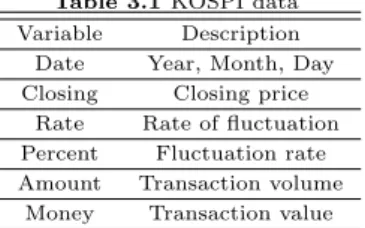
2021, 32
(2)
,267–281
AdaBoost-GRU 앙상블 모형을 이용한 금융 시계열 예측
ᄀ ᅪ ᆨ내원
1
· 임동훈2
12경상대학교 정보통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2020ᄂ ᅧ ᆫ 11ᄋ ᅯ ᆯ 25ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2020ᄂ ᅧ ᆫ 12ᄋ ᅯ ᆯ 29ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2021ᄂ ᅧ ᆫ 1ᄋ ᅯ ᆯ 3ᄋ ᅵ ᆯ
요 약
ᄋ ᅵ
ᆯᄇ ᅡ ᆫᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ (financial time series) ᄋ ᅨᄎ ᅳ ᆨᄋ ᅳ ᆫ ᄇ ᅵᄉ ᅥ ᆫᄒ ᅧ ᆼᄉ ᅥ ᆼ (non-linearity)ᄀ ᅪ ᄇ ᅮ ᆯ ᄀ ᅲᄎ ᅵ ᆨ ᄉ ᅥ
ᆼ(irregularity)ᄋ ᅳᄅ ᅩ ᄋ ᅵ ᆫᄒ ᅢ ᄆ ᅢᄋ ᅮ ᄋ ᅥᄅ ᅧᄋ ᅮ ᆫ ᄋ ᅵ ᆯᄋ ᅵᄃ ᅡ. ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄋ ᅨᄎ ᅳ ᆨᄋ ᅳ ᆯ ᄋ ᅱᄒ ᅢ AdaBoost ᄋ
ᅡ
ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷ ᄀ ᅪ GRU ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄀ ᅧ ᆯᄒ ᅡ ᆸᄒ ᅡ ᆫ ᄒ ᅡᄋ ᅵᄇ ᅳᄅ ᅵᄃ ᅳ ᄋ ᅡ ᆼᄉ ᅡ ᆼᄇ ᅳ ᆯ ᄒ ᅡ ᆨᄉ ᅳ ᆸ ᄇ ᅡ ᆼᄇ ᅥ ᆸ (hybrid ensemble learning ap- proach)ᄋ ᅳ ᆯ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡᄀ ᅩᄌ ᅡ ᄒ ᅡ ᆫᄃ ᅡ. ᄋ ᅧᄀ ᅵᄉ ᅥ GRU ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆫ LSTM (long short term memory) ᄆ ᅩᄒ ᅧ ᆼᄀ ᅪ ᄒ ᅡ ᆷᄁ ᅦ ᄉ
ᅵᄀ ᅨᄋ ᅧ ᆯ ᄋ ᅨᄎ ᅳ ᆨ ᄋ ᅦ ᄂ ᅥ ᆯᄅ ᅵ ᄉ ᅡᄋ ᅭ ᆼ ᄃ ᅬᄂ ᅳ ᆫ RNN (recurrent neural network)ᄋ ᅴ ᄇ ᅧ ᆫᄒ ᅧ ᆼ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅵᄃ ᅡ. ᄋ ᅮᄅ ᅵᄂ ᅳ ᆫ KOSPI ᄃ
ᅦᄋ ᅵᄐ ᅥᄋ ᅪ ᄋ ᅯ ᆫ/ᄃ ᅡ ᆯᄅ ᅥ ᄒ ᅪ ᆫᄋ ᅲ ᆯ ᄀ ᅪ ᄀ ᅡ ᇀᄋ ᅳ ᆫ ᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ ᄃ ᅦᄋ ᅵᄐ ᅥᄅ ᅳ ᆯ ᄀ ᅡᄌ ᅵᄀ ᅩ ᄌ ᅦᄋ ᅡ ᆫ ᄃ ᅬ ᆫ ᄆ ᅩᄃ ᅦ ᆯᄋ ᅳ ᆯ ᄑ ᅧ ᆼᄀ ᅡᄒ ᅡᄀ ᅩᄌ ᅡ ᄒ ᅡ ᆫᄃ ᅡ. ᄉ ᅥ ᆼᄂ ᅳ ᆼᄉ ᅵ ᆯ ᄒ
ᅥ
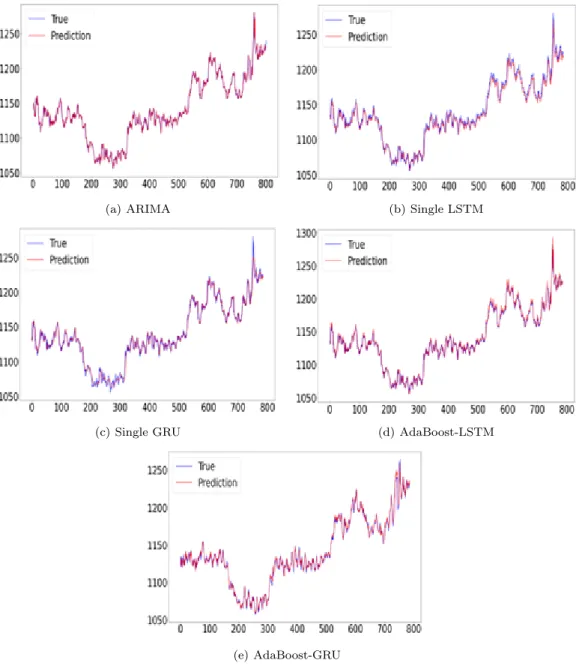
ᆷ ᄀ ᅧ ᆯᄀ ᅪ ᄌ ᅦᄋ ᅡ ᆫ ᄃ ᅬ ᆫ AdaBoost-GRU ᄋ ᅡ ᆼᄉ ᅡ ᆼᄇ ᅳ ᆯᄋ ᅳ ᆫ 3ᄀ ᅡᄌ ᅵ ᄎ ᅥ ᆨᄃ ᅩ ᄌ ᅳ ᆨ, MAE, MSE ᄆ ᅵ ᆾ RMSE ᄎ ᅥ ᆨᄃ ᅩᄋ ᅦᄉ ᅥ ᄀ ᅵᄌ ᅩ ᆫ ᄋ ᅴ ARIMA ᄆ ᅩᄒ ᅧ ᆼ, LSTM ᄆ ᅩᄒ ᅧ ᆼ, GRU ᄆ ᅩᄒ ᅧ ᆼ, ᄀ ᅳᄅ ᅵᄀ ᅩ Adaboost-LSTM ᄋ ᅡ ᆼᄉ ᅡ ᆼᄇ ᅳ ᆯ ᄇ ᅩᄃ ᅡ ᄌ ᅩ ᇂᄋ ᅳ ᆫ ᄉ ᅥ ᆼᄂ ᅳ ᆼᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅧ ᆻᄃ ᅡ.
ᄀ
ᅳᄅ ᅵᄀ ᅩ Adaboost-LSTM ᄆ ᅩᄒ ᅧ ᆼᄀ ᅪᄋ ᅴ ᄎ ᅥᄅ ᅵᄉ ᅩ ᆨ ᄃ ᅩ ᄆ ᅧ ᆫᄋ ᅦᄉ ᅥ ᄌ ᅦᄋ ᅡ ᆫ ᄃ ᅬ ᆫ AdaBoost-GRU ᄆ ᅩᄒ ᅧ ᆼᄋ ᅵ ᄈ ᅡᄅ ᅳ ᆷᄋ ᅳ ᆯ ᄋ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ
ᆻᄋ ᅥ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: AdaBoost-GRU ᄋ ᅡ ᆼᄉ ᅡ ᆼᄇ ᅳ ᆯ, ᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄉ ᅵᄀ ᅨᄋ ᅧ ᆯ, ᄃ ᅵ ᆸᄅ ᅥᄂ ᅵ ᆼ.
1. 서론 그
ᆷ융시장은경제 상황, 정치적 사건, 금융투자자들의 기대 등과 같은여러 요인에 의해 영향을받는 ᄃ
ᅡ. 따라서금융 시계열 (financial time series) 예측은 일반적으로 비선형성 (non-linearity)과 불규칙 서
ᆼ (irregularity)으로 인해 가장 어려운작업 중하나로 간주된다 (Yu 등, 2009).
ᄌ
ᅵ금까지 ARIMA (autoregressive integrated moving average) 모형, VAR (vector auto-regression) ᄆ
ᅩ형, ECM (error correction model) 모형 같은많은 일반적인 계량 경제학 및 통계 모델이금융시계 여
ᆯ 예측하는데 적용되었다. 그러나 기존의 방법들은 금융시계열의 비선형성과 복잡성을해결하지 못 ᄒ
ᅡᆷ으로써 예측정확도가 떨어졌다 (Sun 등, 2018).
ᄎ
ᅬ근 빠른 컴퓨터 기술 발달로 인하여 머신러닝 (machine learning)이 금융 시계열 예측에 활용되 ᄀ
ᅩ 있다. 여기서 머신러닝이란 컴퓨터를 인간처럼 학습시켜, 스스로 규칙을 생성하도록 하는 기술을 ᄆ
ᅡ
ᆯ하는데 대표적인 방법으로는 인공 신경망 (ANN: Artificial Neural Networks)과 서포트 벡터 회귀 (support vector regression) 등이 있다. 인공 신경망은사람의 두뇌가 의사 결정하는형태를모방하여 부
ᆫ류하는방법으로 과대적합 (over-fitting)과 국소최적화 (local optimization) 등의 한계점을갖고 있 ᄃ
ᅡ. 그리고 서포트 벡터 회귀는학습과정에서 마진 (margin)을최대화하는 초평면 (hyperplane)을 추 저
ᆼ한 후 새로운데이터를예측하는방법으로 인공 신경망에서 비해 과대적합이 덜하고 예측의 정확도가 노
ᇁ으나 매개변수 결정과 결과에 대한 설명력이 떨어진다는단점이 있다 (Rundo 등, 2019).
1
(52828) ᄀ ᅧ ᆼᄂ ᅡ ᆷ ᄌ ᅵ ᆫᄌ ᅮᄉ ᅵ ᄌ ᅵ ᆫᄌ ᅮᄃ ᅢᄅ ᅩ 501, ᄀ ᅧ ᆼᄉ ᅡ ᆼᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄒ ᅡ ᆨᄇ ᅮᄌ ᅩ ᆯᄋ ᅥ ᆸ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (52828) ᄀ ᅧ ᆼᄂ ᅡ ᆷ ᄌ ᅵ ᆫᄌ ᅮᄉ ᅵ ᄌ ᅵ ᆫᄌ ᅮᄃ ᅢᄅ ᅩ 501, ᄀ ᅧ ᆼᄉ ᅡ ᆼᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ/ᄇ ᅡᄋ ᅵᄋ ᅩᄋ ᅴᄅ ᅭᄇ ᅵ ᆨᄃ ᅦᄋ ᅵᄐ ᅥᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ ᄆ ᅵ
ᆾ RINS. E-mail: [email protected]
ᄎ
ᅬ근 들어 많이 이용되고 있는 딥러닝 (deep learning)은 머신러닝 기술의 한 분야로, 인공신경망 ᄋ
ᅦ 기반을 둔 심층신경망 (deep neural network)으로 다양한 분야에서 뛰어난 성능을 보이고 있다 (Deng와 Yu, 2014; Lee, 2017; Song 등, 2020; Kim 등, 2020). 딥러닝 모형 중 RNN (recurrent neural network)은시계열 데이터에 특화된모형으로 기존의 인공 신경망 모형보다 높은예측력을갖고 있으나 ᄌ
ᅡᆼ기의존성 (Long-Term Dependency) 문제를갖고 있다 (Hewamalage 등, 2021). LSTM (long short- term memory)과 GRU (gated recurrent unit)은 RNN의 장기의존성 (Long-Term Dependency) 문제 르
ᆯ해결하기 위해 고안되었으며, 많은시계열 예측에 LSTM과 GRU 모형이 이용되고 있다. LSTM과 GRU모형 비교에서 GRU 모형은 LSTM모형보다 간단한 구조와 적은계산시간 그리고 데이터에 따라 조
ᇂ은성능을보인다 (Chung, 등, 2014).
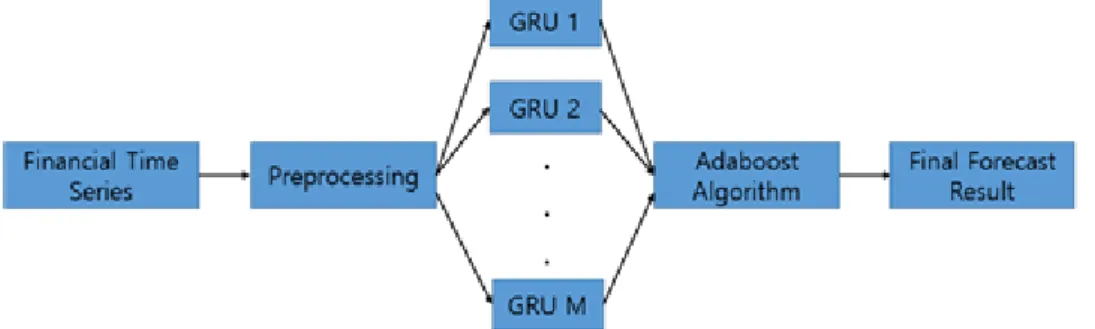
ᄇ
ᅩᆫ 논문에서는 AdaBoost 알고리즘과 GRU 딥러닝을결합한 하이브리드 앙상블학습 방법 (hybrid ensemble learning approach)을제안한다. 먼저, GRU 모형은 AdaBoost 알고리즘에 의해 얻어진 붓 ᄉ
ᅳ트랩 샘플 (bootstrapped samples)을 사용하여 훈련된다. 다음, AdaBoost알고리즘은각 GRU 모 혀
ᆼ의 앙상블가중치 (ensemble weights)를얻기 위해 적용된다. 새로운데이터에 대해 예측하는데 제안 되
ᆫAdaBoost-GRU앙상블모형은모든 GRU모형의 예측결과에 대해 앙상블가중치를결합하여 최종 겨
ᆯ과를얻는다.
ᄌ
ᅦ안된AdaBoost-GRU 앙상블모형의 성능평가를 위해 기존의 ARIMA 모형, LSTM 모형, GRU ᄆ
ᅩ형과 기존의 AdaBoost-LSTM 앙상블 모형을 고려하였으며 2가지 금융 시계열 데이터 즉, KOSPI ᄃ
ᅦ이터, 원/달러 환율 데이터를 가지고 3가지 척도 즉, MAE, MSE 및 RMSE에서 평가하고자 한다 (Saigal과 Mehrotra, 2012; Wang 등, 2018).
보
ᆫ 논문은다음과 같이 구성되어 있다. 제 2절에서는관련 연구로서 AdaBoost 알고리즘과 GRU 모 혀
ᆼ에 대해 논의하고, 제 3절에서는 AdaBoost-GRU 앙상블학습방법에 대해 논의한다. 제 4절에서는 서
ᆼ능실험에서 정성적인 비교와 MAE, MSE 및 RMSE 척도 하에서 정량적인 비교, 그리고 AdaBoost- GRU모형과 AdaBoost-LSTM 모형과의 처리속도를비교한다. 제 5절에서 결론을맺는다.
2. 관련연구
2.1. AdaBoost 알고리즘
Freund와 Shapire (1997)가 처음으로 이진 분류 문제에 AdaBoost 알고리즘을제안하였다.
AdaBoost 알고리즘은 예측력이 약한 분류기 (weak classifier)들을 결합하여 강한 분류기 (strong classifier)를만드는것이다. 여기서 약한 분류기란 랜덤하게 예측하는것보다 약간 좋은예측력을갖고 이
ᆻ는 분류기이고 강한 분류기란 예측력이 최적에 가까운 분류기를말한다.
AdaBoost알고리즘은학습초기에 모든데이터가 추출될 확률은 동일한 상태에서 시작하지만, 분류 ᄀ
ᅡ 잘 못된데이터는추출될 확률을 증가시키고, 분류가 잘된데이터는추출될 확률을감소시키면서 데 ᄋ
ᅵ터가 추출될 확률을재조정하면서 반복학습이 이루어진다. 이에 대한 설명은다음과 같다.
D = {(xxx111, y1), (xxx222, y2), ..., (xxxnnn, yn)} , xxxiii ∈ Rk, yi ∈ {−1, +1}을 훈련용 데이터의 집합이라 하고 ᄀ
ᅡ
ᆨ 데이터가 추출할 확률을 w1, w2, ..., wn이라 하자. 처음 각 데이터가 추출될 확률은 동일하다. 즉, w(1)i =n1, i = 1, ..., n. 여기서 붓스트랩 표본의 수를 M라 하고 각각의 붓스트랩 표본에서 구한 분류기 ᄅ
ᅳᆯ C1, C2, ..., CM이라 하자. 그러면 분류기 Cm의 오분류율 (miss-classification error) ϵm은다음과 같 ᄋ
ᅵ 계산한다.
ϵm= Pn
i=1w(m)i I(Cm(xxxiii) ̸= yi) Pn
i=1wi
, m = 1, ..., M, ᄋ
ᅧ기서 ϵm은 분류기 Cm에 의해 각 데이터의 오분류에 대하여 데이터가 추출된 확률을가중값으로 하 느
ᆫ오분류율이다. 분류기 Cm의 신뢰도 (confidence) αm은다음과 같이 결정한다.
αm=1
2ln1 − ϵm
ϵm
, m = 1, ..., M, ᄋ
ᅧ기서 αm은 분류기 Cm가 결합할 때 중요도를결정하는가중치 역할을한다.
w(m)i 을 m번째 붓스트랩 표본의 추출 확률이라고 할 때 (m + 1)번째 붓스트랩 표본의 추출 확률 w(m+1)i 은다음과 같이 계산한다.
wi(m+1)= w(m)i exp(−αmyiCm(xi)) Zm
, ᄋ
ᅧ기서 Zm는정규화 상수로서 다음을만족한다.
Zm=
n
X
i=1
wi(m)exp(−αmyiCm(xi)).
ᄉ
ᅢ로운테스트 데이터 xxx′i′i′i∈ Rk에 대해 생성된M개의 분류기를결합하여 최종 분류기 C∗(xxx′′′)은다음과 ᄀ
ᅡ ᇀ다.
C∗(xxx′′′) = sign(
M
X
m=1
αmCm(xxx′)),
ᄋ
ᅧ기서 C∗(xxx′′′)은각 분류기에 대한 중요도 αm만큼가중치를반영하여 얻은가중결합식이다.
2.2. GRU 모형
GRU모형은기존의 LSTM 모형의 변형된모형이며 Figure 2.1의 구조를가지고 있다.
Figure 2.1에서 보면 GRU 구조는두 개의 gate 즉, update gate zt와 reset gate rt로 구성되어 있다.
ᄎ ᅡ
ᆷ고로, LSTM 구조는세 개의 gate 즉, input gate, forget gate그리고 output gate로 구성되어 있다.
GRU구조는 LSTM구조와 다르게 output gate가 없고 update gate는 input gate와 forget gate의 역 ᄒ
ᅡᆯ을수행한다. 지금부터 update gate zt와 reset gate rt의 역할에 대해 살펴보고자 한다.
Figure 2.1 Structure of GRU
ᄆ
ᅥᆫ저, update gate zt을수식적으로 나타내면 식 (2.1)과 같다.
zt= σ(Wz• [ht−1, xt]), (2.1) ᄋ
ᅧ기서 xt은현재의 입력, Wz은가중치 행렬, ht−1은이전 state, σ은시그모이드 (sigmoid) 함수를나 ᄐ
ᅡ낸다. 따라서 zt은이전 정보의 양이 다음시점으로 어느 정도 업데이트(즉, 갱신, 전달)될 것인가를 겨
ᆯ정한다.
ᄃ
ᅡ음, reset gate rt을수식적으로 나타내면 식 (2.2)과 같다.
rt= σ(Wr• [ht−1, xt]). (2.2) rt은 이전 정보의 양이 다음 시점으로 어느 정도 리셋(즉, 무시함, 잃음)될 것인가를 결정한다. 식 (2.2)은 식 (2.1)과의 차이는가중치 행렬에 있다.
Figure 2.1에서 이들 gate들이 작동과 최종 결과에 어떤 영향을 미치는지 살펴보고자 한다. 먼저, reset gate rt와 ht−1의 곱셈 연산이 수행된다. 0 ≤ rt ≤ 1이므로 이전 state ht−1의 정보를어느 정 ᄃ
ᅩ 잃을 것인가를 rt에 의해 결정된다. 만약 rt가 0에 가까운값이면 이전 state ht−1의 정보를 잃고, ᄆ
ᅡᆫ약 rt가 1에 가까운값이면 이전 state ht−1의 정보는 잃지 않고 보존된다. 현재 기억 용량 (current memory content) ˜ht을수식적으로 나타내면 다음과 같다.
h˜t= tanh(W • [rt× ht−1, xt]), (2.3) ᄋ
ᅧ기서 tanh은 tanh활성화 함수이고 -1과 1 사이의 값을갖는다.
ᄄ
ᅡ라서 현재의 state ht의 정보는 update gate를사용하여 이전 state ht−1의 정보와 현재 기억 용량 h˜t으로부터 식 (2.4)과 같이 결정한다.