Latent class model for mixed variables with applications to text data
Hyun Soo Shin
a· Byungtae Seo
a,1a
Department of Statistics, Sungkyunkwan University
(Received July 1, 2019; Revised October 18, 2019; Accepted October 20, 2019)
Abstract
Latent class models (LCM) are useful tools to draw hidden information from categorical data. This model can also be interpreted as a mixture model with multinomial component distributions. In some cases, however, an available dataset may contain both categorical and count or continuous data. For such cases, we can extend the LCM to a mixture model with both multinomial and other component distributions such as normal and Poisson distributions. In this paper, we consider a LCM for the data containing categorical and count data to analyze the Drug Review dataset which contains categorical responses and text review.
From this data analysis, we show that we can obtain more specific hidden inforamtion than those from the LCM only with categorical responses.
Keywords: latent class analysis, mixture model, clustering, text mining
1. 서론
잠재변수모형(latent variable model; LVM)은 관측 가능한 변수(manifest variable)를 잠재변수(latent variable) 와 연관시키는 통계 모형으로 다층구조 자료와 종단자료, 그리고 패널 자료를 다루는 다양 한 분야에서 사용되고 있다. 특히, Lazarsfeld와 Henry (1968)가 제안한 잠재범주모형(latent class model; LCM)은 일종의 확률론적 LVM으로 잠재변수와 관측변수의 형태가 모두 범주형일 때 주어진 자료로부터 관측되지 않은 잠재범주를 확률적으로 찾아낼 수 있는 모형으로 교육학, 심리학 등을 포함 한 사회과학 분야에서 자료에 잠재된 요인을 도출 및 분석하는데 널리 이용되고 있다. 초기 LCM은 이 진 관찰 변수를 기반으로 한 건물 유형학에 사용하기 위해 Lazarsfeld (1950)에 의해 처음으로 정의되었 다. Lazarsfeld와 Henry (1968)는 관측 가능한 변수와 잠재범주가 모두 범주형인 잠재변수모형을 잠재 범주모형이라고 정의하였다. Goodman (1974)은 잠재구조모형에서 모형이 식별 가능하기 위한 조건을 규명하였으며 Haberman (1979), Hagenaars (1990), 그리고 Vermunt (1997)는 LCM을 이용한 로그 선형모형을 제시하였다.
일반적인 LCM은 보통 범주형인 다변량 관측변수를 통해 관측되지 않은 잠재변수를 도출하는 모형으로 혼합 다항분포 모형으로 볼 수 있다. 즉, 다항분포를 따르는 각 관측값들이 하나의 다항분포에서 얻어진
This work was supported in part by Basic Science Program from the National Research Foundation of Korea (NRF), funded by the Ministry of Education, Science, and Technolohy (NRF-2019R1F1A1059959).1Corresponding author: Department of Statistics, Sungkyunkwan University, 25-2, Sungkyunkwan-ro, Jongno-gu, Seoul 03063, Korea. E-mail: [email protected]
것이 아니라 몇 개의 서로다른 모수를 가지는 다항분포 중 하나의 분포로부터 얻어졌다고 가정하는 모형 이다. 이때, 각 관측값이 어느 다항분포에서 얻어졌는지는 관측되지 않았고 이를 확률적으로 분석하는 모형이라고 볼 수 있다. LCM은 설문조사와 같이 몇 개의 범주형 응답 문항에 답한 결과들을 통해 모집 단 안에서 서로 성격이 다른 하위모집단을 찾아내 분석하는 데 유용하게 사용될 수 있다. 예를 들어 각 개인이 응답한 여러 영화에 대한 평점들을 바탕으로 응답자들이 속하는 관측되지 않은 하위모집단을 찾 아 이를 추천시스템 등에 이용할 수도 있다. Sung 등 (2016)은 초등학생을 대상으로 한 설문조사 결과 를 LCM을 통해 학교적응에 대한 잠재집단을 찾아내고 잠재집단분류와 학습습관에 대한 영향력을 분석 하였다.
하지만 실제 자료 분석에 있어서는 관측값들이 범주형 자료뿐 아니라 연속형 자료나 빈도 자료등을 포함 하는 경우가 빈번하게 발생하는데 예를 들어 설문 문항이 선택형 문항뿐 아니라 빈도를 물어보는 문항 혹은 서술형 문항이 포함된 경우 일반적인 LCM을 사용할 수 없다. 이렇게 관측변수가 다양한 형태로 이루어진 경우에 관하여 Everitt (1988)는 혼합모형을 이용하여 혼합된 관측변수(mixed variable)의 형 태에서 군집화(clustering) 문제를 고려하였고 특히 Sammel 등 (1997) 이를 좀 더 확장하여 관측 가능 한 변수가 이산형과 연속형의 혼합 형태로 존재할 때 LCM을 정의하였다.
본 논문에서는 이러한 혼합 관측변수 중 특히 범주형 자료와 도수형 자료가 관찰변수로서 혼합되어있 는 경우에 잠재범주모형(LCM for mixed variables; LCMM)을 고려하고자 한다. 이를 통해 범주형 자 료와 텍스트 자료가 혼합되어있는 온라인 의약품 후기 자료(drug review dataset)의 분석에 이용하고 자 한다. 특히, 비정형화된 텍스트 자료를 정형화하여 범주형 자료와 혼합되어 있는 경우에 적용할 구 체적인 모형을 정의하고, LCMM에서의 모수 추정 방법과 모형 선택 방법에 대해 연구하고자 한다. 본 논문의 구성은 다음과 같다. 제 2장에서는 기존의 LCM과 관측변수의 형태가 서로 다른 경우에 적용 할 LCMM에 대해 소개하였다. 제 3장에서는 범주형 자료와 텍스트 자료가 혼합되어있는 경우에 적용 할 구체적인 모형을 제시하고 구체적인 모수 추정 방법과 모형 선택 방법을 기술하였다. 제 4장에서는 온라인 의약품 후기 자료를 이용하여 실증 자료를 분석하여 구체적인 해석을 정리하였다. 마지막으로 제5장에서는 본 논문의 결론에 대해 요약하고 향후 연구에 대해서 논의하였다.
2. 잠재범주모형
2.1. Latent class model
LCM 은 다변량 다항 분포을 따르는 관측변수에 대한 모집단의 분포가 상호 배타적인 하위 분포로 이루 어져 있을때 하위 분포를 확률적으로 찾는 방법이다. 잠재범주분석에서는 전체 모집단이 관측되지 않은 하위 모집단으로 구성되어 있다고 가정한다. 각 잠재범주는 관측 개체의 관측변수값을 통해 확률적으로 알 수 있다. 예를 들어, 설문조사를 실시했을 때 각 질문 문항을 관측 가능한 변수 혹은 관측변수라 할 수 있다. 전체 설문조사의 응답자 집단은 각 집단별 특성을 가진 집단인 잠재범주로 나눌 수 있다.
일반적인 LCM에서는 J개의 모든 관측변수에 대한 i번째 개체 Y
i= (Y
i1, . . . , Y
iJ) 의 확률 분포에 대해 다항 분포를 가정한다. 이 때, Y
ij는 i번째 관측 개체의 j번째 관측변수를 의미하며, Y
i의 확률 분포는 다음과 같이 표현될 수 있다.
f (y
i|θ) =
∑
C c=1γ
cf
c(y
i|θ
c), (2.1)
여기서 γ
c는 각 관측 개체 Y
i가 c번째 잠재집단에 포함될 확률을 의미한다. 이때, 각 관측 개체는 오로 지 한 개의 잠재범주에 포함되기 때문에 ∑
Cc=1
γ
c= 1 을 만족하여야 하며 f
c(y
i|θ
c) 는 c번째 잠재모집단
의 확률밀도함수이고, θ
c는 이 확률밀도함수의 모수 집합을 의미한다.
LCM 에서는 c번째 잠재범주에 속하는 i번째 관측 개체 Y
i= (Y
i1, . . . , Y
iJ) 의 확률밀도함수가 다음과 같은 일종의 다항 분포를 가지는 것으로 가정한다.
f
jc(y
ij|θ
jc) =
mj
∏
m=1
ρ
I(yjmij|c=m),
여기서 Y
ij는 m
j개의 응답 범주를 가지며, 편의상 1부터 m
j까지의 정수값을 가진다고 가정한다. 또한, ρ
jm|c는 잠재범주 c에 속하는 관측 개체가 j번째 관측변수에 대하여 m이라고 응답할 확률을 의미하고, θ
jc= {
ρ
j1|c, . . . , ρ
jmj|c}
는 이때의 모수집단을 의미한다. I(y
ij= m) 는 i번째 관측 개체가 j번째 관측 변수에 대해 m이라고 응답한 경우는 1, 그렇지 않은 경우는 0인 지시함수를 나타낸다. 각 관측 개체는
j번째 관측변수에 대해 한가지 응답만 가능하기 때문에 ∑
mjm=1
ρ
jm|c= 1을 만족하여야 한다.
이때 각 잠재집단이 주어진 경우에 Y
ij들은 서로 독립이라는 조건부 독립 (Lazarsfeld와 Henry, 1968) 가정하에서 잠재범주 c에 속하는 Y
i의 확률밀도함수는 다시
f (y
i|θ
c) =
∏
J j=1f
jc(y
ij|θ
jc) =
∏
J j=1mj
∏
m=1
ρ
I(yjm|cij=m)(2.2)
으로 나타낼 수 있고 Y
i의 확률밀도함수는 다음과 같이 표현될 수 있다.
f (y
i|θ) =
∑
C c=1γ
cf
c(y
i|θ
c) =
∑
C c=1γ
c∏
J j=1mj
∏
m=1
ρ
I(yjm|cij=m).
2.2. Latent class model for mixed variables
2.1 절에서 소개한 LCM은 각 잠재범주 내에서 관측변수 Y
ij가 1부터 m
j의 값들만을 가지는 경우로 범 주형 자료를 위한 잠재변수 모형인데 실제 주어진 자료에서는 종종 관측변수가 단순한 범주형이 아닌 이 산형 혹은 연속형처럼 다양한 형태의 관측변수가 혼합되어 있는 경우를 볼 수 있다. 예를 들어, 설문지 의 문항에서 선호도와 같은 다항선택 문항뿐만 아니라 특정 행위의 빈도수를 물어보는 문항이 존재할 수 있다. 이 경우 일반적인 LCM을 이용하기 위해서는 빈도수 등을 다시 범주화하여야 하는데 이 경우 정 보의 손실이 있을 수 있다. 이러한 경우에 있어서 Everitt (1988, 1993)는 다양한 형태의 자료를 혼합 모드(mixed mode) 자료라고 정의하였고, LCM의 일반적인 구조를 확장하여 혼합 모드 자료에의 잠재 범주 모형으로 LCMM을 제안하였다. 이러한 LCMM은 일반적인 LCM의 구조에서 각각의 관측변수가 단일 분포가 아닌 여러 가지 분포의 형태로 동시에 나타날 때, 각각의 분포를 적절한 일변량 분포로 가 정할 수 있는 잠재변수모형이다. LCMM은 기존의 LCM과는 달리 관측변수가 다양하게 혼합되어 있을 때, 잠재범주에 대한 추론 및 분석을 할 수 있게 해주는데 특히, 관측변수의 성질에 따라서 다양한 분포 가정을 가능하게 함으로써 매우 일반적 모형을 정의할 수 있다.
예를 들어, i번째 관측 개체 Y
i= (W
i, V
i) 에 대하여 W
i는 LCM에서와 같이 범주형 자료를 나타내는
확률벡터이고 V
i는 빈도수를 나타내는 확률벡터라고 하면, 2.1절에서 설명한 것과 같은 LCM을 사용할
수 없게 된다. 여기서, W
i= (W
i1, . . . , W
iJw)이고 V
i= (V
i1, . . . , V
iJv)이다. 이때 W와 V는 그 성질
이 다르므로 서로 다른 분포족을 가정해야 하는데 예를 들어 W는 다항분포 V는 포아송분포, 음이항분
포 등을 가정할 수 있다. 이 경우 식 (2.1)에서의 Y
i는 W
i와 V
i의 결합밀도함수가 되어야 한다. 특히
Bockenholt (1993)와 Wedel 등 (1993)은 각 개체의 관찰변수가 일부는 범주형이고 일부는 빈도수를 나
타내는 경우 각 개체 Y
i의 확률밀도함수를 포아송분포와 다항분포를 이용하는 방법을 제안하였다.
3. 모형과 추정
3.1. 모형
d
1차원 범주형 확률벡터 W
i= (W
i1, . . . , W
id1)과 d
2차원 도수형 확률벡터 V
i= (V
i1, . . . , V
id2)에 대하여 d
1+ d
2차원 확률벡터 Y
i를 Y
i= (W
i, V
i) 라고 정의하자. 주어진 각 잠재범주 c에서 W
is, s = 1, . . . , d
1의 주변확률밀도함수를 f
W(w
is|η
sc) 라고 하고 V
it, t = 1, . . . , d
2의 주변확률밀도함수를 f
V(v
it|ξ
tc)라고 하자. 이때 LCM에서 흔히 가정되어지는 지역독립성가정와 유사하게 각 잠재범주가 주 어졌을 때 (W
i1, . . . , W
id1, V
i1, . . . , V
id2) 이 모두 서로 독립이라고 가정하면 Y
i의 확률밀도함수는 다음 과 같이 표현할 수 있다.
f (y
i|θ) =
∑
C c=1γ
c d1∏
s=1
f
W(w
is|η
sc)
d2
∏
t=1
f
V(v
it|ξ
tc),
여기서 η
sc와 ξ
tc는 각 주어진 잠재범주 c에서 W
is와 V
it의 확률밀도함수에 포함된 모수집합이다. 이 때, W
is를 LCM과 같은 범주형 자료를 나타내는 확률변수라고 하면 f
W(w
is|η
sc) 는 다시
f
W(w
is|η
sc) =
ms
∏
m=1
ρ
I(wsm|cis=m)로 표현될 수 있다. 또한, V
it를 빈도수를 나타내는 포아송 확률변수라고 하면 f
V(v
it|ξ
tc)는 f
V(v
it|ξ
tc) = exp( −λ
t|c) λ
vt|citv
it!
으로 나타낼 수 있다. 여기서 λ
t|c는 잠재범주 c에 속한 확률변수 V
it의 평균을 나타내는 모수이다.
따라서 Y
i의 주변확률밀도함수는 다음과 같이 표현될 수 있다.
f (y
i|θ) =
∑
C c=1γ
c d1∏
s=1 ms
∏
m=1
ρ
I(wsm|cis=m)d2
∏
t=1
exp( −λ
t|c) λ
vt|citv
it! . (3.1)
3.2. 모수 추정
자료에 대한 모형 식 (3.1)에서 최대우도추정량을 얻기 위한 일반적인 수치 해석적 방법은 많은 모수로 인하여 매우 불안정하여 보통은 Dempster, Laird, 그리고 Rubin (Dempster 등, 1977)이 제안한 EM 알고리즘(expectation-maximization algorithm; EM algorithm)을 이용하여 추정한다. EM 알고리즘 은 일반적으로 결측이 있는 자료를 포함한 경우에 있어서 최대우도추정치를 얻는 방법인데 식 (3.1)에서 는 관측되지 않은 범주를 결측으로 보고 EM 알고리즘을 적용하게 된다. 이를 위해 먼저 관측되지 않은 잠재변수 L
i를 1부터 C까지의 정수값을 가지는 확률변수라고 하자. 즉, 확률벡터 Y
i가 잠재범주 c에 속할 때 L
i는 c의 값을 가진다. 따라서 Y
i와 L
i의 결합확률밀도함수는
P (Y
i= y
i, L
i= c) =
∏
C c=1[ γ
cd1
∏
s=1 ms
∏
m=1
ρ
I(wsm|cis=m)d2
∏
t=1
exp(−λ
t|c) λ
vt|citv
it!
]
I(Li=c)이고, 자료 (Y
i, L
i), i = 1, . . . , n이 주어졌을 때의 로그가능도함수는 다음과 같다.
l
c(θ) =
∑
n i=1∑
C c=1I(L
i= c) log {
γ
c d1∏
s=1 ms
∏
m=1
ρ
I(wsm|cis=m)d2
∏
t=1
exp(−λ
t|c) λ
vt|citv
it!
}
. (3.2)
E- 단계는 모수의 MLE를 찾기 위하여 EM 알고리즘에서 초기 모수 값과 관측변수가 주어진 조건 하에 결합로그가능도(complete log likelihood)함수의 기댓값을 구하는 단계이다. Y = (Y
1, . . . , Y
n)
T라고 하고, θ
(r)를 알고리즘을 r번 반복했을 때의 모수 추정값이라고 정의했을 때, E-단계에서 정의된 기댓값 Q(θ |θ
(r)) 은 다음과 같이 정의한다.
Q (
θ |θ
(r))
= E [
l
c(θ) |Y, θ
(r)]
Z ˆ
ic= P (L
i= c |Y, γ
c(r), ρ
(r)sm|c, λ
(r)t|c) 로 정의하면 식 (3.2)를 이용한 Q(θ|θ
(r)) 의 구체적인 계산식은 다 음과 같다.
Q (
γ
c, ρ
sm|c, λ
t|c|γ
c(r), ρ
(r)sm|c, λ
(r)t|c)
= E [
l
c(γ
c, ρ
sm|c, λ
t|c) |Y, γ
c(r), ρ
(r)sm|c, λ
(r)t|c]
=
∑
n i=1∑
C c=1P (
L
i= c |Y, γ
c(r), ρ
(r)sm|c, λ
(r)t|c)
log {
γ
c d1∏
s=1 ms
∏
m=1
ρ
I(wsm|cis=m)d2
∏
t=1
exp( −λ
t|c) λ
vt|citv
it!
}
=
∑
n i=1∑
C c=1Z ˆ
ic[ log γ
c+
d1
∑
s=1 ms
∑
m=1
{ I(w
is= m) log ρ
sm|c} +
d2
∑
t=1
{ v
itlog λ
t|c− log v
it! − λ
t|c} ] .
M- 단계는 E-단계에서 구한 Q(θ|θ
(r)) 를 최대화 하는 θ를 찾는 단계로 Q(θ|θ
(r)) 을 최대화하는 모수의 추정량은 다음과 같다.
ˆ γ
c(r+1)=
∑
n i=1Z ˆ
ic∑
n i=1∑
C c=1Z ˆ
ic, ρ ˆ
(r+1)sm|c=
∑
ni=1
Z ˆ
icI(w
is= m)
∑
n i=1Z ˆ
ic, ˆ λ
(r+1)t|c=
∑
n i=1Z ˆ
icv
it∑
n i=1Z ˆ
ic모형에 포함된 모수의 MLR는 이러한 E-단계와 M-단계를 수렴할때까지 반복적으로 수행하여 얻을 수 있다.
3.3. 모형 선택
일반적으로 잠재변수모형의 적합에 있어서 잠재변수의 개수는 사전에 정해주어야 하는데 이때 가장 널 리 쓰이는 방법은 정보지수를 이용하는 방법이다. 본 논문에서는 다음의 세 가지 정보지수를 바탕으로 잠재변수 혹은 잠재범주의 개수를 선택하였다.
Akaike information criterion (AIC) (Akaike, 1973):
AIC = −2 log ( L ˆ ) + 2q.
Bayesian information criterion (BIC) (Schwarz, 1978):
BIC = −2 log ( L ˆ )
+ log(n)q.
Table 4.1. Manifest items for drug review
항목 응답 범주
1 2 3 4 5
만족도 매우 불만족 불만족 보통 만족 매우 만족
약의 효과 효과 없음 부분적 효과 적당한 효과 상당한 효과 매우 상당한 효과
약의 부작용 효과 없음 약한 효과 적당한 효과 심한 효과 매우 심한 효과
Consistent AIC (CAIC) (Bozdogan, 1987):
CAIC = −2 log ( L ˆ )
+ q [log(n) + 1] .
여기서 ˆL은 주어진 잠재집단의 개수를 바탕으로 적합된 최대가능도함수 값이고, q는 각 모형에서 사 용된 모수의 개수이고 n은 표본의 개수이다. 잠재집단의 수는 이러한 정보지수의 값을 최소로 해주는 숫자로 정하는데 일반적으로 AIC는 모형을 과대추정하는 경향이 있으므로 본 논문에서는 주로 BIC와 CAIC 에 근거하여 집단의 개수를 정하였다.
4. 의약품 후기 자료 분석
본 장에서는 범주형 자료뿐 아니라 텍스트 자료가 포함된 의약품 후기 자료에 대하여 범주형 자료만 을 가지고 분석한 LCM 결과와 텍스트 자료를 범주형 자료에 포함하지 않은 경우에 LCMM을 적합하 여 비교 분석을 진행하였다. 본 연구에서 활용된 자료는 Felix 등 (2018)이 사용한 자료로 Python의 Beautiful Soup 라이브러리를 사용하여 온라인 의약품 후기 사이트(Druglib.com)에서 크롤링하여 얻 은 자료이다. 본 논문에서 사용된 후기 자료는 약에 대한 만족도, 약의 효과, 약의 부작용 정도를 그 강 도에 따라 Table 4.1과 같이 1에서 부터 5사이의 정수 응답 값중 하나를 선택한 응답자료들과 약의 부 작용에 대한 텍스트 리뷰로 구성되어 있다. 총 3,084명의 응답자 자료를 토대로 구성된 자료의 형태는 Table 4.2와 같다.
분석을 위해 비정형 자료인 텍스트 자료를 R의 tm package (Feinerer 등, 2008)를 이용해 코퍼 스(Corpus) 를 형성하고, 이를 기반으로 문서-단어 행렬(document-term matrix; DTM)을 만들었 다. DTM에서 행은 문서, 열은 단어, 그리고 행렬 내의 원소는 단어의 빈도수로 이루어져있다. 분석하 고자 하는 의약품 후기 자료의 전처리 과정 후 DTM으로 변환을 해주었다. 또한, 텍스트 자료에서 의미 없는 단어를 구분하기 위해 단어별 30회 이상 언급된 단어만을 선별하여 183개의 단어를 선별하여 다음 과 같은 DTM을 생성하였다.
DTM =
skin dry ··· hot
1
1 0 · · · 0
2
1 2 · · · 1
3
0 1 · · · 0
.. . .. . .. . . . . .. .
3084
0 0 · · · 0
. (4.1)
최종적으로 잠재범주분석에 사용될 자료의 형태는 기존의 세 가지의 범주형 관측변수와 DTM으로부터
의 183개의 도수형 관측변수가 결합한 형태로서, Table 4.3과 같으며 여기서 각 단어가 나타나는 빈도
수에 대한 분포로 포아송 분포를 고려하였다. 즉, DTM을 LCMM에 활용하기 위하여 잠재범주 c가 주
Table 4.2. Patient reviews on specific drugs dataset
ID Rating Effectiveness SideEffects SideEffects review
1 5 4 2 I had some mental. . .
2 5 5 2 dry mouth and dizziness. . .
3 2 3 4 I felt extremely drugged. . .
.. .
.. .
.. .
.. .
.. .
3084 2 3 3 I really don’t have side effects
Table 4.3. Patient reviews on specific drugs with document term matrix
ID 만족도 약의 효과 약의 부작용 skin dry · · · hot
1 5 4 2 1 0 · · · 0
2 5 5 2 1 2 · · · 1
3 2 3 4 0 1 · · · 0
.. .
.. .
.. .
.. .
.. .
..
. . .. ...
3084 2 3 3 0 0 · · · 0
Table 4.4. AIC, BIC, and CAIC in latent class models
잠재범주 수
1 2 3 4 5 6
AIC 26281.8 23554.6 22425.1 22062.0 21976.8 21968.9
BIC 26354.3 23705.5 22654.4 22369.8 22363.0 22433.5
CAIC 26366.3 23730.5 22692.4 22420.8 22427.0 22510.5
AIC = Akaike information criterion; BIC = Bayesian information criterion; CAIC = consistent AIC.
어졌을 때 t번째 단어의 빈도수 V
it의 분포를 모수 λ
t|c를 갖는 포아송 분포로 가정하였다.
4.1. LCM 분석결과
먼저 주어진 자료 중 텍스트 자료는 제외하고 범주형 응답 문항에 대하여 LCM을 적합해 보았다.
LCM 에서 최적의 잠재범주의 수를 결정하기 위해 잠재범주의 수가 한 개인 모형부터 여섯 개인 모형까 지 LCM을 적합 시킨후 정보지수를 계산하여 Table 4.4에 정리하였다. AIC를 기준으로 최적인 잠재 범주의 수는 일곱 개, BIC 기준으로는 다섯 개, 그리고 CAIC 기준으로 네 개를 최적의 잠재범주의 수 로 판단할 수 있다. AIC는 보통 너무 많은 잠재범주의 수를 선택하는 경향이 있으므로 분석에서는 주로 BIC 와 CAIC를 바탕으로 잠재범주 수를 결정하였다. BIC의 경우 범주 수가 네 개인 경우와 다섯 개인 경우의 차이가 미미하고 CAIC도 그 차이가 미미한데 적절한 해석과 모형의 간결성을 고려하여 잠재범 주의 수는 네 개로 결정하였다.
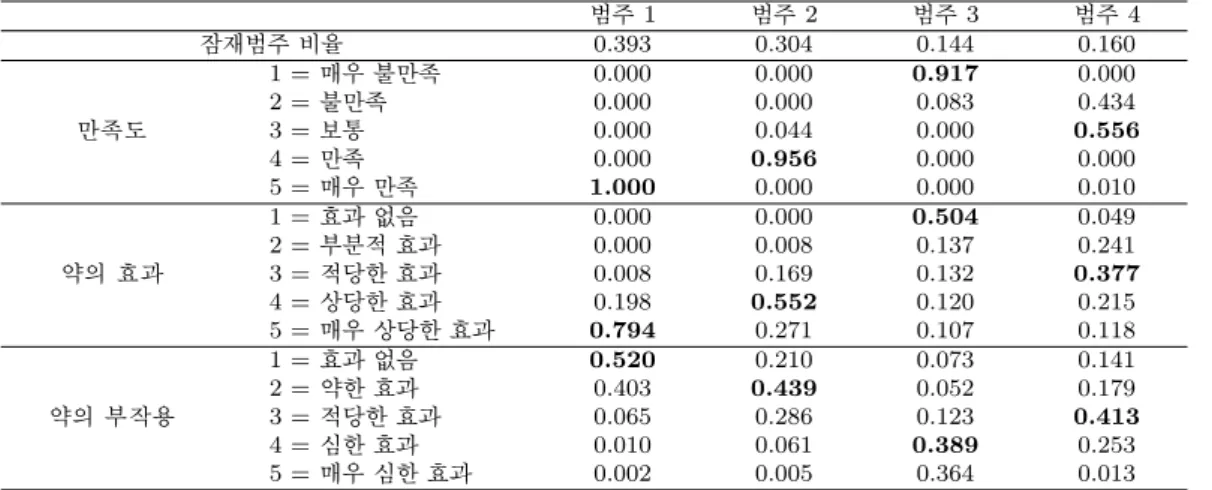
LCM에서 잠재범주의 수가 다섯 개인 모형을 적합 시킨 결과 잠재범주의 비율과 각 잠재범주에 대한 문 항응답확률은 Table 4.5에 정리하였다. 범주 1에서 문항응답확률을 살펴보면 만족도 항목에서는 “매우 만족”(100.0%)이, 약의 효과 항목에서는 “매우 상당한 효과”(79.4%)가, 약의 부작용에 대한 항목에서 는 “효과 없음”(51.9%)이 가장 많은 응답을 하였다. 이를 바탕으로 보아 범주 1은 전반적인 만족도가 매우 높고, 약의 효과도 상당히 높으며, 약의 부작용도 거의 경험하지 않은 집단으로 판단할 수 있다. 범 주 2에서는 만족도 항목에서 “만족”(93.8%)이 가장 많은 응답을 했고, 약의 효과 항목에서 “매우 상당 한 효과”(58.7%)가, 약의 부작용에 대한 항목에서는 “약한 효과”(53.0%)가 가장 많은 응답을 하였다.
따라서, 범주 2에 속하는 집단도 전반적으로 약에 대한 만족도와 효능에 대하여 긍정적이고 부작용도 크
게 경험하지 않은 집단으로 볼 수 있다. 하지만, 범주 2는 범주 1에 비하여 약에 대한 만족도는 다소 약
한데 그 이유는 약의 부작용을 약하지만 어느정도 겪었기 때문이라고 판단할 수 있다.
Table 4.5. Latent class model of patient reviews on drugs
범주 1 범주 2 범주 3 범주 4
잠재범주 비율 0.393 0.304 0.144 0.160
만족도
1 =매우 불만족 0.000 0.000 0.917 0.000
2 =불만족 0.000 0.000 0.083 0.434
3 =보통 0.000 0.044 0.000 0.556
4 =만족 0.000 0.956 0.000 0.000
5 =매우 만족 1.000 0.000 0.000 0.010
약의 효과
1 =효과 없음 0.000 0.000 0.504 0.049
2 =부분적 효과 0.000 0.008 0.137 0.241
3 =적당한 효과 0.008 0.169 0.132 0.377
4 =상당한 효과 0.198 0.552 0.120 0.215
5 =매우 상당한 효과 0.794 0.271 0.107 0.118
약의 부작용
1 =효과 없음 0.520 0.210 0.073 0.141
2 =약한 효과 0.403 0.439 0.052 0.179
3 =적당한 효과 0.065 0.286 0.123 0.413
4 =심한 효과 0.010 0.061 0.389 0.253
5 =매우 심한 효과 0.002 0.005 0.364 0.013
Table 4.6. AIC, BIC, and CAIC in latent class models for mixed variables 잠재범주 수
1 2 3 4 5 6
AIC 143167.0 137582.0 135022.8 133487.2 132277.3 131867.0 BIC 143457.4 138164.3 135896.9 134653.2 133735.2 133616.7 CAIC 143652.4 138555.3 136483.0 135436.6 134714.5 134791.8 AIC = Akaike information criterion; BIC = Bayesian information criterion; CAIC = consistent AIC.
반면에, 범주 3에 속하는 집단은 만족도 항목에서 “매우 불만족”(92.5%), 약의 효과에서는 “효과 없 음”(50.4%), 약의 부작용에서는 “심한 효과”(36.6%)가 가장 많은 응답으로 나타났다. 따라서, 범주 3 은 약에 대한 만족도는 매우 낮고, 약의 효과는 없고, 약의 부작용은 심한 집단임을 알 수 있다. 마지막 으로 범주 4는 만족도 항목에서 “매우 만족”(47.6%), 약의 효과에서는 “상당한 효과”(50.4%), 약의 부 작용 효과는 “적당한 효과”(54.4%)가 가장 많은 응답을 나타낸 집단으로 약의 효과를 어느정도 경험했 지만 약의 부작용도 상당히 경험한 집단으로 판단할 수 있다.
4.2. LCMM 분석 결과
앞서 응답 문항만을 이용한 분석에 텍스트 자료도 함께 포함하여 LCMM을 사용하여 자료를 적합해 보 았다. LCMM에서 최적의 잠재범주수를 결정하기 위해 LCM에서와 비슷하게 잠재범주의 수가 한 개 인 모형부터 여섯 개인 모형까지 LCMM을 적합 시킨 후 정보지수를 계산하여 Table 4.6에 정리하였다.
이 경우 전반적으로 LCM보다 더 많은 잠재범주의 수를 선택하는 경향을 보였고, 본 논문에서는 최적의 잠재범주의 수를 다섯 개로 선택하였다.
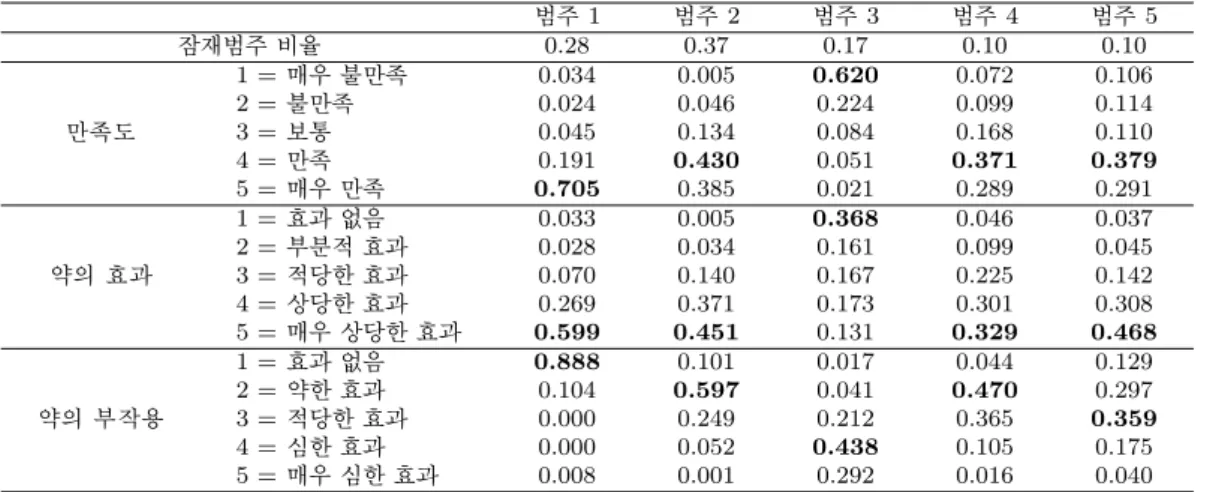
잠재범주의 수가 다섯 개인 모형을 적합 시킨 결과 잠재범주의 비율과 각 잠재범주에 대한 문항응답확
률을 Table 4.7에 정리하였다. 범주 1에서는 만족도 항목에서 “매우 만족”(70.5%)으로 가장 많은 응답
을 했고, 약의 효과 항목에서 “매우 상당한 효과”(59.9%)로 가장 많은 응답을 했고, 약의 부작용에 대한
항목에서는 “효과 없음”(88.8%)으로 가장 많은 응답을 하였다. LCM에서의 첫 번째 집단과 같이 범주
1은 만족도가 매우 높고, 약의 효과도 상당히 높고, 약의 부작용 효과는 없는 특징을 보이는 집단으로 판
단된다. 범주 2에서는 LCM에서의 범주 2와 유사하게 만족도 항목에서 “만족”(40.0%)으로 가장 많은
응답을 했고, 약의 효과 항목에서 “매우 상당한 효과”(45.1%)로 가장 많은 응답을 했고, 약의 부작용에
대한 항목에서는 “약한 효과”(59.7%)로 가장 많은 응답을 하였다. 전반적으로 첫 번째 집단과 두 번째
Table 4.7. Latent class model for mixed variables of patient reviews on drugs
범주 1 범주 2 범주 3 범주 4 범주 5
잠재범주 비율 0.28 0.37 0.17 0.10 0.10
만족도
1 =매우 불만족 0.034 0.005 0.620 0.072 0.106
2 =불만족 0.024 0.046 0.224 0.099 0.114
3 =보통 0.045 0.134 0.084 0.168 0.110
4 =만족 0.191 0.430 0.051 0.371 0.379
5 =매우 만족 0.705 0.385 0.021 0.289 0.291
약의 효과
1 =효과 없음 0.033 0.005 0.368 0.046 0.037
2 =부분적 효과 0.028 0.034 0.161 0.099 0.045
3 =적당한 효과 0.070 0.140 0.167 0.225 0.142
4 =상당한 효과 0.269 0.371 0.173 0.301 0.308
5 =매우 상당한 효과 0.599 0.451 0.131 0.329 0.468
약의 부작용
1 =효과 없음 0.888 0.101 0.017 0.044 0.129
2 =약한 효과 0.104 0.597 0.041 0.470 0.297
3 =적당한 효과 0.000 0.249 0.212 0.365 0.359
4 =심한 효과 0.000 0.052 0.438 0.105 0.175
5 =매우 심한 효과 0.008 0.001 0.292 0.016 0.040
집단의 비중은 LCM에서 약 70%이고 LCMM에서 65%로 유사하지만 첫번째 집단의 비중은 LCMM에 서 더 줄어들었는데 이는 약에 대하여 큰 만족도를 보인 집단이 후기에서는 사용 경험에 대하여 약하지 만 부정적인 견해를 적은 것이 반영된 것으로 판단된다.
범주 3 역시 LCM에서의 범부 3과 유사하게 약에 대한 만족도 항목에서 “매우 불만족”(62.0%), 약의 효과 항목에서는 “효과 없음”(39.8%), 약의 부작용 항목에서는 “심한 효과”(43.8%)가 가장 많이 응답 된 집단으로 전반적으로 약의 만족도가 낮은 범주라고 볼 수 있다. 범주 4와 범주 5에서는 약의 부작용 효과 항목을 제외하고는 전반적으로 비슷한 성향을 보였다. 범주 4에서는 만족도에 서 “만족”(37.1%), 약의 효과에서 “상당한 효과”(32.9%), 약의 부작용 효과에서는 “약한 효과”(47.0%)가 가장 많은 응답 으로 나타났고, 범주 5에서는 범주 4와 유사하게 만족도에 대해 “만족”(37.9%), 약의 효과에 대해 “상 당한 효과”(46.8%), 약의 부작용 효과에서 “적당한 효과”(35.9%)가 많은 응답을 보였다. 두 범주에 속 하는 집단은 전반적으로 만족도가 높지만 동시에 부작용도 어느정도 경험한 집단으로 판단되지만 Table 4.7 에 나타난 응답확률만으로는 두 집단이 명확히 구분되지 않는다.
텍스트 자료를 이용한 LCMM 적합 결과를 보기 위하여 Figure 4.1에 각 잠재범주별 가장 많이 언급된 상위 10개의 단어를 정리하였다. Figure 4.1에서 가로측은 각 단어별로 추정된 포아송 모수 즉 예측 평 균 빈도수를 나타낸다. 또한, 이를 Figures 4.2–4.4에 잠재범주별로 word cloud 형태로 나타내었다. 이 를 통해, 먼저 5개의 범주 중 범주 1, 범주 2, 범주 4에서 “sleepy”가 가장 많이 언급되었다. 범주 1에 서 가장 많이 언급된 상위 단어로는 “sleepy”, “noticeable”, “treatment”, “work”, “blood”가 있었다.
다음으로, 범주 1에서는 다른 집단에서는 보이지 않은 단어 “nothing”이 상대적으로 많이 언급되었다.
또한, 환자에게 직접적인 부작용과 관련되지 않은 단어들 “work”, “nothing” 등 이 언급되었다. 이를 통해 부작용이 다른 집단에 비해 없는 환자들이 범주 1에 속한다고 볼 수 있다. 범주 2에서는 가장 많 이 언급된 상위 단어로는 “sleepy”, “nausea”, “mild”, “stomach”, “fatigue”가 있었다. 또한, 다른 집 단에서는 보이지 않은 단어 “mild”가 많이 언급되었다. 전반적으로 다른 범주에서 볼 수 있는 단어들 이 언급되었다. 범주 3에서는 가장 많이 언급된 상위 단어로는 “pain”, “stomach”, “nausea”, “head”,
“sleepy” 가 있었다. 범주 3에서는 “pain”, “stomach”과 같이 환자에게 직접적으로 부작용 효과가 드러 나는 단어들이 많이 언급되었다. 범주 4에서는 가장 많이 언급된 상위 단어로는 “skin”, “dry”, “red”,
“peel”, “eyes”가 있었다. 특징적으로, 범주 4에서는 단어 “skin”, “face” 등 외상과 관련된 단어가 많
이 언급되었다. 마지막으로, 범주 5에서는 가장 많이 언급된 상위 단어로는 “sleepy”, “eat”, “weight”,
Figure 4.1. Top 10 high-frequency words for patient reviews on drugs.
Figure 4.2. Word cloud in 1st latent class and 2nd latent class.
“night”, “blood”가 있었다. 특히 범주 5는 졸리거나 식욕감퇴등 일상생활에 지장을 받는 부작용이 더 언급되었는데 이때문에 Table 4.7에서 볼수 있듯이 범주 5에서 부작용에 대한 의견이 범주 4보다 강하 게 표현되었다고 판단된다.
기존의 LCM과 비교해보았을 때 LCMM은 잠재범주별 부작용의 세부 차이와 정도를 알 수 있었다.
LCMM 에서 텍스트 자료에 대한 모수 추정을 통해 관측 가능한 범주형 문항에 대해 응답 형태가 유사했
던 범주 간 차이를 알 수 있다. 예를 들어, 관측 가능한 범주형 문항에 대해 범주 4와 범주 5는 뚜렷한
차이를 보이지 않았지만 범주 4에서는 단어 “skin”, “face” 등 외상과 관련된 단어가 많이 언급되었고
Figure 4.3. Word cloud in 3rd latent class.
Figure 4.4. Word cloud in 4th latent class and 5th latent class.
범주 5에서는 일상생활과 관련된 단어들 “sleepy”, “eat”, “weight” 등이 언급된 것을 볼 수 있다. 또 한, 잠재범주별 부작용의 효과에 대해 세부 증상이 어느 정도 나타났는지 알 수 있었다. 예를 들어, 부작 용의 효과가 심각했던 범주 3에서는 “pain”, “stomach”과 같이 환자에게 직접적으로 영향을 주는 단어 들이 많이 언급되었다. 즉, 잠재범주의 상위 빈도 단어와 추정된 평균 빈도수를 통해 잠재범주별 부작용 의 세부 차이와 정도를 알 수 있었다.
5. 결론 및 토의
설문조사 등을 토대로 얻어진 자료에서 확률론적 모형을 통해 잠재된 요인을 찾아내는 기존의 연구는 대 부분 LCM에 기반한 방법인데 이는 분석의 편의성에 주로 기인한다고 볼 수 있다. 하지만 본 논문에서 예시로 든 의약품 후기나 혹은 영화 후기 등은 자료에 범주형 변수뿐만 아니라 텍스트 자료가 포함되는 경우가 대부분이다. 이러한 경우에 특히 글로 서술된 온라인 후기 등은 매우 유용한 많은 정보를 포함하 는 경우가 많은데 이때 텍스트 자료를 몇 가지 방법에 의해 정형화한 후 LCMM 방법을 사용한다면 자 료로부터 보다 유용한 정보를 얻을 수 있는 도구로 활용될 수 있을 것이라 기대된다.
References
Akaike, H. (1973). Information theory and an extension of the maximum likelihood principle. In B. N.
Petrov & F. Csaki (Eds), Second International Symposium on Information theory, 267–281. Budapest,
Akademai Kiado, Hungary.
Bockenholt, U. (1993). A latent class regression approach for the analysis of recurrent choices, British Journal of Mathematical and Statistical Psychology, 46, 95–118.
Bozdogan, H. (1987). Model selection and Akaike’s Information Criterion (AIC): The general theory and its analytical extensions, Psychometrika, 52, 345–370.
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977). Maximum likelihood estimation from incomplete data via the EM algorithm (with discussion), Journal of the Royal Statistical Society Series B, 39, 1–38.
Everitt, B. S. (1988). A finite mixture model for the clustering of mixed-mode data, Statistics and Proba- bility Letters, 6, 305–309.
Everitt, B. S. (1993). Cluster Analysis, Edward Arnold, London.
Feinerer, I., Hornik, K., and Meyer, D. (2008). Text mining infrastructure in R, Journal of Statistical Software, 25, 1–54.
Felix, G., Surya, K., Hagen, M., and Sebastian, Z. (2018). Aspect-Based Sentiment Analysis of Drug Reviews Applying Cross-Domain and Cross-Data Learning. In Proceedings of the 2018 International Conference on Digital Health. ACM, New York, NY, USA, 121–125.
Goodman, L. A. (1974). Exploratory latent structure analysis using both identifiable and unidentifiable models, Biometrika, 61, 215–231.
Haberman, S. J. (1979). Analysis of Qualitative Data, Vol 2. New Developments, Academic Press, New York.
Hagenaars, J. A. (1990). Categorical Longitudinal Data: Log-linear Analysis of Panel, Trend and Cohort Data, Sage, Newbury Park.
Lazarsfeld, P. F. (1950). The logical and mathematical foundation of latent structure analysis & The interpretation and mathmatical foundation of latent structure analysis. S.A. Stouffer et al. (Ed.), Measurement and Prediction, 362–472. Princeton, Princeton University Press, NJ.
Lazarsfeld, P. F. and Henry, N. W. (1968). Latent Structure Analysis, Houghton Mill, Boston.
Sammel, M. D., Ryan, L. M., and Legler, J. M. (1997). Latent variable models for mixed discrete and continuous outcomes, Journal of the Royal Statistical Society, Series B, 59, 667–678.
Schwarz, G. (1978). Estimating the dimension of a model, Annals of Statistics, 6, 461–464.
Sung, M., Chang, Y. E., and Seo, B. (2016). The roles of study habits and emotional-behavioral problems in predicting school adjustment classification among 3rd graders, Korean Journal of Childcare and Education, 12, 79–102.
Wedel, M., DeSarbo, W. S., Bult, J. R., and Ramaswamy, V. (1993). A latent class Poisson regression model for heterogeneous count data with an application to direct mail, Journal of Applied Econometrics, 8, 397–411.
Vermunt, J. K. (1997). Log-linear models for Event Histories, Sage Publications, Thousand Oakes.
혼합모드 잠재범주모형을 통한 텍스트 자료의 분석
신현수
a, 서병태
a,1a
성균관대학교 통계학과
(2019년 7월 1일 접수, 2019년 10월 18일 수정, 2019년 10월 20일 채택)
요 약
일종의 혼합다항분포 모형이라고 볼 수 있는 잠재범주모형은 범주형 자료에서 직접 관측되지 않은 중요한 정보를 얻 어낼 수 있는 유용한 도구이다. 하지만 자료에 범주형 변수 뿐 아니라 연속형 변수 혹은 빈도형 변수가 함께 포함 되어 있을 경우 이 모형을 직접적으로 사용할 수 없다. 본 논문에서는 특히 범주형 변수와 빈도형 변수가 함께 포함 되어 있는 경우에 잠재범주모형인 혼합모드 잠재범주모형을 사용하여 텍스트 후기와 범주형 응답문항이 모두 포함된 의약품 사용 후기자료를 분석하였다. 이 분석을 통해 범주형 응답만을 사용한 보통의 잠재범주 모형에 비해 텍스트 자료를 함께 사용한 혼합모드 잠재범주모형을 사용했을때 잠재범주에 대한 보다 자세한 정보를 얻을 수 있는 것을 확 인하였다.
주요용어: 잠재범주분석, 혼합모형, 군집분석, 텍스트마이닝
이 논문은 한국연구재단의 지원을 받아 수행된 기초연구 사업임 (NRF-2019R1F1A1059959).
1교신저자: (03063) 서울시 종로구 성균관로 25-2, 성균관대학교 통계학과. E-mail: [email protected]