SVM 기반의 가이드 멘션 페어 모델을 이용한 한국어 상호참조해결
최경호˚, 박천음, 이홍규, 이창기 강원대학교
(gangsparkle, parkce, proname, leeck)@kangwon.ac.kr
Coreference Resolution for Korean using Guide Mention Pair with SVM
Kyoungho Choi, Cheoneum Park, Hongyu Lee, Changki Lee Kangwon National University
요 약 본 논문에서는 통계기반 상호참조에 쓰이는 멘션 페어 모델(Mention Pair Model) 에 규칙기반 상호참조해결 시스템인 다-단계-시브 시스템의 상호참조 예측 결과를 자질로 추 가하여 참조여부를 예측하는 방법을 제안한다. 시스템에서는 다-단계-시브 시스템의 예측결과 를 포함하여 총 32개의 자질들을 사용했다. 논문에서 제안한 시스템의 학습과 평가를 위해서 위키피디아(Wikipedia)를 기반으로 하는 201개의 질의응답 문서와 신문기사를 기반으로 하는 20개의 문서를 분석하여 상호참조해결 정보가 담긴 말뭉치를 구축했다. 직접 구축한 말뭉치를 통해 측정한 시스템의 성능은 MUC-F1 63.15%, B-cube-F1 63.57%, CEAFE-F1 69.21% 로 나타났다.
1. 서 론
상호참조해결이란 문서 내에서 완전히 같은 대상을 지칭하는 명사구들을 하나의 엔티티(Entity)로 묶어주는 과정이다. 상호참조해결을 통해 직책 등의 호칭으로 대체되는 인명이나, 대명사 등의 모호성을 수반한 명사구가 발생시키는 문제를 줄여주어, 문서요약,
기계번역 등의 상위 자연언어처리 과정과
응용분야에서의 오류를 줄 일 수 있다.
한국어 상호참조해결 문제를 통계적인 방법으로만 다뤘을 때 성능을 보장 받기는 어렵다. 한국어에서 어느 정도 검증을 받은 규칙기반 시스템과 융합하여 기계학습을 응용한다면, 더 우수한 성능을 기대 할 수 있다. 본 논문에서는 멘션 페어(Mention Pair)라는 기계학습 기반의 상호참조 해결 모델에 규칙기반 상호참조해결 방법을 융합한 방법인 가이드 멘션 페어(Guide Mention Pair) 모델을 소개하고 성능을 평가한다.
일반적으로 상호참조해결 문제를 다룰 때 문서 내에서 명사 혹은 명사구로 표현되어 등장하는 추상적 객체를 엔티티라 칭하며, 이 엔티티가 문서 내에서 피상적으로 표현된 각 명사구를 멘션(Mention)이라 칭한다[1].
상호참조해결의 결과인 엔티티는 집합이기 때문에 단순히 이진적인 정오로 평가할 수 없다. 때문에 본
논문에서는 상호참조해결 시스템 경진대회였던 CoNLL2011에서 사용한 MUC, B-cube, CEAFE를 사용했다.
2. 관련연구
영문 상호참조해결에서는 CoNLL2011에서 소개된 바 있는 규칙기반 시스템인, Multi-pass Sieve[6]시스템이 MUC-F1 61.0%, B-cube-F1 70.8%, CEAFE-F1 47.9%
의 성능으로 가장 우수했다. 이와 같은 방법을 사용한 한국어 상호참조 해결 시스템[8]은 MUC-F1 58.97%, B-cube-F1 59.50%, CEAFE-F1 63.47%의 성능으로 소개된 바 있다.
단순한 분류문제가 아닌 상호참조해결 문제는 곧바로 기계학습 분류기를 사용하여 처리하기 힘들다. 이를 해결하기 위해 상호참조해결 문제를 분류문제로 바꾸어 기계학습을 통해 수행하기 위해 고안된 방법으로는 멘션 페어(Menbtion Pair), 엔티티 멘션(Entity Mention), 멘션 랭킹(Mention Ranking) 등이 있다. 멘션 페어를 기반한 영문 상호참조해결 시스템에서 54.1% B-cube- F1 성능을 보였고, 엔티티 멘션, 멘션 랭킹을 기반한 영문 상호참조해결 시스템은 각각 54.3%, 56.9%의B- cube-F1 성능을 보였다[7].
3. 다-단계-시브(Multi-pass-sieve)
다-단계-시브는 상호참조해결 시스템 컨퍼런스였던 CoNLL2011에서 우승한 시스템인 Stanford의 Multi- pass Sieve을 한국어에 적합하게 변형하여 적용한 규칙기반의 상호참조 해결 시스템이다[8]. 시브는 두 멘션의 참조를 예측하는 휴리스틱 기반의 규칙 단계로써, 문서내의 멘션들을 각 시브를 거치면서 멘션간의 상호참조관계를 예측하게 된다.
다-단계-시브 시스템은 1-정확한 문자열 일치, 2- 엄밀한 구문, 3,4,5-엄격한 중심어 일치 A,B,C, 6- 관대한 중심어 일치, 7-고유 중심어 일치, 8-대명사 상호참조 해결, 8개 시브를 갖고 있다.
8개의 시브에 대한 모든 조합을 가이드 멘션 페어 시스템에 적용 평가했다. 그 중 성능이 가장 우수했던 시브 1,2,3,4,6,7,8 조합을 가이드 멘션 페어 시스템의 다-단계-시브 과정으로 사용하여 최종 성능을 평가했다.
4. 한국어 가이드 멘션 페어(Guide Mention Pair) 시스템 가이드 멘션 페어 모델은 멘션 페어 모델에 다른 시스템의 결과를 가이드 자질로 추가하여 구축한 모델을 말한다. 본 논문에서 가이드로 사용한 시스템은 다-단계-시브의 예측 결과를 사용하여 가이드 자질을 만들었다.
본 논문에서 제안하는 가이드 멘션 페어 모델 기반의 한국어 상호참조해결 시스템은 크게 네 단계로 이루어져 있다.
먼저 ETRI언어분석기를 이용하여 형태소 분석, 의존구문 분석, 개체명 인식을 수행하여 문서에 추가한다.
그 다음으로는 언어분석기의 결과를 받아 멘션들을 찾아내어 멘션 리스트를 결과물로 반환하는 멘션 탐색(Mention Detection)과정을 거친다.
앞선 두 과정의 결과물로 얻은 멘션 리스트에서 각각의 멘션들을 모두 두 개씩 묶어 멘션 페어를 구축함과 동시에 페어로 묶인 두 멘션간의 관계와 각 멘션의 특징들을 자질로 추가하는 자질 추출(Feature Extraction) 과정을 거친다. 이때 한국어 다-단계- 시브 시스템의 두 멘션에 대한 상호참조 예측 결과를 하나의 자질로 사용한다. 사용한 자질들은 아래 표1로 나타냈으며, 가이드 자질을 포함해 총 32개의 자질을 사용했다.
마지막으로 별도의 학습과정을 거친 SVM 분류기[5]를 이용하여 자질이 추가된 멘션 페어들의 참조여부를 평가하고, 취합하여 멘션 페어들을 엔티티로 재구성하고, 싱글턴 엔티티를 제거한다.
표 1. 한국어 멘션 페어 시스템에 사용한 자질
4. 실험
가이드 멘션 페어 시스템의 성능을 타 시스템과 비교하기 위해, 연구원들이 직접 제작한 221개의 문서로 구축된 말뭉치를 이용하여 다-단계-시브 시스템을 평가했고, 순수 멘션 페어 시스템과, 가이드 멘션 페어 시스템에 대해서는 5 fold cross validation을 수행했다.
4.1 실험 데이터
신문기사와 위키피디아 문서에서 얻은 자연어 문서를 ETRI의 언어분석기를 이용하여 형태소 분석, 개체명 인식, 의존구문분석을 과정을 처리하고, 수작업으로 상호참조 정보를 추가해 말뭉치를 제작했다. 또한 2명의 연구원의 검수와 수정을 통하여 말뭉치를 정제했다. CoNLL2011의 평가 규칙을 따라 문서 내에서 단 한번도 상호참조되지 않은 멘션, 싱글톤 엔티티는 추가하지 않았다.
201개의 질의응답 문서는 632개의 엔티티와 1616개의 멘션을 포함하고 있고, 20개의 신문기사 문서는 159개의 엔티티, 485개의 멘션을 포함하고 있다.
4.2 실험결과
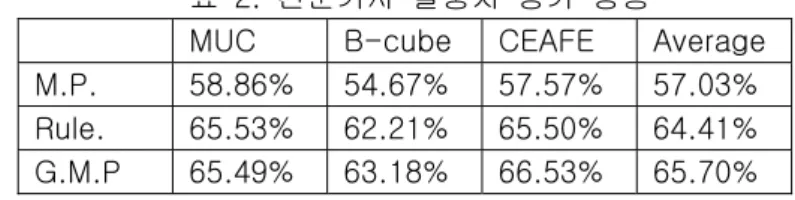
각 시스템들을 직접 구축한 말뭉치를 대상으로 평가한 결과를 표 2와 표 3으로 나타냈다. 표 2. 와 표 3.에서 M.P.는 멘션페어 기반 시스템의 성능을 나타내고, Rule는 8개의 모든 시브를 사용한 다-단계- 시브 시스템의 성능을 나타내며, G.M.P. 는 가이드 멘션 페어 시스템의 성능을 나타낸다.
표 2. 신문기사 말뭉치 평가 성능
MUC B-cube CEAFE Average M.P. 58.86% 54.67% 57.57% 57.03%
Rule. 65.53% 62.21% 65.50% 64.41%
G.M.P 65.49% 63.18% 66.53% 65.70%
표 3. 전체 말뭉치 평가 성능
MUC B-cube CEAFE Average M.P. 56.37% 56.46% 60.38% 57.74%
Rule. 62.86% 63.19% 68.86% 64.94%
G.M.P 63.15% 63.57% 69.21% 65.31%
가이드 멘션 페어 시스템은 규칙기반 시스템보다 신문기사 말뭉치에 대해서는 1.31%, 전체 말뭉치에 대해서는 0.37%가량 향상되었다.
5.결론
같은 자질을 사용한 순수 멘션 페어 모델보다 보다 가이드 멘션 페어 모델이 월등히 우수한 성능을 나타냈다. 또 규칙기반 시스템 보다 도 다소 우수했다.
다-단계-시브 시스템의 각 시브에서의 참조여부 결과들을 각각 하나의 자질로 추가하여 시스템을
구축한다면 더 우수한 성능을 기대 할 수 있을 것으로 본다.
감사의 글
본 연구는 미래창조과학부 및 한국산업기술평가 관리원의 업융합원천기술개발사업(정보통신)의 일환으로 수행하였음[10044577, 휴먼 지식증강서비스를 위한 지능진화형 WiseQA 플랫폼 기술 개발]
6.참고문헌
[1] Sameer Pradhan, Lance Ramshaw, Mitchell Marcus, Martha Palmer, Ralph Weischedel, Nianwen Xue,
“Conll-2011 shared task: Modeling unrestricted coreference in ontonotes.” Association for Computational Linguistics: Proceedings of the Fifteenth Conference on Computational Natural Language Learning: Shared Task, pp. 1-27, 2011.
[2] Marc Vilain, John Burger, John Aberdeen, Dennis Connolly, Lynette Hirschman, "A model-theoretic coreference scoring scheme."Proceedings of the 6th conference on Message understanding. Association for Computational Linguistics, 1995.
[3] Bagga, Amit, and Breck Baldwin. "Algorithms for scoring coreference chains."The first international conference on language resources and evaluation workshop on linguistics coreference. Vol. 1. 1998.
[4] Luo, Xiaoqiang. "On coreference resolution performance metrics." Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2005.
[5] Lee, Changki, and Myung-Gil Jang. "Fast training of structured SVM using fixed-threshold sequential minimal optimization." ETRI journal 31.2 (2009): 121- 128, 2009.
[6] Lee, Heeyoung, et al. "Stanford's multi-pass sieve coreference resolution system at the CoNLL-2011 shared task." Proceedings of the Fifteenth Conference on Computational Natural Language Learning: Shared Task. Association for Computational Linguistics, 2011.
[7] Rahman, Altaf, and Vincent Ng. "Supervised models for coreference resolution."Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 2-Volume 2. Association for Computational Linguistics, 2009.
[8] Cheoneum Park, Kyoungho Choi, Changki Lee,
“Korean Coreference Resolution using the Multi-pass Sieve”, Journal of KIISE, JOK, Vol. 41, No. 11, pp. 992- 1005, 2014.