한국정보통신학회논문지 Vol. 23, No. 11: 1357~1363, Nov. 2019
중기 염색체 객체 검출을 위한 Faster R-CNN 모델의 최적화기 성능 비교
정원석1·이병수2·서정욱3*
Performance Comparison of the Optimizers in a Faster R-CNN Model for Object Detection of Metaphase Chromosomes
Wonseok Jung1 · Byeong-Soo Lee2 · Jeongwook Seo3*
1Graduate Student, Dept. of Information and Communication Eng., Namseoul University, Cheonan, 31020, Korea
2Assistant Manager, Data mining team, Estmob, Seoul, 06627, Korea
3*Assistant professor, Dept. of Information and Communication Eng., Namseoul University, Cheonan, 31020, Korea
요 약
본 논문은 사람의 중기 염색체로 이루어진 디지털 이미지에서 Faster Region-based Convolutional Neural Network(R-CNN) 모델로 염색체 객체를 검출할 때 필요한 경사 하강 최적화기의 성능을 비교한다. Faster R-CNN의 경사 하강 최적화기는 Region Proposal Network(RPN) 모듈과 분류 점수 및 바운딩 박스 예측 블록의 목적 함수를 최 소화하기 위해 사용된다. 실험에서는 이러한 네 가지 경사 하강 최적화기의 성능을 비교하였으며 VGG16이 기본 네 트워크인 Faster R-CNN 모델은 Adamax 최적화기가 약 52%의 Mean Average Precision(mAP)를 달성하였고 ResNet50이 기본 네트워크인 Faster R-CNN 모델은 Adadelta 최적화기가 약 58%의 mAP를 달성하였다.
ABSTRACT
In this paper, we compares the performance of the gredient descent optimizers of the Faster Region-based Convolutional Neural Network (R-CNN) model for the chromosome object detection in digital images composed of human metaphase chromosomes. In faster R-CNN, the gradient descent optimizer is used to minimize the objective function of the region proposal network (RPN) module and the classification score and bounding box regression blocks. The gradient descent optimizer. Through performance comparisons among these four gradient descent optimizers in our experiments, we found that the Adamax optimizer could achieve the mean average precision (mAP) of about 52% when considering faster R-CNN with a base network, VGG16. In case of faster R-CNN with a base network, ResNet50, the Adadelta optimizer could achieve the mAP of about 58%.
키워드 : Faster R-CNN, 경사 하강법 최적화, 중기염색체, VGG16, ResNet50
Keywords : Faster R-CNN, Gradient descent optimizer, Metaphase chromosome, VGG16, ResNet50
Received 29 July 2019, Revised 1 August 2019, Accepted 4 September 2019
* Corresponding Author Jeongwook Seo(E-mail:[email protected], Tel:+82-41-580-2122)
Assistant professor, Department of Information and Communication Engineering, Namseoul University, Cheonan, 31020 Korea
Open Access http://doi.org/10.6109/jkiice.2019.23.11.1357 print ISSN: 2234-4772 online ISSN: 2288-4165
Ⅰ. Introduction
A chromosome is a strand of deoxyribonucleic acid (DNA) encoded with genes. In most cells, humans have 22 pairs of chromosomes plus two sex chromosomes for a total of 46. Thus, because chromosomes are genetic information carriers, chromosome analysis known as karyotyping is an important technique in clinical and cancer cytogenetics studies [1–4]. It is a test to find the size, shape, and number of chromosomes in a sample of body cells for the purpose of diagnosing extra or missing chromosomes, or abnormal positions of chromosome pieces that cause problems with a person’s growth, development, and body functions. Especially, metaphase chromosome analysis is often performed for diagnostic purposes because observations of chromosome segments or translocations during metaphase are most condensed and easiest to distinguish.
However, it takes a lot of effort and time to manually segment and classify some chromosomes in metaphase chromosome images. Accordingly, many methods have so far been developed for automatically segmenting or classifying the chromosomes [5–10] where not only a machine learning algorithm such as support vector machine (SVM) but also a deep learning algorithm such as convolutional neural network (CNN) was presented.
Recently, faster region-based CNN (R-CNN) for object detection has been proposed to overcome the complex training process in both R-CNN [11] and fast R-CNN [12] by using the region proposal network (RPN) [13, 14]. Object detection involves localizing each object by drawing the appropriate bounding box around an image, recognizing and classifying every object in the image. Faster R-CNN is well known to achieve much better speeds and a state-of-the-art accuracy in object detection. Therefore, in this paper, we shall apply faster R-CNN to object detection of metaphase chromosome images and find appropriate gradient descent optimizers for given VGG16 and ResNet50 CNN architectures by comparing Adadelta, Adamax, RMSprop, and Adagrad optimizers used for
the RPN module, the classification score and bounding box regression blocks.
The rest of the paper is organized as follows. Section 2 describes faster R-CNN for object detection of metaphase chromosome images, and Section 3 explains four gradient descent optimizers considered in faster R-CNN. We present the details of the dataset used and experimental results in Section 4. Finally, we close with some brief concluding remarks in Section 5.
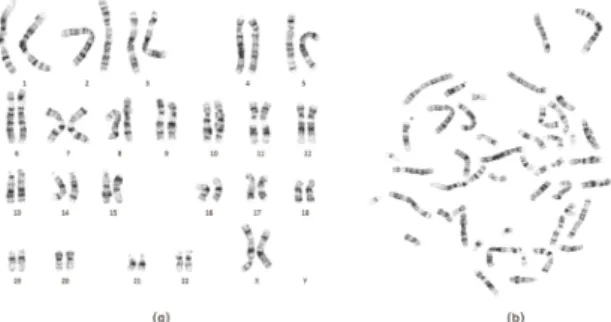
Fig. 1 (a) Karyotype Image and (b) Metaphase chromosome image.
Ⅱ. Faster R-CNN for Object Detection of Metaphase Chromosome Images
Before performing object detection through faster R-CNN, a karyotype image (Fig. 1(a)) has to be prepared by segregating individual chromosomes in a cell spread image (Fig. 1(b)).
From 40 karyotype images, we create a dataset of metaphase chromosomes with bounding box information (x, y, width, height) and labels (chromosome number- left or right) as given in Table 1 (note that 5-? and X-?
denote exceptions). To increase the amount of relevant data in the dataset, we also use random rotation (0, 90, 180, 270 degrees) and flip (vertical, horizontal) methods of data augmentation in [15]. A total of 1838 data were increased to a total of 29408 data through data augmentation such as random rotation and flip.
As shown in Fig. 2, faster R-CNN for object detection can be roughly represented by using three modules:
CNN, RPN and Faster R-CNN. First, as the CNN module, we consider
Table. 1 Dataset of Metaphase Chromosomes Label Number of Data Label Number of Data
1-l 40 13-l 40
1-r 40 13-r 40
2-l 40 14-l 40
2-r 40 14-r 40
3-l 40 15-l 40
3-r 40 15-r 40
4-l 40 16-l 40
4-r 40 16-r 40
5-l 39 17-l 40
5-r 39 17-r 40
5-? 1 18-l 40
6-l 40 18-r 40
6-r 40 19-l 40
7-l 40 19-r 40
7-r 40 20-l 40
8-l 40 20-r 40
8-r 40 21-l 40
9-l 40 21-r 40
9-r 40 22-l 40
10-l 40 22-r 40
10-r 40 X-l 39
11-l 40 X-r 19
11-r 40 X-? 1
12-l 40 Y 20
12-r 40
VGG16[16] or ResNet50 [17] architectures to extract features for RPN and faster R-CNN from metaphase chromosome images (karyotype). Second, in order to generate regions of interest (ROIs), the RPN module pushes a small network (n × n sliding window) onto the CNN features by the last shared convolution layer. For each sliding window location, multiple possible regions based on k fixed-ratio default bounding boxes called anchors are generated and then they are fed into a fully connected (FC) layer of two siblings (object score and region regression blocks). After objectness score and
regressed region of each anchor are calculated, the ROIs in the descending order of objectness score are generated in the RoI proposal block where non-maximum suppression is used to combine regressed anchors before selecting ROIs from anchors. Finally, the subsequent process is the same as Faster R-CNN. In other words, the faster R-CNN module cassifies each ROI and regresses its bounding box. The CNN features from the CNN module are cropped by each ROI, and only cropped features are pooled and the pooled features pass some hidden fully connected (FC) layers. Then, for each ROI, class probability score and regressed bounding box are calculated from FC layers.
Fig. 2 Block diagram of faster R-CNN for object detection of metaphase chromosome images
Ⅲ. Gradient Descent Optimization Algorithms
Gradient descent optimization algorithms are usually associated with a line search method to ensure that the algorithms consistently improve an objective function in deep learning [18]. For faster R-CNN, the objective function can be defined as [13]
(1)
where is the index of an anchor in a mini-batch, is the predicted probability of anchor being an object, and
is the ground-truth label. Here, is a vector representing the 4 parameterized coordinates of the predicted bounding box, and is that of the
ground-truth box associated with a positive anchor.
Also, two terms are normalized by and and weighted by a balancing parameter . denotes the classification loss and normalized by the mini-batch size (i.e., = 256), and does the regression loss and normalized by the number of anchor locations (i.e.,
∼ 2, 400). By default we set = 10, and thus both
and terms are roughly equally weighted.
To minimize the above objective function, we will use four gradient descent optimizers: Adadelta, Adamax, RMSprop, and Adagrad under the assumption that the same optimizer is used for the RPN module, the classification socore and bounding box regression blocks.
Now, we briefly introduce these optimizers as follows and the details of them can be found in [19–21]. Firstly, the Adagrad optimizer in (2), well-suited for dealing with sparse data, adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters. One of its main benefits is that it can eliminate the need to manually tune the learning rate.
⊙ (2)
where is the updated parameter at time step ,
is the current parameter at time step , is the learning rate, is a diagonal matrix where each diagonal element is the sum of the squares of the gradients, is a smoothing term that avoids division by zero, ⊙ is an elementwise matrix-vector multiplication, and is the gradient vector of the objective function.
Secondly, the Adadelta optimizer in (3) is an extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate.
∆ ∆
∆
(3)
where ∆ is the parameter updata vector at time step
, ∆ is the root mean square (RMS) error of
parameter updates at time step , and is the RMS error criterion of the gradient at time step . Instead of accumulating all past squared gradients, it restricts the window of accumulated past gradients to some fixed size. With the Adadelta optimizer, there is no need to set a default learning rate which has been eliminated from the update rule. Next, the RMSprop optimizer in (4) is an adaptive learning rate method which has also been developed to resolve radically diminishing learning rates of the Adagrad.
(4)
where is the running average at time step .
Thus, it is identical to the first update vector of the Adadelta and it divides the learning rate by an exponentially decaying average of squared gradients.
Finally, the Adamax optimizer in (5) is a variant of adaptive moment estimation (Adam) based on the infinity norm.
(5)
where is the infinity norm-constrained , an estimate of the second moment (the uncentered variance) of the gradients and is the bias-corrected first moment estimate. The Adam computes adaptive learning rates for each parameter, stores an exponentially decaying average of past squared gradients like the Adadelta and the RMSprop, and keeps an exponentially decaying average of past gradients similar to momentum. Since relies on the max operation, we do not need to compute a bias correction for .
Ⅳ. Experimental Results and Discussion
For experiments of faster R-CNN to detect metaphase chromosomes, 10 TITAN Xp GPU servers were used.
For training faster R-CNN, we performed 1000 times per epoch and repeated 300 times in total. The parameters of the Adadelta optimizer were set to , ,
−, [19], and those of the Adagrad optimizer were set to , −, .
We set those of the Adamax optimizer to ,
, , −, and did those of the RMSprop optimizer to , ,
−, [20, 21].
Fig. 3 mAP performances of faster R-CNN with VGG16 according to the optimizers
Fig. 4 Loss rate of faster R-CNN with VGG16 (Adamax)
According to the gradient descent optimizers, mean average precision (mAP) performances of faster R-CNN with the VGG16 architecture are shown in Fig. 3. The Adamax optimizer achieves the mAP performance of 51.64% and outperfoms the others. The mAP performance of the Adadelta optimizer is very similar to that of the Adagrad optimizer, and the RMSprop shows the worst
performance of 27.49%. In Fig. 4, loss rate per epoch and precision performance per chromosome are represented when using the Adamax optimizer for faster R-CNN with the VGG16 architecture. The cure of loss rate decreases as the number of epochs increases, and the lowest value of loss rate is about 0.036. In addition, Fig.
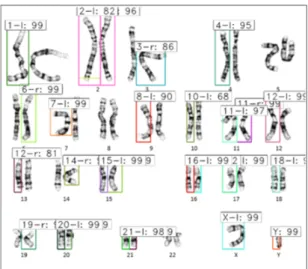
5 shows the results of object detection of metaphase chromosomes. The detected chromosome is the probability that the bounding box is the colon in Table 1 on the left and the label on the right is the chromosome on the right.
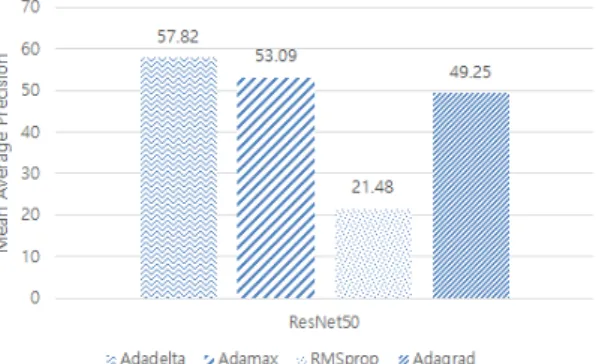
In Fig. 6, mAP performances of faster R-CNN with the ResNet50 architecture are illustrated according to the gradient descent optimizers. The Adadelta optimizer shows the best performance of 57.82% when compared with the others. The mAP peformance of the Adamax optimizer is about 53%, and that of the Adagrad optimizer is about 49%. The RMSprop still shows the worst performance of 21.48%. In Fig. 7, loss rate per epoch and precision performance per chromosome are represented when using the Adadelta optimizer for faster R-CNN with the ResNet50 architecture. The cure of loss rate slightly increases as the number of epochs increases.
In addition, Fig. 8 is the same as Fig. 5 shows the results of object detection of metaphase chromosomes. The detected chromosome is the probability that the bounding Fig. 5 Precision performance of faster R-CNN with VGG16 (Adamax)
box is the colon in Table 1 on the left and the label on the right is the chromosome on the right.
Fig. 6 mAP performances of faster R-CNN with ResNet50 according to the optimizers
Fig. 7 Loss rate of faster R-CNN with ResNet50 (Adadelta)
Fig. 8 Precision performance of faster R-CNN with ResNet50 (Adadelta)
Additionally, for object detection of metaphase chromosomes, faster R-CNN with the ResNet50 using the Adadelta optimizer shows better mAP performance than that with the VGG16 using the Adamax optimizer.
Ⅴ. Conclusion
In this paper, we applied faster R-CNN with VGG16 and ResNet50 to object detection of metaphase chromosomes and found a proper optimizer for RPN and faster R-CNN (classification score and bounding box regresstion) modules in faster R-CNN. Through performance comparisons between Adadelta, Adamax, RMSprop, and Adagrad, it is found that the Adamax optimizer could achieve the mAP performance of 51.64% when using faster R-CNN with VGG16 and that the Adadelta optimizer could achieve the best mAP performance of 57.82% when using faster R-CNN with ResNet50.
Therefore, it is confirmed that it is better than the object detection performance using the existing Faster R-CNN of about 44.6 ~ 59.2%.
ACKNOWLEDGEMENT
Funding for this paper was provided by Namseoul University.
REFERENCES
[ 1 ] Y. Ohnuki, “Structure of chromosomes,” Chromosoma, vol.
25, no. 4, pp. 402-428, Dec. 1968.
[ 2 ] F. Gilbert, “Chromosomes, genes, and cancer: A classification of chromosome abnormalities in cancer,” Journal of the National Cancer Institute, vol. 71, no. 6, pp. 1107-1114, 1983.
[ 3 ] B. Lerner, “Toward a completely automatic neural-network- based human chromosome analysis,” IEEE Transactions on Systems, Man, and Cybernetics, Part B(Cybernetics), vol.
28, no. 4, pp. 544-552, 1998.
[ 4 ] L. B. W. Yan, “Algorithms for chromosome classific- ation,”
Engineering, vol. 5, pp. 400-403, 2013.
[ 5 ] A. Carothers, and J. Piper, “Computer-aided classification of human chromosomes: a review,” Statistics and Computing, vol. 4, no. 3, pp. 161-171, 1994.
[ 6 ] G. Agam, and I. Dinstein, “Geometric separation of partially overlapping nonrigid objects applied to automatic chromosome classification,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 19, no. 11, pp.
1212-1222, 1997.
[ 7 ] P. Nithya, and M. Nirmala, “Automatic segmentation of overlapped images,” International Journal of Modern Engineering Research (IJMER), vol. 2, no. 3, pp. 618-623, 2012.
[ 8 ] C. Markou, C, Maramis, A. Delopoulos, C. Daiou, and A.
Lambropoulos, “Automatic chromosome classification using support vector Machines,” in Pattern Recognition: Methods and Applications, Hong Kong, iConceptPress, pp. 1-24, 2012.
[ 9 ] Tanvi, and R. Dhir, “An efficient segmentation method for overlapping chromosome images,” International Journal of Computer Applications, vol. 95, no. 1, pp. 29-32, 2014.
[10] M. Sharma, O. Saha, A. Sriraman, R. Hebbalaguppe, L. Vig, and S. Karande, “Crowdsourcing for chromosome segmentation and deep classification,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, pp. 786-793, 2017.
[11] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Ohio, pp. 580-587, 2014.
[12] R. Girshick, “Fast R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, pp. 1440-1448, 2015.
[13] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN:
Towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137-1149, 2017.
[14] R. Reiazien, R. Paydar, A. A. Ardakani, and M. tedadialiab- adi, “Mammography lesion detection using Faster R-CNN detector,” in Proceedings of the 7th International Conference on Natural Language Processing, Dubai, pp. 111-115, 2018.
[15] L. Perez, and J. Wang, “The effectiveness of data augmentation in image classification using deep learning,”
Computing Research Repository (CoRR), vol. abs/1805.
09501, 2017.
[16] K. Simonyan, and A. Zisserman, “Very deep convolutional
networks for large-scale image recognition,” in Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, arXiv:1409.1556v6, 2015.
[17] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, Nevada. pp. 770-778, 2016.
[18] Q. V. Le, J. Ngiam, A. Coates, A. Lahiri, B. Prochnow, and A. Y. Ng, “On optimization methods for deep learning,” in Proceedings of the 28th International Conference on Machine Learning, Bellevue, Washington, pp. 265-272, 2011.
[19] M. D. Zeiler, “Adadelta: An adaptive learning rate method,”
Computing Research Repository (CoRR), vol. abs/1212.5701, 2012.
[20] D. P. Kingma, and J. Ba, “Adam: A method for stochastic optimization,” in Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, pp. arXiv:1412.6980v9, 2015.
[21] S. Ruder, “An overview of gradient descent optimization algorithms,” Computing Research Repository (CoRR), pp.
abs/1609.04747, 2016.
정원석(Wonseok Jung)
2018년 3월 – 현재 남서울대학교 정보통신공학과 석사과정
2018년 2월 남서울대학교 정보통신공학과 공학사
※관심분야 : 사물인터넷, 머신러닝/딥러닝, 행위 및 감정인식
이병수(Byeong-Soo Lee)
2018년 12월 – 현재 이스트몹 연구원 2018년 2월 남서울대학교 정보통신공학과 공학
석사
2016년 2월 남서울대학교 정보통신공학과 공학사
※관심분야 : 빅데이터, 데이터 분석, 머신러닝/
딥러닝, 인공지능
서정욱(Jeongwook Seo)
2014년 3월 – 현재 남서울대학교 정보통신공학과 조교수
2001년 1월 – 2014년 2월 KETI 스마트네트워크 연구센터 책임연구원
2010년 8월 연세대학교 전기전자공학과 공학박사
※관심분야 : 사물인터넷, 머신러닝/딥러닝, 행위 및 감정인식