다속성 빅데이터로부터 유용한 정보 추출에 관한 연구
- 서울시 1인 가구를 중심으로 -
A Study on Extraction of Useful Information from Big dataset of Multi-attributes
- Focus on Single Household in Seoul -
최정민* 김건우**
Choi, Jung-Min Kim, Kun-Woo
Abstract
This study proposes a data-mining analysis method for examining variable multi-attribute big-data, which is considered to be more applicable in social science using a Correspondence Analysis of variables obtained by AIC model selection.
The proposed method was applied on the Seoul Survey from 2005 to 2010 in order to extract interesting rules or patterns on characteristics of single household. The results found as follows. Firstly, this paper illustrated that the proposed method is efficiently able to apply on a big dataset of huge categorical multi attributes variables. Secondly, as a result of Seoul Survey analysis, it has been found that the more dissatisfied with residential environment the higher tendency of residential mobility in single household. Thirdly, it turned out that there are three types of single households based on the characteristics of their demographic characteristics, and it was different from recognition of home and partner of counselling by the three types of single households. Fourthly, this paper extracted eight significant variables with a spatial aggregated dataset which are highly correlated to the ratio of occupancy of single household in 25 Seoul Municipals, and to conclude, it investigated the relation between spatial distribution of single households and their demographic statistics based on the six divided groups obtained by Cluster Analysis.
Keywords: Big-data, Data-mining, Single Household, AIC, Multi-attributes
주 요 어: 빅데이터, 데이터마이닝, 1인 가구, AIC (Akaike Information Criterion), 다속성
I. 서 론
1. 연구배경 및 목적
근래 들어 빅데이터(big data)의 유효활용에 대한 관심 이 증가하고 있다. 특히, 대량의 다양한 데이터에 내재하 는 지금까지 잘 알려져 있지 않는 규칙이나 패턴을 추출 하여 정보로 활용하는 것에 대한 사회적 관심이 매우 높 아지고 있다.
빅데이터에 관해 아직 명확한 정의는 힘들지만, 거대한 디지털 데이터의 총칭이다. 여기서 말하는 데이터는 어딘
가 한 곳에서 모은 데이터뿐만 아니라 SNS 등의 보급에 따라 거대한 웹정보, 인터넷에 축적되고 있는 대량의 사 진이나 동영상, 센서가 감지하고 전송하는 거대한 물적 정보, 슈퍼컴퓨터 등에 의해 생성된 거대한 숫자 데이터 등 다양한 분야의 다양한 유형의 데이터를 들 수 있다.
빅데이터의 공통된 특징은 주로 분량(다량), 속도(실시간), 유형(다종)으로 규정된다
1).
빅데이터의 궁극적 목적은 단순히 사회현안을 모니터링 하여 잘 알려져 있지 않은 정보를 추출하려는 것에만 있 는 게 아니라, 시뮬레이션 등을 통해 맞춤형 서비스 모형 을 개발하고, 나아가 서비스의 지원 및 정책을 수립하여 궁극적으로는 행복한 사회 실현에 연계하려는 것이라고 할 수 있다.
이러한 상황에도 불구하고 지금까지 주거, 도시, 건축 등 사회과학 분야에서는 빅데이터의 유효활용에 대한 학 술연구나 논의가 부족하였다. 그 이유는 첫째, 이 분야에 서는 빅데이터 분석에 이용할 만큼 대규모 양질의 데이
**정회원(주저자, 교신저자), 건국대학교 건축대학 주거환경전공 교 수, 공학박사
**정회원, 건국대학교 일반대학원 건축학과 석사과정
Corresponding Author: Jung-Min Choi, Dept. of Architecture, Konkuk Univ., College of Architecture, 120 Neungdong-ro, Gwangjin-gu, Seoul Korea. E-mail: [email protected] 이 논문은 서울 데이터를 활용한 2013년 서울 연구 논문 공모전에 응모 제출한 논문임.
이 논문은 2011년도 정부(교육과학기술부)의 재원으로 한국연구재 단의 지원을 받아 수행된 기초연구사업임(No. 2011-0009607).
1) 野村 稔 (2013). 米國政府のビッグデ一タへの取り組み. 科學技術 動向, 9-10月 , 24.
터, 즉 DB가 구축되지 않았거나, 둘째, 어느 정도 DB는 구축되었지만 공개하지 않아 자료 활용에 한계가 있었거 나, 셋째, 자료DB는 구축되고 공개되었어도 분석할 수 있 는 기법이 제한되었거나 또는 힘들어 응용사례가 드물어 잘 알려져 있지 않았기 때문인 것으로 판단된다. 이는 “1) 빅데이터 구축 → 2) 자료 접근성 → 3) 분석기법 적용 및 정보 추출”이라는 일련의 과정이 원활히 이루어질 수 있 는 환경 구축의 중요함을 보여준다고 할 것이다.
이러한 관점에서 최근 공공기관에서는 다종 다량의 양 질 데이터를 학술연구 목적으로 개방하기 시작하였다
2). 따 라서 비로소 빅데이터 분야에서의 연구가 조금씩 활기를 띨 수 있는 환경, 즉 위에서 언급한 1), 2)의 분위기가 점 차 마련되고 있다고 할 수 있다. 이렇게 데이터라는 ‘장 소’를 공개적으로 제공함으로써 연구자들이 다양한 학술 활동을 펼쳐 혁신과 새로운 부가가치를 창출할 수 있다 는 장점이 있다.
빅데이터는 일반적으로 데이터마이닝(Data mining)이라 는 기술로 접근하여 분석하며, 학문적으로는 발견과학 (Finding science) 에 해당된다. 데이터마이닝이란 통상 대 량의 데이터를 분석하여 중요한 정보를 얻어 현실에 응 용하는 기법을 의미한다. 데이터마이닝은 복합된 학문 분 야의 이론들이 서로 접목되어 있어서 통계학자나 컴퓨터 학자 또는 경영학자들이 서로 자기 분야라고 주장하기도 한다. ‘대량의 데이터 분석’이라는 공통적인 과제를 해결 하기 위해 여러 학문분야의 사람들이 협력하여 데이터마 이닝이라는 새로운 분야를 만들었다
3).
이 같은 배경을 바탕으로 본 연구에서는 주거, 도시, 건 축과 같은 분야에서 향후 활용성이 높을 것으로 판단되 는 새로운 데이터마이닝 응용기법을 제안하고, 이를 서울 서베이 속성정보 DB에 적용하여 1인 가구의 특성을 추 출하고, 이 과정에서 제안 분석기법의 유효성을 증명하고 자 한다. 또한 서울시 집계구별 인구, 가구, 주택 통계자 료로부터 공간에 관한 정보를 공간단위 위계별로(집계 구 → 자치동 → 자치구) 재집계할 수 있도록 분석테이블 을 만들어 사용한다. 이를 기초로 자치구별 1인 가구 점 유비율을 계산 및 관련 요인을 추출하고, 이에 따라 자치 구별 특성을 유형화하여 1인 가구의 공간적 분포특성을 규명하는 것을 연구목적으로 한다.
2. 연구내용 및 방법
본 연구에서는 2013년 서울연구원이 수집한 서울서베이 (2005~2010 년) 자료와 서울시 집계구별 자료(2010년)를 분석에 활용하였다. 먼저, 연구범위는 1인 가구 특성을 파
악하기 위해 크게 속성정보 자료와 공간정보 자료로 분 류하였다. 속성정보 자료로는 <서울서베이> 설문자료가 분석에 적합하다고 판단하였으며, 공간정보 자료로는 집 계구별 통계(인구, 가구, 주택, 사업체)자료와 건물집계 자 료가 적합하다고 판단하였다. 이에 따라 서울서베이(2005~
2010 년) 자료 12만개의 샘플과 서울시 집계구별 자료(2010 년)를 이용하여 분석하였다.
다음으로, 분석방법은 전술한 바와 같이 데이터마이닝 의 관점에서 접근하는데, 관련 선행연구 리뷰를 통해 빅 데이터 및 데이터마이닝에 관한 최근의 동향과 이용사례 를 조사하였다. 선행연구 분석결과, 특히 인구 및 주택분 야의 설문조사와 같은 사회과학 분야에서는 통계자료 특 성은 사례(sample)가 행으로 나열되는 레코드(record) 못 지않게 열로 나열되는 속성(attribute)의 필드(field)도 많기 때문에 이러한 자료특성에 부응할 수 있는 분석수법이 필 요함을 인식하게 되었다.
따라서 이러한 다(多)속성을 갖는 설문조사와 같은 범 주형 데이터에 내재되어 있는 흥미로운 규칙과 패턴을 찾 아내기 위해 본 연구에서는 실험적으로 2장에서 새로운 분석 및 응용기법을 제안하였다. 구체적으로는, 우선 전체 속성정보 필드(서울서베이의 가구 및 가구원)에서 본연구 의 관심주제인 ‘1인 가구’와 관련성이 높은 모든 이산형 (discrete) 변수들을 추출하여 테이블을 구성하고, 이렇게 구성된 모든 이산형 변수들 간의 열(column) 조합에 대 해 카이검정을 일정 수준의 유의수준(여기서는 5%)에서 실시하였다.
그런 다음, 설정된 유의수준에서 추출된 조합에 대하여 뒤에서 자세히 설명하는 AIC지표를 적용하여 적합도가 높은, 다시 말해 상관관계가 높은 조합의 순으로 정렬하 였다. 이렇게 정렬된 각 쌍의 조합에 대하여 일차적으로 단순대응분석을 실시하여 두 이산형 변수 간의 관계를 고 찰한 다음, 이차적으로 특히 흥미로운 관계에 있는 변수 들을 별도로 추출하여 다중대응분석(MCA)을 실시하였다.
이때 인구통계학적 변수를 동시에 모형에 투입하여 변수 들 간의 관계를 종합함으로써 두 변수간의 단편적 관계 를 보다 입체적으로 해석할 수 있다. <Figure 1>은 본 연 구의 흐름 및 분석방법을 제시한 것이다.
한편, 공간정보의 분석방법은 상기 속성정보의 분석방 법과는 달리 다음과 같이 진행하였다. 이번 공간분석에서 는 별도로 지리정보시스템(GIS)의 분석 툴을 사용하지 않 고, <Table 1>과 같은 집계구별 통계자료(txt파일)만을 사 용하였다. 집계구별 통계자료는 인구, 가구, 주택, 사업체 분야별로 각 하위폴더에 개별 파일이 모두 다음 표와 같 이 4개의 필드 형식으로 구성되어 있다.
서울시 전체 16,089개의 집계구를 대상으로 1인 가구 특성과 관련이 높을 것으로 판단한 필드를 추출하였더니 합계 131개의 필드를 이루었고, 여기에 424개 자치동, 25 개 자치구 필드를 추가하여 ‘분석테이블’을 작성하였다.
이렇게 분석테이블을 구성하면 공간위계별로, 즉 집계
2) 예컨대, 2012년 9월 LH공사는 ‘2010년 주거실태조사 DB’를 공개하고 제1회 대한민국 주거실태 대학(원)생 논문 공모전을 실시한 바 있다. 또한 2013년 서울연구원에서도 학술 연구 목적으로 데이터 를 개방하였다.
3) 이정진 (2011). R, SAS, MS- SQL을 활용한 데이터마이닝. 서울 : 자유아카데미, 3.
구 → 자치동 → 자치구별로 통계분석을 실행할 수 있을 뿐 만 아니라, 나아가서는 관심 영역별로 예컨대, 생활권별 등 관심 공간단위별로 응용하여 분석할 수 있다는 장점 이 있다. 이 연구에서는 424개 자치동을 기준 공간단위로 한 분석은 지나치게 세분화된다고 판단하여, 25개 자치구 로 기준 공간단위를 설정하여 분석하였다.
이렇게 만들어진 분석테이블을 이용하여 우선 자치구별 1 인 가구 비율을 계산하고, 이와 상관성이 높은 변수를 찾아내기 위해 상관분석(Pearson의 적률상관)을 실시하였 다. 주의할 점은, 앞의 속성정보와는 달리 공간정보의 분 석테이블은 <Table 1>에 있는 ‘필드4’의 통계 값이 연속 형(continues) 변수로 구성되어 있다는 점이다. 따라서 두
변수간의 관계는 상관분석을 통해 파악할 수 있는데, 본 연구에서는 일정 수준 이상의 상관계수값과 유의수준을 변수 조합의 추출 기준으로 설정하였다. 다시 말해, 자치 구별 1인 가구 점유비율은 일종의 고정 변수로 두고, 각 필드의 점유비율을 하나씩 끄집어내는 방식을 취하였다.
마지막으로, 위의 상관분석으로 추출한 1인 가구 점유 비율과 상관관계 높은 변수들을 기준으로 다차원척도법 (MDS) 및 군집분석을 통해 자치구를 군집별로 유형화하 여 특성을 고찰하였다.
II. 분석기법 및 선행연구 고찰
1. 빅데이터와 데이터마이닝 1) 빅데이터
빅데이터의 핵심은 아주 최근까지도 우리가 온전히 이 해하기 힘들었던 정보들 사이의 관계를 파악하고 이해하 는 것이다. 인류가 대규모의 데이터를 정확하게 처리하려 고 노력한 지는 꽤 오래되었다. 인류 역사의 대부분의 기 간 동안 적은 양의 데이터밖에 수집하지 못했던 이유는
Figure 1. Research Flow and Analytical Methods.Table 1. The Configuration of Statistical Data
No. Field name The contents of the field Field 1 base_year Base year: 2010
Field 2 tot_oa_cd Aggregates Code: 1101053010001 Field 3 item_identifier Statistical items: to_in_001 Field 4 item_value Statistical value: 519
데이터를 수집하고, 조직하며, 저장하고 분석할 툴이 빈약 했기 때문이다. 인류는 데이터를 거르고 걸러서 최소한의 양만 남겼는데, 그래야만 검토가 쉬웠기 때문이다. 말하자 면 무의식적인 자기검열인 셈이었다
4).
빅데이터라는 현상적 개념은 방대한 볼륨, 즉 방대한 데 이터를 지칭하는 의미로 활용되고 있으나, 단순히 방대한 데이터의 양보다는 그 속에 숨겨진 패턴과 가치를 발견 하기 위해 데이터를 분석하고 활용하는 기술이 요체임을 지적하였다
5).
한편, 국내에서도 기업뿐만 아니라 국가에서도 빅데이 터에 대해 관심을 쏟고 있다. 건축, 도시, 주거 분야는 특 성상 공간정보와 매우 밀접한데, 최근 국토교통부는 공간 정보를 통한 창조경제 실현과 세계 공간정보 종주국가로 의 도약을 목표로 ‘2013 스마트국토엑스포’ 행사를 개최 한 바 있다. 공간정보를 중심으로 다양한 속성정보가 연 결되는 것은, 단순히 속성정보가 추가되어 만들어 내는
‘ 덧셈의 효과’가 아니라 새로운 유형의 가치가 창출되고 배가되는 ‘곱셈의 효과’를 가져온다고 말할 수 있을 것이다.
2) 데이터마이닝
데이터마이닝은 전통적인 데이터 분석기법에 대량의 데 이터 처리기법 등을 가미하여 발전시킨 데이터 분석기법 을 의미한다. 데이터마이닝은 대량의 데이터에 숨겨져 있 는 유용한 정보를 추출하여 의사결정에 이용하기도 하고, 고객의 행동에 대한 예측을 하기도 하며, 이미 과거에 분 석했던 데이터를 다시 조명해보는 기회를 제공하기도 한 다
6).
널리 이용되는 데이터마이닝 분석기법으로는 속성정보 와 관련하여, 의사결정나무(Decision Tree), 유전자 알고리 즘(Genetic Algorithm), 인공신경망(Artificial Neural Network), 연관성 규칙 발견(Association Rule Discovery, Market Basket Analysis), 사례기반 추론(Case-Based Reasoning), 연결분석(Link Analysis) 등이 있다.
2. 제안 분석법: AIC지표에 의한 모형 선정 1) 설문조사 데이터의 특징
전술한 대량의 데이터는 관측 데이터의 수가 많다는 의 미와 더불어 데이터의 속성변수도 많다는 의미도 포함하 고 있다. 데이터의 속성은 변수(variable), 특징(feature), 또 는 항목(item)이라고도 한다. 변수는 일반적으로 이산형 변수와 연속형 변수로 구분되며, 전술한 바와 같이 사회 과학 분야에서는 설문조사가 매우 일반적인 연구방법인데, 설문조사의 항목은 대부분 범주형으로 구성되는 경우가 많아 이산형 변수의 특성을 갖고 있다.
한 개의 이산형 변수의 경우 그 분포 구조를 파악하기
위해서는 일반적으로 도수분포표를 자주 이용하며, 이에 비해 연속형인 경우는 데이터의 중심위치, 데이터의 산포, 데이터의 왜도 및 첨도 등의 척도를 이용한다. 두 개의 이산형 변수 상호간의 관계는 교차표(cross table) 또는 속 성표(contingency table)로 나타내는 경우가 일반적인데, 두 변수간의 연관된 특성을 연구하는데 매우 효과적이다. 교 차표는 두 변수의 가능한 값을 행과 열로 나누어 행 변 수의 속성(수준, level)과 열변수의 속성이 교차하는 부분 에 칸(cell)을 만든 후 데이터의 빈도수를 집계한 것이다.
그런데 위의 2차원 교차표에서 두 변수간의 관계가 독 립적인지 상호 특정 관계가 있는지 여부는 독립성 검정 으로 실시하며 대표적인 것이 ‘카이제곱 독립성 검정’이 다. 카이제곱 통계량은 각 셀에서의 관찰도수와 기대도수 의 차이에 대한 제곱을 기대도수로 나눈 후 모두 합친 것 이다.
2) AIC 지표에 의한 최적 모형 선택
설문조사 통계자료가 데이터마이닝 분석 자료로 주어지 는 경우, 대부분 애초부터 연구자의 의도 하에 설계된 설 문지가 아니기 때문에 분석자는 관심 있는 항목을 중심 으로 분석가능한 모든 변수들의 조합을 만들어 그 관계 를 알아보려고 할 것이다. 그런데 만약 도입하는 변수가 많아지면 그만큼 조합 가능한 교차표의 경우의 수가 방 대하게 늘어나게 된다. 이와 같이 방대한 변수간의 조합 에서 흥미로운 변수 조합간의 관계를 추출하기 위해서는 탐색적 분석기법이 필요하다. 즉, 사전 지식을 가정하지 않고 데이터로부터 정보를 획득하는 탐색적 데이터분석 기법을 활용할 필요가 있다.
이를 위해 본 연구에서는 우선 카이제곱 독립성 검증 으로 일정 수준의 유의한 변수 조합을 추출, 여기에 AIC (Akaike Information Criteria) 지표에 의한 모형의 적합도 를 실시하여 변수 조합의 우선순위를 정하는 방법을 채 택하였다. 이와 같이 본 연구에서 카이제곱 독립성 검정 과 더불어 AIC지표를 병행하는 것에 대한 이유를 설명하 면 다음과 같다.
이산형 변수에서 관계성을 나타내는 척도로는 Goodman
& Kruskal’s lambda, Cramer’s V, Cohen’s kappa, Pearson’s Phi coefficient 등 많은 지표들이 제안되어 있다. 그러나 사회과학 분야에서 설문조사를 이용한 선행연구를 보면 대부분 카이제곱 통계량을 이용한다. 그런데 카이제곱 적 합도 검정은 설문항목간의 관련성에 대해 파악할 수는 있 지만 고려해야 할 설문항목의 수가 늘어나면 조합되는 쌍 의 수가 매우 방대해진다. 생각할 수 있는 모든 조합에 대해 교차표를 작성하여 가장 관련성이 높은 것을 순차 적으로 고려하면 되겠으나 사정이 여의치 않을 경우에는 가장 좋은 교차표만을 추출하여 검토하는 것이 유익하다.
이를 위해 복수의 교차표 사이에 있어 상대적으로 ‘좋음’
을 나타내는 지표가 필요한데, 자유도(degree of freedom) 가 다르기 때문에 카이제곱 통계량을 그대로 사용할 수 는 없다.
4) 이지연 (2013). 빅 데이터가 만드는 세상. 서울: 21세기북스, 42.
5) Lee, S. (2013). Create space for the realization of land building big data system. 2013 Smart Land Expo Seminar presentation, 1-18.
6) 이정진 (2011). R, SAS, MS- SQL을 활용한 데이터마이닝. 서울 : 자유아카데미, 4.
따라서 이러한 카이제곱 통계량을 보완하기 위한 대안 으로 본 연구에서는 AIC정보통계량을 이용하여 복수의 통계모형 간의 상대적인 적합도를 비교할 수 있다. 구체 적인 알고리즘을 <Table 2>에 나타내었다. 먼저, <Table 2> 에서 (1) 교차표를 다항분포로 생성되는 통계모형으로 간주하면 교차표의 하나하나에 대응하는 AIC값을 계산할 수 있다. 다음으로, (2)의 다항분포에 의한 실제 AIC1의 값과, (3)의 두 변수가 독립일 경우의 AIC0의 값을 각각 구하고, (4)에서 두 모형의 차이로 AIC1(실제)의 값에서 AIC0( 독립) 값의 차이를 구하는데, 만약 음의 값을 갖는 다면 이때의 AIC1(실제)은 비독립적이라고 말할 수 있다 ( 坂元慶行 외, 1983).
AIC 수치가 작으면 작을수록 모형이 좋다고 말할 수 있으므로, AIC가 보다 작은 쪽의 교차표를 선택하면 된 다. 이와 같이 n개의 교차표가 있다고 할 때, 표의 (4)에 서 두 모형의 차이로 구한 값에서 음수의 절댓값 순서로 조합들을 정렬하면 모형의 상대적 적합도롤 산출할 수 있 다. AIC지표의 대부분은 카이제곱 통계량으로 근사되는데, AIC 는 카이제곱 통계량을 자유도로 조정한 것으로 생각 할 수 있다. 이와 같이 조정하였기 때문에 교차표 상호 간의 모형 적합도를 비교할 수 있는 것이다. 또한 귀무가 설(두 개의 설문항목이 독립)이 성립하는 경우에는 (4)의 모형차이 AIC값은 0이므로 독립성 검증이 가능하다.
3) 대응분석에 의한 변수간의 관계 고찰
위와 같은 방식으로 유의한 변수 조합의 모형을 추출 하고 이를 적합도에 따라 정렬할 수 있으나, 만약 대상으 로 하는 이산형 변수의 수가 너무 많을 경우에는 몇 가 지 대표적 변수를 중심으로 정보를 요약할 필요가 발생
하게 된다. 즉, 데이터 차원의 축소(Dimension reduction) 과정을 통해 정보를 요약할 필요가 있다. 연속형 변수에 서 주성분분석(Principal analysis)을 이용하여 변수의 수 를 축소하는 방법과 유사하게 이산형 변수에서는 대응분 석(Correspondence analysis)을 이용하면 이 같은 일을 처 리할 수 있다.
일반적으로 대응분석은 교차표로 나타낸 범주형 자료의 행과 열의 범주를 저차원(일반적으로 2차원 평면)의 좌표 로 표현하여 그 관계를 알아보는 탐색적 다변량분석 기 법에 해당한다. 대응분석의 구체적인 알고리즘은 <Table 3> 과 같으며, 본 연구에서의 대응분석은 R통계의 ca패키 지
7)를 이용하였다. ca패키지는 이산형 변수 두 개의 조합 에 대한 단순대응분석뿐만 아니라 변수가 3개 이상인 다 중대응분석도 가능하며, 게다가 차원 축소에 따른 축 (Coordination) 별 고윳값 스크리 도표(Scree plot) 지표를 제공하여 차원 축소에 따른 정보 압축의 정도를 파악할 수 있다.
3. 1인 가구의 특성에 관한 선행연구 고찰
1 인 가구에 관한 선행연구는 많이 축적되고 있으나, 이 연구에서는 본 연구의 특성상 속성정보와 공간정보라는 크게 두 가지 측면에서 고찰하여 보았다.
먼저, 속성정보는 1인 가구의 인구통계학적 특성과 실 태에 관한 사항을 주로 다룬 연구와, 이들의 주거지 선택 의 요인에 관한 것으로 대별할 수 있다. 1인 가구가 급 증하는 주요 원인은 결혼의 지연, 이혼, 사별 등이며, 이 들의 주거실태를 파악하고 주택수요를 반영한 주택정책 마련이 시급하다고 하였다
8). 다음으로 1인 가구의 거주지
Table 2. Statistical Model Comparison Algorithm by AIC IndexTable 3. Corresponding Analysis Algorithm
7) Nenadi, O. & M. Greenacre (2007). Correspondence Analysis in R, with Two- and Three-dimensional Graphics: The ca Package.
Journal of Statistical Software, 20(3), 1-13.
선택에 영향을 미치는 요인으로는 통근거리, 지역 편의시 설, 대중교통 접근성이 지대하다고 역설하면서, 직장인의 직주거리와 접근성을 고려한 1인 가구 주택공급 정책이 필요하다고 하였다
9). 같은 맥락에서 1인 가구의 주택수요 에 착안한 연구에서도 자산, 지역, 연령이 1인 가구의 주 거지 선택에 있어 중요한 요인으로 작용한다고 하면서, 연령에 따라 선호 주택유형이 바뀌기 때문에 이 점을 고 려한 사회 안전망구축을 위한 기본 작업으로서 1인 가구 의 주거안정이 중요하다고 역설하였다
10).
다음으로, 공간정보는 1인 가구의 공간적 분포와 특성 에 관한 것이다. 인구, 사회, 주거 측면에서 1인 가구 밀 집지역의 특성을 군집분석으로 4개의 형태로 구분하여 대 학가형에서는 ‘산업예비군’들이, 역세권형에서는 ‘골드세 대’들이, 고시촌형에서는 ‘불안한 독신자’들이, 다세대다가 구형에서는 ‘실버세대’들이 주로 거주하는데, 이들 다양한 1 인 가구 그룹의 특색을 반영한 차별화 정책이 필요하다 고 주장하였다
11). 다음으로 1인 가구를 연령, 소득 등에 따라 밀집지역을 군집분석을 통해 변미리 외(2008)와 유 사하게 도심지형, 대학가/원룸촌형, 고시촌형으로 유형화 하고 지역특성을 분석하였다. 연령과 소득에 있어 일정한 관계가 있는 만큼 1인 가구의 주거비 부담가능성, 생활 편리성, 교통 접근성 등 1인 가구의 라이프 스타일에 따 른 주거지 선택 전략이 필요하다고 하였다
12). 1~2 인 가구 의 연구에서는 서울시 1~2인 가구의 인구통계학적 특성 에 따른 공간적 거주실태를 분석하고 유형화하여, 거주지 특성에 따른 소형 임대주택 공급의 필요성을 제시하였다
13). 같은 맥락에서 이들 1~2인 소형가구 수요가 많은 도시형 생활주택 공급 현황과 실태를 통해 여러 정책적 개선방 향을 제시하였다
14). 또한 1인 가구의 공간분포를 검토한 결과 장년층을 제외한 모든 연령에서 연령과 성별에 따 라 공간적 분포에 있어 차이가 나타난다고 하였다
15).
이 같이 1~2인 가구가 증가함에 따라 관련 다양한 연 구 또한 축적되고 있음을 알 수 있다. 선행연구에서는 속 성정보나 공간정보 중의 어느 한쪽에 집중하거나 또는 이 를 통합하여 1인 가구의 공간적 분포와 이들의 인구통계 학적 특성 및 주거실태 고찰, 이를 통한 정책적 시사점과 연계시키려는 연구가 많이 시도되는 것으로 파악된다. 그 런데 선행연구에서는 본 연구와 같이 데이터마이닝의 수 법에서 접근하여 1인 가구의 다양한 특성을 추출하여 파 악, 종합하려는 시도는 찾기 힘들다. 나아가 본 연구는 새 로운 분석기법까지 제안, 그 유효성을 검증하려 한다는 점에서 선행연구와 차별성을 갖는다고 할 수 있을 것이다.
III. 속성정보로부터 1인 가구의 특성추출
1. 서울서베이 설문조사와 1인 가구 1) 1 인 가구의 일반적 특성
서울서베이 조사는 서울시의 도시정책 지표를 마련하기 위해 2010년도의 경우 12개 분야, 42개 영역, 198개 지 표에 대해 자료조사를 실시하였다. 가구(household)의 표 본크기는 20,000가구이며, 15세 이상 가구원 47,010명의 설문자료가 수록되어 있다. 본 연구에서는 2005년도부터 2010 년도까지의 서울서베이 자료로 분석하였다. 총 120,000 가구 중 1인 가구가 13,452명(11.2%), 2인 가구 26,121명 (21.8%), 3 인 가구 30,107명(25.1%), 4인 가구 41,317명 (34.4%) 등으로 구성되는데, 이 연구에서는 이중 1인 가 구로 13,452명을 대상으로 분석하였다. 서울서베이에서 1 인 가구의 인구통계학적 특성을 정리하면 <Table 4>와 같 다. 여성 62.1%, 60대 이상 32%, 중졸 이하 43.5%, 월 소득 100~200만원, 미혼 35.1%가 각 변수 수준에서 가 장 높은 비율을 점하고 있다.
한편, 거주상황을 보면 단독주택(48.2%)과 전세(44.4%) 입주형태가 각각 가장 많고, 아파트(18.9%)와 자가(23.6%) 또는 보증부월세(21.1%)의 형태로 각각 거주하는 경우가 다음으로 높다.
서울서베이 2010년의 경우[단독주택+전세]로 거주하는 경우는 618가구로 전체의 약 30%를 차지하며, 연령별로 보면 20대(14.1%), 30대(25.1%), 40대(17.2%), 50대 (13.8%), 60 대 이상(29.9%)으로 나타나 고령층이 높은 비 율을 차지하는 것을 알 수 있다. 반면, [아파트+전세]로 거주하는 경우는 245가구이고, 20대(11.8%), 30대(31.0%), 40 대(22.0%), 50대(14.7%), 60대 이상(20.4%)으로 30~40 대의 비율이 높음을 알 수 있다. 반면, [단독주택 + 자가 ] 의 경우는 203가구로, 연령에서 20대(3.4%), 30대(4.9%), 40 대(7.9%), 50대(17.2%), 60대 이상(66.5%)으로 대부분 고령임을 알 수 있다.
15) Lee, C., & Lee, S. (2010). Analysis of Single Household Areas and Evaluation of Their Residential Environment in Seoul. Journal of the Seoul Institute, 11(2), 76-78.
8) Kim, O., & Moon, Y. (2009). Housing analysis of one person household. Journal of the Residential Environment Institute of Korea, 7(2), 43-44, 50-52.
9) Shin E., & Ahn, K. (2010). The Factors affecting on the Residential Location Choice of Single Person Households across Income levels: Focused on working people in Seoul. Journal of the Korean Planners Association, 45(4), 75-77.
10) Kim, J., & Cho, J. (2010). A Study on Characteristics of Housing Demand of Single-Person Households and Policy Proposals: The Case of Residents in Seoul. Working Paper Series 2010, Vol 2, 14-17.
11) 변미리·신상영·조권중·박민진 (2008). 서울의 1인 가구 증 가와 도시정책 수요연구. 정책과제연구보고서, 230, 11-14.
12) Shin, S. (2010). A Study on the Spatial Distribution of One Person Households: The Case of Seoul. Journal of the Korean Planners Association, 45(2), 88-89.
13) Lee, J., & Yang, J. (2012). Housing Policy Directions for Single- and Two-person Households in Seoul. Seoul. The Seoul Institute, 4-6.
14) Lee, J., & Lee, D. (2013). A Research on Current State of and Policy Suggestions for Urbanistic Housing in Seoul. Seoul. The Seoul Institute, 2-5.
한편, 위의 [단독주택+자가]의 60대 이상의 고령자 135 명의 혼인상태를 살펴보면 흥미로운데, 기혼(0.7%), 미혼 (55.6%), 이혼·별거(17.8%), 사별(25.9%)로 나타났다. 따 라서 자가의 단독주택에 거주하는 독거노인의 절반 이상 이 미혼자이다.
2) 1 인 가구의 만족도와 이사계획
먼저, 1인 가구의 생활환경에 대한 만족도를 5점 척도 로 알아보면, 주거환경에 대해 평균 3.3점, 경제환경 2.9 점, 사회환경 3.0점, 교육환경 3.0점으로 나타나, 전체 평 균만족도는 3.1점으로 ‘보통’의 만족도 수준으로 평가되었 다. 이들 만족도 평가항목의 평균값에 대해 성별 T검증을 실시한 결과, 5% 유의수준에서 차이는 없는 것으로 나타 났다.
다음으로, 1인 가구의 만족도와 5년 이내 이사계획 여
부와의 관계에 대해 T검증을 실시하였다. 일반적으로 주 거에 대한 불만이 높아질수록 주거조절행위에 대한 욕구 가 높아지는데, 따라서 주거조절행위의 수단으로써 만족 도와 이사계획과의 관계를 알아보는 것은 유의미하다.
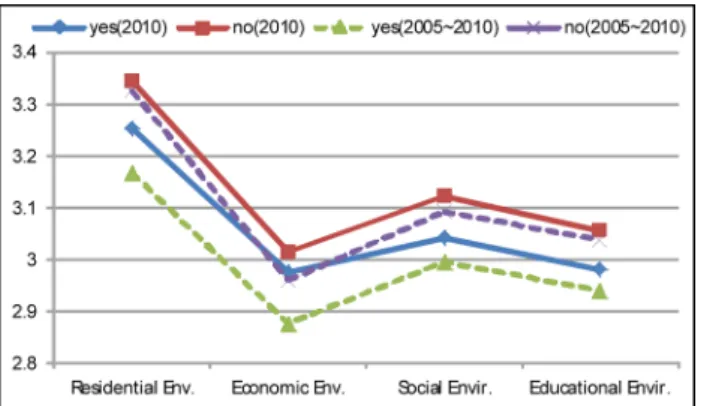
<Figure 2(a)> 는 이 둘의 관계를 나타낸 것인데, 2005년
~2010 년 자료의 만족도와 이사계획을 비교해본 결과 인 구통계학적 특성이 다른 샘플임에도 불구 거의 비슷하게 나타났다. 즉, 1인 가구 중에서 5년 이내 이사계획이 있 는 그룹이 이사계획 없는 그룹에 비해 만족도 평가 4항 목 모두에 걸쳐 낮은 것으로 나타났다. 다시 말해, 이사 계획이 있는 그룹은 그렇지 않은 그룹에 비해 불만도가 높은 것으로 나타나, 만족도와 이사계획 사이에는 일정한 관계가 성립함을 엿볼 수 있다. 특히, ‘주거환경’의 평가 항목에서 이사계획 여부와 만족도에는 유의수준 5% 이내
Table 4. Demographic Characteristics of Single-person Households by Seoul-Survey 2005~2010Division
2005 2006 2007 2008 2009 2010 Total
FrequencyRatio
(%) FrequencyRatio
(%) FrequencyRatio
(%) FrequencyRatio
(%) FrequencyRatio
(%) FrequencyRatio
(%) FrequencyRatio (%)
Gender Man 662 37.1 866 35.9 807 35.8 946 40.6 965 38.1 856 40.1 5102 37.9
Woman 1123 62.9 1549 64.1 1448 64.2 1385 59.4 1568 61.9 1277 59.9 8350 62.1
Age
Twenties 433 24.3 598 24.8 517 22.9 461 19.8 586 23.1 351 16.5 2946 21.9
Thirties 388 21.7 508 21 438 19.4 488 20.9 461 18.2 477 22.4 2760 20.5
Forties 234 13.1 300 12.4 322 14.3 320 13.7 333 13.1 317 14.9 1826 13.6
Fifties 191 10.7 244 10.1 250 11.1 297 12.7 350 13.8 280 13.1 1612 12.0
Sixties≥ 538 30.1 765 31.7 728 32.3 765 32.8 803 31.7 708 33.2 4307 32.0
Education Level
Middle school≤ 574 32.2 806 33.4 731 32.4 1474 63.3 1568 62.1 634 29.8 5787 43.5
High school≤ 524 29.4 699 28.9 634 28.1 358 15.4 384 15.2 699 32.8 3298 24.8
University≤ 504 28.2 829 34.3 812 36 454 19.5 542 21.5 766 36 3907 29.4
Graduate school≥ 47 2.6 79 3.3 70 3.1 42 1.8 31 1.2 29 1.4 298 2.2
Housing Type
Detached house 457 25.6 1539 63.7 1375 61 490 21 1434 56.6 1153 54 6448 48.2
Apartment 432 24.2 481 19.9 403 17.9 149 6.4 585 23.1 478 22 2528 18.9
Multiplex housing 617 34.6 80 3.3 78 3.5 366 15.7 428 16.9 335 16 1904 14.2
Duplex housing 279 15.6 315 13 368 16.3 1287 55.2 86 3.4 167 7.8 2502 18.7
Occupancy Type
Ownership 432 24.2 562 23.3 556 24.7 541 23.2 636 25.1 445 21 3172 23.6
Jeonse 754 42.2 909 37.6 952 42.2 1015 43.5 1197 47.3 1139 53 5966 44.4
Monthly Rent
with Deposit 494 27.7 785 32.5 338 15 369 15.8 451 17.8 395 19 2832 21.1
Monthly Rent 80 4.5 120 5 367 16.3 372 16 232 9.2 129 6 1300 9.7
Others 25 1.4 39 1.6 42 1.9 34 1.5 17 0.7 25 1.2 182 1.4
Income
100≤ 592 33.2 891 36.9 622 27.6 630 27.9 565 22.7 415 20 3715 28.4
100-200 680 38.1 866 35.9 784 34.8 794 35.2 942 37.9 729 35 4795 36.6
200-300 320 17.9 424 17.6 473 21 567 25.1 678 27.3 600 28 3062 23.4
300-400 105 5.9 129 5.3 158 7 204 9 204 8.2 271 13 1071 8.2
400-500 23 1.3 25 1 38 1.7 33 1.5 58 2.3 53 2.5 230 1.8
500≥ 19 1.1 31 1.3 58 2.6 30 1.3 37 1.5 48 2.3 223 1.7
Marriage Status
Married 457 26.9 1164 48 556 24.7 541 23.2 636 25.1 16 0.8 3370 25.4
Single 434 25.6 49 2 952 42.2 1015 43.5 1197 47.3 1012 47 4659 35.1
Divorced/
Separated 185 10.9 769 31.7 338 15 369 15.8 451 17.8 391 18 2503 18.8
Bereaved 621 36.6 443 18.3 367 16.3 372 16 232 9.2 714 34 2749 20.7
Note. ≥ refers to ‘above’, ≤ refers to ‘below’
에서 유일하게 유의한 상관관계가 성립하는 것으로 나타 났다. 사회환경과 교육환경에서도 차이는 있으나 5% 유 의수준에서는 유의하지 않은 것으로 나타났다<Figure 2(b)>.
3) 거주지 선택 시 고려사항
거주지 선택 시 고려사항 1순위에 대해 1인 가구와 2 인 가구 및 3~4인 가족가구와를 비교한 것이 <Figure 3>
이다. 1인 가구는 ‘경제적 여건(47%)’과 ‘주변여건(30%)’
을 중시하는데, 이는 교육환경을 상대적으로 중시하는 3~4 인 가구와 대비된다. 2인 가구는 1인 가구와 유사한 특 성을 보이나, 경제적 여건과 주변여건을 제외한 나머지 모든 부분에서 1인 가구에 비해 상대적으로 높은 것을 알 수 있다.
2. AIC지표에 의한 모형 선택과 적용
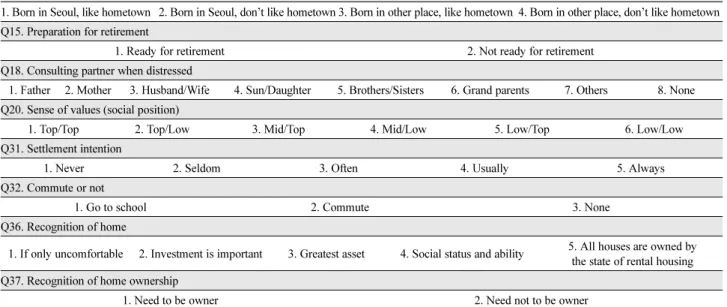
1) 관심 이산형 변수의 추출 및 카이제곱 검정 본 연구의 속성정보 분석자료인 서울서베이2010 설문조 사에서 1인 가구 특성과 관련이 클 것으로 판단한 8개의 이산형 변수를 추출하였다. 인구통계학적 변수를 제외한 이들 총 8개의 관심 변수를 제안수법의 유효성 검증 실 험에 투입하기로 하였는데, 우선 각 이산형 변수의 분포 를 나타낸 것이 <Table 5>이다.
8 개 이산형 변수에 대한 각 변수들 간의 조합의 수는 이므로 총 28가지의 조합수가 나온다. 이들 28가지 모든
조합에 대하여 유의수준 5% 이내에서 카이제곱 검정을 실시한 결과, 전체의 93%인 26개의 조합이 유의한 것으 로 나타났다. 다시 말해, 가능한 모든 조합의 수에서 오 직 2개의 조합만을 제외한 모든 경우의 조합이 유의한 것 으로 나타났다.
<Table 6> 는 이들 26개의 유의 변수 조합의 카이제곱 검정 통계량을 나타낸 것이다. 표에서 알 수 있는 바와 같이 [q18×q32], 즉 ‘고민 의논 상대×통근 통학 여부’의 조합에서 가장 높은 카이제곱값인 571.9를 보였고, [q31×
q32] 의 조합(정주 의향×통근 통학 여부)에서는 16.2로 가 장 낮은 카이제곱값을 보였으나, 이때 주의할 점은 여전 히 유의수준 3.9%로 5% 이내에 있다는 것이다.
2) AIC 지표에 의한 모형 선택과 적합도 순위
앞의 2.2절에서 이산형 변수간의 카이제곱 검정에 대한 모형 선택의 한계를 극복하기 위해 AIC지표를 제안하였 다. 이에 따라 <Table 6>과 같이 일정 유의수준에서 카 이제곱 독립성 검정을 통과하여 추출한 변수 조합에 대 하여 AIC지표를 적용하여 모형도의 적합도 순서로 정리 하여 나타낸 것이 <Table 7>이다. <Table 7>의 핵심은, 두 이산형 변수의 조합에 있어 교차표가 독립일 때의 AIC ( ①)와 실제값 AIC(②)를 각각 구한 다음 그 차이를 구하 여 차이(절댓값)가 큰 순서대로 정렬한 것이다.
Figure 2. Relation between Satisfaction and Mobility Plan of Single-household
a) Relation between Satisfaction and Mobility Plan
Satisfaction Evaluation (2010) Residential
Env.
Economic Env.
Social Envir.
Educational Envir.
Plan to move out
Yes 3.253 2.974 3.043 2.981
No 3.344 3.013 3.123 3.056
t-statistic -2.177 -0.853 -1.87 -1.807
df 928.415 889.454 939.02 890.43
p-value 0.03 0.394 0.062 0.071
b) Satisfaction of the t-value and p-value in year 2010
Figure 3. Comparison of the Important Consideration Features when Selecting a Residential Area by Household Type
<Table 6> 과 <Table 7>을 비교하면, 우선 적합도 순위 가 다소 바뀌어 있음을 알 수 있다. 예컨대, C4와 C3 및 C11 과 C10 등에서 순서가 뒤바뀌어 있다. 무엇보다도 C26 (q31 ×q32)에서 카이제곱 독립성 검정에서는 카이제곱값이
16.2 로 3.9%의 유의수준으로 5% 범위에서 유의하다고 추 출하였던 것이 AIC지표에 의해서는 독립성 차이검증(AIC 차이: ①-②)에서 유의하지 않은 것으로 나타나 검토대상 에서 제외한다는 것이다.
Table 5. Table of Discrete Variables and Levels Q2. Awareness of hometown
1. Born in Seoul, like hometown 2. Born in Seoul, don’t like hometown 3. Born in other place, like hometown 4. Born in other place, don’t like hometown Q15. Preparation for retirement
1. Ready for retirement 2. Not ready for retirement
Q18. Consulting partner when distressed
1. Father 2. Mother 3. Husband/Wife 4. Sun/Daughter 5. Brothers/Sisters 6. Grand parents 7. Others 8. None Q20. Sense of values (social position)
1. Top/Top 2. Top/Low 3. Mid/Top 4. Mid/Low 5. Low/Top 6. Low/Low
Q31. Settlement intention
1. Never 2. Seldom 3. Often 4. Usually 5. Always
Q32. Commute or not
1. Go to school 2. Commute 3. None
Q36. Recognition of home
1. If only uncomfortable 2. Investment is important 3. Greatest asset 4. Social status and ability 5. All houses are owned by the state of rental housing Q37. Recognition of home ownership
1. Need to be owner 2. Need not to be owner
Table 6. Chi-square Statistics of Eight Variables
ID Combination of
variables Chi-square value Significance level C1 q18×q32 571.8508 5.17056063396605e-113 C2 q36×q37 271.4976 1.51694898801563e-57 C3 q20×q32 240.7166 4.84509885803233e-46 C4 q15×q20 211.5883 9.40531775697842e-44 C5 q18×q20 208.9554 1.20475313049851e-26 C6 q15×q32 106.1459 8.92707663915856e-24 C7 q2×q32 74.7781 4.26394205560703e-14 C8 q20×q36 105.2465 1.43338284522869e-13 C9 q18×q37 72.4205 4.78363287113957e-13 C10 q32×q37 56.662 4.96590925118309e-13 C11 q2×q31 84.603 5.42552815519036e-13 C12 q15×q37 47.2688 6.18890303340976e-12 C13 q31×q36 83.6913 3.5723548974766e-11 C14 q15×q36 45.3908 3.2974906025061e-09 C15 q2×q18 71.3091 2.16412419097417e-07 C16 q18×q36 82.451 2.86405986015825e-07 C17 q31×q37 34.9577 4.73924755941177e-07 C18 q20×q37 34.385 1.99565780588922e-06 C19 q2×q15 27.9098 3.79394010945042e-06 C20 q2×q20 52.6378 4.42894353528747e-06 C21 q15×q18 32.3771 3.45719284835786e-05 C22 q20×q31 51.6657 0.000127358941261522 C23 q32×q36 26.9542 0.000719989838274546 C24 q2×q36 28.6863 0.00438494990375114 C25 q15×q31 14.3875 0.00615559049342492 C26 q31×q32 16.2081 0.0394970947081859
Table 7. Comparison Statistics by AIC Index
ID Combination of variables
AIC.I ① Independent
AIC.D ② Dependent
AIC Difference (①-②) C1 q18×q32 9012.6057 8452.0036 -560.6021 C2 q36×q37 8672.7697 8393.3941 -279.3756 C4 q15×q20 8380.6232 8169.3686 -211.2546 C3 q20×q32 8561.1621 8362.289 -198.8731 C5 q18×q20 11287.0103 11176.7554 -110.2549 C6 q15×q32 6096.5958 5987.3147 -109.2812 C7 q2×q32 8011.2128 7945.0151 -66.1977 C8 q20×q36 11131.1623 11065.9296 -65.2327 C9 q18×q37 8827.1921 8767.2204 -59.9718 C11 q2×q31 9944.1281 9886.9033 -57.2248 C10 q32×q37 6090.5262 6037.5363 -52.9898 C13 q31×q36 10781.4678 10733.0813 -48.3866 C12 q15×q37 5911.9072 5865.8529 -46.0542 C14 q15×q36 8682.0717 8644.4284 -37.6433 C15 q2×q18 10746.4124 10716.0065 -30.4059 C16 q18×q36 11585.3367 11555.4878 -29.8489 C17 q31×q37 8025.0301 7997.854 -27.176 C18 q20×q37 8374.615 8349.5347 -25.0802 C20 q2×q20 10282.8739 10260.7945 -22.0794 C19 q2×q15 7832.5281 7810.5034 -22.0247 C21 q15×q18 8832.1322 8813.4209 -18.7113 C23 q32×q36 8861.8845 8849.5777 -12.3068 C22 q20×q31 10483.8732 10473.8506 -10.0226 C25 q15×q31 8029.6282 8023.203 -6.4252 C24 q2×q36 10597.7899 10593.4917 -4.2983 C26 q31×q32 8211.6201 8212.009 0.3889
3) AIC 지표에 의한 적합도 우선 변수 조합의 해석 위의 AIC지표에 의해 추출된 모형의 적합도에 있어서 여전히 많은 변수의 조합이 있기 때문에, 전술한 바와 같 이 데이터를 축소하여 정보를 요약할 필요가 있다. 이에 따라 우선 모든 변수 조합에 대해 두 변수간의 관계를 파 악하기 위해 단순대응분석을 실시하였다. <Figure 4>은
<Table 7> 에서 가장 높은 모형의 적합도를 나타낸 조합 에 대해 단순대응분석의 결과를 나타낸 것이다.
이와 같이 단순대응분석으로 각 변수 조합의 대응관계
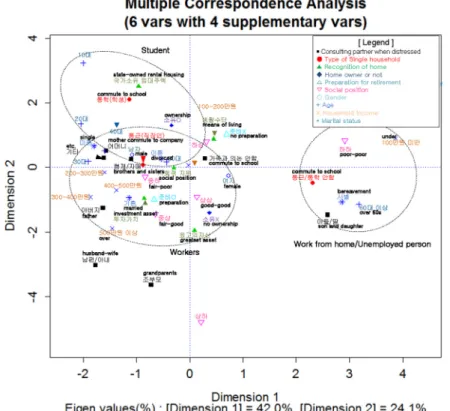
를 출력해 보면 두 변수간의 관계를 손쉽게 파악할 수 있 다. 그러나 본 연구에서와 같이 조합의 수가 방대해지면 개별 조합의 대응관계 만으로는 전체적인 대응관계를 파 악하기 힘들다는 한계가 발생한다. 이를 위해 3개 이상의 이산형 변수를 동시에 대응시켜 분석할 수 있는 다중대 응분석(MCA)을 활용한다.
이 연구에서는 이를 보이기 위해 <Table 7>의 적합도 상위 6개의 변수(q18, q32, q36, q37, q15, q20)와 4개의 인구통계학적 변수(성별, 연령, 학력)를 동시에 투입한 다 중대응분석을 실시하였다. <Figure 5>은 이렇게 하여 생 성된 다중대응분석 결과를 나타낸 것이다. 그림에서 통학 ( 학생), 통근(직장인), 통학이나 통근을 하지 않음(재택/실 업자)의 3 그룹으로 정리하여 보았는데, 그 특징이 인구 통계학적 속성과 잘 대응되어 나타나 있다고 본다. 먼저, 통학하는 10~20대의 학생은 집에 대한 인식에서 모든 집 은 국가소유의 임대주택으로 전환해야 한다는 생각에 많 이 동조하는 편이다. 통근 직장인은 미혼의 30대 또는 이 혼의 50대가 많고, 고민 의논 상대로는 형제/자매나 또는 아예 가족과 의논하지 않는 경향이 짙으며, 노후는 준비 하는 성향이고, 집은 투자가치로 사회적 지위와 최고의 자 산으로 여기는 경향이 큰 것으로 해석할 수 있다. 반면, 통 근이나 통학을 하지 않는 재택 또는 실업자 등으로 추정 되는 사람들은 사별 60대 이상의 100만원 미만 저소득층 이 많고, 이들의 고민 의논상대는 아들과 딸이며, 스스로 인식하는 자신의 정치/경제/사회적인 위상도 가장 낮은 수 준이라고 할 수 있는 ‘하하(최하층)’의 계층에 속하는 것 으로 인식하는 경향을 보인다.
Figure 4. Result of Simple Correspondence Analysis
Figure 5. Plot of Relation among Discrete Variables and Demographic Variables by MCA
IV. 공간정보로부터의 1인 가구의 특성추출
1. 서울시 자치구별 1인 가구 특성
1) 서울시 자치구별 1인 가구 점유비율 추출
1.2 절의 공간정보 원시 데이터로부터 집계구별 분석테 이블 작성방법에 대해서는 자세히 설명하였다. 분석 자료 로부터 1인 가구와 관련된 속성정보는 3개 부문 총 9개 변수 집합으로 구성하였다. <Figure 6>은 각 자치구별 세 대구성에서 1인 가구의 점유비율을 나타낸 것인데, 1인 가구의 점유비율이 가장 높은 곳은 관악구(39.2%)이며, 종 로구(31.7%), 중구(30.8%)의 순이며 반대로 낮은 곳은 양 천구(16.3%), 노원구(17.3%), 도봉구(17.8%)의 순으로 나 타났다.
2) 1 인 가구 점유비율과 속성변수와의 상관관계 서울시 자치구별 1인 가구 점유비율과 집계된 연속형 변수와의 상관관계를 알아보기 위해 모든 조합에 대해 상 관분석을 실시하였다. 우선 모든 항목에 대해 상관분석을 실시해본 결과, 상당히 많은 변수에서 1인 가구 점유비율 과 상관관계가 높은 것으로 나타났는데, 이 중에서도 유 의수준 p=0.05, 즉 5%이하이면서 상관계수 절댓값 또한 0.5 이상의 항목만을 추출하여 보았다.
먼저, 인구부문에서 1인 가구 점유비율과 높은 정(+)의 상관관계를 가지는 항목과 이때의 상관계수값은 <20~24 세: 0.69>, <25~29세: 0.83>, <30~34세: 0.54>로 ‘5세 단 위’로 구분된 전체 18개 연령 계급에서 3개의 항목만이 추출되었다(괄호에서 숫자는 상관계수값임, 이하 동일). 반 대로, 부(-)의 상관관계를 가지는 경우는 <5~9세: -0.85>,
<10~14 세: -0.77>, <15~19세: -0.56>, <40~44세: -0.69>,
<45~49 세: -0.63>, <50~54세: -0.71>로 총 6개가 추출되 었다. 1인 가구는 젊은 층이 많기 때문에 20~34세 미만 의 연령과 상관관계가 높은 반면, 5세~19세의 유아기나 중고등학교의 학령기에 있는 연령은 가족과 함께 거주하 므로 1인 가구의 비율이 낮고, 게다가 40~54세의 중장년 층의 경우에도 통상 가족세대를 구성하여 살기 때문에 1 인 가구의 점유비율이 낮아 부의 관계를 나타내는 것으 로 풀이된다.
다음으로, 학력과의 관계에서도 마찬가지 방법으로 분 석하였는데, 흥미롭게도 유의한 조합은 하나도 추출되지 않았다.
한편, 방/거실/식당 수에 있어서는 방의 개수(5구분: 1~5 개 이상), 거실(3구분: 거실 없음, 1개, 거실2개 이상), 식 당(3구분: 식당 없음, 식당1개, 식당2개 이상) 등 총 11개 의 분류 중에서 유의한 수준에서 추출된 것은 다음의 4 개였다. 정(+)의 관계로는 <방1개: 0.96>, <거실 없음:
0.89> 이며 반대로 부(-)의 관계는 <거실1개: -0.90>, <방3 개: -0.73>로 나타났다. 여기서 ‘방1개 및 거실 없음’의 경우는 1인 가구가 주로 원룸형 가구에 거주하는 형태를 고려하면 정의 관계가 충분히 이해되고, 반대로 ‘거실1개 나 방3개’의 경우에는 예컨대, 3LDK 아파트 등 가족세 대의 주택을 생각하면 부의 관계 또한 잘 이해된다.
점유형태에서는 “자가, 전세, 보증금 있는 월세, 사글세, 무상, 보증금 없는 월세”의 구분에서, 우선 정(+)의 관계 로 추출된 것은 <보증금 없는 월세: 0.78>, <보증금 있 는 월세: 0.77>, <무상: 0.50>으로 나타났고, 부(-)의 관계 는 오로지 <자가: -0.78>이다. 이 또한 1인 가구의 점유 형태가 월세 또는 친인척 등에 의한 무상의 형태로 거주 하기 때문일 것이며, 반대의 자가의 경우는 드물기 때문 인 것으로 풀이된다.
성/혼인 상태에서는 “미혼(남/여), 기혼(남/여), 사별(남/
여), 이혼(남/여)” 등 8개의 구분에서 4개가 유의하였는데, 우선 정의 관계는 <미혼(남): 0.91>, <미혼(여): 0.77>이 며, 부의 관계는 <기혼(여): -0.87>, <기혼(남): -0.86>인 것으로 나타났다. 미혼의 싱글세대 중에서도 1인 가구의 남성이 여성보다 더 많기 때문에 상관계수가 다소 더 높 게 나타난 것으로 보인다.
연건평에서는 “20 m
2이하(호)~230 m
2초과(호)”의 총 9 개 구분에서, 유의한 것은 오직 <230 m
2초과(호): 0.58>
인 것으로 나타났다. 연건평 20 m
2이하 주택은 원룸형태 가 많아 1인 가구 점유비율과 높은 상관이 있을 것으로 기대하였으나 상관계수값은 0.45에 머물렀다.
주택유형에서는 “다세대, 단독, 아파트, 연립, 영업용 건 물 내 주택, 주택 이외 거처” 등 6개 구분에서 마찬가지 방법으로 유의하게 추출된 항목은 2개로, <단독주택: 0.58>,
< 영업용 건물 내 주택: 0.54>으로 상관계수값은 크지 않 았다. 노원구에서는 아파트 비율(86.8%)이 가장 높고, 종 로구에서는 단독주택의 비율(32.6%)과 연립주택의 비율 (12.6%) 이, 은평구에서는 다세대 주택의 비율(43.7%)이 각 각 가장 높은 것으로 나타났다.
3) 1 인 가구의 점유비율과 높은 상관관계를 갖는 항목 을 기준으로 자치구의 유형화 및 유형별 특성분석
위에서 상술한 공간정보 분석테이블에서 자치구별 1인 가구 점유비율과 높은 상관관계에 있는 항목(연속 변수) 들을 추출하고, 이를 기준으로 하여 유사한 공간단위(서 울시 자치구)끼리 군집화, 유형화함으로써 군집별 특성에
Figure 6. Seoul Autonomous Region's Single Household andOccupancy Rate
대해 검토한다. 이를 통해 1인 가구 점유비율에 영향을 미치는 요인들에 의해 어떤 자치구끼리 유사하게 묶이며, 이는 나아가 자치구 도시공간구조의 특성과 함의를 이해 하는데 도움을 줄 수 있기 때문이다.
이를 위해 다차원척도법(MDS)과 군집분석의 두 가지 다변량분석 기법으로 검토하였다. 군집분석이 개체들 간 의 거리관계를 이용하여 개체(object)를 동일한 그룹들로 분류하는 반면, 다차원척도법은 개체들의 비유사성을 이 용하여 공간상에 표시함으로써 개체들 간의 상대적인 위 치를 표시하고, 이를 이용하여 개체들 간의 관계구조를 시각적으로 표현할 수 있다.
위에서 적률상관계수 절댓값 0.5, 유의수준 5% 이하에 서 추출한 변수는 총 24개이지만 다소 많다고 판단하여, 변수 추출 기준을 더 엄격히 적용하여 상관계수 절댓값 0.8, 유의수준 5%이하의 조건을 만족하는 항목들만을 추 출한 결과, “5~9세, 25~29세, 방1개, 거실 없음, 거실1개, 미혼남자, 부인 있는 남자, 남편 있는 여자” 등 8개의 항 목이 추출되었다(지면관계상 표는 생략). 이들 8개 항목을 기준으로 다차원척도법에 의해 출력된 배치관계를 나타낸 것이 <Figure 7(a)>이다.
한편, 다차원척도법에 적용하였던 데이터테이블을 군집 분석에도 그대로 적용하여 유형화하여 보았는데, 적용 군 집분석 방법은 위계적 군집분석법과 K평균 군집분석을 병 행하여 각각 <Figure 7(b), 7(c)>와 같은 결과를 얻었다.
두 분석방법에 의해 오직 ‘구로구’만이 그룹 분류에서 차 이가 났는데, <Table 8>에서 보는 바와 같이 위계적 군 집방법에서는 구로구를 <군집4>로 분류하였으나 K평균 군집분석에서는 <군집2>로 분류하였다.
한편, 위 두 군집분석 중에서 어떤 기법이 더 타당한 지를 알아보기 위해 ‘모형 기반 군집분석’(mclust: Fraley
& Raftery, 2007) 을 실시하였는데, 이 기법은 데이터에 대 한 베이즈 정보기준(BIC)을 통해 가장 최적의 모형과 군 집 수를 도출해 내도록 고안된 모형이다. 이 기법을 적용 한 결과 <Figure 7(b)>와 같이 분류한 6개의 군집에서 최 적의 모형 설명 BIC(Bayesian Information Criterion)값을 얻었다.
이러한 일련의 과정을 통해 알 수 있는 것은, 자치구별 1 인 가구의 인구통계학적 특성인 “연령, 성별, 혼인상태”
의 집계통계량과, 주거특성인 “방과 거실수”의 집계통계 량이 결정적으로 1인 가구의 점유비율과 관계되어 있다는 점이다. 즉, 인구특성과 주거특성이 <군집5>의 관악구나
< 군집6>의 종로구 등 1인 가구의 점유비율이 상대적으로
Figure 7. Autonomous Region's cluster and Typology by MDS and Cluster Analysis
Table 8. Comparison of the Classified Cluster According to the Cluster Analysis Method
Cluster Hierarchical cluster analysis K means clustering analysis
1 Nowon, Eunpyeong, Dobong, Yangcheon
Dobong, Nowon, Eunpyeong, Yangcheon
2 Seocho, Songpa, Kangbuk, Kangseo, Jungrang, Gangdong
Jungrang, Kangbuk, Kangseo, Guro, Seocho, Songpa,
Gangdong
3 Gangnam, Jung-Gu Mapo, Yongsan, Seodaemun
Gangnam, Jung-Gu Mapo, Yongsan, Seodaemun
4 Guro, Yeongdeungpo, Seongdong, Seongbuk
Yeongdeungpo, Seongdong, Seongbuk
5 Gwanak Gwanak
6 Gwangjin, Dongdaemun, Dongjak, Jongno, Geumcheon
Gwangjin, Dongdaemun, Dongjak, Jongno, Geumcheon
높은 자치구와, 반대로 <군집1>의 노원구 등 1인 가구 점 유비율이 매우 낮은 자치구를 잘 구분하고 있다는 점이 다. 다시 말해, 1인 가구는 도시공간구조에 의해 규정되 는 주거특성과 라이프 스타일의 인구통계학적 특성에 따 라 이들의 주거지가 자연스럽게 공간상에 분화되어 나타 난다고 하겠다. 예컨대, <군집1>의 도봉구, 노원구, 은평 구, 양천구 등 소위 1980년대 택지개발지구로 신도시가 형성되어 대규모의 중대형 평형의 아파트가 많이 공급된 지역에서는 1인 가구가 거주할 수 있는 원룸형 주거의 부 족으로 1인 가구 형성이 어려운 도시 공간구조이며, 이에 따라 결과적으로 1인 가구의 점유비율이 낮게 나타남을 알 수 있다.
V. 결 론
본 연구는 주거, 도시, 건축의 사회과학 분야에서 향후 활용성이 높을 것으로 판단되는 새로운 데이터마이닝 응 용기법을 제안하고, 이를 서울서베이 속성정보 및 공간정 보에 적용하여 1인 가구의 특성을 추출하고 분석기법의 유효성을 증명하고자 하였다. 동시에 집계구별 통계자료 로부터 공간에 관한 정보를 공간 위계단위로 분석할 수 있는 분석테이블을 작성하고, 이를 바탕으로 서울시 자치 구별 1인 가구 점유비율과 이와 상관관계가 높은 변수를 추출하고, 자치구를 유형화하여 1인 가구의 공간적 분포 특성과 함께 지역 유형별 함의를 고찰하였다. 연구에서 얻은 주요 결과는 다음과 같다.
첫째, 서울서베이 2005~2010에서 나타나는 1인 가구의 몇 가지 특성으로, 인구통계학적 특성이 연도별로 다른 샘플임에도 불구하고 나타나는 특성은 거의 유사한 것으 로 나타났다. 즉, 1인 가구의 주거환경 만족도와 이사계 획과는 2005년에서 2010년까지 샘플 자료에서 모두 유의 한 관계가 성립함이 밝혀졌는데, 주거 불만이 높아질수록 이주하려는 경향이 높아 1인 가구에게는 경제, 사회, 교 육환경보다는 주거환경이 우선적으로 마련되어야 주거안 정이 확보됨이 밝혀졌다.
둘째, 본 연구에서 제안한 AIC지표에 의한 모형 선택 과 대응분석으로 이어지는 일련의 정보요약 과정은 서울 서베이 설문조사와 같은 다속성 범주형 빅데이터 분석에 효과적일 수 있음을 1인 가구 특성관련 8개 이산형 변수 를 모형에 투입하여 그 유효성을 검증하여 보였다.
셋째, 제안 분석방법에 의해 추출한 흥미로운 사실 중 의 하나는, 통학하는 10~20대의 학생은 모든 집은 국가 소유의 임대주택으로 전환해야 한다는 집에 대한 인식이 강하고, 미혼의 30대나 이혼 50대 통근 직장인은 집은 투 자가치이자 사회적 지위와 최고의 자산을 나타내는 수단 이라는 인식이 강하였다. 또한 이들의 고민 의논 상대자 로는 형제나 자매, 또는 아예 가족과 의논하지 않는 경향 으로 나타났다. 반면, 재택 또는 실업자 등으로 추정되는 1 인 가구들은 사별 60대 이상의 저소득층이 많고, 자신의
자녀와 고민을 의논하며 자신은 사회의 가장 하류층에 속 한다고 스스로 인식하는 경향이 강한 것으로 나타났다.
넷째, 서울시 자치구별 1인 가구 점유비율과 매우 높은 상관관계를 보이는 속성정보를 추출한 결과, 이것들은 연 령(5세~9세, 25세~29세), 주택형태(방1개, 거실 없음, 거 실1개), 혼인상태(미혼남자, 기혼남자, 기혼여자)의 3개 변 수 8개 수준의 항목이었다. 이들 항목을 기준으로 하여 서울시 25개 자치구를 군집분석으로 유형화하였더니 1인 가구는 6개의 자치구 군집으로 분류되었으며, 군집별 특 성은 1인 가구의 인구통계학적 특성과 주거특성이 결합되 어 도시 공간구조로 분화되어 나타남을 확인할 수 있었다.
본 연구는 선행연구에서 그다지 잘 밝혀져 있지 않는 다속성 범주형 빅데이터로부터 흥미로운 규칙과 패턴을 추출하기 위하여 AIC검증 및 대응분석을 결합한 새로운 데이터마이닝 접근방법을 제시하였다. 더불어, 공간정보를 속성정보와 연계 분석함으로써 기존 1인 가구 연구에서 중요한 요인으로 언급하고 있는 인구통계학적 속성과 주 거형태가 이 연구에서도 실제로 1인 가구의 가치관과 공 간적 주거분포와 밀접히 관련되어 있음을 실증으로 보였 다. 본 연구의 후속 연구로는 주거, 도시, 건축 분야에서 도 점점 빅데이터가 증가하고 있으므로 통계학, 컴퓨터공 학, 경영학 등에서 배양된 데이터마이닝의 다양한 분석기 법을 적극 활용, 또는 개량하여 지금까지 잘 알려져 있지 않은 흥미롭고 유익한 정보를 추출하여 다른 학문분야 못 지않게 이 분야에서도 활용할 수 있도록 실험적인 다양 한 연구를 계속하는 일일 것이다.
REFERENCES