水 工 學
大 韓 土 木 學 會 論 文 集第28卷 第4B 號·2008年 7月 pp. 363 ~ 374
누가분포함수를 활용한 강우강도식의 국내 적용성 평가
Application of Intensity-Duration-Frequency Curve to Korea Derived by Cumulative Distribution Function
김규태*·김태순**·김수영***·허준행****
Kim, Kewtae
·
Kim, Taesoon·
Kim, Sooyoung·
Heo, Jun-Haeng···
Abstract
Intensity-Duration-Frequency (IDF) curve that is essential to calculate rainfall quantiles for designing hydraulic structures in Korea is generally formulated by regression analysis. In this study, IDF curve derived by the cumulative distribution function (“IDF by CDF”) of the proper probability distribution function (PDF) of each site is suggested, and the corresponding param- eters of IDF curve are computed using genetic algorithm (GA). For this purpose, IDF by CDF and the conventional IDF derived by regression analysis (“IDF by REG”) were computed for 22 Korea Meteorological Administration (KMA) rainfall recording sites. Comparisons of RMSE (root mean squared error) and RRMSE (Relative RMSE) of rainfall intensities com- puted from IDF by CDF and IDF by REG show that IDF by CDF is more accurate than IDF by REG. In order to accom- modate the effect of the recent intensive rainfall of Korea, the rainfall intensities computed by the two IDF curves are compared with that by at-site frequency analysis using the rainfall data recorded by 2006, and the result from IDF by CDF show the better performance than that from IDF by REG. As a result, it can be said that the suggested IDF by CDF curve would be the more efficient IDF curve than that computed by regression analysis and could be applied for Korean rainfall data.
Keywords : intensity-duration-frequency curve, cumulative distribution function, genetic algorithm, parameter estimation
···
요 지
국내에서 수공구조물의 설계를 위한 확률강우량을 산정하기 위해서 널리 사용되는 강우강도식은 주로 회귀분석을 적용한 형태가 일반적이지만, 본 연구에서는 각 지점별 적정확률분포형의 누가분포함수를 활용하여 강우강도식의 형태를 결정하고, 매개변수는 유전자알고리즘을 적용하여 추정하는 강우강도식을 제안하고자 한다. 기존에 사용하던 강우강도식과의 정확도 비 교를 위하여 기상청 22개 지점에 대한 재현기간, 지속기간별 평균제곱근오차, 평균제곱근 상대오차를 검토한 결과 누가분포 함수를 활용한 강우강도식이 더 높은 정확도를 가짐을 보였으며, 또한, 최근의 집중호우에 대한 영향을 살펴보기 위하여
2006년 까지의 강우자료를 이용하여 기존의 회귀식에 의한 방법과 누가분포함수를 활용한 경우의 결과값을 비교한 결과 이 경우에도 누가분포함수를 활용한 강우강도식의 정확도가 더 높음을 알 수 있었다. 결과적으로 본 연구에서 제안된 누가분포 함수를 활용한 강우강도식은 기존의 회귀분석을 활용한 강우강도식보다 정확도면에서 우수하다고 할 수 있으며, 국내에 충분 히 적용가능한 형태의 강우강도식이라고 판단된다.
핵심용어
:강우강도식, 누가분포함수, 유전자알고리즘, 매개변수추정
···
1.
서 론
주어진 해당지점에 대해서 서로 다른 지속기간(duration)과 재현기간(frequency)을 고려한 확률강우량을 구하는 것은 크 게 지점 및 지역빈도해석(at-site and regional frequency
analysis)
을 포함한 빈도해석 절차를 이용하는 것이 보통이다.
이런 빈도해석을 위해서는 원하는 지속기간에 대해서 충분 한 기간동안 관측된 강우량 자료를 구축한 후 다양한 확률 분포형의 매개변수를 구하고 이를 이용하여 대상지점에 대
한 적정확률분포형을 적합도검정(goodness-of-fit test)등의 방 법을 통해서 선정하는 복잡한 과정을 거치게 된다.
이런 방법은 정확한 확률강우량값을 얻을 수 있는 장점이 있는 반면에 적어도 30년 이상의 기간동안 구축된 강우량 자료가 필요하며, 확률분포형의 매개변수를 구하거나 적합도 검정을 하는 등의 과정에 상당히 전문적인 지식이 필요하다 는 단점이 있다. 반면에, 빈도해석으로 구한 확률강우량을 활 용한 강우강도식(intensity-duration-frequency curve)은, 빈도 해석을 통한 분석보다는 정확도가 떨어지지만 한번 강우강
*정회원·연세대학교 사회환경시스템공학부 석사과정 (E-mail : [email protected])
**정회원·연세대학교사회환경시스템공학부 BK21 연구교수 (E-mail : [email protected])
***정회원·연세대학교 사회환경시스템공학부 박사과정 (E-mail : [email protected])
****정회원·교신저자·연세대학교사회환경시스템공학부교수 (E-mail : [email protected])
도식의 매개변수를 결정해놓으면 별다른 추가적인 작업 없 이도 비교적 정확한 확률강우량 혹은 강우강도를 얻을 수 있으며, 또한 과거의 강우자료가 구축되지 않은 임의의 지속 기간에 대한 결과값도 손쉽게 얻을 수 있는 장점이 있다.
강우자료를 활용한 빈도해석을 이용해서 강우강도식을 유 도한 이후에는, 추가적인 빈도해석 절차 없이도 임의의 지속 기간에 대한 강우강도를 손쉽게 얻을 수 있다는 장점 때문 에 국내에서도 강우강도식은 폭넓게 사용되고 있으며, 기존 에 널리 사용되던 Talbot, Sherman, Japanese형의 강우강도 식(윤용남, 1998; 이원환, 1997)을 개선하기 위해서 여러 가 지 강우강도식이 개발되어 왔다(이원환, 1980; 이원환 등,
1993;
허준행 등, 1999). 하지만, 기존에 개발되던 강우강도
식의 형태는 경험적인 사실에 바탕을 두고 각 식의 매개변 수를 모두 회귀분석(regression analysis)에 의해서 구하는 형태이므로 강우강도식이 적용되는 해당지역의 강우가 가지 는 특성을 이론적인 근거를 바탕으로 반영했다고 말하기는 어렵다고 할 수 있다.
본 연구의 목적은 기존에 국내에 적용되고 있던 강우강도 식의 형태를 이론적인 근거를 가지는 형태로 개선하기 위한 것으로서, Koutsoyiannis et al.(1998)에 의해서 제안된 누가 분포함수를 활용한 강우강도식의 형태를 기본적으로 활용하 고 매개변수를 추정하는데 있어서는 회귀분석방법보다 적용 성에 있어서 더 효율적인 유전자알고리즘을 이용하여, 전국 에 있는 기상청산하 22개 관측지점에 대한 강우강도식의 매 개변수를 새롭게 추정하여 제안하고자 한다.
이를 위해서 기존에 사용되던 강우강도식 중에서 비교적 정확도가 높다고 알려진 허준행 등(허준행 등, 1999)이 개발 한 강우강도식을 대상으로 새롭게 유도된 강우강도식의 정 확도를 비교하고, 매개변수 추정을 위한 유전자알고리즘을 적용하는데 있어서 필수적인 개체수(population number)와 세대수(generation number)를 결정하며, 대상지점에 대한 새 로운 강우강도식의 매개변수를 제안함으로써 국내에 적용할 수 있는 새로운 강우강도식을 제시하고자 한다.
2.
기본이론
2.1
대상지점의 누가분포함수를 고려한 강우강도식 강우강도식은 강우강도-지속기간-재현기간(Intensity-Duration-
Frequency, IDF)
사이의 관계를 나타내기 위해서 사용하는
식으로, 주로 수공구조물을 설계할 때 복잡한 빈도해석
(frequency analysis)
을 거치지 않고 간략하게 원하는 재현기
간에 대한 강우강도 혹은 확률강우량을 산정하기 위해서 사 용한다. 우리나라에서는 주로 Talbot, Sherman, Japanese형 과 같이 간단한 형태의 강우강도식이 사용되고 있으며, 국내 에서 개발된 강우강도식은 이원환 등(1993), 허준행 등
(1999)이 제안한 식이 있다.
다음의 식 (1)~(3)은 각각 국내에서 주로 사용되고 있는 강우강도식을 나타낸 것이다.
(1)
(2)
(3)
여기서, I(t)와 I(t, T)는 강우강도(mm/hr), t는 지속기간
(min), T는 재현기간(year)이며, a, b, c, d, n은 각 지점마 다 산정되는 매개변수이다. 식 (1)은 이원환(1980)에 의해서 제시된 강우강도식으로, Talbot, Sherman, Japanese형을 통 합한 형태로 나타낸 것이고, 식 (2)는 이원환 등(1993)에 의 해서 개발된 식으로 식 (1)이 재현기간을 고려하지 못하는 단점을 개선한 형태로 개발된 식이다. 반면에 식 (3)은 재현 기간별로 서로 다른 매개변수를 사용하던 식 (2)의 단점을 개선한 것으로 재현기간별로 같은 매개변수를 사용하더라도 정확도 면에서는 기존에 개발된 강우강도식과 크게 차이가 없는 형태로 개발된 식이다.
최근에는 위에서 언급한 것과 같이 제안자의 경험적인 판 단이나 회귀분석의 용이함을 위해서 강우강도식의 형태를 결 정하는 것이 아니라, 대상지점의 확률분포형을 고려한 형태 의 강우강도식을 이용한 결과들이 제안되고 있다(Koutso-
yiannis et al., 1998; Mohymont et al., 2004).이와 같은 강우강도식은 기본적으로 식 (1)과 같은 형태의 강우강도식 의 분자항을 확률분포형의 누가분포함수(cumulative distribution
function, CDF)
를 이용하여 표현할 수 있다는 성질을 이용
한 것으로 Koutsoyiannis et al.(1998)에 의해서 제안되었다.
여러 강우강도식의 형태 중 다음의 식 (4)는 가장 기본적 이면서도 비교적 효율적인 강우강도식으로 알려져 있다
(Baldassarre et al., 2006; Bernard, 1932; Chen, 1983; Kout- soyiannis et al., 1998; Meyer, 1928; Mohymont et al., 2004;Sherman, 1931).
(4)
여기서, i는 강우강도를 나타내며, d는 지속기간,
ω, ν, θ, η는 매개변수를 의미한다. 식 (4)의 좌변에 위치한 강우강도 는 일반적으로 일정한 지속기간에 대한 평균값을 의미하는 것이 보통이다. 즉, 자연 현상에서는 순간적으로 발생하는 강 우강도이지만 실제로는 이런 순간강우강도(instantaneous
rainfall intensity)를 측정할 수가 없으므로 일정한 시간간격
(time window)
을 설정한 후 해당 시간간격에 대해서 적분,
혹은 평균하는 형태를 취한다.
여기서 주목해야 할 것은, 강우강도식을 결정하는 세 가지 요소인 강우강도(rainfall intensity), 지속기간(duration), 재현 기간(frequency)간의 관계이다. 즉, 식 (4)의 좌변에 위치한 강우강도는 자연현상인 순간강우강도를 일정한 시간단위로 평균한 후 매년최대치(annual maximum) 혹은 일정한 강우 강도를 넘는 값(threshold)을 추출하는 과정이므로 임의변수
(random variable)라고 할 수 있는 반면에, 지속기간은 관측 자가 임의로 결정하는 값이므로(예를 들어서 10분, 30분, 혹 은 24시간 등) 임의변수가 될 수 없다는 것이다.
또한, 식 (4)의 분모인 (d
v+θ)η중에서
ν는 값의 변화에 따른 강우강도식 정확도의 변화가 극히 적으므로
ν=1로 할 수 있으며 남아있는 두 개의 매개변수인
θ와
η는 재현기 간과는 상관이 없는 상수매개변수이고, 분자인
ω는 재현기
I t( )
atn+b ---
=
I t T
( ) a blogT ,
+ c t+ n ---=
I t T
( ) ,
a b ln T tn + ----
c d ln T ---t + t +
---
=
i
ω
d v+
θ ( )
η ---=
간에 따라서 변화되는 값이므로(Koutsoyiannis et al.,
1998),
결국 식 (4)는 라는 간단한 식으로 나
타낼 수 있다. 이 관계를 좀더 간단한 식으로 나타내면 다 음 식으로 나타낼 수 있다.
(5)
앞서 언급한 것과 같이, 강우강도 i는 지속기간에 따라서 확률분포형을 가지고 있는 임의변수이며, b(d)는 지속기간에 따라서 값이 결정되어 있는 상수항이라고 할 수 있다. 따라 서, a(T)를 확률분포형을 이용해서 구하기 위해서는 다음의
관계를 이용하면 된다.
(6) (7) (8)
여기서, I(d)는 강우강도 i에 대한 임의변수를 의미하므로
P{I(d)≤i}는 강우강도가 i보다 적은 경우의 대한 I(d)의 누 가분포함수 값을 의미한다. 또한, 앞서 언급한 대로 b(d)는 지속기간 d에 대해서 변화하는 상수값이므로 I(d)b(d)는 임 ω ( ) i f d
T =× ( )
i a T
( )
b d( )
---=
P I d
{ ( ( ) i ≤ ) } P I d
={ ( )b d ( ) ib d ≤ ( ) } P Y y
={ ≤ }
F i;d( ) F
Y( ) 1 1
yTT--- –
= =
yT
≡
ib d( )
=a T( ) F
= Y–1(
1 1 T–⁄ )
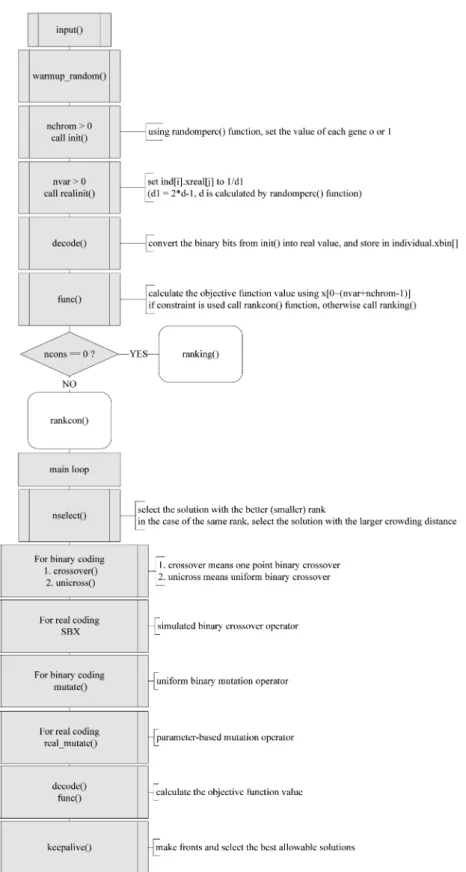
Fig. 1 Flowchart of NSGA-II
의변수 I(d)가 b(d)배 만큼 값이 비례함(rescale)을 의미한다.
따라서 I(d)b(d)는 I(d)에 대한 확률분포함수가 가지고 있는 성질을 그대로 가지고 있다고 말할 수 있다. 결과적으로
I(d)b(d)
를 새로운 임의변수 Y라고 정의하고 재현기간을 T라
고 정의한다면 식 (5), (7)과 (8)에 의해서 a(T)를 I(d)에 관한 누가분포함수와 연결시킬 수 있게 된다.
위의 관계를 이용하여 우리나라에서 주로 쓰이는 확률분포 형인 Gumbel 분포형과 GEV분포형에 대한 강우강도식은 다 음 식 (9), (10)과 같습니다.
: Gumbel (9)
: GEV (10)
여기서,
λ, ψ, κ는 각각의 확률분포형에 따라 형태가 결정 되는 a(T)의 규모, 위치, 형상매개변수이며,
θ, η는 지속기 간에 해당되는 항인 b(d)의 상수매개변수이다(Koutsoyiannis
et al., 1998).2.2
유전자 알고리즘
유전자알고리즘은 1970년대에 Holland(1975)에 의해서 구 체화되고 Goldberg(1989)에 의해서 각종 공학분야에 적용되 기 시작한 기법으로, 염색체(chromosome)의 집합으로 이루 어진 군(population)을 이용하여 교배(crossover), 돌연변이
(mutation),선택(selection)등의 유전자연산자(genetic operator)를 적용하여 주어진 문제의 최적해를 구하는 최적화기법이다.
유전자알고리즘은 기존의 최적화 기법들이 가지고 있었던 단 점중의 하나인 목적함수(objective function)의 형태에 따른 기법적용의 제약이 없으며, 각종 제약조건들의 비선형성을 비교적 효율적으로 처리할 수 있는 최적화 기법으로 알려져 있다. 특히, 비선형성의 대표인 강우강도식과 같은 경우 유 전자알고리즘은 효과적으로 매개변수를 추정할 수 있는 방 법이다(Giustolisi et al., 2006).
본 연구에서는 유전자알고리즘을 적용하기 위하여 최근에 가장 활발히 적용되고 있는 다목적 유전자알고리즘 기법인
NSGA-II(Non-dominated Sorting Genetic Algorithm-II)를 적용하였다. NSGA-II는 기존에 개발되었던 NSGA(Srinivas
and Deb, 1994)
의 단점을 보완하기 위하여 1) 가장 우수한
염색체를 다음 세대로 전달하는 기능을 하는 엘리티즘
(elitism)
을 적용하고, 2) 염색체의 다양성(diversity)을 확보하
기 위한 sharing 기법에서 사용자가 임의로 설정하는
sharing parameter를 없앤 군집거리방법(crowding distance) 을 적용하였으며, 3) NSGA에 비해서 염색체의 순위
(ranking)를 매기는 복잡도(complexity)를 줄이는 개선을 한 기법이다(Deb et al., 2002). NSGA-II는 원래 다목적 문제 의 최적화를 위해서 개발되었으나 최근에는 단일목적함수에 도 적용이 가능하도록 소스코드가 수정되었으며, 일반적으로 흔히 쓰이고 있는 유전자알고리즘 기법인 SGA(Simple
Genetic Algorithm)
보다 더 좋은 결과값을 주기 때문에 본
연구에서 사용하였다. NSGA-II의 순서도는 Fig. 1에 나타내 었으며, 소스코드는 C언어로 구성되어 있어 http://www.iitk.
ac.in/kangal/soft.htm
사이트에서 자유롭게 다운로드 받아 사
용할 수 있다(Kim, 2005).
3.
연구방법
본 연구에서는 우리나라 주요지점에 대한 적정 확률분포형 을 결정한 후 해당 확률분포형의 누가분포함수를 이용하여 식 (9), (10)과 같은 형태를 가지는 강우강도식의 매개변수 를 유전자알고리즘을 이용하여 추정한 후 완성된 강우강도 식으로부터 얻어진 강우강도와, 기존의 식 (3)과 같은 회귀 분석을 활용한 강우강도식을 이용하여 얻어진 강우강도를 서 로 비교하여 누가분포함수를 활용한 강우강도식의 적용성을 검토하고자 하였다. 여기서, 기존에 사용되던 식 (1), (2)보 다 식 (3)을 이용한 이유는 다른 두 가지 식들보다 정확도 면에서 더 높은 결과를 보이기 때문이고(김태순 등, 2007), 비교적 최근의 자료를 활용한 연구결과(건설교통부, 2000)와 의 비교가 가능하기 때문이다.
3.1
강우자료
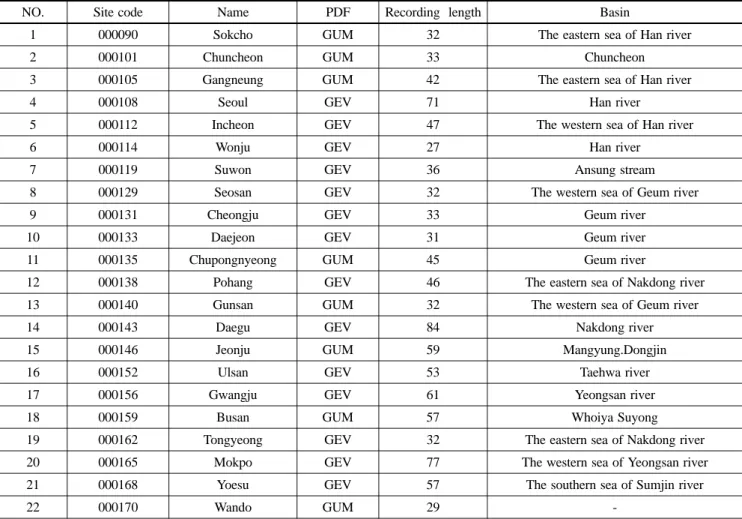
연구대상 강우자료는 보다 정확한 비교를 위하여 연구가 실시되었던 2000년 식 (3)의 매개변수를 산정할 때 사용한 자료를 동일하게 사용하였다(건설교통부, 2000; 한국건설기 술연구원, 2000). 이때 사용된 강우자료는 당시의 전국에 있 는 기상청 산하 68개 관측소의 자료 중 자료기간이 30년 정도 되는 비교적 장기간 관측된 강우자료에 대하여 이동 지속기간 1, 2, 3, 6, 9, 12, 15, 18, 24, 48시간 별 매년 최대치 자료를 모두 사용하였으며, 다음의 Table 1에 해당지 점과 기상청에서 관리하는 지점코드, 적정확률분포형, 대상 지점의 자료기록년수, 그리고 해당지점이 위치한 유역이 표 시되어 있다. 또한, 강우강도식의 매개변수를 구하기 위해서 사용한 자료는 해당 지점의 적정확률분포형에 따른 지속기 간, 재현기간별 확률강우량(quantile) 값이며, 이때 사용된 확 률분포형의 매개변수 추정방법은 모두 확률가중모멘트법
(probability weighted moment)이다.
3.2
강우강도식의 매개변수 추정
식 (9)와 (10)을 각 지점에 적용하여 매개변수를 추정할 때 사용된 변수들은
λ, ψ, κ, θ, η이며, 각각의 매개변수가 가지는 범위는 0<
λ, 0<ψ<4, 0<κ<10, 0<θ<3, 0<η<1로 설 정하였다. 유전자알고리즘을 수행할 때 사용한 목적함수는 주어진 확률분포형에 의한 확률강우량을 이용한 강우강도값 과 식 (9) 그리고 식 (10)을 이용해서 구한 강우강도와의 차이를 이용한 평균제곱근오차(Root Mean Squared Error,
RMSE)
와 평균제곱근 상대오차(Relative RMSE, RRMSE)를
최소화 하는 형태의 목적함수를 사용하였다.
식 (11)로 표현된 RMSE는 n
1개의 지속기간과 n
2개의 재 현기간에 대해서, 각각 확률분포형으로부터 계산된 확률강우 량을 이용한 강우강도(Q
ij)와 강우강도식으로부터 계산된 추 정값(
)간의 차이를 나타내는 형태이고, 식 (12)로 표현된
RRMSE
는 관측값(
θij)에 대한 상대적인 RMSE를 표현하기
i a T
( )
b d( )
---λ ψ
ln ln 1 1 T---⎝
–⎠
⎛ ⎞
–⎩
–⎭
⎨ ⎬
⎧ ⎫
t+
θ ( )
η ---= =
i a T
( )
b d( )
---λ ψ
ln 1 1 T---
⎝
–⎠
⎛ ⎞
–κ– –1
---
κ
⎩
+⎭
⎪ ⎪
⎨ ⎬
⎪ ⎪
⎧ ⎫
t+
θ ( )
η ---= =
Qˆ
ij
때문에 관측값이 적을 경우에 대한 오차를 표현하기에 좀더 용이하다는 특징이 있다.
(11)
(12)
본 연구에서는 목적함수로 RMSE를 사용한 경우의 결과를
Objective Function_I(OF_I)이라고 하였고, RRMSE를 사용 한 경우의 결과를 Objective Function_II(OF_II)로 하여 매 개변수를 추정하였다.
3.3
유전자알고리즘의 개체수와 세대수 결정
유전자알고리즘을 통해 매개변수를 추정하기 위해서는 먼 저 최적의 개체수(population number)와 세대수(generation
number)
의 조합을 찾아야 한다. 개체수는 유전자알고리즘이
수행될 때 사용될 가능해(possible solution)의 개수를 의미 하는 것으로 많을수록 좋다고 생각하기 쉽지만 프로그램의 수행속도가 느려짐으로 인해서 생기는 단점을 고려해서 가 장 적절한 개수의 개체수를 선택하는 것이 일반적이며, 유전 자알고리즘의 수행회수를 결정하는 세대수는 일정한 회수가 반복되고 나면 목적함수의 개선정도가 뚜렷하게 낮아지는 지 점을 선택해서 가장 작은 회수를 반복하도록 하는 것이 일
반적이다. 결과적으로 개체수와 세대수 모두 유전자알고리즘 을 이용해서 최적화를 할 경우 민감도 분석을 통해서 최적 의 개수를 결정하는 과정이 필요하다.
빈도해석절차의 특성상 관측자료의 기간이 길수록 더 안정 적인 결과를 보인다고 할 수 있기 때문에 본 연구에서는 사 용된 기상청 22개 지점 중 관측 기록년수가 가장 긴 상위 8 개 지점인 서울(000108_GEV), 대구(000143_GEV), 전주
(000146_GUM),울산(000152_GEV), 광주(000156_GEV), 부산
(000159_GUM),목포(000165_GEV), 여수(000168_GEV)의 대 해서 개체수와 세대수에 따른 목적함수의 변화를 살펴보았다.
다음의 Fig. 2는 각 지점에 대해서, 개체수 100, 500, 1000,
2000, 3000, 4000, 5000
개와 세대수 3000번까지의 결과값으로
목적함수중의 하나인 RRMSE를 도시한 것이다. RMSE에 비해 서 RRMSE는 상대적인 오차를 나타내기 때문에 보다 정확한 값을 나타낸다고 생각되어서 RRMSE를 이용하였다. 8개 지점 의 결과를 살펴보면, 여수의 경우 개체수가 100개인 경우를 제 외하고는 다른 모든 개체수를 적용한 결과에서 매우 적은 세 대수를 반복회수로 사용하더라도 빠르게 수렴되는 것으로 나 타났고, 서울, 울산, 부산은 개체수 100개와 500개를, 대구와 전주는 100개, 500개, 1000개를, 그리고 광주와 목포는 개체수
100개, 500개, 2000개를 제외한 모든 개체수에서 매우 적은 세 대수를 사용하더라도 가장 적은 목적함수값에 매우 근접한 목 적함수값을 나타내는 것으로 나타났다.
결과적으로 개체수는 2000개이상이면 충분하고 세대수 역시
RMSE 1
n--- Qˆ
ij–Qij
( )
2i=1 n1
∑
j=1 n2
∑
=
RRMSE 1
n--- Qˆ
ij–Qij Qij ---
⎝ ⎠
⎜ ⎟
⎛ ⎞
2i 1= n1
∑
j=1 n2
∑
=
Table 1. 22 Rainfall recording gages of Korea Meteorological Administration
NO. Site code Name PDF Recording length Basin
1 000090 Sokcho GUM 32 The eastern sea of Han river
2 000101 Chuncheon GUM 33 Chuncheon
3 000105 Gangneung GUM 42 The eastern sea of Han river
4 000108 Seoul GEV 71 Han river
5 000112 Incheon GEV 47 The western sea of Han river
6 000114 Wonju GEV 27 Han river
7 000119 Suwon GEV 36 Ansung stream
8 000129 Seosan GEV 32 The western sea of Geum river
9 000131 Cheongju GEV 33 Geum river
10 000133 Daejeon GEV 31 Geum river
11 000135 Chupongnyeong GUM 45 Geum river
12 000138 Pohang GEV 46 The eastern sea of Nakdong river
13 000140 Gunsan GUM 32 The western sea of Geum river
14 000143 Daegu GEV 84 Nakdong river
15 000146 Jeonju GUM 59 Mangyung.Dongjin
16 000152 Ulsan GEV 53 Taehwa river
17 000156 Gwangju GEV 61 Yeongsan river
18 000159 Busan GUM 57 Whoiya Suyong
19 000162 Tongyeong GEV 32 The eastern sea of Nakdong river
20 000165 Mokpo GEV 77 The western sea of Yeongsan river
21 000168 Yoesu GEV 57 The southern sea of Sumjin river
22 000170 Wando GUM 29 -
GUM means that Gumbel distribution is selected as proper probability distribution function at corresponding site, and GEV means GEV distribution is proper.
200
번 정도에서 8개 지점이 모두 수렴되는 것으로 나타났 으며, 일반적으로 유전자알고리즘은 세대수를 증가시키는 것 보다는 개체수를 증가시키는 것이 해를 구하는 효율면에서 더 좋다고 할 수 있으므로 본 연구에서 세대수를 200회로 사용하 고 개체수는 충분히 크다고 할 수 있는 5000개를 사용하였다.
4.
누가분포함수를 활용한 강우강도식의 정확도 비교 및 매개변수 추정
4.1
각 지점별 평균에 의한 정확도와 재현기간별
,지속기 간별로 구분된 정확도 비교
누가분포함수를 이용한 강우강도식인 식 (9)와 (10)이 국
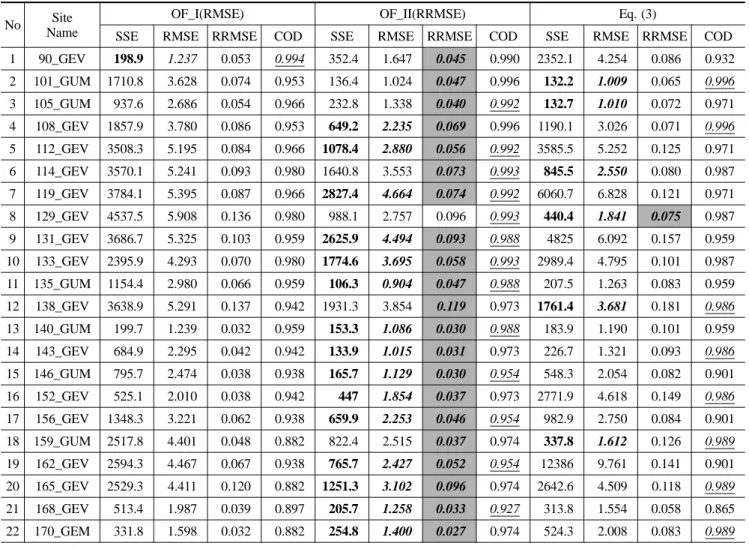
내에 적용 가능한지 알아보기 위하여, 1999년까지의 강우자 료를 적용하여 매개변수를 추정한 후 식 (3)과 정확도를 비 교해 보았다. 아래의 Table 2에서 OF_I(RMSE)의 90_GEV 는 a) 유전자알고리즘의 목적함수로 RMSE인 식 (11)을 사 용하고, b) 속초(090)지점의 적정 확률분포형인 GEV분포형 을 사용한 강우강도식인 식 (10)의 매개변수를 추정하여 완 성된 강우강도식으로 강우강도를 계산한 후, 지점빈도해석을 활용하여 구한 속초지점에서의 지속기간별 재현기간별 강우 강도와 비교한 RMSE와 RRMSE를 구한 것이다. 즉, Table
2의 RMSE와 RRMSE는 유전자알고리즘을 수행한 결과값이 아니라 유전자알고리즘을 통해서 구한 매개변수를 지점의 적 정 확률분포형에 따른 강우강도식에 적용하여 구한 강우강
Fig. 2 Objective function values as population number increases at the 8 longest recording sites of Korea MeteorologicalAdministration
도값과, 빈도해석에 의한 확률강우량값을 강우강도로 변환한 값을 비교하여 산정된 RMSE와 RRMSE로서 각 지점별로 전체 지속기간과 재현기간에 대한 평균값을 의미한다.
Table 2
에서 굵은 이탤릭체로 표기된 값은 같은 지점에
대한 결과 중 RMSE가 가장 적은 것을 나타내고 있고, 음 영과 함께 굵은 이탤릭체로 표기된 값은 RRMSE가 가장 적은 것을 나타내고, 이탤릭체에 밑줄이 쳐진 값은 결정계수
(coefficient of determination, COD)가 가장 큰 것을 나타 내고 있는 것이다. 여기서 RMSE를 살펴보면 OF_I(RMSE) 가 1개 지점에서 다른 두 가지 방법보다 적은 RMSE값을 보여주고 있고, OF_II(RRMSE)는 22개 지점중에서 모두
15개 지점에서 RMSE가 최소이며, 식 (3)에 의한 경우는 모 두 6개 지점에서 RMSE가 최소인 것으로 나타났다. 또한,
RRMSE
에 의한 결과를 살펴보면, OF_I(RMSE)는 모든 지
점에서 최소 RRMSE를 갖는 경우가 없는 것으로 나타났고
OF_II(RRMSE)
는 21개 지점에서 최소 RRMSE를 나타냈으
며 식 (3)에 의한 경우는 1개 지점에서 최소 RRMSE를 갖 는 것으로 나타났다. 결정계수의 결과를 살펴보면
OF_I(RMSE)
가 1개 지점에서 다른 두 가지 방법보다 큰
결정계수 값을 보여주고 있고, OF_II(RRMSE)는 22개 지점
중에서 모두 13개 지점에서 결정계수가 최대이며, 식 (3)에 의한 경우는 모두 8개 지점에서 결정계수가 최대인 것으로 나타났다.
앞서 언급한 것과 같이 Table 2의 결과는 각 지점별로 전체 재현기간(2, 3, 5, 10, 20, 30, 50, 70, 80, 100,
200, 300, 500
년)과 3.1절에서 언급한 10가지 경우의 지속
기간에 대한 RMSE와 RRMSE를 평균한 값이므로, 누가분 포함수를 활용한 강우강도식의 평균적인 정확도를 나타내고 있다. 이번에는 이런 평균적인 값이 아닌 임의의 재현기간에 대한 정확도와 지속기간을 장기간과 단기간으로 구분했을때 의 정확도를 비교해보았다. 이때 사용한 재현기간은 국내에 서 수공구조물을 설계할 때 가장 많이 쓰이는 재현기간인
30년, 50년, 100년, 200년(건설교통부, 1993)에 대하여
RMSE, RRMSE
를 계산하여 비교해 보았으며, 지속기간은
12
시간을 기준으로 12시간 미만인 단기간과 12시간 이상인 장기간으로 나누어서 정확도를 각각 비교해 보았다. 단, 여 기서 장-단기간으로 지속기간을 구분한 것은 매개변수를 추정 할 때가 아닌 정확도 비교만을 위해서 구분한 것이며, 매개변 수를 추정할 때는 장-단기간의 구분 없이 추정한 것이다.
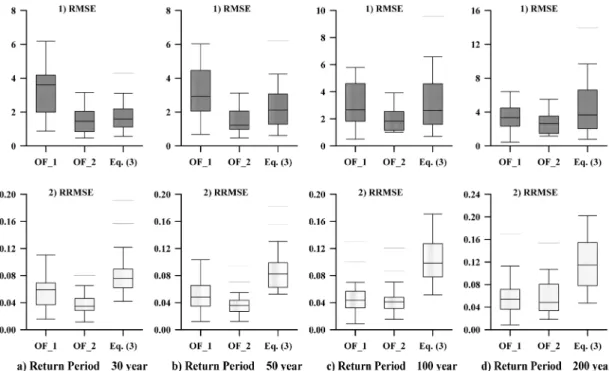
Fig. 3
은 Table 1의 22개 지점에 대한 RMSE, RRMSE
Table 2. Average RMSE and RRMSE of each site when two different objective functions are used in GA for parameter estimation, and Eq. (3) whose parameters are estimated by regression analysis
No Site
Name
OF_I(RMSE) OF_II(RRMSE) Eq. (3)
SSE RMSE RRMSE COD SSE RMSE RRMSE COD SSE RMSE RRMSE COD
1 90_GEV 198.9 1.237 0.053 0.994 352.4 1.647 0.045 0.990 2352.1 4.254 0.086 0.932 2 101_GUM 1710.8 3.628 0.074 0.953 136.4 1.024 0.047 0.996 132.2 1.009 0.065 0.996 3 105_GUM 937.6 2.686 0.054 0.966 232.8 1.338 0.040 0.992 132.7 1.010 0.072 0.971 4 108_GEV 1857.9 3.780 0.086 0.953 649.2 2.235 0.069 0.996 1190.1 3.026 0.071 0.996 5 112_GEV 3508.3 5.195 0.084 0.966 1078.4 2.880 0.056 0.992 3585.5 5.252 0.125 0.971 6 114_GEV 3570.1 5.241 0.093 0.980 1640.8 3.553 0.073 0.993 845.5 2.550 0.080 0.987 7 119_GEV 3784.1 5.395 0.087 0.966 2827.4 4.664 0.074 0.992 6060.7 6.828 0.121 0.971 8 129_GEV 4537.5 5.908 0.136 0.980 988.1 2.757 0.096 0.993 440.4 1.841 0.075 0.987 9 131_GEV 3686.7 5.325 0.103 0.959 2625.9 4.494 0.093 0.988 4825 6.092 0.157 0.959 10 133_GEV 2395.9 4.293 0.070 0.980 1774.6 3.695 0.058 0.993 2989.4 4.795 0.101 0.987 11 135_GUM 1154.4 2.980 0.066 0.959 106.3 0.904 0.047 0.988 207.5 1.263 0.083 0.959 12 138_GEV 3638.9 5.291 0.137 0.942 1931.3 3.854 0.119 0.973 1761.4 3.681 0.181 0.986 13 140_GUM 199.7 1.239 0.032 0.959 153.3 1.086 0.030 0.988 183.9 1.190 0.101 0.959 14 143_GEV 684.9 2.295 0.042 0.942 133.9 1.015 0.031 0.973 226.7 1.321 0.093 0.986 15 146_GUM 795.7 2.474 0.038 0.938 165.7 1.129 0.030 0.954 548.3 2.054 0.082 0.901 16 152_GEV 525.1 2.010 0.038 0.942 447 1.854 0.037 0.973 2771.9 4.618 0.149 0.986 17 156_GEV 1348.3 3.221 0.062 0.938 659.9 2.253 0.046 0.954 982.9 2.750 0.084 0.901 18 159_GUM 2517.8 4.401 0.048 0.882 822.4 2.515 0.037 0.974 337.8 1.612 0.126 0.989 19 162_GEV 2594.3 4.467 0.067 0.938 765.7 2.427 0.052 0.954 12386 9.761 0.141 0.901 20 165_GEV 2529.3 4.411 0.120 0.882 1251.3 3.102 0.096 0.974 2642.6 4.509 0.118 0.989 21 168_GEV 513.4 1.987 0.039 0.897 205.7 1.258 0.033 0.927 313.8 1.554 0.058 0.865 22 170_GEM 331.8 1.598 0.032 0.882 254.8 1.400 0.027 0.974 524.3 2.008 0.083 0.989 SSE: Sum of square error
RMSE: Root mean square error RRMSE: Relative RMSE
COD: Coefficient of determination
를 각각 재현기간 30년, 50년, 100년, 200년에 대해서 각각 구한 결과값을 상자수염도(Box-Whisker Plot)로 나타낸 것으 로써, 상자수염도의 box는 윗 부분부터 각각 1st quartile,
median, 3rd quartile을 나타내는 것이고 box와 연결된 상, 하한계는 각각 최대, 최소값을 의미하는 것이다. 또한 box와 연결되지 않은 수평선이 나타나는 경우는 최대, 최소값에서 일정간격 떨어져 있는 이상치를 나타내는 것으로, 여기서 이 상치는 최대, 최소값으로부터 떨어진 거리가 1st quartile과
3rd quartile
의 차이에 1.5배를 곱한 값보다 클 경우를 의미
한다.
상자수염도의 특성상 전체적으로 1st quartile과 3rd
quartile
간의 간격이 좁으면서 동시에 box의 형태가 전체적으
로 다른 값들보다 적은 값을 갖는 경우가 전체적으로 적은 오차를 갖는 것이라고 말할 수 있으며, 여기에 덧붙여서 이 상치가 나타나지 않는 것이 보다 안정적으로 강우강도를 계 산할 수 있는 경우라고 할 수 있을 것이다. 이런 관점에서 살펴본다면, 재현기간 30년의 경우 RMSE, RRMSE 모두
OF_II
가 가장 정확한 결과값을 보인다고 말할 수 있으며,
재현기간 50년, 100년, 200년 모두, 재현기간 200년의
RRMSE
가 OF_I이 가장 정확한 경우를 제외하고는 모두
OF_II
가 가장 정확한 것으로 나타났다. 즉, 재현기간별로 정
확도를 살펴본 8가지 경우 모두 누가분포함수를 활용한 강 우강도식의 정확도가 회귀분석을 활용한 강우강도식보다 높 은 정확도를 보이면서 동시에 안정적인 값을 보이는 것을 알 수 있다.
이번에는 지속기간 12시간을 기준으로, 12시간 미만의 단 기간 지속기간인 1, 2, 3, 6, 9시간과 12시간 이상의 장기 간 지속기간인 12, 15, 18, 24, 48 지속기간을 이용하여 강 우강도식의 정확도를 비교해 보았다. Fig. 4는 각각 지속기 간 1시간~9시간에 해당하는 강우강도를 비교한 결과와 지속 기간 12시간~48시간에 해당하는 강우강도를 비교한 결과를
나타낸 것이다. 앞서 설명한 재현기간별로 정확도를 비교한 결과에서는 전반적으로 OF_II가 OF_I보다 높은 정확도를 가지는 것으로 나타났지만, 여기서는 단기간의 지속기간에 해당하는 경우에는 OF_II를 사용하는 것이 더 높은 정확도 를 갖는 것으로 나타났고, 장기간의 지속기간에 해당하는 경 우에는 OF_I이 OF_II보다 더 높은 정확도를 보이는 것으로 나타났다.
이는 OF_I의 경우 관측값과 추정값간의 확률강우량에 관한 RMSE를 최소화시키는 형태로 구성되었기 때문에 상
Fig. 3 RMSE and RRMSE of OF_I, OF_II and Eq. (3) when return period is 30, 50, 100, and 200 years, respectively. Rainfallrecords observed until 1999 are used in this case
Fig. 4 RMSE and RRMSE of OF_I, OF_II and Eq. (3) when duration is divided by two periods that are short (1 hr~9 hr) and long (12 hr~48 hr). Rainfall data of which recording period is until 1999 are used
대적으로 큰 확률강우량을 가지는 장기간의 지속기간에 대 한 결과값이 정확하게 나오는 경향이 있으며, 반대로
OF_II
의 경우 확률강우량간의 상대적인 차이를 최소화시키
는 형태의 목적함수인 RRMSE를 최소화시키는 형태로 구 성되었기 때문에 단기간의 지속기간에 대한 정확도가 더 높게 나오는 경향이 있기 때문이다(신주영 등, 2007). 결 과적으로 Fig. 4의 결과에 의하면 단기간과 장기간에 해당 하는 경우 모두 누가분포함수를 활용한 강우강도식의 정확 도가 회귀분석을 활용한 강우강도식의 정확도보다 높은 것 으로 나타났다.
4.2 2006
년까지의 자료를 이용한 경우의 정확도 비교와 매개변수 추정값 제시
앞 절까지의 결과는 기존에 유도된 강우강도식과의 비교를 위하여 누가분포함수를 활용한 강우강도식의 매개변수는 유 전자알고리즘을 이용하여 추정하고, 기존의 회귀분석에 의한 강우강도식의 매개변수는 건설교통부(2000)에 나와 있는 매 개변수 값을 이용하여 서로간의 정확도를 비교해 본 것이다.
여기서는 최근의 연구결과(김태순 등, 2007; 신주영 등,
2007)
를 이용하여 식 (3)의 매개변수를 2006년까지의 자료를
활용하여 유전자알고리즘으로 새로 구하고 동시에 누가분포 함수를 활용한 강우강도식의 매개변수 역시 유전자알고리즘 으로 구하여 정확도를 비교해 보았다.
Table 3
은 이와 같이 구한 결과를 보여주는 것으로써,
RMSE
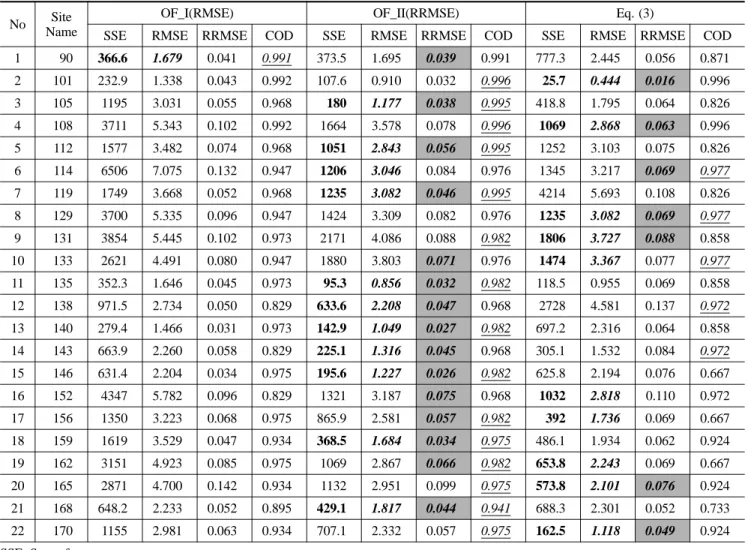
를 비교했을때는 OF_I이 1개소, OF_II가 11개소, 식
(3)에 의한 경우가 10개소에서 최소값을 보였으며, RRMSE 를 비교하였을때는 OF_II가 15개소, 식 (3)에 의한 경우가
7개소에서 최소값을 보이는 것으로 나타나서 1999년까지의 강우자료를 이용한 와 비교해서는 식 (3)에 의한 결과값이 좀더 양호해진 것으로 나타났다. 그러나, 재현기간별로 구분 한 경우와 함께 지속기간으로 구분한 경우를 도시한 Fig. 5 와 Fig. 6를 살펴보면 거의 모든 경우에 대해서 누가분포함 수를 활용한 강우강도식의 정확도가 회귀분석을 활용한 강 우강도식보다 높은 것으로 나타나서, 2006년까지의 강우자료 를 활용하여서 매개변수를 추정하더라도 누가분포를 활용한 강우강도식의 정확도가 더 높은 것으로 나타났다.
Table 4
는 2006년까지의 강우자료를 이용하여 누가분포함
수를 활용한 강우강도식인 식 (9), (10)의 매개변수를, Table
1에 나타난 각 지점별 최적분포형에 대해서 유전자알고리즘 을 이용해 추정한 결과를 제시한 것이다.
Table 3. Average RMSE and RRMSE of three cases such as OF_I, OF_II, and Eq. (3). In this case, the recent recording rainfall data observed until 2006 are used
No Site Name
OF_I(RMSE) OF_II(RRMSE) Eq. (3)
SSE RMSE RRMSE COD SSE RMSE RRMSE COD SSE RMSE RRMSE COD
1 90 366.6 1.679 0.041 0.991 373.5 1.695 0.039 0.991 777.3 2.445 0.056 0.871
2 101 232.9 1.338 0.043 0.992 107.6 0.910 0.032 0.996 25.7 0.444 0.016 0.996
3 105 1195 3.031 0.055 0.968 180 1.177 0.038 0.995 418.8 1.795 0.064 0.826
4 108 3711 5.343 0.102 0.992 1664 3.578 0.078 0.996 1069 2.868 0.063 0.996
5 112 1577 3.482 0.074 0.968 1051 2.843 0.056 0.995 1252 3.103 0.075 0.826
6 114 6506 7.075 0.132 0.947 1206 3.046 0.084 0.976 1345 3.217 0.069 0.977
7 119 1749 3.668 0.052 0.968 1235 3.082 0.046 0.995 4214 5.693 0.108 0.826
8 129 3700 5.335 0.096 0.947 1424 3.309 0.082 0.976 1235 3.082 0.069 0.977
9 131 3854 5.445 0.102 0.973 2171 4.086 0.088 0.982 1806 3.727 0.088 0.858
10 133 2621 4.491 0.080 0.947 1880 3.803 0.071 0.976 1474 3.367 0.077 0.977
11 135 352.3 1.646 0.045 0.973 95.3 0.856 0.032 0.982 118.5 0.955 0.069 0.858
12 138 971.5 2.734 0.050 0.829 633.6 2.208 0.047 0.968 2728 4.581 0.137 0.972
13 140 279.4 1.466 0.031 0.973 142.9 1.049 0.027 0.982 697.2 2.316 0.064 0.858
14 143 663.9 2.260 0.058 0.829 225.1 1.316 0.045 0.968 305.1 1.532 0.084 0.972
15 146 631.4 2.204 0.034 0.975 195.6 1.227 0.026 0.982 625.8 2.194 0.076 0.667
16 152 4347 5.782 0.096 0.829 1321 3.187 0.075 0.968 1032 2.818 0.110 0.972
17 156 1350 3.223 0.068 0.975 865.9 2.581 0.057 0.982 392 1.736 0.069 0.667
18 159 1619 3.529 0.047 0.934 368.5 1.684 0.034 0.975 486.1 1.934 0.062 0.924
19 162 3151 4.923 0.085 0.975 1069 2.867 0.066 0.982 653.8 2.243 0.069 0.667
20 165 2871 4.700 0.142 0.934 1132 2.951 0.099 0.975 573.8 2.101 0.076 0.924
21 168 648.2 2.233 0.052 0.895 429.1 1.817 0.044 0.941 688.3 2.301 0.052 0.733
22 170 1155 2.981 0.063 0.934 707.1 2.332 0.057 0.975 162.5 1.118 0.049 0.924
SSE: Sum of square error RMSE: Root mean square error RRMSE: Relative RMSE COD: Coefficient of determination
5.
결 론
본 연구에서는 누가분포함수를 활용한 강우강도식의 국내 적용성을 살펴보기 위하여, 기존에 사용되던 회귀분석을 활 용한 강우강도식의 결과와 정확도를 비교해 보았으며, 최근
까지의 강우자료를 사용하여 새로운 강우강도식의 매개변수 를 제시하였다. 누가분포함수를 활용한 강우강도식의 매개 변수를 추정하는데 있어서는 유전자알고리즘을 사용하였으 며, 비교적 충분한 기간 동안 강우자료가 기록된 기상청
22개 지점에 대해서 평균제곱근오차(RMSE)와 평균제곱근
Table 4. Parameters of OF_II using the recent rainfall recording data until 2006No Site Name Parameters
λ ψ θ η κ
1 000090_GEV 15.2383 2.9860 1.8782 0.6267 0.1485
2 000101_GUM 11.7903 2.9815 0.7783 0.5612 -
3 000105_GUM 31.0553 1.8227 3.0000 0.6905 -
4 000108_GEV 22.5368 2.5088 1.1790 0.6861 0.0431
5 000112_GEV 26.9523 2.5694 2.3911 0.7826 0.1309
6 000114_GEV 10.6149 2.9915 0.3060 0.5246 0.0619
7 000119_GEV 28.0786 2.8235 2.8059 0.8055 0.1970
8 000129_GEV 11.9143 2.7222 0.0729 0.5663 0.0000
9 000131_GEV 21.5212 3.1462 2.5133 0.8058 0.1003
10 000133_GEV 30.7520 2.7219 2.9927 0.8291 0.0536
11 000135_GUM 14.6877 3.0655 1.8757 0.7063 -
12 000138_GEV 19.0215 2.8427 2.6698 0.7711 0.2797
13 000140_GUM 21.6501 2.7427 1.8593 0.7771 -
14 000143_GEV 16.1671 3.0686 1.6346 0.7576 0.0000
15 000146_GUM 21.7611 2.8173 1.3343 0.80000 -
16 000152_GEV 23.4532 2.5493 3.0000 0.7442 0.1651
17 000156_GEV 22.1331 2.7138 2.1254 0.7621 0.0693
18 000159_GUM 25.9323 2.5742 1.5882 0.7545 -
19 000162_GEV 16.3886 2.5786 0.8312 0.6473 0.1251
20 000165_GEV 15.2131 2.6681 1.7203 0.6702 0.0413
21 000168_GEV 21.6205 2.9600 1.9614 0.7433 0.0092
22 000170_GUM 25.0974 2.5243 2.2070 0.7042 -
Fig. 5 RMSE and RRMSE of OF_I, OF_II and Eq. (3) when return period is 30, 50, 100, and 200 years, respectively. The recent rainfall records observed until 2006 are used in this case
상대오차(RRMSE)를 최소화시키는 형태의 목적함수를 구성 하여서 최적 매개변수를 추정하였다. 유전자알고리즘을 적 용하기 위해서 필요한 세대수는 3000번, 개체수 5000개로 하였다.
정확도의 비교를 위해서는 각 지점별로 모든 재현기간과 지속기간에 대한 RMSE, RRMSE값의 평균값을 비교하였으 며, 보다 정확한 비교를 위하여 재현기간 30년, 50년, 100 년, 200년에 해당하는 강우강도값만의 RMSE와 RRMSE, 그리고 지속시간 12시간을 기준으로 단기간과 장기간 지속 기간에 해당하는 강우강도값의 RMSE, RRMSE를 비교한 결과 누가분포함수를 활용한 강우강도식의 정확도가 기존의 회귀분석에 의한 강우강도식의 정확도보다 높은 것으로 나 타났다.
최근의 집중호우에 의한 강우강도식 정확도의 변화를 살펴 보기 위해서 2006년까지의 강우자료를 이용하여 누가분포함 수를 활용한 강우강도식과 회귀분석을 활용한 강우강도식의 매개변수를 유전자알고리즘으로 각각 구한 후, 얻어진 강우 강도식으로 강우강도를 구해서 RMSE, RRMSE를 비교한 결과 누가분포함수를 활용한 경우의 정확도가 더 높은 것으 로 나타났다.
본 연구의 결과는 그 동안 제안자의 주관적인 판단에 의해서 제시되던 국내 강우강도식의 형태를 개선하는데 있어서 각 지 점의 적정확률분포형을 고려한 강우강도식을 개발할 수 있음 을 보여주는 것이며, 또한 강우강도식의 매개변수를 추정하는 데 있어서도 최소자승법 등의 기존 방법보다 유연하다고 알려 진 유전자알고리즘을 적용함으로써 보다 적절한 매개변수를 손 쉽게 얻을 수 있어 국내의 수공구조물 설계 시 보다 유용하게 적용할 수 있을 것으로 판단된다.
감사의 글
본 연구는 21세기 프론티어연구개발사업인 수자원의 지속 적 확보기술개발사업단의 연구비지원(1-6-3)에 의해 수행되 었습니다.
참고문헌
건설교통부(1993) 하천시설기준. p.581.
건설교통부(2000)
1999년도 수자원관리기법개발연구조사보고서, 제
1권
:한국확률강우량도 작성
.한국건설기술연구원.
김태순, 신주영, 김수영, 허준행(2007) 유전자알고리즘을 이용한 강우강도식 매개변수 추정에 관한 연구(I): 기존 매개변수 추 정방법과의 비교. 한국수자원학회 논문집, 한국수자원학회,
Vol. 40, No. 10, pp. 811-821.신주영, 김태순, 김수영, 허준행(2007) 유전자알고리즘을 이용한 강우강도식 매개변수 추정에 관한 연구(II): 장단기간 구분 방법의 제시. 한국수자원학회 논문집, 한국수자원학회, Vol.
40, No. 10, pp. 823-832.
윤용남(1998) 공업수문학, 청문각, 서울.
이원환(1980) 도시하천 및 하수도 개수계획상의 계획강우량 설정 에 관한 추계학적 해석. 대한토목학회지, 대한토목학회, 제28 권 제4호, pp. 81-93.
이원환(1997) 개정판 수문학, 문운당, 서울.
이원환, 박상덕, 최성열(1993) 한국 대표확률강우강도식의 유도.
대한토목학회 논문집, 대한토목학회, 제13권 제1호, pp. 115-
120.한국건설기술연구원(2000) 강우자료 추출 및 확률강우량 산정프로 그램 개발 최종보고서, 연세대학교 건설공학연구소.
허준행, 김경덕, 한정훈(1999) 지속기간별 강우자료의 적정분포형 선정을 통한 확률강우강도식의 유도. 한국수자원학회 논문집, 한국수자원학회, Vol. 32, No. 3, pp. 247-254.
Baldassarre, G.D., Brath, G., A., and Montanari, A. (2006) Reliabil- ity of different depth-duration-frequency equations for estimat- ing short-duration design storms. Water Resources Research, 42, W12501, doi:10.1029/2006WR004911.
Bernard, M.M. (1932) Formulas for rainfall intensities of long dura- tion. Transactions, ASCE, 96(Paper No.1801), pp. 592-624.
Chen, C.-L. (1983) Rainfall intensity-duration-frequency formulas.
Journal of Hydraulic Engineering, Vol. 109, No. 12, pp. 1603- 1621.
Deb, K., Pratap, A., Agarwal, S., and Meyarivan, T. (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. Evolu- tionary Computation, IEEE Transactions on, Vol. 6, No. 2, pp.
182-197.
Giustolisi, O., Savic, D. and Kapelan, Z., 2006. Multi-Objective Evolution Polynomial Regression, 7th International Conference on Hydroinformatics (HIC 2006), Nice, FRANCE
Goldberg, D.E. (1989) Genetic algorithms in search, optimization
& machine learning, Addison Wesley, Reading, Massachusetts.
Holland, J.H. (1975) Adaptation in natural and artificial systems, University of Michigan Press.
Kim, T. (2005) Multireservoir System Optimization Using Multi- Objective Genetic Algorithms, PhD dissertation, Yonsei Uni- versity, Seoul
Koutsoyiannis, D., Kozonis, D., and Manetas, A. (1998) A mathe- matical framework for studying rainfall intensity-duration-fre- quency relationships. Journal of Hydrology, Vol. 206, No. 1-2, pp. 118-135.
Meyer, A.F.B. (1928) The elements of hydrology, London, Chap- man & Hall, New York, J. Wiley.
Mohymont, B., Demarée, G.R., and Faka, D.N. (2004) Establish- Fig. 6 RMSE and RRMSE of OF_I, OF_II and Eq. (3) when
duration is divided by two periods that are short (1 hr~9 hr) and long (12 hr~48 hr). Rainfall data of which recording period is until 2006 are used
ment of IDF-curves for precipitation in the tropical area of Central Africa - comparison of techniques and results. Natural Hazards and Earth System Sciences, Vol. 4, pp. 375-387.
Sherman, C.W. (1931) Frequency and intensity of excessive rain- falls at Boston, Massachushtts. Transactions, ASCE, 95(Paper No.1780), pp. 951-960.
Srinivas, N. and Deb, K. (1994) Multiobjective optimization using nondominated sorting in genetic algorithms. Evolutionary Computation, Vol. 2, No. 3, pp. 221-248.
(