Principal component regression for spatial data
Yaeji Lim
a,1a
Department of Statistics, Pukyong National University
(Received November 23, 2016; Revised January 11, 2017; Accepted February 4, 2017)
Abstract
Principal component analysis is a popular statistical method to reduce the dimension of the high dimensional climate data and to extract meaningful climate patterns. Based on the principal component analysis, we can further apply a regression approach for the linear prediction of future climate, termed as principal component regression (PCR). In this paper, we develop a new PCR method based on the regularized principal component analysis for spatial data proposed by Wang and Huang (2016) to account spatial feature of the climate data.
We apply the proposed method to temperature prediction in the East Asia region and compare the result with conventional PCR results.
Keywords: principal component analysis, empirical orthogonal functions, principal component regression, spatial data, temperature prediction
1. Introduction
주성분분석은 서로 상관관계가 있는 변수들의 복잡한 구조를 선형결합을 통해 독립적인 새로운 변수를 생성함으로서 자료를 이해하는 대표적인 다변량 분석방법 중 하나이다. 특히, 기상학 분야에서 사용되 는 주성분 분석은 경험적 직교 함수(empirical orthogonal function; EOF)라고 불러지며, 기상자료의 의미있는 패턴을 발견하는 데 사용된다. 즉, 주어진 기상자료의 공분산 행렬의 고유벡터(eigenvector)값 으로 정의되는 경험적 직교 함수를 통하여 주된 기상패턴을 찾는 방법론이다.
하지만, 기존의 주성분분석은 공간적인 정보를 고려하지 않은 채, 단순히 공분산 행렬을 계산한다. 따라 서 공간적 정보를 고려한 주성분분석이 개발되어 왔다 (Demˇsar 등, 2013; Shen과 Jianhua, 2008). 또 한, 변수의 개수 p가 관측치의 개수인 n에 비해 매우 큰 경우에는 추정된 고유벡터가 잡음이 많음이 알 려져있다. 이를 해결하기 위해, 부드럽고(smooth) 드문(sparse)한 고유벡터를 추정하는 방법론이 개발 되었다 (Ramsay와 Silverman, 2005; Wang과 Huang, 2016).
본 논문에서는 Wang과 Huang (2016) 논문에서 제안한 제한된 주성분분석(regularized principal com- ponent analysis)을 사용하여 공간정보를 고려하여 주어진 지표면 온도자료에서의 의미있는 기상패턴을 찾고자 한다. 또한, 이렇게 구한 주성분을 이용하여 예측을 위한 주성분 회귀분석(principal component
This work was supported by the Pukyong National University Research Fund in 2016 (C-D-2016-1164) and the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIP) (2014R1A1A3049447).1Department of Statistics, Pukyong National University, 45, Yongso-ro, Nam-gu, Busan 48513, Korea.
E-mail: [email protected]
regression; PCR)을 시행하고자 한다. 주성분 회귀분석은 기존의 설명변수 대신 주성분을 설명변수로 사용하여 회귀분석을 시행하는 것으로, 다중공선성문제와 고차원 문제를 해결하기 위해 사용하는 회귀 분석 방법론이다.
논문의 구성은 다음과 같다. 2장에서는 주성분분석에 대한 기본이론을 소개하고, 3장에서는 이를 발전 시킨 공간자료 분석을 위한 제한된 주성분 분석을 설명하였다. 4장에서는 주성분 회귀분석 방법론에 대 해서 소개하고 5장과 6장에서는 제안된 방법론을 이용하여 시뮬레이션과 실제 자료인 온도자료를 각각 분석하였다.
2. 주성분 분석
관측값 Y
i= (Y
i(s
1), . . . , Y
i(s
p))
′가 p개의 공간, s
1, . . . , s
p∈ D ⊂ R
d에 대해 주어져있을 때, 다음과 같이 관측값을 공간프로세스 모형인 η
i(s) 와 백색노이즈 ϵ
i∼ (0, σ
2Ip×p) 로 이루어졌다고 고려하자.
Yi
= η
i+ ϵ
i, i = 1, . . . , n.
단, 여기서 η
i= (η
i(s
1), . . . , η
i(s
p))
′이다. 이를 주성분분석을 이용하여
Yi
= η
i+ ϵ
i= Φξ
i+ ϵ
i(2.1) 로 표현하고자 한다. 여기서 Φ = (ϕ
1(s), . . . , ϕ
K(s)) 는 p × K인 행렬이며 (j, k)번째 값은 ϕ
jk= ϕ
k(s
j)이다. 또한, ξ
i= (ξ
i1, . . . , ξ
ik)
′는 평균 0의 상관성이 없는 랜덤변수이다. ϕ
k(s)는 서로 수직인 기저함수(basis function)가 되며, K개(K ≪ p)의 ϕ
k(s)으로 자료의 주된 패턴을 설명할 수 있게 된다.
다음의 주성분 분석을 통해 ϕ
k(s)값을 찾을 수 있다. 먼저, 관측치 행렬 Y = (Y
1, . . . , Y
n)
′인 n × p 행렬을 고려하자. 일반성을 잃지 않는 범위 내에서, 우리는 Y 의 평균이 0이라고 가정한다. 다음의 최 소화 수식을 고려해보자.
min
Φ||Y − Y ΦΦ
′||
2L2, under Φ
′Φ = I
K×K. (2.2) 위 수식의 해 Φ는 Y 의 표본공분산 행렬인 S = Y
′Y /n의 처음 K개의 고유벡터이 된다. 또한, 주성분인 ξ
i는 ξ
i= Φ
′Yi로 계산되어 진다.
하지만 앞서 언급한 바와 같이, 표본공분산 행렬은 공간적인 정보를 전혀 고려하지 않은 채 분산을 추정 하게 된다. 또한, 이렇게 구한 기저함수는 p가 n에 비해 매우 큰 경우에는 의미있는 패턴을 알아보기에 잡음이 많음이 알려져있다. 따라서, 다음 장에서 이를보완한 제한된 공간주성분분석을 사용하고자한다.
3. 제한된 공간 주성분분석
Wang 과 Huang (2016)에서 제안한 본 방법론은 아래와 같이 (2.2)에 다음의 패널티 항을 추가하는 것 이다.
arg min
Φ
||Y − Y ΦΦ
′||
2L2+ τ
1∑
K k=1ϕ′k
Ωϕ
k+ τ
2∑
K k=1∑
p j=1|ϕ
jk|. (3.1)
위 수식 또한 기저함수의 정규직교(orthonormal) 가정하에서 구해져야 하며 (Φ
′Φ = I
K), ϕ
′1Sϕ
1≥
ϕ′2Sϕ
2≥ · · · ≥ ϕ
′KSϕ
K의 가정도 만족되어야 한다.
추가된 두 항 중, 첫 번째 항은 ϕ
k의 부드러움성(smoothness)를 보장하는 부분으로 smoothing spline 방법론에서의 roughness penalty 부분과 동일히다. Ω는 p×p행렬로 위치값 s
1, . . . , s
p으로만결정된다.
두 번째 항은 자료의 성김성(sparseness)를 보장하는 부분으로 Tibshirani (1996)의 lasso penalty를 이 용하여 정의된다. τ
1값이 클수록 부드러운 기저함수를 추정할 것이며 반대로 τ
2값이 클수록 성긴 기저 함수를 추정한다. 또한, τ
1, τ
2모두 0이라면, 기존의 주성분분석이 시행된다.
기저함수 추정을 위해 smoothing spline (Green과 Silverman, 1993)을 이용하여 다음과 같이 natural cubic spline 또는 thin-plate spline을 사용하여 기저함수를 정의하였다. s ⊂ R
d인 s = (s
1, . . . , s
d) 에 대해서,
ϕ ˆ
k(s) =
∑
p i=1a
ig ( ||s − s
i||) + b
0+
∑
d j=1b
js
j, subject to E
′a = 0이며, E는 i번째 행이 (1, s
′i) 인 p × (d + 1)행렬이며, a = (a
1, . . . , a
p)
′이다. 또한,
g(r) :=
1
16π r
2log r, if d = 2, Γ(d/2 − 2)
16π
d2r
4−d, if d = 1, 3
로 정의된다. τ
1과 τ
2또한 추정되어야 하는 값인데, 이는 M-fold cross-validation(CV) 방법으로 추정 되었다. 즉, 자료를 M 등분으로 나눈 후, 다음을 최소화 하는 τ
1과 τ
2를 사용하였다.
CV(τ
1, τ
2) = 1 M
∑
M m=1Y
(m)− Y
(m)Φ
(−m)τ1,τ2( Φ
(−m)τ1,τ2)
′2
L2
.
단, 여기서 Y
(m)는 Y 의 M 등분한 자료의 m번째 부분자료이고, Φ
(τ−m)1,τ2는 나머지 자료인 Y
(−m)를 사 용하여 τ
1, τ
2에서 수식 (3.1)를 통해 얻은 추정값이다.
4. 주성분 회귀분석
위에서 정의된 주성분을 이용하여 아래와 같이 주성분 회귀분석을 시행한다. 주성분 회귀분석은 아래의 세 가지 단계로 이루어진다. 설명변수 X와 반응변수 Y 가 주어져 있다고 하자.
1. 주성분분석: n × p 차원의 설명변수 X에 대해 주성분 분석을 시행하여 아래의 주성분(PC) 행렬을 얻는다.
Ξ := b
( ˆ
ξ1, . . . , ˆ
ξn)
T.
단, ˆξ
i= ( ˆ ξ
i,1, . . . , ˆ ξ
i,p)
T이다. 차원축소를 위해 K(K ≪ p)개의 주성분만을 선택하여, n × K의 e Ξ 행렬을 만든다.
2. 회귀분석: 아래와 같이 e Ξ 를 설명변수로 하는 회귀분석 모형을 고려한다. 즉, j에 대해 다음의 회귀 분석에서의 회귀계수 β
0,j, . . . , β
K,j를 구한다.
Y
i,j= β
0,j+ β
1,jζ ˜
i,1+ · · · + β
K,jζ ˜
i,K+ ϵ
i,j, i = 1, . . . , n. (4.1)
단, ˜ζ
i,k는 e Ξ 행렬의 (i, k) 위치의 값이다. 이를 모든 j (j = 1, . . . , p)에 대해 시행한다.
3. 예측: n + 1시점에서의 예측값을 얻기 위해, 다음의 회귀모형 예측값을 구한다. 여기서 ˆ β
0,j, . . . , β ˆ
K,j값은 위의 회귀모형에서 얻어진 회귀계수값이다.
Y ˆ
n+1,j= ˆ β
0,j+ ˆ β
1,jζ ˜
n+1,1+ · · · + ˆ β
K,jζ ˜
n+1,K. (4.2) 단, 설명변수 ˜ξ
n+1= ( ˆ ξ
n+1,1, . . . , ˆ ξ
n+1,K)
T는 새로운 값 x
n+1에 대해 주성분 분석을 시행하여 얻은 주성분값이다.
5. 시뮬레이션 자료 분석
기존의 주성분 분석과 제한된 공간 주성분 분석의 성능을 비교하기 위해, 먼저 간단한 시뮬레이션을 실 행하였다. 수식 (2.1)에 따라서 K = 2일 때, p = 50개의 공간 s
1, . . . , s
p⊂ D, D = [−5, 5]에 대해서 다음과 같이 Φ를 정의하였다.
ϕ
1(s) = 1 c
1ln ( s
2)
, ϕ
2(s) = 1
c
2x ln ( s
2)
,
여기서 c
1과 c
2는 ||ϕ
1||
2= ||ϕ
2||
2= 1 이 되게 하는 상수이다. 또한, ξ
i∼ N(0, diag(9, 4))로 생성하고,
ϵi∼ N(0, I)에 대해서 다음과 같이 데이터 Y 를 만들었다.
Yi
= Φξ
i+ ϵ
i, i = 1, . . . , n.
단, n = 100으로 두었다.
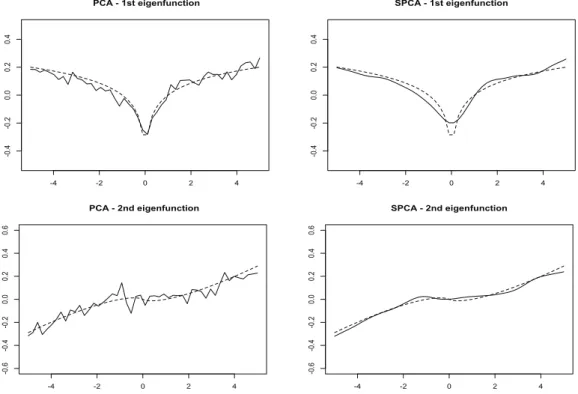
이렇게 생성한 자료에 대해서 기존의 주성분 분석과 제한된 공간 주성분 분석을 K = 1, 2에 대해 적용 한 결과가 Figure 5.1과 5.2에 각각 나와있다. 실제 참 값 ϕ
1( ·)과 두 주성분 분석 방법론을 통해 얻은 ϕ ˆ
1(·)을 비교함으로써, 제한된 공간 주성분 분석을 통해 얻은 ˆϕ
1(·)값이 참 값에 가까움을 알 수 있었다.
마찬가지로, K = 2일 때도 같은 결론을 얻을 수 있었다.
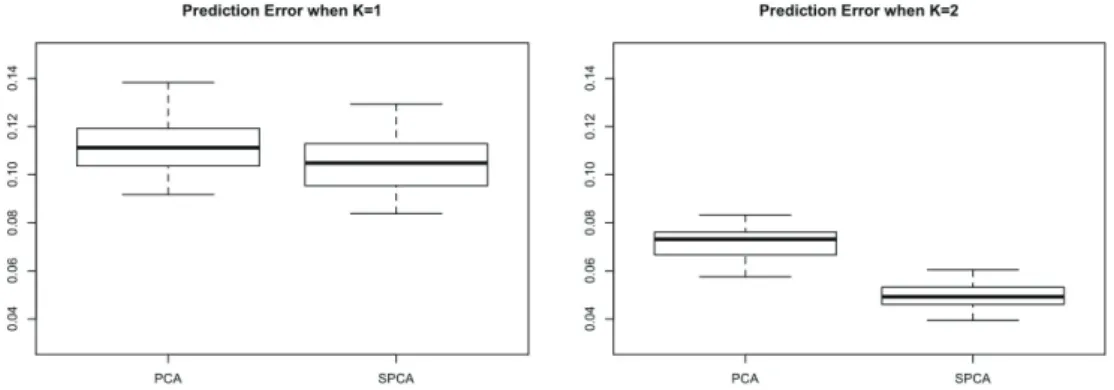
수치적 비교를 위해, 이를 500번 반복하여 아래와 같이 예측오차를 계산하였다.
Loss = 1 n
∑
n i=1Φξ
i− ˆ Φˆ
ξi2
단, 주성분 예측값인 ˆξ
i는 ˆξ
i= ˆ Φ
′Yi로 계산되어진다. 결과에 따른 상자그림이 Figure 5.3에 나와있으 며, K = 1과 K = 2인 경우 모두 제한된 공간 주성분 분석이 작은 예측오차값을 줌을 알 수 있었다.
6. 기상자료 분석
대순환모델(general circulation model; GCM)이란 기후계 구성요소들의 물리적,화 학적, 생물학적 특
성, 구성요소 간의 상호작용 과정 등을 고려하여 기후계를 수치로 표시한 것을 의미한다. GCM을 통한
기후예측은 계절예측에 뛰어남이 알려져 있지만, 이를 보다 향상시키기 위해서 통계적 모형을 함께 고
려하는 model output statistics(MOS)라는 방법이 사용되어 왔다 (Wilks, 2011). MOS는 시점 T 까지
의 GCM 예측값 {X
t}
Tt=1와 실제 관측 기후값 {Y
t}
Tt=1을 사용하여 그 관계를 통계적 모델링을 통해 구
축한 후, 새로운 시점인 T + 1에서의 기후값인 Y
T +1을 구축된 통계적 모델에 GCM 예측값인 X
T +1을
input 값으로 사용하여 예측하는 것이다 (Figure 6.1). 본 논문에서는 MOS에서 필요한 통계적 모델링
을 주성분 분석 기반의 회귀분석으로 한 것이다.
-4 -2 0 2 4
-0.4-0.20.00.20.4
PCA - 1st eigenfunction
-4 -2 0 2 4
-0.4-0.20.00.20.4
SPCA - 1st eigenfunction
Figure 5.1. True ϕ1(·) (dashed line) and the estimated function ˆϕ1(·) from PCA and SPCA (solid lines). PCA
= principal component analysis; SPCA = sparse principal component analysis.
-4 -2 0 2 4
-0.4-0.20.00.20.4
PCA - 1st eigenfunction
-4 -2 0 2 4
-0.4-0.20.00.20.4
SPCA - 1st eigenfunction
-4 -2 0 2 4
-0.6-0.4-0.20.00.20.40.6
PCA - 2nd eigenfunction
-4 -2 0 2 4
-0.6-0.4-0.20.00.20.40.6
SPCA - 2nd eigenfunction
Figure 5.2. True ϕ1(·) and ϕ2(·) (dashed line) and the estimated functions ˆϕ1(·) and ˆϕ2(·) from PCA and SPCA (solid lines). PCA = principal component analysis; SPCA = sparse principal component analysis.
6.1. 자료설명
• GCM 자료
본 논문에서는 온도 예측을 위해, GCM 예측값을 설명변수 X로 사용하였다. GCM 값은 기상
청(Korea meteorological administration; KMA)에서 제공하는 global data assimilation and pre-
diction system(GDAPS) 자료를 사용하였고, 1983년부터 2002년까지의 월별 20년의 자료를 사용하
Figure 5.3. Boxplots of averaged prediction errors for PCA and SPCA based on 500 simulation replicates. PCA
= principal component analysis; SPCA = sparse principal component analysis.
Figure 6.1. Model output statistics (MOS).
였다. 계절예측을 위해 월별 자료 중, 6, 7, 8월 자료의 평균값을 년마다 구하여 총 n = 20개의 관측 값을 사용하였다. 자료는 전 지구를 2.5
◦× 2.5
◦간격으로 나누어 총 144 × 73 격자점에 대해서 관측 이 되었고, GCM의 여러 예측값 중에서 지표면 온도(ground temperature; Ts)를 사용하였다.
또한, 제한된 공간 주성분 분석의 효용성을 확인하기 위해, GCM 자료에 Gaussian noise N(0, σ
2), σ
2= 1
2, 3
2, 5
2를 추가하였다. 이를 통해 잡음이 섞인 자료에서 주성분 분석 방법론의 성과를 비교하고 자 하였다.
빠른 계산을 위하여 144 × 73 격자점 중 랜덤하게 선출한 1, 000개의 격자점 자료를 사용하였고, 이 에 따라 n = 20년, p = 1, 000 격자점으로 설명변수를 정의하였다. 즉, 설명변수는 20 × 100의 X 행 렬이며, 주성분 분석의 결과로 얻은 K = 4개의 주성분만을 사용하여 회귀분석을 시행하였다.
• 관측 온도 자료
실제로 관측된 지표면 온도 자료는 영국에서 제공하는 climatic research unit(CRU) 자료를 사용하 였다. 본 자료 또한 1983년부터 2002년까지의 월별 자료이며 여름자료만 사용하였고, 144 × 73 격 자점에서 관측된 자료이다. 마찬가지로 계산의 편리를 위해 p = 1, 000개의 격자점에 대해서만 분석 하였으며, 따라서 Y 는 20 × 1000의 행렬이 된다.
• 동아시아 지역 예측
지역적 예측을 위하여, 27.5
◦–47.5
◦N 과 93.15
◦–153.57
◦W 의 189개의 격자점에 해당하는 동아시아지 역에 대해서 결과를 정리하였다.
6.2. 분석 모형
4 장에서 설명한 바와 같이, 주성분 회귀분석은 아래와 과정을 통해 시행되었다.
1. 주성분분석: 20 × 1000 차원의 설명변수 X에 대해 주성분 분석을 시행하여 아래의 주성분(PC) 행 렬을 얻는다.
Ξ := b
( ˆ
ξ1, . . . , ˆ
ξn)
T.
차원축소를 위해 4개의 주성분만을 선택하여, 20 × 4의 e Ξ 행렬을 만든다.
2. 회귀분석: 아래와 같이 e Ξ를 설명변수로 하는 회귀분석 모형을 고려한다. 즉, j = 1, . . . , 1000에 대 해 다음의 회귀분석에서의 회귀계수 β
0,j, . . . , β
4,j를 구한다.
Y
i,j= β
0,j+ β
1,jζ ˜
i,1+ · · · + β
K,jζ ˜
i,4+ ϵ
i,j, i = 1, . . . , 20.
단, ˜ζ
i,k는 e Ξ 행렬의 (i, k) 위치의 값이다.
3. 예측: 2003년 여름 (i = 21) 시점에서의 예측값을 얻기 위해, 다음의 회귀모형 예측값을 구한다. 여 기서 ˆ β
0,j, . . . , ˆ β
4,j값은 위의 회귀모형에서 얻어진 회귀계수값이다.
Y ˆ
21,j= ˆ β
0,j+ ˆ β
1,jζ ˜
n+1,1+ · · · + ˆ β
4,jζ ˜
n+1,4, j = 1, . . . , 1000. (6.1) 단, 설명변수 ˜ξ
21= ( ˆ ξ
21,1, . . . , ˆ ξ
21,4)
T는 새로운 GCM값 x
21에 대해 주성분 분석을 시행하여 얻은 주성분값이다.
예측력을 확인하기 위해서는 참 값인 Y
21,j와의 비교가 필요하지만, 주어진 자료는 i = 1, . . . , 20의 관측 치 뿐이므로 자료를 충분히 활용하기 위해 우리는 leave-one-out cross validation을 사용하였다. 즉, 주 어진 20 × 1000차원의 X에서 i = n
∗일 때의 자료를 제거한 후, 위의 주성분 회귀분석에서의 1, 2 단계 를 시행한다. 그리고 3 단계인 예측단계에서 제외했던 i = n
∗값을 새로운 값으로 사용하여 ˆ Y
n∗,j를 예 측하였다. 이 과정을 i = 1, . . . , 20에 대해서 반복하였다.
6.3. 결과
주성분 회귀분석을 진행하기 앞서, 주어진 설명변수 X에 대해서 주성분 분석을 시행하였다. 논문에서 는 Gaussian noise의 분산 σ
2= 1 일 때의 결과만 표시하였다. 기존의 주성분분석을 통해 얻은 주성분 4 개의 동아시아 지역의 결과가 순서대로 Figure 6.2에 그려져있고, 마찬가지로 제한된 공간 주성분을 사 용한 주성분 결과는 Figure 6.3에 나와있다. 제한된 공간 주성분에서 실제 사용된 τ
1과 τ
2값은 앞서 설 명된 바와 같이 5-fold CV로 구하였으며 그 값들의 평균은 각각 11, 143.77과 10.60이었다. 즉, 상대적 으로 성김성보다는 부드러움성에 더 고려하여 해를 구하고 있음을 알 수 있었다.
두 방법론의 결과를 비교해보면, Gaussian noise를 추가하였음에도 불구하고 제한된 공간 주성분을 통 해 얻은 주성분은 부드러운 등고선형태를 보임을 알 수 있다. 반면에 기존 주성분은 noisy한 결과를 줌 을 알 수 있었다.
주성분 회귀분석을 시행한 결과는 Figure 6.4에 예측오차를 통해 확인할 수 있다. 각 방법론에 의해 얻 어진 예측값 ˆ Y
i,j에 대해 동아시아 지역에 해당하는 격자점에 대해서 평균을 낸 ˆ Y
i,·(i = 1, . . . , 20)을 구 한 후, Error
i= (Y
i,·− ˆ Y
i,·)
2값을 막대그림으로 표현하였다. 그 결과, 대부분의 시점에서 제한적 주성 분분석을 통한 예측값이 상대적으로 작은 오차값을 보였다.
공간적인 패턴에 대한 수치적 평가도 시행하였는데, 이를 위해 주어진 20년도를 다음과 같이 3개의 그
룹으로 나누었다: El-Nino (1987, 1991, 1992, 1994, 1997, 2002), Neutral (1983, 1984, 1986, 1989,
1990, 1993, 1995, 1996, 2000, 2001), La-Nina years (1985, 1988, 1998, 1999) -on the basis of a
100 110 120 130 140
30354045
0.00 0.05 0.10
100 110 120 130 140
30354045
-0.10 -0.05 0.00 0.05
100 110 120 130 140
30354045
-0.10 -0.05 0.00 0.05
100 110 120 130 140
30354045
-0.05 0.00 0.05
Figure 6.2. Four principal components from conventional principal component analysis method applied to data matrix X added σ2= 1 gaussian noise.
100 110 120 130 140
30354045
-0.14 -0.12 -0.10 -0.08 -0.06 -0.04 -0.02 0.00
100 110 120 130 140
30354045
-0.15 -0.10 -0.05 0.00 0.05 0.10
100 110 120 130 140
30354045
-0.10 -0.05 0.00 0.05 0.10 0.15 0.20
100 110 120 130 140
30354045
-0.10 -0.05 0.00 0.05 0.10 0.15
Figure 6.3. Four principal components from sparse principal component analysis method applied to data matrix X added σ2= 1 gaussian noise.
threshold of +/ − 0.5
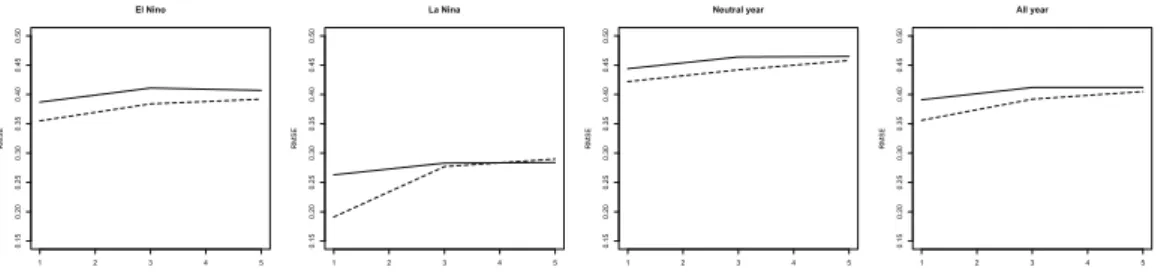
◦C for the Oceanic Nino 3.4 index(ONI) (Huang 등, 2015). 이렇게 나누어진 해 당 그룹에서의 실제 온도값과 예측값 간의 오차인 root mean squared error(RMSE)를 다음과 같이 구 하였다.
RMSE (
Y , ˆY
)
= v u u t 1
189
∑
189 j=1(
Y
·,j− ˆ Y
·,j)
2,
여기서 Y
·,j는 j번째 동아시아 지역 격자점에서의 실제 관측 온도의 20년 평균값이며, ˆ Y
·,j는 주성분 분
석을 통해 얻은 예측값이다. 그 결과가 Table 6.1과 Figure 6.5에 나와있다. 다양한 noise 분산 σ
2=
PCA SPCA
time(1983~2002) Error 0.00.10.20.30.40.50.60.7
Figure 6.4. Squared prediction errors from PCA and SPCA methods applied to data X added σ2= 1 gaussian noise. PCA = principal component analysis; SPCA = sparse principal component analysis.
Table 6.1. Root mean squared error values and their standard errors in parenthesis from PCA and SPCA methods applied to data X added σ2= 1 gaussian noise.
PCA SPCA
El Nino 0.383(0.099) 0.341(0.168)
La Nina 0.274(0.172) 0.227(0.165)
Neutral year 0.445(0.292) 0.352(0.235)
All year 0.392(0.228) 0.324(0.201)
PCA = principal component analysis; SPCA = sparse principal component analysis.
1 2 3 4 5
0.150.200.250.300.350.400.450.50
El Nino
Sigma
RMSE
1 2 3 4 5
0.150.200.250.300.350.400.450.50
La Nina
Sigma
RMSE
1 2 3 4 5
0.150.200.250.300.350.400.450.50
Neutral year
Sigma
RMSE
1 2 3 4 5
0.150.200.250.300.350.400.450.50
All year
Sigma
RMSE
Figure 6.5. RMSE values from principal component analysis (solid line) and sparse principal component analysis (dashed line) for various gaussian noise levels. RMSE = root mean squared error.
1
2, 3
2, 5
2에 대해, 모든 그룹화된 연도에서 제한된 공간 주성분 분석의 RMSE값이 대체적으로 기존의 주성분 분석 방법론에 비해 낮게 나타났으며, 특히 noise의 분산이 작은 경우에 그 차이가 컸다. 표준오 차를 고려하면 유의한 정도의 차이라고 보기에는 무리가 있지만 기존의 방법론보다는 예측의 정확성을 높인다고 할 수 있겠다.
마지막으로, 주성분 회귀분석에서 GCM 온도예측값인 X뿐만 아니라 추가적인 기후정보(강수량, 풍속,
. . .) 를 설명변수로 추가한다면 조금 더 예측력을 높일 수 있을 것으로 기대된다.
References
Demˇsar, U., Harris, P., Brunsdon, C., Fotheringham, A. S., and McLoone, S. (2013). Principal component analysis on spatial data: an overview, Annals of the Association of American Geographers, 103, 106–
128.
Green, P. J. and Silverman, B. W. (1993). Nonparametric Regression and Generalized Linear Models: a Roughness Penalty Approach, CRC Press, Boca Raton, FL.
Huang, B., Banzon, V. F., Freeman, E., Lawrimore, J., Liu, W., Peterson, T. C., Smith, T. M., Thorne, P. W., Woodruff, S. D., and Zhang, H. M. (2015). Extended reconstructed sea surface temperature version 4 (ERSST. v4), part I: upgrades and intercomparisons, Journal of Climate, 28, 911–930.
Ramsay, J. O., and Silverman, B. W. (2005). Functional Data Analysis (pp. 173–185), Springer, New York.
Shen, H. and Huang, J. Z. (2008). Sparse principal component analysis via regularized low rank matrix approximation, Journal of Multivariate Analysis, 99, 1015–1034.
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society Series B (Methodological), 58, 267–288.
Wang, W. T. and Huang, H. C. (2016). Regularized principal component analysis for spatial data, Journal of Computational and Graphical Statistics, Available from: http://dx.doi.org/10.1080/10618600.2016.115 7483
Wilks, D. S. (2011). Statistical Methods in the Atmospheric Sciences (Vol. 100), Academic Press, Oxford.
공간자료 주성분분석
임예지
a,1a
부경대학교 통계학과
(2016년 11월 23일 접수, 2017년 1월 11일 수정, 2017년 2월 4일 채택)
요 약
주성분 분석은 통계학 뿐만 아니라 기상학에서 널리 사용되는 방법론이며, 고차원 자료에 대한 차원축소 역할 뿐만 아니라 기상자료에서의 의미있는 패턴을 찾아내기 위해 사용되는 방법론이다. 또한 주성분분석에 기반을 둔 주성 분 회귀분석 방법론은 기후예측이 가능하므로 미래 시점의 기후값 예측에 사용될 수 있다. 본 논문에서는 Wang과 Huang (2016)논문에서 제안한 제한된 공간 주성분 분석을 기반으로 한 주성분 회귀분석 방법론을 개발하였다. 이 를 시뮬레이션을 통하여 확인하였고, 실제 자료인 동아시아 지역 온도예측에 적용하여 기존의 주성분 회귀분석 예측 값에 비해 예측력이 높아짐을 확인하였다.
주요용어: 주성분 분석, 공간자료, 경험적 직교 함수, 온도 예측, 주성분 회귀분석
이 논문은 2016학년도 부경대학교의 지원을 받아 수행된 연구이며 (C-D-2016-1164), 2014년도 정부(미래창조 과학부)의 재원으로 한국연구재단의 지원을 받아 수행된 연구임(NRF-2014R1A1A3049447).
1(48513)부산광역시 남구 용소로 45, 부경대학교 통계학과. E-mail: [email protected]