水 工 學
大 韓 土 木 學 會 論 文 集第26卷 第4B 號·2006年 7月 pp. 355 ~ 362
수문 및 기후 자료에 대한 선형 경향성 및 평균이동 분석
Trend and Shift Analysis for Hydrologic and Climate Series
오제승*·김형수**·서병하***
Oh, Je Seung · Kim, Hung Soo · Seo, Byung Ha
···
Abstract
Several techniques of MK test, Spearman's Rho test, Linear Regression test, CUSUM test, Cumulative Deviation, Worsley Likelihood Ratio test, Rank Sum test, and Students' t test were applied to detect the trends of slope and shift which exist in hydrologic and climate time series. The time series of annual rainfall, inflow, tree ring index, and southern oscillation index (SOI) were used and the trends of these series were compared in the study. From the results, it can be found that the data could be classified into two categories such as linear trend and shift. 4 series data of 8 rainfall series which reveal the trend show the shift and 8 series data of 18 tree ring index and March and April series of monthly SOI data show shift. Moreover, ADF test and BDS test were used to test stationarity and non-linearity of the data. In conclusion, through the study, various trend anal- ysis techniques were compared and 6 kinds of characteristics which can exist in hydrologic time series were identified.
Keywords : hydrologic time series, stationarity, trend analysis, shift analysis
···
요 지
본 연구에서는 수문 및 기후 시계열 자료에 존재하는 경향성을 분석하기 위하여 MK 검정 , Spearman's Rho 검정 , Linear Regression 검정 , 비모수 Cusum 검정 , Cumulative Deviation 검정 , Worsley Likelihood Ratio 검정 , Rank Sum
검정 , Student's t 검정 등의 8 가지 기법을 사용하였다 . 관측된 연 강우량과 유입량 시계열 자료 , 나이테 자료 그리고 SOI
자료에 적용하여 그 결과를 비교 분석 하였다 . 분석 결과 시계열 자료에는 어떤 기울기를 가지거나 어느 시점을 기준으로
평균이 변화하는 두 가지의 경향성이 존재함을 확인 할 수 있었다 . 경향성을 나타낸 8 개의 강우자료중 4 개 지점이 평균이 동 (shift) 을 나타내었으며 , 18 개 지역의 나이테 지수중 8 개 지역과 월별 SOI 자료 중 3, 4 월자료에서 경향성의 존재가 확인 되었고 , 소양강댐 유입량 자료에서는 경향성이 나타나지 않았다 . 특히 , 나이테 지수의 경우에는 평균이동으로 인한 경향성만 을 가지고 있는 자료가 확인되었다 . 또한 정상성 검정을 위한 ADF 검정과 비선형성 검정을 위한 BDS 통계검정 기법을
적용하였다 . 본 연구를 통하여 여러 경향성 분석 기법을 비교할 수 있었으며 , 실제 관측된 수문 및 기후 시계열에 존재하는 경향성을 확인 할 수 있었고 , 연구 결과를 통하여 수문시계열 해석시 다양한 분석을 통한 경향성의 존재여부를 확인 하여야 한다는 것을 알 수 있었다 .
핵심용어 : 수문 시계열 , 정상성 , 경향성 분석 , 평균이동분석
···
1. 서 론
수자원 계획 수립을 위하여 목적에 따라 추계학적 모형 구축이나 빈도분석등 수문시계열 해석을 시행한다 . 이 때 수 문시계열 자료는 정상성과 독립성을 지녀야 하고 우선적으
로 이들에 대한 검정 (test) 을 수행하여야 한다 . 그러나 국내
의 경우 사전에 수문 시계열 자료가 정상성이나 독립성을 지니고 있다고 가정하고 수문 분석을 실시하는 경우가 많았 기 때문에 , 왜곡된 결과를 초래할 여지가 있었다고 사료된다 .
따라서 수문자료를 확률적인 분석이나 추계학적 분석에 사 용하기 위해서는 수문자료의 시계열 특성을 사전에 반드시
분석할 필요가 있다 . 또한 , 지구 온난화 , 기후변화 및 도시
화 등의 영향으로 강우를 비롯한 홍수나 가뭄 등의 크기는 증가 또는 감소하는 경향을 나타낼 소지를 가지고 있으며 ,
이러한 경향성은 시계열 자료를 도시함으로써 쉽게 파악할 수 있지만 , 경향성이 뚜렷하게 나타나지 않는 경우에는 통계
적 방법을 이용하여 경향성 분석을 실시한다 . 경향성 분석을 위한 통계적 분석 방법으로 Spearman's Rho 검정 , Linear Regression) 검정 , 비모수 Cusum 검정 , Cumulative Deviation
검정 , Worsley Likelihood Ratio 검정 , Rank Sum 검정 , Student's t 검정 , Hotelling-pabst 검정 , Cox-Stuart 검정 ,
비선형 경향성 검정 (nonlinear trend test), Mann-Kendall
***
인하대학교토목공학과석사과정(E-mail : [email protected])
***
정회원·교신저자·인하대학교토목공학과교수(E-mail : [email protected])
***
정회원·인하대학교토목공학과교수(E-mail : [email protected])
검정 (MK 검정 ), Sen 검정 등의 여러 가지 방법이 있다 .
Zhang 등 (2001) 은 캐나다의 유출량에 대해 경향성의 존재
여부를 분석하였으며 , Burn 과 Hag(2002) 은 기후변화 연구
를 위한 수문학적 경향성에 대하여 , Yue 와 Hashino (2003)
는 일본에서의 월 및 연 강우량에 대한 장기 경향성 분석에
대해 연구한 바 있다 . Birsan 등 (2003) 은 과거의 홍수와 기
후변화를 고려한 스위스에서의 하천유출 경향에 대하여 연 구하였으며 , Wang 등 (2005) 은 20 세기 서유럽에서의 하천 유출량에 대한 경향성 및 정상성에 대하여 분석 하였다 . 국
내에서는 김병식 등 (1997) 이 우리나라 연 강우량 자료의 시
계열 특성분석에 대하여 연구 하였으며 , 이상복 등 (2004) 은 강수자료에 대한 변동성 및 경향성 해석에 대하여 연구 하 였다 .
본 연구에서는 30 개 지점의 30 년 연 강우량 , 18 개 지역의
109 년 나이테 지수 자료 , 49 년 동안의 월별 SOI(Southern Oscillation Index) 자료와 30 년 동안의 소양강댐 유입량 자 료를 사용하여 경향성 분석을 수행하였다 . MK 검정을 비롯 한 8 개의 경향성 분석 기법을 적용하여 시계열 자료가 가지 고 있는 전반적인 증가 또는 감소의 경향성 여부와 어느 시
점을 기준으로 평균이 변화하는 평균이동 (shift) 으로 인한 경
향성 여부를 분석 하였다 . 2. 경향성 분석 기법의 이론
2.1 Mann-Kendall 검정
Mann-Kendall(MK) 검정은 시계열 자료의 경향성 여부를
분석하기 위한 비모수적인 통계 기법으로 시계열 자료의 단
조 경향 (monotonic trend) 을 분석하는데 유용하게 사용되어
지고 있다 . MK 검정의 귀무가설은 분석대상 시계열에 경향
성이 존재하지 않는다는 것이며 검정 통계량 S 를 정의하면 다음 식 (1), (2) 와 같다 (Mann, 1945; Kendall, 1975).
(1)
여기서 , X
j: j 번째 시계열 자료 값
n : 시계열 자료의 크기
(2)
MK 검정의 표준 검정 통계량과 단측 (one-side) 검정을 위
한 P-value 등은 식 (3) 및 식 (4) 와 같이 나타내어진다 .
(3)
(4)
위의 식에서 Z 값의 부호는 경향성의 증가 또는 감소
특성을 나타낸다 . 유의수준이 0.05 일 경우 이면 경향성의 존재는 통계적으로 의미 있는 값으로 고려되어 진다 . 즉 , 분석된 시계열에 존재하는 경향성을 고려하여야 한다 .
2.2 Spearman's Rho 검정
Spearman's ρ 검정은 관측된 시계열 자료의 순위에 기초하
여 두 변수들간의 상관 여부가 통계적으로 유의한가를 알아 보는 검정이다 . 검정의 귀무가설은 두 변수 ( 경향성 분석의 경우에는 시간과 관측값 ) 사이에 연관성이 없다는 것으로 경
향성을 나타내지 않음을 의미한다 (Mendenhall, 1983). 관측
된 시계열이 가지는 경향성의 방향을 모르는 경우에는 양측 검정을 실시하며 , 증가 또는 감소의 경향을 알고 있는 경우 에는 단측 검정을 수행한다 . 검정 통계량 ρ
s는 일반적인 상 관계수와 같은 식으로 계산되어지지만 시계열 자료의 관측 값이 아닌 그들의 순위를 사용하여 다음 식 (5) 과 같이 계 산된다 .
(5)
여기서 ,
식 (5) 에서 x
i는 시간의 순위이므로 30 개의 자료를 사용한
경우 , 1~30 까지의 값을 가지며 y
i는 관측값의 순위 , 그리
고 는 순위의 평균값으로 자료개수의 중앙값이 된다 . 2.3 Linear Regression 검정
모수적 검정 방법인 Linear Regression 검정은 시계열 자
료가 정규분포라고 가정하며 , 시간 ( x ) 과 관측 변수 ( y ) 사이의 선형 경향 여부를 검정한다 . 회귀 경사 (regression gradient)
와 회귀 상수는 다음 식 (6) 과 같이 계산된다 .
(6)
검정 통계량 S는 다음 식 (7) 과 같다 .
(7)
검정 통계량 S는 자유도가 n -2 인 Student-t 분포를 따르며 ,
따라서 각 유의수준에 따른 한계 통계량 값은 Student-t 통
계량 표로부터 얻어진다 .
S sgn ( X
j– X
i)
j i 1= + n
∑
i 1= n 1–
∑
=
θ ( ) sgn
1 if θ 0 >
0 if θ 0 = 1 – if θ 0 <
⎩ ⎪
⎨ ⎪
⎧
=
Z
S 1 – Var S ( ) --- S 0 >
0 S 0 = S 1 + Var S ( ) --- S 0 <
⎩ ⎪
⎪ ⎨
⎪ ⎪
⎧
=
p 0.5 Φ Z = – ( )
Φ Z ( ) ( ) 1
--- e 2π
t2 2--- –
d t)
0
∫
Z=
p 0.05 ≤
ρ
s= S
XY⁄ ( S
XS
Y)
0.5S
X( x
i– X )
2i 1=
∑
n=
S
Y( y
i– Y )
2i 1=
∑
n=
S
XY( x
i– X ) y (
i– Y )
i 1=
∑
n=
X Y
a y bx b
x
i– x ( ) y (
i– y )
i 1=
∑
nx
i– x ( )
2i 1=
∑
n---
= , –
=
S b σ ⁄ , σ
12 ( y
i– a – bx
i)
i 1=
∑
nn n 2 ( – ) n (
2– 1 ) ---
=
=
2.4 CUSUM 검정
이 검정 방법은 비 모수적 검정으로 변화 시점을 모르는 관측된 두 기간 에서 평균의 변화가 통계적으로 유의한가에 대해 검정한다 (Chiew 와 McMahon, 1993).
시계열 자료가 x
1, x
2, x
3, ...., x
n과 같이 주어질 때 검정통 계량은 다음 식 (8) 과 같다 .
(8) V
k는 Kolmogorov-Smirnov 이산 표본 통계 KS =(2/ n )max
분포를 따르며 , sgn ( x ) 는 MK 검정의 식 (2) 와 같이 계 산된다 . 의 값이 최대인 시점을 변화 시점으로 하여 , 그 값이 음수인 경우에는 변화 시점을 기준으로 뒷부분의 평균 이 앞부분의 평균보다 크다는 것을 나타낸다 .
2.5 Cumulative Deviation 검정
모수적 검정 방법으로 , 관측된 기간 중 모르는 어느 시점 을 기준으로 전 , 후의 평균값이 다른지를 검정하며 , 자료는 정규분포인 것으로 가정한다 (Buishand, 1982). 이 검정의 목 적은 몇 번째 관측 값 이후에 평균이 변화하는 가를 알아내 는 것이다 . 번째 관측값 이후에 평균이 변화한다고 하면 ,
(9) (10)
여기서 , µ : : 변화 이전의 평균
∆ : 평균의 변화량
E ( x
i) : 변화 시점 전·후의 평균의 기대값
검정 통계량 Q 는 다음 식 (11) 과 같이 계산되며 가
최대일 때의 시점을 변화의 기준점으로 하고 , 값이 음수 인 경우에는 변화 시점을 기준으로 뒷부분의 평균이 앞부분 의 평균보다 크다는 것을 나타낸다 .
(11)
여기서 ,
2.6 Worsley Likelihood Ratio 검정
모수적 검정 방법으로 , 관측된 기간 중 모르는 어느 시점
을 기준으로 전 , 후의 평균 값이 다른지를 검정하며 , 자료는 정규분포인 것으로 가정하는 것은 Cumulative Deviation 검 정과 유사하지만 , 시계열의 위치에 의해 의 값이 가중된 다 (Worsley, 1979).
(12) (13)
여기서 , k =1,2,...,n
= 자료의 개수
: 식 (11) 과 같음
검정 통계량 W 는 다음 식 (14) 와 같으며 , W 값이 음수인
경우에는 변화 시점을 기준으로 뒷부분의 평균이 앞부분의 평균보다 크다는 것을 나타낸다 .
(14)
여기서 ,
2.7 Rank Sum 검정
Rank-Sum 검정은 순위에 기초한 비 모수적 검정으로
Wilcoxon- Mann-Whitney 검정 또는 Mann-Whitney 검정 으로도 알려져 있으며 , 관측된 자료 기간에서 두 구간의 중 앙값의 차이가 통계적으로 유의한가를 검정하는 방법이다
(Siegel 과 Castellan, 1988). 귀무가설은 두 집단의 중앙값이 동일하다는 것이며 , 검정을 위해서는 자료 기간을 두 개로 나눌 시점을 지정해 주어야 한다 .
검정 통계량을 계산하기 위해서는 우선 , 모든 관측 자료를 가장 작은 값의 순위를 1 로 하여 크기 순서대로 나열한다 .
동일한 값이 존재하는 경우에는 순위의 평균값을 사용한다 .
통계량 는 두 그룹중 작은 그룹의 관측값 순위의 합으로 계 산된다 . 작은 그룹의 자료 개수를 n , 큰 그룹의 관측 개수 를 m 이라하고 , S 의 이론적인 평균과 표준편차를 전체 자료 에 대해 다음 식과 같이 계산한다 .
(15) (16)
표준화된 형태의 검정 통계량 는 다음과 같이 계산된다 .
if if (17)
if
Z
rs는 정규분포에 근사하며 , 유의 수준에 따른 한계 검정
통계량 값은 정규 확률 표로부터 얻어진다 . 2.8 Student's t 검정
모수적 검정 방법으로 서로 다른 두 기간에서의 평균이 일정한가를 검정하며 , 자료는 정규분포인 것으로 가정한다 .
귀무가설은 두 독립된 자료 그룹의 평균이 동일하다는 것이 며 대립가설은 양측 검정의 경우에는 평균이 다르다는 것이 고 , 단측 검정의 경우에는 한 그룹의 평균이 다른 그룹의
평균보다 크다는 것이다 . Rank-Sum 검정과 같이 어느 한
시점을 지정해 주어야 하며 , 지정된 시점을 기준으로 평균의 변화 여부를 검정한다 .
검정 통계량 t는 다음 식 (18)과 같이 계산된다.
(18)
여기서 , n, m : 각 그룹의 관측 자료 개수
S : 표본의 표준편차
검정 통계량은 t- 분포를 따르며 , 기각역은 단측검정의 경우
t>t
a, 양측검정의 경우 이다 . V
ksgn ( x
i– x
median) k
i=1
∑
k1 2 3 , , , …… , n
= =
V
kV
kE x ( ) µ
i= i = 1 2 3 , , , …… , m E x ( ) µ ∆
i= + i m = + 1 , m + 2 , …… , n
S
k**S
k*Q = max S
k**S
k*( x
i– x ) S
k**S
k*D
xD
x2( x
i– x )
2--- n
i=1
∑
n=
,
= ⁄ ,
i=1∑
k=
S
k*Z
k*= [ k n k ( – ) ]
–0.5S
k*Z
k**= Z
k*⁄ D
xn S
k*, D
xW n ( – 2 )
0.5V 1 – V
2( )
0.5---
=
V = max Z
k**µ = n N ( + 1 ) ⁄ 2
σ = [ nm N ( + 1 ) ⁄ 12 ]
0.5Z
rs= ( S – 0.5 – µ ) σ ⁄ S > µ
Z
rs= 0 S = µ
Z
rs= ( S + 0.5 – µ ) σ ⁄ S < µ
t ( x y – )
S 1 n --- + loverm ---
=
t t >
a⁄23. 정상성 및 비선형성 검정
3.1 Augmented Dickey-Fuller 검정
시계열에 단위근의 존재여부를 검정하므로 정상성 여부를 판단하는 Augmented Dickey-Fuller(ADF) 검정은 Dickey
와 Fuller(1981) 에 의해 개발된 이후로 여러 특성을 가지는
시계열의 정상성 분석에 사용되어지고 있다 . ADF 검정에서
는 AR(p) 과정을 따르는 시계열에서 상수항과 시간추세의
유무에 따라 다음과 같은 세 가지 모형이 사용된다 . (19)
(20)
(21)
식 (19) 는 상수항과 확정적 시간추세가 모두 없는 경우 ,
식 (20) 은 상수항만 포함하는 경우 , 식 (21) 은 상수항과 확
정적 시간추세를 모두 포함하는 경우의 모형이며 , 각각의 검 정통계량 그리고 귀무가설과 대립가설은 다음 표 1 과 같다 .
3.2 BDS 통계 검정
BDS 통계는 Brock, Dechert, 그리고 Scheinkman(1987)
에 의하여 제안된 방법으로 무작위성과 비선형 동역학 시스 템을 구분하는데 탁월한 능력이 있는 것으로 알려져 왔다 .
시계열 자료가 무작위한 분포를 따른다는 가설 하에 m >1 인
경우의 BDS 통계는 다음과 같은 식으로 나타낼 수 있다 .
BDS(m,M,r) = (22)
여기서 ,
(23)
(24)
BDS 통계를 통해 비선형 확정론적 시스템과 비선형 추계
학적 시스템을 구분할 수는 없으나 , 무작위한 시계열 자료와 카오스 시스템 혹은 비선형 추계학적 시스템을 구분하기 위 해서는 매우 유용한 통계기법이다 . 자료가 IID 일 때 , S ( m, M,r ) → 0 인 BDS 통계량에 대해 그림 1 에서 설명하고 있다 . 4. 관측 시계열 자료에 대한 경향성 분석 기법의
적용
4.1 대상 관측 시계열 자료
앞에서 요약한 8 가지의 경향성 분석 기법과 정상성 및 비 선형성 분석 기법을 다음 표 2 와 같은 수문 및 기후 시계
열 자료에 적용하였다 .
4.2 경향성 분석기법의 적용
위에서 언급한 경향성 분석 기법은 크게 두 가지로 나누 어 질 수 있다 . 자료가 가지고 있는 증가 또는 감소의 전반 적인 경향성 여부만을 그 결과로 제시하는 MK 검정 , Spearman's Rho 검정 , Linear regression 검정과 , 관측된 기간 내의 어느 시점을 기준으로 평균의 변화 여부를 검정 하는 Cusum 검정 , Cumulative deviation 검정 , Worsley likelihood 검정 , Rank Sum 검정 , Student's t 검정이다 . 이 검정 방법들 중에서 Cusum 검정 , Cumulative deviation 검
정 , Worsley likelihood 검정은 자료의 변화 시점을 계산하
고 , 계산된 시점을 기준으로 평균이동 (shift) 을 검정하며 ,
Rank Sum 검정 , Student's t 검정은 지정한 시점을 기준으 로 앞 , 뒤 부분의 중앙값과 평균의 차이가 통계적으로 유의 한지 여부를 검정한다 . 따라서 본 연구에서는 Cusum 검정 , Cumulative deviation 검정 , Worsley likelihood 검정을 먼 저 수행하고 이 세 가지의 검정결과에서 나타내는 변화 시 점을 기준으로 하여 Rank Sum 검정과 Student's t 검정을 실시하였다 .
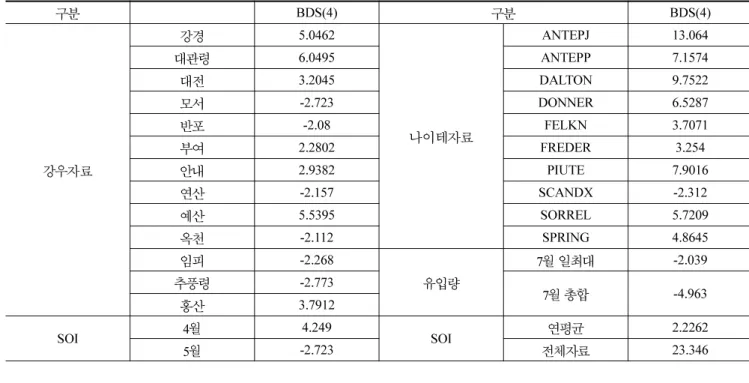
강경 지점의 분석 결과를 표 3 에 나타내었고 , 결과란의 S
는 significant 를 NS 는 not signficant 를 의미하며 , 강우지점 의 분석 결과를 다음 표 4 에 요약하였다 . 여러 분석 기법의 결과 중 유의수준 에서 하나 이상의 분석 결과가 경향성을 나타낸 자료만을 나타내었고 , 표 3 에 나타낸 결과는 유의 수준 까지 경향성을 나타낸 경우 로 표시 하였다 . 표 3 으로 부터 유의수준에 따라 각 분석 기법의 결과가 상이함을 알 수 있는데 , 예를 들어 유의수준이 0.1 인 경우에는 강경 , 대 관령 , 반포 , 안내 , 연산 , 영동 , 예산 , 정안 지점의 자료는 ⓐ
∆ y
tγ y
t–1φ
j*∆ y
t j–j=1
∑
pε
t+ +
=
∆ y
tα γ + y
t–1φ
j*∆ y
t j–j=1
∑
pε
t+ +
=
∆ y
tα γ + y
t–1β t φ
j*∆ y
t j–j=1
∑
pε
t+ + +
=
σ M
--- [ C m r ( , ) – C
m( 1 , r ) ]
σ
2( m M r , , ) 4 ⁄ = m m ( – 1 ) C
2(m–1)( K C –
2) + K
m– C
2m+2 [ C
2i( K
m i–– C
2(m i–)) – nC
2(m i–)( K C –
2) ]
i=1m–1
∑
K m M r ( , , ) 6
M M ( – 1 ) ( M – 2 )
--- [ Θ ( r x –
i– x
j)Θ ( r x –
i– x
j) ]
1≤i j M