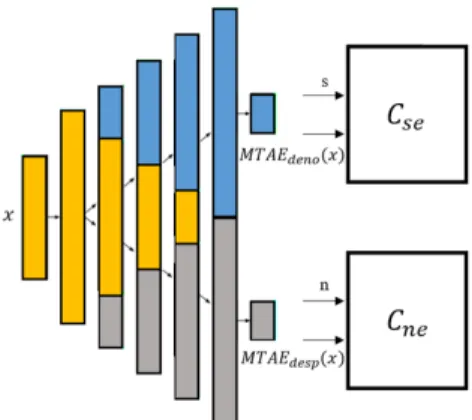
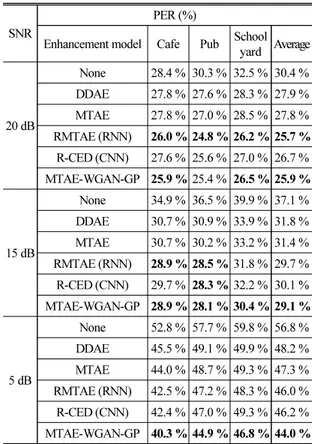
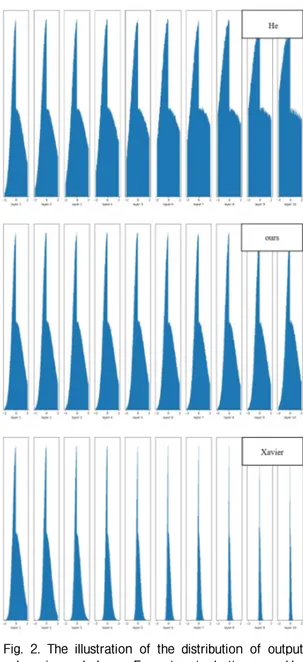
관련 문서
SigmaNEST 펀칭 파워팩 제품 관리, 자동 다이나믹™ 배 열 및 펀칭 툴 관리를 갖춘 터렛 펀칭 프로그래밍을 위한 가장 완벽하고 최적화된
Single prediction → large error Multi-model mean prediction → smaller error Probability and various scenarios (X). → Preparing for the
- 각종 지능정보기술은 그 자체로 의미가 있는 것이 아니라, 교육에 대한 방향성과 기술에 대한 이해를 바탕으로 학습자 요구와 수업 맥락 등 학습 환경에 맞게
1) An LSTM network model is designed to deep extract the speech feature of Log-Mel Spectrogram/MFCC, which solves the high dimensional and temporality of the speech data. 2)
Read the error step using a peripheral device and check and correct contents of the dedicated instruction for special function modules of
with the experimental C versus t data. If the fit is unsatisfactory, another rate equation is guessed and tested. Integral method is especially useful for fitting simple
Metz, “Unsupervised representation learning with deep convolutional generative adversarial networks”, ICLR(International Conference on Learning Representations)
(linguistic units)이 speech production에 연관되어 있다는 것을 보여줌.. Speech errors의 형태. i) 음성적 자질 (phonetic features)이 서로 인접한 음소끼리 바뀜.