2019, 30
(3)
,515–524
모형 기반 하이브리드 의사결정나무
†
ᄌ
ᅥᆫ유택
1
·조형준2
12고려대학교 통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2019ᄂ ᅧ ᆫ 1ᄋ ᅯ ᆯ 17ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 4ᄋ ᅯ ᆯ 5ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 4ᄋ ᅯ ᆯ 12ᄋ ᅵ ᆯ
요 약
ᄋ
ᅴᄉ ᅡᄀ ᅧ ᆯᄌ ᅥ ᆼᄂ ᅡᄆ ᅮᄂ ᅳ ᆫ ᄌ ᅮᄋ ᅥᄌ ᅵ ᆫ ᄋ ᅨᄎ ᅳ ᆨ ᄇ ᅧ ᆫᄉ ᅮ ᄀ ᅩ ᆼ ᄀ ᅡ ᆫᄋ ᅳ ᆯ ᄋ ᅧᄅ ᅥ ᄀ ᅢᄋ ᅴ ᄃ ᅡ ᆫᄉ ᅮ ᆫ ᄒ ᅡ ᆫ ᄉ ᅡᄀ ᅡ ᆨ ᄒ ᅧ ᆼᄐ ᅢᄋ ᅴ ᄀ ᅩ ᆼ ᄀ ᅡ ᆫᄋ ᅳᄅ ᅩ ᄇ ᅮ ᆫ ᄒ ᅡ ᆯᄒ ᅢᄀ ᅡᄆ ᅧ ᆫᄉ ᅥ ᄆ
ᅩ
ᆨ ᄑ ᅭ ᄃ ᅢᄉ ᅡ ᆼᄋ ᅳ ᆯ ᄇ ᅮ ᆫ ᄅ ᅲᄒ ᅡᄀ ᅥᄂ ᅡ ᄋ ᅨᄎ ᅳ ᆨ ᄒ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄃ ᅡ. ᄋ ᅴᄉ ᅡᄀ ᅧ ᆯᄌ ᅥ ᆼᄂ ᅡᄆ ᅮᄂ ᅳ ᆫ ᄉ ᅡᄋ ᅭ ᆼ ᄋ ᅵ ᄋ ᅭ ᆼ ᄋ ᅵᄒ ᅡᄆ ᅧ, ᄋ ᅵᄒ ᅢᄒ ᅡᄀ ᅩ ᄉ ᅥ ᆯᄆ ᅧ ᆼᄒ ᅡᄀ ᅵ ᄉ ᅱᄋ ᅮ ᆫ ᄀ
ᅮᄌ ᅩᄅ ᅳ ᆯ ᄌ ᅵᄂ ᅵᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ. ᄒ ᅡᄌ ᅵᄆ ᅡ ᆫ ᄉ ᅥᄑ ᅩᄐ ᅳ ᄇ ᅦ ᆨᄐ ᅥ ᄆ ᅥᄉ ᅵ ᆫᄀ ᅪ ᄀ ᅡ ᇀᄋ ᅵ ᄉ ᅮᄌ ᅵ ᆨᄉ ᅥ ᆫ ᄒ ᅩ ᆨᄋ ᅳ ᆫ ᄉ ᅮᄑ ᅧ ᆼᄉ ᅥ ᆫ ᄒ ᅧ ᆼᄐ ᅢᄋ ᅪ ᄇ ᅵᄀ ᅭᄒ ᅢ ᄒ ᅯ ᆯᄊ ᅵ ᆫ ᄇ ᅩ ᆨ ᄌ ᅡ ᆸᄒ ᅡ ᆫ ᄀ ᅧ
ᆯᄌ ᅥ ᆼ ᄀ ᅧ ᆼᄀ ᅨᄅ ᅳ ᆯ ᄌ ᅵᄂ ᅵ ᆫ ᄇ ᅮ ᆫᄉ ᅥ ᆨ ᄀ ᅵᄇ ᅥ ᆸᄋ ᅦ ᄇ ᅵᄒ ᅢ ᄋ ᅨᄎ ᅳ ᆨ ᄌ ᅥ ᆼᄒ ᅪ ᆨ ᄃ ᅩᄀ ᅡ ᄉ ᅡ ᆼᄃ ᅢᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄂ ᅡ ᆽᄃ ᅡᄂ ᅳ ᆫ ᄃ ᅡ ᆫᄌ ᅥ ᆷᄋ ᅳ ᆯ ᄀ ᅡᄌ ᅵᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄋ ᅧ ᆫᄀ ᅮ ᄋ
ᅦᄉ ᅥᄂ ᅳ ᆫ ᄋ ᅲᄋ ᅧ ᆫᄒ ᅡ ᆫ ᄀ ᅧ ᆯᄌ ᅥ ᆼ ᄀ ᅧ ᆼᄀ ᅨᄅ ᅳ ᆯ ᄀ ᅡᄌ ᅵᄂ ᅳ ᆫ ᄋ ᅴᄉ ᅡᄀ ᅧ ᆯᄌ ᅥ ᆼᄂ ᅡᄆ ᅮ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄅ ᅩ ᆫᄋ ᅳ ᆯ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡ ᆫᄃ ᅡ. ᄈ ᅮᄅ ᅵ ᄆ ᅡᄃ ᅵᄋ ᅦᄉ ᅥᄇ ᅮᄐ ᅥ ᄋ ᅲᄋ ᅧ ᆫᄒ ᅡ ᆫ ᄀ ᅧ ᆯᄌ ᅥ ᆼ ᄀ ᅧ
ᆼᄀ ᅨᄅ ᅳ ᆯ ᄌ ᅵᄂ ᅵᄂ ᅳ ᆫ ᄀ ᅵᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄋ ᅨᄎ ᅳ ᆨ ᄌ ᅥ ᆼᄒ ᅪ ᆨ ᄃ ᅩᄅ ᅳ ᆯ ᄒ ᅣ ᆼᄉ ᅡ ᆼᄉ ᅵᄏ ᅵ ᆫᄃ ᅡ. ᄄ ᅩᄒ ᅡ ᆫ, ᄋ ᅵᄂ ᅳ ᆫ ᄂ ᅡᄆ ᅮ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅴ ᄏ ᅳᄀ ᅵᄃ ᅩ ᄌ ᅮ ᆯ ᄋ ᅧᄌ ᅮ ᆫ ᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄃ ᅦᄋ ᅵᄐ ᅥᄆ ᅡᄋ ᅵᄂ ᅵ ᆼ, ᄋ ᅴᄉ ᅡᄀ ᅧ ᆯᄌ ᅥ ᆼᄂ ᅡᄆ ᅮ, ᄒ ᅩ ᆫ ᄒ ᅡ ᆸ ᄆ ᅩᄒ ᅧ ᆼ.
1. 서론 ᄋ
ᅴ사결정나무는 데이터마이닝에서 널리 사용되는예측모형이며, 모형을구축하는과정을관측할 수 이
ᆻ기 때문에 결과를해석하기 쉽다는장점이 있다 (Kim 등, 2017). 또한, 자료를별도의 전처리 과정을 ᄀ
ᅥ치지 않고 사용할 수 있기 때문에 모형의 사용이 간단하다. 그러나 예측정확도의 측면에서 비교적 최 ᄀ
ᅳᆫ에 개발된모형에 비해 상대적으로 낮다. 이는주어진 설명 변수가 목표 대상에 대해 수직적 혹은수 펴
ᆼ적으로 분류하기 어려울때 자주 발생하는 문제이다. 이런 경우에 분류가 쉽게 이루어지지 않기 때문 ᄋ
ᅦ 더 많은 분류 지점을탐색하게 되어 모형 적합 시간이 늘어나고 모형은더 복잡해지게된다. 결과적 ᄋ
ᅳ로 장점인 설명력과 간결함을 잃게 되고 동시에 좋은성능또한 기대할 수 없게된다.
보
ᆫ 연구에서는 위와 같은 이유로 간단한 구조를 지닌 의사결정나무를 기반으로 유연한 결정 경계를 ᄌ
ᅵ닌 혼합 모형을 제안한다. 사실 두 가지 이상의 모형을 혼합하는 연구는다양하게 진행되어져 왔다 (Kim과 Loh, 2003; Kumar와 Gopal, 2010; Hong 등, 2017). 다만 모형 성장단계에서 변수의 개수 르
ᆯ 선택적으로 가져가는 방식이거나 의사결정나무의 단점을 극복하기 위함이 아닌, 서포트 벡터 머신 (SVM)의 단점을극복하기 위해 연구였다. 혹은변수의 유형에 따라 데이터를나누어 각각에 대해 모형 으
ᆯ적합하였다. 또한, 모형의 혼합을 통해 예측정확도를향상시킨다는 본연구와 유사한 목적을 지닌 ᄃ
ᅡ른 연구에서는 오차 패턴에 따라 다른 모형을 적합하였다 (Cho와 Hur, 2006). 본연구에서는 위의 ᄉ
ᅥᆫ행 연구들과는 조금다른 방식을 채택한다. 단순하게 생각하면 의사결정나무의 마디를 보다 유연한 겨
ᆯ정 경계를가진 통계적 모형인 선형판별분석 모형 (LDA)과 SVM으로 대체하는방법이다. 본연구의
†
ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ ᄀ ᅩᄅ ᅧᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄋ ᅧ ᆫᄀ ᅮᄇ ᅵ (K1707561)ᄋ ᅪ 2018ᄂ ᅧ ᆫᄃ ᅩ ᄌ ᅥ ᆼᄇ ᅮ (ᄀ ᅭᄋ ᅲ ᆨ ᄇ ᅮ)ᄋ ᅴ ᄌ ᅢᄋ ᅯ ᆫ ᄋ ᅳᄅ ᅩ ᄒ ᅡ ᆫᄀ ᅮ ᆨᄋ ᅧ ᆫᄀ ᅮᄌ ᅢᄃ ᅡ ᆫᄋ ᅴ ᄌ ᅵᄋ ᅯ ᆫᄋ ᅳ ᆯ ᄇ
ᅡ
ᆮᄋ ᅡ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬ ᆫ ᄀ ᅵᄎ ᅩᄋ ᅧ ᆫᄀ ᅮᄉ ᅡᄋ ᅥ ᆸ(2018R1D1A1B07044479)ᄋ ᅵ ᆸᄂ ᅵᄃ ᅡ.
1
(02841) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥ ᆼᄇ ᅮ ᆨ ᄀ ᅮ ᄋ ᅡ ᆫᄋ ᅡ ᆷᄅ ᅩ 145, ᄀ ᅩᄅ ᅧᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄉ ᅥ ᆨᄉ ᅡᄌ ᅩ ᆯᄋ ᅥ ᆸ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (02841) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥ ᆼᄇ ᅮ ᆨ ᄀ ᅮ ᄋ ᅡ ᆫᄋ ᅡ ᆷᄅ ᅩ 145, ᄀ ᅩᄅ ᅧᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
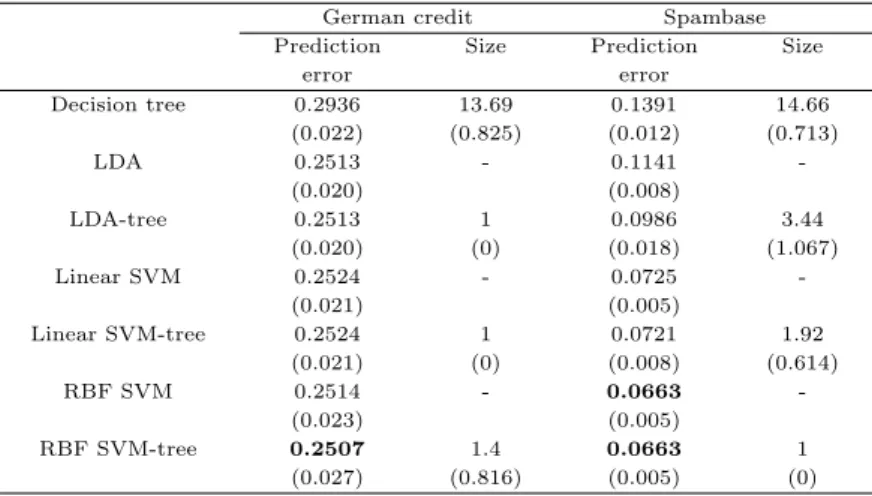
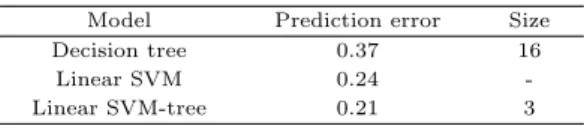
2절에서는연구에서활용될의사결정나무의 종류, LDA, SVM 그리고 하이브리드 의사결정나무 모형을 ᄉ
ᅩ개한다. 3절에서는다양한 실제 데이터를 통해 모형들의 성능을 비교한다. 예측정확도와 모형의 크 ᄀ
ᅵ를비교하여 제안한 모형의 성능을확인한다. 4절에서는한 가지 사례 연구를 들어 실제 데이터에 적 ᄋ
ᅭ
ᆼ되는방식을살펴본다. 5절에서는 본연구에 대한 결론과 향후 개선 방안에 대해 논의한다.
2. 연구 배경 ᄇ
ᅩᆫ절에서는 연구의 토대가 되는의사결정나무, 선형판별분석, 그리고 서포트 벡터 머신을소개한다.
ᄀ ᅡ
ᆨ 방법론에 대해 작동 원리와 판별 규칙을설명한다. 이 후 본연구에서 제안하는하이브리드 의사결정 ᄂ
ᅡ무 모형의 상세한 과정을소개한다.
2.1. 의사결정나무 ᄋ
ᅴ사결정나무는반복적으로 분류 규칙을생성하여 가장 효과적인 분류 규칙 조합을완성해 나가는 분 ᄉ
ᅥᆨ 기법이다. 본연구에서는여러 의사결정나무 방법론 중에서 CART 알고리즘을사용한다. Brieman ᄃ
ᅳᆼ (1984)에 의해 개발된CART는이진 분할을 통해 지점을 분할하며, 모형 성장 과정에서 지니 계수를 ᄇ
ᅮᆯ순도의 척도로 사용한다. 어떤 주어진 집합에서의 지니 계수는다음과 같이 계산한다.
Gini(S) =
m
X
i=1
pi(1 − pi). (2.1) ᄋ
ᅵ때 분류의 대상은 m개의 클래스로 이루어졌고 pi는주어진 집합 내 각 클래스의 비율이다. S는주 ᄋ
ᅥ진 집합에서 분류를하게될부분집합의 정보이다. 모든 분할 지점 중에서 불순도를가장 크게 감소시 ᄏ
ᅵ는지점을최적의 분할 기준으로 선택한다. 즉,다음의 함수를최대화 하는지점을선택한다.
△i(s, t) = i(t) − [pL× i(tL) + pR× i(tR)]. (2.2) ᄋ
ᅵ때 i(t)는현재 노드 t의 불순도 함수다. pL과 pR은설명 변수 내의 s라는지점을기준으로 분류한 ᄋ
ᅵ후, 상위 노드 t 대비 두 자식노드의 비율을나타낸다. i(tL)과 i(tR)은 s라는지점을기준으로 분류한 ᄋ
ᅵ후 각 자식노드의 불순도 함수다. 결과적으로 △i(s, t)는주어진 상위 노드 t에서 지점 혹은조합 s를 ᄉ
ᅥᆫ택함으로써 감소시킬 수 있는 불순도의 변화량이라고 할 수 있다. 이러한 과정을재귀적으로 반복하 ᄋ
ᅧ 최하위 마디에 속한 자료의 수가 미리 지정한 최솟값에 도달하면 분류를 중단하게 된다. 최하위 마 ᄃ
ᅵ에 속하게될자료의 수를자료의 크기에 비해 지나치게 작게 지정할 경우, 최종모형이 과대적합하게 되
ᆯ가능성이 높다. 이러한 경우에 불필요하게 성장된자식 마디를제거하는가지치기 과정을거치게된 ᄃ
ᅡ. 본연구에서는가지치기 과정을거치지 않는대신, 최하위 마디에 속하게될자료의 크기를제한하 ᄋ
ᅧ 모형이 지나치게 크게 성장되는것을방지한다.
2.2. 선형판별분석 (Linear discriminant analysis) ᄉ
ᅥᆫ형판별분석은 목표 대상의 클래스를구분할 수 있는판별식을도출하여 분류하고 예측하는 분석 기 버
ᆸ 중하나다. 주어진 설명 변수의 선형 조합으로 최적의 결정 경계를형성한다. 클래스 간의 거리를최 ᄃ
ᅢ화 시키는방향으로 결정 경계를형성하게 되는데, 이는 곧 클래스 간의 분산을최대화 하는방법으로 ᄀ
ᅱ결된다. 선형판별분석은 Fisher (1936)의 연구에서 소개된 선형 판별 개념을확장시킨 것으로, 다양 ᄒ
ᅡᆫ 분야에서 널리 사용되고 있다.