Semi-automatic Legal Ontology Construction based on Korean Language Sentence Patterns
1)
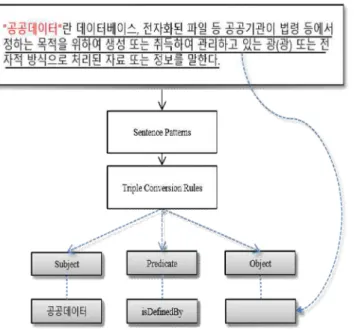
전체 글
1)
수치
![Table 4는 기존의 온톨로지 자동 구축 연구 방법들과 제안 하는 방법을 항목에 따라 비교해 놓은 것이다. M. Y. Dahab 외 2명[12]은 영어 문장으로부터 추출 가능한 시맨틱 패턴을 정의하고, 해당 패턴에 적용되는 단어들을 추출 하였다(Table 4에서 1)](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5317107.384996/3.892.457.802.210.425/기존의-온톨로지-방법들과-방법을-문장으로부터-정의하고-적용되는-단어들을.webp)
관련 문서
Based on the results, this study concluded that competitive power of construction business in uncertain management environment lies in human resources rather
Co The students must match safety signs to their places and write down a sentence using the target language.. ET The teacher shows the students some
Lessons 1 through 10 help students get acquainted with Korean vowels and consonants, while lessons 11 through 16 contain basic sentence patterns and
41 Developing Web Intelligence System of Construction Tacit Knowledge Based on Text
Resource Based Construction Rate Work Based. Construction
In this paper, it is implemented the image retrieval method based on interest point of the object by using the histogram of feature vectors to be rearranged.. Following steps
A Method for Line Parameter Estimation of Unbalanced Distribution System based on Forward/Backward Sweep Using..
This study, therefore, suggests that cooperative art activity based on collage can be used in the child education field for the improvement of