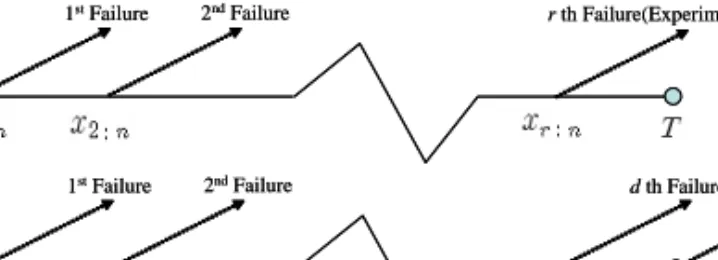
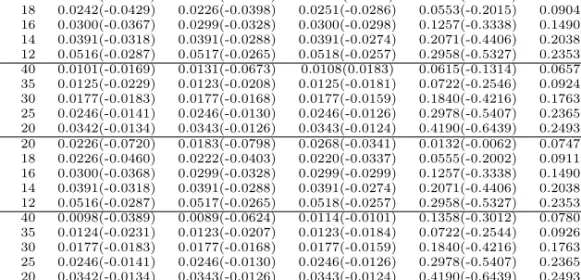
Estimation for the half triangle distribution based on Type-I hybrid censored samples
9
0
0
전체 글
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
수치
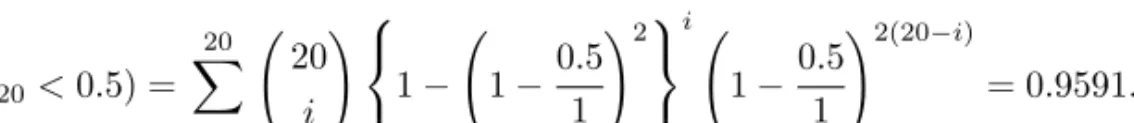
관련 문서
Third, based on the above results, this study concluded that the competitiveness of the agricultural product distribution industry in uncertain business
12 As such, using finite element modeling, the effect of stress distribution around the internal non-submerged type implants on marginal bone resorption
Based on the above results, the 12-week complex type correction program had a positive effect on the shoulder angle, trunk rotation angle, and body shape
Maximum heat generation, temperature distribution(case) considering various time, maximum von-mises stress and maximum deformation under discharge current(1.25 A discharge)
By analysing the dependences of the maximum increase in temperature and the maximum acceleration on the medium properties and the information of the damage
Phylogenetic analysis of Orientia tsutsugamushi strains based on the sequence homologies of 56-kDa type-specific antigen genes. FEMS
As examined above, based on the type changes this study confirmed that <Seoyukyonmunrok> has plenty of 'aaba' type structures and most lines are
Based on the introduction of industrial wastewater TOC effluent standard, the distribution characteristics of organic matter according to the type of business
