地 盤 工 學
大 韓 土 木 學 會 論 文 集第26卷 第6C 號·2006年 11月 pp. 421~429
국내 연약지반의 신뢰성 있는 강성지수 추정을 위한 인공신경망 이론의 적용
Application of Artificial Neural Network Reliable to Estimation Rigidity Index of Korean Soft Clay
김영욱*·김영상**·구남실***·박지호****
Kim, Young Uk · Kim, Young Sang · Goo, Nam Sil · Park, Ji Ho
···
Abstract
This study was undertaken to develop an analysis model representing a reliable estimation of rigidity of Korean soft clay using an artificial neural network (ANN). Data for the model development were obtained through a laboratory study, and were used for training and verification. The coefficient of correlation between the measured and predicted data using the developed model was relatively high. It demonstrates the potential application of ANN for the reliable estimation of Korean soft clay rigidity while past attempts at building such a mathematical model have proved difficult.
Keywords : artificial neural network, rigidity, sensitive analysis, soft clay
···
요 지
본 연구에서는 국내 연약지반의 신뢰성 있는 강성지수 추정을 위하여 인공신경망기법을 적용하였다. 실내시험을 통한 물성 치결과들을 통하여 인공신경망을 위한 입력자료를 확보한 뒤 이를 이용하여 모델을 학습시킨 후 모델검증을 실시하였다. 개 발된 모델의 검증결과 측정값과 예측값의 상관관계가 매우 높게 나타났으며 이를 통하여 수학적 모델 수립이 곤란한 국내 연약지반의 신뢰성 있는 강성지수 추정의 전반적인 고찰의 기초를 확립하였다.
핵심용어 : 인공신경망, 강성지수, 민감도분석, 연약점토
···
1. 서 론
근래에는 산업단지 , 택지 , 항만 및 공항 등의 시설이 대부 분 해안 지역 연약지반에 많이 건설되고 있는 추세이다 . 이 러한 연약지반에 구조물을 축조하기 위해서는 적절한 지반 개량이 필요하므로 그 지반에 대한 정확하고 신뢰성 있는 지반 정보를 얻기 위한 다양한 지반조사 및 실내·현장시험 이 시행되고 있다 .
지반의 강성지수는 피에조 콘으로 C
h를 추정할 때 이론해 를 사용하기 위해서 요구되는 압밀특성을 지배하는 중요한 영향요소이나 현재까지 국내 연약지반의 강성지수에 대해서 는 체계적으로 연구된 사례가 거의 없어 현장 여건상 비교 란 시료채취나 강성지수 산정을 위한 신뢰할 만한 시험 실 시가 어려운 경우에는 해외에서 제시된 값 ( 일반적으로 I
r=100, Levadoux & Baligh(1986) 의 이론해는 I
r=500) 을 해석에 그대로 적용하고 있는 실정이다 . 그러나 기존 제안된
경험값의 경우는 대부분 국내지반과 전혀 다른 물성치 , 응력
이력 그리고 입자배열 구조를 갖는 국외지반에 국한된 결과 라고 할 수 있다 . 강성지수의 산정에 있어 불확실성을 포함 할 수 있는 국외에서 제시된 값을 맹목적으로 적용하는 것 보다는 불확실성을 최소화하고 국내 지반의 기본 물성치들 에 대한 충분한 검토에 근거하는 적합한 강성지수를 제안하 여 경제적인 설계가 이루어질 수 있도록 자료를 제공할 필 요성이 증가하고 있다 . 본 연구는 국내 연약지반의 실내시험 결과로부터 보다 신뢰성 있는 강성지수를 예측할 수 있도록 인공신경망 이론의 적용성을 검토하였다 .
2. 이론적 배경 2.1 강성지수
지반의 비배수 전단탄성계수 ( G ) 와 비배수 전단강도 ( s
u) 의 비로 나타내는 강성지수 ( I
r=G/s
u) 는 공동확장이론과 변형률
*정회원·교신저자·명지대학교토목환경공학과부교수·공학박사
(E-mail : [email protected])
**정회원·국립여수대학교해양공학전공조교수·공학박사
(E-mail : [email protected])
***정회원·한국토지공사대전충남지사과장
(E-mail : [email protected])
****정회원·명지대학교토목환경공학과공학석사
(E-mail : [email protected])
경로법을 이용하는 분야나 피에조 콘에 의한 압밀계수 및 비배수 전단강도 해석 등 다양한 분야에 적용된다 . 그러나 콘 관입 시 주변 지반에 발생하는 다양한 수준의 변형률 분 포와 전단탄성계수의 변형률 의존성은 콘 시험결과 해석에 적용할 적정한 전단탄성계수의 선택을 매우 어렵게 하며 , 또 한 전단탄성계수와 비배수 전단강도를 구하는 시험에서 변 형률 속도나 시험방법 등에 따라 강성지수가 두 배 이상 차 이가 나기도 한다 . 이와 같은 강성지수의 불확실성은 간극수 압 소산시험결과 해석에 큰 영향을 주며 , 알려진 바와 같이 강성지수는 압밀특성을 지배하는 중요한 영향 요소로 강성 지수가 클수록 초기 과잉간극수압은 상대적으로 크게 되어 압밀 소요시간에 영향을 주므로 강성지수에 따라 시간계수
가 다르게 된다 ( 김영상 , 1999). 강성지수의 산정은 식 (1) 과
같고 , 지반의 변형계수 ( E
50) 는 식 (2) 와 (3) 으로 산정하며 ,
식 (2) 는 삼축압축시험 ( UU ), 식 (3) 은 일축압축시험 ( q
u) 방법 이다 .
(1) (2)
(3)
여기서 ,
E : 지반의 변형계수 s
u: 비배수 전단강도 : 축차응력의 최대치 q
u: 일축압축강도
ε
50: 일 때의 변형률
Gupta(1983) 는 공동팽창이론을 이용하여 소성공동을 소성
영역을 둘러싸고 있는 교란되지 않은 탄성영역에 의하여 지 배되며 , 이 값이 소성영역의 크기를 결정짓는 중요한 요소이 므로 콘 시험결과 해석 시 탄성계수는 교란되지 않은 영역 의 초기 접선 탄성계수를 사용하는 것이 바람직하다고 하였 고 Robertson & Companella(1983) 는 탄성계수가 변형률 수준에 따라서 매우 크게 변화하므로 콘 주변의 복잡한 변 형률 장을 고려하여 중간 응력 수준의 비배수 할선 전단탄
성계수 ( G
50) 을 선택하는 것이 적절하다고 하였다 . Roy 등
(1982) 은 자연 점토가 교란된 후에는 전단 탄성계수가 50%
정도 감소된다는 기존의 시험결과를 바탕으로 직경 20cm 의 모형말뚝으로부터 관측된 간극수압과 공동팽창 이론을 비교 하여 콘 선단부에서는 초기 E값을 사용하고 콘 선단부 뒤에
서는 50% 감소된 E
50값을 사용하여야 한다고 하였으며 , 콘
선단부의 지반이 실제로 경험하는 응력과 다르므로 이 값의 사용에 주의하여야 함을 지적하였다 . 이상에서 살펴본 바와 같이 강성지수 산출에도 연구자마다 다르고 대상지반마다 달 라 각 조건에 맞는 해석법을 도출해야만 정확한 물성치를 결정할 수 있다 . 따라서 본 연구에서는 지반의 다변성을 충 분히 반영하면서 신뢰성 있는 강성지수 산정이 가능하도록 인공신경망이론의 적용성에 대하여 검토하였다 .
2.2 인공신경망
신경망이란 사고 , 학습인식 등 인간과 유사한 지능을 실현 하기 위해 인간의 뇌신경 조직을 모형화한 것으로 신호처리 ,
제어 , 패턴인식 , 의학 , 손상추정 등의 분야에 적용되고 있다 .
학습과 일반화의 두 가지 기능을 지니고 있는 신경망의 특 징은 연결가중치의 단계적 조정으로 수행된 학습을 통하여 신경망의 성능을 향상시키며 , 학습되지 않은 경우에 대해서 도 일반화된 기능을 이용하여 합리적인 해를 제공한다는 것 이다 . 본 연구에서는 신뢰할 수 있는 강성지수를 예측하기 위해 가장 일반적으로 사용하는 역전파 네트워크 모델을 사 용하였으며 , 이는 그림 2 와 같이 입력층과 은닉층 , 출력층으 로 구성된 다층구조이다 .
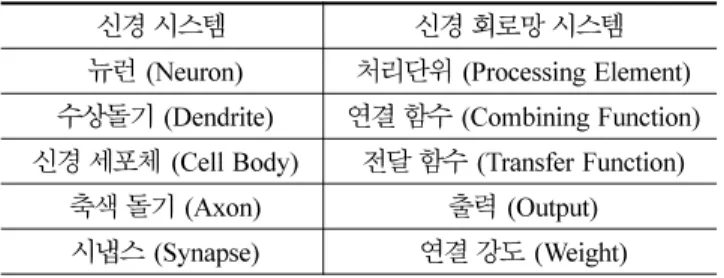
신경회로망모델의 기본 단위는 하나의 처리단위 (processing element) 로서 , 입력 (input), 연결강도 (weight), 전달함수 (transfer function), 출력 (output) 이라는 4 가지의 주요 부분으로 구성되 어 있다 . 인간의 신경시스템과 신경회로망모델을 비교하면 표 1 과 같다 .
입력을 통하여 정보가 처리단위에 들어오는데 , 정보의
Source 는 다른 처리 단위일수도 있고 외부일수도 있다 . 연결
강도는 어떤 정보의 입력이 그 처리 단위에 얼마나 영향을 미칠 것인가를 결정하고 한 처리단위로부터 다른 처리 단위 I
rG
s
u---- 3 --- E s
u= =
E
501 2--- ( σ
1– σ
3)
maxε
50---
=
E
501 2--- q
uε
50---
=
σ
1– σ
3( )
maxσ 1
2--- ( σ
1– σ
3)
max=
그림 1. 응력-변형률 곡선 그림 2. 신경망 모델
로 보내지는 신호의 강도는 연결강도에 의해 수정된다 . 연결 함수는 입력과 정보와 연결강도를 조합하는데 가장 일반적 인 연결함수는 Weighted Sum 의 형태를 취하는 것이다 . 전 달함수는 연결함수의 결과를 해석해서 그 처리단위의 출력 값을 결정한 후 출력값을 결정한다 . 전달함수에는 계단함수
(hard limiter), 임계논리 (threshold logic), S 자 형태의 시그 모이드 (sigmoid) 형 , 쌍곡탄젠트 (tanh) 등 ( 그림 3) 이 있으며 ,
그 중에서 가장 많이 쓰이는 것은 시그모이드 함수와 쌍곡 탄젠트함수이다 ( 김대수 , 2001). 처리단위의 출력은 전달함수 의 결과이며 , 하나의 처리단위에서 오직 하나의 출력 값만이
존재한다 . 하나 이상의 처리 단위들이 모여 층 (layer) 을 이루
는데 입력층 , 출력층 , 은닉층이 있다 . 3. 인공신경망 모델의 구축
인공신경망 모델의 구축과정은 크게 두 단계로 나눌 수 있으며 , 먼저 기지의 입력과 결과값을 이용하여 그림 1 과 같이 각 층 ( 입력층 , 은닉층 , 출력층 ) 에 존재하는 뉴런
(neuron) 간의 연결강도 (weight) 와 바이어스 (bias) 를 조정하는
훈련단계 (training phase) 로 이 과정을 통하여 신경망 모델은
주어진 자료들을 일반화할 수 있는 최적의 연결강도를 스스 로 학습하게 된다 . 다음은 훈련과정을 통하여 구축된 신경망 모델을 학습에 사용되지 않은 입력값을 이용하여 예측을 수 행하고 기지의 결과값과 비교함으로써 학습된 네트워크를 검
증하는 단계 (testing phase) 이다 . 이와 같이 검증된 후에야
학습뿐 아니라 검증단계에서도 전혀 사용되지 않은 자료를 인공신경망에 입력하고 예측을 수행함으로써 구축된 인공신 경망을 실제 사례에 사용할 수 있다 . 인공신경망 모델에서는 회귀분석과 같은 통계적 방법과 달리 사전에 어떠한 수학적 인 관계나 경향이 주어지지 않으며 훈련과정을 통하여 이러 한 관계를 스스로 학습하기 때문에 부여된 관계식에 따라
예측정도가 결정되는 기존 경험적 방법을 단점을 극복할 수 있다 ( 김영상 , 2004).
3.1 데이터베이스
인공신경망 모델의 구축을 위해서는 학습단계와 검증단계
( 교차검증세트와 시험세트 ) 에 사용될 신뢰성 있는 자료의 축 적이 요구된다 . 본 연구에서는 이미 발표된 연구논문 ( 박용
원 , 2003) 을 참조하여 국내 12 개 지역 ( 그림 4) 에서 채취된
불교란 시료에 대해 수행되어 얻어진 강성지수와 물성치 시 험결과 자료를 사용하였으며 , 인공신경망을 구축하였다 . 동 해안의 인공신경망모델에 사용된 전체자료는 12 개로 7 개의 자료만이 인공신경망모델구축을 위한 학습과정에 사용되었 으며 , 학습에 사용되지 않은 5 개의 자료를 구축된 인공신경 망의 검증·시험자료에 활용하였다 . 서해안은 57 개의 전체 자료 중 41 개의 학습자료 , 16 개의 검증자료로 남해안은 86
개의 전체자료 중 44 개의 학습자료 , 42 개의 검증자료로 사 용되었다 .
3.2 모델의 입력요소와 출력요소
본 연구 대상지반의 조사 및 시험결과에 근거하여 국내 지반의 강성지수와 공학적 특성 ( 깊이 , 비배수 전단강도 ,
OCR, 소성지수 ) 과의 관계를 나타낸 것이 그림 5 이다 . 그림
5(a) 를 보면 깊이와 강성지수는 뚜렷한 관계는 보이지 않으 표 1. 신경 시스템과 신경회로망 시스템의 비교(이진섭 등,
2003)
신경 시스템 신경 회로망 시스템
뉴런 (Neuron) 처리단위 (Processing Element)
수상돌기 (Dendrite) 연결 함수 (Combining Function)
신경 세포체 (Cell Body) 전달 함수 (Transfer Function)
축색 돌기 (Axon) 출력 (Output)
시냅스 (Synapse) 연결 강도 (Weight)
그림 3. 4가지 대표적인 비선형 함수
그림 4. 조사지역 위치도
나 대체로 깊이가 증가할수록 강성지수는 감소하는 추세를
보이고 있다 . 또한 , 그림 5(b) 에서 보는 바와 같이 비배수
전단강도 변화에 따라 일정한 추세로 변하지는 않았으나 대 체로 비배수 전단강도가 증가하면서 강성지수는 감소하는 경 향을 나타내고 있다 . 이와 같이 깊이와 비배수 전단강도가 증가함에 따라 강성지수가 감소하는 경향은 서수봉 등 (2000)
과 박용원 등 (2003) 이 국내 연약지반을 대상으로 강성지수에
대하여 연구한 결과와 비교해 볼때 거의 유사한 양상을 보
이고 있다 . 그리고 Ladd 등 (1977) 은 OCR 10 이하를 기준으
로 할때 OCR 이 증가함에 따라 강성지수는 크게 감소한다고 제안하였으나 그림 5(c) 를 보면 국내 연약지반의 경우 대부 분 4 이하의 낮은 OCR 을 나타내므로 OCR 에 따른 큰 변화
를 보이지는 않았다 . 다만 , OCR 증가에 따라 강성지수는
감소하는 양상을 보이고 있다 . 한편 , 그림 5(d) 에 나타낸 소
성지수와의 관계에서는 뚜렷한 경향을 보이지 않는다 . 이 자 료들과 민감도 분석결과를 바탕으로 깊이 , 비배수 전단강도
( s
u), OCR, 소성지수 (PI), 그리고 강성지수의 함수인 할선탄
성계수 ( E
50) 를 입력자료로 강성지수 ( I
r) 를 출력자료로 선택하 였다 . 하지만 연구과정에서 비배수 전단강도 ( s
u) 와 할선탄성
계수 ( E
50) 는 강성지수의 함수 ( I
r= G/s
u) 임으로 두 인자를 모두 선택하여 인공신경망을 구축을 하는 것은 의미가 없는 것으 로 판단하여 비배수 전단강도 ( s
u) 와 할선탄성계수 ( E
50) 를 분 리하여 인공신경망을 구축하였다 . 그 결과 비배수 전단강도
( s
u) 만을 입력자료로 포함하였을 때 인공신경망의 학습이 전 혀 이루어지지 않았고 , 할선탄성계수 ( E
50) 를 입력 자료로 선 택하였을 때 비교적 높은 강성지수 예측을 나타내었다 . 이
결과를 바탕으로 본 연구에서 사용될 입력자료로는 깊이 ,
OCR, 소성지수 (PI), 할선탄성계수 ( E
50) 로 결정하였으며 구간
별 값은 표 2~4 에 정리되어 있다 .
3.3 자료의 분할
보통 주어진 환경에서 신경망 모델의 예측을 평가하기 위 하여 주로 독립검증세트 (independent validation set) 와 신경
망 모델을 만들기 위한 훈련세트 (training set) 등 두 개의
하위세트 (sub set) 로 나누어 전체 데이터를 분할하여 사용한
그림 5. 국내 지반의 강성지수와 공학적 특성 관계(박용원, 2003)
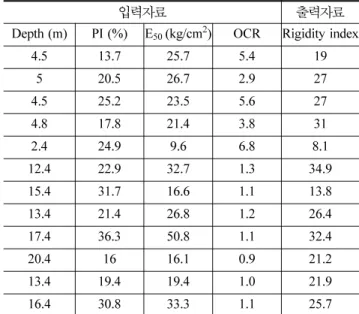
표 2. 동해안 데이터베이스
입력자료 출력자료
Depth (m) PI (%) E
50(kg/cm
2) OCR Rigidity index
4.5 13.7 25.7 5.4 19
5 20.5 26.7 2.9 27
4.5 25.2 23.5 5.6 27
4.8 17.8 21.4 3.8 31
2.4 24.9 9.6 6.8 8.1
12.4 22.9 32.7 1.3 34.9
15.4 31.7 16.6 1.1 13.8
13.4 21.4 26.8 1.2 26.4
17.4 36.3 50.8 1.1 32.4
20.4 16 16.1 0.9 21.2
13.4 19.4 19.4 1.0 21.9
16.4 30.8 33.3 1.1 25.7
다 . 그러나 단지 두 개의 하위세트로 분할한 데이터를 이용
한 신경망 모델은 과잉맞춤 (overfitting) 될 가능성이 높아
교차검증 (cross validation) 을 포함하도록 제안되고 있는데 ,
이 연구에서는 학습을 정지하기 위한 기준으로 교차검증이 사용되었다 . 이 연구에 사용된 전체데이터는 무작위로 훈련
세트 (training set), 교차검증세트 (cross validation set), 시험 세트 (testing set) 등 세 개의 세트 (sets) 로 나누어졌다 .
3.4 모델의 구성
지금까지 인공신경망 모델에 존재하는 은닉층의 수와 각 층에 존재하는 뉴런의 수를 결정하는 체계적인 방법은 확립 되어 있지 않으며 대부분 경험적인 반복법을 통하여 구축되 어져 왔다 . 따라서 같은 자료를 바탕으로 하더라도 모델 구 성자에 따라 인공신경망 모델의 구축 시 적용된 은닉층의 수와 은닉층 내의 뉴우런의 수 , 입력변수 , 사용된 전달함수 ,
훈련규칙과 최적화기법 , 수렴기준 등이 다르며 결과적으로 모델의 구성과 예측결과가 달라질 수 있다 . 본 연구에서는
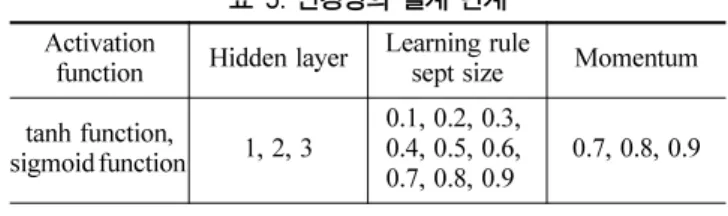
보다 신뢰성 있는 신경망 모델의 구축을 위하여 은닉층의 수와 은닉층에 존재하는 뉴런의 수 , 수렴규준 등을 변화시키 면서 관측된 강성지수와 가장 상관성이 높은 강성지수를 예 측하도록 모델을 구축하였으며 , 전달함수로는 쌍곡탄젠트함 수와 시그모이드함수가 사용되었다 .
본 연구에서 설계된 인공신경망의 모델 구축을 위한 조건 은 다음과 표 5 와 같다 .
3.5 학습규칙 및 학습기법
본 연구에서 구축된 모델은 AMD 64bit 3000+, 메모리
1GB 인 개인용 컴퓨터에 NeuroDimension 社에서 개발한 상
용소프트웨어인 NeuroSolutions
TMVersion 4.21 을 설치하여 시뮬레이션환경을 조성하였으며 , 다층퍼셉트론 (multilayer
perceptron) 모델을 사용하였다 . 학습규칙으로는 입력값과 결
과값의 비선형적인 관계를 구축하는 함수근사화에 매우 효 율적인 것으로 알려진 오차역전파 알고리즘이 사용되었으며 ,
학습규칙 규준은 식 (4) 와 같다 .
표 3. 서해안 데이터베이스
입력자료 출력자료 입력자료 출력자료
Depth (m) OCR E
50(kg/cm
2) PI (%) Rigidity index Depth (m) OCR E
50(kg/cm
2) E
50(kg/cm
2) Rigidity index
3.4 2.5 17.1 21.6 38 6.5 1.2 7.6 17.1 12.6
3.4 2.5 20.9 21.6 41 3.4 2.8 9.3 32.7 15.8
3.4 2.7 6.8 19.5 25 2.9 2.8 3.9 22.1 6.63
3.4 2.9 17.3 17.5 34 4.4 1.9 5.3 16.9 10.4
3.4 2.7 18.4 13.7 34 5.4 2.6 19.7 11.5 33.3
3.4 2.9 24.5 13.7 34 6.4 1.4 15.2 2.3 22.2
3.9 1.9 31.2 29 65 8.4 1.2 17.1 23.6 7.9
4.4 2.5 31.7 22.8 46 9.4 0.9 67.5 6.9 41.7
3.5 2.6 8.9 21.9 27 15 0.6 38.5 15 33.3
4.5 1.2 5.6 17.9 16.9 12.4 1.3 46.7 11.8 36.2
7.1 1.6 15 17 29.4 4.9 1.3 26 17 33.3
8.4 0.8 11.3 22.2 26.8 5.2 1.3 18.6 8.8 27.8
7.4 2.2 13 20.2 17.3 6.4 1.2 13 8.6 13.3
7.4 1.9 23.7 25 35.9 6.4 1.7 82.5 5.8 33.3
7.4 2.3 27.4 15.2 33.8 1.9 2.5 12.3 4.7 27.8
7.4 2.4 42.7 15.2 47.5 1.9 2.4 7 3.5 22.2
21 1.0 19.1 11.7 28.9 8 2.1 9.3 11.7 8.4
11 2.0 5.4 14.6 10.6 4 2.7 10.4 12.7 26.7
5 1.9 3.4 14.2 7.6 8 1.7 20 14.8 41.7
5 1.7 4.9 16.1 10.1 6 2.2 16.4 11 15.2
3.5 1.5 7.5 16.8 14.7 6 2.1 6 13.5 9.5
2 2.8 5.3 16.7 9.8 11 1.7 17.4 14.3 23.2
5 0.4 4.1 17 9.7 10 1.9 8.8 4.7 18.3
2 2.8 6.3 14.7 7.3 5 0.6 37.5 18.8 83.3
8 1.1 4.0 14.7 5.8 7 1.5 19 5.5 33.3
3.5 2.7 24.7 12.9 39.2 4.5 1.9 11.3 6.5 22.2
2 2.7 4.2 16 8.8 6 1.6 6.3 2.1 17.5
5 1.9 8.8 16 14.7 5 2.8 19 6.3 33.3
2 2.2 4.9 17.1 10.4 - - - - -
(4)
여기서 , MSE = 평균제곱오차 , Q = 학습에 사용된 전체자
료의 수 , e ( k )= t(k)-a(k) 목표값과 출력값의 차이로 오차를
의미한다 . 가중치 (weight) 와 바이어스 (bias) 를 최적화하기 위
한 성능함수 (performance function) 로는 식 (4) 와 같이 인공 신경망 모델이 제공하는 출력값 [ a ( k )] 과 관측값이 목표값
[ t ( k )] 으로 정의되는 평균제곱오차 (mean squared error, mse)
MSE 1 2---
ke k ( )
21
=