논문 2015-52-6-14
Positive Random Forest 기반의 강건한 객체 추적
( Positive Random Forest based Robust Object Tracking )
조 윤 섭*, 정 수 웅*, 이 상 근***
( Yunsub Cho, Soowoong Jeong, and Sangkeun Lee
ⓒ)
요 약
고성능 컴퓨터와 디지털 카메라의 보급으로 컴퓨터를 이용한 객체 탐지 및 추적은 컴퓨터 비전의 다양한 응용분야에서 중 요한 문제로 대두 되고 있다. 또한, 지능형 자동화 감시 장치, 영상 분석 장치, 자동화된 로봇 분야 등에서 그 필요성이 점점 부각 되고 있다. 객체 추적은 카메라를 이용하여 움직이는 객체의 위치를 찾는 처리 과정을 의미 하며, 강건한 객체 추적을 위 해서는 객체의 스케일, 형태 변화, 회전에 강건하고 정확한 객체의 위치를 파악할 수 있어야한다. 본 논문에서는 랜덤 포레스 트를 이용한 강건한 객체 추적에 대한 알고리즘을 제안하였다. 정확한 객체의 위치를 찾기 위해 지역 공분산과 ZNCC (Zeros Mean Normalized Cross Correlation)를 사용하여 객체를 검출하고 검출된 객체를 5개의 부분으로 나누어 랜덤 포레스트로 객 체가 잘 검출 되었는지 검증 한다. 검증된 객체 중 모델을 선택하여 객체 검출이 잘못 되었다고 판단된 경우 입력 모델을 변 경하여 정확한 객체를 찾도록 하였다. 제안된 알고리즘과 기존의 알고리즘들을 비교 하였을 때 비교적 정확한 객체의 위치를 잘 찾아 가는 것을 확인하였다.
Abstract
In compliance with digital device growth, the proliferation of high-tech computers, the availability of high quality and inexpensive video cameras, the demands for automated video analysis is increasing, especially in field of intelligent monitor system, video compression and robot vision. That is why object tracking of computer vision comes into the spotlight.
Tracking is the process of locating a moving object over time using a camera. The consideration of object’s scale, rotation and shape deformation is the most important thing in robust object tracking. In this paper, we propose a robust object tracking scheme using Random Forest. Specifically, an object detection scheme based on region covariance and ZNCC(zeros mean normalized cross correlation) is adopted for estimating accurate object location. Next, the detected region will be divided into five regions for random forest-based learning. The five regions are verified by random forest. The verified regions are put into the model pool. Finally, the input model is updated for the object location correction when the region does not contain the object. The experiments shows that the proposed method produces better accurate performance with respect to object location than the existing methods.
Keywords : Region Covariance, Random Forest, ZNCC(Zero Mean Normalized Cross Correlation)
* 학생회원, ** 평생회원, 중앙대학교 첨단영상대학원 영상학과
(Department of Image Engineering, Graduate School of Advanced Imaging Science, Multimedia, and Film, Chung-Ang University)
ⓒ Corresponding Author(E-mail: [email protected])
※ 이 논문은 2015년도 중앙대학교 두뇌한국(BK)21 PLUS 사업과 2014년도 미래창조과학부와 교육부 의 재원으로 한국연구재단에서 지원을 받아 수행 된 연구(No. NRF-2014R1A2A1A11049986 / NRF-2014S1A5B6037633)입니다.
Received ; January 2, 2015 Revised ; May 20, 2015 Accepted ; May 26, 2015
Ⅰ. 서 론
최근 고성능 처리 장치 및 고품질 카메라의 보급으로 자동화된 영상분석을 위한 객체 추적 알고리즘에 대한 관심이 많아지고 있다. 특히 지능형 감시시스템, 비디오 압축 및 편집, 로봇 비전, 증강현실 등의 다양한 분야에 서 각광받고 있기 때문에 컴퓨터 비전 분야에서 중요성 이 강조되고 있다[1].
하지만 객체 추적은 조명변화, 객체의 포즈변화, 객체 의 크기변화, 저해상도 등으로 인해 정확한 객체의 위 치 추적이 힘든 문제점이 있으며, 이러한 문제점을 해 결하고자 최근 다양한 연구가 활발히 진행되고 있다.
객체 추적 분야는 크게 세 가지 방향으로 연구가 진 행 되고 있다[2]. 첫 번째로 특징을 이용한 객체 추적은 영상에서 얻을 수 있는 특징인 Gradients, Color, Texture, Multiple Feature Fusing등을 이용하여 객체 를 추적하는 방법이며, 대표적으로 Mean shift[3], Cam shift[4]등이 여기에 해당한다. Cam Shift는 Mean Sift를 개선한 알고리즘으로 색상을 비모수적 방법으로 찾아가 는 방법에 Blob이라는 개념을 추가하여 더 강건하게 객 체를 추적하는 방법이며, 객체의 크기에 적응적으로 객 체 추적을 할 수 있으며 객체의 모양변화 회전에 대해 서 강건하다.
두 번째로 통계적인 방법인 몬테 카를로 방법은 행동 을 시뮬레이션하기 위한 수학적 계산 알고리즘을 이용 하여 객체를 추적한다. 대표적으로 파티클 필터[5], 칼만 필터[6] 등이 이에 해당한다. 파티클 필터의 경우 몬테 카를로 방법을 이용하여 반복적으로 상태 공간의 사후 확률을 측정하고 이를 기반으로 객체를 추적하기 때문 에 강건하게 객체를 추적 할 수 있다.
세 번째로 학습기반의 객체 추적 방법으로 학습을 통 하여 시간에 따라, 움직임에 따라 변하는 객체의 변화 를 학습시킴으로서 정확한 데이터가 많아질수록 더욱 강건한 객체 추적을 할 수 있으며, 대표적인 학습 기반 의 객체 추적방법으로 TLD(Tracking Learning Detection)[7]이 있다. 이 방법은 객체를 검출하는 검출 자와 추적을 하는 추적자를 이용하여 객체 추적을 한 다. 검출자와 추적자를 이용하여 객체를 검출하고 검출 된 결과를 비교하여 객체인지 아닌지 확인을 한다. 이 렇게 검출된 객체는 다시 학습 데이터로 쓰이게 되며 변화하는 객체에 대해서 능동적으로 데이터를 축적하며 객체를 추적 할 수 있다.
위와 같이 다양한 방법 중 학습 기반의 객체 추적 방 법을 이용한 객체 추적 방법은 객체를 학습 하여 추적 함으로써 객체의 외형에 대한 변화나 다양한 외부의 변 화에도 강건한 객체 추적성능 결과를 보여주었다. 이와 관련한 학습 기반의 대표적인 알고리즘으로는 MIL[8]
Tracker, TLD[7] Tracker가 있다.
MIL Tracker라고 불리는 방법은 Harr-Like 특징을
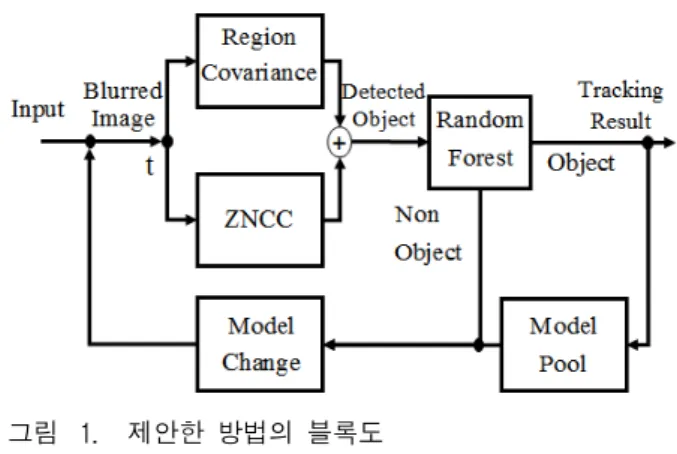
그림 1. 제안한 방법의 블록도
Fig. 1. Block diagram of the proposed algorithm.
이용하였고, 첫 번째 프레임에 객체 내에 인스턴스들을 Positive로 라벨링하고 객체영역을 제외한 배경영역에 서 영역을 선택하여 그 영역의 인스턴스들을 Negative 로 라벨링을 한 후 MIL 분류기로 학습을 시킨다. 학습 된 MIL 분류기를 이용하여 객체의 위치를 찾게 되는데, MIL appearance model을 하나의 Positive bag와 여러 개의 Negative bag를 가지고 업데이트를 하며 지속적 으로 객체의 위치를 찾게 된다.
위에서 언급한 TLD 방법은 P-N Tracker라고도 하 며 이 방법은 옵티컬 플로우 기반의 추적기와 Random Ferns 검출기를 이용하여 객체를 추적 한다. 최초 프 레임에서 추적기와 검출기를 모두 초기화 하고 이후 영 상이 들어오면 추적기로 대상을 찾고, 검출기로도 대상 을 찾아 추적에 성공하였다면 학습데이터로 활용하여 검출기를 학습 시키게 된다. 만일 추적에 실패하였다면 검출기가 대상을 찾을 때 까지 추적을 멈추고 다시 객 체를 찾게 되면 검출된 위치로 추적기를 초기화 하여 다시 추적하는 방식을 가지고 있다.
움직이는 객체에 대하여 정확한 객체 추적을 위하여 객체 검출 성능 또한 정확하여야 한다. 때문에 모양변 화에 강건한 지역 공분산(Region Covariance)[9]와 스케 일에 변화에 민감한 ZNCC(Zeros mean Normalized Cross Correlation)[10]을 이용하여 형태변화와 스케일에 대한 추정에 강건한 객체 검출 방법을 제안한다.
앞서 언급한 기존의 방법들은 최초 객체를 학습함에 있어서 항상 Positive와 Negative가 있어야하며 학습 데이터에 따라 성능이 달리 짐에도 불구하고 객체를 제 외한 배경영역에서 랜덤으로 Negative 데이터를 학습하 는 문제가 있다. 따라서 검출된 객체만을 가지고 객체 를 제대로 찾았는지 아닌지를 판단하기 위하여 지역 공
분산과 랜덤 포레스트[11]를 이용하여 정확한 객체를 찾 았는지에 대한 사후 확률을 구하는 방법을 제안한다.
또한, 객체 추적은 움직이는 대상을 추적하는 것이기 때문에 추적하고자 하는 객체의 외형의 변화가 있을 수 있다. 때문에 정확히 찾아진 객체를 대상으로 모델 풀 을 구성함으로써 정확한 객체가 찾아지지 않았을 경우 모델을 변경하여 객체 추적 성능을 향상시켰다.
본 논문의 구성은 다음과 같다. Ⅱ장에서는 객체를 찾기 위한 모델 구성과 지역 공분산, ZNCC(Zero Mean Cross Correlation)을 이용한 강건한 객체 추적 방법에 대해 설명한다. Ⅲ장에서는 찾아진 객체의 사후 확률을 계산하고 모델 풀에 있는 모델을 업데이트하는 방법에 대해 설명한다. Ⅳ장에서는 제안된 알고리즘과 기존의 알고리즘간의 성능을 비교분석하고 Ⅴ장에서는 본 논문 에 대한 결론을 서술한다.
Ⅱ. ZNCC와 지역 공분산을 이용한 객체 검출
ZNCC는 영역의 상관관계를 구하는 것이다. 구하는 과정에서 조명변화에 영향을 적게 받기 위해 평균을 빼 고 각 좌표마다 상관관계를 구한 후 구해진 상관관계를 모두 합하여 영역에 대한 상관관계를 나타낸다. 이 방 법은 스케일에 대해 민감하고 평평한 영역에서 상관관 계가 높게 나오는 경우가 발생한다. 그에 반면에 지역 공분산은 영역을 하나의 공분산 행렬로 나타낼 수 있 다. 때문에 스케일 변화에 ZNCC보다 민감하지 않고 객 체의 회전, 형태 변화에 대하여 강건하다. 때문에 ZNCC의 문제를 보완하기 위하여 지역 공분산을 이용 하여 문제를 해결하고자 한다.
1. ZNCC를 이용한 객체 검출
ZNCC와 지역 공분산를 구하기전 객체 모델은 다양 한 변화에 강건할 수 있고 움직이면서 생기는 모션 블 러에 대한 성능저하를 감소시키기 위하여 블러를 시킨 영상을 대상으로한다.
ZNCC를 이용한 매칭 방법은 객체의 위치를 찾는 것 에 많이 쓰이고 있으며 조명변화에 강건하다고 알려져 있다. 하지만 평평한 곳에서 다른 객체와 상관관계가 높은 치명적인 약점이 있다. 때문에 ZNCC만이 아니라 지역 공분산을 이용하여 객체의 검출 성능을 높이고자 한다.
( , ) ZNCC x y =
( ) ( ( )) ( ) ( ) ( ) ( ( )) ( ) ( )
1 1
2 2
1 1 1 1
, , ,
, , ,
N M
c x y
N M N M
c
x y j i
I x i y j I i j T x y T
I x i y j I i j T x y T
μ μ
μ μ
= =
= = = =
⎡ + + − ⎤⎡⎣ − ⎤⎦
⎣ ⎦
⎡ + + − ⎤ ⎡⎣ − ⎤⎦
⎣ ⎦
∑∑
∑∑ ∑∑
i
i
(1)
ZNCC는 수식 (1)에 의해 구해지며 구해진 값의 범위 는 0∼1까지의 범위를 가진다. 1에 가까울수록 객체와 의 상관관계가 높고, 0에 가까울수록 객체와의 상관관 계가 낮다.
위 수식에서 는 영상, 는 템플릿, 는 평균, 는
축 좌표, 는 축 좌표를 의미한다.
그림 2. 적분영상의 계산
Fig. 2. Integral image computation.
2. 지역 공분산을 이용한 객체 검출
지역 공분산은 객체의 회전, 형태변화에 강건하고 다 양한 객체의 특징을 이용하여 정방행렬의 특징으로 나 타낼 수 있다. 본 논문에 지역 공분산에 사용되는 특징 이미지는 색상 성분의 HSV와 1차 그라디언트, 2차 그 라디언트로 구성하여 색상과 형태도 고려하여 수식 (2) 과 같이 구성한다.
2 2
2 2
( , ) ( , ) ( , ) ( , ) ( , ) ( , ) ( , ) ( , )
I x y I x y I x y I x y T
F x y H x y S x y V x y
x y x y
⎡ ∂ ∂ ∂ ∂ ⎤
= ⎢⎣ ∂ ∂ ∂ ∂ ⎥⎦
(2)
특징 이미지를 이용하여 지역 공분산을 구하는 식은 식(3)와 같이 정의된다.
( )( )
1
1 1
n T
R k k
k
C z z
n
μ μ=
= − −
−
∑ (3)
수식 (3)에서 은 전체 픽셀의 개수, 는 특징 이미 지에서의 값, 는 특징에 해당하는 평균을 의미 한다.
위 수식에서 지역 공분산은 특징 이미지에서 구성된 특 징에 해당하는 개수의 정방행렬이 영역의 크기에 상관
없이 생성된다. 생성된 지역 공분산과의 오차를 구하기 위해서는 수식 (4)를 이용한다.
2
1 2 1 2
1
( , ) n ln i( , )
i
C C C C
ρ λ
=
=
∑ (4)
수식 (4)에서 는 각 영역의 지역 공분산이고
는 고유 값을 의미한다. 전체 영상에서 다음과 같은 연산을 수행할 때 매번 같은 연산하기 때문에 연 산량이 많다. 때문에 전체적으로 한번 처리하고 속도를 높이기 위해 적분영상을 이용하여 연산량을 줄였다. 적 분영상은 수식 (5)과 같다.
( ) ( )
', '
', ', , ,
x x y y
P x y i F x y i
< <
=
∑
( ) ( ) ( )
', '
', ', , , , , ,
x x y y
Q x y i j F x y i F x y j
< <
=
∑ (5)
위의 수식에서 는 영상의 좌표를 의미하고, 는 특징의 개수를 의미 한다. 다음과 같은 연산을 했을 때 얻어지는 는 수식 (6)과 같다.
( ) ( )
( ) ( )
( ) ( )
,
,
, , 1 , ,
, , 1 , 1 , , 1 , 1
, , , 1 , , ,
T x y
x y
p P x y P x y d
Q x y Q x y
Q
Q x y d Q x y d d
= ⎡⎣ ⎤⎦
⎡ ⎤
⎢ ⎥
= ⎢ ⎥
⎢ ⎥
⎣ ⎦
(6)
를 이용한 Region Covariance를 구할 때 구하고 자 하는 객체가 그림 2과 같을 때 수식 (7)과 같이 계산 할 수 있다.
( )( )
(x',y';x'',y'') '', '' ', ' '', ' ', ''
'', '' ', ' '', ' ', '' '', '' ', ' '', ' ', ''
1 [ 1
1 ]
R x y x y x y x y
T
x y x y x y x y x y x y x y x y
C Q Q Q Q
n
P P P P P P P P
n
= + − −
−
− + − − + − −
(7)
수식 (7)에서 ,는 수식 (6)에서 정의 되었으며 은 영역내의 픽셀 개수를 의미한다.
2. ZNCC와 지역공분산을 이용한 객체 검출 객체를 검출하기 위해서는 탐색영역 내에서 모델과 의 오차를 구하여야 한다. 이때 우리는 ZNCC와 지역 공분산을 이용하여 탐색영역에 대한 오차 값을 얻을 수 있고, 이것을 에러맵이라고 정의하였다. ZNCC의 에러 맵과 지역 공분산의 에러맵을 서로의 장점을 취하고 단 점을 보완하기 위하여 수식 (8)와 같이 ZNCC와 Region
Covariance의 에러맵을 결합한다.
( ) ( )
1
max max
Z R
Z R
E E
E E E
= − +
(8)
은 결합된 에러맵, 는 ZNCC의 에러맵, 은 지역 공분산의 에러맵을 의미한다. 두 에러는 서로 다른 특 징, 방법을 이용하여 구하였기 때문에 서로 독립적이다.
하지만 ZNCC의 값의 범위는 1~0의 범위, 지역 공분산 의 값의 범위는 0에서 무한대까지의 범위를 가질 수 있 기 때문에 탐색 영역에서 구한 각 에러맵들의 에러 값 들을 정규화 시켜주기 위하여 각 에러맵의 최대값을 이 용하여 정규화를 시킨다. 위와 같이 을 통해 얻어진 에러맵의 최솟값을 찾아 객체를 검출한다. 또한, 객체를 검출할 때 객체의 크기가 달라짐에 따라 객체 검출의 성능에 저하가 발생할 수 있다. 그러므로 객체의 크기 를 고려하기 위하여 이미지 피라미드를 이용하여 객체 의 크기를 고려하는 방법을 사용하였으며, 현재의 객체 의 크기와 다음 프레임의 객체의 크기의 변화는 크지 않을 것이기 때문에 현재 객체의 스케일을 기준으로 크 기를 크게/작게 하여 계산 한다. 지역 공분산 객체의 크 기에 영향을 받지 않기 때문에 이미지 피라미드를 사용 하는 것이 아닌 비교하고자 하는 영역을 이미지 피라미 드로 구해진 영상과 같은 크기로 사용하여 계산한다.
2 min( , )
sl
= ×5w h (9)
ZNCC와 지역 공분산은 영상의 탐색영역 안에서 구 해지게 되며 탐색 영역은 그림 3과 같이 정의한다. 그 림 3에 서 는 각각 객체의 가로와 세로의 값을 의미 하며, 은 수식 (9)과 같이 구하여진다.
그림 3. 탐색 영역 Fig. 3. Search range.
그림 4. 객체 클래스 분할 Fig. 4. Object classes.
Ⅲ. 랜덤 포레스트와 모델 풀을 이용한 객체 추적
모델 하나를 이용하여 모든 프레임에서 정확한 객체 를 검출하기엔 어렵다. 때문에 변화하는 객체에 대하여 여러 모델을 이용하여 정확한 객체의 위치를 파악해야 하며, 모델은 정확한 객체여야 한다. 정확한 객체를 모 델로 사용하기 위하여 첫 번째 프레임부터 학습된 랜덤 포레스트를 이용하여 객체의 신뢰도를 구할 수 있다.
객체의 신뢰도 높은 영역을 찾았다면 이전 모델과 비교 하여 형태가 달라진 객체를 모델로 사용하고 신뢰도가 낮은 경우 모델 중 하나를 선택함으로써 정확한 객체를 추정 하도록 한다.
1. 랜덤 포레스트를 이용한 예측
본 논문에서는 변화하는 객체에 대하여 정확한 객체 의 위치를 찾았는지 판별하기 위해 랜덤 포레스트를 사 용하였다. 랜덤 포레스트는 기계학습 알고리즘중 하나 로 L.Breiman에 의해 제안 되었으며, 결정 이진 트리의 앙상블 분류기로, 랜덤한 방법을 사용하여 각 트리들을 성장시킨다. 랜덤 포레스트는 결정 트리를 기본으로 하 고 있기 때문에, 빠른 학습 속도와 많은 양의 데이터 처 리 능력, 다양한 클래스 분류를 할 수 있다. 학습 데이 터로 들어가는 특징의 개수는 모두 같은 것이 좋다. 때 문에 영역의 크기에 상관없이 항상 특징 개수의 정방행 렬을 가지는 지역 공분산를 특징으로 사용한다.
일반적으로 객체와 배경을 구별하기 위하여 랜덤 포 레스트를 사용할 때 객체를 포지티브 데이터로 객체를 제외한 영역에서 랜덤으로 선택하여 네거티브 데이터로 사용한다. 랜덤 포레스트는 교사 학습 종류 중 하나이 며, 학습 데이터에 따라 성능이 달라지기 때문에 랜덤 으로 배경 영역을 네거티브로 데이터로 사용하는 것은 성능에 좋지 않은 영향을 줄 수 있다. 그러므로 제안된 방법은 포지티브 네거티브로 나누는 것이 아닌 그림 4 과 같이 객체를 여러 개의 클래스로 나누어 객체인지
그림 5. 오버랩 된 객체의 영역 Fig. 5. Overlapped object regions.
판단하도록 한다. 이 방법은 기존의 방법에서 어떤 것 을 네거티브로 사용할 것인가가 아닌 객체만으로 검출 된 객체의 제대로 된 것인지 아닌지를 판단 할 수 있으 며 현재 프레임에서 사용된 모델을 통하여 정확한 객체 를 찾았는지에 대한 평가를 할 수 있다.
첫 프레임에서 객체를 그림 4과 같이 각 클래스로 분 류하고, 데이터의 개수가 많을수록 랜덤 포레스트의 성 능이 좋기 때문에 그림 5와 같이 현재 좌측 상단 좌표 를 기준으로 축으로 -1부터 1까지, 축으로 -1부터 1 까지 총 9개의 오버랩 된 객체의 영역을 생성하고 각각 지역 공분산을 구한다.
한 프레임에서 얻어지는 지역 공분산은 클래스의 개 수 5개, 오버랩 된 좌표 9개로 총 45개의 특징이 생성되 고 이 특징들의 이상적인 결과를 알고 있기 때문에 다 음 수식 (10)와 같이 객체인지 아닌지를 판단한다.
Obect Probability nCorrectResult nClass nCooldinate
= ×
(10)
는 클래스의 개수, 는 기준 좌표의
개수, 는 랜덤 포레스트를 통한 예측된 클
래스와 Ground Truth와 비교하여 올바른 경우의 개수 를 나타낸다. 구해진 학습데이터를 이용하여 랜덤 포레
스트의 트리를 학습시킨 후 매 프레임 객체인지 아닌지 를 판단하고 객체라고 판단된다면 학습을 시킨다. 또한 객체가 아니라면 모델영상을 모델 풀에서 대체하여 객 체를 성공적으로 객체를 추적한다.
2. 모델 풀 구성 및 업데이트
하나의 모델로 모든 프레임에서 객체를 추적할 수 없 다. 때문에 객체의 외형이 변화 되었을 때 적절한 모델 을 사용함으로써 객체의 추적 성능을 높이고자 하였다.
ZNCC와 지역 공분산로부터 검출 되어 랜덤 포레스 트로 객체라 판단된 영역을 대상으로 모델들과 에러 값 을 구하고, 이미 있는 모델과 다른 형태의 모델을 구하 기 위하여 임계값 이상이 되는 객체를 대상으로 모델 풀을 구성한다.
( )
( )
min ρ C Cc, mi >θ , i=1 n
(11)
수식 (11)에서 는 객체라 판단된 영역에 대한 지역 공분산, 모델 풀에 있는 모델들의 공분산, 는 임계 값, 은 모델 풀에 있는 모델들의 수이다. 그림 6은 228 개의 프레임들에 대하여 모델 풀을 구성하였을 때 나온 모델들이다.
3. 모델 풀 활용
구성된 모델 풀은 움직이는 객체에 대하여 다양한 포 즈와 형태를 보이고 있다. 때문에 움직임에 의해 변화 되는 객체에 대하여 알맞은 객체를 모델로 사용함으로 써 객체의 추적 성능을 향상 시킬 수 있다.
모델을 바꾸는 시기는 랜덤 포레스트를 통하여 객체
그림 6. 구성된 모델 풀 Fig. 6. Constructed model pool.
가 아닌 경우가 발생 된다면 모델을 변경하여 객체를 추적하고 이후 객체가 아닌 경우가 발생 될 때 까지 모 델을 유지하며 객체 추적한다.
Ⅳ. 실 험
제안된 방법의 성능을 평가하기 위하여 CVPR 2013 Online Object Tracking : A Benchmark[12]에 포함된 다른 알고리즘들의 결과와 영상을 이용하여 결과를 비 교하였다. 비교된 알고리즘은 기존 널리 알려진 Color Based Probabilistic Tracking(CPF)[13], Mean shift Blob Tracking through Scale Space(SMS)[14] 학습기반 의 알고리즘들로 Real Time Tracking via On-line Boosting(OAB)[15], Semi-supervised On line Boosting for Robust Tracking(SBT)[16], Beyound semi supervised Tracking(BSBT)[17], P-N learning(TLD)[7], Context Tracker(CXT)[18]와 비교하였고 오차를 구하는 방법은 객체의 영역을 정확하게 포함하였는지를 확인하 기 위하여 수식(12)과 같이 오차를 정의한다.
( ) ( )
( ) ( )
2 2
1 1 1 1
2 2
2 2 2 2
1
2
1 2
2
d R x G x R y G y
d R x G x R y G y
d d
E r r o r
= − + −
= − + −
= +
(12)
식 (12)에서 와 는 추적 결과의 좌측상 단과 실제 좌표의 좌측상단을 나타내며, 와
는 추적 결과의 우측하단과 실제 좌표의 우측 하단을 나타낸다. d1과 d2의 유클리디언 거리(Euclidean Distance)를 구하여 평균을 구하여 영역을 제대로 포함 하였는지 제대로 포함하지 못하였는지에 대한 오차로 사용한다.
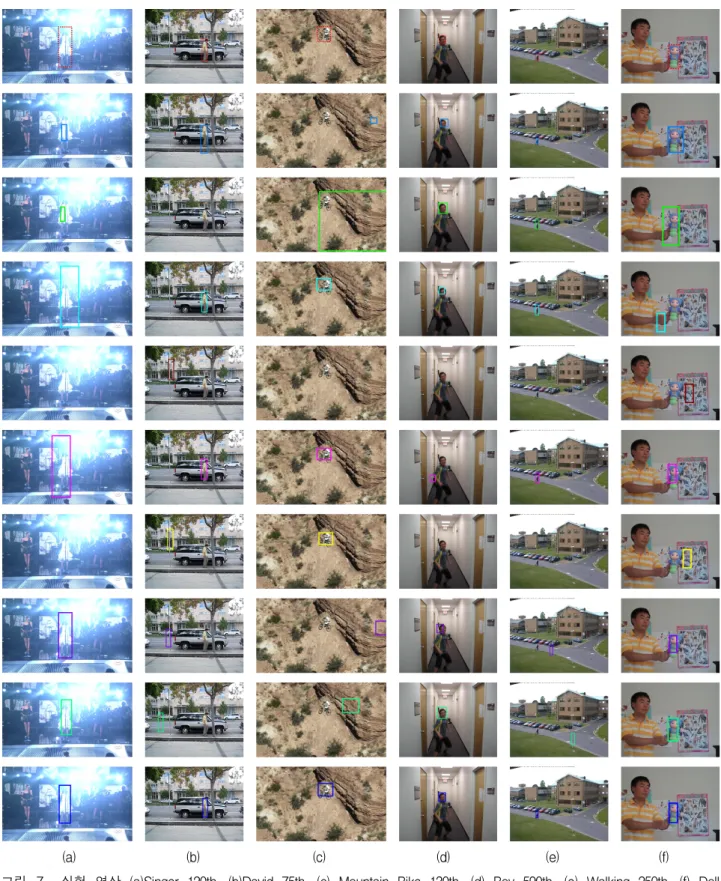
그림 7은 실험 영상들과 그 중간 결과이다. 그림 7은 각 영상과 알고리즘들의 결과를 나타내고 있으며, 영상 내에 객체의 위치를 나타내는 박스가 없는 경우 이전 프레임에서 알고리즘의 오류로 결과를 알 수 없는 경우 를 나타낸다.
그림 7에 (a) 영상의 특징은 조명변화, 스케일 변화, 폐색, 객체 회전, (b)는 폐색, 비강체의 객체, 객체와 비 슷한 배경, 객체 회전, (c)는 객체 회전, 객체와 비슷한 배경, (d)는 스케일 변화, 모션 블러, 빠른 움직임, 객체
(a) (b) (c) (d) (e) (f) 그림 7. 실험 영상 (a)Singer 120th, (b)David 75th, (c) Mountain Bike 130th, (d) Boy 590th, (e) Walking 250th, (f) Doll
2500th, 상단에서부터 하단까지 각각 실측 좌표, CPF, SMS, OAB, SBT, MIL, BSBT, TLD, CTX, 제안한 방법의 결과
Fig. 7. Experimental results. (a) Singer 120th frame, (b) David 75th frame, (c) Mountain Bike 130th frame, (d) Boy 590th frame, (e) Walking 250th frame, (f) Doll 250th frame. From top to bottom : Ground truth, CPF, SMS, OAB, SBT, MIL, BSBT, TLD, CTX, and Proposed method.
CPF[13] SMS[14] OAB[15] SBT[16] MIL[8] BSBT[17] TLD[7] CXT[18] Prop.
Singer 38.7 32.1 85.6 437.4 86.2 410 16.2 22.8 8.2
David 28.3 220.9 103.1 280.9 38.1 354.5 152.1 256.1 17.4
Bike 275 234.2 18.5 405.5 11.9 385.1 102.4 165.1 14
Boy 7.8 10.2 5.8 121.1 35.9 292.3 10.9 6.1 3.5
Walking 6.7 19.7 15.4 443.6 16 485.3 116.3 255.4 6.1
Doll 15.2 87 107.5 181.8 181.8 32.5 19.8 9.5 11.6
Avg. 61.95 100.68 55.98 311.71 61.65 326.61 69.616 119.16 10.13
표 1. 영상별 평균 에러
Table 1. Average error for each sequence.
회전, (e) 스케일 변화, 폐색, 비강체, (f)는 조명변화, 스케 일 변화, 폐색, 회전등 객체 추적을 방해하는 요소가 있 다. 실험에 쓰인 영상들은 대부분 객체의 형태 변화와 스 케일 변화를 가지고 있다. 또한 검출된 영역을 랜덤포레 스트를 통하여 정확한 객체인지 판단하고 모델 풀 구성 과 이용을 잘하여 객체 성능이 향상 되었는지를 확인하 기 위하여 수식 (11)의 식을 이용하여 각 프레임 별 오차 를 구한다.
표 1은 영상과 알고리즘별로 각 프레임 별 실측값과 의 오차를 나타낸다. TLD 알고리즘은 객체 추적에 실 패 하였을 경우 추적을 멈추고 객체를 찾을 때 까지 지 속 적으로 객체를 검출한다. 검출 되지 않았다면 매 프 레임 지속적으로 검출을 시도하게 되는데 이때 객체의 위치를 알 수 없기 때문에 몇몇 영상에서 객체의 위치 를 파악할 수 없다. 때문에 객체의 위치를 알 수 없는 프레임은 오차를 계산하지 않고 찾아진 프레임에서만 계산을 한다.
표 1 에서 볼 수 있듯이 정확한 객체의 위치를 파악
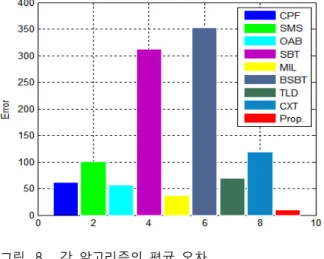
그림 8. 각 알고리즘의 평균 오차 Fig. 8. Average error for each algorithm.
할 수 있다. 실험한 영상에서 전반적으로 정확한 객체 의 위치를 파악한다. 각 영상의 알고리즘별 평균 오차 를 이용하여 오차를 구하면 그림 8과 같다.
그림 8에서 제안한 방법은 객체의 크기 변화를 잘 반 영하지만 객체의 형태 변화에 민감한 ZNCC와 객체의 형태 변화에 강건 하지만 크기 변화를 잘 반영 하지 못 하는 지역 공분산을 이용하여 검출능력을 향상 시켰고, 랜덤포레스트를 이용한 신뢰성 있는 모델 선택 하여 변 화하는 객체의 형태 변화에 대하여 능동적으로 대처하 였기 때문에 다른 알고리즘들에 비하여 낮은 평균 오차 값을 가지는 것을 확인 하였다.
Ⅳ. 결 론
본 논문에서는 객체의 크기의 변화 감지에 좋지만 형 태 변화에 민감한 ZNCC와 크기 변화를 파악하는데 좋 지 않지만 형태의 변화에 강건한 지역 공분산을 이용하 여 객체의 정확한 위치를 파악하는 방법을 제안하였다.
또한, 기존의 배경영역과 객체의 영역을 학습하는 방법 과는 다르게 객체의 영역을 여러 영역으로 나누어 랜덤 포레스트로 학습함으로써 정확한 객체의 검출 유무를 판단하는 방법을 제안 하였다.
제안된 방법에서 정확한 객체로 판단된 경우 지역 공 분산 오차를 통하여 일정 임계값 이상인 영상을 모델 풀에 넣게 되고, 정확한 객체로 판단되지 않은 경우 모 델 풀에 있는 모델로 변경하여 객체를 재 검출 하였다.
제안된 방법은 객체의 검출을 여러 영상에서 테스트 를 해보았을 때 기존의 방법들보다 평균적으로 낮은 오 차 값을 가지는 것을 확인 하였다. 하지만 객체의 완전 한 폐색된 환경, 시간을 고려하지 않았기 때문에 향후
폐색된 환경과 속도측면에서도 좋은 결과가 나올 수 있 도록 연구를 할 예정이다
REFERENCES
[1] A. Yilmaz, O. Javed, and M. Shah, “Object tracking: a survey,” Association for Computing
Machinery, vol. 38, no. 4, pp. 1–45, 2006.
[2] H. Yang, L. Shao, F. Zheng, L. Wang, and Z.
Song, “Recent advances and trends in visual tracking: A review,” Neurocomputing, vol. 74, no. 18, pp. 3823–3831, Nov. 2011.
[3] D.Jeong, D. Kang, Y. Yang, and J. Ra, “A real-time head tracking algorithm using mean-shift color convergence and shape based Refinement,” Journal of The Institute of Electronics Engineers of Korea, vol. 42SP, no.6, pp. 1-8, Nov. 2015.
[4] D. Kim, S. Lee, and S. Ko, “Target modeling with color arrangement for region-based object tracking,” Journal of The Institute of Electronics Engineers of Korea, vol. 49SP, no.1, pp. 1-10, Jan. 2012.
[5] K. Nummiaro, E. Koller-Meier, and L. Van Gool,
“An adaptive color-based particle filter,” Image
and Vision Computing, vol. 21, no. 1, pp.
99-110, 2003.
[6] G. Welch, and G. Bishop. An introduction to the kalman filter. Technical report, UNC-CH Computer Science Technical Report 95041, 1995.
[7] Z. Kalal, J. Matas, and K. Mikolajczyk, “P-N learning: Bootstrapping binary classifiers by structural constraints,” IEEE Conference on
Computer Vision and Pattern Recognition, pp.
49–56, Jun. 2010.
[8] B. Babenko, M. Yang, and S. Belongie, “Visual tracking with online multiple instance learning,”
in Proceeding IEEE Conference on Computer Vision and Pattern Recognition, pp. 983–990,
Jun. 2009.[9] O. Tuzel, F. Porikli, and P. Meer, “Region covariance: A fast descriptor for detection and Classification,”
European Conference on Computer Vision, vol. 2, pp. 589-600, 2006.
[10] J.P. Lewis, “Fast normalized cross-correlation,”
Vision Interface, 1995.
[11] A. Liaw, and M. Wiener, “Classification and regression by randomforest,” R News, vol. 2, no.
3, pp. 18–22, 2002.
[12] Y. Wu, J. Lim, and M.-H. Yang, “Online object tracking: A benchmark,” IEEE Conference on
Computer Vision and Pattern Recognition, pp.
2411–2418, 2013.
[13] P.Feguth and D. Teropulos, “Color-Based Tracking of Heads and Other Mobile Object at Video Frame Rates," IEEE Conference on
Computer Vision and Pattern Recognition,
pp.21-27, 1997.[14] R. Collins, “Mean shift blob tracking through scale space,” IEEE Conference on Computer
Vision and Pattern Recognition, pp. II: 234–240,
Jun. 2003.[15] H. Grabner, M. Grabner, and H. Bischof,
“Real-Time Tracking via Online Boosting,”
Proceeding Conference on British Machine Vision, pp. 47-56, 2006.
[16] H. Grabner, C. Leistner, and H. Bischof,
“Semi-Supervised Online Boosting for Robust Tracking,” in Proceeding European Conference
on Computer Vision, 2008.
[17] S. Stalder, H. Grabner, and L. van Gool,
“Beyond Semi-Supervised Tracking: Tracking Should Be as Simple as Detection, But Not Simpler than Recognition,”
in Proceeding Workshop on Online Learning for Computer Vision, 2009.
[18] T. B. Dinh, N. Vo, and G. Medioni, “Context tracker: Exploring supporters and distracters in unconstrained environments,” IEEE Conference
on Computer Vision and Pattern Recognition,
pp.1177-1184, Jun. 2011.저 자 소 개 조 윤 섭(학생회원)
2013년 선문대학교 정보통신공학 과 학사 졸업.
2015년 중앙대학교 첨단영상대학 원 영상학과 석사 졸업.
<주관심분야 : 객체추적, 패턴인식, 컴퓨터 비전>
정 수 웅(학생회원)
2010년 남서울대학교 멀티미디어 학과 학사 졸업.
2012년 중앙대학교 첨단영상대학 원 영상학과 석사 졸업.
2012년~현재 중앙대학교 첨단영 상대학원 영상학과 박사 과정.
<주관심분야 : 영상 개선, 패턴 인식>
이 상 근(평생회원)-교신저자 1996년 중앙대학교 전자공학과
학사 졸업.
1999년 중앙대학교 전자공학과 석사 졸업.
2003년 조지아공과대학교 전기 및 컴퓨터 공학과 박사 졸업.
2003년~2008년 Samsung Information and System America, Irvine, CA. Staff Research Engineer.
2008년~현재 중앙대학교 첨단영상대학원 영상학 과 교수
<주관심분야 : 멀티미디어 신호 및 통신, 영상 압 축, 영상 개선 및 복구, 영상 검색, 컬러 보정>