다축-다변량회귀분석 기법을 이용한 회분식 공정의 이상감지 및 통계적 제어 방법
우경섭·이창준·한경훈·고재욱*·윤인섭† 서울대학교화학생물공학부
151-742 서울시관악구신림동산 56-1
*광운대학교화학공학과 139-701 서울시노원구월계동 447-1 (2006년 11월 17일접수, 2006년 12월 13일채택)
Fault Detection & SPC of Batch Process using Multi-way Regression Method
Kyoung Sup Woo, Chang Jun Lee, Kyoung Hoon Han, Jae Wook Ko* and En Sup Yoon†
School of Chemical & Biological Engineering Seoul National University, San 56-1, Sillim-dong, Gwanak-gu, Seoul 151-742, Korea
*Department of Chemical Engineering Kwangwoon University, 447-1, Wolgye-dong, Nowon-gu, Seoul139-701, Korea (Received 17 November 2006; accepted 13 December 2006)
요 약
통계적인공정제어기법을회분식공정에적용하여, 일반적인회분식공정의데이터를통해보다빠르고, 손쉽게
공정의상태를진단할수있는시스템을구현해보았다. 대표적인회분식공정의하나인반도체식각공정과반회분식
스타이렌-부타디엔고무생산공정의데이터를이용하여공정변수와공정의상태간의연관관계를규명할수있는모 델을수립하였으며, 이모델의출력(output) 결과를이용해통계적공정제어차트를구성하고, 시간에따른공정의추
이를분석해이상을판별해보았다. 회분식공정의다축(multi-way) 데이터를두개의축으로만드는펼치기(unfolding)
과정을거쳤으며, 모델링방법으로는 Support Vector Regression 및 Partial Least Square 등의다변량회귀분석방법을
이용하였다. 또한에러차트및변수기여도차트(variable contribution chart)를이용해이상의세기, 형태및이상데이
터에대한각변수들의기여도를계산해보았으며, 그결과이상의발생유무및발생시점뿐만아니라이상의세기및
원인까지진단해볼수있는우수한성능을보이는것을확인할수있었다.
Abstract −A batch Process has a multi-way data structure that consists of batch-time-variable axis, so the statistical modeling of a batch process is a difficult and challenging issue to the process engineers. In this study, We applied a sta- tistical process control technique to the general batch process data. and implemented a fault-detection and Statistical pro- cess control system that was able to detect, identify and diagnose the fault. Semiconductor etch process and semi-batch styrene-butadiene rubber process data are used to case study. Before the modeling, we pre-processed the data using the multi-way unfolding technique to decompose the data structure. Multivariate regression techniques like support vector regression and partial least squares were used to identify the relation between the process variables and process condi- tion. Finally, we constructed the root mean squared error chart and variable contribution chart to diagnose the faults.
Key words: Batch Process, Fault Detection, Statistical Process Control, Multi-way Unfolding, Support Vector Regression, Partial Least Squares
1. 서 론
최근센서및컴퓨터의발달로공정에서실시간으로수많은데 이터를얻고관리할수있게됨에따라이러한데이터를이용한다 변량통계적인공정관리기법(multivariate statistical process control)이 각광을받고있다. 통계적인공정관리기법은기존의제어모델에
비해공정의복잡한 modeling 과정을거치지않고도공정의데이
터만으로손쉽게공정의상태를알아낼수있다는점에서이점을 가지고있다. 또한직접제품의품질을검사하거나, 제품의품질과 직결되는변수가있지않더라도, 여러변수들의상태를총체적으로
파악해빠르게공정의이상유무를알아낼수있다. 이러한통계적 공정제어방법에서는공정의수많은데이터중에서유용한정보 를찾아내강건성(robustness)과민감성(sensitivity)을모두갖춘시 스템을구현하는것이중요하기때문에, 최근이에대한많은연구
†To whom correspondence should be addressed.
E-mail: [email protected]
가이루어지고있다.
회분식공정은화학산업을비롯해제약, 생명과학, 반도체산업 등많은산업분야에서두루사용되는공정중의하나이다. 회분식 공정은주로고부가가치의제품을소량으로생산하는공정으로이 용되기때문에공정의이상을조기에발견해서제품의품질을균 일하게제어하는것은공정의생산비용감소및이익증대에결 정적인영향을미친다. 회분식공정의데이터는일반적인화학공
정데이터처럼고도의비선형성(nonlinearity)을가지고있고, 시
간×변수(two-way) 축으로이루어지는연속반응공정(continuous process)과는달리 Batch×시간×변수(tree-way) 축으로이루어지는
데이터상의특성과, batch 마다조업시간및조업환경이변하는
Process drift 나 batch-to-batch variation과같은난점들이존재한다[1].
본연구에서는통계적인공정관리기법을 Batch 공정에적용하
여, 일반적인회분식공정의데이터를통해보다빠르고, 손쉽게공 정의상태를모니터링할수있는시스템을구현해보았다. 축펼치기
(multi-way unfolding) 방법을이용해데이터를전처리(pre-processing)
한후 M-PLS(multiway-partial least square) 및 M-SVR(multiway- support vector regression) 기법을이용하여공정의데이터와공정
의상태간의연관관계를알아낼수있는모델을구현하였으며, 이
를이용한제어차트(control chart)를구성하여시간에따라회분
식공정의상태를감지하고, 이상의발생유무를판단할수있는 시스템을구현하였다.
이와같은방법을반도체식각공정(semiconductor etch process)
및스타이렌-부타디엔고무(styrene-butadiene rubber) 생산공정데 이터에적용하여보았으며, 그결과효과적으로공정의이상을감 지하고, 우수한모니터링성능을보이는것을확인할수있었다.
2. 본 론
2-1.
데이터 전처리(preprocessing)
회분식공정의데이터축은연속공정데이터와는다르게 3개의 축으로구성된다. 이는연속공정의 ‘변수×시간’ 데이터구조가
각 batch별로존재하기때문이다. 따라서일반적인회분식공정의
데이터는 ‘batch(I) ×변수(J) ×시간(K)’의 3축구조(3-way structure)
를가지게된다. 그뿐만아니라각 batch의시간길이도일정하지
않고, batch에따라조금씩 sensor shift나 process drift가일어나기 때문에통계적인모델을수립하는데어려운점이많다. 이와같은 이유때문에데이터의전처리과정은통계적인모델수립에필수 적인과정이라고할수있다. 크게세가지의데이터전처리과정
을들수있는데, 한가지는서로다른 batch 길이를해결하기위
한방법이고, 두번째는 3축데이터를 2개의축으로사영시키는방 법이다. 그리고마지막은회귀분석모델을수립할때각변수들의
변화량이주는영향을동일하게하기위한스케일링과정을거쳤 다. sensor shift나 process drift 문제에는현재에가까운데이터일
수록가중치를주는방법(EWMA)[4] 등이이용되고있으나본연
구에서는시간간격이그리크지않은 batch 데이터를이용하였으
므로적용하지않았다.
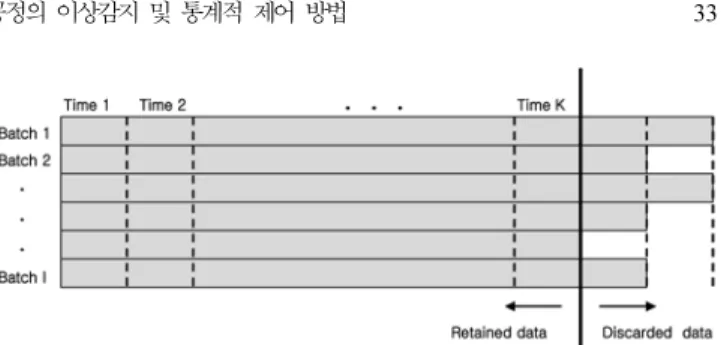
첫번째로각 batch들의길이가다를경우 Fig. 1과같이길이가
최소인 batch를기준으로데이터의앞부분이나뒷부분을쳐내는방
법을사용하였는데, 대개의경우 batch 시간의차이는전체 batch
길이에비해무시할수있을정도로작기때문에쉽게이용되는방
법이다. 이밖에도 Dynamic time wrapping[3]이나 Pseudo batch를 만드는방법[8]등다양한방법들을사용할수있다.
두번째로는 3축의 데이터를 2개의 축으로사영시키기위해
Multiway-unfolding 방법을사용하였다. Multiway-unfolding 방법
이란회분식공정의 3축데이터(I × J × K) 중에두개의축을묶어
서총 2개의축으로사영시키는방법을일컫는데, 어느축을통합 하느냐에따라서 Batch-wise unfolding(I × JK) 또는 Variable-wise unfolding(IK × J)으로분류할수있다(Fig. 2).
Batch-wise unfolding 방법이각각의 Batch 상태를총체적으로
파악하는데에는유리한반면에, 시간에따른변수및각 batch들
의상태변화를예측하는모델을만드는데에는부적합하기때문 에 Variable-wise unfolding 방법을사용하였다.
마지막으로회귀분석모델을만드는데에있어서각변수들이가 지는영향력을모두같게하기위해 Column auto-scaling 방법을사용 하여, 각변수들이모두표준정규분포(standard normal distribution)
를따르도록데이터를구성하였다.
2-2.
다변량회귀분석전처리된 데이터를이용한 모델링방법으로는 Partial Least Square(PLS)와 Support Vector Regression(SVR) 기법을사용하였 다. 회귀분석방법을이용한이유는공정의데이터(원인)와공정의
상태(결과) 간의인과관계를파악해, 공정의데이터만으로공정의
Fig. 1. Preprocessing for the proposed modeling when batch lengths are different.
Fig. 2. Two unfolding methods.
이상을진단해낼수있는모델을만들기위해서이다.
PLS 기법은공정의원인변수들과결과변수들사이의공분산
을최대화할수있는원인변수들의요소를순서대로파악하여,
결과변수에가장큰영향을미치는변수들만으로회귀분석을수
행하는방법으로요약할수있다. 예를들어원인변수 X(m × nx : m
=관찰횟수, nx =원인변수의개수)와결과변수 Y(m × ny : ny
=결과변수의개수)가있을때원인변수의요소는 tk, 결과변수
의요소는 uk가된다. tk와 uk vector는두 vector들간의공분산을 최대화할수있도록선택된다.
(1) E와 F는 error이고 pk와 qk는 loading vector이다.
이후 tk와 uk vector 간에회귀분석이수행되는데, 선형회귀분석
을사용하면선형 PLS, 비선형방법을사용하면비선형 PLS로분
류된다.
본연구에서는 2차식모형을이용한회귀분석(quadratic PLS)을
수행하였다.
SVR 기법은 AT&T Bell 연구소의 Vapnik(1992)에의해개발된
Support Vector Machine 알고리즘에기반한회귀분석방법으로, 후 속연구들을통해우수한성능을보이는것이입증되었다[6].
기본적인아이디어는데이터 X를고차원공간으로사상시키는
nonlinear mapping Φ을거친후에그공간에서회귀분석을수행하
는것인데, 식(2)와같이고차원평면에서 margin이최대가되는
초평면(hyperplane)을찾는방법이다.
(2)
margin을최대화하는문제는곧, Risk를최소화하는문제로귀결
될수있는데, 이에따른 Risk 함수를구성하고 (3)
min R(C) = (3)
제약조건에따라최적화를수행해 Karush-Kuhn-Tucker(KKT)
조건에맞는최적분류초평면(optimal seperating hyperplane)을찾 는다.
사상함수 Φi(x)는실제로구체적인형태를알필요없이다음과 같이정의되는커널함수(kernel function)를사용한다.
(4)
본연구에서는 2nd-order polynomial kernel 및ε-insensitive loss function을사용해 SV-Regression을수행하였다.
2-3.
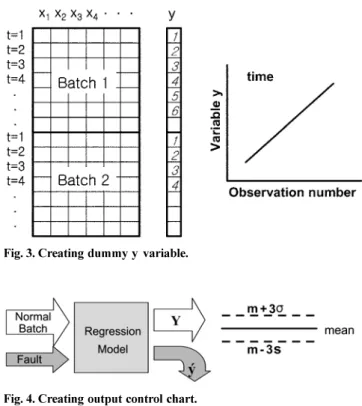
모니터링회귀분석의경우결과변수 y는공정의상태나제품의품질을
나타내는변수로구성하게된다. 따라서결과변수를품질변수
(quality variable)라하기도한다. 하지만이러한결과변수는공정 이끝난이후품질검사를통해얻어지거나, 실시간으로얻어지기 어려운경우가대부분이기때문에, 실시간모니터링에는이용할수
없는경우가많다. 따라서관찰변수로시간에따른더미 y 변수
(dummy y variable)를만들어회귀분석을수행하기도한다. [2, 5, 8]
본연구에서도 Fig. 3과같이공정의시간(local batch time)으로더 미 y 변수를생성하여이용하였다.
먼저정상적인 Batch들중일부를가지고회귀분석방법을이용
해 Batch data와더미 y 변수간의인과관계모델을만든뒤, Fig. 4
처럼학습에이용된정상적인 batch 데이터출력값(output)들의평
균과편차를통해제어차트를구성하였고, 학습에사용되지않은
정상적인 batch 데이터들을이용해모델의정확성을 검증한후
(cross-validation) 이상데이터들을판별해보았다. 이때제어한계
(control limit)가너무작으면이상뿐만아니라정상데이터까지이
상으로판별할수있고, 너무넓으면이상데이터까지정상으로판
별할수있기때문에일반적으로통계제어방법에이용되는 3σ를 제어한계로설정한후수행하였다.
이후이상데이터들이제어한계에서얼마나벗어나는지를계산 해 Root mean square error(RMSE) chart를만들어각이상의추
이를살펴보았다. Error는식 (5)와같이이상데이터들의출력값 과정상데이터의평균출력값의차이를제어구간의크기로나누 어계산하였다.
RMSE = (5)
또, 각변수별로정상데이터와의차이를식 (6)과같이계산하여
기여도(contribution) 차트를만들어어떤변수로인해이상이발생
하였는지분석해보았다.
Contrib. = (6)
X tkpkT k 1= np nx<
= ∑ E and Y ukqkT+F
k 1= np nx<
= ∑ +
y wiΦi i 1=
∑I
= +b
C1N---- Li 1∑=N ε(di,yi) 1 2--- w2 +
K x( j,xj) Φ= i( )xiTΦi( )xj
yˆi–µi
( )2
i 1=
∑k
3σi
---
Xi–Xi
( )
i 1=
∑n
---n
Fig. 3. Creating dummy yvariable.
Fig. 4. Creating output control chart.
3. 사례 연구
3-1.
반도체 식각공정(semiconductor etch process)
반도체를생산하는공정은식각공정(etch)을비롯한수많은단계
들로이루어지는데, 식각공정은각각의 wafer별로반응이따로진
행되기때문에회분식공정이라고볼수있다. 본연구에서는상업 적으로이용가능한 Lam 9600 plasma etch tool을통해얻은 Al-stack etch 공정의 machine 데이터를사용하였다. 이공정은 BCl3/Cl2 plasma
를사용하여 TiN/Al~0.5% Cu/TiN/oxide stack을식각하는공정으로,
Al layer를균일한깊이와폭으로깎는것이중요하다.
공정은 6단계로진행되는데, 첫단계와두번째단계는반응기
(chamber) 내에가스를흘려주고, 압력을안정화시키는과정이고,
세번째단계는플라즈마(plasma) 점화단계, 네번째는 Al 층의 main etch 단계, 다섯번째는아대층의 TiN, oxide layer의 overetch 단계,
여섯번째는반응기를비우는(vent) 단계로진행된다.
데이터는한달이상의긴시간간격을두고진행된 3번의실험
으로얻어진총 127개 batch로구성되어있으며, 20개의유도된이
상 batch(induced-faults)를포함하고있다(Table 1). batch 시간은 1
초간격으로측정된 80개의 time step으로구성되며, 측정변수는
12개로이루어져있다(127 × 12 × 80)(Table 2).
3-2.
스타이렌-부타디엔고무공정(SBR)
에멀젼중합(emulsion polymerization)에의해스타이렌부타디 엔고무(styrene-butadiene rubber)를생산하는공정은 1930년대독
일에서 Buna-S라는이름으로알려진이래현재까지세계적으로가
장많이이용되는고분자공정의하나이다. 에멀젼중합반응은보
통유순한(mild) 공정조건과에멀젼의물성덕분에공정제어에도유
리하고, 벌크중합(bulk polymerization)에비해점도(viscosity)로 인한문제도덜한편이다.
본연구에적용한데이터는 semi-batch 에멀젼중합공정으로,
총 53개의 batch로구성되어있으며, Table 3과같이한 batch 당
측정변수 9개를 200 time point 동안관찰한데이터로구성되어
있다(53 × 9 × 200). 또한, Table 4와같이 53개 batch의생산제품 당측정한 5개의품질변수(quality variables, 53 × 5)를통해제품 의품질을예측할수있다.
4. 결과 분석
4-1.
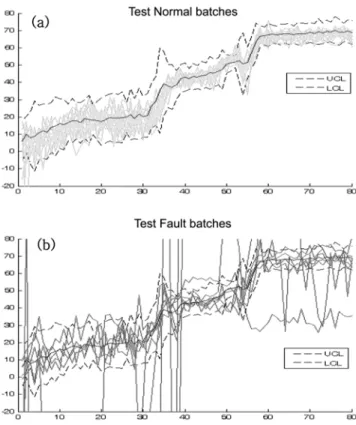
반도체식각공정결과정상 34개, 이상 9개씩총 43개의 batch로구성된 Exp 29 데이
터를이용한결과는다음과같다. 우선정상 batch 중 17개의 batch
를가지고 SVR을이용해회귀분석모델학습을진행하였고, 학습
데이터의평균과편차로만든통계 제어차트(statistical control
chart)에나머지 17개의정상 batch 데이터와 9개의이상데이터를도
시해보았다. 그결과 Fig. 5와같이정상적인 batch의모델출력값들 은대부분제어한계(control limit)를벗어나지않는반면에, 이상이
있는 batch들은제어한계에서많이벗어나는것을확인할수있었
고, 이를통해볼때구현된모델의신뢰성을확인할수있었다.
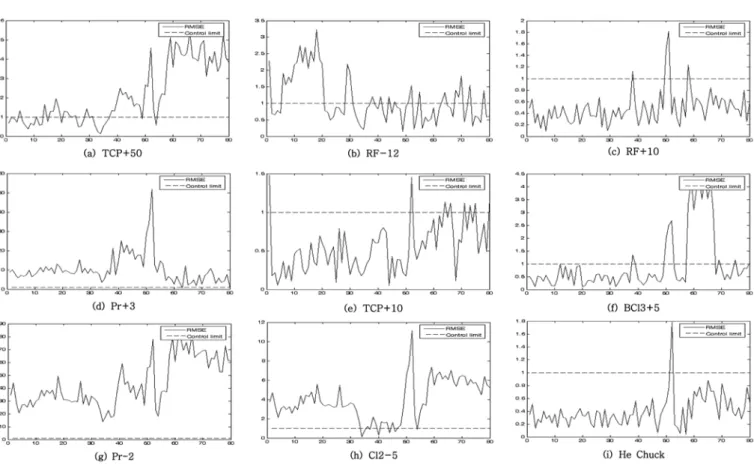
다음으로 9개의이상에대해서각각제어한계에서벗어난정도 (RMSE)를계산한결과는 Fig. 6과같다.
Table 2. 12-measured variables
1 Endpoint A Detector 7 RF Impedance
2 Chamber Pressure 8 TCP Tuner
3 RF Tuner 9 TCP Phase Error
4 RF Load 10 TCP Reflected Power
5 RF Phase Error 11 TCP Load
6 RF Power 12 Vat Valve
Table 3. 9-measured variables
1 Feed Styrene 6 T R. Jackt .
2 Feed Butadiene 7 Latex Density
3 Temp. Feed 8 Conversion
4 Temp. Reactor 9 Energy Rel
5 Temp. Cooling
Table 1. 3-experiment batch data set
Normal Fault Total
Exp29 34 9 43
Exp31 36 5 41
Exp33 37 6 43
Total 107 20 107
Table 4. 5-quality variables
1 Composition 4 Cross Link
2 Particle Size 5 Polydispersion
3 Branching
Fig. 5. Regression model output of Noramal data (a), Fault data (b).
Fig. 6. Root mean square error chart for all fault batches.
Fig. 7. Variable contribution chart for all batches.
그결과 Fig. 6과같이각각의이상의종류에따라고유한발생
시기및세기(intensity)를가지는것을확인할수있었다. 이러한
이상의추이에따라새로운 batch 데이터들의이상유무및종류
를판별할수있다. 다음으로각각의이상에대한변수기여도차 트를그려본결과는 Fig. 7과같다.
가령어떤 batch에서 TCP + 50으로인한이상이발생할경우, 모
델의출력값이 Fig. 6(a) 처럼초반에약간씩제어한계를넘다가
40초이후로는제어한계를크게벗어나는형태를보이고, 그러한
결과가발생하는원인은 Fig. 7(a)에서처럼 1번, 4번, 8번, 11번변 수값들이정상과크게다르기때문이라는해석을내릴수있다.
Exp31(41batches, 5faults)와, Exp33(43batches, 6faults) 실험셋 에본방법을적용한결과에도나머지 11가지종류의이상을정확
히식별해내었으며, 각각의이상에대한원인을분석해볼수있 었다.
4-2. SBR
공정결과SBR 공정의데이터는 5개의품질변수(quality variable)를가지 고있다는점에서반도체식각공정데이터와는다르다고할수있
다. 이품질변수는각각의 batch별로공정이끝난후제품의품질
을분석한 1 time의측정값만을가지기때문에, 우선 Fig. 8과같
이 53개 batch의품질변수값을 auto-scaling한후 control chart를
만들어제어한계(LCL)를벗어나는 2개의 batch를찾아임의의이
상 batch로설정하였다.
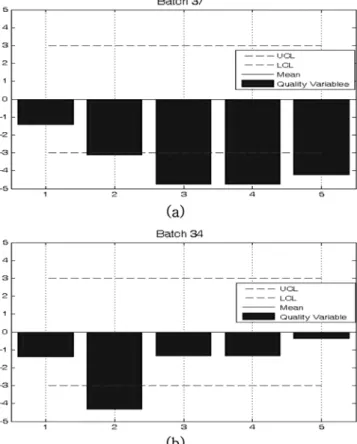
임의의이상 batch 34와 37의 scaling된품질변수값은 Fig. 9와 같다.
정상데이터 51개중 27개로 PLS 방법을이용하여회귀분석모
델을만든후나머지 24개정상 batch와 2개의이상 batch에적용
해보았다. 그결과 Fig. 10에서볼수있는바와같이정상적인
batch 데이터들의출력값들은제어영역을벗어나지않는반면에,
Fig. 8. Quality variable chart for all batches.
Fig. 9. Quality variable for batch 34(a), batch 37(b).
Fig. 10. Regression model output for Normal batches(a), Fault 1(b), Fault 2(c).
제품의품질에이상이있는 batch 34와 batch 37의출력값들은제 어한계를벗어나는것을확인할수있다.
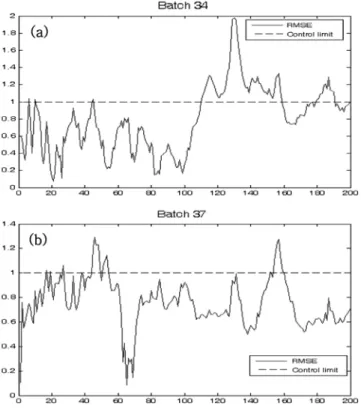
이들이상에대한 Error chart와 contribution chart를그려본결
과각각이상의추이는 Fig. 11과같았으며, 각이상의원인변수
들은 Fig. 12와같았다.
SBR 공정에대한사례연구결과공정이끝난이후에알수있
는품질의이상(품질변수측정결과)을제안된모델로도충분히 감지할수있음을증명하였으며, 이는품질변수가없거나, 실시간
으로측정할수없는경우에도공정의원인변수(cause variable)만
으로제품의이상을미리발견해낼수있다는것을보였다는점 에서의미가있다고할수있다.
5. 결 론
본연구에서는새로운다축-다변량회귀분석방법론을반도체식
각공정및 Semi-batch SBR 공정모니터링에적용해보았다. 뿐만
아니라회귀분석모델의출력값을통해제어차트를구성하고, 이 러한결과들을통해 PC 기반방법에서사용하는 T2나 SPE(squared prediction error) 차트처럼, RMSE 차트, 기여도차트를이용해서 각각의이상을식별하고, 원인을분석할수있도록하였다. 사례연
구결과제안된다축-다변량회귀분석방법론이 batch 공정의이상
감지및모니터링에우수한성능을보이는것을알수있었다. 또
한제안된모델은시간에따른공정의상태및추이를지켜볼수 있기때문에, 실시간모니터링에도이용될수있다는점에서의미 가크다고할수있다.
참고문헌
1. Nomikos, P. and MacGregor, J. F., “Monitoring Batch Processes Using Multiway Principal Component Analysis,”AIChE J.,
40
(8), 1361-1375(1994).2. Wold, S., Kettaneh, N., Friden, H. and Holmberg, A., “Modeling and Diagnostics of Batch Processes and Analogous Kinetic Experiments,”Chemometrics Intell. Lab. Syst.,
44
(1), 331-340(1998).3. Kassidas, A., Macgregor, J. F. and Taylor, P. A., “Synchroniza- tion of Batch Trejectories Using Dynamic time Warping,”AIChE J.,
44
(4), 864-875(1998).4. Wise, B. M., Gallagher, N. B., Butler, S. W., White, Jr. D. D. and Barna, G. G., “A Comparison of Principal Components Analysis, Multi-way Principal Components Analysis, Tri-linear Decompo- sition and Parallel Factor Analysis for Fault Detection in a Semi- conductor Etch Process,”J. Chemometrics.,
13
(3-4),379-396(1999).5. Theodora Kourti, “Abnormal Situation Detection, Three-way Data and Projection Method; Robust Data Archiving and Modeling for Industrial Applications,”Annual Rewiew in Control.,
27
(2), 131- 139(2003).6. Smola, A. J., Schölkopf, B., “A Tutorial on Support Vector Regres- sion,”Statistics and Computing.,
14
(3), 199-222(2004).7. Lee, J. M., Yoo, C. K. and Lee, I. B., “Enhanced Process Moni- toring of Fed Batch Penicillin Cultivation Using Time-varying and Multivariate Statistical Analysis,”J. Biotechnology.,
110
(2), 119-136(2004).8. Simoglou, A., Georgieva, P., Martin, E. B., Morris, A. J. and Feyo de Azevedo, S., “On-line Monitoring of a Sugar Crystalli- zation Process,”Comp. Chem. Eng.,
29
(6), 1411-1422(2005).9. Marjanovic, O., Lennox, B., Sandoz, D., Smith, K. and Crofts, M., “Real-time Monitoring of an Industrial Batch Process,”
Comp. Chem. Eng.,
30
(10-12), 1476-1481(2006).Fig. 11. RMSE Chart for Batch 34(a), Batch 37(b).
Fig. 12. Contribution Chart for Batch34(a), Batch37(b).