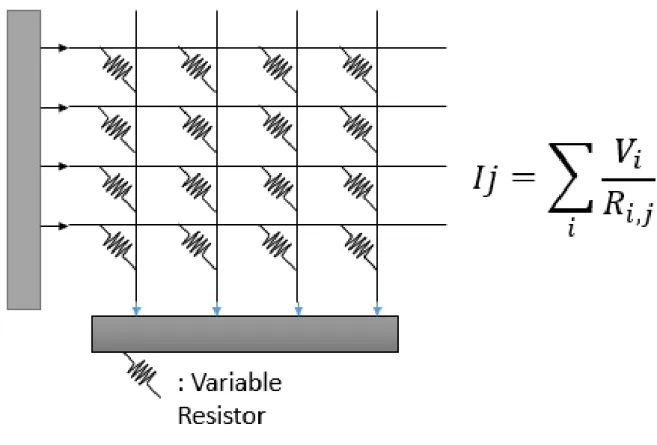
In the case of the ReRAM crossbar, it is gaining attention as a next-generation deep learning accelerator because it can compute MVM from analog very quickly due to its structure. However, the results of MVM cannot be displayed normally by the case of many non-idealities in the ReRAM, and for this reason, practical use in deep learning is not yet possible. Many methods have been studied to solve non-idealities, but in the case of those currently being studied, the problem is that a lot of pre- or post-processing is needed for each crossbar.
In the case of both non-idealities, a lot of research [3-6] is being conducted to solve the problem, but in the case of current methods, large preprocessing calculations are required, such as retraining and remapping at the digital level. and in some cases computer use is required after processing. In the case of this method, there is no knowledge that needs to be known at the digital level, such as the error map and the dataset label.
Structure of RCA
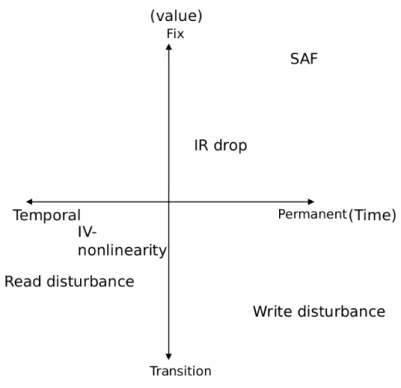
ReRAM non-idealities and Related Works
IR drop: Unlike the ideal situation, in reality there is wire resistance and the current is calculated even lower than the real value of the resistance. In the case of the previous methods, it is calculated on the premise that they have equivalent wire resistance (rw), and has the disadvantage that new requalification is required for other rw. Variability: This is a case where the value is slightly different from the normal value due to programming or other factors (heat, hardware.) in ReRAM.
Disturbances in writing where programming is not normally done and problems that cannot be read as normal values are common. Basically, it is difficult to predict, so online solutions are introduced instead of offline methods [11]. SAF: This is a case where the weight value located in a particular node is not normally used due to permanent failure/lifetime of the device and remains on or off.
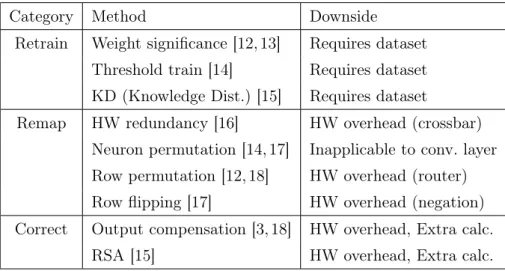
Since it is a kind of non-ideality that remains fixed after it occurs, there are many ways to deal with it, and the solution to fixing mistakes can be broadly divided into three categories (see Table 1. In the rehabilitation method, the value of the location where the error occurs is fixed, and training is mainstream [12, 13], and there are methods such as threshold training [14] and kernel distillation [15]. In the case of node permutation, an additional hardware module is not required in the fully connected layer, but the convolution layer has a disadvantage that it cannot be used because the mapping of weight crossbars is changed by im2col.
This is somewhat similar to our method because it interferes with the output, but since it corrects the value in the output by only recalculating the wrong weight, there is a problem that the computation time and hardware modules are added even for sparse operations.
Statistical Perspective
As we have seen so far, the current solution to deal with RCA non-ideality has many pre-processing steps and many computations required during runtime processing in the RCA accelerator.
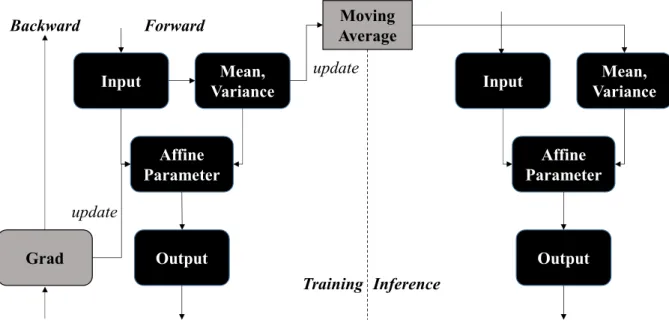
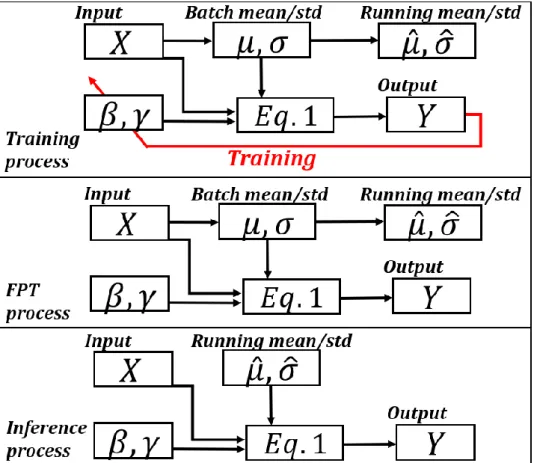
Batch Normalization
Unlike the affine transform parameters (β, γ), in the case of mean and std.dev, the running average is calculated by updating the mean of each output forward and during inference, and std.dev are not used, but a running average is used for stability , calculated during training.
Free Parameter Tuning
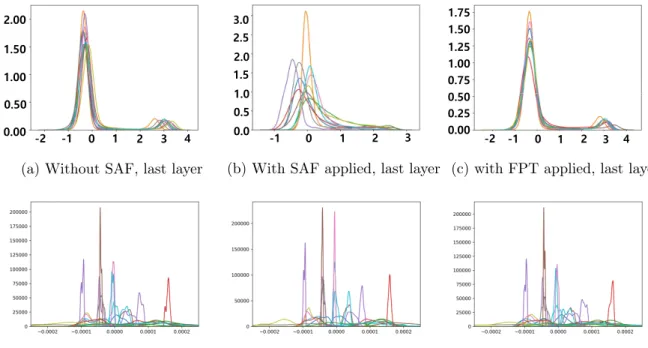
At the last layer, the distribution is ideally clearly divided into two. This appears to be due to an internal covariance shift, and upon application of FPT it returns to levels similar to the original output. In the case of the middle layer, we can also see that the FPT returns to a level similar to the original case.
Analysis of FPT method
Let us assume that the effect of SAF in the weight parameters can be modeled as Gaussian noise with different parameters depending on the target output. We add an affine layer modeling BN as Yi = aXi0 +b, where the calculation of BN is assumed to be free of SAF. Now our goal is to find how to minimize the total error rateL=φ0e0+φ1e1, where φ0, φ1 is the prior probability of the true output (φ0+φ1= 1).
Although it is difficult to find a closed-form solution to the above equation, our analysis shows that an affine transformation such as BN can help reduce classification error in the presence of random noise. Note that we only show that optimal(a, b)6= (1,0) can exist, but we do not claim that our FPT method can find the optimal values; our method is only a heuristic.
Experimental Setup
Effectiveness of FPT Method with SAF
Comparison with Other Mapping Method in SAF
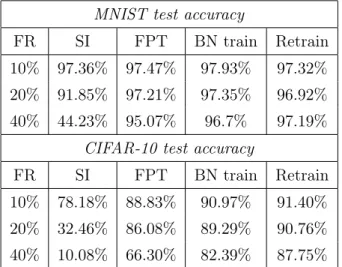
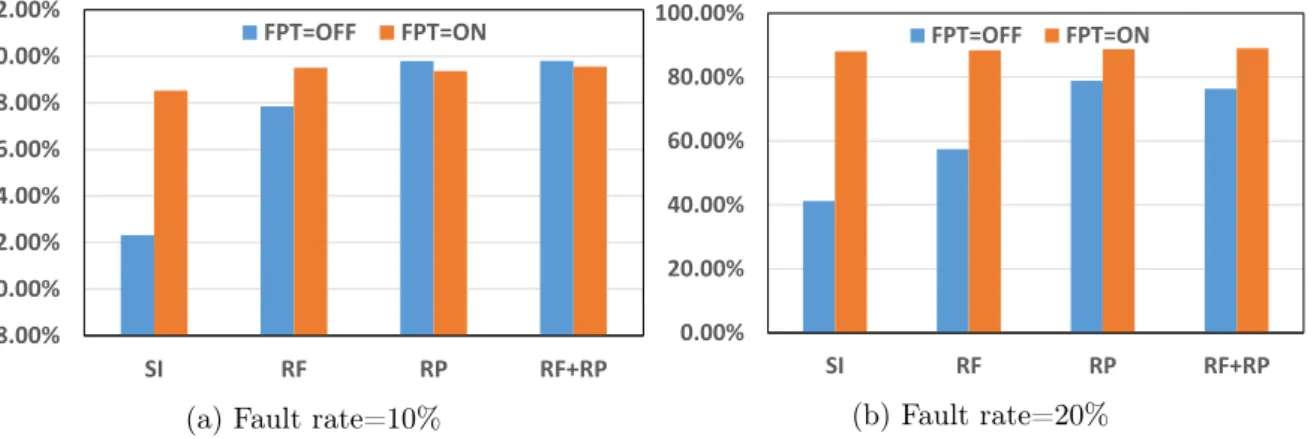
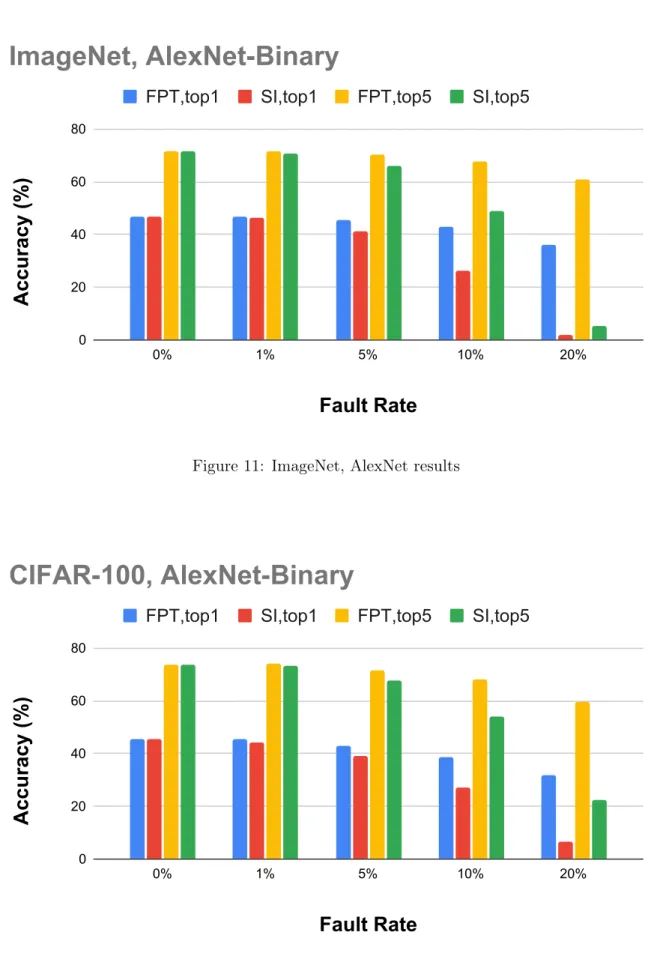
SI refers to simple termination, RF refers to row flip, and RP stands for row replacement. Line reversal is an error reduction method by changing the sign value of each line, and there is an additional cost of changing the sign value in the corresponding part of the output. In the case of 10% in Figure 6, other remapping methods precede FPT, but in the case of 20%, the result of applying only FPT is better than other methods without FPT.
One of the advantages of FPT, combining with other methods shows the best results at 20%, which is close to the basic accuracy. Although FPT does not have any additional overhead, it shows excellent results compared to other remapping methods.
Effect of Weight Representation
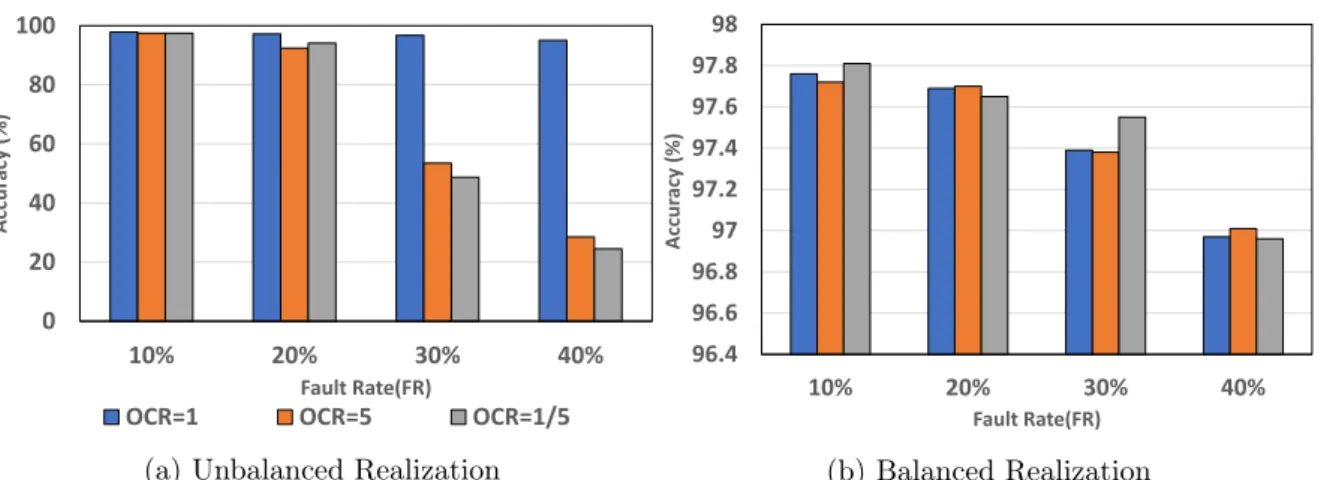
In Figure 7, we compare which of the two expressions is advantageous with MNIST, fixed to error case. When the unbalance realization is OCR=1, the accuracy is rather higher than the balance realization. This is because the probability of an error occurring in one weight node is lower in unbalance realization, so it appears that recovery is performed well, but when the OCR is far from 1, the accuracy drop appears clearly when the FR increases.
The reason for this appears to be that in the balance realization, even if Stack at on and Stuck at off are shown at different error rates, each result is subtracted to produce the final result, so that the error balance is that appear, well balanced. Based on these results, we basically used the mapping method as a balance realization in the experiment.
ReRAM Variability Case
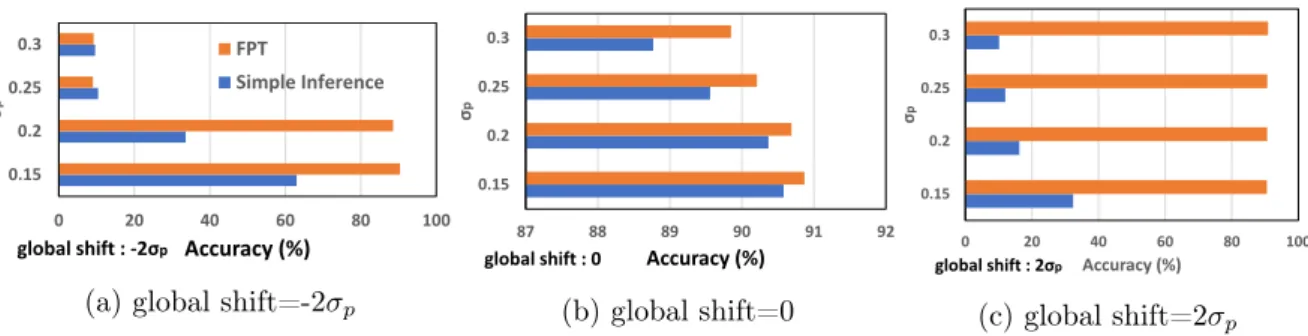
IR drop with Variability
Influence of Calibration Set
Using the calibration set for the inference set is a kind of cheating, so it can be thought that the accuracy could be higher, but if you look at Table 5, the training dataset produces better results. This appears to be due to the fact that the inference set is limited information, so it could not detect noise. Second, what is the minimum iteration/batch size required for the forward process in ReRAM to update running average, and Table 6 outputs the result.
Overall, the larger the iteration, the better it is to catch errors caused by noise with statistics, so it is considered to have excellent resilience. Furthermore, the effect of batch size is apparent to some extent when the iteration is sufficiently large, and it is believed that this is due to the ability to assess the overall pattern of noise occurring in different labels. Based on these results, we decided that iteration 32 and batch size 32 could use the smallest image set as the calibration set without showing a significant decrease in accuracy.
The last experiment is an experiment on how well each tag balances. In this experiment, the accuracy is higher when label 0 is at the same level as the other labels, and it is shown that it is important to have a good balance even if it is chosen randomly.
Experiment on Complex Dataset
Even with a low error rate of about 5%, there is a clear effect on SI, and FPT also shows a drop of about 1% based on top 1, but it shows a satisfactory result. However, compared to simple models, even if it is about 10%, it can be confirmed that the problem appears to some extent in FPT. However, it produces quite good results compared to simple inference and it seems that it can be restored to its original state through coupling with other offline methods as mentioned in the previous section.
In Figure 12, CIFAR-100 also shows the degree of deterioration of IMAGENET accuracy compared to floating point, and the overall flow is almost consistent with IMAGENET.
Result of Multi-bit Case
One of the ways we would like to propose seems to be able to be solved by training the bias by using each generated output with the original weight without applying non-idealities in the digital and the real output generated in the RCA as a dataset. Fan, “Noise injection adaptation: end-to-end ReRAM crossbar non-ideal effect adaptation for neural network mapping,” in Proceedings of the 56th Annual Design Automation Conference 2019. Chakrabarty, “Fault tolerance in neuromorphic computing systems,” in Proceedings of the 24th Asia Pacific Design Automation Conference.
Shanbhag, "Swipe: Enhancing robustness of reram crossbars for in-memory computing," in 2020 IEEE/ACM International Conference on Computer Aided Design (ICCAD). Choi, “Vcam: Variation compensation by activation matching for analog binarized neural networks,” in 2019 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED). Kurdahi, “Learning to predict their drop with effective training for reram-based neural network hardware,” in 2020 57th ACM/IEEE Design Automation Conference (DAC).
Jiang, “Accelerator-friendly neural network training: learning variations and defects in RRAM crossbar,” in Design, Automation & Test in Europe Conference & Exhibition (DATE), 2017. Li, “Rescuing memristor-based neuromorphic design with high defects,” inProceedings of the 54th Annual Design Automation Conference 2017. Ewetz, “Handling stuck faults in memristor crossbar arrays using matrix transforms,” in Proceedings of the 24th Asia and South Pacific Design Automation Conference.
Nakahara, "On-chip memory based binarized convolutional deep neural network applying batch normalization free technique on an FPGA," in 2017.