Received 19 January 2021, Revised 17 February 2021, Accepted 02 March 2021 *Corresponding Author Jeongkyu Hong (E-mail: [email protected], Tel: +82-53-810-2553)
Department of Computer Engineering, Yeungnam University, Gyeongsan, Gyeongbuk 38541, Republic of Korea.
https://doi.org/10.6109/jicce.2021.19.1.22 print ISSN: 2234-8255 online ISSN: 2234-8883
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
Copyright ⓒ The Korea Institute of Information and Communication Engineering
MATE: Memory- and Retraining-Free Error Correction for
Convolutional Neural Network Weights
Myeungjae Jang1 and Jeongkyu Hong2* , Member, KIICE
1School of Computing, Korea Advanced Institute of Science and Technology, Daejeon 34141, Republic of Korea 2Department of Computer Engineering, Yeungnam University, Gyeongsan, Gyeongbuk 38541, Republic of Korea
Abstract
Convolutional neural networks (CNNs) are one of the most frequently used artificial intelligence techniques. Among CNN-based applications, small and timing-sensitive applications have emerged, which must be reliable to prevent severe accidents. However, as the small and timing-sensitive systems do not have sufficient system resources, they do not possess proper error protection schemes. In this paper, we propose MATE, which is a low-cost CNN weight error correction technique. Based on the observation that all mantissa bits are not closely related to the accuracy, MATE replaces some mantissa bits in the weight with error correction codes. Therefore, MATE can provide high data protection without requiring additional memory space or modifying the memory architecture. The experimental results demonstrate that MATE retains nearly the same accuracy as the ideal error-free case on erroneous DRAM and has approximately 60% accuracy, even with extremely high bit error rates. Index Terms: Convolutional neural network, Error correction codes, Main memory, Reliability, Weight data
I. INTRODUCTION
The use of deep neural networks (DNNs) was first pro-posed in the early 21st century and has become the most popular and practical artificial intelligence technology. Many DNN-related studies have been conducted, out of which many systems with real-world applications have emerged. Among various DNNs, a convolutional neural network (CNN) is a popular form of neural network for image processing. Supported by a feature extraction technique called convolu-tion, it increases the overall image processing accuracy. The latest CNN winner of the ImageNet Large Scale Vision Rec-ognition Challenge (ILSVRC) [1] officially exceeds human accuracy for image processing. With this technological advancement, many companies have accepted CNN-based image processing as the core technique for their products or services.
In particular, several CNN-based small and timing-sensi-tive systems have also recently emerged, such as drones, robots, and Internet of Things (IoT) edge devices. These sys-tems typically use CNN object–based recognition to accom-plish their missions. Therefore, the accuracy of CNN is a key factor in determining the success of a system, and thus maintaining high accuracy in various situations is very important. However, maintaining accuracy is difficult. Many studies have reported that memory data integrity becomes weaker with memory scaling, and the bit error rate (BER) can be up to 10−4 [2, 3]. In addition, low-power DRAM architecture, which reduces memory power consumption by decreasing the data sensing voltage or time, considerably decreases data reliability [4]. Therefore, adequate memory data protection is required to maintain the inference accu-racy, considering the resource constraints of small and tim-ing-sensitive systems.
To provide cost-effective protection for such systems, we identified the following four design constraints that must be considered. First, the CNN accuracy must be maintained during the repetitive inference process. A small loss of accu-racy may be acceptable in normal systems, but not in timing-sensitive systems. Second, hardware constraints should be considered. Our target systems have many physical limita-tions, such as area, power consumption, and weight; thus, their error protection components must be small. Third, the error correction process must be sufficiently short to satisfy real-time constraints. Fourth, memory errors should be detected and corrected as soon as possible before completing the CNN inference to prevent error. Because weight data are repetitively referenced, few-bit errors may cause a signifi-cant loss of accuracy.
To address all these considerations, we propose MATE, a memory- and retraining-free error correction technique for CNN weights. MATE protects CNN weight data stored in the main memory (DRAM) during the repetitive inference pro-cess. Based on observations that not all mantissa bits of the 32-bit floating-point (FP32) weight data affect the CNN accuracy, MATE utilizes a part of mantissa bits as error cor-rection codes (ECCs), such as triple modular redundancy (TMR), single error correction, and double error detection (SECDED) codes. Experimental results demonstrated that MATE achieves nearly the same accuracy as the ideal error-free case at 10−8 to 10−5 BER, without requiring additional memory space and modifications to the memory architecture. Furthermore, even in a harsh environment with a BER of 10−4, the proposed scheme maintains an ideal accuracy of 99.77%. Compared with the previously proposed competitive scheme, St-DRC [5], MATE shows 31.35% higher normal-ized accuracy at 10−4 BER with fewer hardware overheads and CNN transformation. We summarize our contributions as follows:
• For the FP32 datatype of CNN weights, we observe that the lower 19 bits of the 23 mantissa bits do not affect the inference accuracy.
• The proposed scheme preserves the ideal accuracy from 10−8 to 10−4 BER, and approximately 60% of the ideal accuracy even at 10−3 BER where the competitive scheme completely fails to inference.
• Because the proposed scheme operates on the basis of the conventional 32-bit system, it can be applied to small, timing-sensitive systems where it is difficult to modify the system architecture or utilize the dedicated GPUs. The remainder of this paper is organized as follows. In Section II, we present the background of the FP32 datatype (based on the IEEE 754 standard). We explain our key obser-vations and the proposed MATE scheme in Section III. The experimental evaluation of the MATE is presented in Section IV. Related works on CNN reliability are briefly introduced in Section V. Finally, we present our conclusions in Section VI.
II. BACKGROUNDS
A. FP32 Datatype
The floating-point datatype represents a wide dynamic range of numeric values using a floating radix point. Com-pared with the fixed-point value of the same bit width, the floating point can represent a wider range of numbers at the cost of value precision. Fig. 1 shows the schematic layout of the FP32 datatype on the IEEE 754 standard; the most sig-nificant bit (MSB) represents a sign, the next 8 bits are called the “exponent” bits and collectively interpreted as the exponential value, and the remaining 23 bits are called the “mantissa” bits, which conclude the detailed logical value.
exp = exponent, Mant = Mantissa (1)
Equation (1) shows the process of FP32 datatype transla-tion to real values based on the IEEE 754 standard. As shown in this equation, changes in the exponent bits can result in a completely different value as the exponent bits determine the logical magnitude of the data value. Further-more, the exponent bits near the MSB position have a signif-icant effect on the real value. For example, a bit flip on the 30th bit changes the value up to 2128 times. In addition, if all the exponent bits become one (i.e., 11111111), an exception of NaN (Not-a-Number) occurs. Because most CNNs use the FP32 datatype as their weights, the integrity of FP32 is closely related to the CNN’s inference results.
B. CNN Weights
Fig. 2 shows the data distribution of the nine CNNs sup-ported by Darknet [6]. Here, Inputs indicates the number of input image pixels. Weights denote the number of weights and biases in all the convolutional and fully connected lay-ers. Outputs (CONV, FC) are the number of output values computed by the convolutional and fully connected layers, whereas Outputs (Others) is the number of outputs from other layers. All inputs, weights, and output values are com-posed of FP32 datatype, and the proportion of each part is equal to the required memory space, which indicates that more than half of the memory space is used for the weights. Outputs also have a high proportion, but most of the outputs Fig. 1. FP32 datatype based on the IEEE 754 standard.
are in the cache areas and are removed after being used directly as inputs for the next layer during inference. There-fore, CNN weight data are more vulnerable to memory errors, and the errors in the CNN weight data can result in significant accuracy loss.
In addition, small and timing-sensitive systems usually do not perform both the training and inference processes because of latency and computing resource limitations. They employ pre-trained CNNs for inference, and the training is usually performed on a large-scale remote server. A retrained CNN can be obtained through periodic communication with the server. Because communication causes much less over-head than self-training, we only consider the inference pro-cess by assuming that well-trained CNN weights are already available. During the inference process, multiple repeated multiplication and accumulation (MAC) operations are per-formed on an input image. This process is repeated for every image of every layer, and finally, the outputs of the last layer become the results of the inference. Hence, if there are errors in the weights, the faulty results can be accumulated across multiple layers resulting in a significant accuracy loss.
III. MATE: MEMORY- AND RETRAINING-FREE
CNN WEIGHT ERROR CORRECTION
Most previous schemes that focus on high-performance or low-power system architectures do not consider data vulner-ability by relying on CNN error robustness. Although several studies have provided error protection for CNN inference, they are usually based on retraining, which is not suitable for small and timing-sensitive IoT/embedded systems because of the large resource requirements. Therefore, we propose a cost-effective CNN weight error correction scheme, MATE, which does not require additional memory area or retraining to retain CNN accuracy, based on the following two key observations. A. Key Observations
First, all exponent bit patterns in the CNN weights were
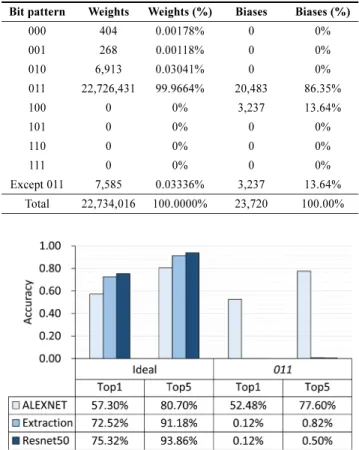
closely related to the CNN accuracy. Table 1 shows the num-ber of weights in terms of the upper three-bit patterns of the exponent in Resnet50 (the 28th, 29th, and 30th bits in Fig. 1). The results show that most weights (more than 99.97%) have the same bit pattern, 011. However, we found that weights that do not have the 011 exponent bit pattern can seriously affect the CNN accuracy despite their small portion. Fig. 3 shows the accuracy for three CNNs (ALEXNET, Extraction, and Resnet50), assuming that all the weights have a 011 exponent bit pattern without any errors. ALEXNET has Top1 and Top5 accuracy losses of 4.82% and 3.10%, respectively, which are not significant. However, Extraction and Resnet50 have significant accuracy losses that are no longer available, because the upper exponent bits can significantly change the weight value (up to 2128 times) and the erroneous weight data is continuously applied to MAC operations.
Second, not all mantissa bits in the CNN weights are closely related to the CNN accuracy. Fig. 4 shows the rela-tionship between the accuracy loss and the mantissa bit reduction. As shown in this figure, there was approximately the same accuracy as the ideal even if 18 of the 23 mantissa bits were removed. Even with only four mantissa bits, the average accuracy was 99.20%. Extraction suffers the greatest accuracy losses, but is still within 5% of the ideal. Based on Table 1. The upper three exponent bit patterns in Resnet50
Bit pattern Weights Weights (%) Biases Biases (%)
000 404 0.00178% 0 0% 001 268 0.00118% 0 0% 010 6,913 0.03041% 0 0% 011 22,726,431 99.9664% 20,483 86.35% 100 0 0% 3,237 13.64% 101 0 0% 0 0% 110 0 0% 0 0% 111 0 0% 0 0% Except 011 7,585 0.03336% 3,237 13.64% Total 22,734,016 100.0000% 23,720 100.00%
Fig. 3. Accuracy comparison between the ideal case and the case where upper three bits of the exponent are replaced with 011 without any errors.
these two observations, our proposed scheme protects the sign bit, all the exponent bits, and only four or five bits of 23 mantissa bits of the CNN weights.
B. MATE Architecture
By using the removed mantissa area as a storage space for ECCs and metadata for error correction, MATE effectively protects the weight data without any accuracy losses and modifications to the conventional memory architecture. Fig. 5 shows a conceptual view of the proposed scheme. MATE requires three simple components in the memory controller: an encoder, an error checker, and a decoder. Note that the conventional DRAM architecture does not need to be modi-fied. The MATE encoder encodes the raw weight data read from the secondary storage to include an error correction code for a DRAM write operation (WR). After generating ECCs without considering the lower 19 mantissa bits, the ECCs are stored in the position where the excluded 19 man-tissa bits are located. Therefore, all the weights stored in the main memory have an encoded form. In contrast, the MATE error checker and decoder are used for DRAM read
opera-tion (RD). The MATE error checker checks the data integrity and corrects any errors, and decodes the read weight data as the reverse of the encoding process.
C. MATE Encoding and Decoding Process
1) Write operation
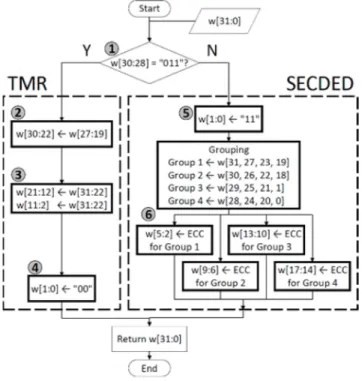
To maximize the error protection efficiency, MATE distin-guishes the CNN weights into two parts, exponent bits start-ing with 011 and non-011, and provides different error protection schemes, TMR and SECDED. Fig. 6 shows the detailed process for ECC encoding on the DRAM write. w[x:y] represents one FP32 weight data from the y-th bit to the x-th bit, and these bit indices are the same as those used in Fig. 1.
First, when the FP32 datatype weight w[31:0] is loaded from a secondary storage, the MATE encoder checks whether the upper three bits of the exponent (i.e., w[30:28]) are 011 (circle 1). If true, the encoder excludes not only the 19 bits of the mantissa but also the 011 bits of the exponent, to min-imize the amount of data that needs to be protected (circle 2). Therefore, only 10 bits remain (1-bit sign + 5-bit expo-nent + 4-bit mantissa = 10 bits), which are small enough to apply a triple modular redundancy (TMR) scheme (circle 3). After occupying 30 bits for TMR protection, two bits (w[1:0]) remain and are used as flags to notify the protection scheme as TMR. In this case, we assigned 00 (circle 4). Because almost all the CNN weights belong to this TMR
Fig. 6. MATE encoding process.
Fig. 4. Normalized Top1 accuracy in CNNs when the N lower mantissa bits are removed. The legend shows the number of removed lower mantissa bits, N.
protection type, we can achieve high reliability.
Otherwise, if the upper three exponent bits are not 011, the encoder retains the entire 8-bit exponent to be protected. Because the CNN weights have different exponent bit pat-terns, all exponent bits must remain for data consistency. As a result, the total number of data bits becomes more than 13; thus, TMR protection cannot be applied. Hence, we provide SECDED protection instead of TMR (right side of Fig. 6). To maximize bit efficiency and data reliability, we generate 16-bit data by storing 5-bit mantissa rather than 4-bit and a 2-bit flag, which is set to 11 (circle 5). As a result, the 1-bit sign + 8-bit exponent + 5-bit mantissa + 2-bit flag becomes 16 bits in total. Then, the 16-bit data are divided into four 4-bit groups so as to apply Hamming (8, 4) SECDED codes to each group, which enables up to 4-bit error correction and 8-bit error detection (circle 6). However, as we discussed, each exponent bit does not have the same importance in terms of CNN accuracy. If the SECDED protection fails owing to two or more consecutive errors in the upper exponent bit, it can result in a higher accuracy loss than if the lower exponent bit is defective. Therefore, we group 16 data bits one by one to ensure that a certain SECDED is not dedicated to protecting more sensitive data bits than others by having contiguous bits.
2) Read Operation
Read operations require both error checking and data decoding. First, the MATE error checker checks the flag bits to determine which ECCs are used. If the flag bits are intact (00 or 11), the error checker can perform a proper error detection and correction process with TMR or SECDED. In contrast, if an error occurs, thereby changing the flag bits to 01 or 10, the error checker assumes that the original flag bit value is 11, and tries to restore the flag bits with SECDED. If the corresponding SECDED can correct the single-bit error, the assumption is correct, and the error checking pro-cess can be conducted for the remaining bits. However, if the corresponding SECDED cannot correct the error, the error checker applies for TMR protection, assuming the flag value was originally 00.
After error correction, a decoding process is performed, which is the reverse of the encoding process. However, even after completing the error correction process, some errone-ous bits may remain because the ECCs cannot correct all errors. In particular, if the defected bits are in the exponent part, the weight value differs significantly from the original value. Therefore, to enhance the weight data integrity, we performed post-processing for the exponent value. Accord-ing to previous studies on weight quantization, more than 99.99% weight values were located between -2.0 and +2.0 [7-9]; the MATE decoder verifies whether the weight value is over 512, and simply flips the 30th bit to zero to make a small weight value. Although it is not a correct error
correc-tion process, it prevents significant CNN accuracy loss by avoiding suspicious large weight values.
IV. EXPERIMENTAL RESULTS
A. Experimental Environment
To verify the reliability of the CNN, we injected bit errors on Darknet [6], and the errors were injected into the weights according to the given BERs. All the CNNs were pre-trained with the ImageNet 2012 [1] training dataset, and all the experiments used the ImageNet 2012 validation dataset to measure the CNN accuracy. Intel Core i7-6850K CPU and NVIDIA GeForce TITAN X Pascal GPU were used for the simulation. The experimental results are shown in terms of the normalized accuracy, which indicates the ratio of the erroneous weight-based accuracy to the ideal error-free weight-based accuracy. For example, if the ideal error-free accuracy was 60% and the accuracy obtained with erroneous weights was 40%, then the normalized accuracy was 66.7%. B. Analysis of Accuracy Loss
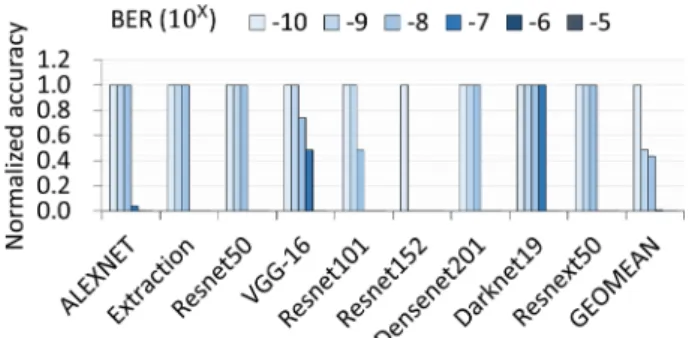
Before confirming the CNN reliability with MATE, we first conducted an experiment to verify the error robustness of the nine CNNs. Previous studies [10-13] reported that a CNN has some error robustness, and thus its accuracy cannot further decrease when there are only resistible faults. How-ever, as shown in Fig. 7, which shows the normalized aver-age accuracy with various BERs from to 10−10 to 10−5, all CNNs lose their accuracy without a proper error protection scheme. Every CNN gradually loses its accuracy as the BER increases, and its inference begins to fail at a BER of 10−7, except for Darknet19 and VGG-16. Resnet152 was the most error-sensitive CNN and started to fail at a BER of 10−9. Although the current JEDEC standard is 10−15 BER [14], we need to consider the various environments in which the safety- and/or timing-critical systems and the memory vul-nerability trend. Fig. 8 shows the accuracy losses in the nine CNNs after adopting the proposed MATE with various BERs
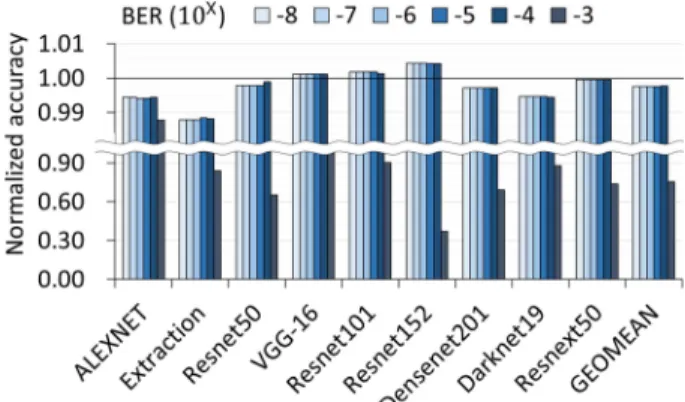
from 10−8. On average, MATE preserves almost the same accuracy up to 10−5 BER and shows only a 1% accuracy loss at 10−4 BER. Extraction has the highest accuracy loss, but it is still less than 2%. Even with an extremely high BER of 10−3, the proposed error protection scheme maintains an inference accuracy of approximately 60%.
For state-of-the-art CNNs, having more layers does not mean having more weights. Current CNN designers increase the number of convolutional layers with fewer weights for better training performance. However, this approach worsens the error robustness of the weight, and thus makes CNN weight protection more important. Hence, MATE can be an effective solution for the reliability of future CNN infer-ences. In addition, low-power DRAM architecture, which reduces DRAM power consumption by scaling down the data sensing voltage or time (tRC), has a much higher BER than the conventional DRAM. Because the increased BER is one of the major obstacles to further scaling [4], the high fault-tolerance of MATE enables the use of low-power DRAM with significantly reduced timing or voltage parame-ters.
C. Comparison with Competitive Work
As shown in Fig. 3, the competitive scheme, St-DRC [5], which uniformly replaces the exponent bits to 011, cannot be used for pre-trained CNNs because of the significant loss of accuracy. Hence, for a fair comparison, we assume that the CNNs have been trained using St-DRC. Fig. 9 shows the Top1 accuracy when changing the BER range from 10−7 to 10−3 for three CNNs (ALEXNET, Extraction, and Resnet50) after applying MATE and St-DRC. Before reaching a 10−5 BER, both techniques preserved the ideal accuracy. How-ever, St-DRC lost its accuracy at 10−4 BER and completely failed to inference at 10−3 BER. In contrast, MATE main-tains the inference accuracy at 10−4 BER and achieves a much higher accuracy even at 10−3 BER. As a result, the
proposed MATE outperforms St-DRC by preserving the inference accuracy even at a higher error probability without requiring any retraining process.
V. RELATED WORK
Since the 1990s, reliability has been one of the main research areas in the field of CNNs. In the early years, most studies were conducted at the algorithm level. Bolt [10] sum-marized various algorithm-level studies and classified the factors potentially affecting the CNN accuracy. After the 2000s, CNN reliability became an important issue at the sys-tem and architecture levels. Pullum et al. [15] discussed the importance of risk analysis for neural networks and empha-sized the importance of a reliable CNN for autonomous spacecraft flight systems. Mittal [16] summarized architec-ture-level studies conducted in the 2010s. Li et al. [17] clas-sified several factors that affect CNN accuracy and proposed optimized error correction techniques for each factor.
VI. CONCLUSIONS
Most previous studies have used CNN’s error robustness to improve performance or energy savings with approximate computing, such as quantization. However, these approaches are impractical for upcoming timing-critical or resource-lim-ited systems because of their accuracy losses and retraining overhead. In this paper, we proposed MATE, a low-cost error protection technique for CNN weights. Based on several bit-level observations, MATE utilizes insignificant mantissa bits to store ECC bits. The removed mantissa bits do not affect the CNN accuracy, and the conventional DRAM can be used without any modification by using the empty space. Experi-mental results show that MATE preserves the ideal inference accuracy at up to 10−4 BERs for nine state-of-the-art CNNs without retraining.
Fig. 8. Normalized Top1 accuracy after applying MATE.
Fig. 9. Top1 accuracy in ALEXNET, Extraction, and Resnet50 after applying MATE and St-DRC.
ACKNOWLEDGEMENTS
This work was supported by a National Research Founda-tion of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2019R1G1A1003780).
REFERENCES
[ 1 ] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, and A. C. Berg, “ImageNet large scale visual recognition challenge,” International Journal of Computer Vision (IJCV), vol. 115, no. 3, pp. 211-252, 2015. DOI: 10.1007/s11263-015-0816-y.
[ 2 ] P. J. Nair, V. Sridharan, and M. K. Qureshi, “Xed: Exposing on-die error detection information for strong memory reliability,” in ACM/ IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), pp. 341-353, 2016. DOI: 10.1109/ISCA.2016.38.
[ 3 ] P. J. Nair, D. Kim, and M. K. Qureshi, “Archshield: Architectural framework for assisting dram scaling by tolerating high error rates,” ACM SIGARCH Computer Architecture News, vol. 41, no. 3, pp. 72-83, 2013. DOI: 10.1145/2508148.2485929.
[ 4 ] K.K. Chang, A.G. Yağlıkçı, S. Ghose, A. Agrawal, N. Chatterjee, A. Kashyap, D. Lee, M. O'Connor, H. Hassan, and O. Mutlu, “Understanding reduced-voltage operation in modern DRAM devices: Experimental characterization, analysis, and mechanisms,” in Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 1, no. 1, pp. 1-42, 2017. DOI: 10.1145/ 3084447.
[ 5 ] D. Nguyen, N. Ho, and I. Chang, “St-drc: Stretch-able dram refresh controller with no parity-overhead error correction scheme for energy-efficient DNNs,” in Proceedings of the 56th Annual Design Automation Conference 2019, pp. 1-6, 2019. DOI: 10.1145/3316781. 3317915.
[ 6 ] J. Redmon, “Darknet: Open source neural networks in c,” 2013-2016. [online] Available: http://pjreddie.com/darknet/.
[ 7 ] E. Park, S. Yoo, and P. Vajda, “Value-aware quantization for training and inference of neural networks,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 580-595, 2018. [ 8 ] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing
deep neural networks with pruning, trained quantization and huffman coding,” arXiv preprint arXiv:1510.00149, 2015.
[ 9 ] J. H. Ko, D. Kim, T. Na, J. Kung, and S. Mukhopadhyay, “Adaptive weight compression for memory-efficient neural networks,” in Design, Automation & Test in Europe Conference & Exhibition (DATE), pp. 199-204, 2017. DOI: 10.23919/DATE.2017.7926982. [10] G. R. Bolt, “Fault tolerance in artificial neural networks: Are neural
networks inherently fault tolerant?,” 1996.
[11] Q. Shi, H. Omar, and O. Khan, “Exploiting the tradeoff between program accuracy and soft-error resiliency overhead for machine learning workloads,” arXiv preprint arXiv:1707.02589, 2017. [12] P. J. Edwards and A. F. Murray, “Can deterministic penalty terms
model the effects of synaptic weight noise on network fault-tolerance?,” International Journal of Neural Systems, vol. 6, no. 4, pp. 401-416, 1995. DOI: 10.1142/S0129065795000263.
[13] J. T. Ausonio, “Measuring fault resilience in neural networks,” PhD thesis, University of Reading, 2018.
[14] P. Keller, “Understanding the new bit error rate dram timing specifi-cations,” in Proceedings of JEDEC Server Memory Forum, 2011. [15] L. Pullum and B. J. Taylor, “Risk and hazard analysis for neural
network systems,” in Methods and Procedures for the Verification and Validation of Artificial Neural Networks, pp. 33-49, Springer, Boston, MA, 2006. DOI: 10.1007/0-387-29485-6_3.
[16] S. Mittal, “A survey on modeling and improving reliability of DNN algorithms and accelerators,” Journal of Systems Architecture, vol. 104, 2020. DOI: 10.1016/j.sysarc.2019.101689.
[17] G. Li, S.K. S. Hari, M. Sullivan, T. Tsai, K. Pattabiraman, J. Emer, and S. W. Keckler, “Understanding error propagation in deep learning neural network (DNN) accelerators and applications,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Association for Computing Machinery, New York, NY, USA, no. 8, pp. 1-12, 2017. DOI: 10.1145/3126908.3126964.
Myeungjae Jang
Myeungjae Jang received his master’s degree from the School of Computing, Korea Advanced Institute of Science and Technology (KAIST). He is currently pursuing his Ph.D. degree with KAIST. His current research interests include computer architecture for machine learning and neural processing unit.
Jeongkyu Hong
Jeongkyu Hong received the B.S. degree from the College of Information and Communications, Korea University, in 2011, the M.S. degree from the Department of Computer Science, Korea Advanced Institute of Science and Technology (KAIST), in 2013, and the Ph.D. degree from the School of Computing, KAIST, in 2017. He has been with the Department of Computer Engineering, Yeungnam University, since 2018, as an Associate Professor. His current research interests include the design of low-power, reliable, and high-performance processor and memory systems.