JKSCI
A Study on Stock Trend Determination in Stock Trend Prediction
1)
Chungsoo Lim*
*Professor, Dept. of Electronic Eng., Korea National University of Transportation, Chungju, Korea
[Abstract]
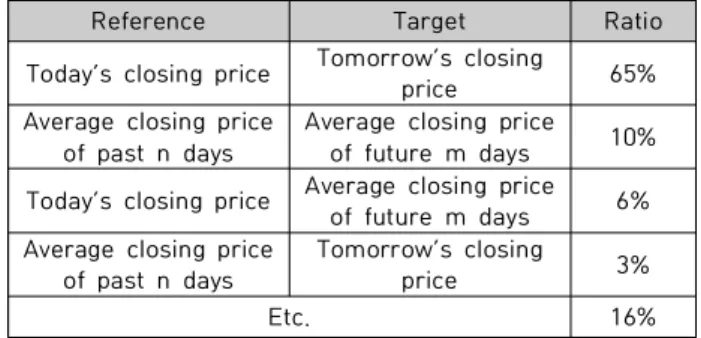
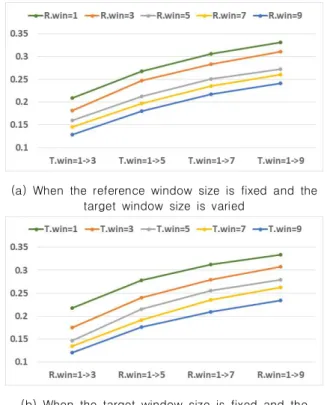
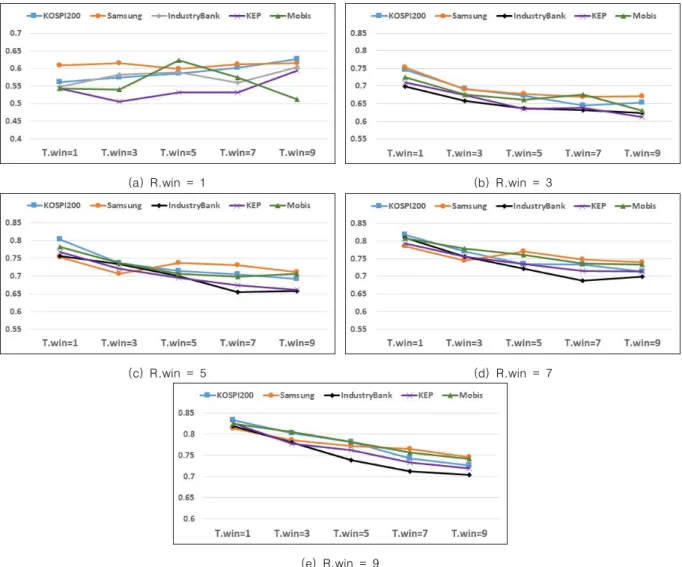
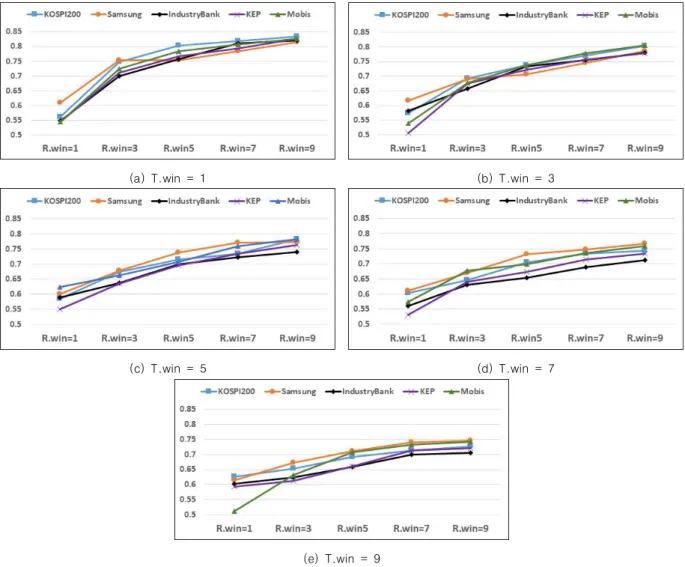
In this study, we analyze how stock trend determination affects trend prediction accuracy. In stock markets, successful investment requires accurate stock price trend prediction. Therefore, a volume of research has been conducted to improve the trend prediction accuracy. For example, information extracted from SNS (social networking service) and news articles by text mining algorithms is used to enhance the prediction accuracy. Moreover, various machine learning algorithms have been utilized. However, stock trend determination has not been properly analyzed, and conventionally used methods have been employed repeatedly. For this reason, we formulate the trend determination as a moving average-based procedure and analyze its impact on stock trend prediction accuracy. The analysis reveals that trend determination makes prediction accuracy vary as much as 47% and that prediction accuracy is proportional to and inversely proportional to reference window size and target window size, respectively.
▸Key words: Stock investment, Stock trend prediction, Stock trend determination, Machine learning
[요 약]
본 연구에서는 주가 결정 방법이 주가 경향 예측에 미치는 영향을 확인하기 위한 분석을 수행 한다 . 주식시장에서 성공적인 투자를 위해서는 주가의 상승과 하락을 정확하게 예측하는 것이 큰 도움이 되므로 주가 경향 예측에 관해 많은 연구가 진행되고 있다 . 예를 들어 근래에는 SNS나 뉴 스의 내용을 텍스트 마이닝을 이용하여 분석하고, 이를 이용한 주가 등락의 예측 방법이 제안되 었으며 다양한 기계학습 기법들이 활용되고 있다 . 그러나 주가의 경향을 ‘상승’ 또는 ‘하락’으로 결정하는 방법은 제대로 분석된 적 없으며 일반적으로 쓰던 방법을 답습하고 있다 . 이에 본 논문 에서는 주가 경향 결정 방법을 이동평균을 이용해 일반화하고 주가 경향 결정 방법이 예측 정확 도에 미치는 영향을 분석한다 . 분석 결과, 다음 날의 주가 경향을 예측하는 경우, 주가 경향 결정 방법에 따라 예측 정확도가 47%까지 차이가 남을 발견하였다. 또한 경향 결정에 사용되는 기준값 윈도우의 크기와 예측의 정확도는 비례 관계이며, 대상값 윈도우의 크기와 정확도는 반비례 관례 임을 알 수 있었다 .
▸주제어: 주식 투자, 주가 경향 예측, 주가 경향 결정, 기계학습
∙First Author: Chungsoo Lim, Corresponding Author: Chungsoo Lim
*Chungsoo Lim ([email protected]), Dept. of Electronic Eng., Korea National University of Transportation
∙Received: 2020. 08. 31, Revised: 2020. 11. 18, Accepted: 2020. 11. 19.
Copyright ⓒ 2020 The Korea Society of Computer and Information http://www.ksci.re.kr pISSN:1598-849X | eISSN:2383-9945