A comparison study of multiple linear quantile regression using non-crossing constraints
Sungwan Bang
a· Seung Jun Shin
b,1a
Department of Mathematics, Korea Military Academy;
b
Department of Statistics, Korea University
(Received March 15, 2016; Revised May 31, 2016; Accepted July 6, 2016)
Abstract
Multiple quantile regression that simultaneously estimate several conditional quantiles of response given covariates can provide a comprehensive information about the relationship between the response and co- variates. Some quantile estimates can cross if conditional quantiles are separately estimated; however, this violates the definition of the quantile. To tackle this issue, multiple quantile regression with non-crossing constraints have been developed. In this paper, we carry out a comparison study on several popular methods for non-crossing multiple linear quantile regression to provide practical guidance on its application.
Keywords: multiple linear quantile regression, non-crossing, linear programming
1. 서론
제곱 손실함수를 이용한 최소제곱추정법(least squares estimation)과 같은 전통적인 회귀분석은 p차원 의 설명변수 x ∈ D ⊂ R
p가 주어졌을 때 반응변수 y ∈ R의 조건부 평균 함수(conditional mean func- tion)를 추정한다. 여기서 D는 설명변수의 정의역(domain)을 나타낸다. 반면에 Koenker와 Bassett (1978)에 의해 제안된 분위수 회귀모형(quantile regression)은 최소절대추정법(least absolute estima- tion) 을 일반화한 것으로 반응변수의 조건부 분위수 함수(conditional quantile function)을 추정함으 로써 반응변수의 조건부 분포에 대한 포괄적인 정보를 제공하는 이점을 지니고 있다. 분위수 회귀모형 은 회귀계수 추정의 강건성과 유용성을 바탕으로 의학 (Cole과 Green, 1992; Heagerty와 Pepe, 1999;
Hendricks 와 Koenker, 1992; Koenker와 Hallock, 2001), 생존분석 (Yang, 1999; Koenker와 Geling, 2001), 마이크로어레이 연구 (Wang과 He, 2007) 등 여러 다양한 분야에 적용되고 있다.
반응변수 y에 대한 100τ% 조건부 분위수 함수 q
τ(x) 는
inf P (y ≤ q
τ(x)|x) = τ, 단, 0 < τ < 1 (1.1) This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (NRF-2015R1C1A1A02036473) for S. Bang and (NRF-2015R1C1A1A01054913) for S.
Shin.
1
Corresponding author: Department of Statistics, Korea University, 145 Anam-ro 145, Seongbuk-Gu, Seoul
02841, South Korea. E-mail: [email protected]
와 같이 정의 되며, 본 논문에서는 다음과 같은 선형 분위수 함수를 가정한다.
q
τ(x) = x
Tβ
τ= β
0,τ+ x
1β
1,τ+ · · · + x
pβ
p,τ. (1.2) 이때 x = (1, x
1, . . . , x
p)
T이고 β
τ= (β
0,τ, β
1,τ, . . . , β
p,τ)
T이다. 개체수가 n인 훈련자료 {x
i, y
i}
ni=1가 주어졌을 때, 식 (1.2)를 활용한 선형 분위수 회귀모형은 회귀계수 벡터 β
τ에 대한 다음과 같은 최적화 문제로 정의된다.
β ˆ
τ= argmin
βτ
∑
n i=1(
y
i− x
Tiβ
τ)
, (1.3)
여기서 ρ
τ(t) = t(τ − I(t < 0))이며 체크(check) 손실함수라 부르며 τ의 값에 따라 그 형태가 변한다.
실제 분석에서는 반응변수의 조건부 분포에 대한 정보를 보다 자세히 얻기 위해, 여러 개의 분위수 함 수 q
τk(x) (k = 1, 2, . . . , K) 를 동시에 추정을 하는 경우가 흔히 발생한다. 식 (1.3)의 분위수 회귀모형 을 이용하여 각각의 분위수 함수들을 개별적로 추정하는 방법을 우선 고려할 수 있다. 하지만, 개별추정 의 문제점은 서로 다른 분위수 함수들의 추정치가 서로 교차할 가능성이 있다는 점이다. 이를 분위수 교 차(quantile crossing) 현상이라 하며, 이는 식 (1.1)의 조건부 분위수 함수의 정의에 모순된다. 분위수 교차는 훈련자료의 개체수가 작을수록 더 심각하게 발생되며, 추정된 분위수 함수의 해석을 어렵게 할 뿐만 아니라 예측력을 감소시킨다 (Koenker, 2005).
분위수 교차 현상을 해결하기 위하여, 비교차(non-crossing) 제약식(constraint)을 이용한 동시 추정 법(simultaneous estimation)에 관한 연구가 진행되었으며, 대표적인 비교차 다중 분위수 회귀모형의 연구에는 Takeuchi 등 (2006), Bondell 등 (2010), Liu와 Wu (2011) 등이 있다. Takeuchi 등 (2006)은 훈련자료에 기반을 둔 비교차 제약식을 적합식에 추가함으로써 서로 다른 τ값에 대하여 교차하지 않는 다중 분위수 함수 추정법을 제안하였다. Bondell 등 (2010)은 설명변수의 정의역이 컨벡스 헐(convex hull)임을 이용하여 각각의 꼭짓점(vertex)에서 분위수 함수들 간에 서로 교차하지 않도록 하는 제약식 을 제안하였으며, Liu와 Wu (2011)은 분위수 회귀모형의 회귀계수 벡터를 이용한 비교차 제약식을 제 안하였다. 이 외에도 비교차 분위수회귀모형으로 He (1997), Shim 등 (2009), Takeuchi와 Furuhashi (2004), 그리고 Wu와 Liu (2009) 등이 있다. He (1997)와 Shim 등 (2009)의 경우 location-scale 모형 만을 고려하였고, Takeuchi와 Furuhashi (2004)는 통상적인 분위수 체크 손실함수 대신 ϵ-강화 체크 손 실함수를 활용하였다. Wu와 Liu (2009)는 모수추정과 비교차 제약을 단계적으로 해결하는 방법을 제 시하였다.
비교차 제약식을 이용한 분위수 함수 추정법들은 각각의 장, 단점을 지니고 있으나, 이들의 특성들에 대 한 비교연구는 미흡한 실정이다. 본 논문에서는 앞서 언급한 여러 가지 비교차 분위수 회귀함수 추정방 법 중 Takeuchi 등 (2006), Bondell 등 (2010), Liu와 Wu (2011) 방법을 비교 분석하고자 한다. 이 세 가지 방법은 통상적인 분위수 선형회귀모형에 비교차를 위한 제약을 추가한 형태로, 제약이 없는 분위수 회귀모형과 비교하여 추가적인 가정을 필요로 하고 있지 않기 때문에 직접적인 비교가 가능하다.
논문의 구성은 다음과 같다. 2절에서는 비교차 제약식을 이용한 세 가지 동시 추정법들의 특성을 적합 식과 계산 알고리즘의 측면에서 살펴보았다. 3과 4절에서는 모의생성 자료와 실제 자료를 통해 기존의 개별적인 추정법과 세 가지 동시 추정법들의 성능을 비교분석하였다. 마지막으로 5절에서는 결론과 더 불어 차후 연구방향을 제시하였다.
2. 비교차 제약식을 이용한 다중 분위수 회귀모형
개체수가 n인 훈련자료 {x
i, y
i}
ni=1를 이용하여 다양한 τ값(0 < τ < 1)에 대한 100% 조건부 분위수 함
수들을 추정하기로 하자. 이때 분위수 회귀모형의 적합식 (1.3)을 이용하여 0 < τ
1< τ
2< · · · < τ
K<
1에 대한 분위수 함수들을 개별적으로 추정하면 추정된 분위수 함수들이 서로 교차할 가능성을 배제할 수 없다. 식 (1.1)에서 정의된 바와 같이 분위수 함수 q
τk(x) 는 이론적으로
q
τk+1(x) > q
τk(x) for k = 1, 2, . . . , K − 1 and ∀x ∈ D (2.1) 을 만족해야 한다. 분위수 함수의 교차현상은 추정의 정확도를 감소시킬 뿐만 아니라 추정된 회귀모형 의 해석을 어렵게 하는 것으로 알려져 있다.
다중 분위수 함수의 추정에서 교차현상을 해결하기 위해 비교차 제약식을 이용한 다중 분위수 회귀모 형(non-crossing multiple quantile regression; NMQR)이 연구되었으며, 이들의 기본적인 적합식은 다 음과 같다.
( β
τ1, . . . , β
τK)
N M QR= argmin
βτ1,...,βτK
∑
K k=1∑
n i=1ρ
τk(
y
i− x
Tiβ
τk)
, (2.2)
subject to x
Tβ
τk+1
> x
Tβ
τk
for k = 1, 2, . . . , K − 1 and ∀ x ∈ D ⊂ R
p. (2.3) 비교차 제약식을 추가함으로써 추정된 K개의 서로 다른 분위수 함수들이 교차하는 것을 방지한다. 본 절에서는 Takeuchi 등 (2006), Bondell 등 (2010), Liu와 Wu (2011)에 의해 제안된 비교차 제약식의 특 성과 계산 알고리즘을 살펴보고 이들을 비교분석하기로 한다. 각각의 방법론에 대한 세부적인 R 코드 는 차후 다양한 자료 분석과 새로운 방법론의 개발을 위해 요청 시 제공토록 할 것이다.
2.1. Takeuchi 등 (2006)의 방법: NMQR 1
서로 교차하지 않은 다중 분위수 함수의 추정을 위하여 Takeuchi 등 (2006)은 훈련자료에 기반한 비교 차 제약식을 식 (2.2)의 동시 추정 적합식에 추가하는 추정법을 고려하였다. 다시 말해, 관측된 n개의 개체 {x}
ni=1에 대하여 식 (2.3)의 비교차 조건을 만족하도록 하는 제약식을 제안하였으며, 그 적합식은
( β ˆ
τ1, . . . , ˆ β
τK
)
N M QR1= argmin
βτ1,...,βτK
∑
K k=1∑
n i=1ρ
τk(
y
i− x
Tiβ
τk
) ,
subject to x
Tβ
τk+1> x
Tβ
τkfor k = 1, 2, . . . , K − 1 and i = 1, 2, . . . , n (2.4) 와 같다. 여기서는 Takeuchi 등 (2006)의 비교차 동시 추정법을 NMQR 1이라 하겠다.
비교차 제약식 (2.4)를 이용한 NMQR 1의 최적화 문제는 선형계획법(linear programming)으로 공식 화 될 수 있다. 이를 위하여 y
i−β
0,τk− ∑
pj=1
x
ijβ
j,τk= u
ik−v
ik를 만족하는 2nK개의 잉여변수(slack variable) {(u
ik, v
ik), i = 1, . . . , n, k = 1, . . . , K}를 사용하고, 설명변수를 β
jk= β
jk+− β
jk−와 같이 표 기하기로 하자. 이때 u
ik≥ 0, v
ik≥ 0, β
jk+≥ 0, β
jk−≥ 0이다. 이와 같은 새로운 변수들을 이용하면 NMQR 1 의 계산 알고리즘은 다음과 같이 선형계획법으로 공식화 된다.
min
∑
K k=1∑
n i=1(τ
ku
ik+ (1 − τ
k)v
ik) (2.5)
subject to β
0,τ+k−β
0,τ−k+
∑
p j=1x
ij( β
+j,τk−β
j,τ−k) +u
ik−v
ik= y
ifor all 1≤k ≤K and 1≤i≤n (2.6) (
β
+0,τk+1−β
−0,τk+1+
∑
p j=1x
ij(
β
j,τ+k+1−β
j,τ−k+1)) − (
β
+0,τk−β
−0,τk+
∑
p j=1x
ij( β
j,τ+k−β
−j,τk) )
≥0
for all 1 ≤ k ≤ K − 1 and 1 ≤ i ≤ n (2.7) β
jk+≥ 0, β
−jk≥ 0, u
ik≥ 0, v
ik≥ 0 for all 1 ≤ k ≤ K, 1 ≤ i ≤ n and 0 ≤ j ≤ p. (2.8) Takeuchi 등 (2006)에 의해 제안된 비교차 제약식 (2.4)는 계산 알고리즘에서 (2.7)로 표현되어지며 이는 매우 직관적인 방법으로 선형함수의 추정에서 뿐만 아니라 비선형 분위수 함수의 추정 (Li 등, 2007) 에서도 쉽게 적용할 수 있다. 그러나 비교차 제약식 (2.4)는 주어진 훈련자료의 설명변수 x
i∈ D (i = 1, 2, . . . , n) 에서는 각각의 분위수 함수들 간의 비교차를 보장하지만, 설명변수의 정의역 전체구간 D에 대하여 비교차를 보장하지는 못한다. 다시 말해, 관측된 훈련자료로부터 멀리 있는 설명변수의 구 간에 대해서는 추정된 분위수 함수들이 서로 교차할 가능성이 여전히 존재한다.
2.2. Bondell 등 (2010)의 방법: NMQR 2
K 개의 선형 분위수 함수들이 식 (2.3)의 비교차 조건을 만족하게 하기 위하여 Bondell 등 (2010)은 설 명변수의 정의역이 컨벡스 헐임을 이용하여 모든 꼭짓점 {x
l}
Nl=1에서 분위수 함수들 간에 서로 교차하 지 않도록 하는 제약식을 제안하였다. 이때 c
l≥ 0 (l = 1, 2, . . . , N)이고 ∑
Nl=1
c
l= 1이라고 하면 설명 변수의 정의역에 해당하는 모든 관측값들은 ∑
Nl=1
c
lx
l으로 표현된다. 따라서 제약식 x
Tlβ
τk
≤ x
Tlβ
τk+1
for k = 1, 2, . . . , K − 1 and l = 1, 2, . . . , N (2.9) 을 만족하면 설명변수의 임의의 영역에 대하여 비교차의 조건 식 (2.3)을 만족하게 된다.
비교차 제약식 (2.9)의 계산 효율을 높이기 위해 Bondell 등 (2010)은 가역(invertible) 아핀변환(affine transformation) 을 통해 관심 있는 정의역을 닫힌 폐구간(closed bounded interval) D = [0, 1, ]
p으로 변환하고, 새로운 잉여변수 α
+j,k≥ 0와 α
−j,k≥ 0를 사용하여
β
j,τk+1− β
j,τk= α
+j,k− α
−j,kfor k = 1, 2, . . . , K − 1 and j = 1, 2, . . . , p 와 같이 회귀계수들을 재매개화(reparametrization)하였다. 이를 통해 비교차 제약식 (2.9)는
β
0,τk+1− β
0,τk−
∑
p j=1α
−j,kfor k = 1, 2, . . . , K − 1 와 같이 표현 가능하며, Bondell 등 (2010)은 비교차 다중 분위수 회귀모형의 적합식을
( β ˆ
τ1, . . . , ˆ β
τK)
N M QR2= argmin
βτ1,...,βτK
∑
K k=1∑
n i=1ρ
τk(
y
i− x
Tiβ
τk)
subject to β
j,τk+1− β
j,τk= α
+j,k− α
−j,kfor k = 1, 2, . . . , K − 1 and j = 1, 2, . . . , p (2.10) β
0,τk+1− β
0,τk−
∑
p j=1α
−j,k≥ 0 for k = 1, 2, . . . , K − 1 (2.11) α
+j,k≥ 0, α
−j,k≥ 0 for k = 1, 2, . . . , K − 1 and j = 1, 2, . . . , p (2.12) 와 같이 제안하였다. Bondell 등 (2010)의 비교차 동시 추정법을 NMQR 2라 하겠다.
NMQR 1에서처럼 NMQR 2의 계산 알고리즘도 선형계획법으로 공식화 될 수 있다. 즉, NMQR 2의 적합식은 다음과 같이 선형계획법(linear programming)으로 공식화 된다.
min
∑
K k=1∑
n i=1(τ
ku
ik+ (1 − τ
k)v
ik)
subject to β
0,τ+k− β
0,τ−k+
∑
p j=1x
ij( β
+j,τk
− β
j,τ−k) + u
ik− v
ik= y
ifor all 1 ≤ k ≤ K and 1 ≤ i ≤ n (
β
+j,τk+1− β
j,τ−k+1) − (
β
j,τ+k− β
j,τ−k) = α
+j,k− α
−j,kfor k = 1, 2, . . . , K − 1 and j = 1, 2, . . . , p (
β
+j,τk+1− β
j,τ−k+1) − (
β
j,τ+k− β
j,τ−k) −
∑
p j=1α
−j,k≥ 0 for k = 1, 2, . . . , K − 1
β
j,τ+k≥0, β
−j,τk≥0, u
ik≥0, v
ik≥0, α
+j,k≥0, α
−j,k≥0 for all 1 ≤k ≤ K, 1≤i ≤ n, 0≤j ≤ p.
재매개화를 통한 제약식 (2.11)은 비교차의 필요충분조건을 만족하는 제약식 (2.9)와 동일한 표현이므 로, 설명 변수의 받침(support)가 D = [0, 1]
p이라는 가정 하에서, 비교차에 대한 필요충분조건을 만족 한다. 더불어 비교차를 위한 제약식의 수가 K − 1개이므로 선형계획법의 계산 알고리즘 측면에서도 매 우 효율적이다. Bondell 등 (2010)은 스플라인 기법 (Koenker 등, 1994)을 이용하여 비교차의 제약식 을 비선형 분위수 함수의 동시 추정에도 적용하였다. 그러나 비교차 제약식 (2.11)은 커널(kernel)을 이 용한 비선형 분위수 함수의 추정 Li 등 (2007)에는 직접적인 적용이 불가능하다.
2.3. Liu 와 Wu (2011)의 방법: NMQR 3
설명변수의 정의역을 D = [0, ∞]
p라고 가정하자. Liu와 Wu (2011)는 이와 같은 가정 하에서 식 (1.2)의 회귀계수에 대하여 비교차 제약식을
β
j,τk+1≥ β
j,τkfor k = 1, 2, . . . , K − 1 and j = 1, 2, . . . , p 와 같이 제안하였으며, 이를 이용한 비교차 다중 분위수 회귀모형의 적합식은
( β ˆ
τ1, . . . , ˆ β
τK
)
N M QR3= argmin
βτ1,...,βτK
∑
K k=1∑
n i=1ρ
τk(
y
i− x
Tiβ
τk
)
subject to β
j,τk+1≥ β
j,τkfor k = 1, 2, . . . , K − 1 and j = 0, 1, 2, . . . , p (2.13) 와 같다. 여기서는 Liu와 Wu (2011)의 비교차 동시 추정법을 NMQR 3이라 하겠다.
다른 방법론에서와 마찬가지로 선형 분위수 함수의 동시 추정을 위한 NMQR 3의 계산 알고리즘은 다음 과 같이 선형계획법으로 공식화 된다.
min
∑
K k=1∑
n i=1(τ
ku
ik+ (1 − τ
k)v
ik) subject to
β
0,τ+k− β
0,τ−k+
∑
p j=1x
ij( β
j,τ+k− β
j,τ−k) + u
ik− v
ik= y
ifor all 1 ≤ k ≤ K and 1 ≤ i ≤ n (
β
+j,τk+1− β
−j,τk+1) − (
β
j,τ+k− β
j,τ−k) ≥ 0 for k = 1, 2, . . . , K − 1 and j = 0, 1, 2, . . . , p
β
j,τ+k≥ 0, β
j,τ−k≥ 0, u
ik≥ 0, v
ik≥ 0 for all 1 ≤ k ≤ K, 1 ≤ i ≤ n, 0 ≤ j ≤ p.
Liu 와 Wu (2011)의 비교차 제약식 (2.13)은 매우 직관적인 방법으로 커널(kernel)을 이용한 비선형
분위수 함수의 추정 (Li 등, 2007)에 직접적으로 적용가능하다. 설명변수의 받침이 D = [0, ∞]
p인
Table 2.1. Comparison for different NMQR methods
방법 설명변수의 받침에 대한 가정 비교차 제약의 영역 비선형 커널 확장
NMQR 1 없음 관측된 훈련자료 점 가능
NMQR 2 양의 유계영역, [0, M]
pfor some M < ∞ [0, M ]
p불가능
NMQR 3 양의 비유계영역, [0, ∞)
p[0, ∞)
p가능
선형 분위수 회귀모형에서는, 이 제약식이 분위수 함수들의 비교차에 대한 필요충분조건이 됨을 알 수 있다 (Liu와 Wu, 2011, Proposition 3). 하지만 실제자료 분석에서 관심 있는 받침의 영역이 유 계(bounded)인 경우가 일반적이다. 따라서 비유계(unbounded) 구간인 받침의 모든 영역에서 교차가 일어나지 않도록 하는 것은 매우 강한 조건이다. 때문에 비교차 제약식 (2.13)은 설명변수의 관측값이 커짐에 따라 분위수 함수들의 간격이 넓어지는 것은 허용하지만 좁아지는 것을 제약하고 있다. 이는 실 제자료의 분석에는 너무 강한 조건이 될 수 있으며, 분위수 함수의 추정에 왜곡을 발생시킬 수 있다.
2.4. 방법 간 비교 요약
본 논문에서 고려하고 있는 세가지 비교차 선형 분위수 회귀모형은 선형계획법의 형태로 공식화 될 수 있다. 차이점은 설명변수의 받침에 대한 가정과 비교차의 제약을 가하는 영역에 있다. NMQR 1의 경 우 독립변수의 받침에 대한 가정은 없지만, 관측된 훈련표본들의 비교차만을 보장한다. NMQR 2와 NMQR 3 의 경우, 관심 있는 모든 설명변수 영역에 대해 비교차를 보장한다. 하지만, NMQR 2의 경 우 관심영역 혹은 설명변수의 받침이 반드시 유계 폐구간으로 표현 되어야한다는 가정이 필요하다. 이 론적으로는 매우 강한 조건으로 보이지만, 통상적인 회귀모형이 외삽(extrapolation)을 허용하지 않는 다는 점을 고려할 때 타당한 가정이라 하겠다. NMQR 3은 관심영역이 양의 비유계구간이라고 가정하 고, 이 모든 영역에서 비교차를 제약한다. 선형 모형 가정하에서는, NMQR 3이 NMQR 2보다 이론적 으로 더 타당하지만, 실제 분석에서는 훈련자료와 전혀 상관없는 영역의 비교차를 제약하기 위해, 관측 자료 주변의 영역에 대해서 지나친 제약을 가하는 것이 단점으로 작용할 수 있다 (3.3절 참조). 마지막 으로, NMQR 1와 NMQR 3은 커널을 이용한 비선형으로의 확장이 용이한 반면, NMQR 2는 그렇지 않 다 (Table 2.1).
3. 모의실험
비교차 다중 분위수 함수의 동시 추정에서 제안된 NMQR의 세 가지 방법론들을 비교하기 위하여 모의 실험을 진행하였다. 본 논문에서는 선형 회귀모형
y = 1 + x
1+ x
2+ x
3+ x
4+ x
5+ σ(x)ϵ (3.1) 을 고려하였으며, 설명변수 x
j(j = 2, . . . , 5)는 균등분포 U(0, 1)를, 오차항 ϵ은 표준정규분포 N(0, 1)를 따르는 것으로 가정하였다. 이때 세 방법론의 특성을 살펴보기 위하여 x
1의 확률분포와 σ(x)의 세 가지 조합
1) x
1∼U(0, 1), σ(x)=1, 2) x
1∼Exp(1), σ(x)=1, 3) x
1∼U(0, 1), σ(x)= 0.2+ 0.1
x
2+0.1 (3.2)
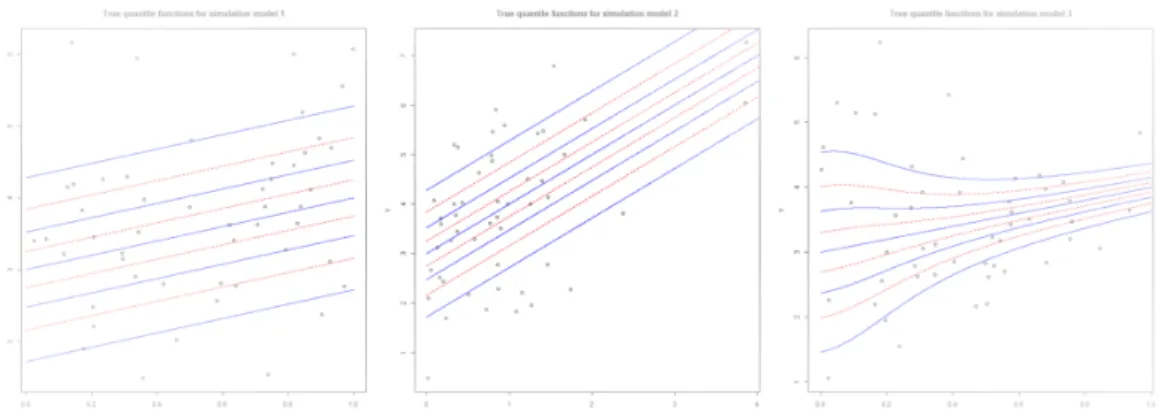
에 대하여 모의실험을 진행하였다. 여기서 Exp(1)은 모수 λ = 1인 지수분포를 의미한다. Figure 3.1은
설명변수 x
j(j = 2, 3, 4, 5) 를 중앙값에 고정하고 실제 분위수 함수를 x
1에 대하여 적합한 결과를 나타
내고 있다. 이때 좌측 패널과 중앙 패널은 각각 분위수 함수들이 서로 평행한 1)과 2)의 경우에 해당하
Figure 3.1. The true quantile functions for model 1–3 (left to right). The solid lines represent the quantile functions at τ = 0.1, 0.3, 0.5, 0.7, 0.9 and the dashed lines represent the quantile functions at τ = 0.2, 0.4, 0.6, 0.8.
며, 우측 패널은 분위수 함수들이 완전한 선형의 형태는 아니지만 x
1의 값이 커짐에 따라 분위수 함수들 의 폭이 좁아지는 형태를 나타내고 있다.
모의실험을 통하여 각 방법론들의 성능을 분위수 함수들의 교차현상과 추정의 정확도 측면에서 비교분 석하였다. 모형적합을 위해 크기가 50인 훈련자료를 생성하였으며, 모형의 평가를 위해 크기가 1,000인 평가자료를 독립적으로 생성하였다. 서로 다른 K = 9개의 τ
k= 0.1k (k = 1, 2, . . . , 9)에서 선형 분위 수 함수 q
τk(x) 를 추정하였으며, 방법론들의 정확도를 평가하기 위하여 평가자료를 이용한 평균절대오 차(mean absolute error; MAE)
MAE
τk= 1 1, 000
1,000
∑
i=1
|q
τk(x
i) − ˆq
τk(x
i)| (3.3)
를 계산하였다. 또한 이러한 절차를 100회 독립 반복시행 하였으며, 각각의 표에는 이들의 평균과 표준 편차를 제시하였다.
3.1. 실험모형 1: x
1∼ U(0, 1), σ(x) = 1인 경우
실험모형 1에서는 먼저 설명변수 x
1을 균등분포 U(0, 1)를 따르게 하고 σ(x) = 1로 하여 등분산성을 만 족하는 일반적인 경우에 대하여 다루었으며, 세 가지 비교차 동시 추정법 NMQR 1, 2, 3의 성능을 확 인하기 위하여 분위수 함수들을 개별적으로 추정하는 분위수 회귀모형(QR)을 모의실험에 포함하였다.
Table 3.1 은 각각의 방법론에 대한 평균절대오차를 나타내고 있다. 비교차 제약식을 이용한 NMQR 방 법들이 개별적으로 추정하는 QR 방법에 비해 추정의 정확도가 매우 높은 것을 알 수 있다. 특히 분위수 의 값이 양 극단으로 갈수록 개별추정에 비해 NMQR의 성능이 보다 안정적임을 확인할 수 있으며, 필 요충분조건을 만족하는 NMQR 2와 3의 성능이 NMQR 1에 비해 우수함을 알 수 있다. Figure 3.2는 각각의 방법론들로부터 추정된 분위수 함수들을 나타내고 있으며, 이때 설명변수 x
j(j = 2, . . . , 5) 는 중 앙값에 고정하였다. Figure 3.2로부터 QR의 분위수 함수들은 서로 교차되게 추정되는 반면에 NMQR 방법들은 서로 교차하지 않는 분위수 함수들을 추정함을 알 수 있다.
3.2. 실험모형 2: x
1∼ Exp(1), σ(x) = 1인 경우
실험모형 2에서는 설명변수 x
1을 모수 λ = 1인 지수분포 Exp(1)를 따르게 하여 훈련자료에서 관측이
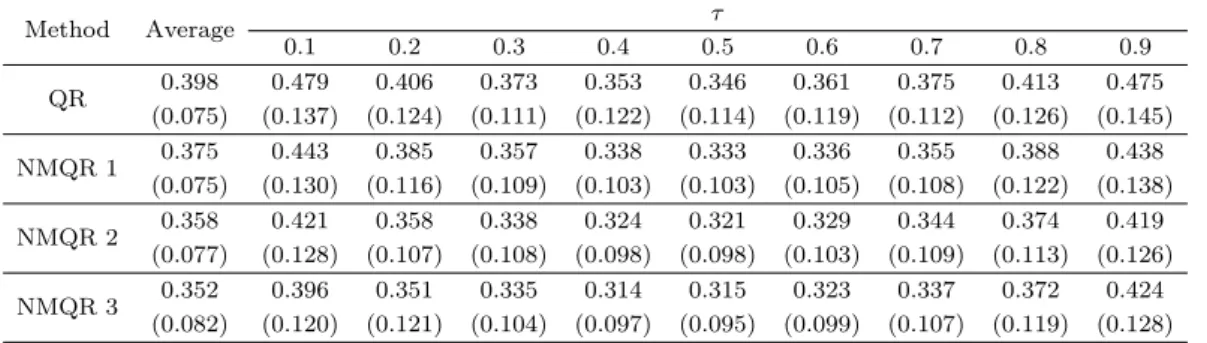
Table 3.1. Mean absolute errors for simulation model 1
Method Average τ
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
QR 0.398 0.479 0.406 0.373 0.353 0.346 0.361 0.375 0.413 0.475 (0.075) (0.137) (0.124) (0.111) (0.122) (0.114) (0.119) (0.112) (0.126) (0.145) NMQR 1 0.375 0.443 0.385 0.357 0.338 0.333 0.336 0.355 0.388 0.438
(0.075) (0.130) (0.116) (0.109) (0.103) (0.103) (0.105) (0.108) (0.122) (0.138) NMQR 2 0.358 0.421 0.358 0.338 0.324 0.321 0.329 0.344 0.374 0.419
(0.077) (0.128) (0.107) (0.108) (0.098) (0.098) (0.103) (0.109) (0.113) (0.126) NMQR 3 0.352 0.396 0.351 0.335 0.314 0.315 0.323 0.337 0.372 0.424
(0.082) (0.120) (0.121) (0.104) (0.097) (0.095) (0.099) (0.107) (0.119) (0.128) The numbers in parentheses are standard deviations.
Figure 3.2. The estimated quantile functions by QR(top left panel), NMQR 1(top right panel), NMQR 2(bottom left panel), and NMQR 3(bottom right panel) for simulation model 1. The solid lines represent the quantile functions at τ = 0.1, 0.3, 0.5, 0.7, 0.9 and the dashed lines represent the quantile functions at τ = 0.2, 0.4, 0.6, 0.8.
되지 않은 설명변수의 구간에 대하여 NMQR 방법론들의 성능을 살펴보고자 하였다. Table 3.2는 각각
의 방법론에 대한 평균절대오차를 나타내고 있으며, 이러한 결과는 실험모형 1과 유사하다. Figure 3.3
은 각각의 방법론들로부터 추정된 분위수 함수들을 나타내고 있으며, 이로부터 NMQR 1의 경우 훈련자
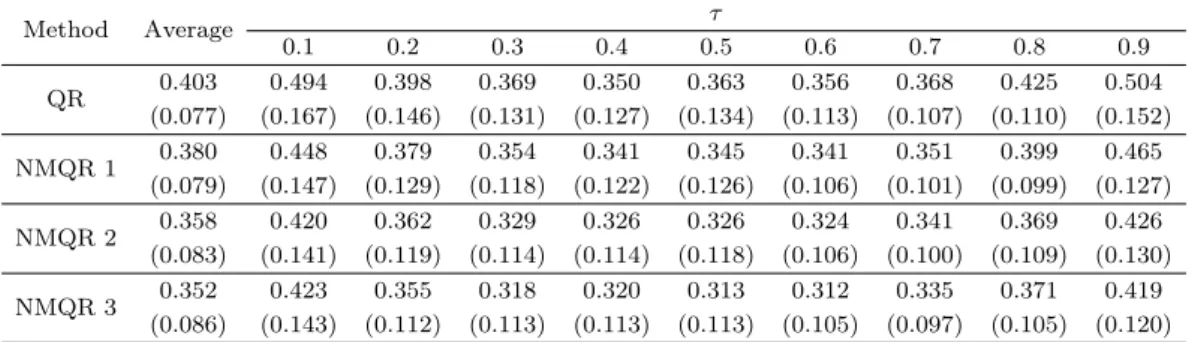
Table 3.2. Mean absolute errors for simulation model 2
Method Average τ
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
QR 0.403 0.494 0.398 0.369 0.350 0.363 0.356 0.368 0.425 0.504 (0.077) (0.167) (0.146) (0.131) (0.127) (0.134) (0.113) (0.107) (0.110) (0.152) NMQR 1 0.380 0.448 0.379 0.354 0.341 0.345 0.341 0.351 0.399 0.465
(0.079) (0.147) (0.129) (0.118) (0.122) (0.126) (0.106) (0.101) (0.099) (0.127) NMQR 2 0.358 0.420 0.362 0.329 0.326 0.326 0.324 0.341 0.369 0.426
(0.083) (0.141) (0.119) (0.114) (0.114) (0.118) (0.106) (0.100) (0.109) (0.130) NMQR 3 0.352 0.423 0.355 0.318 0.320 0.313 0.312 0.335 0.371 0.419
(0.086) (0.143) (0.112) (0.113) (0.113) (0.113) (0.105) (0.097) (0.105) (0.120) The numbers in parentheses are standard deviations.
Figure 3.3. The estimated quantile functions by QR(top left panel), NMQR 1(top right panel), NMQR 2(bottom left panel), and NMQR 3(bottom right panel) for simulation model 2. The solid lines represent the quantile functions at τ = 0.1, 0.3, 0.5, 0.7, 0.9 and the dashed lines represent the quantile functions at τ = 0.2, 0.4, 0.6, 0.8.
료의 관측이 희박한 곳에서는 여전히 교차현상이 발생 가능함을 알 수 있다. 반면에 비교차에 대한 필요
충분조건을 만족하는 NMQR 2와 3의 방법론은 서로 교차하지 않는 분위수 함수들을 추정하는 것을 확
인할 수 있다.
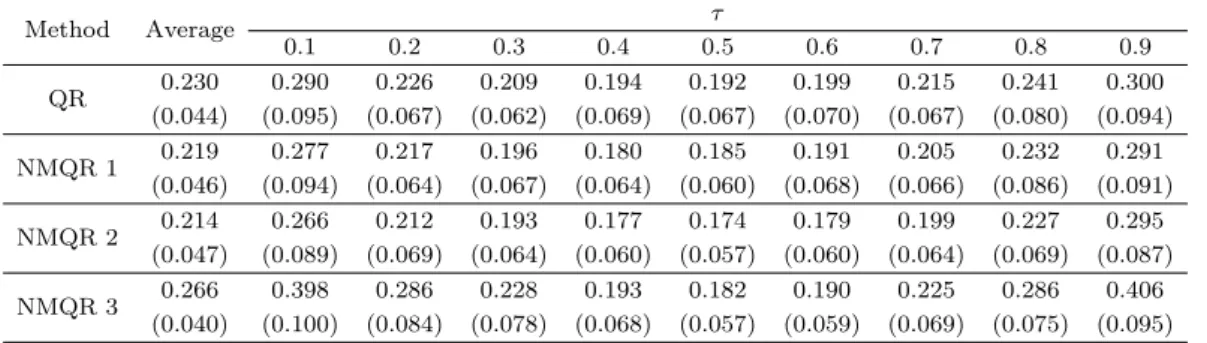
Table 3.3. Mean absolute errors for simulation model 3
Method Average τ
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
QR 0.230 0.290 0.226 0.209 0.194 0.192 0.199 0.215 0.241 0.300 (0.044) (0.095) (0.067) (0.062) (0.069) (0.067) (0.070) (0.067) (0.080) (0.094) NMQR 1 0.219 0.277 0.217 0.196 0.180 0.185 0.191 0.205 0.232 0.291
(0.046) (0.094) (0.064) (0.067) (0.064) (0.060) (0.068) (0.066) (0.086) (0.091) NMQR 2 0.214 0.266 0.212 0.193 0.177 0.174 0.179 0.199 0.227 0.295
(0.047) (0.089) (0.069) (0.064) (0.060) (0.057) (0.060) (0.064) (0.069) (0.087) NMQR 3 0.266 0.398 0.286 0.228 0.193 0.182 0.190 0.225 0.286 0.406
(0.040) (0.100) (0.084) (0.078) (0.068) (0.057) (0.059) (0.069) (0.075) (0.095) The numbers in parentheses are standard deviations.
Figure 3.4. The estimated quantile functions by QR(top left panel), NMQR 1(top right panel), NMQR 2(bottom left panel), and NMQR 3(bottom right panel) for simulation model 3. The solid lines represent the quantile functions at τ = 0.1, 0.3, 0.5, 0.7, 0.9 and the dashed lines represent the quantile functions at τ = 0.2, 0.4, 0.6, 0.8.
3.3. 실험모형 3: x
1∼ U(0, 1), σ(x) = 0.2 + 0.1/(x
2+ 0.1) 인 경우
실험모형 3에서는 설명변수들의 값이 커짐에 따라 분위수 함수들의 폭이 좁아지는 형태를 나타내기 위
하여 σ(x) = 0.2 + 0.1/(x
2+ 0.1) 으로 하여 이분산성 회귀모형을 고려하였다. Figure 3.1에서 보는
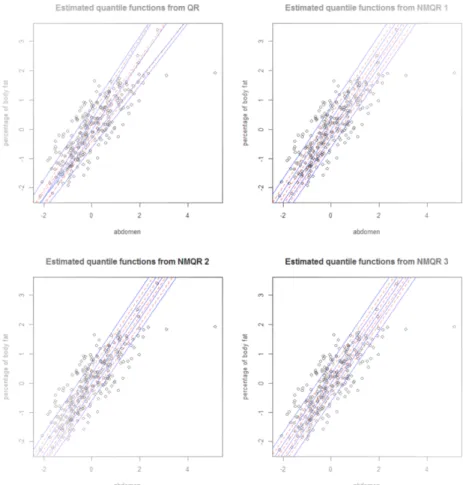
Figure 4.1. The estimated quantile functions by QR(top left panel), NMQR 1(top right panel), NMQR 2(bottom left panel), and NMQR 3(bottom right panel) for body fat data. The solid lines represent the quantile functions at τ = 0.1, 0.3, 0.5, 0.7, 0.9 and the dashed lines represent the quantile functions at τ = 0.2, 0.4, 0.6, 0.8.
바와 같이 분위수 함수가 비선형임을 유의하자. Table 3.3은 각각의 방법론에 대한 평균절대오차를 나 타내고 있으며, 예상했던 바와 같이 NMQR 3의 성능이 개별적으로 추정한 QR의 성능보다도 더 떨 어짐을 알 수 있다. 이러한 현상은 NMQR 3의 비교차 제약식 (2.13)이 분위수 함수들의 폭이 좁아지 지 못하도록 제약함으로써 추정에서 왜곡이 발생하였기 때문이다. Figure 3.4를 보면 QR, NMQR 1, NMQR 2 방법론의 경우에는 x
1의 값이 커짐에 따라 분위수 함수들의 폭이 좁아지는 경향을 유지하는 반면에 NMQR 3은 분위수 함수들을 서로 평행되게 추정함으로써 실제 분위수 함수들의 패턴을 왜곡하 여 추정함을 알 수 있다.
4. 실제자료 분석
본 절에서는 비교차 다중 분위수 함수의 세 가지 동시 추정법 NMQR 1, 2, 3과 개별적으로 분위수 함수
들을 추정하는 QR 방법을 이용하여 Johnson (1996)의 체지방 자료(body fat data)를 분석하였다. 이
때 체지방률을 반응변수로 사용하였으며, 설명변수로는 나이, 키, 몸무게와 더불어 10가지 신체둘레(목,
Table 4.1. Mean prediction errors and pairwise t-test results for body fat data
Method Mean prediction error p-values for pairwise t-test
QR NMQR 1 NMQR 2 NMQR 3
QR 0.1768
- 3.23e −12 <2.2e −16 <2.2e −16 (0.0115)
NMQR 1 0.1756
- <2.2e −16 1.579e −12 (0.0118)
NMQR 2 0.1730
- 0.3584
(0.0120)
NMQR 3 0.1732
(0.0123) -
The numbers in parentheses are standard deviations.
가슴, 복부, 엉덩이, 허벅지, 무릎, 발목, 이두근, 팔뚝, 팔목)를 사용하였다. 반응변수와 모든 설명변수 들은 표준화하였으며, 서로 다른 K = 9개의 τ
k= 0.1k (k = 1, 2, . . . , 9)에서 선형 분위수 함수를 추정 하였다.
Figure 4.1은 각각의 방법론으로부터 추정된 분위수 함수들을 복부 둘레에 대하여 적합한 결과를 나 타내고 있으며, 이때 나머지 설명변수들은 중앙값에 고정하였다. Figure 4.1로부터 QR 방법에 의해 개별적으로 추정된 분위수 함수들은 서로 교차하는 반면에, 비교차의 제약식 하에서 동시에 추정된 NMQR의 분위수 함수들은 서로 교차하지 않는 것을 확인할 수 있다. 특히 체지방 자료의 분석에서 는 세 가지 NMQR 방법들이 매우 유사한 추정 결과를 제공하고 있음을 알 수 있다.
나아가, 추정의 정확도 측면에서 방법론들을 비교하기 위하여 전체 체지방 자료를 2대 1의 비율로 훈 련자료와 평가자료로 랜덤하게 나눈 후, 훈련자료로 모형을 적합하고 평가자료를 이용하여 평균예측오 차(mean prediction error; MPE)
MPE = 1 n
0K
∑
K k=1n0
∑
i=1
ρ
τk(q
τk(x
i) − ˆq
τk(x
i))
를 계산하였다. 여기서 n
0는 평가자료의 관측수를 나타낸다. 이러한 절차를 독립적으로 100번 반복시 행 하였으며, Table 4.1에는 각각의 방법론에 대한 평균예측오차의 평균과 표준편차, 그리고 쌍체 t-검 정의 결과가 제시되어 있다. 이로부터 NMQR의 방법들이 QR의 방법에 비해 더 정확한 추정을 하고 있는 것을 확인할 수 있다. 또한 NMQR 방법론들 중에서는 NMQR 2와 3의 성능이 NMQR 1보다 더 우수함을 알 수 있다.
5. 결 론
본 연구에서는, 다중 비교차 분위수 회귀 모형의 대표적인 추정방법들의 특성을 적합식과 계산 알고 리즘의 측면에서 살펴보고, 모의실험과 실제자료 분석을 통해 그 성능을 비교하였다. 비교 실험 결과 Bondell 등 (2010)이 제안한 방법이 선형회귀 모형 하에서는 가장 안정적인 성능을 보여주었다. Liu와 Wu (2011)의 방법의 경우, 비교차 제약식의 형태가 비교적 단순하지만 줄어드는 형태의 이분산이 존재 하는 경우 왜곡된 결과를 제공한다.
분위수 교차는 비모수적 분위수 회귀(nonparameteric quantile regression)에서 보다 흔히 발생하는 문
제이다. 비모수적 분위수 회귀의 대표적인 방법으로는 커널 분위수 회귀를 예로 들 수 있는데, Bondell
등 (2010)의 방법은 커널을 이용한 확장이 용이하지 않다. 반면 Liu와 Wu (2011)의 방법은 커널을 활 용한 자연스러운 확장이 가능하다. Takeuchi 등 (2006)의 방법 역시 커널 분위수 회귀로 확장가능하지 만, 선형 분위수 회귀의 결과로 유추해 볼 때, Liu와 Wu (2011)의 방법이 커널 분위수 회귀에서는 가장 유용한 것으로 보인다.
개별 추정 방법과 비교하여, 비교차 다중 분위수 회귀의 유일한 단점은 계산의 복잡성에 있다. 하지만 본 연구에서 자세히 기술하였다시피 고려하고 있는 세 가지 방법 모두 선형계획법으로 표현될 수 있으 며, 따라서 실제 자료 분석에서는 비교차 다중 분위수 회귀를 사용하는 것이 더욱 바람직하다 하겠다.
References
Bondell, H. D., Reich, B. J., and Wang, H. (2010). Noncrossing quantile regression curve estimation, Biometrika, 97, 825–838.
Cole, T. J. and Green, P. J. (1992). Smoothing reference centile curves: the LMS method and penalized likelihood, Statistics in Medicine, 11, 1305–1319.
He, X. (1997). Quantile curves without crossing, The American Statistician, 51, 186–192.
Heagerty, P. J. and Pepe, M. S. (1999). Semiparametric estimation of regression quantiles with application to standardizing weight for height and age in US children, Journal of the Royal Statistical Society:
Series C (Applied Statistics), 48, 533–551.
Hendricks, W. and Koenker, R. (1992). Hierarchical spline models for conditional quantiles and the de- mand for electricity, Journal of the American Statistical Association, 87, 58–68. Journal of Economic Perspectives, 15, 43–56.
Johnson, R. W. (1996). Fitting percentage of body fat to simple body measurements, Journal of Statistics Education, 4, 265–266.
Koenker, R. (2005). Quantile Regression, Cambridge university press, New York.
Koenker, R. and Bassett, Jr, G. (1978). Regression quantiles, Econometrica: Journal of the Econometric Society, 46 33–50.
Koenker, R. and Geling, O. (2001). Reappraising medfly longevity: a quantile regression survival analysis, Journal of the American Statistical Association, 96, 458–468.
Koenker, R. and Hallock, K. (2001). Quantile regression: an introduction, Journal of Economic Perspectives, 15, 43–56.
Koenker, R., Ng, P., and Portnoy, S. (1994). Quantile smoothing splines, Biometrika, 81, 673–680.
Li, Y., Liu, Y., and Zhu, J. (2007). Quantile regression in reproducing kernel Hilbert spaces, Journal of the American Statistical Association, 102, 255–268.
Liu, Y. and Wu, Y. (2011). Simultaneous multiple non-crossing quantile regression estimation using kernel constraints, Journal of Nonparametric Statistics, 23, 415–437.
Shim, J., Hwang, C., and Seok, K. H. (2009). Non-crossing quantile regression via doubly penalized kernel machine, Computational Statistics, 24, 83–94.
Takeuchi, I. and Furuhashi, T. (2004). Non-crossing quantile regressions by SVM, In Neural Networks, 2004.
Proceedings. 2004 IEEE International Joint Conference on, 1, IEEE.
Takeuchi, I., Le, Q. V., Sears, T. D., and Smola, A. J. (2006). Nonparametric quantile estimation, Journal of Machine Learning Research, 7, 1231–1264.
Wang, H. and He, X. (2007). Detecting differential expressions in GeneChip microarray studies: a quantile approach, Journal of the American Statistical Association, 102, 104–112.
Wu, Y. and Liu, Y. (2009). Stepwise multiple quantile regression estimation using non-crossing constraints, Statistics and Its Interface, 2, 299–310.
Yang, S. (1999). Censored median regression using weighted empirical survival and hazard functions, Jour-
nal of the American Statistical Association, 94, 137–145.
비교차 제약식을 이용한 다중 선형 분위수 회귀모형에 관한 비교연구
방성완
a· 신승준
b,1a
육군사관학교 수학과,
b고려대학교 통계학과 (2016 년 3월 15일 접수, 2016년 5월 31일 수정, 2016년 7월 6일 채택)
요 약
분위수 회귀는 반응변수의 조건부 분위수 함수를 추정함으로써 반응변수와 예측변수의 관계에 대한 포괄적인 정보를 제공한다. 그러나 여러 개의 분위수 함수를 개별적으로 추정하게 되면 이들이 서로 교차할 가능성이 있으며, 이러 한 분위수 함수의 교차(quantile crossing) 현상 분위수의 이론적 기본 특성에 위배된다. 본 논문에서는 다중 비교 차 분위수 함수의 추정의 대표적인 방법들의 특성을 적합식과 계산 알고리즘의 측면에서 살펴보고, 모의실험과 실제 자료 분석을 통해 그 성능을 비교하였다.
주요용어: 다중 선형 분위수 회귀, 비교차, 선형 계획법
이 논문은 2015년도 정부(미래창조과학부)의 재원으로 한국연구재단의 지원을 받아 수행된 연구임 ((NRF-2015 R1C1A1A02036473) 방성완, (NRF-2015R1C1A1A01054913) 신승준).
1
![Table 2.1. Comparison for different NMQR methods 방법 설명변수의 받침에 대한 가정 비교차 제약의 영역 비선형 커널 확장 NMQR 1 없음 관측된 훈련자료 점 가능 NMQR 2 양의 유계영역, [0, M] p for some M < ∞ [0, M ] p 불가능 NMQR 3 양의 비유계영역, [0, ∞) p [0, ∞) p 가능 선형 분위수 회귀모형에서는, 이 제약식이 분위수 함수들의 비교차에 대한 필요충분조건이 됨](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5445684.433493/6.892.152.743.215.288/설명변수의-훈련자료-유계영역-비유계영역-회귀모형에서는-제약식이-함수들의-필요충분조건이.webp)