석사학위 석사학위 석사학위
석사학위 논문 논문 논문 논문
SVM 을 을 을 을 이용한 이용한 이용한 악성 이용한 악성 악성 악성 댓글 댓글 댓글 판별 댓글 판별 판별 판별 시스템의
시스템의
시스템의 시스템의 설계 설계 설계 및 설계 및 및 및 구현 구현 구현 구현
국민대학교 국민대학교 국민대학교
국민대학교 교육대학원 교육대학원 교육대학원 교육대학원
전자계산 전자계산
전자계산 전자계산 교육전공 교육전공 교육전공 교육전공
김 김 김
김 묘 묘 묘 묘 실 실 실 실
2 0 0 6
SVM 을 을 을 을 이용한 이용한 이용한 이용한 악성 악성 악성 악성 댓글 댓글 댓글 댓글 판별 판별 판별 판별 시스템의
시스템의 시스템의
시스템의 설계 설계 설계 설계 및 및 및 및 구현 구현 구현 구현
지도교수 강 승 식
이 이 이
이 논문을 논문을 논문을 논문을 석사학위 석사학위 석사학위 석사학위 청구 청구 청구 청구 논문으로
논문으로 논문으로
논문으로 제출함 제출함 제출함 제출함
2007 년 6 월 일
국민대학교 국민대학교 국민대학교
국민대학교 교육대학원 교육대학원 교육대학원 교육대학원
전자계산 전자계산
전자계산 전자계산 교육전공 교육전공 교육전공 교육전공
김 김 김
김 묘 묘 묘 묘 실 실 실 실
2 0 0 6
김 김
김 김묘 묘 묘 묘실 실 실 실 의 의 의 의 석사학위 석사학위
석사학위 석사학위 청구논문을 청구논문을 청구논문을 인준함 청구논문을 인준함 인준함 인준함
2007 년 6 월 일
심 사 위 원 장 심 사 위 원 장 심 사 위 원 장
심 사 위 원 장 황 황 황 황 선 선 선 선 태 태 태 태 심 심 심
심 사 사 사 사 위 위 위 위 원 원 김 원 원 김 김 김 혁 혁 혁 만 혁 만 만 만 심 심 심
심 사 사 사 사 위 위 위 위 원 원 강 원 원 강 강 강 승 승 승 식 승 식 식 식
국민대학교 국민대학교 국민대학교
국민대학교 교육대학원 교육대학원 교육대학원 교육대학원
국문요약
SVM 을 을 을 이용한 을 이용한 이용한 이용한 악성 악성 악성 댓글 악성 댓글 댓글 댓글 판별 판별 판별 판별 시스템의 시스템의
시스템의 시스템의 설계 설계 설계 설계 및 및 및 및 구현 구현 구현 구현
국민대학교 교육대학원 전자계산교육 김 묘 실
댓글은 온라인 상에서 자신의 의견을 달고 다른 사람의 의견을 공유함 으로써 필요한 정보를 쉽고 빠르게 얻을 수 있다. 본 논문에서는 익명성 을 이용해서 특정인을 근거 없이 비방하거나 명예를 훼손하는 악성 댓글 을 판단하는 시스템을 구현한다. 인터넷 뉴스의 댓글을 수집하고 형태소 분석기를 이용하여 지질을 추출하여 자질의 품사 정보에 따라 실험 데이 터를 구성하였고 자질의 출현빈도를 이용한 가중치를 계산하고, 용어 벡 터로 표현된 입력 문서를 이진 분류기(Binary Classifier)인 SVMlight을 이용 하여 악성 댓글을 판별하는 시스템을 구현하고 그 성능을 평가한다.
차 례
I. 서 론 ...5
II. 관련 연구 ...8
2.1 댓글에 쓰인 언어의 특징...8
2.2 문서처리(Document Processing)...11
2.2.1 자질 추출 ...12
2.2.2 자질(Feature) 선택 ...13
2.2.3 자질 가중치 계산 ...14
2.2.4 벡터 수치화 ...15
2.3 SVM(Support Vector Machine)...17
2.3.1 SVM의 개념 ...17
2.3.2 SVMlight...20
III. 악성 댓글을 판단하는 시스템의 설계 및 구현...21
3.1 시스템 구조...21
3.2 문서분류기의 구현...24
3.2.1 테스트 데이터(Texts)의 수집...24
3.2.2 자질 선택 ...27
3.2.3 TF-IDF 가중치 계산 ...28
3.2.4 자질 정보 사전(Word List)의 구성...31
3.2.5 SVMlight의 Learn ...33
3.2.6 SVMlight의 Classifier ...34
3.2.7 제약사항 ...35
IV. 실험 및 평가 ...37
4.1 실험 데이터 구성...37
4.2 실험 평가 방법...39
4.3 실험 결과...41
V. 결론 및 향후 연구과제...43
참고문헌 ………... 45
Abstract ……….. 48
그림 차례
[그림 1] 문서 처리 단계.. ...11
[그림 2] 자질 추출 처리 ...12
[그림 3] 벡터 데이터 표현법 ...15
[그림 4] SVM의 범주 분류...18
[그림 5] SVMlight 데이터 구성도 ...20
[그림 6] 시스템 구성도 ...22
[그림 7] 악성 또는 Non악성으로 분류된 테스트 데이터...26
[그림 8] 가중치 계산 알고리즘 ...29
[그림 9] 벡터 수치화된 결과 파일(train.txt) ...30
[그림 10] 정렬 알고리즘 ...31
[그림 11] 자질 정보 사전(Word.txt)...32
[그림 12] prediction.dat 출력 파일 ...34
표 차례
[표 1] SVM 용어 정리...19
[표 2] 인터넷 신문 댓글 분석 자료 ...25
[표 3] 자질 선택 데이터 구성 ...27
[표 4] 데이터 셋의 구성 ...38
[표 5] 테스트 셋의 댓글 개수 ...39
[표 6] 댓글 필터링 성능 비교 ...41
I. 서 론
정보화 시대에 대량으로 생겨나는 문서들에 대해서 익명으로 자신의 의견을 달 수 있는 댓글은 상호 작용적 의견 개진이라는 취지로 시작되 었다. 댓글은 온라인 상에서 자신의 의견을 달고 다른 사람의 의견을 공 유함으로써 필요한 정보를 쉽고 빠르게 알 수 있는 방법 중 하나이다.
고객은 사고자 하는 물건의 상품평을 읽고 자신에 욕구에 맞는 물건을 고르는데 도움을 받을 수 있다. 또 영화를 예매하기 전에 그 영화에 대 한 감상평을 읽고 나면 자신에 맞는 영화를 고를 때 도움이 될 수도 있 고, 보다 다양한 관점에서 영화를 감상하는데 도움이 된다. 이렇듯 상품 평이나 영화 감상평 같은 경우는 그 제품의 마케팅에 상당한 영향을 미 치고 매출로 직결된다.
그러나, 포탈 사이트의 뉴스나 웹 로그(블로그)는 악성 댓글로 인해 심 각한 명예훼손 및 개인 정보 침해의 위험에 노출되어 있다. 인터넷 포탈 사이트의 뉴스 댓글이 엄청난 사회적 경제적 영향을 미치고 있는 것은 누구나 잘 안다. 익명성을 이용해서 특정인을 근거 없이 비방하거나 명 예를 훼손하는 글을 올렸다가 처벌된 전례는 있지만 `악플'로 불리는 악 성 댓글을 문제 삼아 형사 처벌키로 한 것은 임수경씨 사례가 처음이었 다.
일부 네티즌은 당시 관련 기사에 임씨를 `빨갱이'라고 묘사하는 등 임
씨를 비하하고 아들의 죽음을 조롱하는 글을 남겨 포털 사이트에서도 관 련 기사들에 대해 댓글 제한 조치를 취하기도 했다.
검찰 관계자는 "댓글을 통한 인신공격이나 명예훼손이 위험수준에 이 르러 경종을 울릴 필요가 있어 이러한 방침을 정했다"고 전했다.
형법상 모욕죄 또는 명예훼손죄가 적용될 예정이며 구체적인 사실을 담지 않은 `악플'은 모욕죄가 적용된다
주요 포탈 사이트에서는 악성 댓글로 인해 상호작용적 의견 교환 기능 마저 해치는 상황에서 추천 수에 따라 보이는 댓글의 종류를 제한하는 식의 필터링 제도를 준비 중이라고 밝혔다. 네이버, 다음, 네이트, 싸이, 야후 등 포털마다 '착하게 살자!!'고 외치면서 악플 차단방지대책, 사생활 침해나 명예훼손에 대한 구제책을 마련하느라 분주하다.
그러나 대량의 댓글을 효율적으로 관리하기 위한 문서 분류의 필요성 이 증가하고 있다. 일반적으로 문서 범주화에 관한 연구는 효과적인 범 주화 모델의 계산 방법과 학습 자질의 추출 방법이라는 두 가지 문제를 중심으로 발전되어 왔다. 문서 범주화 모델 중 기계학습을 이용한 신경 망(Neural Network), SVM(Support Vector Machine) 등 다양한 방법을 이용하 여 구성하고 있고, 각각의 방법은 학습 정도에 따라 높은 정확도를 가진 분류기로 구성되어 활용되고 있다.
최근에는 학습에 대한 빠른 처리 및 대용량 데이터처리를 위한 성능이 높다고 평가되는 SVM을 활용한 방법이 많이 사용되고 있다[12].
문서의 자질 추출 방법은 학습 문서에서 형태소 분석기를 이용하여 해
당 자질에 대한 가중치를 계산하는 것이 일반적이다. 문서를 표현하기 위해서는 자질에 대한 출현 빈도(Term Frequency: TF)를 이용하여 하나의 문서를 표현하는 방법과 역 문헌빈도(Inverse Document Frequency: IDF)를 같이 이용하여 가중치(Weighting)를 표현하는 방법으로 구분한다.
본 논문에서는 댓글을 악성 댓글과 Non악성 댓글로 분류한다. 악성 댓 글을 판별하는 시스템은 각 댓글 문장에 사용된 단어들에 대한 빈도로 가중치를 계산하여 벡터 수치화한다. 학습된 범주들의 특성 벡터와 사용 자 입력 댓글의 벡터 사이의 유사도 계산에 의해 사용자 입력 댓글의 범 주를 결정한다.
본 논문의 구성은 다음과 같다. 2장에서는 댓글의 특징, 문서 처리,
SVMlight에 대한 관련 연구에 대해 살펴보고, 3장에서는 악성 댓글을 판
단하는 시스템 구조와 자질 선택 방법에 대한 내용을 설명한다. 그리고 4장에서는 실험 및 평가를 하고 5장에서는 결론 및 향후 연구과제에 대 해서 기술한다.
II. 관련 연구
인터넷 문서 특히 웹 로그(블로그)의 주관적이고 감정적인 표현들을 SVM 같은 기계 학습 알고리즘에 의해 학습하고 입력 문서를 자동적으로 긍정 또는 부정으로 분류하는 연구들이 활발히 진행되고 있다[7].
이런 연구에서는 영화 비평, 상품 사용기, 고객 피드백과 같은 특정 영역별로 다르게 사용되는 감정적 표현들을 인지하고 그것을 범주화 한 다[1,3,4,8,9,10].
본 장에서는 본 논문에서 제안한 인터넷 신문 댓글의 악성 여부를 판 단하는 분류 시스템을 구현하기 위해 먼저 댓글에 쓰인 언어의 특징을 알아보고, 댓글 문서 처리 방법과 SVMlight에 대해 설명한다[2].
2.1 댓글에 쓰인 언어의 특징
댓글은 네티즌들이 인터넷 게시판에 올린 글에 대한 답글을 의미한다.
인터넷 게시판의 댓글은 대부분 사적인 내용을 담고 있는 경우가 많은데 인터넷 신문 가사의 댓글은 사회의 민감한 문제를 토론하는 장으로서 공 적인 내용을 담는다는 특성이 있다. 이러한 댓글 제도는 동아일보의 <의 견올리기>란에서 시작되었으며 2003년 4월 1일부터는 네티즌들의 수준 이 인터넷 신문 초창기보다 높아졌다고 판단하여 각 기사에 대한 <의견
쓰기>란을 마련하여 댓글 작성자들의 자유로운 글쓰기 활동을 보장해주 고 있다[13]. 조선 닷컴은 <100자평 쓰기>, 조인스 닷컴은 <나도 한마디>, 인터넷 한겨레는 <기사에 대한 의견> 등 각각의 인터넷 신문들은 댓글 작성자들이 인터넷 상에서 신문을 보고 난 후 그 기사에 대한 의견을 쓸 수 있도록 댓글 제도를 마련해 두고 있다. 한편 의견을 쓰기 위해서는 회원가입을 함과 동시에 실명 확인을 받도록 되어 있는데, 이는 익명성 을 담보로 비윤리적인 글쓰기가 이루어지는 것을 막는 방안이라고 할 수 있다.
댓글에 쓰인 언어의 특징을 표기·어휘·문법·의미로 분류하여 알아 보자.
표기 면에서는 필자의 느낌이나 의도, 감정 등을 직접 표현할 수 없다 는 한계를 보완하는 기능으로 이모콘티을 사용하였고, 맞춤법이나 띄어 쓰기 같은 기초적인 언어 규칙을 지키는 경우가 매우 드물다.
어휘 면에서는 글을 빨리 쓰기 위하여 “걍, 황빠, 황까…”등과 같이 글을 빨리 쓰기 위한 방법으로 줄임말과 음운을 축약하여 두 글자는 한 글자로, 세 글자는 두 글자로 줄여 쓰던 것이 하나의 새로운 단어가 되 는 경우, 의성어나 의태어의 첫 자음을 따서 쓰는 경우 , 또 의식적으로 만들어 쓰는 경우가 있다.
문법 면에서는 문장의 구성 성분을 제대로 갖추지 않은 글이 많다. 전 반적으로 종결의미를 생략하는 경우가 많아 완결된 문장이 적다.
의미 면에서는 인터넷 신문 댓글 언어의 의미를 살펴보면 논리적으로
주장을 펼치는 내용보다는 자신과 다른 의견을 갖고 있는 사람을 비방하 고, 욕하는 등 폭력적인 의미를 담고 있는 경우가 많다. 각 신문사 사이 트마다 마련해 두고 있는 인터넷 신문 댓글 공간은 사회 제반 문제점들 을 여러 사람들이 토론하고 해결책을 제시하자는 의의를 갖고 있다. 그 러나 서로 자기의 주장만 옳다고 하고, 남을 수용하는 태도를 찾을 수 없으며, 자신과 다른 의견은 욕설로 비방하는 경우가 많다.
2.2 문서처리(Document Processing)
문서처리는 학습(Learning)과정과 분류과정에서 분류기가 인식할 수 있는 데이터로 변환하기 위한 처리과정이다. 이러한 과정은 기계학습의 처리가 가능하도록 문서의 내용이나 특징을 잘 반영하는 자질을 추출하 고 선별하여 분류기에서 학습이 가능하도록 입력 자질들의 가중치를 계 산하여 수치화를 한다. 이는 벡터모델에서 사용이 가능한 벡터로서 표현 이 가능하고, 벡터는 자질의 빈도에 따라서 가중치를 부여하는 방식으로 표현한다[14,15].
문서처리는 <그림 1>과 같은 단계로 처리한다.
그림 1. 문서 처리 단계 입력문서
(Training Document)
자질 추출
(Extracting Contents Word)
자질 가중치 계산 (Weighting)
자질 선택 (Selecting Feature)
벡터 수치화 (Processing Vector)
2.2.1 자질 추출
이 단계에서는 입력 문서의 문장을 단어로 분리하는데 이것을 자질이 라고 한다. 이러한 자질을 추출하기 위해서는 먼저 형태소 분석기 또는 사용자 정의 사전을 통해 단어를 추출한다. 형태소 분석기를 사용할 경 우 각각의 단어에 대한 기본적인 품사 할당과 중의성이 있는 품사들에 대해 중의성 해소를 위한 태킹을 수행한다. 이는 문서의 내용이나 의미 를 판단할 수 있는 비중이 가장 크기 때문이다. 또한 단어를 기준으로 내용어를 추출하였다고 하더라도 공통적으로 많이 사용되는 단어는 제거 한다. 이는 자질 선택 단계에서 계산 시 오히려 정확도를 낮추고, 계산량 을 증가시키는 조건으로 작용하기 때문이다.
자질 추출을 처리하면 문장에서 자질을 선택할 수 있도록 단어 리스트 형태로 정보가 관리되며, 이러한 리스트는 <그림 2>와 같이 문서내의 출 현빈도와 동일하게 중복을 허용하여 관리한다.
그림 2. 자질 추출 처리 인과응보라는 말이 생각
나는건 나만의 생각인 가?? 잘했으면 그런일들 이 벌어지겠는가..?? 말 과 행동이 비슷하기라도 해야지...어느누가 좋아할 까나..??
K:그런일 I:그런일들이 I:나만의 P:누가 I:말과
…
I:좋아할까나 I:해야지 N:행동
2.2.2 자질(Feature) 선택
자질 선택은 문서에서 추출된 자질 중에 범주(Class)에서 학습데이터 에 효율적으로 사용될 정보만을 선택하는 단계이다. 모든 자질을 포함하 여 학습을 한다면 학습 및 분류에서 사용될 데이터의 처리량이 많아질 뿐만 아니라 범주 간 정보 독립성이 낮아지는 문제점으로 인해 정확도의 영향이 없는 범위 내에서 자질의 수를 최소화하는 연구가 많이 진행되어 왔다. 이러한 자질 선택에 대한 여러 가지 방법 중 본 논문에서 사용한 방법으로는 자질의 품사 정보를 이용한 특정 단어의 문서 빈도이다.
문서 빈도는 문서에서 어떤 단어가 나타난 빈도를 수치화하여 일정 빈 도 수 이상의 단어만을 자질로 선택하는 방법이다. 이 방법은 문서에서 많이 나타난 단어일수록 문서의 의미에 크게 영향을 미친다는 기준으로 분석되는 방법으로 가장 계산량이 적고 빠르게 자질을 선택할 수 있는 장점이 있다. 하지만 적게 나타난 단어의 경우도 문서의 의미에 크게 영 향을 미칠 수 있다는 점에서는 정확도를 보장받지 못하므로 문서크기가 일정한 문서라는 전제에서만 사용할 수 있다[16].
2.2.3 자질 가중치 계산
문서를 표현하기 위해서는 자질에 대한 출현빈도(Term Frequency:TF) 를 이용하여 하나의 문서를 표현하는 방법과 역 문헌빈도(Inverse Document Frequency:IDF)를 같이 이용하여 가중치(Weighting)을 표현하 는 방법으로 구분한다[6].
본 논문에서는 TF-IDF 가중치를 이용한 벡터수치화 방법을 선택하였고, TF-IDF 가중치 방법을 다음과 같이 설명한다.
TF-IDF 가중치는 문서의 자질에 가중치를 부여하여 문서를 표현하는 방법이다. 문서에서 나타나는 자질의 빈도수 TF와 역 문헌빈도 IDF의 곱 으로 표현하여 <식 1>와 같다.
NNN N aaaaikikikik = f = f = f = fikikikik × log( × log( × log( × log(
nnnnkkkk )))) <식 1>
where
ffffik : ik : ik : ik : I문서내 k단어 빈도수
nnnnk : k : k : k : 전체문서 중 k단어가 출현한 문서 수
본 논문에서 사용한 TF-IDF 가중치 계산은 문서내의 자질이 나타난 빈 도수와 역 문헌빈도수만을 고려하여 수식에서 적용하였다.
2.2.4 벡터 수치화
벡터 수치화는 자질 선택 단계에서 선택된 자질을 사용하여 문서를 수 치화하여 표현하는 방법이다. 일반적으로 사용되는 문서 표현 방법은 벡 터 공간 모델(Vector Space Model)이다.
TF-IDF 가중치 계산이 처리된 데이터는 <자질:값> 형태로 표현되어 학 습이 가능하도록 파일 형태로 생성하여 처리된다[17]. 자질은 자질 선택 시 자질 정보 사전의 일련번호로 할당되며, 할당된 데이터를 기준으로 계산된 TF-IDF 가중치 값을 적용한다[18].
SVMlight를 이용하기 위해서는 <그림 3>과 같이 벡터 데이터를 표현하
는 표현법을 따른다.
<line> .=. <target> <feature>:<value> <feature>:<value> ... <feature>:<value> #
<info>
<target> .=. +1 | -1 | 0 | <float>
<feature> .=. <integer> | "qid"
<value> .=. <float>
<info> .=. <string>
그림 3. 벡터 데이터 표현법
본 논문에서는 한 line이 댓글 문서 1개와 동일한 의미를 가진다. 또한 앞서 자질 선택 후 자질 정보 사전(Word List)의 일련번호(index)가 그 자 질의 feature에 해당되며, 자질의 가중치 계산된 값이 value에 해당된다.
Target의 경우 문서 분류의 결과값인 True/False의 개념과 일치시켜 Positive인 경우 +1, Negative의 경우 -1로 구성이 가능하다[19].
<info>의 경우 설명 정보이므로 생략도 가능하다.
본 논문에서는 Positive는 Non악성 댓글을 의미하며, Negative는 악성 댓글을 의미한다.
2.3 SVM(Support Vector Machine)
SVM(Support Vector Machine)은 2개의 범주를 분류하는 이진 분류기 (Binary Classifier)이다. SVM은 기계학습 알고리즘으로써 분류 프로그 램에 응용되어 높은 성능을 보여주고 있다[12,20,21].
2.3.1 SVM의 개념
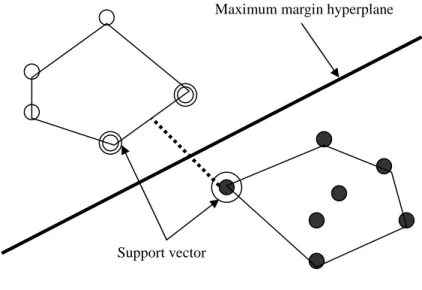
SVM에서 분류를 처리하는 개념은 <그림 4>과 같다.
<그림 4>에서 A범주에 속하는 자질을 white point, B범주에 속하는 자 질을 black point라고 표현 할 때 이 point는 벡터로 구성된다. 이러한 벡 터 가운데 같은 범주를 기준으로 바깥으로 위치한 벡터들의 연결선을 convex hull이라 하고, convex hull 안의 벡터는 범주를 구분하는데 영향을 미치지 않으므로 분류를 하기 위한 정보로 적합하지 않다. 또한 범주를 구분하는 선을 hyperplane이라 한다. 이러한 hyperplane은 무수히 많은 선 으로 표현할 수 있다. 이러한 무수한 선 중 각 범주의 convex hull에 속한 벡터 안에서 가장 가까운 벡터와 수직거리로 가장 먼 거리를 가진 hyperplane을 maximum hyperplane이라고 하고, 이 때 가장 가까운 벡터들 을 support vector라고 한다.
그림 4. SVM의 범주 분류
Support vector는 hyperplane을 결정하는 정보로서 만약 hyperplane을 재 조정할 시에는 support vector도 재계산되어야 한다.
Hyperplane은 선형 또는 비선형으로 표현이 가능하며 일정 수식의 방 정식으로 표현이 가능하다. <그림 4>을 통한 SVM의 분류원리는 벡터가 hyperplane에 위치하며 0, A범주에 속하면 > 0, B범주에 속하면 < 0이 되며, 이를 방정식에 대입하여 결과값을 비교하여 분류범주에 속하는 여 부를 판단한다.
Support vector
Maximum margin hyperplane
SVM에서 설명한 용어는 <표 1>에 정리한다.
표 1. SVM 용어 정리
용어 설 명
Convex hull 범주에 속한 벡터들 중 바깥부분을 구성하고 있는 벡 터들을 연결한 다각형 공간
Hyperplane 두 범주를 구분하고 있는 선
Maximum margin hyperplane
두 범주에 속한 convex hull간 직각거리로 각각 가장 거리가 먼 hyperplane
Suppert vector Maximum margin hyperplane에서 convex hull까지 거리 를 측정할 때 표면 직선에 속한 벡터들
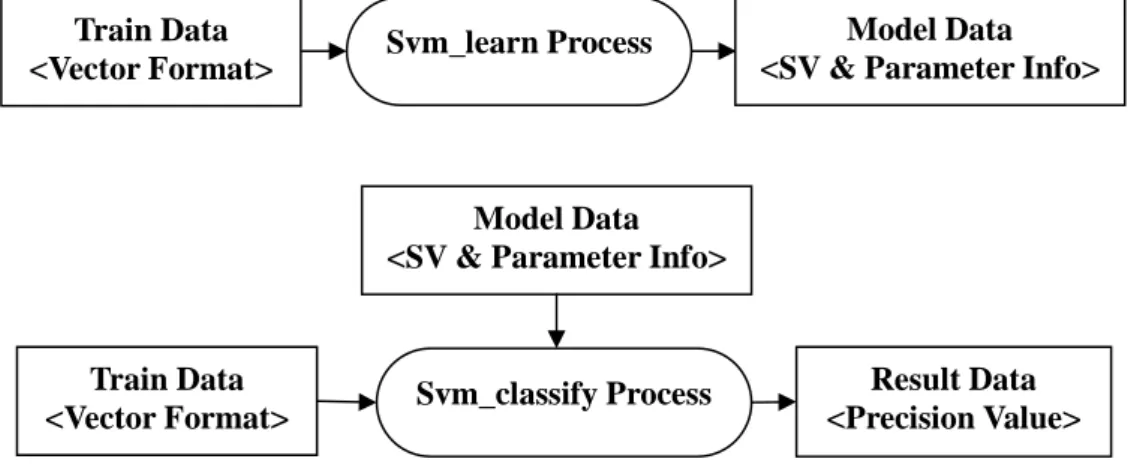
2.3.2 SVMlight
SVMlight는 C언어로 Vapnik의 Support Vector Machine 알고리즘을 구현한
분류기 프로그램이다. 본 논문에서는 SVMlight를 이용하여 분류기를 수행 하였으며 분류에서 입력되는 데이터는 SVMlight에서 호환하는 형식에 따 라 수행하였다[2].
SVMlight는 svm_learn 프로세스와 svm_classify 프로세스로 구성되어 있
다. 프로세스의 데이터 흐름은 <그림 5>과 같다[2].
그림 5. SVMlight 데이터 구성도 Svm_learn Process
Model Data
<SV & Parameter Info>
Train Data
<Vector Format> Svm_classify Process Result Data
<Precision Value>
Model Data
<SV & Parameter Info>
Train Data
<Vector Format>
III. 악성 댓글을 판단하는 시스템의 설계 및 구현
본 장에서는 2장에서 기술한 연구분야를 응용하여 제안된 문서 분류 기술을 바탕으로 인터넷 신문의 악성 댓글을 판단하는 시스템의 구조를 설계하고 각 서비스 모듈을 자세하게 기술한다.
3.1 시스템 구조
<그림 6>과 같은 흐름을 통해 인터넷 신문의 댓글을 분류하기 위한 처리 절차를 설명한다. 악성 댓글을 판단하는 시스템은 크게 두 가지 부분으로 나눌 수 있다. 인터넷 뉴스 포탈 사이트에서 수집한 댓글을 수 작업으로 악성인지 아닌지 분류된 학습 문서와 입력 문서에 대해 자질들 을 선별하고 가중치를 계산하는 문서 처리 부분과 SVMlight에서 문서 처 리된 데이터를 학습하고 입력 문서를 악성 또는 Non악성으로 분류하는 과정이다. 학습하기 위해 수집된 문서와 분류하기 위해 입력 받은 문서 는 공용으로 같은 문서 처리 모듈을 이용한다.
그림 6. 시스템 구성도
<그림 6>과 같이 수작업으로 분류된 댓글들은 전처리 과정을 걸치게 되는데 전처리 과정으로는 형태소 분석기(KTL)를 이용하여 품사정보와 쌍을 이룬 자질을 추출한다[11]. 댓글을 악성인지 아닌지 분류하는데 모 든 어절이 의미있는 것이 아니므로 품사별로 자질을 선택한다. 형태소 분석기로부터 얻은 품사 정보로는 명사, 동사, 형용사, 부사 등을 조합하 여 사용한다. 선택된 자질들은 오름차순으로 자질 정보 사전(Word List)을 구성한다. 자질 정보 사전은 벡터 수치화를 할 때 그 단어의 고유번호를
SVMlight
Texts Input
POS Tagger
형태소 분석기(KTL)
자질 선택
[명사, 동사, 형용사, 어절자체]
Learn
Classifier
<index:value>
[Module]
악성 Non악성
가중치계산
(TF-IDF 가중치) Word List
구하기 위한 조치이기도 하다. 이 추출된 자질에 대해 가중치를 구해서 벡터 수치화 한다. 가중치 계산은 문서 분류 분야에서 보편적으로 사용 되는 TF-IDF 방식을 적용하였다. 문서분류 분야에서 가장 많이 사용되는 기법이다.
SVMlight의 경우 분류의 실제적인 SVM알고리즘을 수행하는 부분으로
SVMlight를 사용하여 구성하였다.
3.2 문서분류기의 구현
<그림 6> 시스템 구성도의 세부적인 모듈에 대해서 구체적으로 설명 한다.
3.2.1 테스트 데이터(Texts)의 수집
이 논문에서는 연구를 위하여 조선 닷컴의 ‘100자평’과 네이버의 ‘의견 쓰기’라는 댓글 제도를 통하여 등록된 댓글 2200개를 선정하고자 한다.
정치, 경제, 사회 등 여러 분야에서 화제가 되고 있는 인물 중심으로 자 료를 선정한다.
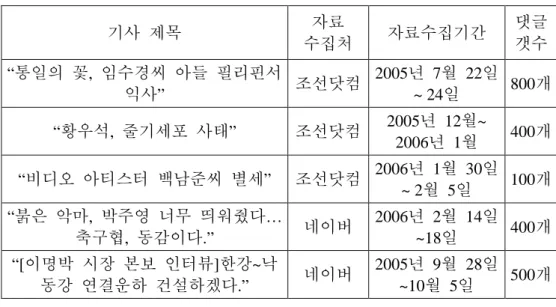
댓글 분석 대상은 “통일의 꽃, 임수경씨 아들 필리핀서 익사”의 댓글 2005년 7월 22일부터 24일까지의 조선닷컴 100자평, “황우석, 줄기세포 사태”관련 기사의 댓글 2005년 12월부터 2006년 1월까지의 조선닷컴 100 자평, “비디오 아티스터 백남준씨 별세”의 댓글 2006년 1월 30일부터 2월 5일까지의 조선닷컴 100자평, “붉은 악마, 박주영 너무 띄워줬다…축구협, 동감이다.”의 댓글 2006년 2월 14일부터 18일까지의 네어버 의견쓰기와
“[이명박 시장 본보 인터뷰]한강~낙동강 연결운하 건설하겠다.”의 댓글 2005년 9월 28일부터 10월 5일까지이다.
표 2. 인터넷 신문 댓글 분석 자료
기사 제목 자료
수집처 자료수집기간 댓글 갯수
“통일의 꽃, 임수경씨 아들 필리핀서
익사” 조선닷컴 2005년 7월 22일
~ 24일 800개
“황우석, 줄기세포 사태” 조선닷컴 2005년 12월~
2006년 1월 400개
“비디오 아티스터 백남준씨 별세” 조선닷컴 2006년 1월 30일
~ 2월 5일 100개
“붉은 악마, 박주영 너무 띄워줬다…
축구협, 동감이다.” 네이버 2006년 2월 14일
~18일 400개
“[이명박 시장 본보 인터뷰]한강~낙
동강 연결운하 건설하겠다.” 네이버 2005년 9월 28일
~10월 5일 500개
수집된 인터넷 신문 댓글은 SVMlight의 학습(Learn) 모듈을 사용하기 위 해서 수작업으로 악성인지 아닌지를 분류한다. <그림 7>은 수작업으로 분류된 테스트 파일이다. 각 Line은 한 개의 댓글로 구성되고 댓글의 맨 앞에 숫자가 -1이면 악성이고 1이면 Non악성을 의미한다.
-1 악플러들인데 따로 조사할 필요있나?....
-1 임수경을 생각할때는 지금도 화가 나는군요
-1 아이가 무슨 죄가 있나 마는 니 조둥아리가 하도 악하니 … -1 이런사람 아들 익사해도 신문에 나오는구나 세상많이 좋아졌다
…
그림 7. 악성 또는 Non악성으로 분류된 데이터
3.2.2 자질 선택
형태소 분석기에 의해 추출된 자질들은 각각 품사 정보를 가지고 있다.
각 자질이 가지고 있는 품사 정보를 이용하여 자질 데이터를 구성한다.
이렇게 구성된 자질 데이터를 실험하고 그 성능을 비교함으로써 특정 품 사와 악성 표현과의 관계를 분석한다.
표 3. 자질 선택 데이터 구성
구분 내용
K_0 명사만 추출
K_1 명사, 형용사, 동사 추출 K_4 모든 품사의 통합 추출 K_S0 어절 자체와 명사만 추출
K_S1 어절 자체와 명사, 형용사, 동사 추출 K_S4 어절 자체와 모든 품사의 통합 추출
<표 3>에서 K_S0, K_S1, K_S4와 같이 어절 자체를 추출한다는 것은 해 당 단어가 사전 파일에 등록되어 있지 않으며 단지 띄어쓰기에 의해 어 절 그대로를 추출하는 것이다.
3.2.3 TF-IDF 가중치 계산
본 논문에서 사용한 TF-IDF 가중치 계산은 문서 내 자질이 나타난 빈 도수와 역 문헌빈도수만을 고려하여 수식에서 적용하였다. <그림 8>의 가중치 계산 알고리즘에서 구조체 배열 ReplyData는 각 댓글에 대한 배 열이다. ReplyData는 각 댓글에 대해 자질의 개수(ndata), 자질(word), 자질 고유 번호 (word_index), 문장 빈도(word_df), 자질 빈도(word_tf), 가중치(word_score) 등의 정보를 가지고 있는 구조체이다.
Algorithm word_weightingword_weightingword_weightingword_weighting(ReplyData, max_reply) {
int cnt_reply=0, j=0;
char *filename = "word_cnt";/*자질 정보 사전(WordList)*/
load_worddata(filename);
/*각 댓글에 대해 자질들이 저장되어 있는 파일*/
fpin = fopen("replyData","r");
fpout = fopen("train","w");/*학습파일생성*/
/*catagory : 악성내지 Non악성 구분자*/
/*n : 각 댓글이 포함하고 있는 자질의 갯수*/
for(int i=0; i<max_reply-1;i++) {
for (j=0; j<ReplyData[i].ndata;j++) {
ReplyData[i].word_index[j] =
bsearch_string(ReplyData[i].word[j], WordData.data, 0, WordData.ndata)+1;
/*자질(word)에 대한 WordList의 DF을 얻는다.
DF는 WordList생성시 자질과 함께 저장되었다.*/
ReplyData[i].word_df[j]=
atoi(WordData.data[ReplyData[i].word_index[j]]+
strlen(WordData.data[ReplyData[i].word_index[j]])+1);
ReplyData[i].word_score[j]=1*log10(max_reply/word_df[j]);
}//end of for
/*자질들을 오름차순 정렬 및 중복 자질 제거하면서 TF 계산 */
int rtn = sortWord();
for(j=0; j<ReplyData[i].ndata; j++) { fprintf(fpout, " %d:%3.10f",
ReplyData[i].word_index[j], ReplyData[i].word_score[j] * ReplyData[i].word_tf[j]);
}//end of for }//end of for }//end of Algorithm
그림 8. 가중치 계산 알고리즘
TF-IDF 가중치 계산이 처리된 데이터는 <index:value> 형태로 표현되 어 학습이 가능하도록 파일 형태로 생성하여 처리한다.
-1 2685:3.9180827846 15016:6.6852400851 32916:6.6852400851 -1 4801:3.3426200426 19847:3.0413926852 29255:3.3426200426
-1 447:6.6852400851 698:3.3426200426 2876:6.6852400851 3091:3.3426200426 4125:3.3426200426
1 639:3.3426200426 1561:6.6852400851 1717:3.3426200426 3349:3.9180827846 3562:3.3426200426
1 1238:6.6852400851 1680:3.7501225268 9332:3.3426200426 10977:3.5706596700
…
그림 9. 벡터 수치화한 결과 파일(train.txt)
3.2.4 자질 정보 사전(Word List)의 구성
형태소 분석기에 의해 추출된 자질을 벡터정보에서 구성할 수 있도록 인텍스화하여 구성한다. 자질 정보를 구성할 때는 중복된 자질을 제거하 고 오름차순으로 정렬된 파일 형태로 생성된다.
<그림 10>은 자질 정보 사전을 생성할 때 사용한 정렬 알고리즘이다.
Int sortWordsortWordsortWord(int index[],int n) sortWord {
long i,j,temp1;
//오름차순으로 정렬 for(i=0;i<n-1;i++){
for(j=i+1;j<n;j++){
if(index[i]>index[j]){
emp1 = index[i];
ndex[i] = index[j];
ndex[j] = temp1;
} } }
//중복된 자질 제거 for(i=0; i<n; i++) { if(n != i-1 ){
//이전의 어절과 비교해서 출력
if(index[i] !=index[i+1]){
fprintf(fpout2, " %d", index[i]);
} } } }
그림 10. 정렬 알고리즘
<그림 11>과 같은 자질 정보 사전(Word List)가 생성된다. 자질 정보 사전에는 일련번호가 있어 벡터 수치화할 때 인텍스로 사용된다.
1 I:가 2 I:가..
3 I:가거라 4 I:가게 5 I:가겠구만 6 I:가격안정 7 I:가격에 8 I:가고 9 I:가관이네
…
그림 11. 자질 정보 사전(Word.txt)
3.2.5 SVMlight의 Learn
학습처리는 학습에 기준이 되는 학습데이터를 이용하여 분류기에서 사 용될 학습모델을 생성하는 것이다. 학습처리의 처리기준에서 가장 중요 한 것은 Non악성 학습 데이터와 악성 학습 데이터를 구분하여 학습시켜 야 한다. 따라서 <그림 6>에서 텍스트(Texts) 문서는 Non악성(1)의 태그 정보와 악성(-1)의 태그 정보를 같이 제공해야 한다. 텍스트(Texts) 문서 는 벡터 수치화되어 출력 파일(train.txt)에 저장된다.
본 논문에서 training은 SVM에 의하여 실행되기 때문에 이미 구현되어 있는 SVM을 사용하였다.
실제 Training은 다음과 같은 명령어로 실행한다.
C:\ >svm_learn train.txt Modul.dat
학습되어진 모델은 Modul.dat에 쓰여진다. Modul.dat는 입력 문서 (Input)의 악성여부를 예측하기 위해서 분류기에서 사용된다.
3.2.6 SVMlight의 Classifier
분류처리는 학습처리에서 생성된 범주 별 모델을 해당 범주의 분류기 의 모델로 사용하여 분류를 처리하는 것이다. 분류처리의 처리기준에서 가장 중요한 것은 학습처리에서 사용한 문서처리와 동일한 방법으로 문 서처리를 수행하여야 한다. 즉, 학습처리에서 선택과 동일한 자질을 선택 하여 벡터데이터를 생성하고 이렇게 생성된 데이터를 입력하여 분류의 결과를 판단한다. 다음과 같은 명령어로 svm_classify을 실행한다.
C:\ >svm_classify input.txt Modul.dat prediction.dat
댓글이 있는 입력 파일(Input.txt)은 Modul.dat에 의해 학습되고 예측된 결과가 prediction.dat에 저장된다. <그림 12>은 prediction.dat 파일이다.
입력 파일에는 한 Line당 하나의 댓글이 있고 그 댓글의 예측한 결과 값이 <그림 12>에 나와있다. 음수는 악성 댓글을 의미하고 양수는 Non 악성 댓글을 의미한다.
-0.030731617 -0.13147995 0.041253744 0.014331281
그림 12. prediction.dat 출력 파일
3.2.7 제약사항
본 논문에서 제안하는 댓글 문서 분류기를 구현하기 위해서는 다음과 같은 제약사항을 정의하고, 시스템에 적용하였다.
제약규칙은 문서처리 시 적용한 사항, 학습처리 시 적용한 사항, 분류 처리 시 적용한 사항으로 구분하여 기술한다.
첫째, 문서처리 시 적용할 사항은 다음과 같다.
l 문서는 텍스트 문서만을 입력 데이터로 구성한다.
l 자질 선택은 형태소 분석한 결과에서 품사별로 추출해서 각각 학습데이터로 사용한다.
l 선택된 자질 정보 사전은 별도의 일련번호를 가지며 벡터 데 이터로 사용 시 인텍스로 활용한다.
l 벡터 데이터는 <feature : value>의 형식으로 구성하여 value 는 TF-IDF 가중치 값을 사용한다.
l Value는 소수점 10자리까지 허용한다.
l 문서처리는 학습기와 분류기에서 공용으로 같은 모듈을 구성 하여 사용한다.
둘째, 학습처리 시 적용할 사항은 다음과 같다.
l 학습데이터는 Non악성 학습데이터와 악성 학습데이터를 구분
하여 SVM 학습기에서 학습이 가능하도록 파일형태로 생성하여 처리한다.
l 범주 별로 학습모델을 별도로 생성하여 분류 서비스에서 제공 하는 처리방법에 따라 학습모델을 적용한다.
l 학습모델은 MODEL(범주번호).model의 파일생성 규칙에 따라 생성한다.
l 학습 정확도는 SVM에서 반환하는 precision값을 사용하여 분 석한다.
셋째, 분류처리 시 적용할 사항은 다음과 같다.
l 학습처리에서 사용한 문서처리 모듈을 이용하여 동일하게 분 석 처리한다.
l 분류처리에서는 자질의 추출 및 자질 선택에 대한 문서처리는 제외한다.
IV. 실험 및 평가
본 시스템은 C, C++ 언어를 사용하여 구현하였으며 자질 추출을 위하 여 국민대학교 자연어처리 연구실의 형태소 분석기를 이용하였다. 실험 에 사용된 댓글 문서는 국내 웹사이트(조선닷컴, 네이버)에서 악성 댓글 로 인해 인권 침해 논란이 있었던 기사의 댓글을 무작위로 선정하였다.
총 댓글 문서 수는 2200개였고, 이 SVMlight의 성능을 높이기 위해 Non악 성 댓글 문서 수와 악성 댓글 문서 수를 각 1100개씩 추출하였다.
4.1 실험 데이터 구성
트레이닝 및 테스트에 사용된 데이터들은 실제 포탈사이트의 뉴스에 대한 댓글들을 수집하여 구성하였다.
데이터의 구성은 <표 4>와 같다. 실험을 하기 위해 학습기와 분류기에 사용된 데이터들은 총 2,200개의 인터넷 뉴스 댓글을 사용하였고, 이에 학습 문서을 위해 총 댓글의 90%인 1,980개, 분류 실험을 위해 총 댓글 의 10%인 220개를 사용하였다.
표 4. 데이터 셋의 구성
Training Data Test Data
악성 댓글 990 110
Non악성 댓글 990 110
합 계 1,980 220
학습의 정확도를 높이기 위해 악성 댓글과 Non악성 댓글의 비율을 1:1 로 같게 하였다.
4.2 실험 평가 방법
문서 분류의 성능을 평가하기 위한 기준은 정확률(Precision), 재현율(Recall) 그리고 F1-measure 측정식이 사용된다[22][23].
표 5. 테스트 셋의 댓글 개수
정답
시스템 Non악성 악성
Non악성 a b
악성 c d
<표 5>에 의해서 정확률(Precision)과 재현율(Recall)을 다음 식과 같이 정의한다.
P(Precision)Non악성 = a
a + b <식 2>
R(recall)Non악성 = a
a + c
<식 3>
2PNon악성RNon악성 F1-measureNon악성 =
PNon악성 + RNon악성
<식 4>
P(Precision)악성 = d
c + d <식 5>
R(recall)악성 = d
b + d
<식 6>
2P악성R악성 F1-measure악성 =
P악성 + R악성
<식 7>
a + d Accuracy =
a + b + c + d
<식 8>
정확률(precision)은 어떤 분류에 속한다고 판정된 문서 중 제대로 분 류된 문서의 비율을 말한다. 재현율(Recall)은 실제로 어떤 분야에 속하 는 문서 중 제대로 분류된 문서의 비율을 말한다.
<식 5>과 <식 6>에서 P(Precision)악성은 분류 시스템에서 악성 댓글에 속한다고 판정된 문서 중 진짜 악성인 댓글의 개수이다. R(recall)악성은 실제로 악성 댓글에 속하는 문서 중 분류 시스템이 제대로 악성으로 분 류한 댓글의 개수이다.
4.3 실험 결과
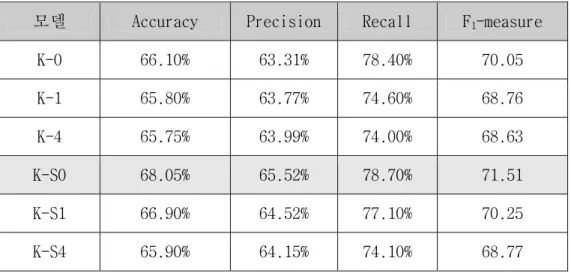
본 논문에서는 자질 추출 후 자질 선택 방법을 6가지로 구성하여 실험 하였다. <표 3>은 6가지의 자질 선택 방법에 따라 문서 처리 과정을 마 친 2,200개의 댓글 문서를 10-fold cross validation방식으로 실험한 평균값 이다. Accuracy은 전체 입력 댓글 수 중 분류기가 Non악성 댓글을 Non악 성 댓글로, 악성 댓글을 악성 댓글로 맞게 분류한 총 개수이다.
표 6. 댓글 필터링 성능 비교
모델 Accuracy Precision Recall F1-measure K-0 66.10% 63.31% 78.40% 70.05 K-1 65.80% 63.77% 74.60% 68.76 K-4 65.75% 63.99% 74.00% 68.63 K-S0 68.05% 65.52% 78.70% 71.51 K-S1 66.90% 64.52% 77.10% 70.25 K-S4 65.90% 64.15% 74.10% 68.77
F1-measure 측정 결과에서 자질 선택시 명사만(K_0) 선택한 것은 같은 조건의 다른 품사를(K_1, K_4) 포함하는 것보다 1.1%정도 성능이 높게
나왔고, 공백을 기준으로 얻은 자질 즉, 어절 자체와 명사(K_S0)를 포함한 것은 어절 자체를 포함하지 않은 데이터보다(K_0) 1.5% 향상된 성능을 얻을 수 있었다.
어절 자체와 명사(K_S0)를 포함한 실험이 성능 면에서 향상된 결과를 얻을 수 있었던 이유는 누리꾼들 사이에서 유행처럼 사용하는 신조어의 영향 때문이다. 신조어들이 많이 만들어지는 현상에 대한 원인은 글을 빨리 쓰기 위하여 음운을 축약하여 두 글자는 한 글자로, 세 글자는 두 글자로 줄여 쓰던 것이 하나의 새로운 단어가 되는 경우, 의성어나 의태어의 첫 자음을 따서 쓰는 경우, 또 의식적으로 만들어 쓰기 때문인 경우로 나누어 생각할 수 있다. 댓글에서 이런 신조어들을 네티즌들이 많이 사용하고 있고, 그런 단어들의 빈도수가 높기 때문이다.
SVMlight의 성능이 높게 나오려면 해당 범주를 잘 표현하는 문장이
텍스트 문서 내에 다수 포함하고 있어야 한다. 그러나, 댓글의 특성상 대부분이 100자 이내의 한 줄 문장이며, 해당 범주를 잘 표현하는 자질이 한 문장에 한번내지 두번 등장하기 때문에 높은 성능을 내는데 한계가 있었다.
V. 결론 및 향후 연구과제
요즘 인터넷 뉴스 댓글에서 문제가 되고 있는 악성 댓글은 댓글 작성 자들이 전혀 상대방을 배려하지 않는 공격적인 단어를 사용함으로써 댓 글을 읽는 상대방을 흥분시키고, 논리적인 비판을 하려는 노력하는 모습 을 보이기보다는 나와 다른 의견을 갖고 있는 상대방을 비방하고, 비속 어를 사용하여 공격한다. 이러한 글을 쓰지 못하도록 운영자가 삭제할 수도 있지만 인터넷 신문의 자율성을 유지하기 위해서 인터넷 신문 댓글 작성자들이 자율적으로 규제할 수 있도록 하는 것이 최선의 방법이다.
본 논문에서는 인터넷 뉴스에 대한 악성 댓글을 판단하는 시스템을 제 안하고 구현하였다. 제안한 시스템의 성능은 문서 처리 과정의 자질 선 택시 어절 자체와 명사를 포함한 실험이 다른 품사 실험보다 우수한 성 능을 보였다.
향후 과제로는 문서에 자주 사용되는 단어 중에는 문서 범주화에 영향 을 미치지 않은 것이 있다. 그러나, 이 단어는 높은 빈도에 의해 가중치 계산에 큰 영향을 준다. 이런 불용어를 제거하는 방법이 연구되어야 할 것이다.
그리고, 현재 수집된 금칙어 사전을 이용하여 분류기가 잘못 판단한 댓글을 다시 한번 필터링 하거나, “극도로 싫어한다.”, ”쌤통이다.”, ”얼마 나 잘되나”와 같은 악성 댓글에 나타나는 독특한 표현들에 대한 연구를
적용한 최적의 시스템을 제시할 수 있을 것이다.
참 참 참
참 고 고 고 문 고 문 문 문 헌 헌 헌 헌
[1] Sara Owsley, Sanjay C. Sood, and Kristian J. Hammond, “Domain Specific Affective Classification of Documents ” , The AAAI Spring Symposia on Computational Approaches to Analysing Weblogs, pp.181-183, 2006.
[2] T. Joachims,”Support Vector Machine(SVMlight)”, http://svmlight.joachims.org/, 2004
[3] Hong Qu, Andrea La Pietra, Sarah Poon, “Automated Blog Classification: Challenges and Pitfalls”, The AAAI Spring Symposia on Computational Approaches to Analysing Weblogs, pp.184-186, 2006.
[4] Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan, “Thumbs up? Sentiment Classification using Machine Learning Techniques”, In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.79-86, 2002.
[5] Soo-Min Kim and Edward Hovy, “Determining the sentiment of opinions”, In COLING-2004, pp.1367-1373, 2004.
[6] N.Hiroshima, S. Yamada, O. Furuse and R. Kataoka,“Searching for Sentences Expression Opinions by using Declaratively Subjective Clues”, In Proceedings of the Workshop on Sentiment and Subjectivity in Text, c2006 Association for Computational Linguistics, pp.39– 46, 2006.
[7] P.D. Turney and M.L. Littman, “Unsupervised Learning of Semantic Orientation from a Hundred-billion-word Corpus”, National Research Council, Institute for Information Technology, (No. ERB-1094, NRC #44929), 2002.
[8] Michael Gamon. “Sentiment Classification on Customer Feedback Data: noisy data, large feature vectors, and the role of
linguistic analysis”, In Proceedings the 20th, International Conference on Computational Linguistics, pp.841– 847, 2004.
[9] Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan, “A Sentimental Education: Sentiment Analysis using Subjectivity Summarization Based on Minimum Cuts”. ACL 2004, pp.271– 278, 2004.
[10] P.D. Turney and M.L. Littman. “Measuring Praise and Criticism: Inference of Semantic Orientation from Association”
ACM Transactions on Information Systems (TOIS). Vol. 21, No. 4.
October 2003. pp.315-346, 2003.
[11] 강승식, 한국어 형태소 분석 및 정보 검색, 홍릉과학출판사, 2002.
[12] Joachims, T. “Text categorization with Support Vector Machines: Learning with Many Relevant Features. In Machine Learning”, ECML-98, Tenth European Conference on Machine Learning, pp.137-142, 1998.
[13] 권순희, “하이퍼미디어 시대의 언어 문화 교육 연구 : 인터넷 신문 수용자의 이해 반응과 이해 교육 방안”, 서울대학교 국어 교육연구소, 2003.
[14] Tak W.Yan, Hector Garcia-Molina, “SIFT – A Tool for Wide- Area Information Dissenmination”, In Proceedings of th 1995 USENIX Technical Conference, pp.177-186, 1995.
[15] Salton, G., “Automatic Text Processing: The Transformation, Analysis and Retrieval of Information by Computer”, Addison- Wesley Publishing, 1989.
[16] Pattie Maes, “Agents that reduce work and information overload”, Communications of the ACM, pp.33-40, 1994.
[17] Frakes, W. B. and R. B. Yates, “Information Retrieval:
Data Structures and Algorithm”, Prentice-Hall, 1992.
[18] Joachims, “Learning to Classify Text using Support Vector Machines: Methods, Theory and Algorithms”, Kluwer Academic
Publishers, 2002.
[19] Vapnik, “The Nature of Statistical Learning Theory”, Springer, 1995.
[20] Chapelle, O., Haffner, P. Vapnik, V., “SVM for histogram- based image classification”, IEEE Trans. On Neural Networks, pp.1055-1064, 1999.
[21] T. Doszkocs, J. Reggia, and X. Lin, “Connectionist models and information retrieval”, Annual Review of Information Science & Technology, pp.209-260, 1990.
[22] Nobuaki Hiroshima, Setsuo Yamada, Osamu Furuse and Ryoji Kataoka, “Searching for. sentences expressing opinions by using declaratively subjective clues”, In Proceedings of the.
Workshop on Sentiment and Subjectivity in Text, pp.39– 46, 2006.
[23] Androutsopoulos, I., Koutsias, J., Chandrinos, K.V., Paliouras, G. and Spyropoulos, C. D., "An Evaluation of Naive Bayesian Anti-Spam Filtering", Proc of the 11th European Conference on Machine Learning, pp.9-17, 2000.
Abstract
A Design and Implementation of Malicious Web Log Identification System by Using
SVM
by Kim, Myo-Sil
Major in Computer Science Education Graduate School of Education
Kookmin University Seoul, Korea
To write opinion of oneself about news is sweet at on-line and it owns jointly the opinion of the person who is different with information which is necessary to be easy, there is a possibility of getting quickly. In this paper, we present a system that can be used to classify malicious Web Logs of news which ground it slanders the specific person without or damage an honor. The system gathers and analyzes Web Logs. It
experiments with 6 data models by extracting features and calculates the weight by TF*IDF. These features were used as feature parameters in a Support Vector Machine to classify malicious Web Logs.
![그림 6. 시스템 구성도 <그림 6>과 같이 수작업으로 분류된 댓글들은 전처리 과정을 걸치게 되는데 전처리 과정으로는 형태소 분석기(KTL)를 이용하여 품사정보와 쌍을 이룬 자질을 추출한다[11]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5281463.146115/26.892.182.699.242.655/수작업으로-댓글들은-걸치게-되는데-과정으로는-이용하여-품사정보와-추출한다.webp)