A Framework for Internet of Things (IoT) Data Management
1)
전체 글
1)
수치
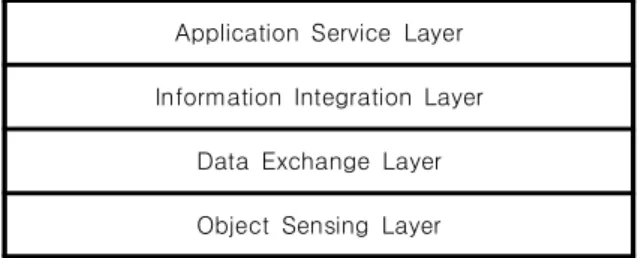
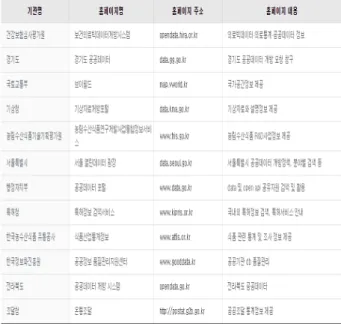
관련 문서
Introduction to Data Communication Networks, M2608.001200, 2021 FALL SEOUL NATIONAL
표면 불순물층 중부인 dark gray 상 (Zr-rich zone) 의 안쪽 부위까지는 Si 침투가 이뤄지지 않음. • Uranium은 중부 dark gray
• Mechanism of boundary layer growth on a smooth flat plate - Boundary layer flow: laminar → transition → turbulent - Velocity of the fluid particle at the body wall is
The simplest method of storing a raster layer in the memory of the computer is using a data structure called an array.. We consider alternative methods for searching through
19 Movie: Boundary layer concept (Velocity profile near plate, Boundary layer thickness on moving plate) ./mmfm_movies/1_02035_04.mov ./mmfm_movies/2_02005.mov. 20 Movie:
An RNN model is neural network architecture using a single layer or multiple layers, consisting of circulation connections, commonly applied for learning the
□ Each host and router on a subnet needs a data link layer address to specify its address on the subnet. § This address appears in the data link layer frame sent on
congestion avoidance: additive increase loss: decrease window by factor of 2 congestion avoidance: additive increase loss: decrease window by factor of
