A study on a composite support vector quantile regression with varying coefficient model †
Insuk Sohn 1 · Jooyong Shim 2 · Kyungha Seok 3
1 Statistics and Data Center, Samsung Medical Center
23 Department of Statistics, Inje University
Received 1 June 2018, revised 25 June 2018, accepted 29 June 2018
Abstract
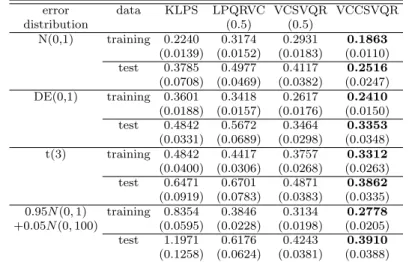
Varying coefficient models are widely used to explore dynamic patterns of regression parameters among regression models available to avoid the curse of dimensionality. In this paper we propose a new regression estimation of the varying coefficient composite support vector quantile regression which combines the formulations of the composite quantile regression and the varyng coefficient support vector quantile regression which is a nonparametric quantile regression with varying regression quantiles. We also consider a cross validation method for the optimal values of hyperparameters which affect the performance of the proposed method. Numerical studies with synthetic and real data are conducted to illustrate the performance of the proposed estimation of the regression functions.
Keywords: Composite quantile regression, cross validation function, quantile regression, support vector quantile regression, varying coefficient model.
1. Introduction
Koenker and Bassett (1978) introduced the quantile regression (QR), which is known as a useful and robust statistical methods for estimating and better statistical analysis of the relationships among variables included in the model. Applications of QR in many different areas include the medicines (Heagerty and Pepe, 1999), the survival analysis (Koenker and Geling, 2001; Shim and Hwang, 2009), and the growth chart (Wei and He, 2006).
Generally QR is less efficient than the least squares estimation when errors have a normal distribution. The composite QR (CQR) estimator for the classical linear model was proposed by Zou and Yuan (2008) to overcome the weakness of QR. The CQR estimator can be viewed
† This research was supported by Basic Science Research Program through the National Research Foun- dation of Korea(NRF) funded by the Ministry of Education (NRF-2015R1D1A1A01056582, NRF- 2017R1D1A1B03029792 and NRF-2017R1E1A1A01075541).
1
Senior Researcher, Statistics and Data Center, Samsung Medical Center, Seoul 06351, Korea.
2
Adjunct Professor, Institute of Statistical Information, Department of Statistics, Inje University, Gyungnam 50834, Korea.
3