저작자표시-비영리-변경금지 2.0 대한민국 이용자는 아래의 조건을 따르는 경우에 한하여 자유롭게 l 이 저작물을 복제, 배포, 전송, 전시, 공연 및 방송할 수 있습니다. 다음과 같은 조건을 따라야 합니다: l 귀하는, 이 저작물의 재이용이나 배포의 경우, 이 저작물에 적용된 이용허락조건 을 명확하게 나타내어야 합니다. l 저작권자로부터 별도의 허가를 받으면 이러한 조건들은 적용되지 않습니다. 저작권법에 따른 이용자의 권리는 위의 내용에 의하여 영향을 받지 않습니다. 이것은 이용허락규약(Legal Code)을 이해하기 쉽게 요약한 것입니다. Disclaimer 저작자표시. 귀하는 원저작자를 표시하여야 합니다. 비영리. 귀하는 이 저작물을 영리 목적으로 이용할 수 없습니다. 변경금지. 귀하는 이 저작물을 개작, 변형 또는 가공할 수 없습니다.
이학 석사학위 논문
국민건강보험공단 데이터를 이용한
네트워크 이론 기반 질병 패턴 분석
아 주 대 학 교 대 학 원
의 학 과 /의 학 전 공
국민건강보험공단 데이터를 이용한
네트워크 이론 기반 질병 패턴 분석
지도교수 윤 덕 용
이 논문을 이학 석사학위 논문으로 제출함.
2019 년 2 월
아 주 대 학 교 대 학 원
의학과/의학전공
정 유 진
감사의 글
석사과정을 진행하면서 저의 학위논문이 잘 마무리되어 나오기까지 수많은 분들의 도움이 있었습니다. 그 분들의 도움이 없었다면 논문이 나올 수 없었을 것이기에 이 글을 통해 감사의 인사를 드리고자 합니다. 먼저 석사과정 중 여러가지 어려움이 있던 저를 받아주시고 아낌없이 지도해주신 윤덕용 교수님께 깊은 감사의 뜻을 전합니다. 절 믿어주시고 연구에 대한 지식 뿐만 아니라 연구자로서의 역할과 자질에 대해 많은 것들을 가르쳐주셨습니다. 바쁘신 중에도 꼼꼼하고 면밀하게 지도해주신 교수님 덕분에 한 단계 더 발전할 수 있었고 좋은 연구를 진행 할 수 있었습니다. 감사의 글을 빌려 다시 한번 감사의 뜻을 전합니다. 늘 의료정보학과의 기둥으로 지도해주시고 다독여주셨던 박래웅 교수님, 진로에 대해 진지하게 상담해주시고 연구에 대해 많은 의견을 주셨던 고정길 교수님께 다시 한번 감사드립니다. 그리고 무엇보다 늘 희로애락을 함께한 연구실 사람들에게 감사의 뜻을 전합니다. 특히 석사과정을 무사히 마칠 수 있도록 뒤에서 큰 도움을 준 태영이, 늘 밝은 모습으로 내게 큰 힘이 되어 준 재형이에게 특별히 고마움 마음이 있습니다. 이 둘은 제 연구실 생활의 시작부터 끝까지 늘 한결 같은 모습으로 저에게 큰 힘이 되었습니다. 그 밖에도 늘 엘리트한 모습으로 발표도 곧 잘해서 속으로 많이 부러웠던 종환이, 옆에서 심한 장난도 치고 하소연해도 늘 웃는 얼굴로 잘 받아준 찬민이, 눈이오나 비가오나 누구보다 연구실 생활 성실하게 해서 나 스스로를 많이 반성하게 했던 정구, 이 연구실 사람들이 없었다면 고된 석사과정을 이렇게즐겁게 마무리 할 수 없었습니다. 모두들 정말 고맙습니다. 언제나 변함없이 저를 응원해주신 부모님께 감사의 인사를 드립니다. 대학 졸업 후 많은 실패와 방황 속에서도 조급해하지 말고 천천히 저의 길을 찾으라며 조언해주시고 저를 믿어주셔서 감사합니다. 부모님 덕분에 정말 원하는 공부를 할 수 있었습니다. 아직 남은 단계들이 많지만 언젠가 부모님 은혜 꼭 보답하겠습니다. 그리고 마지막으로 1달 후면 내 아내가 될 내 하나 뿐인 예은이에게 내 모든 공로를 돌리고 싶습니다. 4년전 아무 것도 없던, 늘 신세 한탄만 하던 내 옆에서 현재까지 한결같이 긍정적인 모습으로 기댈 어깨를 제공해줘서 고맙습니다. 당신 덕분에 현재에 내가 있다고 생각합니다. 앞으로의 날들도 지금 마음 변치 않고 늘 함께하고 행복했으면 좋겠습니다. 감사하고 사랑합니다. 지면으로 미처 언급하지 못했지만, 저를 아끼고 격려해주셨던 모든 분들께 진심으로 감사합니다.정말 많은 분들의 도움 덕분에 저는 석사과정을 무사히 마칠 수 있었습니다. 앞으로 더 정진하고 성장하여 다른 이에게 도움이 될 수 있는 존재가 되도록 노력하겠습니다
i 국문 요약 -국민건강보험공단 데이터를 이용한 네트워크 이론 기반 질병 패턴 분석 현재 주요 병원 및 공공기관에서 의료 빅데이터의 규모와 다양성이 증가함에 따라 많은 연구자들이 빅 데이터 기반 의학 연구를 활발히 진행하고 있다. 오랜 기간 동안 유전자 데이터 및 단백질 데이터와 같은 생물학 기반 빅 데이터를 활용한 질병 네트워크 구축은 많았지만 임상 데이터 기반으로 질병 네트워크 구축을 한 사례는 적다. 뿐만 아니라 임상 데이터 기반으로 네트워크를 구축했더라도 데이터의 불완전성, 국내 환자에 대입하기 힘든 해외 데이터, 네트워크 구축 시 중요한 위험 인자 배제 등 여러 가지 한계점이 존재했다. 그래서 본 연구에서는 국민건강보험공단에서 제공하는 표본연구 데이터베이스를 활용하고 질병 발병에 중요한 원인이 되는 위험 인자들을 보정하여 국내 맞춤의 신뢰성 있는 질병 네트워크를 제공하고 더 나아가 질병 네트워크의 구조적 특징을 분석하여 질병의 패턴 및 중요성 정보를 제시하고자 한다. 선행질병이 후행질병 발병의 위험 인자로써 영향을 준다는 전제하에 국민건강보험공단 표본연구 데이터베이스의 2002년부터 2013년까지의 환자들의 발병 순차 데이터를 활용하여 질병간의 연결성을 분석하였다. 많은 질병의 발병 위험 인자인 성별, 나이 그리고 방문 시기를 정확 매칭을 통해 보정하고 피셔의 정확성 검정을 통해 유의성 검정을 거쳤다. 네트워크의 구조적 특징 및 질병의 역할을 분석하기 위해 커뮤니티 탐지와 중심성 계산을 진행하였다. 그 결과, 839개 질병과 2,757개의 연결성으로 이루어진 질병 네트워크를 구축하였다. 뇌전증, 무과립구증과 같이 여러 질병의 발병의 원인 또는 결과가
되는 것으로 밝혀진 질병들이 네트워크 상에서 많은 연결성을 가지고 있었으며 서로 영향을 많이 주는 것으로 알려진 정신 및 행동 장애 질병들 경우 네트워크 상에서도 서로 많이 연결된 것을 확인할 수 있었다. 5개의 중심성을 계산한 결과 파종성 혈관내응고가 모든 중심성에서 상위에 위치해있었고 통합 중심성에서도 가장 높은 것으로 나왔다. 커뮤니티 탐지 결과 4개의 대표 커뮤니티들을 발견할 수 있었고 각 대표 커뮤니티들은 질병 분류, 성별, 나이와 같은 요인들로 군집화 된 것이 아니라 보험 청구 데이터 분석에서 나온 질병 패턴 기반으로 구성된 것을 확인할 수 있었다. 국민건강보험공단 표본연구 데이터베이스 기반으로 질병 네트워크를 구축함으로써 기존 알려진 질병간의 연결성 또는 질병의 특성을 재확인하고 더 나아가 질병의 군집화 및 패턴을 다각도로 제공함으로써 임상의에게 진단에 대한 도움을 줄 도구로써 활용될 것으로 기대된다. 핵심어: 국민건보험공단 데이터베이스, 네트워크 의학, 질병 패턴, 위험 인자
iii
차 례
국문 요약 ··· i 차 례 ··· iii 그림 차례 ··· v 표 차례 ··· vi 수식 차례 ··· vii I. 서 론 ··· 1 A. 연구의 배경 및 필요성 ··· 1 1. 네트워크 과학 ··· 1 2. 네트워크 의학 ··· 3 (A) 유전자 네트워크 ··· 3 (B) 단백질 네트워크 ··· 4 (C) 임상 네트워크 ··· 5 B. 연구의 목적 ··· 6 II. 연구대상 및 방법 ··· 7 A. 분석 대상 데이터 ··· 7 B. 한국표준질병·사인분류 기반 질병 정의 ··· 9 C. 질병-질병 연결성 ··· 10 1. 질병간의 연결성 정의 및 빈도 ··· 10 2. 위험 인자 보정 ··· 11 3. 질병간의 연결성 유의성 검정 ··· 12D. 질병 네트워크 구축 ··· 14 E. 질병 중심성 분석 ··· 15 1. 연결 중심성 ··· 15 2. 고유벡터 중심성 ··· 16 3. 근접 중심성 ··· 17 4. 매개 중심성 ··· 18 5. 통합 중심성 ··· 19 F. 질병 네트워크 커뮤니티 탐지 ··· 20 G. 프로그래밍 언어 ··· 22 III. 결과 ··· 23 A. 국민건강보험공단 표본연구 데이터베이스 분석 ··· 23 B. 질병 네트워크 ··· 27 C. 기존 진단 네트워크와 비교 ··· 33 D. 질병 네트워크 기반 질병 중요도 ··· 34 E. 질병 네트워크의 대표 커뮤니티 ··· 37 1. 정신질환 관련 커뮤니티 ··· 38 2. 호흡기질환 관련 커뮤니티 ··· 43 3. 암 관련 커뮤니티 ··· 46 4. 뇌질환 관련 커뮤니티 ··· 51 IV. 고 찰 ··· 55 V. 결 론 ··· 58 참고문헌 ··· 59 ABSTRACT ··· 64
v
그림 차례
그림 1. 노드의 진입 차수와 출력 차수 예시 ··· 2 그림 2. 환자 발병 기록 선택편의 최소화 예시 ··· 8 그림 3. 선행질병 발병군과 비발병군 정확 매칭 과정 ··· 11 그림 4. 선행질병 → 후행질병 연결성의 이차원 분할표 ··· 13 그림 5. 중심성 종류별 중요도가 높은 노드 예시 ··· 19 그림 6. 대표커뮤니티1에 신생물 그룹 질병 분포 유의성 검정을 위한 이차원 분할표 ··· 21 그림 7. 질병 네트워크 ··· 28 그림 8. 파종성혈관내응[탈피브린증후군]과 연결된 질병 모음 ··· 34 그림 9. 질병 네트워크 내 4개의 대표 커뮤니티 ··· 37 그림 10. 정신질환 관련 커뮤니티 ··· 39 그림 11. 호흡기질환 관련 커뮤니티 ··· 43 그림 12. 암 관련 커뮤니티 ··· 47 그림 13. 뇌질환 관련 커뮤니티 ··· 52표 차례
표 1. 국민건강보험공단 표본연구 데이터베이스에서 사용한 테이블 및 열 정보 ··· 8 표 2. 국민건강보험공단 표본연구 데이터 변수별 수치 ··· 24 표 3. 한국표준질병·사인분류 대분류별 평균 전체 차수, 진출 차수 그리고 출력 차수 ··· 29 표 4. 상대위험도 상위 20 연결성 및 빈도 상위 20 연결성 ··· 30 표 5. 중심성별 상위 20개 질병 ··· 35 표 6. 정신질환 관련 커뮤니티에 속한 질병 정보 ··· 39 표 7. 호흡기질환 관련 커뮤니티에 속한 질병 정보 ··· 44 표 8. 암 관련 커뮤니티에 속한 질병 정보 ··· 48 표 9. 뇌 관련 장애 커뮤니티에 속한 질병 정보 ··· 53vii
수식 차례
수식 1 ··· 15 수식 2 ··· 16 수식 3 ··· 17 수식 4 ··· 18 수식 5 ··· 19I. 서 론 A. 연구의 배경 및 필요성 1. 네트워크 과학 지난 수십 년 동안 사회전반에서 데이터가 기하급수적으로 쌓여감에 따라 빅데이터 활용에 대한 관심도가 꾸준히 상승하고 있고 그 결과 빅데이터 기반의 다양한 모델이 개발되고 여러 가지 분석법들을 통해서 새로운 결과를 얻어내려는 노력들이 늘어나고 있다(Chiang et al., 2012; Haider, 2015). 보건의료분야 또한 의료빅데이터 기반 질병 감시 및 예측 시스템, 환자 맞춤형 치료, 신약후보군 탐색 등의 연구가 활발히 진행되고 있고 더 나아가 이를 통해 보건의료정책 수립에 기여하기위해 노력하고 있다(Bhardwaj et al., 2018; Nanayakkara et al., 2018; Raghupathi et al., 2014). 의료빅데이터를 분석하기 위해 여러 가지 분석법들이 제시되었고 그 중 네트워크 과학은 최근 기존 연구와 다른 새로운 방향성을 제시해주는 분석법으로 각광 받고 있다(Barabasi et al., 2011; Vidal et al., 2011; Zhou et al, 2014). 네트워크
과학은 수학의 그래프 이론에서 비롯되었으며 특정 분야에 국한된 정보를 제공하기보다는 다영역을 포괄하는 전반적인 정보를 제공함으로써 서로의 상호관계 및 패턴이 어떠한 구조적 특징을 가지고 있는지 시각화해준다. 네트워크는 노드(node)와 그 노드들을 연결하는 간선(edge)으로 구성되어있는 집합이며 그 성격에 따라 여러 가지 모델로 정의된다. 대표적인 네트워크 모델은 가중치 네트워크 , 방향성 네트워크, 또는 가중치 방향성 네트워크가 있다. 가중치 네트워크란 간선에 특정 변수를 가중치로 두어 표현하는 방식으로 모든 노드간의 연결성을 동등하게 보지 않고 강도를 주어 간선의 차이를 정의할 수 있는 네트워크이다. 방향성 네트워크란 간선에 방향성이 존재하는 네트워크를 의미하며 노드의 차수(degree)는 진입 차수(in-degree)와 출력 차수(out-degree)로 나뉜다. 노드의 차수란 노드와
2 -간선의 수를 의미하고 출력 차수는 노드를 기준으로 나가는 방향의 -간선의 수를 의미한다 (그림 1). 가중치 뱡향성 네트워크는 가중치와 방향성 둘 다 존재하는 네트워크를 의미한다. 현재 의학, 경제학, 전산학, 생물학 등 여러 분야에서 네트워크 분석 기반으로 연구가 진행되고 있다. 그림 1. 노드의 진입 차수와 출력 차수 예시
2. 네트워크 의학 네트워크 의학이란 네트워크 과학을 응용하여 유전자, 단백질, 약물 또는 질병의 연결성 등을 다각도로 확인하고 분석하는 학문을 의미한다. 의학 연구에서 대표적인 네트워크로는 유전자 네트워크, 단백질 네트워크, 그리고 임상 네트워크가 존재한다. (A) 유전자 네트워크 유전자 네트워크란 여러 가지 유전자 정보를 이용하여 유전자간 또는 질병간의 관계를 분석하는 네트워크이다(Bauer-Mehren et al., 2011; Ozgur et al., 2008; Park et al., 2009; Wang et al., 2011). 예를 들어, 유전자의 생물학적 경로(pathway) 정보를 포함하고 있는 케그(Kyoto Encyclopedia of Genes and Genomes, KEGG) 데이터베이스를 활용하여 같은 생물학적 경로에 속한 유전자들끼리 연결 시켜 네트워크를 구축하여 유전자간의 연관성을 확인하거나(Kanehisa et al., 2010), 또는 질병과 관련된 유전자 정보를 포함하고 있는 OMIM (Online Mendelian Inheritance in Man) 데이터베이스를 기반으로 같은 유전자에 돌연변이(locus heterogeneity)가 있는 경우 질병을 연결하여 질병간의 연결성을 정의하는 연구가 진행됐다(Goh et al., 2007). 유전자 네트워크는 유전 질환간의 연결성을 분석하는데 크게 기여하였지만, 비 유전 질환간의 연결성을 정의할 수 없는 한계점을 가지고 있다.
4
-(B) 단백질 네트워크
단백질 네트워크란 단백질 상호 작용 (Protein-Protein Interation, PPI) 정보를 기반으로 구축하는 네트워크를 의미한다(Jeong et al., 2001; Lim et al., 2006; Yook et al., 2004). 단백질 상호 작용이란 단백질 간의 직접적 연결(물리적 연결) 또는 간접적 연결(기능적 연결)를 의미하며 질병 상태의 세포 생리를 이해하는 데 중요한 역할을 한다. 특히 약물재창출을 목적으로 다량의 단백질을 상호작용 데이터를 포함하고 있는 STRING (Search Tool for the Retrieval of Interacting Genes/Protein) 데이터베이스를 활용하여 단백질 상호 작용 네트워크를 구축 및 분석하는 연구가 활발히 이루어지고 있다(Wu et al., 2009).
(C) 임상 네트워크
최근 임상 데이터가 늘어남으로써 임상 데이터 기반으로 질병 네트워크를 구축하는 사례가 늘어나고 있다. 특히 청구 데이터는 유전 및 비 유전 질환의 진단 내역 및 성별 및 연령과 같은 위험 요인에 대한 정보를 다수 포함하고 있어 다른 인구 통계 학적 배경을 가진 환자 간의 차이, 질병 진행 등을 연구하는 데 유용하다(Hidalgo et al., 2009; Jeong et al., 2017). 예를들어 Jeong et al.에서는 국민건강보험공단 표본연구 데이터를 기반으로 질병 네트워크를 구축 및 분석하였고 Hidalgo et al.에서는 미국 보험 청구 자료인 Medicare 데이터베이스를 이용하여 질병 네트워크를 구축하였다. 하지만 Jeong et al. 연구는 위험 인자인 성별, 나이 등을 전혀 보정하지 않았고, Hidalgo et al. 연구에서 사용한 메디케어 데이터베이스는 노인의 입원 기록만을 포함하고 있어 여러 가지 한계점을 가졌다. 질병간의 연결성을 연구하기위해 고려해야할 여러가지 위험 인자(risk factor)들이 존재한다. 위험 인자는 질병을 발병시킬 가능성을 높이는 특성, 상태 또는 행동을 의미하며 개별적으로 질병 발병에 영향을 줄 수 있지만 여러 개의 위험 인자들이 서로 상호 작용하는 경우도 많다(Cohen et al., 1993; Farrer et al., 1997; Meisinger et al., 2002; Piccinelli & Wilkinson, 2000). 특히 여러 위험 인자 중 환자의 선행질병이 후에 질병 발병에 영향을 주는 것은 많은 연구에서 밝혀졌다(Sarnak et al., 2003; Vagelatos et al., 2013).
6 -B. 연구의 목적 본 연구에서는 국민건강보험공단 표본연구 데이터베이스를 이용하여 여러 위험 인자들이 보정된 국내 맞춤 질병 네트워크를 구축하여 질병과 연결성을 심층 분석하고 임상의에게 진단을 도울 수 있는 가이드라인을 제공하는데 의의를 두고 있다.
II. 연구대상 및 방법 A. 분석 대상 데이터 본 연구에서는 국민건강보험공단에서 공유하는 표본연구 데이터베이스를 사용하였다. 국민건강보험공단 표본연구 데이터베이스는 전체 보험 가입자 모집단의 약 2 %(약 100 만명)의 2002 년 1 월부터 2013 년 12 월까지 청구자료를 포함하는 자료이며 환자의 모든 사립 및 공립 병원 방문을 포함하고 있다. 표본연구 데이터베이스는 성별, 연령대 및 거주지역등과 같은 환자 정보를 포함하고 있는 자격 및 보험료 테이블, 출생정보 및 사망원인 내용을 포함하고 있는 출생 및 사망 테이블, 진료 받은 내역에 대해 요양급여가 청구된 자료를 포함하고 있는 진료 테이블, 일반건강검진 관련 자료를 포함하고 있는 건강검진 테이블, 그리고 요양기관 정보를 포함하고 있는 요양기관 테이블로 구성되어있다. 본 연구에서는 네트워크 구축을 위한 자료로 질병의 발병자료만을 사용하였기 때문에 환자별 각 질병의 첫 번째 진단 자료만 추출하여 새롭게 테이블을 구성하였다(표 1). 하지만 표본연구데이터베이스는 2002 년 이전의 기록을 포함하고 있지 않기 때문에 2002 년의 발병한 질병들이 그 이전에 발병했을 가능성이 존재한다. 따라서 불완전한 데이터에 의한 생길 수 있는 선택편의(selection bias) 문제점을 최소화하기 위해 2002 년에 발병한 질병은 제외하였고 2003 년의 진료 기록부터 사용하였다(그림 2). 환자의 나이 정보 같은 경우 원본 데이터는 5 년 단위로 연령대를 그룹화하여 제공하였지만 환자의 연도별 진단 기록 정보를 기반으로 계산하여 환자의 태어난 해 정보를 구했다. 예를 들어 한 환자가 2003 년 기록에 나이 그룹 3(10~14 세)에 속해있었고 2005 년 기록에 나이 그룹 4(15 세~19 세)에 속해있었다면 이 환자의 나이를 2003 년 기준으로 13 세 인 것을 유추할 수 있다. 전체 환자 중 약 2,000 명(전체 환자의 약 0.2%)의 환자들은 태어난 해 정보를 연 단위로
8 -구하기에 충분한 진단 기록을 가지고 있지 않아 연령대 그룹의 중간값으로 나이를 설정하여 태어난 해를 계산하였다. 소스 테이블 및 필드 필드 내용 자격 테이블.person_id 환자 ID 자격 테이블.sex 성별 정보 자격 테이블.age_group 환자의 태어난 해 진료내역 테이블.recu_fr_dt 방문 날짜 진료 내역 테이블.sick_sym 진단 코드 표 1. 국민건강보험공단 표본연구 데이터베이스에서 사용한 테이블 및 열 정보 그림 2. 환자 발병 기록 선택편의 최소화 예시
B. 한국표준질병·사인분류 기반 질병 정의
국민건강보험공단 표본 연구데이터베이스의 진료 내역 테이블에 진단 코드는 제 6 차 한국표준질병·사인분류(The 6th edition of Korean Standard Classification of Diseases, KCD-6)로 이루어져 있다. 제 6 차 한국표준질병·사인분류는 의무기록자료에 진단을 정의할 때 그 성질의 유사성에 따라 체계적으로 코드화한 것으로 제 10 차 국제질병사인분류(International Classification of Diseases, 10th Revision, ICD-10) 체계를 근거로 표준화된 한국표준질병 용어체계이다. 한국표준질병·사인분류는 대분류, 중분류, 소분류(3 단위), 세분류(4 단위), 세세분류(5 단위)로 나누어질 수 있으며 코드의 첫자리는 알파벳, 나머지 자리는 숫자로 이루어져 있다. 진단의 기본분류는 소분류인 3 단위분류이기에 본 연구에서는 진단 코드의 3 단위 코드만 사용하였다. 예를 들어 “신경학적 합병증을 동반한 1 형당뇨병(KCD-6 코드: E10.4)”과 “순환계 합병증을 동반한 1 형 당뇨병(KCD-6 코드: E10.5)”는 똑같이 “1 형 당뇨병(KCD-6 코드: E10)” 진단으로 변환되었다. KCD-6 코드 중 질병으로 정의하기 불확실한 진단들로 간주된 진단 코드들은 데이터에서 제외하였다(Jensen et al., 2014). 제외한 코드들은 “임신, 출산 및 산후기(KCD-6 코드: O00-O99)”, “달리 분류되지 않은 증상, 징후와 임상 및 검사의 이상소견(KCD-6 코드: R00-R99)”, “질병이환 및 사망의 외인(KCD-6 코드: V01-Y98)”, “건강상태 및 보건서비스 접촉에 영향을 주는 요인(KCD-6 코드: Z00-Z99)” 그리고 “특수목적 코드(KCD-6 코드: U00-U99)” 이다. 국민건강보험공단에서 민감상병으로 정의한 진단 코드(남성 생긱기관의 양성 신생물, 기타 선천성 감염 및 기생충 질환등)는 대분류(1 단위) 정보만 제공되어있기 때문에 데이터에서 제외하였고 최종적으로 1,418 개의 진단을 질병으로 정의하였다.
10 -C. 질병-질병 연결성 1. 질병간의 연결성 정의 및 빈도 질병의 연결성은 선행질병이 후행질병에 직접적인 영향을 준다는 전제하에 분석하였다. 우선 환자별로 모든 질병 발병기록을 순차적으로 정렬하고 모든 질병-질병 관계 종류를 구하였다. 예를 들어 한 환자가 진단을 {A, B, C, D}라는 순서로 진단을 받았다면 A→B, A→C, A→D, B→C, B→D, C→D 라는 연결성이 존재하는 것으로 정의하였다. 만약 같은 날에 여러 개의 진단을 받았을 경우, 서로의 방향으로 연결성이 존재한다고 가정하였다 (예를 들어 A, B 가 같은 날에 진단받았다면 A→B 와 B→A 가 존재). 환자 중 최소 2 건 이상의 질병 발병 기록이 존재하는 경우만 데이터로 활용하였다.
2. 위험 인자 보정 선행질병 외에 질병 발병에 영향을 줄 수 있는 인자인 환자의 성별, 나이, 방문 시기를 보정하기 위해 선행질병이 있었던 그룹(발병군)과 없었던 그룹(비발병군)으로 나누어 1 대 4 정확 매칭을 진행한 후 각 질병-질병 연결성의 빈도를 확인하였다(그림 3). 성별과 태어난 해가 같고 방문 시기가 같은 연도 같은 주일 경우에만 매칭을 진행하였다. 방문 시기를 보정한 이유는 시기에 따라 병원 환경 또는 정책이 바뀔 수 있다는 가능성을 최대한 보정하기 위함이다. 그림 3. 선행질병 발병군과 비발병군 정확 매칭 과정
12 -3. 질병간의 연결성 유의성 검정 연결성의 유의성을 확인하기 위해 피셔의 정확성 검정(Fisher’s Exact test)을 수행하였고 본 연구에서는 선행질병이 있었을 경우 후행질병으로 진행할 확률이 선행질병이 없었을 경우 후행질병으로 진행할 확률과 차이가 없다는 것을 귀무가설로 차이가 있다는 것을 대립가설로 설정하였다. 그림 4 는 피셔의 정확성 검정을 진행하기 위해 만든 이차원 분할표 (2x2 contigency table) 예시이며 a 는 선행질병이 있었던 환자 중 후행질병이 발병된 건 수, b 는 선행질병이 있었던 환자들 중 후행질병이 발병되지 않았던 건 수, c 는 선행질병이 없었던 환자들(선행질병이 있었던 환자와 성별, 나이, 방문 시기를 기준으로 1 대 4 매칭이 된 환자 그룹) 중 후행질병이 발병된 건 수, d 는 선행질병이 없었던 환자 중 후행질병이 발병되지 않았던 건 수를 의미한다. 데이터에 확인된 471,140 개의 연결성에 대해 각각 이차원 분할표를 만들어 검정과정을 거쳤다. 피셔의 정확성 검정에서 유의 확률(probability value, p-value)과 상대위험도(relative risk)를 기반으로 연결성의 유의함을 확인하였다. 여기서 유의 확률이란 귀무가설이 참임에도 불구하고 대립가설을 참으로 잘못 선택하는 제 1 종 오류를 범할 확률을 의미한다. 예를 들어 유의확률이 0.05 이면 귀무가설을 잘못 기각할 가능성이 5%임을 인정하는 것과 같다. 본 연구에서 상대위험도란 선행질병이 있는 경우 후행질병이 발병할 확률과 선행질병이 없는 경우 후행질병의 비로 정의되고 상대 위험도가 클수록 선행질병과 후행질병 간의 연관성이 큰 것으로 간주한다. 그림 1 의 이차원 분할표 기준으로 상대위험도 수식은 다음과 같다. 상대위험도 다중비교에서 올 수 있는 오류를 보정하기위해 본페로니 교정(Bonferroni correction)을 시행하였다. 본페로니 교정은 검정하는 가설의 숫자가
늘어남으로써 중가할 수 있는 제 1 종 오류를 보정하는 방법으로 n 이 가설의 수라고 정의하였을 때 유의확률을 n 으로 나누어 새로운 유의확률로 정의한다. 최종 본페로니 교정을 거친 유의확률이 0.001 보다 작고 상대위험도가 4 이상이고 a 의 건 수가 최소 22 건 이상인 연결성만이 유의한 연결성으로 선택하였다. 그림 4. 선행질병 → 후행질병 연결성의 이차원 분할표
14 -D. 질병 네트워크 구축 본 연구에서 네트워크의 노드는 질병으로, 간선은 질병간의 연결성으로 정의하였다. 노드의 색깔은 한국표준질병·사인분류의 대분류 기준으로 정의하였다. 노드의 가로 길이는 여성의 연별 평균 발병 건 수, 세로 길이는 남성의 연별 평균 발병 건 수를 의미한다. 간선의 두께는 연결성의 상대위험도 기반으로 설정하였다. 네트워크의 레이아웃은 노드와 간선의 가중치, 간선의 연결성에 따라 연관성 높은 노드끼리 가깝게 배치하는 포스-디렉티드(force-directed) 레이아웃을 사용하였다.
E. 질병 중심성 분석
구축된 네트워크 상에 질병의 상대적 중요성을 확인하기 위해 각 질병의 중심성(centrality) 지표를 확인하였다. 중심성은 네트워크 상에서 어느 노드가 상대적으로 중요한지 찾기 위해 생긴 척도로써 중심성 지수는 그 계산 방법에 따라 다르다. 여러가지 중심성 지표들 중 대표적으로 연결 중심성(degree centrality), 고유벡터 중심성(eigenvector centrality), 근접 중심성(closeness centrality), 그리고 매개 중심성(betweenness centrality)이 노드의 중심성을 확인하기 위해 널리 사용되고 있다. 1. 연결 중심성 연결 중심성이란 노드가 얼마나 많은 연결성을 가졌는지 확인하는 지표로써 연결성이 많은 노드가 네트워크상에서 중요한 역할을 한다는 가정에서 나온 지표이다. 방향성 있는 네트워크 같은 경우 진입 차수는 노드의 인기도를 의미하며 출력 차수는 그 노드의 영향력을 알 수 있다고 정의한다. 하지만 단순히 이웃 노드(First neighbor)만을 고려하기 때문에 국지적인 범위에서의 역할만을 의미한다. 연결 중심성의 수식은 아래와 같다.
는 와 의 연결 유무를 의미하여 연결이 존재하면 1, 존재하지 않으면 0이다. 은 전체 노드의 수를 의미한다. 방향성 네트워크에서는 진입 차수와 출력 차수가 존재할 수 있으며 본 연구에서는 두 차수를 따로 계산하지 않고 전체 차수를 계산하였다.16 -2. 고유벡터 중심성 고유벡터 중심성이란 연결 중심성과 같이 단순히 연결성이 많은거 보다 중요도가 높은 노드와 연결된 노드일수록 중요도가 높아지는 지표이다. 예를 들어, 매우 강력한 영향력을 가진 한 노드와 연결되어 것이 경우에 따라서 다른 여러 평범한 노드들과 연결된 것보다 더 유용할 수 있다는 거와 같다 (Bonacich 1987, 2007). 고유벡터 중심성 계산 수식은 아래와 같다.
는 와 의 연결 유무를 의미하여 연결이 존재하면 1, 존재하지 않으면 0이다. 은 전체 노드의 수, 는 의 고유벡터 중심성 값, 은 고윳값을 의미한다. 고유벡터 중심성은 하나의 산식으로 도출되는 것이 아니라 인접행렬을 이용하여 값에 대한 고유벡터를 계산하는 과정을 거친다. 예를 들어, 노드A의 고유벡터중심성을 구하기 위해서는 노드A와 이웃으로 연결된 노드들의 연결 중심성 값의 합(1단계 고유벡터 중심성)을 구한다. 노드A와 이웃으로 연결된 노드들과 연결된 노드들의 1단계 고유벡터 중심성 값의 합을 2단계 고유벡터 중심성으로 정의한다. 이런 식으로 단계별 계산과정을 계속 거치고 최종 고유벡터 중심성 값이 변하지 않을 때 그 값을 고유벡터 중심성 값으로 정의한다. 방향성 네트워크에서는 진입 고유벡터 중심성(in-eigenvector)과 출력 고유벡터 중심성(out-eigenvector)이 존재할 수 있으면 본 연구에서는 두 고유벡터 중심성을 따로 구하지 않고 전체 고유벡터 중심성을 계산하였다.3. 근접 중심성 근접 중심성이란 노드가 네트워크에 있는 모든 다른 질병까지 도달하기 위한 평균 단계(step) 수를 기반으로 중요도를 확인하는 지표이다(Sabidussi, 1966). 근접 중심성이 높다면 네트워크 상 다른 질병들과 더 가깝게 연결되어 있다는 의미이다. 근접 중심성 계산 수식은 아래와 같다.
는 에서 까지의 최단 경로의 길이, 은 전체 노드의 수를 의미한다. 방향성 네트워크에서는 진입 근접 중심성(in-closeness)와 출력 근접 중심성(out-closeness)가 존재할 수 있으며 본 연구에서는 두 근접 중심성을 따로 계산하지 않고 전체 근접 중심성으로 계산하였다.18 -4. 매개 중심성 매개 중심성이란 네트워크 상 모든 노드 간의 최단 거리들(shortest paths)에 노드가 얼마나 많이 속해있는지 계산하여 중요도를 확인하는 지표이다(Freeman, 1977). 매개 중심성이 높다면 다른 질병들간의 연결하는 중계자 역할로 많이 사용된다는 의미로 해석할 수 있다. 매개 중심성 계산 수식은 아래와 같다.
는 와 사이에 존재하는 최단거리 경로가 를 포함하는 수, 는 와 사이에 존재하는 최단거리 경로의 경우의 수를 의미한다. 본 연구에서는 매개 중심성을 계산할 때 방향성을 고려하도록 설정하였다.5. 통합 중심성 앞서 언급된 4가지 중심성은 서로 다른 접근으로 노드의 중심성를 확인하는 방법임으로 네트워크에 따라 각기 다른 노드들을 중요하다고 판단할 수 있다(그림 5). 4가지 중심성들이 내포한 정보가 서로 겹치지 않기 때문에(Valente et al., 2008) 지표들을 통합하여 노드들의 통합 중심성을 확인하였다. 노드의 통합 중심성 계산 수식은 다음과 같다. max ∈ max ∈ max ∈ max ∈ 는 노드, ()는 연결 중심성, ()는 매개 중심성, ()는 근접 중심성, ()는 고유벡터 중심성, ()는 통합 중심성을 의미한다. 각 중심성은 서로 다른 단위를 가지고 있기때문에 min-max 스케일링 과정을 거쳐 모든 중심성을 0과 1사이의 값으로 변환하였고 표준화된 4가지 중심성 값들의 평균을 통합 중심성으로 정의하였다.
20 -F. 질병 네트워크 커뮤니티 탐지 질병 네트워크의 구조적 특징을 확인하기 위해 커뮤니티 탐지(community detection)을 진행하였다. 커뮤니티란 네트워크의 하위구조를 의미하며 같은 커뮤니티에 속한 노드들은 서로 밀접하게 연결되어있지만 다른 커뮤니티와는 연결성이 적게 연결되어 있다. 여러가지 커뮤니티 탐지 알고리즘 중 가장 성능이 좋은 인포맵(Infomap) 알고리즘을 사용하여 커뮤니티 탐지를 하였다(Aldecoa et al., 2013; Lancichinetti et al., 2009). 인포맵 알고리즘이란 맵 방정식(Map equation)을 이용하여 네트워크 간 이동과 네트워크 내 이동 경로 정보를 최소화하는 엔트로피를 구해서 하위구조를 밝히는 알고리즘이다. 본 연구에서는 노드가 30개 이상 속해있는 커뮤니티를 대표커뮤니티로 정의하여 추가 심층분석을 진행하였다. 대표커뮤니티에서 각각 어떤 질병군이 유의하게 많이 분포되어있나 확인하기 위해 KCD-6 대분류 기준으로 피셔의 정확성 검정을 진행하였다(그림 6). 예를 들어 “신생물(C00-D48)” 그룹이 대표커뮤니티 1에 유의하게 분포하는지 확인하기 위해서 그림 6과 같은 이차원 분할표를 만들어 진행하였다. 그림 4에서 a는 대표커뮤니티1에 속해있고 신생물 그룹에 속해있는 질병 수, b는 대표커뮤니티1에 속해있지만 신생물 그룹에 속해있지 않는 질병 수, c는 대표커뮤니티1 외 다른 커뮤니티들에 속해있고 신생물 그룹에 속해있는 질병 수, d는 대표커뮤니티1 외 다른 커뮤니티들에 속해있지만 신생물 그룹에는 속해있지 않는 질병 수를 의미한다. 유의확률은 0.05보다 작고 상대위험도는 1보다 큰 경우만 질병군이 대표커뮤니티에 유의하게 많이 분포해있다고 판단하였다.
신생물 그룹 질병 수 신생물 외 질병 수 대표커뮤니티1
a
b
대표커뮤니티1 외 다른 커뮤니티c
d
그림 6. 대표커뮤니티1에 신생물 그룹 질병 분포 유의성 검정을 위한 이차원 분할표22 -G. 프로그래밍 언어 국민건강보험공단 표본연구 데이터베이스는 에스큐엘 서버(SQL server)로 구축되었고 질병-질병 연결성 추출 및 빈도 작업은 파이썬(python)으로 진행하였다. 파이썬의 멀티프로세싱(multiprocessing) 모듈을 활용하여 프로그램을 병렬 처리해 수행시간을 최소화하였다. 피셔의 정확성 검정을 포함한 통계검정은 프로그래밍 언어 R을 사용하였고 R 패키지인 아이그래프(igraph) 패키지를 사용하여 네트워크 중심성 분석을 진행하였다. 싸이토스케이프(Cytoscape) 프로그램을 이용하여 네트워크 시각화를 진행하였다.
III. 결과 A. 국민건강보험공단 표본연구 데이터베이스 분석 2003 년~2013 년까지 데이터에 존재하는 진단 기록은 49,886,769 건이였고 환자의 수는 1,113,655 명 그 중 남자는 558,186 명 여자는 555,469 명 이였다. 환자 나이대 특징을 살펴보면 0-9 세(2003 년 기준 나이)가 수가 가장 많았으며 평균 발병 건 수는 60-69 세가 52.07 건으로 가장 높았다(표 2). 전체 환자의 평균 발병 수는 44.8 개이고 가장 발병 건 수가 많은 환자는 242 개 가지고 있었다. 방문 경로별 건 수를 살펴보면 기록이 되지 않은 경우가 90.5%로 가장 많았고 그 다음 외래, 입원, 응급 순으로 많았다. 연도별 환자 수 및 건 수를 살펴보면 연도별 환자 수 범위는 762,139 명~803,364 명, 건 수 범위는 3,393,370 건~3,907,501 건으로 연도별 차이가 크지 않았다. 발병 기록이 1 건이라도 있는 질병 종류는 총 1,418 개였고 발병 건 수가 가장 많은 질병은 “위염 및 십이지장염(KCD-6 코드:K29)”이었고 그 다음으로 “혈관운동성 및 알레르기성 비염(KCD-6 코드:J30)“이 가장 많았다.
24 -변수 데이터 성별 (비율 %)환자 수 여성 555,469 (49.9) 남성 558,186 (50.1) 나이 (2003년 기준) (비율 %)환자 수 평균 발병 건 수 0-9세 219,713(19.8) ±14.5529.78 10-19세 139,971(12.6) ±10.3427.01 20-29세 165,897(15.0) ±12.8231.46 30-39세 186,585(16.8) ±13.4833.18 40-49세 171,279(15.5) ±15.1839.66 50-59세 99,270(9.0) ±17.6346.95 60-69세 77,391(7.0) ±19.8152.07 70-79세 36,259(3.2) ±20.6747.47 80세 이상 12,505(1.1) ±18.9929.59 방문 경로 (비율 %)건 수 외래 3,545,908(9.0) 입원 123,187(0.3) 응급 60,613(0.2) 알수없음 35,579,108(90.5) 표 2. 국민건강보험공단 표본연구 데이터 변수별 수치
연도별 정보 환자 수 총 발병 건 수 (비율 %) 2003 762,139 3,907,501(9.9) 2004 771,432 3,782,109(9.6) 2005 777,956 3,725,469(9.5) 2006 762,196 3,407,655(8.7) 2007 776,703 3,393,370(8.6) 2008 778,681 3,406,224(8.7) 2009 795,586 3,539,869(9) 2010 771,492 3,412,532(8.7) 2011 801,614 3,696,179(9.4) 2012 803,364 3,583,265(9.1) 2013 795,293 3,454,643(8.8) KCD 대분류 발병 질병 종류 수 (비율 %) 총 발병 건 수 (비율 %) 특정 감염성 및 기생충성 질환(A00-B99) (12.1)172 2,242,211 (5.7) 신생물(C00-D48) (9.7)137 514,701 (1.3) 혈액 및 조혈기관의 질환과 면역메커니즘을 침범하는 특정장애(D50-D89) 34 (2.4) 340,674 (0.9) 내분비, 영양 및 대사 질환(E00-E90) (5.1)73 1,298,870 (3.3) 정신 및 행동 장애(F00-F99) (5.5)78 882,887 (2.2) 신경계통의 질환(G00-G99) (4.8)68 930,175 (2.4)
26 -(3.3) (7.7) 귀 및 유돌의 질환(H60-H95) (1.7)24 1,293,046 (3.3) 순환계통의 질환(I00-I99) (5.4)77 1,230,585 (3.1) 호흡계통의 질환(J00-J99) (4.4)63 7,807,247 (19.9) 소화계통의 질환(K00-K93) (5)71 5,602,047 (14.3) 피부 및 피하조직의 질환(L00-L99) (5.1)72 3,775,492 (9.6) 근골격계통 및 결합조직의 질환(M00-M99) (5.6)79 4,435,117 (11.3) 비뇨생식계통의 질환(N00-N99) (5.8)82 2,074,401 (5.3) 출생전후기에 기원한 특정 병태(P00-P96) (4.2)59 35,157 (0.1) 선천 기형, 변형 및 염색체이상(Q00-Q99) (6.1)87 41,881 (0.1) 손상, 중독 및 외인에 의한 특정 기타 결과(S00-T98) (13.8)195 3,774,943 (9.6)
B. 질병 네트워크 질병간 유의한 연결성을 추출하였을 때 총 839 개 질병과 2,757 개의 연결성(단방향성 연결: 1,390 개, 양방향성 연결: 1,367 개)이 나왔다 (그림 7). 질병 대분류 기준으로 네트워크에 존재하는 질병 특징은 표 3 과 같다. “손상, 중독 및 외인에 의한 특정 기타 결과(KCD-6 코드: S00-T98)” 그룹에 속한 질병들이 122 개로 가장 많았으며 “신생물(KCD-6 코드: C00-D48)” 그룹에 속한 질병들이 그 다음으로 가장 많았다(99 개). 대분류별 평균 차수, 입력차수 그리고 출력차수를 확인해보면 모든 종류의 차수에서 “혈액 및 조혈기관의 질환과 면역메커니즘을 침범한 특정 장애 (KCD-6 코드: D50-D89)”가 가장 높은 것으로 나왔다 (표 3). 한국표준질병·사인분류 3 단위 기준으로 봤을 때 “뇌전증(KCD-6 코드: G40)”이 총 88 개의 연결성으로 가장 많은 연결성을 가지고 있었고 “파종성 혈관내응고(KCD-6 코드: D65)”과 “무과립구증 (KCD-6 코드: D70)”이 그 뒤를 따랐다. 가장 빈도가 높은 질병간의 연결성은 “대상포진(KCD-6 코드: B02)”에서 “달리 분류된 질환에서의 뇌신경장애(KCD-6 코드: G53)”으로 가는 연결성이였고 상대위험도가 가장 높은 연결성은 “아래팔부위의 신경의 손상(KCD-6 코드: S54)”에서 “아래팔 부위의 혈관의 손상(KCD-6 코드: S55)”으로 가는 경우였다 (표 4).
28 -그림 7. 질병 네트워크
한국표준질병·사인 분류 대분류 평균 전체 차수 평균 진출 차수 평균 출력 차수 혈액 및 조혈기관의 질환과 면역메커니즘을 침범한 특정 장애 21.65 11.55 10.1 내분비, 영양 및 대사 질환 15.57 8 7.57 정신 및 행동 장애 14.42 7.19 7.23 신생물 12.39 5.53 6.87 신경계통의 질환 11.87 6 5.87 순환계통의 질환 10.69 5.76 4.93 호흡계통의 질환 9.64 5.02 4.62 눈 및 눈 부속기의 질환 9.47 4.65 4.82 소화계통의 질환 9.29 4.53 4.76 귀 및 유돌의 질환 9.06 4.47 4.59 특정 감염성 및 기생충성 질환( 8.4 4.46 3.94 손상, 중독 및 외인에 의한 특정 기타 결과 8.1 4.16 3.94 비뇨생식계통의 질환 7.3 3.3 4 근골격계통 및 결합조직의 질환 4.83 2.43 2.4 선천기형, 변형 및 염색체이상 4.74 2.48 2.26 피부 및 피하조직의 질환 4.44 2.33 2.12 표 3. 한국표준질병·사인분류 대분류별 평균 전체 차수, 진출 차수 그리고 출력 차수
30 -순위 상대위험도 상위 20 연결성 빈도 상위 20 연결성 선행질병 후행질병 상대위험도 선행질병 후행질병 빈도 1 아래팔 부위의 신경의 손상 아래팔 부위의 혈관의 손상 1,467.32 대상포진 달리 분류된 질환에서 의 뇌신경장 애 24,293 2 렙토스피라병 리케차병기타 627.08 달리 분류되지 않은 귀의 기타 장애 전음성 및 감각신경 성 청력소실 23,748 3 탄광부진폐증 의 진폐증상세불명 579.09 전음성 및 감각신경 성 청력소실 달리 분류되지 않은 귀의 기타 장애 20,474 4 기타 가스, 연무 또는 물김의 독성효과 화학물질, 가스, 훈증기 및 물김의 흡입에 의한 호흡기병 태 530.97 달리 분류되지 않은 귀의 기타 장애 기타 청력소실 15,172 5 달리 분류되지 않은 기타 바이러스출 혈열 렙토스피 라병 525.90 청력소실기타 달리 분류되지 않은 귀의 기타 장애 12,223 6 아래팔 부위의 혈관의 손상 아래팔 부위의 신경의 손상 515.02 달리 분류된 질환에서 의 뇌신경장 애 대상포진 11,660 7 화학물질, 가스, 훈증기 및 물김의 흡입에 의한 호흡기병태 기타 가스, 연무 또는 물김의 독성효과 491.07 머리의 표재성 손상 두개골 및 안면골의 골절 9,094 8 복강내기관의 손상 복부, 아래등 및 골반 부위의 혈관의 손상 467.80 전음성 및 감각신경 성 청력소실 기타 청력소실 8,819 9 관절연골의 골 및 사지의 골 및 443.91 뇌경색증 편마비 8,511 표 4. 상대위험도 상위 20 연결성 및 빈도 상위 20 연결성
양성 신생물 관절연골 의 악성 신생물 10 기타 및 상세불명 유형의 비호지킨림 프종 비소포성 림프종 298.17 두개골 및 안면골의 골절 머리의 표재성 손상 8,336 11 손목 및 손 부위의 혈관의 손상 손목 및 손 부위의 신경의 손상 245.00 두개내손상 두개골 및 안면골의 골절 7,956 12 손목 및 손 부위의 신경의 손상 손목 및 손 부위의 혈관의 손상 234.41 두개골 및 안면골의 골절 두개내손 상 7,483 13 렙토스피라병 달리 분류되지 않은 기타 바이러스 출혈열 226.52 바이러스만성 간염 간 및 간내 담관의 악성 신생물 6,804 14 아래팔 부위의 혈관의 손상 아래팔 부위의 근육 및 힘줄의 손상 222.24 항문 및 직장부의 열창 및 누공 항문 및 직장의 기타 질환 6,285 15 전반발달장애 정신지체중등도 187.89 항문 및 직장의 기타 질환 항문 및 직장부의 열창 및 누공 6,075 16 조혈기관의 혈액 및 기타 질환 림프, 조혈 및 관련 조직의 행동양식 불명 및 미상의 기타 신생물 177.27 망막장애기타 기타 사시 5,529 17 상세불명의 바이러스출 혈열 렙토스피 라병 171.65 기타 장애외이의 달리 분류된 질환에서 의 외이의 장애 5,491 18 기관의 기타 결핵 달리 분류된 감염성 질환에서 의 복막의 장애 166.64 편마비 뇌혈관질환의 후유증 5,411 19 중이의 달리 분류되지 않은 귀 162.35 자궁의 자궁내막 5,047
32 -장애 20 톡소포자충증 거대세포 바이러스 병 160.92 만성 바이러스 간염 간의 섬유증 및 경변증 4,636
C. 기존 진단 네트워크와 비교
위험 인자 보정의 역할을 확인하기 위해 같은 국민건강보험공단 표본연구 데이터베이스를 사용하여 구축한 진단 네트워크(Diagnosis Progression Network, DPN)(Jeong et al., 2017)를 본 연구에서 구축한 네트워크와 비교를 하였다. 진단 네트워크 또한 피셔의 정확성 검정을 통해 유의성 검정을 진행하였고 컷오프 값은 본 연구에서 설정한 것과 같다. 다만 질병으로 정의한 KCD-6 코드에서 차이가 존재하여 두 그룹에서 똑같이 질병으로 정의한 진단 코드만을 선택하여 비교하였다. 진단 네트워크는 700 개의 질병과 3,038 개의 연결성(단방향성: 1,715 개 , 양방향성: 1,323 개)으로 이루어져 있었고 본 연구의 네트워크는 717 개의 질병과 2,351 개의 연결성(단방향성: 1,199 개 , 양방향성: 1,152 개)을 가지고 있었다. 두 네트워크가 공통적으로 포함하고 있는 노드는 총 586 개였지만 연결성은 단방향성 기준(양방향성 연결을 2 개의 단방향성 연결로 정의)으로 1,342 개만이 두 네트워크에서 공통적으로 포함하고 있었다. 진단 네트워크와 본 연구의 네트워크의 노드의 평균 진입 차수와 출력 차수를 두 독립표본 t-검정(two samples t-test)으로 평균 비교하였을 때 진단 네트워크에 속해있는 노드의 평균 진입 차수와 출력 차수가 유의하게 높은 것으로 나왔다 (진입 차수: p-value = 0.000243, 출력 차수: p-value = 0.000143)
34 -D. 질병 네트워크 기반 질병 중요도 네트워크 상 질병의 중요도를 확인하기 위해 모든 질병의 4 개 중심성 및 통합 중심성을 계산하였다(표 5). 연결 중심성이 가장 높은 질병은 “뇌전증(KCD-6 코드: G40)” 이었고, 근접 중심성과 고유벡터 중심성은 “파종성 혈관내응고[탈피브린증후군](KCD-6 코드: D65)”, 매개 중심성은 “복부내 기관의 손상(KCD-6 코드: S36)”이 가장 높았다. 4 개의 중심성을 통합한 통합 중심성 기준으로는 여러 중심성에서 상위권에 있었던 “파종성 혈관내응고[탈피브린증후군](KCD-6 코드: D65)” (연결 중심성 2 위, 근접 중심성 1 위, 매개 중심성 2 위, 고유벡터 중심성 1 위)이 가장 중심성이 높은 질병이었다(그림 8). 그림 8. 파종성혈관내응[탈피브린증후군]과 연결된 질병 모음
중심성 순위 연결 중심성 상위 20개 질병 근접 중심성 상위 20개 질병 매개 중심성 상위 20개 질병 고유벡터 중심성 상위 20개 질병 통합 중심성 상위 20개 질병 1 뇌전증 파종성 혈관내 응고[탈피브 린증후군] 복부내 기관의 손상 파종성 혈관내응고[탈피 브린증후군] 파종성 혈관내 응고[탈피브 린증후군] 2 파종성 혈관내응고[ 탈피브린증 후군] 중등도 및 경도의 단백질-에 너지 영양실조 파종성 혈관내 응고[탈피브 린증후군] 기타 대사장애 복막염 3 무과립구증 달리 분류되지 않은 흉막삼출액 간질 기타 패혈증 간질 4 기타 및 상세불명 부위의 이차성 악성 신생물 복막염 기타 및 상세불명 부위의 이차성 악성 신생물 복막염 무과립구증 5 복막염 무과립구증 두개골 및 안면골의 골절 심장정지 복부내 기관의 손상 6 호흡 및 소화기관의 이차성 악성 신생물 기타 응고결함 복막염 달리 분류되지 않은 호흡부전 중등도 및 경도의 단백질-에 너지 영양실조 7 림프절의 이차성 및 상세불명의 악성 신생물 림프절의 이차성 및 상세불명의 악성 신생물 중등도 및 경도의 단백질-에 너지 영양실조 무과립구증 기타 패혈증 8 중등도 및 경도의 단백질-에너 지영양실조 기타 대사장애 무과립구증 중등도 및 경도의 단백질-에너지 영양실조 기타 및 상세불명 부위의 이차성 악성 신생물 9 기타 패혈증 기타 패혈증 기능저하 및 뇌하수체의 기타 장애 달리 분류되지 않은 흉막삼출액 대사장애기타 10 대사장애기타 기타 및 상세불명 부위의 이차성 악성 신생물 기타 부위의 정맥류 달리 분류된 만성 질환에서의 빈혈 달리 분류되지 않은 흉막삼출액 달리 분류된 림프절의 표 5. 중심성별 상위 20개 질병
36 -빈혈 악성 신생물 12 정동장애양극성 급성 출혈후 빈혈 알코올 사용에 의한 정신 및 행동장애 식도정맥류 림프절의 이차성 및 상세불명의 악성 신생물 13 조현병 식도정맥류 응고결함기타 상세불명의 중증 단백질-에너지 영양실조 달리 분류된 만성 질환에서의 빈혈 14 달리 분류되지 않은 흉막삼출액 달리 분류된 만성 질환에서의 빈혈 하반신마비 및 사지마비 상세불명의 단백질-에너지 영양실조 호흡 및 소화기관의 이차성 악성 신생물 15 부갑상선기 능항진증 및 부갑상선의 기타 장애 호흡 및 소화기관의 이차성 악성 신생물 전신성 홍반루푸스 호흡 및 소화기관의 이차성 악성 신생물 식도정맥류 16 응고결함기타 무기질대사장애 급성 출혈후 빈혈 달리 분류된 병태에서의 흉막삼출액 하반신마비 및 사지마비 17 식도정맥류 달리 분류되지 않은 호흡부전 세균학적으 로나 조직학적으 로 확인되지 않은 호흡기결핵 급성 출혈후 빈혈 급성 출혈후 빈혈 18 및 사지마비하반신마비 지주막하출혈 이뇨제 및 기타 상세불명의 약물; 약제 및 생물학적 물질에 의한 중독 복막의 기타 장애 달리 분류되지 않은 호흡부전 19 운동과다장애 뇌의 악성 신생물 식도정맥류 성인호흡곤란증후군 상세불명의 단백질-에 너지 영양실조 20 복강내기관의 손상 상세불명의 중증 단백질-에 너지 영양실조 기타 패혈증 복강내기관의 손상 심장정지
E. 질병 네트워크의 대표 커뮤니티
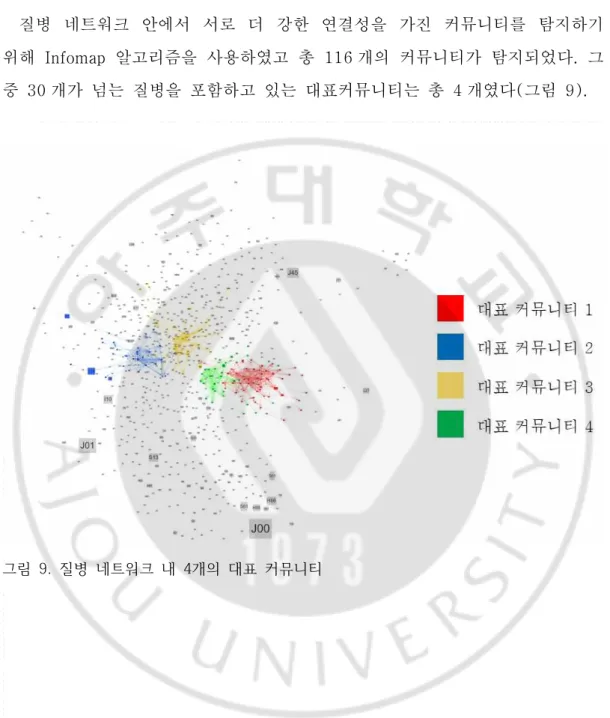
질병 네트워크 안에서 서로 더 강한 연결성을 가진 커뮤니티를 탐지하기 위해 Infomap 알고리즘을 사용하였고 총 116 개의 커뮤니티가 탐지되었다. 그 중 30 개가 넘는 질병을 포함하고 있는 대표커뮤니티는 총 4 개였다(그림 9).
38 -1. 정신질환 관련 커뮤니티 첫 번째 대표커뮤니티는 52 개의 질병을 포함하고 있다(그림 10). 이 대표커뮤니티는 대부분 정신질환과 관련된 질병들을 많이 포함하고 있어 “정신질환 관련 커뮤니티”로 정의하였다. 한국표준질병·사인분류 대분류 기준으로 피셔의 정확성 검정을 시행한 결과 정신 및 행동 장애와 신경계통의 질환이 다른 커뮤니티에 비교하여 이 커뮤니티에서 유의하게 많이 분포하는 것을 확인하였다 (정신 및 행동 장애: p-value=2.46e-10, 신경계통의 질환: p-value=0.0045). 정신질환 관련 커뮤니티의 속한 질병의 특징을 살펴보면 전체 질병 평균 환자 나이는 44.08 세으로 대표커뮤니티 중 가장 낮았다. 연평균 여성 발병 건 수는 206.77 건, 연평균 남성 발병 건 수는 171 건으로 비교적 남성보다 여성이 더 많이 발병하는 질병들을 많이 포함하는 것으로 확인되었다(표 6). 상대위험도가 가장 높은 연결성은 “상세불명의 비기질성 정신병(KCD-6 코드: F29)”에서 “조현정동장애(KCD-6 코드: F25)”으로 진행된 연결성이였으며(상대위험도: 75.98), 가장 빈도가 높은 연결성은 “알콜성 간질환(KCD-6 코드: K70)”에서 “알콜사용에 의한 정신 및 행동 장애(KCD-6 코드: F10)”으로 진행된 연결성이었다(빈도: 3,719).
KCD 대분류 진단명 진단 코드 연평균발병 건수 연평균 여성 건수 연평균 남성 건수 평균 환자 나이 내분비, 영양 및 대사 질환 티아민결핍 E51 7.33 1.58 5.75 52.95 정신 및 행동 장애 알츠하이머병에 서의 치매(G30.-+) F00 1055.0 8 739.00 316.08 68.88 정신 및 행동 장애 달리 분류된 기타 질환에서의 치매 F02 43.58 26.75 16.83 67.40 정신 및 행동 장애 상세불명의 치매 F03 580.25 395.92 184.33 68.47 정신 및 행동 장애 알콜 및 기타 정신활성물질에 의하여 유발된 것이 아닌 섬망 F05 58.67 30.25 28.42 66.05 정신 및 행동 장애 뇌손상, 뇌기능이상 및 신체질환에 의한 기타 정신장애 F06 549.00 341.17 207.83 61.23 정신 및 행동 장애 상세불명의 기질성 또는 F09 27.17 14.33 12.83 53.99 표 6. 정신질환 관련 커뮤니티에 속한 질병 정보 그림 10. 정신질환 관련 커뮤니티
40 -장애 의한 정신 및 행동 장애 정신 및 행동 장애 진정제 또는 수면제 사용에 의한 정신 및 행동 장애 F13 19.58 13.75 5.83 44.38 정신 및 행동 장애 여러 약물 사용 및 기타 정신활성물질의 사용에 의한 정신 및 행동 장애 F19 36.17 22.33 13.83 37.14 정신 및 행동 장애 조현병 F20 529.75 266.83 262.92 43.33 정신 및 행동 장애 조현형장애 F21 19.25 7.67 11.58 37.62 정신 및 행동 장애 망상장애지속성 F22 78.83 40.42 38.42 53.00 정신 및 행동 장애 급성 및 일과성 정신병장애 F23 65.17 36.83 28.33 39.69 정신 및 행동 장애 조현정동장애 F25 57.67 33.92 23.75 40.66 정신 및 행동 장애 기타 비기질성 정신병장애 F28 31.58 17.75 13.83 42.35 정신 및 행동 장애 비기질성 정신병상세불명의 F29 111.08 60.5 50.58 42.89 정신 및 행동 장애 조증에피소드 F30 29.42 16.17 13.25 44.79 정신 및 행동 장애 정동장애양극성 F31 362.08 214.25 147.83 42.90 정신 및 행동 장애 우울에피소드 F32 4243.5 2855.83 1387.67 46.51 정신 및 행동 장애 우울장애재발성 F33 646.08 461.00 185.08 51.24 정신 및 행동 장애 기분[정동]장애지속성 F34 837.00 566.58 270.42 48.15 정신 및 행동 장애 기분[정동]장애기타 F38 184.83 113.92 70.92 45.55 정신 및 행동 장애 기분[정동]장애상세불명의 F39 147.67 91.25 56.42 45.5 정신 및 행동 장애 불안장애공포성 F40 310.75 170.08 140.67 41.54 정신 및 행동 장애 강박장애 F42 169.17 76.17 93.00 34.61 정신 및 행동 장애 심한 스트레스에 대한 반응 및 F43 1410.7 5 865.5 545.25 38.59
적응장애 정신 및 행동 장애 해리[전환]장애 F44 64.42 48.00 16.42 42.06 정신 및 행동 장애 비기질성 수면장애 F51 2011.58 1237.25 774.33 51.66 정신 및 행동 장애 특정 인격장애 F60 77.17 33.50 43.67 35.12 정신 및 행동 장애 습관 및 충동 장애 F63 49.92 15.33 34.58 25.46 정신 및 행동 장애 성인의 인격 및 행동의 상세불명의 장애 F69 2.33 0.58 1.75 41.43 정신 및 행동 장애 특정 발달장애학습술기의 F81 29.5 10.42 19.08 11.53 정신 및 행동 장애 운동과다장애 F90 481.83 104.17 377.67 10.78 정신 및 행동 장애 행동장애 F91 48.58 16.83 31.75 13.64 정신 및 행동 장애 행동 및 정서의 혼합 장애 F92 71.75 36.5 35.25 23.12 정신 및 행동 장애 소아기에만 발병하는 정서장애 F93 171.83 77.58 94.25 10.36 정신 및 행동 장애 소아기 및 청소년기에만 발병하는 사회적 기능수행장애 F94 19.83 8.33 11.50 10.34 정신 및 행동 장애 틱장애 F95 154.17 39.92 114.25 14.66 정신 및 행동 장애 정신장애 NOS F99 81.33 33.67 47.67 30.92 신경계통의 질환 운동실조유전성 G11 17.67 7.33 10.33 48.87 신경계통의 질환 파킨슨병 G20 342.00 207.67 134.33 66.63 신경계통의 질환 파킨슨증이차성 G21 105.67 62.25 43.42 65.38 신경계통의 질환 달리 분류된 질환에서의 파킨슨증 G22 48.42 27.08 21.33 65.80 신경계통의 질환 기저핵의 기타 퇴행성 질환 G23 15.67 8.50 7.17 61.38 신경계통의 질환 기타 추체외로 및 운동 장애 G25 569.25 338.83 230.42 53.32 신경계통의 질환 알츠하이머병 G30 174.58 117.42 57.17 68.50
42 -기타 퇴행성 질환 소화계통의 질환 알콜성 간질환 K70 2231.00 352.92 1878.08 48.51 손상, 중독 및 외인에 의한 특정 기타 결과 항뇌전증제, 진정제-수면제 및 항파킨슨제에 의한 중독 T42 99.33 70.67 28.67 49.99 손상, 중독 및 외인에 의한 특정 기타 결과 알콜의 독성효과 T51 148.00 49.33 98.67 47.24 손상, 중독 및 외인에 의한 특정 기타 결과 학대증후군 T74 33.08 32.25 0.83 25.27
2. 호흡기질환 관련 커뮤니티 두 번째 대표 커뮤니티는 총 34 개의 질병을 포함하고 있다(그림 11). 이 대표커뮤니티는 호흡기질환 관련 질병들을 대거 포함하고 있어 “호흡기질환 관련 커뮤니티”로 정의하였다. 호흡기계통의 질환 뿐만 아니라 특정 감염성 및 기생충성 질환 또한 유의하게 많이 분포했음을 확인할 수 있었다(호흡기계통의 질환: p-value < 2.2e-16, 특정 감염성 및 기생충성 질환: p-value=0.014). 호흡기질환 관련 커뮤니티에 속한 질병의 특징을 살펴보면 전체 질병 평균 환자 나이는 49.43 세, 연평균 여성 발병 건 수는 450.03 건, 연평균 남성 발병 건 수는 442.57 건으로 남성 발병 건수와 여성 발병 건수가 크게 차이가 없음을 알 수 있다(표 7). 상대위험도가 가장 높은 연결성은 “탄광부진폐증(KCD-6 코드: J60)”에서 “상세불명의 진폐증(KCD-6 코드: J64)”으로 진행된 연결성이었으며(상대위험도: 579.09) 가장 빈도가 높은 연결성은 “세균학적으로나 조직학적으로 확인되지 않은 호흡기결핵(KCD-6 코드: A16)”에서 “세균학적 및 조직학적으로 확인된 호흡기결핵(KCD-6 코드: A15)”으로 진행된 연결성이었다(빈도: 3,016).
44 KCD 대분류 진단명 진단 코드 연평균발병 건수 연평균 여성 건수 연평균 남성 건수 평균 환자 나이 특정 감염성 및 기생충성 질환 세균학적 및 조직학적으로 확인된 호흡기결핵 A15 725.83 296.17 429.67 48.69 특정 감염성 및 기생충성 질환 세균학적으로나 조직학적으로 확인되지 않은 호흡기결핵 A16 1012.58 412.92 599.67 45.24 특정 감염성 및 기생충성 질환 좁쌀결핵 A19 13.33 6.17 7.17 50.87 특정 감염성 및 기생충성 질환 기타 형태의 마이코박테리아 에 의한 감염 A31 39.92 23.00 16.92 52.46 특정 감염성 및 기생충성 질환 연쇄구균패혈증 A40 16.92 7.5 9.42 20.25 특정 감염성 및 기생충성 질환 아스페르길루스증 B44 18.75 8.75 10.00 55.42 특정 감염성 및 기생충성 질환 결핵의 후유증 B90 301.00 120.67 180.33 52.40 신생물 기관지 및 폐의 악성 신생물 C34 531.92 167.50 364.42 62.92 신생물 심장, 종격 및 흉막의 악성 신생물 C38 12.17 5.25 6.92 50.55 신생물 호흡계통의 중이 및 제자리암종 D02 11.83 4.08 7.75 59.30 신생물 기타 및 상세불명의 흉곽내기관의 양성 신생물 D15 56.75 30.67 26.08 49.68 신생물 중이, 호흡기관, 흉곽내기관의 행동양식 불명 또는 미상의 신생물 D38 156.92 67.58 89.33 55.53 순환계통의 질환 폐혈관의 기타 질환 I28 10.67 5.42 5.25 43.91 순환계통의 질환 심장막의 기타 질환 I31 31.92 17.00 14.92 55.48 호흡계통의 질환 달리 분류되지 않은 세균성 J15 4745.83 2518.75 2227.08 30.81 표 7. 호흡기질환 관련 커뮤니티에 속한 질병 정보
폐렴 호흡계통의 질환 병원체의 폐렴상세불명 J18 12727.5 6585.42 6142.08 28.50 호흡계통의 질환 점액화농성 만성 단순성 및 기관지염 J41 6926.0 8 3866.92 3059.17 43.66 호흡계통의 질환 폐기종 J43 329.92 69.33 260.58 57.85 호흡계통의 질환 기관지확장증 J47 845.75 456.25 389.5 54.88 호흡계통의 질환 탄광부진폐증 J60 25.50 5.83 19.67 62.75 호흡계통의 질환 상세불명의 진폐증 J64 19.83 2.00 17.83 64.12 호흡계통의 질환 유기물먼지에 의한 과민성 폐렴 J67 10.25 5.33 4.92 46.75 호흡계통의 질환 외부요인에 의한 기타 호흡기병태 J70 5.00 2.50 2.50 48.00 호흡계통의 질환 달리 분류되지 않은 폐호산구증가 J82 20.75 8.25 12.50 45.34 호흡계통의 질환 기타 간질성 폐질환 J84 177.75 69.33 108.42 58.83 호흡계통의 질환 폐 및 종격의 농양 J85 65.25 17.00 48.25 56.00 호흡계통의 질환 농흉 J86 41.25 9.58 31.67 55.09 호흡계통의 질환 않은 흉막삼출액달리 분류되지 J90 213.75 88.58 125.17 53.15 호흡계통의 질환 달리 분류된 병태에서의 흉막삼출액 J91 24.00 10.00 14.00 53.82 호흡계통의 질환 흉막판 J92 19.75 7.67 12.08 56.33 호흡계통의 질환 기흉 J93 331.75 54.00 277.75 35.05 호흡계통의 질환 기타 흉막의 병태 J94 75.75 28.83 46.92 49.21 호흡계통의 질환 기타 호흡장애 J98 885.42 414.58 470.83 50.02 호흡계통의 질환 달리 분류된 질환에서의 호흡장애 J99 18.83 10.25 8.58 44.87
46 -3. 암 관련 커뮤니티 세 번째 대표커뮤니티는 32 개의 질병을 포함하고 있다(그림 12). 이 대표커뮤니티는 유방의 악성 신생물, 소화기관의 악성 신생물등 암과 관련된 질병들을 많이 포함하고 있고 신생물 그룹만이 유의하게 많이 분포하고 있어 최종 “암 관련 커뮤니티”로 정의하였다(신생물: p-value=4.51e-7). 암 관련 커뮤니티의 속한 질병의 특징을 살펴보면 전체 질병 평균 환자 나이는 50.34 세로 모든 대표커뮤니티 중 가장 환자 나이가 높았고 연평균 여성 발병 건 수는 246.89 건, 연평균 남성 발병 건 수는 107.42 건으로 평균 여성의 발병 건 수가 평균 남성 발병 건 수의 2 배 이상 많았다(표 8). 상대위험도가 가장 높은 연결성은 “유방의 제자리암종(KCD-6 코드: D05)”에서 “유방의 악성 신생물(KCD-6 코드: C50)”으로 진행된 연결성이었으며(상대위험도: 86.68) 가장 빈도가 높은 연결성은 “호흡 및 소화기관의 이차성 악성 신생물(KCD-6 코드: C78)”에서 “기타 및 상세불명 부위의 이차성 악성 신생물(KCD-6 코드: C79)”으로 진행된 연결성이었다 (빈도: 2,464).