Detection of Malicious PDF based on
Document Structure Features and Stream Objects
1)
전체 글
1)
수치
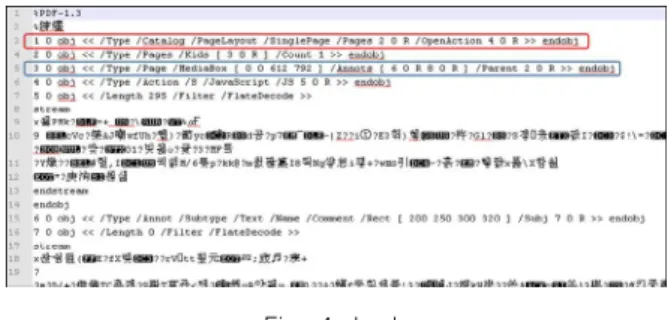
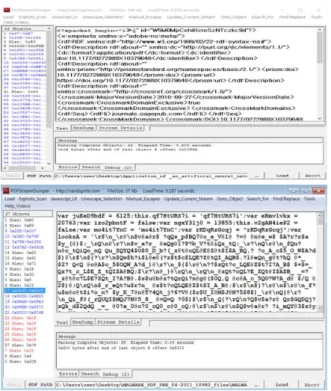
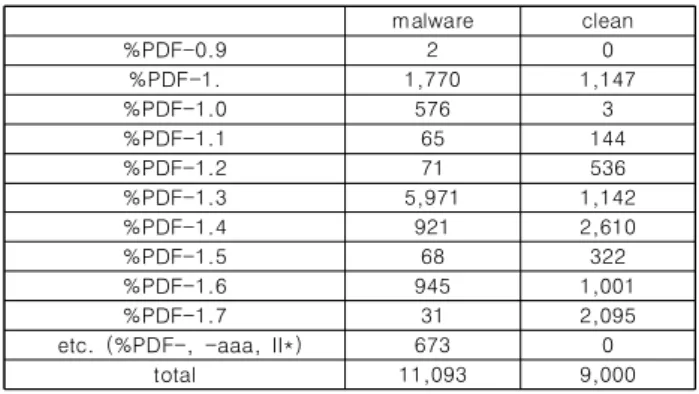

관련 문서
- "This work was supported by the Korea Foundation for the Advancement of Science and Creativity(KOFAC) grant funded by
- "This work was supported by the Korea Foundation for the Advancement of Science and Creativity(KOFAC) grant funded by the Korea government(MOE)"... 다양한
- "This work was supported by the Korea Foundation for the Advancement of Science and Creativity(KOFAC) grant funded by the Korea government(MOE)"..
- "This work was supported by the Korea Foundation for the Advancement of Science and Creativity(KOFAC) grant funded by the Korea government(MOE)"...
This work was supported by the Korea Foundation for the Advancement of Science and Creativity(KOFAC) grant funded by the Korea government(MOE)... 과연 그들에게
- "This work was supported by the Korea Foundation for the Advancement of Science and Creativity(KOFAC) grant funded by the Korea government(MOE)"... NFC 기술에
- "This work was supported by the Korea Foundation for the Advancement of Science and Creativity(KOFAC) grant funded by the Korea government(MOE)"... 여러분들이
- "This work was supported by the Korea Foundation for the Advancement of Science and Creativity(KOFAC) grant funded by the Korea government(MOE)"...
