Analysis of the Yearbook from the Korea
Meteorological Administration using a text-mining agorithm
Hyunseok Sun
a· Changwon Lim
a· YungSeop Lee
b,1a
Department of Applied Statistics, Chung-Ang University;
b
Department of Statistics, Dongguk University
(Received June 19, 2017; Revised July 7, 2017; Accepted July 10, 2017)
Abstract
Many people have recently posted about personal interests on social media. The development of the Internet and computer technology has enabled the storage of digital forms of documents that has resulted in an explosion of the amount of textual data generated; subsequently there is an increased demand for technology to create valuable information from a large number of documents. A text mining technique is often used since text-based data is mostly composed of unstructured forms that are not suitable for the application of statistical analysis or data mining techniques. This study analyzed the Meteorological Yearbook data of the Korea Meteorological Administration (KMA) with a text mining technique. First, a term dictionary was constructed through preprocessing and a term-document matrix was generated. This term dictionary was then used to calculate the annual frequency of term, and observe the change in relative frequency for frequently appearing words. We also used regression analysis to identify terms with increasing and decreasing trends. We analyzed the trends in the Meteorological Yearbook of the KMA and analyzed trends of weather related news, weather status, and status of work trends that the KMA focused on. This study is to provide useful information that can help analyze and improve the meteorological services and reflect meteorological policy.
Keywords: text-mining, unstructured format, the Korea Meteorological Administration, word cloud
1. 서론
최근 IT 기술의 발달과 스마트폰 사용이 늘어나면서 웹상에는 이미지, 영상, 텍스트 등 방대한 양의 자 료가 유통되고 있다. 이러한 자료들의 특징은 특정 형식을 취하지 않은 비정형적인 자료(unstructured data) 구조를 갖고 있다. 그 중에서도 텍스트로 이루어진 자료를 통해 새로운 의미를 찾아내기 위한 방 법으로 텍스트 마이닝을 이용한 빅데이터 분석에 대한 수요가 증가하고 있다 (Lim과 Kim, 2016). 텍스
This work was funded by the Korea Meteorological Administration Research and Development Program under Grant KMIPA 2015-1110.1Corresponding author: Department of Statistics, Dongguk University-Seoul, 30, Pildong-ro, 1-gil, Jung-gu, Seoul 04620, Korea. E-mail: [email protected]
트 마이닝은 머신러닝, 통계학 등의 여러 분야의 방법을 이용하여 단순한 단어의 검색이 아닌 비정형 자 료의 분석을 통해 새로운 정보를 창출하는 기법이다 (Gupta와 Lehal, 2009).
텍스트 마이닝은 다양한 분야에서 사용되고 있다. 의학통계 분야에서는 질병의 원인과 치료를 위한 분 석을 위하여 텍스트 마이닝을 사용하여 왔고 가장 텍스트 마이닝이 발전한 분야 중 하나이다 (Chen 등, 2016). Kam 과 Song (2012)은 신문 기사의 분석을 통해 주요 신문사들 간의 논조의 차이를 비교하기도 했다. 금융 쪽에서는 Ahn과 Cho (2010)이 뉴스에 대한 텍스트 마이닝을 통해 뉴스가 주가 상승에 미치 는 영향을 분석하는 모형을 제시하기도 했다. 이와 같이 텍스트 마이닝은 다양한 분야에서 사용 되고 있 고 기상청 업무에 대한 분석에 역시 적용할 수 있다. 예를 들어, Lee 등 (2016)은 기상콜센터의 전화 상 담내용을 기록한 텍스트 자료를 이용하여 상담 내용의 월별 특징과 시간대별 특징 등을 분석하였다.
본 연구는 텍스트 마이닝을 통해 기상청이 발행한 기상연감을 분석하여 기상과 관련된 키워드의 연도 별 변화를 파악하는 비교 분석을 다룬다. 기상청의 업무 중점, 기상 예보 및 현황이 어떻게 바뀌어 왔 는지를 분석하였다. 이를 위해 먼저 전처리 과정을 통하여 용어사전을 구축하고, 용어-문서 행렬(term- document matrix) 을 생성하였다. 그리고 이것을 사용하여 연도별 용어 빈도수를 계산하고, 자주 나타 나는 단어들에 대하여 상대도수의 변화를 관찰하였다. 또한 회귀 분석 기법을 사용하여 증가추세와 감 소추세를 보이는 용어들을 파악하였다. 이러한 분석으로 기상청 기상연감 문서에서의 트렌드를 파악하 고, 이를 통해 이슈가 되었던 기상 관련 소식과 기상현황, 그리고 기상청이 중점으로 하고 있는 업무 현 황의 트렌드를 파악하였다. 본 연구를 통해 기상업무 분석 및 효율화에 도움을 주고 기상정책에 반영할 수 있는 유용한 정보를 이끌어내고자 하였다.
본 논문은 총 4장으로 구성되어 있다. 2장에서는 본 연구에서 사용한 자료에 대한 설명과 분석 방법에 대해 서술하였고, 텍스트 마이닝 분석을 위한 준비 단계인 전처리 과정이 어떻게 이루어졌는지에 대해 설명하였다. 3장에서는 텍스트 마이닝을 통한 기술 통계 분석 결과를 바탕으로 각 분석에서 사용한 텍 스트 별로 결과를 제시하였다. 마지막으로 4장에서는 본 논문을 종합적으로 정리하였고 추후의 연구 주 제에 대하여 논하였다.
2. 자료 설명 및 분석 방법
2.1. 자료 설명
본 연구에서 사용된 자료는 2004년부터 2015년까지 기상청에서 제공하는 총 12개년의 기상연감 텍스트 자료이다. 기상연감 텍스트 자료는 해당연도의 기상과 관련한 소식을 기록한 보고서로, 구성은 10대 주 요뉴스, 1부 총설, 2부 국내외 동향, 3부 분야별 업무활동으로 총 4개 분야로 구성되어있다. 본 연구의 목적은 기상과 관련된 키워드의 변화를 파악하고, 기상업무에서의 중점사항을 파악하기 위함으로 본 연 구에서 사용된 텍스트는 2004년부터 2015년까지의 기상연감 10대 주요뉴스와 1부 총설이다.
10 대 주요뉴스에는 기상연감 서론 등장 전에 해당연도에 이슈가 되었던 10개의 기상 관련 소식이 기록
되어있다. 1부 총설에서는 기상업무 추진개요, 기상업무 변화관리 추진현황 등 매해 기상청 업무에 대
해 서술한 부분과 해당연도의 기상현상을 기록한 부분으로 이루어져있다. 총설에서 “기상업무 추진개
요”와 “기상업무 변화관리 추진현황” 등 기상청 업무를 서술해 놓은 부분을 업무현황이라 구분하고, 기
상현상을 서술한 부분을 기상현황으로 구분하여 분석을 진행하였다. 업무현황과 기상현황으로 항목을
나눈 이유는 각 항목에 기록된 텍스트의 주제와 성격이 다르기 때문이다. 기상현황은 한 해의 기온, 강
수량 등을 기록한 “기상현황 개요”와 겨울철, 봄철, 여름철, 가을철 기상을 기록한 “계절별 특징”, 마지
막으로 해당연도에 발생했던 대설, 황사, 장마, 태풍 같은 특정 기상현상에 대해서 기록한 “주요기상현
상”으로 이루어져있다. 2007년 이후의 기상연감에서는 주요기상현상 항목이 기상현황 개요 부분에 포
함되어 기록되어있다.
2.2. 분석 수행 절차
본 연구에서는 연도별 기상연감을 10대주요뉴스, 업무현황, 기상현황으로 나누어 각 항목에 대하여 각 각 분석을 진행하였다. 텍스트 마이닝 기법을 이용하여 보다 더 정확한 분석과 의미 있는 결론을 도출하 기 위해서는 추출한 단어가 텍스트 내에서 단어의 쓰임에 맞게 추출되었는지 확인하는 과정이 필요하다.
이 과정에 따라 분석의 토대가 되는 단어 추출 결과가 달라지기 때문에 전처리 과정에서 사전구축과 띄 어쓰기 수정 및 용어 통일 과정이 필수적이다. 사전을 구축하기 위해 기상연감에서 등장하는 단어들 중 에서 오픈소스로 제공되는 NIA사전이나 세종사전에 등록되지 않은 단어들을 찾아서 사전을 만든 후 원 래의 사전과 함께 분석에 사용하였다. 분석을 진행하기 위한 전처리 작업의 자세한 설명은 뒤의 전처리 과정 부분에 기술하였다.
전처리 과정 이후 통계 프로그램인 R (R Core Team, 2016)에서 한나눔 형태소 분석기를 바탕으 로 형태소 분석을 구현해 놓은 패키지인 KoNLP (Jeon, 2016)를 활용하여 사전에 등록된 단어를 태 깅(tagging)된 품사에 따라 단어를 추출하였다. 이후 추출한 단어를 tm 패키지 (Feinerer와 Hornik, 2015) 를 이용하여 말뭉치(corpus)로 만들고 분석에 쓰이지 않을 단어를 제거하였다. 정제된 말뭉치를 기반으로 용어-문서 행렬을 만들어 연도별 빈도표를 작성하고 이를 이용하여 연도별 용어의 출현빈도를 파악하였다. 이 과정에서 분석 결과를 효과적으로 나타내기 위하여 연도별 단어 빈도표를 바탕으로 워 드 클라우드를 구현하여 분석 결과를 시각화하였다. 워드 클라우드는 문서에 사용된 단어의 빈도를 시 각적으로 표현한 방법이다. 단어들을 구름모양으로 나타내어 빈도가 높고 핵심어일수록 큰 글씨로 중심 부에 표현한다. 이후 구체적인 수치를 통해 연도별 단어의 흐름을 파악하였다. 특정 단어가 출현한 횟 수를 연도별로 비교하기 위하여 연도별로 단어가 출현한 절대도수가 아닌 상대도수를 계산하여 분석하 였다. 특정 단어의 각 연도별 출현 횟수와 해당연도에 나타난 총 단어의 출현횟수 합계를 이용하여 단어 들의 연도별 상대도수를 구하고 연도별 상대도수 그래프를 그려서 분석 결과를 나타내었다.
분석 결과를 살펴보았을 때 본 연구에서 사용한 텍스트 성격 상 서술성 명사가 높은 빈도로 등장하였고 종류도 다양하게 나타났다. 보통명사에서는 서술성 명사와 비서술성 명사로 품사가 구분되어 있는데, 서술성 명사는 기능동사와 결합하여 문장 내에서 서술적 기능을 갖는 명사를 뜻한다. 예를 들어, “수 행”, “개발” 같은 단어는 명사의 형태이지만 문장 내에서 “-하다”와 같은 기능동사와 결합하여 서술성 기능을 갖는다 (KAIST Semantic Web Research Center, 2011). 기상연감 자료에서 단어들을 추출하 였을 때 서술성 명사의 빈도와 종류가 많았기 때문에 이 단어들에 의하여 기상과 관련된 키워드가 빈도 표에서 하위에 있었고 워드 클라우드를 통해 시각화하였을 때 등장하지 않았다. 따라서 본 연구의 목적 인 기상 관련 핵심 키워드의 변화를 살피기 위해 분석에서 서술성 명사는 제외하였다. 추가적으로 증가 추세 또는 감소추세가 있는 단어를 파악하기 위해 각 단어마다 연도를 설명변수로 하고 상대도수를 반응 변수로 한 회귀분석 기법을 적용하여 결정계수가 0.5이상인 단어를 추려내고 그 중 회귀계수가 0보다 큰 단어와 0보다 작은 단어를 파악하였다.
2.3. 전처리 과정
텍스트 마이닝을 이용하여보다 더 정확한 분석과 의미 있는 결론을 도출하기 위해서는 추출한 단어가 텍
스트 내에서 의미하는 단어로 추출될 수 있도록 자료를 정제하는 것이 중요하다. 영어권의 경우에는 자
연어 처리 기술에 대한 연구가 많이 진행되어 왔고 영어의 특성상 형태소 분석 알고리즘을 적용하기에
더 적합하기 때문에 어간(stemming word)추출과 같이 전처리 알고리즘이 높은 수준으로 구현되어 있
다. 하지만 한글로 이루어진 텍스트인 경우, 한글 어순의 복잡한 구조적 특성으로 인하여 한글 자연어 처리 기술이 영어에 비해 미흡한 상태이다. 따라서 한글 텍스트인 경우 전처리 과정에 많은 시간이 소요 되고 이 작업의 수행 정도에 따라서 분석 결과의 방향과 의미가 달라질 수 있다. 우선 tm패키지를 이용 하여 텍스트 내의 구두점, 공백 등 결과 해석에서 의미가 없는 자료를 제거하였다. 이후 실제로는 같은 뜻을 의미하지만 다른 형태의 단어로 쓰여 진 경우, 용어를 통일하여 그 의미를 분석에 담을 수 있도록 용어를 수정하는 과정을 수행하였다. 예를 들어, “한국기상청”과 “우리나라기상청” 라는 두 단어는 실 제로 의미하는 것은 같지만, 키워드를 추출한 결과로 보면 두 단어의 빈도는 나누어지기 때문에 정확한 결론을 내기 위해서는 서로 같은 의미를 갖는 단어로 통일하여야 한다.
띄어쓰기 사용에 따라서도 추출하는 단어가 달라지기 때문에 단어의 의미에 따라 띄어쓰기를 수정하는 작업이 필요하다. 예를 들어, “기후 변화”라는 단어에 대해 형태소 분석기에 따라 명사를 추출할 경우, 기본적으로 띄어쓰기 단위로 형태소를 구분하기 때문에 “기후”와 “변화”가 따로 추출될 것이다. 따라서
“기후 변화”를 “기후변화”로 수정하여서 추출 시 “기후변화”로 빈도가 카운트 될 수 있도록 하는 작업이 필요하다.
이 과정을 수행하기 위하여 텍스트 자료를 말뭉치로 변환된 결과를 원래의 자료와 비교하여 분석의 목적 에 맞게 단어가 추출되었는지를 확인하였다. 본 연구의 목적은 의미있는 분석 결과를 토대로 기상정책 에 활용할 수 있는 방안을 제시함이므로 위에서 말한 작업을 반복하여 추출된 단어가 텍스트의 내용을 이해할 수 있을 만큼의 정보를 제공하도록 하였다.
마지막으로 추출할 단어들이 사전에 탑재되어야 정확한 형태로 추출될 수 있기 때문에 텍스트 내 단어들 을 사전에 추가하여야 한다. 예를 들어 “세계기상기구”가 사전에 등록되어있지 않다면, “세계”, “기상”,
“기구”와 같이 사전에 등록되어있는 단어들을 바탕으로 추출될 것이다. 따라서 텍스트의 단어들을 많이 포함할 수 있는 사전을 업데이트 하는 과정이 필요하다. 본 연구에서 사용한 사전은 국립국어원에서 제 공하는 세종사전(8만개), 한국정보화진흥원에서 제공하는 NIA사전(93만개), 본 연구진이 선행 연구에 서 한국기상학회에서 제공한 대기과학용어집에 나온 단어들로 구축한 사전(2만개)이다. 추가적으로 기 상연감과 한국기상산업진흥원 최종보고서에 등장하는 기상 관련 용어 6,552개를 사전에 업데이트하여 분석을 진행하였다.
3. 분석 결과
3.1. 10대 주요 뉴스
10 대 주요뉴스를 분석한 결과, 2009년과 2010년을 제외하고 매년 “기상청”이 빈도가 가장 높게 나타났 다. 2004년부터 2015년까지의 단어별 빈도 합계를 살펴본 결과 “기상청”이 출현 빈도 203회로 1위였 고 상위 20위까지의 단어를 살펴본 결과 서술성 명사가 차지하는 비중이 높게 나타났다. 상위 5개 단어 는 “기상청”, “발생”, “제공”, “운영”, “태풍”이었고 이 단어들의 연도별 상대도수 그래프로 그린 그림 은 Figure 3.1 과 같다. 본 연구의 목적은 연도별로 주요 키워드의 변화를 살피기 위함이기 때문에 분 석 결과에서 높은 비중을 차지하는 서술성 명사와 매해 가장 높게 나타난 “기상청”을 제외하고 워드 클 라우드를 그린 결과는 Figure 3.2이고 이를 통해서 전체적인 단어의 분포를 파악하였다. 워드 클라우드 를 통해 분석 결과를 보았을 때, “국민”, “예보”, “우리나라”가 전체적으로 높은 빈도로 나타났고 “태풍”
과 “지진”은 특정 연도에만 빈도가 가장 높게 나타났다는 것을 알 수 있다.
특히 태풍 피해가 가장 컸던 2010년 자료에 “태풍”의 빈도가 가장 높게 나타났고, 서해안 지진이 발생한 2013 년에 “지진”이 빈도수 1위로 나타났다. 이를 통해 전체적으로 이슈가 되었던 기상과 관련된 뉴스는
“국민”과 “예보”에 초점이 맞춰져 있음을 알 수 있었고, “태풍”과 “지진” 같은 피해규모가 큰 기상재해
Figure 3.1. Top5 word relative frequency in“10대 주요 뉴스”.
Figure 3.2. Wordcloud by year in“10대 주요 뉴스”.
는 발생연도에 이슈화가 민감하게 일어남을 알 수 있다. 또한 연도별로 “예보”와 관련한 키워드의 변화 를 살펴보면, 2005년 “디지털예보”, 2008년 “동네예보”, 2010년 “초단기예보”, 2014년 “미세먼지예보”
와 “중기예보”가 등장하였고 이를 통해 예보의 성격과 시스템의 변화를 확인할 수 있다. 마지막으로 “기 후변화”는 2008년부터 등장하기 시작하여 2015년까지 높은 빈도로 등장한 것으로 보아, 세계적으로 이 슈화되고 있는 기후변화 문제에 대해 우리나라도 기후변화 대응을 위한 정책과 연구를 진행하고 있음을 알 수 있다.
워드 클라우드를 통해 전체적인 단어의 분포를 파악한 뒤, 2013년부터 2015년까지 처음 등장한 단어를
추출하여 최근 이슈화되고 있는 기상소식에 대해 살펴보았다. 살펴볼만한 점은 2015년 “엘니뇨”의 출현
빈도가 이전에 나타나지 않다가 2015년 엘니뇨현상 발생시점에 출현 빈도가 급증하였다. 이를 통해 이
후에도 엘니뇨현상 발생 시 관심이 많아질 가능성이 크다는 예측을 할 수 있다. 또한 2014년 세월호 사
Figure 3.3. Top5 word relative frequency in“업무현황”.
Figure 3.4. Wordcloud by year in“업무현황”.
고, 2015년 영종대교 추돌사고와 관련된 단어들인 “세월호”, “안개”, “추돌사고”가 처음 등장한 것으로 보아 악기상으로 인한 사고 발생에 관심이 높아진 것을 알 수 있다. 이를 통해 추후 악기상으로 인한 사 고를 예방하기 위한 업무개선 및 기상정책에 활용할 수 있는 방안이 필요하다.
3.2. 업무현황
기상청의 업무 중점사항의 추세와 업무 동향을 파악하기 위해 1부 총설에서 기상업무와 관련한 부분을
분석해본 결과, 10대 주요뉴스와 마찬가지로 서술성 명사의 빈도가 높게 나타났다. 특히, “추진”, “운
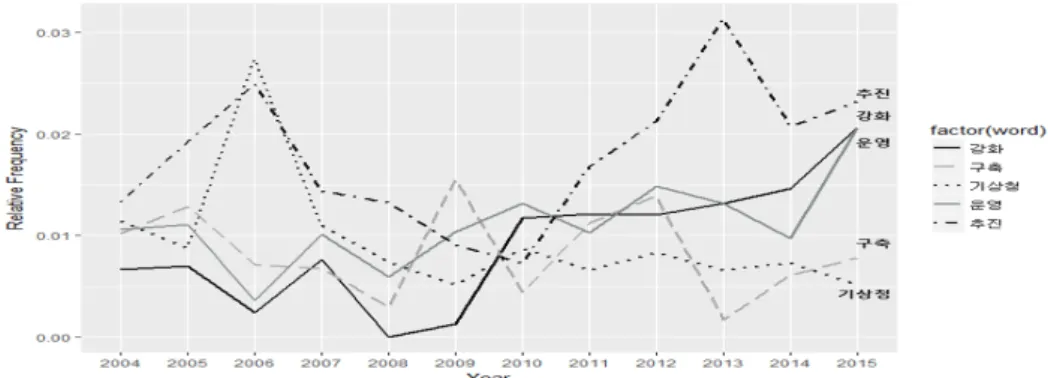
영”, “구축”, “강화”의 빈도가 높게 나타났다. 마찬가지로 상위 5개 단어들에 대해서 연도별 상대도수
그래프를 그린 결과는 Figure 3.3과 같다. 핵심 키워드의 분포를 파악하기 위해 서술성 명사를 제거하
고 워드 클라우드를 그려본 결과는 Figure 3.4와 같다.
Figure 3.5. Increasing trend word relative frequency result by regression in“업무현황”.
(a) Related word with“소통” (b) Related word with“창의” (c)“변화관리” and “혁신”
Figure 3.6. Related word with Increasing trend word.
우선, “국민”이 역시 전체적으로 높게 나타났다. “지진”과 “기술”은 2007년부터 2009년까지 동시에 높 은 빈도로 나타났다. 이를 통해 이 기간 동안 지진과 관련한 기술 개발 업무가 중점이었음을 알 수 있다.
2016 년 경주 대지진 발생으로 인해 앞으로 지진과 관련한 기술 개발이 다시 업무 중점사항이 될 가능성 이 있을 것으로 보인다. 2011년 이후에는 “소통”과 “창의”가 높은 빈도로 나타나기 시작했고, “혁신”은 2004년부터 2007년까지 자주 등장하다가 2008년부터는 나타나지 않고 2008년 이후에는 “변화관리”가 등장하면서 빈도수가 증가함을 확인하였다.
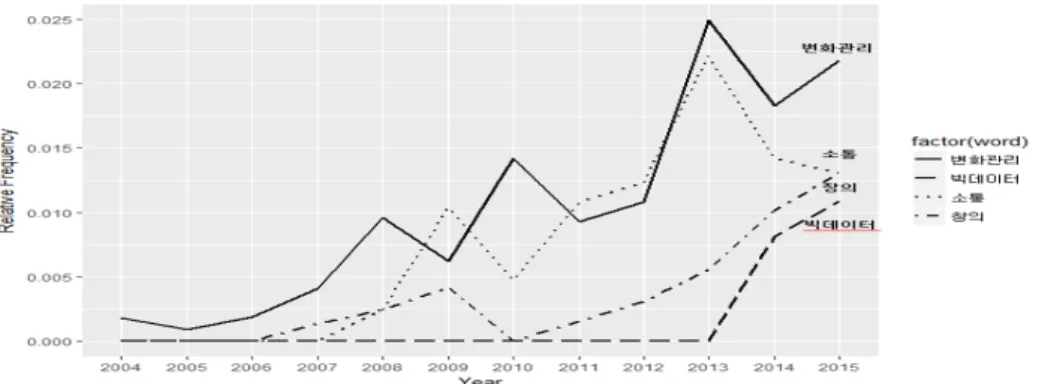
워드 클라우드를 통해 증가 추세가 있는 단어들을 대략적으로 파악한 뒤, 회귀분석을 통해 증가추세 단 어를 선별하였다. 선별기준은 회귀분석 결과 결정계수가 0.5보다 크게 나온 단어 중 회귀계수가 0보 다 큰 단어를 증가추세 단어로 정하였다. 분석 결과, “소통”, “창의”, “변화관리”, “빅데이터”가 회귀 계수가 0 보다 큰 것으로 나타났고 이 단어들의 연도별 상대도수 그래프 Figure 3.5를 통해 이 단어 들의 증가 추세를 시각적으로 확인하였다. 그리고 이 단어들과 관련한 단어들을 살펴보았다. “소통”과 관련한 단어인 “소통프로그램”, “소통워크숍”, “내부소통강화”의 연도별 상대도수 그래프를 그린 결과 는 Figure 3.6(a)와 같고 이를 통해 세 단어 모두 최근 출현빈도의 상대도수가 증가한 것을 확인하였 다. 또한 “창의”와 관련한 “아이디어”, “제안경진대회”, “장려상”도 연도별 상대도수 그래프를 그린 결 과 Figure 3.6(b)와 같이 나타났고, 세 단어 모두 최근 사용이 증가하였다. Figure 3.6(c)는 “변화관리”
와 “혁신”의 연도별 상대도수 그래프를 그린 결과이다. “변화관리”는 높은 증가추세를 보였고 반대로
“혁신”은 2007년까지 출현 빈도가 높았다가 2008년 이후에 등장하지 않았다. 이는 기상청 업무에서 용
어의 변화가 이루어졌음을 짐작할 수 있다. 2004년부터 2007년까지는 “기상업무 혁신”으로 사용되다가
Figure 3.7. Top5 word relative frequency in“기상현황”.
Figure 3.8. Wordcloud by year in“기상현황”.
2008 년 이후에는 “기상업무 변화관리”라는 표현을 사용하게 됨을 확인하였다. 마지막으로 “빅데이터”
가 2014년에 처음 등장하여 2015년 출현 빈도가 증가하였다. 이를 통해 전 사회경제적으로 이슈가 되고 있는 추세에 맞춰 기상청에서도 업무 관련 과제 해결을 위한 빅데이터 활용이 강조될 것으로 예상된다.
3.3. 기상현황
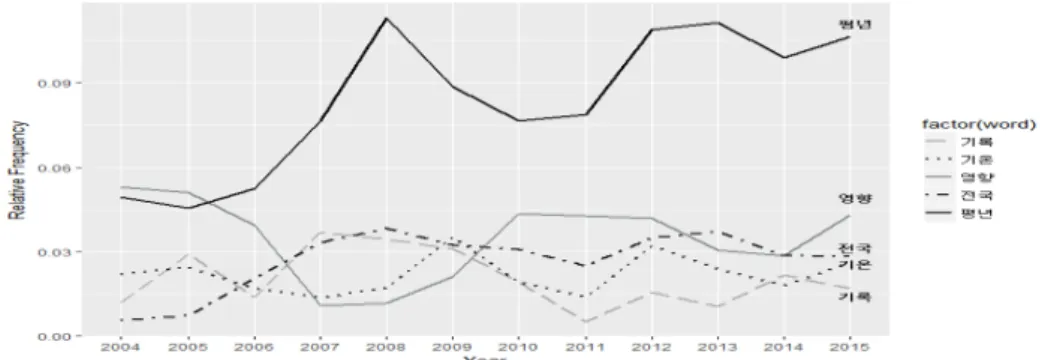
2004 년부터 2015년까지 기상현황 부분에 나타난 단어들의 총 빈도표를 살펴보면 10대 주요뉴스와 업무 현황과는 다른 성격의 단어들이 등장하였다. “평년”이 압도적으로 빈도수가 높게 나타났고 서술성 명사 의 비율이 낮았으며 기후요소(기온, 강수, 기압 등)의 빈도가 높게 나타났다. 상위 5개 단어는 “평년”,
“영향”, “전국”, “기온”, “기록”으로 나타났고, Figure 3.7은 상위 5개 단어들을 시각화한 결과이다. 이
후 하위 단어들의 분포를 파악하기 위해 매년 1위로 나타난 “평년”을 제거하고 워드 클라우드를 그려본
결과 Figure 3.8과 같다.
Figure 3.9. Major meteorological phenomena relative frequency.
2004 년부터 2007년까지 “대관령”, “서귀포”, “제주”의 출현 빈도가 높았고 2008년 이후에는 “평균기 온”, “평균최저기온”, “평균최고기온”의 출현빈도가 높게 나타났다. 이는 2004년부터 2007년까지 한 해 의 기상현황을 서술하는데 있어 위 지역들을 언급하는 경우가 많았고, 2008년부터 최근까지는 지역별로 기상현황을 서술하지 않고 평균적인 기온, 강수량 등으로 서술하기 때문임을 확인하였다. 이후 연도별 로 특정 기상현상이 갖는 추세를 파악하기 위해 “장마”, “태풍”, “황사”, “폭염”, “호우”, “대설” 총 6개 의 주요기상현상을 연도별 상대도수 그래프로 시각화하였다. 결과는 Figure 3.9와 같았고, 이를 통해
“장마”, “태풍”, “황사”의 영향을 많이 받음을 확인하였고 전반적으로 여름철 기상현상에 대해 민감하게 나타나는 것을 확인하였다. 이러한 자료와 결과가 주요 기상현상, 기후요소, 지역 등에 대한 상호연관성 을 파악하는데 기초 자료로 활용될 수 있을 것으로 보인다.
4. 결론
본 연구를 통해 국민과 가장 밀접한 관련을 보인 예보 분야에서 국민들의 편익과 필요를 만족하기 위해 서 예보의 기간과 서비스 제공방법 등이 변화함을 알 수 있었고 최근에는 중기예보 및 미세먼지 대비 예 보체계를 위한 정책을 보완 강화하는 것이 필요함을 알 수 있었다. 또한 과거에는 적었지만 최근 들어 빈도가 늘어나거나 피해 정도가 늘어나 이슈가 되었던 재해들을 파악하였고 이 자료를 이용하여 추후 과 거에 미흡했던 재해에 관한 대비매뉴얼을 작성 및 보완할 수 있을 것이다. 재해와 더불어 세계적으로 이 슈화 된 기후변화에 관하여 대응 정책과 감시체계를 수립하는데 반영할 수 있는 자료로 활용될 수 있다.
기상청 업무 동향으로는 업무 효율성 향상을 위한 소통이 중시되고 있음을 확인하였다. 업무 관련 소통 의 현재의 정책과 제도를 보완하여 더욱 향상된 업무 개선방안을 제시할 필요성을 확인할 수 있었다. 또 한 새로운 아이디어 제안과 창의적인 업무에 대한 수요가 증가할 것으로 예상된다. 더불어 텍스트와 같 은 비정형 자료의 양이 늘어나면서 여러가지 자료를 통해 새로운 정보를 습득하기 위한 딥러닝, 인공지 능 머신러닝과 같은 기계학습 기법을 활용하는 것이 강조될 것으로 예상된다.
본 연구에서는 기상연감의 10대 주요뉴스, 업무현황, 기상현황에서 이슈가 되었던 단어들을 중심으로
기상청의 업무 효율성 향상을 위한 기초자료로 활용하여 기상관련 자료 사용자들의 필요를 만족시키는
데 의의가 있다. 특히 오픈소스로 제공하는 사전에 탑재되어있지 않은 기상과 관련한 용어들을 업데이
트하였다는 점에서 이후 기상관련 텍스트에서 이러한 단어들이 분석에 알맞게 추출할 수 있기 때문에 기
상정책 마련이나 기상사업 추진 시 가치 있는 자산이 될 것이다. 본 연구에서 진행한 키워드 중심의 빈
도분석이 추후 단어들의 군집화 및 연관성 분석을 하는 연구에서 기초자료로 활용될 수 있고 용어 사전
의 지속적인 업데이트가 이루어져서 기상관련 자료 분석 시에 중요한 자료로 활용될 것이다.
References
Ahn, S. and Cho, S. (2010). Stock prediction using news text mining and time series analysis, In 2010 Conference Proceedings of Korean Institute of Information Scientists and Engineers, 37, 364–369.
Chen, P., Ponocko, J., Milosevic, N., Nenadic, G., and Milanovic, J. V. (2016). Towards application of text mining for enhanced power network data analytics-part i: retrieval and ranking of textual data from the internet, Mediterranean Conference on Power Generation, Transmission, Distribution and Energy Conversion (MedPower 2016), 1–8.
Feinerer, I. and Hornik, K (2015). tm: Text Mining Package. R package version 0.6-2., from: https://CRAN.R- project.org/package=tm/
Gupta, V. and Lehal, G. S. (2009). A survey of text mining techniques and applications, Journal of Emerging Technologies in Web Intelligence, 1, 60–76.
Jeon, H. (2016). KoNLP: Korean NLP package. R package version 0.80.1., from: https://CRAN.R-project.
org/package=KoNLP/
KAIST Semantic Web Research Center (2011). Hannanum Korean morphological analyzer user manual, from:
http://www.sketchengine.co.uk/wp-content/uploads/Original-HanNanum-manual.pdf/
Kam, M. and Song, M. (2012). A study on differences of contents and tones of arguments among newspapers using text mining analysis, Journal of Intelligence and Information Systems, 18, 53–77.
Lee, Y., Lim, C., Heo, M., and Kim, H. (2016). Text mining technique for Weather call center data analysis, In 2016 Spring Conference Proceedings of Korean Meteorological Society, 153–154.
Lim, M. and Kim, N. (2016). Investigating dynamic mutation process of issues using unstructured text analysis, Journal of Intelligence and Information Systems, 22, 1–18.
R Core Team (2016). R: A language and environment for statistical computing, R Foundation for Statistical Computing, Vienna, Austria, from: https://www.R-project.org/
텍스트 마이닝 알고리즘을 이용한 기상청 기상연감 자료 분석
선현석
a· 임창원
a· 이영섭
b,1a
중앙대학교 응용통계학과,
b동국대학교 통계학과
(2017년 6월 19일 접수, 2017년 7월 7일 수정, 2017년 7월 10일 채택)요 약
최근 들어 많은 사람들이 자신의 관심사를 SNS에 게시하거나 인터넷과 컴퓨터의 기술 발달로 디지털 형태의 문서 저장이 가능하게 됨으로써 생성되는 텍스트 자료의 양이 폭발적으로 증가하게 되었다. 이에 따라 수많은 문서 자료 로부터 가치 있는 정보를 창출하기 위한 기술의 요구 또한 증가하고 있다. 그러나 대부분 비정형 형태로 구성되어 있는 텍스트 기반의 자료는 기존의 통계 분석이나 데이터 마이닝 기법을 적용하기에 부적합하기 때문에 텍스트 마이 닝 기법이 사용되고 있다. 본 연구에서는 비정형 자료 분석 기법 중 하나인 텍스트 마이닝 기법으로 기상청 기상연 감 자료를 분석하였다. 먼저 전처리 과정을 통하여 용어사전을 구축하고, 용어-문서 행렬을 생성하였다. 그리고 이 것을 사용하여 연도별 용어 빈도수를 계산하고, 자주 나타나는 단어들에 대하여 상대도수의 변화를 관찰하였다. 또 한 회귀 분석 기법을 사용하여 증가추세와 감소추세를 보이는 용어들을 파악하였다. 이러한 분석으로 기상청 기상연 감 문서에서의 트렌드를 파악하고, 이를 통해 이슈가 되었던 기상 관련 소식과 기상현황, 그리고 기상청이 중점으로 하고 있는 업무 현황의 트렌드를 파악하였다. 본 연구를 통해 기상업무 분석 및 효율화에 도움을 주고 기상정책에 반영할 수 있는 유용한 정보를 이끌어내고자 하였다.
주요용어: 텍스트마이닝, 비정형데이터, 한국기상청, 워드클라우드
본 연구는 기상청 “기상 관측·예보 분야의 비정형데이터 분석 기술 개발”의 지원에 의한 것임 (KIMPA2015-1110).
1교신저자: (04620) 서울시 중구 필동로 1길 30, 동국대학교 통계학과. E-mail: [email protected]