Automatic Machine Fault Diagnosis System using Discrete Wavelet Transform and Machine Learning
Kyeong-Min Lee
†, Caleb Vununu
††, Kwang-Seok Moon
†††, Suk-Hwan Lee
††††, Ki-Ryong Kwon
†††††ABSTRACT
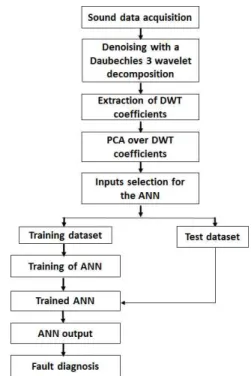
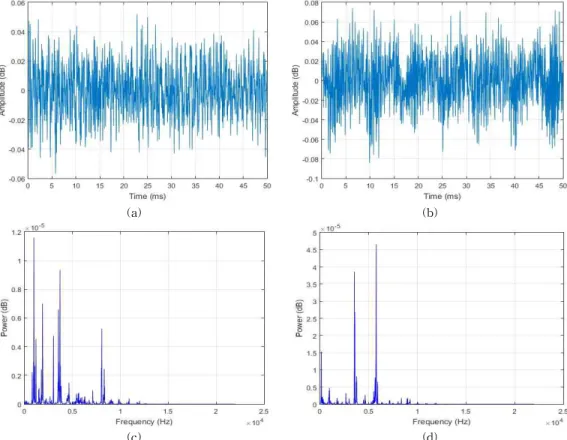
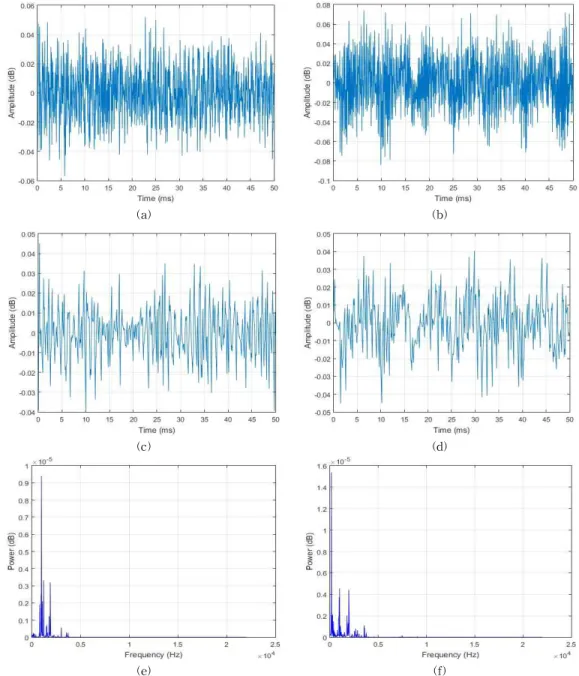
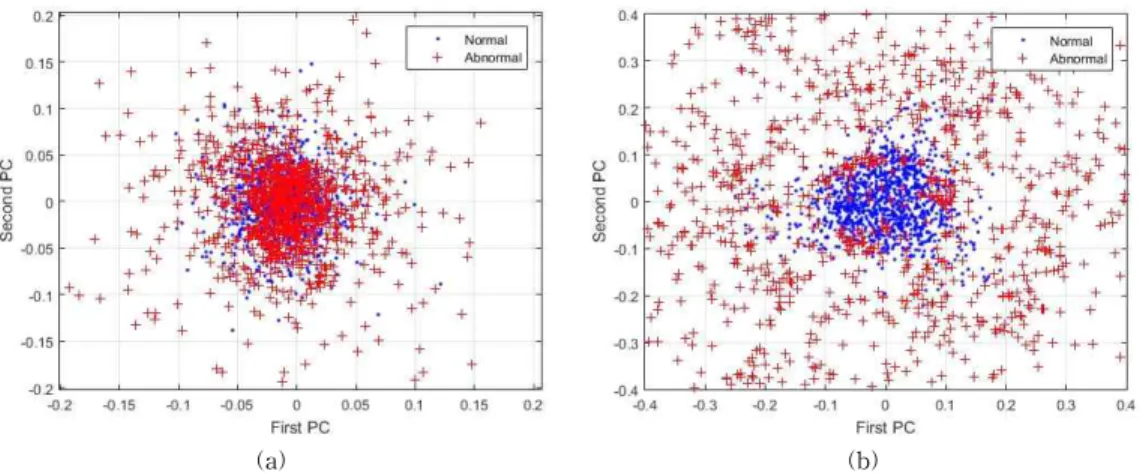
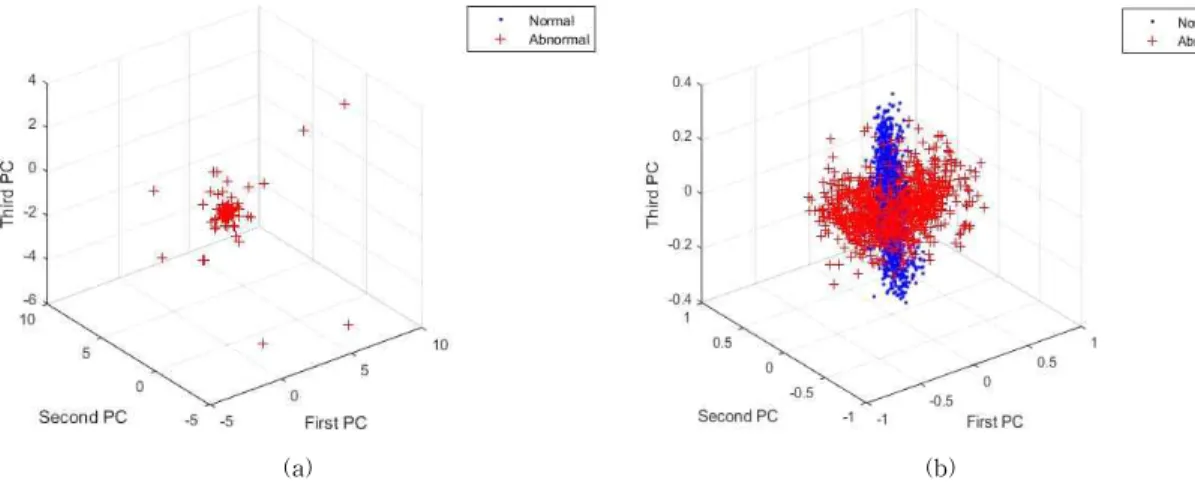
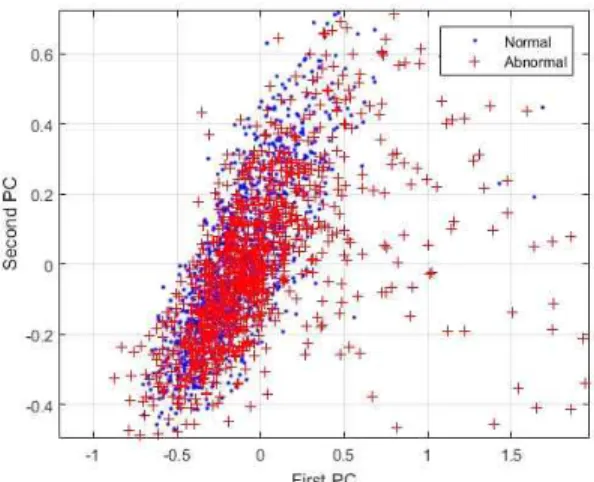
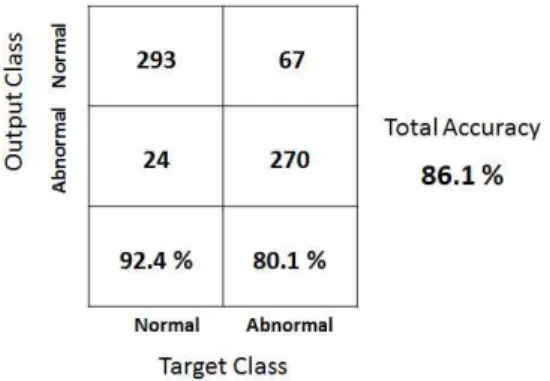
Sounds based machine fault diagnosis recovers all the studies that aim to detect automatically faults or damages on machines using the sounds emitted by these machines. Conventional methods that use mathematical models have been found inaccurate because of the complexity of the industry machinery systems and the obvious existence of nonlinear factors such as noises. Therefore, any fault diagnosis issue can be treated as a pattern recognition problem. We present here an automatic fault diagnosis system of hand drills using discrete wavelet transform (DWT) and pattern recognition techniques such as principal component analysis (PCA) and artificial neural networks (ANN). The diagnosis system consists of three steps. Because of the presence of many noisy patterns in our signals, we first conduct a filtering analysis based on DWT. Second, the wavelet coefficients of the filtered signals are extracted as our features for the pattern recognition part. Third, PCA is performed over the wavelet coefficients in order to reduce the dimensionality of the feature vectors. Finally, the very first principal components are used as the inputs of an ANN based classifier to detect the wear on the drills. The results show that the proposed DWT-PCA-ANN method can be used for the sounds based automated diagnosis system.
Key words: Pattern Recognition, Machine Learning, Machine Fault Diagnosis, Discrete Wavelet Transform, Principal Component Analysis, Artificial Neural Network
※ Corresponding Author : Ki-Ryong Kwon, Address:
(608-737) 599-1, 45 Yongso-ro, Namgu, Busan, Korea, TEL : +82-51-629-6257, FAX : +82-51-629-6230, E-mail : [email protected]
Receipt date : Jun. 21, 2017, Approval date : Aug. 1, 2017
††††
Dept. of IT Convergence and Application Engineering, Pukyong National University
(E-mail : [email protected])
††††
Dept. of IT Convergence and Application Engineering, Pukyong National University
(E-mail : [email protected])
††††
Dept. of Electronics Engineering, Pukyong National University (E-mail : [email protected])
††††
Dept. of Information Security, Tongmyong University (E-mail : [email protected])
†††††