RBF 1, 2, 3, 4, 5,
6, 10, 12 7, 10, 11, 12 2, 4, 7, 9, 11, 12 1, 2, 9, 10, 11 2, 7, 8, 11 1, 4, 5, 7, 10, 11, 12 Polynomial 1, 2, 3, 4, 5, 7,
8, 9, 11 1, 2, 3, 7, 8, 11 1, 2, 3, 4, 6, 7,
8, 9, 10, 11, 12 1, 2, 4, 6, 8 1, 2, 4, 5, 6, 7, 8, 9, 12
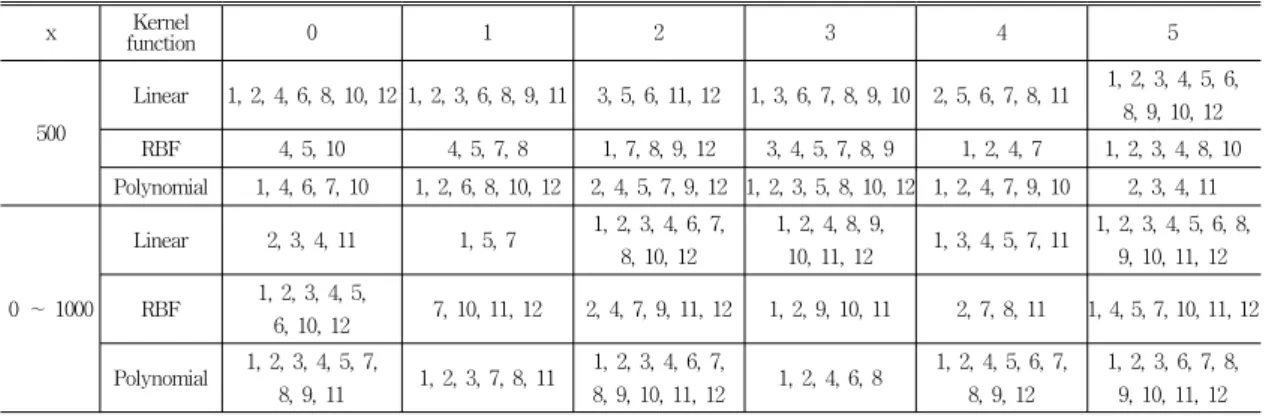
1, 2, 3, 6, 7, 8, 9, 10, 11, 12 표 3. 유전 알고리즘으로부터 선택된 특징들
Table 3. Features selected from the genetic algorithm
≥
≤ (2)
SVM에서는 대부분 그림 2의 경우와는 달리 비선형적 특징을 가지는 데이터들을 분류하는 경우가 많기 때문에 선형적 특징을 가지는 데이터뿐만 아니라 비선형적 특징 을 가지는 데이터를 분류할 수 있도록 커널 함수(kernel function)을 사용한다. 본 연구에서는 linear, RBF, polynomial 세 가지 종류의 커널 함수가 SVM을 학습시 키기 위해 사용되었다[12].
그림 2. SVM 선형 분류
Fig. 2. SVM linear classification
본 논문에서 SVM은 one-versus-rest 방법을 활용하 여 각 결함 유형에 따라 분류하고 그 결과는 표로 나타내 었다[12]. 입력 데이터가 들어왔을 때 그 데이터의 클래스 를 직접적으로 판별하기 위해 다중 계층 SVM 분류기를
그림 3과 같이 설계하였다[14]. 입력이 들어오면 SVM 분 류기는 하나의 클래스에 대해 판별하고 해당 클래스가 아니면 다른 SVM 분류기로 분류한다. Multi-layer SVM의 분류 결과는 표 5와 같이 나타내었고 CNN의 분 류 성능과 비교하였다.
Ⅳ. 유전 알고리즘 기반의 특징선택
유전 알고리즘은 생물학적 진화과정을 시뮬레이션하 여 최적의 해를 얻을 수 있는 기법으로 존 홀랜드에 의 해 제안되었다[15]. 유전 알고리즘은 초기 염색체 집단으 로부터 적합도 함수의 결과에 따라 선택(selection), 교차 (crossover), 변이(mutation) 그리고 대치(replacement) 연산 순서로 최상의 해답을 얻을 때까지 진행된다.
그림 3. 다중 계층 SVM Fig. 3. Multi-layer SVM
본 논문에서는 표 2의 특징들을 0과 1의 2진 비트코드 로 표현하여 하나의 염색체로 사용하였다. 해가 1로 표현
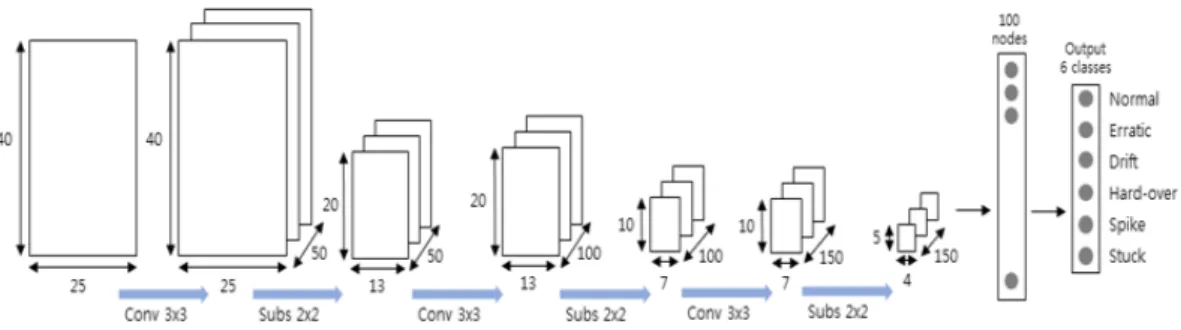
그림 4. 센서 고장 진단을 위한 CNN 구조
Fig. 4. CNN architecture for sensor fault diagnosis 이 되면 해당 특징이 사용되고, 해가 0이면 해당 특징은 사용되지 않는다. 예를 들어 [0, 1, 0, ... , 1]으로 염색체가 표현된다면 1로 표현된 두 번째 특징과 마지막의 특징이 입력으로 사용되고 나머지 0으로 표현된 특징들은 사용 되지 않는다. 유전 알고리즘을 사용하기 위해 먼저 초기 세대를 생성한다. 초기 세대 생성과정에서는 바이너리 스트링을 랜덤하게 초기화하였으며 개체는 20개를 생성 하였다. 선택과정에서는 선택된 해에 대한 적합도 함수 의 평가에 따라 부모 개체를 선택하는데 적합도 함수가 높은 개체가 더 많이 선택되는 roulette-wheel 방법을 사 용하였다. 적합도 함수는 선택된 해들을 사용하여 학습 데이터에 대해 cross validation을 사용한 SVM의 정확도 가 높고 사용된 특징들의 개수가 적을수록 높은 점수를 부여하였다. 교차는 선택된 부모 개체가 가지는 유전자 를 조합하여 새로운 자식 염색체를 생산한다. 염색체에 서 임의로 자름 점을 n개 선택한 후, 두 부모 객체를 교차 하는 방식으로 2점 교차방식이 본 연구에서 사용되었다
[16]. 변이는 교차 연산 이후, 확률적으로 자식 객체의 유 전자에 비트를 반전시켜 해의 다양성을 높여줌으로써 지 역 최저점에 빠지는 것을 방지한다. 변이가 일어날 확률 은 0.001로 설정하였다. 마지막으로 대치과정에서는 전체 적인 해집단의 품질을 향상시키기 위해 기존 세대에서 가장 성능이 우수한 해를 제외한 나머지 세대 전부를 대 치하는 방법을 사용하였다. 표 3에서 보는 바와 같이 해 는 학습 데이터에 유전 알고리즘을 적용하여 얻었다. 참 고문헌[12]의 SVM을 이용한 센서 고장 진단에서는 특징 을 고를 때 5개의 특징을 선택하는 것만 고려하였으므로 각 고장 유형에 따른 분류성능을 최적화하지 못하였다.
따라서 본 논문에서는 SVM의 분류성능을 높이기 위해 커널 함수와 각 고장유형 클래스에 따라 해를 구하였다.
Ⅴ. CNN 기반 센서고장진단
CNN은 인공 신경망을 여러 층 쌓아 올린 딥 러닝 (deep learning) 기법중 하나이다. CNN이 이미지 분류에 서 뛰어난 성능을 보여주면서 우수성을 인정받아 관심이 크게 증가하였고 최근에는 데이터의 양이 증가하면서 이 미지 분류뿐만 아니라 다양한 분야에 적용되어 활발하게 연구되고 있다[17-21].
CNN은 convolution layer, pooling layer 그리고 fully connected layer 세 가지 계층으로 구성된다. 그림 4는 본 논문에서 센서 고장을 분류하기 위해 고려한 CNN 구조 를 나타낸다.
Convolution layer는 입력 데이터로부터 특징을 추출 하기 위해 사용된다. Convolution 과정을 통해 입력데이 터에 대해서 필터를 이동시키면서 계산한 결과를 얻는다.
일반적으로 CNN은 이미지 처리를 위해 주로 사용되기 때문에 2차원 convolution 연산이 많이 사용되는데 식 (3)과 같이 나타낼 수 있다[18].
(3)
는 2차원 입력 데이터, 는 필터를 의미한다.
Convolution 단계에서는 필터의 크기와 이동간격을 설정한다. 일반적으로 필터는 N×N 크기를 사용하고 간 격은 위아래로 다르게 설정할 수 있지만 보통 같은 크기 로 설정한다. 필터의 가중치 값은 초기에 무작위로 설정 되는데 학습을 통해 최적의 값을 할당 받게 된다. 필터를 적용한 후의 결과를 feature map이라고 하는데 feature map의 크기는 convolution 연산에 적용되는 필터의 크 기, stride 그리고 padding에 따라 결정된다. 필터를 통해
추출된 feature map은 activation function의 입력으로 사 용된다.
Pooling layer에서는 sub-sampling을 이용하여 feature map에서 대표 특징 값을 추출한다. 주로 사용되는 방법 은 max pooling과 average pooling이 있다[17]-[19].
Fully connected layer에서는 모든 노드들이 각 층의 모든 노드들과 서로 연결되어 있으며 sub-sampling 단 계를 거친 특징들은 인공 신경망의 입력으로 사용되어 최종적으로 클래스를 분류한다.
Ⅵ. 실험 및 결과
센서 고장 진단을 위해 사용된 SVM 분류기는 MATLAB에서 ficsvm을 통해 구현되었다. SVM을 학습 시키기 위해서 각 고장 클래스 별로 20개의 샘플들이 사 용되었고 80개의 샘플들이 테스트를 위해 사용되었다.
SVM 학습을 위해 사용된 커널 함수는 linear, RBF, polynomial이며, 커널 함수별로 학습된 SVM을 사용하여 각각 센서 고장 감지 및 분류를 하였다. RBF와 polynomial 커널 함수에서 kernel scale은 1, polynomial kernel function order은 3으로 설정하였다. SMO (sequential minimal optimization) 알고리즘이 사용되었 고 cost 값은 1로 설정되었다.
CNN에서는 SVM과 마찬가지로 20개의 데이터 샘플 들로 학습을 시키고 80개의 데이터 샘플로 테스트하였다.
그림 4는 센서 고장 진단을 위해 제안된 CNN 구조를 보 여준다. 구현된 CNN 모델은 세 개의 convolution layer, 세 개의 pooling layer 그리고 하나의 fully connected layer를 가진다. 입력 단계에서 1000개의 데이터 포인트 를 가진 하나의 데이터 샘플을 convolution 연산을 하기 위해 40×25 형태의 행렬로 만들어 사용하였다. 세 개의 convolution layer에서 convolution 연산에 사용된 필터 의 크기는 3×3, stride는 1로 설정 하였고, zero padding을 사용하여 convolution 연산 후에도 feature map의 크기를 동일하게 유지하였다. 첫 번째 convolution layer에서는 50 feature maps가 사용되었고 100, 150 feature maps가 두, 세 번째 convolution layer에 사용되었다. 추출된 feature map에 적용된 activation function은 ReLU가 사 용되었다[18]. 각 pooling layer에서는 max pooling 기법이 사용되었고 2×2 크기로 sub-sampling 되었으며 stride는
1로 설정되었다. Fully connected layer는 100개의 neuron nodes와 6개의 클래스 출력을 가진다. 분류 결과 에 softmax 함수가 사용되고, softmax 함수에 대한 cross entropy 함수의 평균이 cost 함수로 사용되었다[19]. CNN 을 훈련시키기 위한 역전파 과정에서는 ADAM optimization이 사용되었고 over-fitting을 방지하기 위해 0.7의 확률로 dropout 기법이 적용되었다[18]. 또한 CNN 의 분류 성능을 향상시키기 위해 각각의 CNN 분류기로 부터 얻은 결과를 종합하여 최종 결과를 고려하는 병렬 적 결합 방법의 앙상블 기법을 사용하였다. CNN을 학습 및 테스트하기 위해 Python 기반의 TensorFlow 라이브 러리를 사용하였다.
그림 5. x=0에서의 각 클래스에 대한 하나의 데이터 샘플 Fig. 5. One data sample for each class at x=0
그림 6. 무작위 지점에서 발생한 각 클래스에 대한 데이터 샘 플들
Fig. 6. Data samples for each class that occurred at random points
x Kernel Function
Selected features All features
0 (normal)
1 (erratic)
2 (drift)
3 (hardover)
4 (spike)
5 (stuck)
0 (normal)
1 (erratic)
2 (drift)
3 (hardover)
4 (spike)
5 (stuck)
0
Linear 100 100 100 100 100 100 100 100 100 100 100 100
RBF 100 100 100 100 100 100 100 100 100 100 100 100
Polynomial 100 100 100 100 100 100 100 100 100 100 100 100
500
Linear 94.17 100 100 100 100 92.29 94.17 100 100 100 100 92.29
RBF 98.54 99.79 100 100 99.79 98.54 99.79 99.79 100 100 99.58 98.75
Polynomial 97.71 100 100 100 100 97.71 97.5 100 100 100 100 97.71
0∼1000
Linear 83.33 99.79 83.33 90.21 97.92 85.21 83.33 100 83.33 90.83 97.08 85.21
RBF 91.04 100 95.83 99.79 99.17 85.83 90.21 99.58 96.04 98.75 98.75 86.25
Polynomial 90.21 100 97.08 99.79 99.38 94.38 90.21 97.5 97.08 99.38 99.17 92.08
표 4. 유전자 알고리즘에 선택된 특징들과 모든 특징들을 사용한 SVM의 정확도(%)
Table 4. Accuracy of SVM(%) with features selected by genetic algorithm and all features
그림 5는 데이터 측정 시작점부터 바로 고장이 발생한 데이터 샘플을 보여주고 있다. 고장 발생 지점을 x로 표 현하며, 0지점에서 고장이 발생하였으므로 x=0으로 나타 냈다. 그림 1과 그림 6은 각각 고장 발생지점이 500과 0
∼1000 사이 지점에서 무작위로 발생한 것을 보여주므로, x=500, x=0∼1000으로 표시된다. 고장 발생지점에 따라 데이터 셋은 학습 및 테스트에 사용된다.
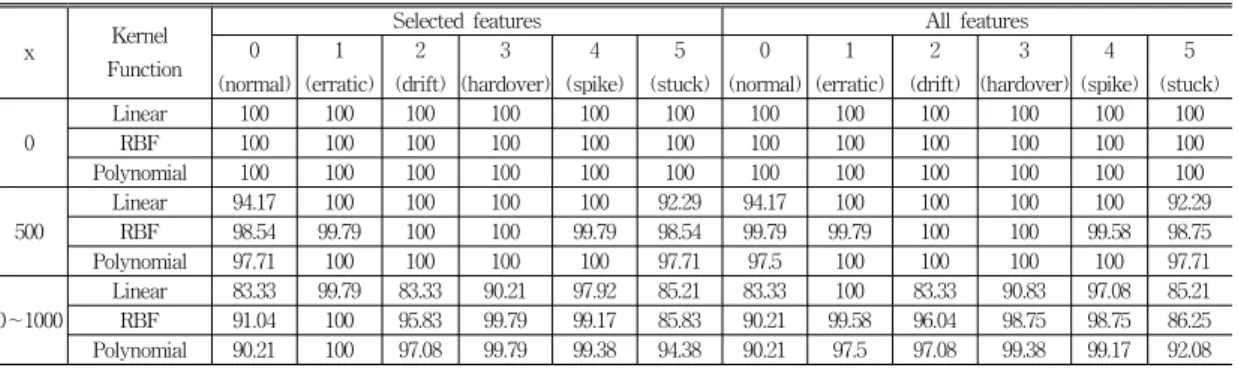
표 4는 센서 고장 진단에 사용된 SVM의 테스트 정확 도 결과를 보여준다. 표에서 x는 고장발생 지점(x=0, 500, 0∼1000)에 따라 테스트되었음을 의미한다. SVM은 커널 함수인 linear, RBF, polynomial을 사용하여 분류하였다.
Selected features은 유전 알고리즘을 사용해서 얻은 특 징을 의미한다. 표 3에 나타낸 것처럼 고장 발생지점, 커 널 함수 그리고 클래스 유형에 따라 특징들이 사용되었 다. 표 3에서 x=0 인 조건에서는 특징 4, 5, 6(SV,IF,SRA) 만으로 모든 클래스와 커널 함수에 대해 100%의 정확도 를 보여주었으므로 따로 표시하지 않았다. 표 4의 All features는 표 2에서의 특징들을 SVM을 이용한 센서 고 장 분류에 모두 사용한 것을 의미한다. 클래스는 0, 1, ...
, 5와 같은 숫자로 표현되었고 각각 normal, erratic, drift, hard-over, spike, stuck faults를 나타낸다.
표 4의 x=0 지점 조건에서 분류결과는 상이한 특징의 개수 조건에서도 모두 100%의 정확도를 보여준다. 여기 서 주목할 점은 모든 특징들을 사용하지 않아도 선택된 특징들(SV, IF, KF)만으로 같은 결과를 얻었다는 것이 다. 따라서 선택된 특징들이 충분히 고장 신호들을 분류 할 수 있는 특징정보를 가지고 있다는 것을 의미한다.
고장 발생 x=500 에서 각 클래스에 대한 분류결과는 x=0 에 비해 비교적 정확도가 다소 떨어지는 것을 표 4에 서 확인할 수 있다. 각 유형별 데이터가 지니는 특성이
일부만 관측되기 때문에 분류 정확도가 떨어지는 것으로 판단된다.
x=0∼1000 은 고장의 발생 시점이 데이터 포인트 0부 터 1000 사이에서 랜덤하게 발행하는 경우를 나타낸다.
분류 정확도는 x=0, 500의 조건들에 비해 떨어진다. 또한 linear 커널 함수에서의 분류 결과는 다른 커널 함수에 비 해 현저히 성능이 낮다. 이는 x=0∼1000에서의 문제가 x=0, 500에 비해 분류하기 어려운 패턴임을 의미한다. 분 류 정확도는 특징들과 커널 함수를 적절히 선택하여 개 선시킬 수 있다. Polynomial 커널 함수와 selected features를 사용한 분류 성능은 평균 96.81%로 가장 우수 한 정확도를 보여주고 있다.
x Kernel
function
Selected features
12 features
0
Linear 100 100
RBF 100 100
Polynomial 100 100
500
Linear 94.17 92.92
RBF 98.13 98.96
Polynomial 98.13 97.92
0∼1000
Linear 64.79 64.17
RBF 87.92 85.21
Polynomial 90.83 90.42
표 5. 다중 계층 SVM 정확도(%)
Table 5. Accuracy of multi-layer SVM(%)
표 5에서는 multi-layer SVM을 사용하여 센서 고장 데이터를 분류한 결과를 보여준다. multi-layer SVM은 사용된 커널 함수별로 설계되었으며, 표 4에서 정확도가 높은 클래스에 해당하는 SVM 분류기가 multi-layer SVM의 상위 계층에 위치하도록 설계하였다. x=0∼1000 과 polynomial 커널 함수의 경우에는 1(erratic),
3(hard-over), 4(spike), 2(drift), 5(stuck), 0(normal)순으 로 multi-layer SVM이 설계되었다. 표 5를 보면 x=500 에서 RBF를 사용한 SVM 분류 결과를 제외한 나머지 결 과에서는 유전 알고리즘에 의해 선정된 특징들이 충분히 좋은 성능을 보여줌을 알 수 있다. x=0∼1000에서 RBF 커널 함수를 사용한 분류 결과에서는 선택된 특징들을 사용한 결과가 모든 특징을 사용한 결과보다 2.71%의 정 확도 향상을 보임을 확인 할 수 있다.
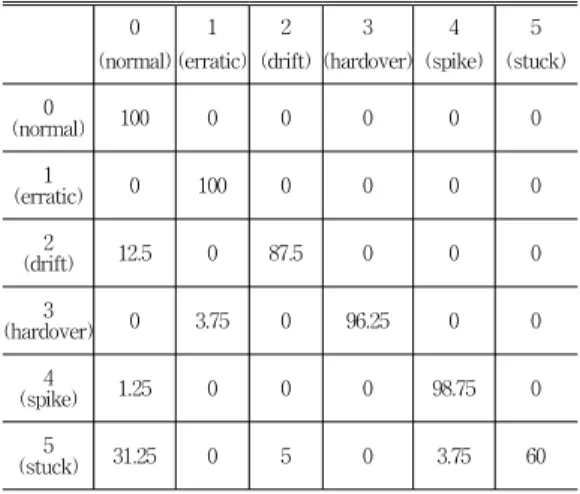
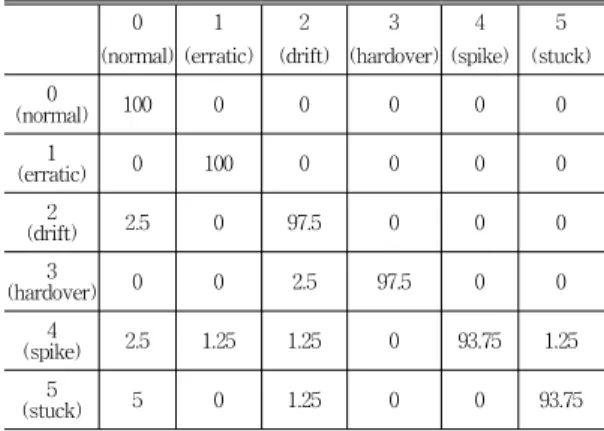
표 6과 7은 각각 all features와 selected features를 사 용한 multi-layer SVM에 대한 혼동 행렬을 보여주며, 이 는 x=0∼1000에서 polynomial 커널 함수를 사용한 결과 이다. 표에서 좌측과 상단에 0부터 5까지의 숫자는 각각 실제 class와 예측된 class로 표시하여 정확도를 나타내 었다. 예를 들어, 표 6에서 2(erratic)는 87.5%가 2(erratic)으로 분류되었고 나머지 12.5%는 0(normal)로 분류되었음을 나타낸다. 표6과 7을 비교해 보았을 때 selected features를 사용하여 3(hard-over fault)을 분류 한 결과가 all features를 사용한 결과보다 2% 더 높은 정 확도를 보여준다. 표 6과 7에서 가장 분류 정확도가 낮은 클래스는 5(stuck)로써 60%의 분류 정확도를 보이며, 이 는 각 표의 전체 오분류에 대해 69.57%, 72.73%로 가장 높은 오류비율을 가진다. 따라서 5(stuck) 클래스를 나타 내는 특징이 다른 특징들과 특징 공간에서 겹쳐져 식별 이 어려움을 알 수 있다.
0 (normal)
1 (erratic)
2 (drift)
3 (hardover)
4 (spike)
5 (stuck) 0
(normal) 100 0 0 0 0 0
(erratic)1 0 100 0 0 0 0
(drift)2 12.5 0 87.5 0 0 0
3
(hardover) 0 3.75 0 96.25 0 0
4
(spike) 1.25 0 0 0 98.75 0
(stuck)5 31.25 0 5 0 3.75 60
표 6. 모든 특징을 사용한 SVM-Poly 분류 결과에 대한 혼 동행렬 (%)
Table 6. Confusion matrix for SVM-Poly classification results using all features(%)
0 (normal)
1 (erratic)
2 (drift)
3 (hardover)
4 (spike)
5 (stuck)
(normal)0 100 0 0 0 0 0
1
(erratic) 0 100 0 0 0 0
(drift)2 12.5 0 87.5 0 0 0
3
(hardover) 1.25 0 0 98.75 0 0
(spike)4 1.25 0 0 0 98.75 0
5
(stuck) 32.5 0 5 0 2.5 60
표 7. 선택된 특징을 사용한 SVM-Poly 분류 결과에 대한 혼 동행렬(%)
Table 7. Confusion matrix for SVM-Poly classification results using all features(%)
표 8은 x=0∼1000인 조건에서 CNN을 사용하여 고장 클래스를 분류한 결과이다. x=0, x=500에서의 CNN을 사 용한 센서 고장 진단에서는 모든 클래스에 대해 100%의 정확도로 분류하였으므로 따로 나타내지는 않았다. 앙상 블(ensemble)은 model1부터 model5까지의 CNN모델을 종합한 결과이며, CNN 앙상블의 분류 전체 결과는 97.08%로 다른 CNN모델들의 결과보다 더 향상된 결과 를 얻었다. CNN 앙상블은 표 5에서 polynomial 커널 함 수를 사용한 SVM 분류기의 정확도인 90.83%보다 훨씬 높은 분류결과를 보여준다. 고장 발생지점 x=0에서는 SVM도 CNN과 동일한 성능을 보여주지만 x=500, 0∼
1000에서는 CNN에 비해 성능이 떨어진다. 따라서 데이 터의 질이 떨어지거나 그 복잡성이 증가 할수록 SVM 보 다는 CNN이 좀 더 신뢰성 높은 분류가 가능함을 알 수 있다.
0 (normal)
1 (erratic)
2 (drift)
3 (hardover)
4 (spike)
5 (stuck)
Model1 93.75 100 96.25 100 92.5 93.75
Model2 88.75 100 96.25 96.25 91.25 93.75
Model3 100 100 97.75 92.5 95 95
Model4 98.75 100 90 92.5 95 93.75
Model5 98.75 100 97.5 97.5 92.5 92.5
Ensemble 100 100 97.5 97.5 93.75 93.75
표 8. CNN 센서 고장 진단, x=0∼1000(%)
Table 8. Accuracy of CNN for sensor fault diagnosis, a random x=0∼1000(%)
표 9에서는 CNN의 앙상블 모델의 분류 결과를 혼동 행렬로 보여준다. CNN 앙상블을 사용한 분류에서는 0, 1(normal, erratic) 클래스들에 대한 분류는 100% 수행되 었고 4, 5(spike, stuck) 클래스들을 분류함에 있어서는 93.75%로 가장 낮은 정확도를 얻었다. 표 8에서 selected features를 사용한 SVM의 분류 결과와 비교해 보았을 때 3(hard-over) 분류에서 1%, 4(spike)에서는 5% 정도 분류성능이 떨어졌다. 하지만 2(drift), 5(stuck)에서의 결 과는 CNN 앙상블을 사용한 경우 훨씬 더 높은 성능을 보여 주었으며, 특히 5(stuck)에서의 결과는 CNN 앙상블 을 사용한 결과가 33.75%로 상당히 높았다. 6가지 유형 의 클래스 중 5(stuck)의 분류 정확도가 SVM과 CNN에 서 모두 다 가장 낮은 분류 정확도를 보여주었다. 따라서 다른 고장 유형들에 비해 5(stuck) 클래스로부터 식별하 기 위한 특징 추출이 어렵고 복잡하다는 것을 알 수 있다.
0 (normal)
1 (erratic)
2 (drift)
3 (hardover)
4 (spike)
5 (stuck) 0
(normal) 100 0 0 0 0 0
(erratic)1 0 100 0 0 0 0
2
(drift) 2.5 0 97.5 0 0 0
(hardover)3 0 0 2.5 97.5 0 0
4
(spike) 2.5 1.25 1.25 0 93.75 1.25
(stuck)5 5 0 1.25 0 0 93.75
표 9. CNN앙상블 결과에 대한 혼동행렬(%) Table 9. Confusion matrix for CNN-Ensemble
classification results(%)
그림 7에서는 분류기의 성능을 효과적으로 표현할 수 있는 AUC-ROC를 보여주고 있다[12]. 5(stuck) 클래스 의 데이터 샘플들이 positive class로 사용되었고, 나머지 클 래스들은 negative class로 사용되었다. 그래프에서 가장 우수한 성능을 보여주는 것은 CNN 앙상블을 이용한 분 류이다. CNN 앙상블 그래프는 false positive rate가 0.1 정도에 가장 먼저 true positive rate 1에 도달하였으며, AUC 값도 0.996으로 selected features를 사용한 SVM 분류기 보다 0.41이나 높은 수치를 기록했다.
그림 7. SVM-Poly와 CNN의 AUC-ROC, x=0∼1000 Fig. 7. AUC-ROC of SVM-Poly and CNN, a random
x=0∼1000.
Ⅶ. 결 론
본 논문에서는 센서 고장 검출 및 분류를 위해 SVM 과 CNN을 적용하였다. 센서 데이터 샘플들로부터 시간 영역 통계 특징들을 추출하였고, 유전 알고리즘을 사용 하여 선별된 특징들을 이용하여 SVM 분류기의 분류 성 능을 개선시켰다. 유전 알고리즘에 의해 선택된 특징들 을 사용한 multi-layer SVM은 고장 시점이 랜덤한 경우 에서 모든 특징을 사용하여 분류한 것보다 더 좋은 결과 를 보여주었다. CNN을 사용한 분류에서는 CNN의 성능 을 향상시키기 위해 앙상블 기법을 사용하였으며, 유전 알고리즘을 적용시킨 SVM 분류기에서 잘 분류하지 못 한 stuck 클래스를 93.75%의 정확도로 분류하였다.
Stuck fault 분류의 효과적인 성능 비교를 위해 AUC-ROC를 사용하였고 CNN 앙상블이 가장 좋은 성능 을 보임을 확인 할 수 있었다.
References
[1] Don-Ha Hwang, Young-Woo Youn, Jong-Ho Sun, Kyeong-Ho Choi, Jong-Ho Lee and Yong-Hwa Kim, “Support Vector Machine Based Bearing Fault Diagnosis for Induction Motors Using Vibration Signals”, Journal of Electrical Engineering & Technology, Vol. 10, no. 4, pp.
1558-1565, 2015.
DOI: http://dx.doi.org/10.5370/JEET.2015.10.4.1558 [2] WadeA.Smith, RobertB.Randall , “Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study”, Mechanical Systems and Signal Processing, Vol.
64-65, pp. 100-131, 2015.
DOI: https://doi.org/10.1016/j.ymssp.2015.04.021 [3] Subhasis Nandi, Hamid A. Toliyat and
Xiaodong Li, "Condition Monitoring and Fault Diagnosis of Electrical Motors", IEEE Transactions On Energy Conversion, Vol. 20, no.
4, pp. 719-729, 2005.
DOI: http://doi.org/10.1109/TEC.2005.847955 [4] J. L. Yang, Y. S. Chen, L. L. Zhang, and Z. Sun,
“Fault detection, isolation, and diagnosis of self-validating multifunctional sensors,” Rev. Sci.
Instrum., vol. 87, no. 6, 2016.
DOI: https://doi.org/10.1063/1.4954184
[5] R. Dunia, S. J. Qin, T. F. Edgar, and T. J. Mcavoy,
“Identification of Faulty Sensors Using Principal Component Analysis,” Process Syst. Eng., vol. 42, no. 10, pp. 2797–2812, 1996.
DOI: https://doi.org/10.1002/aic.690421011 [6] J. Kullaa, “Detection, identification, and
quantification of sensor fault in a sensor network,”
Mech. Syst. Signal Process., vol. 40, no. 1, pp. 208 –221, 2013.
DOI: https://doi.org/10.1016/j.ymssp.2013.05.007 [7] Y. Yu, W. Li, D. Sheng, and J. Chen, “A novel
sensor fault diagnosis method based on Modified Ensemble Empirical Mode Decomposition and Probabilistic Neural Network,” Measurement, vol.
68, pp. 328–336, 2015.
DOI: https://doi.org/10.1016/j.measurement.2015.03.003 [8] Ming Liu, Xibin Cao, and Peng Shi,
“Fuzzy-Model-Based Fault-Tolerant Design for Nonlinear Stochastic Systems Against Simultaneous Sensor and Actuator Faults,” IEEE Transactions on Fuzzy Ststems, vol. 21, no. 5, pp.
789–799, 2015.
DOI: https://doi.org/10.1109/TFUZZ.2012.2224872 [9] Gilbert Hock Beng Foo, Xinan Zhang, and D. M.
Vilathgamuwa, “A Sensor Fault Detection and Isolation Method in Interior Permanent-Magnet Synchronous Motor Drives Based on an Extended Kalman Filter,” IEEE Transactions on Electonics, vol. 60, no 8, pp. 3485-3495, 2013
DOI: https://doi.org/10.1109/TIE.2013.2244537 [10] B. Samanta, “Gear fault detection using artificial
neural networks and support vector machines with genetic algorithms,” Mech. Syst. Signal Process., vol. 18, no. 3, pp. 625–644, 2004.
DOI: https://doi.org/10.1016/S0888-3270(03)00020-7 [11] T. W. Rauber, F. De Assis Boldt, and F.M.
Varejãao, “Heterogeneous feature models and feature selection applied to bearing fault diagnosis,” IEEE Trans. Ind. Electron., vol. 62, no.
1, pp. 637–646, 2015.
DOI: https://doi.org/10.1109/TIE.2014.2327589 [12] Sana Ullah Jan, Young Doo Lee, Jungpil Shin and
Insoo Koo, "Sensor Fault Classification Based on Support Vector Machine and Statistical Time-Domain Features", IEEE Access, Vol. 5, pp.
8682-8690, 2017.
DOI: https://doi.org/10.1109/ACCESS.2017.2705644 [13] Seung-Jae Kim, Jung-Jae Lee, "A Study on Face Recognition using Support Vector Machine", The Journal of The Institute of Internet, Broadcasting and Communication, Vol. 16, No. 6, pp. 183-190, Jun. 2016.
DOI: https://doi.org/10.7236/JIIBC.2016.16.6.183 [14] L.V. Ganyun, Cheng Haozhong, Zhai Haibao and
Dong Lixin , "Fault diagnosis of power transformer based on multi-layer SVM classifier", Electric Power Systems Research, Vol. 74, no 1, pp. 1-7, 2005.
DOI: https://doi.org/10.1016/j.epsr.2004.07.008 [15] David E. Goldberg and John H. Holland, "Genetic
Algorithms and Machine Learning", Machine Learning, Vol. 3, no 2-3, pp. 95-99, 1988.
DOI: https://doi.org/10.1023/A:1022602019183
※ 본 논문은 중소기업청에서 지원하는 2016년도 산학연협력 기술개발사업(No.C0398156)의 연구수행으로 인 한 결과물임을 밝힙니다.
[16] Hideyuki Ishigami, Toshio Fukuda, Takanori Shibata and Fumihito Arai, "Structure optimization of fuzzy neural network by genetic algorithm", Fuzzy Sets and Systems, Vol. 71, no 3, pp. 257-264, 1995.
DOI: https://doi.org/10.1016/0165-0114(94)00283-D [17] Shahrzad Faghih-Roohi, Siamak Hajizadeh and Alfredo Núñez, "Deep Convolutional Neural Networks for Detection of Rail Surface Defects", International Joint Conference on In Neural Networks(IJCNN), pp. 2584-2589, 2016.
DOI: https://doi.org/10.1109/IJCNN.2016.7727522 [18] Dean Lee, Vincent Siu, Rick Cruz, and Charles
Yetman, "Convolutional Neural Net and Bearing Fault Analysis", in Proc. Int. Conf. Data Min., Las Vegas, NV, USA, 2016, pp. 194–200.
[19] Min Meng, Yiting jacqueline Chua, Erwin Wouterson, and Chin Peng Kelvin Ong,
"Ultrasonic signal classification and imaging system for composite materials via deep convolutional neural networks", Neurocomputing, Vol. 257, pp. 128-135, 2017.
DOI: https://doi.org/10.1016/j.neucom.2016.11.066 [20] Seok-Cheon Park, "Design and Implementation of
Personal Information Identification and Masking System Based on Image Recognition", The Journal of The Institute of Internet, Broadcasting and Communication, Vol. 17, No. 5, pp. 1-8, May. 2017.
DOI: https://doi.org/10.7236/JIIBC.2017.17.5.1 [21] Seo-Hyeon Ryu, Jae-Bok Yoon, "The Effect of regularization and identity mapping on the performance of activation functions", Journal of the Korea Academia-Industrial cooperation Society, Vol. 18, No. 10, pp. 75-80, 2017.
DOI: https://doi.org/10.5762/KAIS.2017.18.10.75
저자 소개
양 재 완(준회원)
∙2017년 : 울산대학교 전기공학부 (학사)
∙2017년 ∼ 현재 : 울산대학교 전기공 학부 석사과정
<관심분야 : 신호처리, 고장진단, 차세 대 통신 시스템>
이 영 두(정회원)
∙2007년 : 울산대학교 전기전자정보시 스템 공학부 (학사)
∙2009년 : 울산대학교 전기전자정보시 스템 공학부 (석사)
∙2013년 : 울산대학교 전기전자정보시 스템 공학부 (박사)
∙2013년 ∼ 현재 : 울산대학교 전기공 학부 (리서치펠로우)
<관심분야 : 인공지능 기반 네트워크, 무선인지 네트워크, 수 중 센서 네트워크, 차세대 통신 시스템>
구 인 수(정회원)
∙1996년 : 건국대학교 전자공학과 졸업 (학사)
∙1998년 : 광주과학기술원 정보통신공 학과 졸업 (석사)
∙2002년 : 광주과학기술원 정보통신공 학과 졸업 (박사)
∙2002년 ∼ 2004년 : 광주과학기술원 연구교수
∙2003년 ∼ 2004년 : 스웨덴왕립공과대학 박사 후 연수과정
∙2005년 ∼ 현재 : 울산대학교 전기공학부 교수 <관심분야 : 차세대 통신 시스템, 무선센서 네트워크>