1. 서 론
오늘날 인간과 컴퓨터의 상호작용이 주목되고 이 에 따라 사람의 행위를 분석하여 보행인식 및 인간의 행동분석, 감시시스템 등에 적용하고자 하는 연구에 관하여 관심이 증대하고 있다. 인간의 몸체를 검출하 고 검출 객체를 추적하는 기술은 컴퓨터 비전 기술을 기반으로 다양한 연구가 진행되고 있다. 컴퓨터 비전 기법을 이용하여 인체를 검출하고 추적하는 기술은 다양한 분야에서 응용되고 있으며 특히 인간의 행동 인식 및 분류에도 응용되고 있다. 인간의 행동인식 및 분류를 위해 신체의 각 부위가 어떤 모습으로 움
직이고 변화하는지를 찾아내어 분석하는 기법들이 연구되고 있다. 인간의 행동인식 및 분류는 컴퓨터 비전의 인식 분야의 기법을 기반기술로 하며 이는 특징 추출과 추출된 특징을 기반으로 행동 분류 및 인식하는 과정으로 나뉠 수 있다. 응용 분야에 유용 한 인체의 추적과 모형화를 위한 특징으로는 인체의 실루엣, 외곽선, 특정 신체 부위의 위치 및 연결 성분, 관절정보 등이 있다[1-3]. 또한, 인간의 행동인식 및 분류를 위한 특징을 추출하는 방법에 따라 인식기법 은 인체의 특정 부위에 센서를 부착하여 수집된 센서 정보를 관측하고 분석하는 방범[4-5]과 카메라를 통 해 입력된 영상을 대상으로 인체의 특징을 검출한
보행자 타입에 따른 보행자의 관절 점 자동 추출 알고리즘
곽내정†, 송특섭††
Auto-Detection Algorithm of Gait’s Joints According to Gait’s Type
Nae-Joung. Kwak†, Teuk-Seob. Song††
ABSTRACT
In this paper, we propose an algorithm to automatically detect gait’s joints. The proposed method classifies gait’s types into front gait and flank gait so as to automatically detect gait’s joints. And then according to classified types, the proposed applies joint extracting algorithm to input images. Firstly, we split input images into foreground image using difference images of Hue and gray-scale image of input and background one and extract gait’s object. The proposed method classifies gaits into front gait and flank gait using ratio of Face’s width to torso’s width. Then classified gait’s type, joints are detected 10 at front gait and detected 7~8 at flank gait. The proposed method is applied to the camera's input and the result shows that the proposed method automatically extracts joints.
Key words: Joint Detection, Gait Detection, Object Detection
※ Corresponding Author : Teuk-Seob. Song, Address:
(35349) 88, Doanbuk-ro, Seogu, Daejeon, Korea, TEL : +82-42-829-7635, FAX : +82-42-822-8431, E-mail : [email protected]
Receipt date : Jan. 4, 2017, Revision date : Sep. 30, 2017 Approval date : Nov. 9, 2017
†Dept. of Information & Communication Eng., Chung- buk National University (E-mail: [email protected])
††Div. of Convergence Computer and Media, Mokwon University
※ This research was supported by Basic Science Research Program through the National Research Foun- dation of Korea (NRF) funded by the Ministry of Education, Science and Technology (NRF-2015R1D1A 1A01058786).
후 특징을 기반으로 행동을 인식하고 분류하는 방법 [6]으로 분류된다.
기존 연구의 중점이 되는 실루엣이나 외곽선 정보 는 인간의 몸체를 모형화하기 위해 중요한 특징이지 만 관절의 위치나 신체 및 관절의 움직임 정보만으로 도 인체의 실루엣 및 외곽선의 재구성이 가능하다. 또한, 행동의 패턴을 분석하는 것도 추출된 관절의 움직임 정보의 분석을 이용하면 가능하다. 따라서 인 체의 움직임이 존재하는 비디오 영상에서 관절 점의 검출과 움직임 검출은 중요한 연구 분야이다[7]. 그 러나 기존의 연구에서는 인체의 관절에 센서나 마커 를 부착하여 관절을 검출하고 움직임을 검출한다. 또 한, 인체의 실루엣과 윤곽선 정보를 얻기 위해서도 깊이 정보를 이용하기 위해 스테레오 카메라를 이용 하거나 3D 카메라 또는 다수의 카메라가 필요하다 [8-9]. 이러한 특징을 바탕으로 인간의 행위 인식 및 자세를 추정하는 기법은 추출된 특징을 학습하고 학 습된 데이터를 이용하여 입력되는 영상데이터 혹은 센서 데이터로부터 행위를 인식하거나 자세를 추정 한다. 따라서 학습을 위한 많은 양의 데이터와 복잡 한 학습 알고리즘이 필요하다.
본 논문은 기존방법의 단점을 보완하여 학습 알고 리즘이 필요하지 않으며 한 대의 고정 카메라에서 입력되는 영상을 이용하여 인간의 행동인식 및 보행 인식 등에 적용이 가능한 특징인 인체의 관절 점을 자동 추출하는 알고리즘을 제안한다. 제안 방법은 보 행자의 영상을 먼저 객체로 분리한 후 보행 타입에 따라 측면 보행자와 정면 보행자로 분류하고 관절 점을 자동 검출한다. 먼저 고정 카메라를 통해 입력 되는 입력 영상과 배경영상의 회색 조(grayscale) 영 상과 색상(hue) 영상의 차 영상을 구한 후 그 결과를 결합하여 배경과 전경을 분리하고 객체를 추출한다. 추출된 인간 객체의 얼굴과 인체의 몸체의 비율을 이용하여 정면객체와 측면 객체로 분류하며 정면객 체는 10개, 측면은 7∼8개의 관절 점을 자동검출 한다.
본 논문은 2장에서 객체 추출 알고리즘과 보행자 유형 분류 및 관정점 추출 알고리즘에 관해 기술하며 3장에서는 제안 방법의 실험결과를 기술하고 4장에 서는 결론 및 향후 과제에 대해 기술 한다
2. 제안한 방법
본 논문에서는 관절 점의 위치 정보를 이용하여
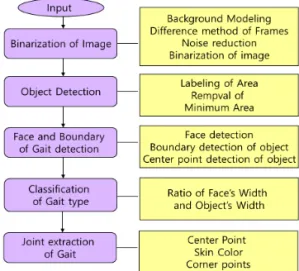
단일카메라에서 입력되는 영상에서 보행자의 관절 점을 자동으로 추출하는 알고리즘을 제안한다. 카메 라 입력으로 들어오는 보행자는 측면으로 걸어오거 나 정면으로 걸어간다. 따라서 Fig. 1과 같이 보행자 는 정면으로 걷거나 측면으로 걷는 두 가지로 크게 분류할 수 있으며 이에 따라 검출되는 관절 점도 다 르게 검출된다. 다중 카메라 입력이나 3D 카메라 혹 은 스테레오 카메라를 이용하여 관절 점을 추출하는 경우는 영상의 깊이 정보나 3차원 정보를 추출하여 활용할 수 있다. 그러나 제안 방법은 단일카메라로 입력받는 2차원 영상을 이용하여 깊이 정보 없이 관 절 점을 추출해야 하므로 관절 점 검출 시 더 정확한 검출을 위해 보행자를 정면 보행자와 측면 보행자로 분류한다. 그리고 분류된 보행 타입에 따라 관절 점 의 검출을 다르게 수행한다. Fig. 2는 제안하는 보행 자 유형에 따른 관정점 검출 방법의 흐름도이다.
(a) (b)
Fig. 1. Gait’s Types. (a) Front, and (b) Flank.
Fig. 2. Flowchart for Joints Detection Algorithm.
2.1 객체 및 경계선 검출
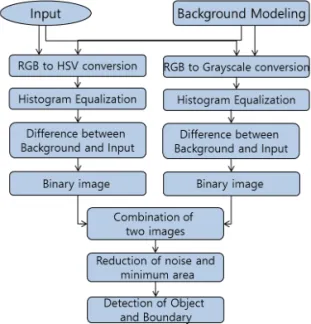
객체 및 외곽선 추출은 보행자의 관절 점을 추출 하기 위한 전처리 단계로서 관정점 추출의 정확도를 결정하기 위해 매우 중요하다. 또한, 정확한 객체 검 출 및 분할을 위해 전경과 배경의 분리는 필수적이며 매우 중요한 기술이다. 본 논문에서는 입력 영상의 그림자 영역이 객체로 결합하거나 조명의 변화로 인 한 전경과 배경의 분리 오차를 개선하기 위하여 RGB 영상의 회색 조 영상과 HSV 좌표계의 색상 영상을 이용하여 전경과 배경을 분리한다. 먼저 배경 및 입 력 영상의 회색 조 영상의 차 영상을 구하고 이진화 하며 또한 배경과 입력 영상을 HSV 좌표계로 변환 하여 색상(hue) 영상의 차 영상의 이진화 영상을 구 하여 그 결과를 결합한다. 색상 영상과 회색 조 영상 의 이진화는 Otsu의 방법을 사용하며 최종이진 영상 은 회색 조 영상과 색상 영상의 이진화 영상의 객체 영역을 결합하여 얻는다.
foreground or background otherwise (1) 여기서 는 색상 영상의 이진화 영상,
는 회색 조 영상의 이진화 영상, 는 최종 이진 화 영상이다.
이와 같이 이진화한 결과 영상은 객체 영역 이외 의 미세영역이 다수 존재한다. 따라서 최종이진 영상 을 얻기 위해 식(1)의 결과 이 진영상의 미세영역 및 잡음을 제거하여 최종이진 영상을 구한다. 제안 방법 에서는 모폴로지컬 필터와 영역의 크기에 제한을 두 어 미세영역 및 잡음을 제거하였다. Fig. 3은 객체 추출을 위한 배경과 전경의 분리 및 이진화와 객체 검출 알고리즘이다.
2.2 보행자의 유형 분류
제안 방법은 관정점 정확한 검출을 위해 보행자를 정면 보행자와 측면 보행자로 분류하여 분류된 보행 타입에 따라 관절 점의 검출을 다르게 수행한다. Fig.
4는 검출된 객체를 얼굴 영역, 몸체 영역으로 분리하 여 나타낸 그림이다.
보행자의 유형은 Fig. 4의 객체의 얼굴 영역의 너 비(fw)와 객체영역의 너비(tw)를 이용하여 구한다.
얼굴 영역은 피부색을 이용하여 검출하며 검출된 얼 굴 영역의 너비를 구하여 fw 값으로 한다. 피부색
검출 각 색 공간에서의 미리 정의된 피부색 영역에 따라 피부색 영역을 검출하여 이루어지며, 색 공간 중 RGB, YCbCr, HSI 등이 가장 널리 사용되고 있다 [10]. 먼저 RGB 색 공간은 밝기 정보와 컬러 정보를 동시에 포함하므로 조명에 민감한가. 따라서 RGB 색 공간의 조명에 의한 영향을 감소시키기 위해 YCbCr 색 공간이나 HSI 색 공간을 이용한 피부색 검출이 연구되었다. 본 논문에서는 YCbCr 색 공간에 서 정의된 피부색 영역을 이용하여 얼굴을 검출하며 YCbCr의 다음과 같은 영역을 사용한다[11].
Fig. 3. Flowchart for Object and Boundary of it Algorithm.
Fig. 4. Bounding Boxes of Object.
≤ ≤ ∩ ≤ ≤ (2) 제안 방법은 검출된 얼굴 영역과 객체정보를 이용 하여 보행자의 유형을 분류하며 객체의 비율과 얼굴 영역을 비율을 이용한다. 다음은 보행자의 타입을 분 류하는 식이다.
front i f ≥ ×
flank otherwise (3)
여기서 GT는 보행자 타입, tw는 객체 몸통의 폭, fw는 얼굴 영역의 폭이다.
이때 보행자가 팔을 벌리고 있거나 객체의 기울어 짐 등으로 보행자의 타입이 잘못 분류되는 것을 방지 하기 위해 객체의 너비는 전체 객체영역 중(Bw) 어 깨 영역을 중심으로 객체영역의 중심점에서 어깨 영 역까지의 길이(SC)의 1/3 지점( × )까지를 구 하여 그 영역의 너비(tw)로 정하였다.
2.3 보행자 타입에 따른 관정점 검출
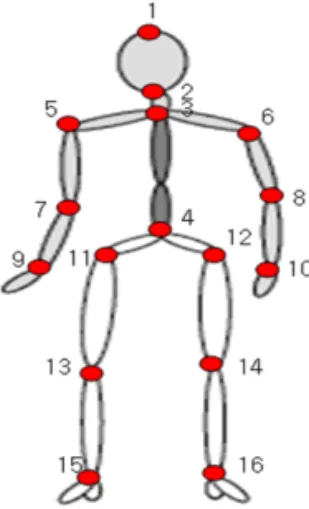
인체의 기본 관절 점은 Fig. 5와 같이 16개로 정의 될 수 있으며[12], 본 논문에서는 16개의 기본 관절 점에서 보행자 타입에 따라 움직임에 영향을 줄 수 있는 관절 점을 추출하였다. 정면 보행자는 움직임에 영향을 줄 수 있는 관절 점을 (1,2,5,6,9,10,11,12,15, 16)의 10개로 정하였고 이 10개의 관절점을 추출한 다. 그러나 측면 보행의 경우 겹쳐진 영역으로 인하 여 한쪽의 관절 점은 추출하기가 어렵다. 따라서 측 면 보행은 겹쳐진 영역의 관절점을 제외하고 영상에 따라 기본 7개(1,2,5,9,11,15,16 또는 1,2,6,10,12,15,16) 의 관절 점과 다른 쪽 손 영역 관절점 등을 추출한다.
제안 방법은 객체 중심점을 기준으로 관절 점의 위치정보(거리정보)를 이용하여 관절 점을 검출하기 때문에 관절 점 추출을 위해 먼저 객체의 중심점을 계산한다. 객체의 중심점은 객체의 다양한 정보를 표 현할 수 있지만 움직임에 영향을 주는 관절 점은 아 니므로 관절 점으로 추출되지 않는다. 정면보행에서 관절 점을 추출하기 위한 알고리즘은 다음과 같다.
측면 보행에서 관절 점 추출 과정은 정면보행의 관절 점 중 겹침으로 인해 추출되지 않는 관절점을 고려하여 선택하므로 정면보행에서 관절 점 추출 과 정과 유사하며 다음과 같다.
1. 객체의 중심점(C)을 계산한다.
2. 중심점(c)보다 낮은 영역이면서 중심점에서 가 장 먼 두 점을 발목 점(f1,f2)으로 선택한다.
3. 얼굴 영역의 두 점을 얼굴 점(a1,a2)으로 선택한다.
4. 중심점 위의 영역에서 객체의 폭이 제일 넓은 영역의 좌우 경계점을 검출하여 중심점을 어깨 점 (s1)으로 선택한다.
5. 피부색 및 영역정보를 이용하여 손 영역을 검출 하고 손목 관절 점(w1)으로 선택한다.
6. 중심점+1/3h (h:목점과 중심점 길이) 지점과 f1,f2의 좌표를 이용하여 힙 관절 점(h1)을 선택한다.
4. 실험 결과 및 고찰
제안 방법은 실내 환경에서 단일 카메라를 이용하 여 획득된 영상을 이용하여 성능을 테스트하였다. 제 안 방법은 단일카메라의 입력으로 보행자의 관절 점 을 자동으로 추출하는 것을 목적으로 한다. 따라서 보행자 객체 추출을 위하여 사람이 걸어가는 동작을 대상으로 제안 방법을 적용하여 그 결과를 분석하였 다. 시스템은 Intel cpu 2.6GHz, 16G RAM에서 비주 얼 스튜디오 2010과 Open CV 2.4.9를 이용하여 구현 하였으며, 640×480 24bit의 실시간 입력영상을 이용 하여 실험하였다.
Fig. 6은 제안 방법을 적용한 결과를 단계적으로 보여준다. Fig. 6(a)는 배경영상이며 (b)는 입력 영상 (c)는 객체 검출 영상 (d)는 객체의 경계선과 객체영 역의 사각 박스 (e)는 객체의 코너 점 검출 결과 (f)는 10개의 관절 점 추출결과를 보여준다. 또한 (g)는 (f) 의 관절 점의 좌표를 보여준다.
Fig. 5. Basic Joint of Human Body.
Algorithm for Extracting Joint Point in Front Gait
/* Calculate Center Point and Select Ankle Point(f1,f2) of Object*/
input : object region
n : the number of object region m : the number of corner point maxd=0, d=0;
for i=0 to n
compute center point cx,cy for i=0 to m
If y(i) > cy
(1) compute the distance from center point to corner point
�� �
(2) find two joint of max distance(left ankle joint, right ankle joint) if ( maxd< d) maxd=d, ind=i
end
/*Select Face Point (a1, a2)*/
input : top-left point(p1) and right-bottom point(p2) of box of face region a1.x=(p1.x+p2.x)/2 , a1.y=p1.y
a2.x=a1.x , a2.y=p2.y
/*Select Shoulder Point (s1, s2)*/
input : top-left point(sc1) and right-bottom point(sc2) of sc region of fig4.
m : the number of corner point
mind1 =10000000000, mind2 =10000000000, d=0
for i=0 to m
If x(i) >= sc1.x && x(i) <= sc2.x && y(i) >= sc1.y && y(i) <= sc2.y (1) compute the distance from boundary-points of sc region to corner point (2) find two joint of min distance(left shoulder joint, right shoulder joint)
if x(i) <= (sc1.x +sc2.x)/2
if ( mind1 > d) mind1=d, ind=i else
if ( mind2> d) mind2=d, ind=i end
s1 =ind1, s2=ind2
/* Extraction of Wrist Joint Point (w1, w2) */
input : object region except face region m : the number of corner point
mind1 =10000000000, mind2 =10000000000, d=0;
(1) Detection of Hand Region
- detect of skin color region((77 ≤≤127)∩(133≤≤173))
Fig. 7은 정면 보행자와 측면 보행자에 대해 객체 영역과 얼굴 영역을 검출한 결과와 관절 점 추출한 결과를 보여준다. Fig. 7은 정면 및 측면 보행자의 객체 및 얼굴 영역을 잘 분류하고 각 영상에 대해 관절 점도 잘 추출되었음을 보여준다.
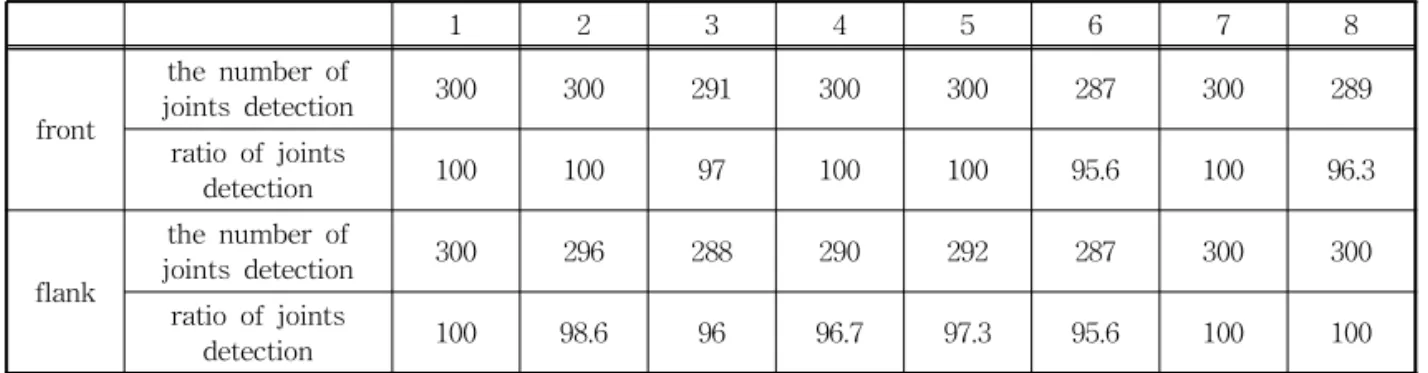
Table 1은 제안된 방법을 실험 영상에 적용하여 관절점 추출결과를 분석한 결과이다. 실험 영상은 배 경이 다른 3 장소를 대상으로, 정면 보행자 8 영상과 측면 보행자 8 영상에 대해 실험하였으며, 입력 영상 은 300프레임을 사용하였다. 제안 방법은 98.3%의 완성도를 보였다. 이것은 입력 영상에서 다리 영역에
그림자 등으로 인하여 객체영역 검출 시 다리 영역 검출이 잘못되어 발목 점 검출에서 발생했으며, 관절 점 추출 시 어깨 점 추출 및 힙 관절 점 추출에서 발생했다.
5. 결 론
본 논문에서는 단일카메라에서 실시간 입력되는 동영상에서 보행자의 실루엣과 관절 점을 자동으로 추출하는 알고리즘을 제안한다. 제안 방법은 마커나 센서 없이 실루엣을 추출하며 3D 카메라와 다수의 wr1: top-left point of hand region , wr2: right-bottom point of hand region
(2) Extraction of Wrist Joint Point for i=0 to m
(a) compute the distance from wr1 and wr2 to corner point (b) find two joint of min distance(left wrist joint, right wrist joint)
if x(i) <= (wr1.x +wr.x)/2
��
if ( mind1 > d) mind1=d, ind=i else
� if ( mind2 > d) mind2=d, ind=i end
w1 =ind1, w2=ind2
/* Select the Hip Joint (h1,h2)*/
input : object region
h : neck joint , center point between left shoulder joint and right shoulder joint h.x= (s1.x+s2.x)/2 h.y= (s1.y+s2.y)/2
c : center point
m : the number of corner point
mind1 =10000000000, mind2 =10000000000 d=0;
ref = c+ h*(1/3) for i=0 to m
If y(i) > cy
if x(i) <= ref.x ��
if ( mind > d) mind1=d, ind1=i else
if ( mind2 > d) mind2=d, ind2=i end
h1 =ind1, h2=ind2
카메라를 필요로 하는 기존의 방법과 다르게 한 대의 카메라를 통해 입력된 영상으로 자동으로 인체의 실 루엣과 관절 점을 추출한다. 제안 방법은 차 영상 기 법을 적용하여 객체를 추출하며 추출된 객체의 얼굴 영역과 몸체의 비율을 이용하여 보행자의 타입을 결 정하고 각 타입에 따라 정면 영상은 10개, 측면 영상
은 7∼8의 관절 점을 자동검출 한다. 제안 방법을 배 경이 다른 3 장소를 대상으로, 정면 보행자 8 영상과 측면 보행자 8 영상에 대해 실험하였으며, 실험 영상 은 300프레임을 사용하였다. 제안 방법은 정면 및 측 면 영상을 잘 분류하였고 관절 점 검출에 98.3%의 완성도를 보였다. 제안방법은 보행자 인식, 보행인
(a) (b) (c)
(d) (e) (f)
x y 1: 366 49 2: 366 104 5: 326 130 6: 404 117 9: 313 266 10: 420 261 11: 345 245 12: 387 245 15: 345 410 16: 387 410
(g)
Fig. 6. Images of Proposed Method. (a) Background image, (b) Input image, (c) Object detection (d) Boundary of object (e) Corner points of object, (f) Joints detection of input (g) Coordinates of joints
(a) (b) (c)
(d) (e) (f)
Fig. 7. Results by the Proposed Method (a) Input image(front), (b) Object and face detection of (a), (c) Joints detection of (a), (d) Input image(flank), (e) Object and face detection of (d), and (f) Joints detection of (d).
식, 행동인식 및 3D 애니메이션 등의 다양한 분야에 응용 가능하다.
REFERENCE
[ 1 ] W. Gong, X. Zhang, J. Gonzàlez, A. Sobral, T.
Bouwmans, C. Tu, and E. Zahzah, “Human Pose Estimation from Monocular Images: A Comprehensive Survey,”Sensors, Vol. 16, No.
12, pp. 1-39, 2016.
[ 2 ] D.S. Patil, R.B. Khanderay, and T. Padvi,
“Survey on Moving Body Detection in Video Surveillance System,”International Journal of Engineering and Techniques, Vol. 1, No. 3, pp.
123-128, 2015.
[ 3 ] K.M. Lee and W.N. Streeet, “Model-Based Detection, Segmentation and Classification Using On-Line Shape Learning,” Machine Vision and Application, Vol. 13, No. 4, pp.
222-333, 2003.
[ 4 ] D.H. Wilson, A.C. Long, and C. Atkeson, “A Context-Aware Recognition Survey for Data Collection Using Ubiquitous Sensors in the Home,” Proceeding of CHI 2005: Late Bre- aking Results, pp. 1865-1868, 2005.
[ 5 ] E. Murphy-Chutorian and M. Trivedi, “Head Pose Estimation in Computer Vision: A Survey,” IEEE Transaction on Pattern Anaysis and Machine Intelligence, Vol. 31, No. 4, pp. 607-626, 2009.
[ 6 ] M. Paul, S.M.E. Haque, and S. Chakraborty,
“Human Detection in Surveillance Videos and
Its Applications-A Review,”EURASIP Journal of Advances in Signal P rocessing, Vol. 2013, No, 22, pp. 176-185, 2013.
[ 7 ] A. Hill, C.J. Taylor, and A.D. Brett, “A Fra- mework for Automatic Landmark Identifica- tion Using a New Method of Nonrigid Corres- pondence,” IEEE Transaction on Pattern Analysis and Machine Intelligence, Vol. 22, No. 3, pp. 241-251, 2000.
[ 8 ] K. Jujimura, T. Zhu, and V.N. Thow-Hing,
“Estimating Pose from Depth Image Stream,”
Proceeding of IEEE International Confer- ence on Humanoid Robots, pp. 154-160, 2005.
[ 9 ] S. Asteriadis, A. Chatzitofis, D. Zarpalas, D.S.
Alexiadis, and P. Daras, “Estimating Human Motion from Multiple Kinect Sensors,” Pro- ceeding of the 6th International Conference on Computer Vision/Computer Graphics Colla- boration Techniques and Applications, No. 3, pp. 1-6, 2013.
[10] P. Viola and M.J. Jones, “Robust Real-Time Face Detection,” International J ournal of Computer Vision, Vol. 52, No. 2, pp. 137, 2004.
[11] D. Chai and A. Bouzerdoum, “A Bayesian Approach to Skin Color Classification in YCgcr Color Space,” Proceeding of IEEE Tencon 2000, pp. 421, 2000.
[12] N.J. Kwak and T.S. Song, “Object-Action and Risk-Situation Recognition Using Moment Change and Object Size’s Ratio,” J ournal of Korea Multimedia Society, Vol. 17, No. 5, pp.
556-565, 2014.
Table 1. The Performance for Proposed Algorithm
1 2 3 4 5 6 7 8
front
the number of
joints detection 300 300 291 300 300 287 300 289
ratio of joints
detection 100 100 97 100 100 95.6 100 96.3
flank
the number of
joints detection 300 296 288 290 292 287 300 300
ratio of joints
detection 100 98.6 96 96.7 97.3 95.6 100 100
곽 내 정
2005년 2월 충북대학교 정보통신 공학과 공학박사 2005년 3월~2006년 2월 : 목원대
학교 정보통신 공학과 프 로그래밍 전문강사 2006년 3월~2009년 2월 : 목원대
학교 정보통신 공학과 강 의전임
2009년 3월~ 현재 : 충북대학교, 고려대학교 ,배재대학 교 시간강사
관심분야 : 멀티미디어 정보처리, 멀티미디어 통신, 행동 인식 및 상황인지
송 특 섭
2001년 2월 연세대학교 수학과 (이학박사)
2006년 2월 연세대학교 컴퓨터과 학과(공학박사)
2006년 3월~현재 목원대학교 융 합컴퓨터미디어학부 교수
관심분야: 웹환경 어노테이션, 센서네트워크