플래시 메모리 기반의 실시간 임베디드 시스템을 위한 실시간 demand
paging 기법
Real-Time Demand Paging for Flash-Memory Storage Systems of Real-Time Embedded Systems
국 민 대 학 교 대 학 원
전산과학과 컴퓨터과학 전공
이 영 호
2007년 7월
플래시 메모리 기반의 실시간 임베디드 시스템을 위한 실시간 demand
paging 기법
Real-Time Demand Paging for Flash-Memory Storage Systems of Real-Time Embedded Systems
국 민 대 학 교 대 학 원
전산과학과 컴퓨터과학 전공
이 영 호
2007년 7월
시스템을 위한 실시간 demand paging 기법
Real-Time Demand Paging for Flash-Memory Storage Systems of Real-Time Embedded Systems
지도교수 임 성 수
이 論文을 電算科學 碩士學位 請求論文으로 提出함
2007 년 6 월 7 일
국민대학교 대학원
전산과학과 컴퓨터과학 전공
이 영 호
2007
李 榮 縞 의
碩 士 學 位 請 求 論 文 을 認 准 함
2007년 6월 7일
審査委員長 우 종 우 審 査 委 員 임 은 진 審 査 委 員 임 성 수
국 민 대 학 교 대 학 원
차례
그림 차례 ... i
표 차례 ... ii
국문 요약 ... iii
1 서론 ... 1
1.1 연구 배경 및 목적 ... 1
1.2 논문 구성... 3
2 배경 및 관련 연구 ... 3
2.1 실시간 시스템 이론 ... 3
2.1.1 스케줄링 가능성 분석 기법 ... 5
2.2 플래시 메모리 ... 7
2.3 demand paging 기법 ... 9
2.3.1 페이지 교체 정책 ... 10
3 실시간 demand paging 기법 ... 11
3.1 시스템 아키텍쳐... 11
3.2 demand paging 환경에서의 태스크 최악 응답 시간 분석 ... 14
3.2.1 고려 사항 ... 15
3.2.2 태스크 최악 응답 시간 분석 과정 ... 17
3.2.3 demand paging 비용 분석 ... 18
3.2.4 페이지 재사용 양상 분석 ... 20
3.2.5 태스크 최악 응답 시간 계산 ... 22
4 실험 ... 24
4.1 태스크 최악 응답 시간 분석 결과 ... 24
5 결론 및 향후 과제 ... 27
6 참고 문헌 ... 29
그림 차례
그림 1. 주기 태스크의 스케줄링 ... 5
그림 2. 플래시 메모리의 특성 ... 8
그림 3. 시스템 아키텍쳐 ... 12
그림 4. 페이지 재사용 양상 ... 16
그림 5. 태스크 최악 응답 시간 분석 과정 ... 18
그림 6. 제어 흐름 그래프 상에서 basic block과 페이지 대응 ... 19
그림 7. DPC 테이블 ... 21
그림 8. 페이지 재사용 양상 분석 과정 ... 22
그림 9. 정적 프로그램 분석기 ... 24
그림 10. 태스크 최악 응답 시간 분석기 ... 25
표 차례
표 1. 실행 경로와 demand paging 비용 간의 관계 ... 15 표 2. 태스크 집합 및 매개변수 ... 25 표 3. 태스크 최악 응답 시간 분석 결과... 27
국문 요약
최근 플래시 메모리를 저장장치로 사용하는 임베디드 시스템이 증가하고 있다.
특히 고용량 데이터를 기반으로 하는 멀티미디어 관련 기기가 주가 됨에 따라 NAND 플래시 메모리의 비율이 높아지고 있다. 임의 접근이 가능한 NOR 플래시 메모리와는 달리 NAND 플래시 메모리에서는 순차 접근만을 허용하기 때문에, 기 존의 실시간 시스템에서는 프로그램 실행 전에 전체 프로그램 이미지를 NAND 플 래시 메모리로부터 DRAM에 복사하는 shadowing 기법을 주로 사용해왔다. 그러 나 shadowing 기법은 실행하지 않는 페이지 영역도 DRAM에 적재하기 때문에 DRAM 영역을 지나치게 낭비하고 부팅 시간을 높일 수 있기 때문에, 자원 제약이 심한 실시간 임베디드 시스템에 적합한 기법이라고 할 수 없다.
요구 페이징 시스템은 실시간 임베디드 시스템보다는 서버나 데스크톱 환경에서 사용되어 왔다. 이는 실시간 임베디드 시스템에 사용되는 프로그램이 대부분 요구 페이징 시스템을 요구할 만큼 크지 않았기 때문이다. 그러나 최근 시스템이 복잡해 지고 다기능을 요구함에 따라, 실시간 시스템에서도 요구 페이징이 필수 요소가 되 고 있다. 단, 기존의 요구 페이징 기법은 다음과 같은 문제점 때문에 실시간 시스템 에 적용하기 힘들다. 첫째, 기존의 요구 페이징 기법은 대부분 디스크 기반의 저장 장치를 가정한다. 따라서 플래시 메모리의 특성을 고려한 요구 페이징 기법이 필요 하다. 둘째, 실시간 시스템은 엄격한 시간적 제약을 요구하는 반면 요구 페이징 시 스템에서는 page fault에 의한 시간 지연이 발생하고, page fault의 발생 빈도 및 양상을 예측할 수 없기 때문에 결과적으로 태스크의 최악 응답 시간을 예측하기 어 렵다.
본 논문에서는 플래시 메모리 기반의 실시간 요구 페이징 기법을 제안한다. 제안 하는 기법은 요구 페이징 환경에서 각 태스크의 최악 성능을 보장하고, 전체 시스템 의 최악 성능 분석을 통해 예측 가능한 실시간 시스템을 만드는 것을 목표로 한다.
주요어: 실시간 demand paging, WCRT, worst case response time, 플래시 메모리
1 서론
1.1 연구 배경 및 목적
최근 NAND 플래시 메모리를 데이터뿐만 아니라 프로그램 코드를 저장하기 위한 목적으로 사용하는 임베디드 시스템이 증가하고 있다. 임의 접근이 가능한 NOR 플래시 메모리와는 달리 NAND 플래시 메모리에서는 순차 접근만을 허용하기 때문에, 기존의 NAND 플래시 메모리 기반 실시간 임베디드 시스템에서는 프로그램을 수행하기 위한 주로 shadowing 기법1을 사용해왔다.
그러나 shadowing 기법은 실행하지 않는 페이지 영역도 DRAM에 적재하기 때문에, DRAM 영역을 지나치게 낭비하고 부팅 시간을 높일 수 있다는 단점이 있다. 이러한 특성 때문에 shadowing 기법은 자원 제약이 심한 실시간 임베디드 시스템에 적합한 기법이라고 할 수 없다.
이에 대한 대안 중 하나로 최근 실시간 임베디드 시스템을 위한 demand paging 기법이 주목을 받고 있다. 최근까지 demand paging 시스템은 실시간 임베디드 시스템보다는 서버나 데스크톱 환경에서 사용되었으나, 시스템이 복잡해지고 다기능을 요구함에 따라, 실시간 임베디드 시스템에서도 demand paging의 필요성이 커지고 있다. 단, 기존의 요구 페이징 기법을 플래시 메모리 기반의 실시간 임베디드 시스템에 적용하기 위해서는 다음과 같은 문제를 고려해야 한다. 첫째, 기존의 demand paging 기법은 대부분 디스크 기반의 저장장치를 가정하기 때문에, 플래시 메모리의 특성을 고려한 demand paging 기법이 필요하다. 둘째, demand paging 시스템에서는 page fault에 의한 시간 지연이 발생하기 때문에, 실시간 시스템에서 요구하는 엄격한 시간 제약을 보장하지 않을 가능성이 있다. 더 큰 문제는 page fault의 발생 빈도 및 발생 양상을 예측하기 어렵기 때문에, demand paging 환경에서 수행되는 태스크의 최악 수행 성능을
1 프로그램 실행 이전에 전체 프로그램 이미지를 RAM에 복사하는 방식
예측하기 어렵다는 점이다. 이러한 특성 때문에, 플래시 메모리 기반의 실시간 시스템에서 demand paging 기법이 실시간성을 만족시키기 위해서는 다음과 같은 특성이 요구된다.
1. demand paging 환경에서의 최악 실행 성능 파악 : demand paging 환경에서 실시간성을 보장하기 위해서는 시스템의 최악 실행 성능을 파악해야 한다. 본 논문에서는 NAND 플래시 메모리 기반의 임베디드 실시간 시스템에서 demand paging 비용을 고려한 태스크 최악 응답 시간2 분석 기법을 제안한다. 제안하는 기법에서는 각 태스크에 대한 demand paging 비용을 계산하고, 이를 전통적인 WCRT 분석 기법과 결합하는 방법을 사용한다. Y. Lee[8] 등은 플래시 메모리 기반의 실시간 시스템에서 demand paging 비용을 고려한 태스크 최악 응답 시간을 제안하였다. [8]에서는 각 태스크 인스턴스에 대한 최악 demand paging 비용을 계산하기 위해, 태스크의 각 실행 경로에 대한 최악 실행 시간과 demand paging 비용을 결합하는 방법을 사용하였다. [1]에서 제안한 기법은 각 태스크 인스턴스에 대해 최적의 demand paging 비용을 얻을 수 있다는 장점이 있는 반면, demand paging 비용을 계산하기 위해 각 실행 경로에 대한 WCET 값을 모두 알아야 한다는 단점이 있다. 특히 최근 WCET 분석 관련 연구[9][10][11]에서는 분석의 효율을 위해 모든 실행 경로에 대한 WCET을 예측하는 방식은 채택하지 않고 있다. 따라서 본 논문에서는 각 태스크 내의 페이지 정보만을 사용하여 demand paging 비용을 분석하는 데 초점을 맞춘다. 이는 WCET 분석과 demand paging 비용 분석 과정을 독립적으로 수행함으로써, 분석 기법을 단순화하고 분석의 복잡도를 낮추는데 목적이 있다.
2 Worst Case Response Time : WCRT
2. 실시간 페이지 교체 정책(real-time page replacement policy) : 페이지 교체(page replacement)를 최소화함으로써, 페이지 적재에 따른 실시간 태스크의 지연을 최소화해야 한다.
1.2 논문 구성
2장에서는 실시간 demand paging에 대한 기존 연구를 살펴본다. 관련 연구로는 실시간 시스템 이론의 스케줄링 가능성 분석 기법, demand paging 기법, 플래시 메모리의 특성 등이 있다. 3장에서는 논문에서 제안하는 demand paging 환경에서의 태스크 최악 응답 시간 분석 기법을 제시한다. 4장에서는 가상의 태스크 집합을 사용한 시뮬레이션 결과를 보인다. 마지막으로, 5장에서는 결론 및 향후 과제를 제시한다.
2 배경 및 관련 연구
본 절에서는 배경 및 관련 연구에 대해 기술한다. 2.1절에서는 실시간 시스템 이 론 및 스케줄링 가능성 분석 기법에 대해 설명한다. 2.2절에서는 플래시 메모리의 특성에 대해 설명한다. 2.3절에서는 demand paging 기법 및 페이지 교체 정책에 대해 기술한다.
2.1 실시간 시스템 이론
실시간 시스템에서 각 태스크의 기본 실행 단위는 태스크 인스턴스(task instance), 또는 작업(job)이다. 각 태스크 인스턴스는 프로세서와 자원을 할당받 아 주어진 주기만큼 실행하며, 해당 주기가 종료되면 시스템은 다른 태스크 인스턴 스에게 제어권을 넘긴다.
본 논문에서는 주기 태스크 모델을 가정한다. 일반적인 주기 태스크 모델에서 태 스크( 는 주기( , 위상( , 실행 시간( , 데드라인( 의 집합으로 구성된다.
이때 주기는 연속되는 두 태스크 인스턴스간의 최소 release 시간 간격을 의미하며, 위상은 각 태스크의 첫 번째 태스크 인스턴스의 release 시간을 뜻한다. 또한 실행
시간은 모든 태스크 인스턴스들 중 최악 실행 시간(WCET)을 의미하며, 데드라인 은 각 태스크 인스턴스의 시간 제약을 뜻한다. 식 1은 일반적인 테스크 모델을 나 타낸다.
, , , (식 1)
주기 태스크 모델에서 각 태스크는 우선순위에 따라 실행된다. 즉, 우선순위가 높 은 태스크는 우선순위가 낮은 태스크에 비해 먼저 실행된다. 실시간 스케줄링 기법 은 각 태스크에 우선순위를 할당하는 방식에 따라 결정되는데, 크게 정적 및 동적 스케줄링으로 나뉜다 [1][10][11]. 정적 스케줄링 기법은 태스크의 사전 정보(주기, 실행 시간, 데드라인 등)를 이용해서 우선순위를 사전에 할당하는 방식으로, 태스크 수행 후에는 우선순위가 변하지 않는다는 특징이 있다. 정적 스케줄링 기법에는 RM(Rate Monotonic)3, DM(Deadline Monotonic: DM)4 등이 있다. 반면 동 적 스케줄링 기법은 각 태스크의 우선순위를 실행 중에 변경하는 방식으로, EDF(Earlist Deadline First) 등이 있다.
그림 1은 주기 태스크 모델을 기반으로 한 정적 스케줄링 실시간 시스템에서 태 스크가 수행되는 예를 보인다. 예제 실시간 시스템은 3개의 태스크, : 4, 0, 2, 4 ,
: 11, 0, 3, 11 , : 30, 0, 3, 30 ,로 구성되며, RM 스케줄링 방식을 따른다고 가정 한다.
3 작은 주기를 갖는 태스크에 더 높은 우선순위를 할당하는 방식
4 데드라인이 작은 태스크에 더 높은 우선순위를 할당하는 방식
그림 1. 주기 태스크의 스케줄링
RM 스케줄링 방식은 주기가 작을수록 더 높은 우선순위를 할당하는 방식이므로, 예제 시스템에서 태스크 우선순위는 , , 순으로 높다. 각 태스크 인스턴스는 해당 주기동안 실행되지만 실행 중 상위 태스크 인스턴스가 수행될 차례가 될 경우, 해당 태스크 인스턴스는 상위 태스크 인스턴스에 의해 선점(preemption)된다. 예 를 들어 , 은 실행 시간이 3이므로 시간 5까지 실행되어야 하지만, 상위 우선순위 를 갖는 , 에 의해 시간 4에서 선점되었다. 반면 해당 태스크 인스턴스가 실행을 마친 경우에는 하위 우선순위를 갖는 태스크 인스턴스가 실행되도록 제어권을 넘긴 다. 본 논문에서는 주기 태스크 모델을 기반으로 한 정적 스케줄링 실시간 시스템을 가정한다.
2.1.1 스케줄링 가능성 분석 기법
실시간 시스템을 구성할 때는 스케줄링 가능성 분석 (schedulability analysis)을 통해 시스템 내의 태스크 집합이 데드라인(deadline)과 같은 실시간 성능 요구조건을 만족시키는지를 판단할 수 있어야 한다. 스케줄링 가능성 분석 기법에는 이용률 기반(utilization-based) 분석 기법[1][2]과 최악 응답 시간 (worst-case response time: WCRT) 분석 기법[3][4][5]이 있다.
Liu 와 Layland [1]는 고정 우선순위를 가지는 주기 태스크를 위한 스케줄링 가능성 테스트(schedulability test)를 제안했다. [1]에서는 태스크 집합이 스케줄 가능하기 위한 CPU 이용률의 상한선을 제시했으며, 식 2 와 같이 나타낸다.
2 1 (식 2)
식 2 에서 와 는 각각 태스크 의 최악 실행 시간과 주기를 나타낸다. 만약 가 이용률 상한선(보통 0.693)보다 작거나 같을 경우, 해당 태스크 집합은 비율 단조 우선순위 할당시 스케줄 가능하다고 알려져있다. 이후 Lehoczky[2] 등은 CPU 이용률 기반의 스케줄링 분석 기법에서 해당 태스크 집합이 스케줄 가능하기 위한 필요 충분 조건을 제시했다.
최악 응답 시간 분석 기법에서는 각 태스크에 대해 최악 응답 시간을 계산하고, 각 태스크의 최악 응답 시간이 해당 태스크의 데드라인보다 작거나 같을 경우 해당 시스템은 스케줄 가능하다고 한다. 태스크 의 최악 응답 시간 는 의 최악 실행 시간과 상위 우선순위 태스크에 의한 시간 지연의 합으로 나타내는데, 일반적으로 식 3 과 같이 나타낸다.
(식 3)
식 3 에서 는 보다 높은 우선순위에 해당하는 태스크 집합을 의미한다.
최악 응답 시간은 반복적으로 계산되는데, 초기 조건은 이고, 일 때까지 재귀적으로 계산된다.
전통적인 최악 응답 시간 분석 이론에서는 분석을 단순화하기 위해 태스크 수행시 발생하는 추가 비용은 모두 0 으로 가정한다. 그러나 실제 시스템에서는 태스크 최악 응답 시간에 영향을 미치는 다양한 요소가 존재할 수 있다. 최근에는 release jitter[6][7][8], 선점 비용(preemption cost)[9][10], 임의의 데드라인 (arbitrary deadlines)[11] 등 다양한 추가 비용을 고려한 최악 응답 시간 모델이 제시되었다. N. Audsley [8] 등은 release jitter 를 고려한 경우의 태스크 최악 응답 시간을 제안했는데, 이는 식 4 와 같이 나타낸다.
(식 4)
식 4 에서 는 의 release jitter 를 나타내며, 태스크 최악 응답 시간은 식 3 과 마찬가지로 일 때까지 반복적으로 계산된다. 이때, 는 가 release 될 때부터 종료될 때까지 걸린 시간이므로, 의 최악 응답 시간은
로 나타낸다.
C. Lee[10] 등은 태스크가 선점될 때 캐시에 의해 발생하는 간접적인 선점 비용(indirect preemption costs)를 고려한 최악 응답 시간을 제시하였다. 식 5 는 [10]에서 제안한 태스크 최악 응답 시간을 나타내며, 이때 는 에 의해 발생한 총 선점 비용을 나타낸다.
(식 5)
본 논문에서는 page fault 처리 비용을 기존의 WCRT 이론과 어떻게 결합할 수 있는지에 초점을 맞춘다. 기존 연구에서는 모든 태스크 인스턴스에 대해 추가적인 비용이 같다고 가정하였다. 그러나 page fault 처리 비용은 각 태스크의 실행 양상에 따라 달라질 수 있다. 이는 page fault 발생 양상이 과거의 메모리 접근 패턴에 따라 달라지는 demand paging 시스템의 특성 때문이다. 따라서 demand paging 비용을 고려한 각 태스크의 WCRT 를 정확하게 얻기 위해서는 플래시 메모리 기반의 demand paging 시스템의 특성을 고려해야 한다.
2.2 플래시 메모리
플래시 메모리는 물리적인 특성에 따라 NAND 플래시 메모리와 NOR 플래시 메 모리로 구분된다. NAND 플래시 메모리와 NOR 플래시 메모리의 가장 큰 차이점 은 버스 인터페이스(bus interface)이다 [4]. NAND 플래시 메모리는 제어 입력 (control input)을 가진 I/O 인터페이스를 가지는 반면, NOR 플래시 메모리는 SRAM과 같이 주소 및 데이터 버스에 직접적으로 연결되어 있다. NAND 플래시 메모리는 고집적도, 저비용, 빠른 쓰기 연산등의 특성을 갖기 때문에 일반적으로 데 이터 저장용으로 사용된다. NOR 플래시 메모리는 빠른 읽기 연산과 임의의 주소에 접근 가능한 특성을 가지고 있기 때문에, 주로 프로그램 코드를 저장하기 위한 목적
으로 사용된다. 특히 임의 주소에 접근 가능한 특성 때문에 NOR 플래시 메모리에 서는 프로그램 코드를 직접 수행할 수 있는 XIP(eXecute-In-Place) 특성을 지 원한다. 반면 NAND 플래시 메모리에서는 일반적으로 프로그램 수행 이전에 전체 프로그램 이미지를 RAM에 적재하는 shadowing 기법을 통해 프로그램 코드를 수 행한다.
플래시 메모리는 자기 디스크와는 달리 다음과 같은 특성을 가진다. 첫째, 플래시 메모리에서는 데이터를 읽거나 쓸 때 올바른 섹터 위치를 찾기 위해 기계적인 헤드 를 움직이는데 소요되는 지연 시간(latency time)이 존재하지 않는다. 자기 디스 크에서 이러한 지연 시간은 I/O 연산에 걸리는 시간의 대부분을 차지한다. 따라서 일반적으로 자기 디스크 기반의 운영체제에서는 지연 시간에 따른 성능 저하를 줄이 기 위해 prefetch나 디스크 스케줄링과 같은 방식을 통해 I/O 성능을 최적화한다.
둘째, 플래시 메모리는 읽기 및 쓰기 연산의 성능이 비대칭적이다. 그림 2는 플래 시 메모리에서 4KB 크기의 데이터 읽기, 쓰기 및 삭제 연산에 소요된 시간과 에너 지 소비량을 나타낸다. 그림 2에서 플래시 메모리의 쓰기 연산은 읽기 연산에 비해 6.3~6.4 배의 접근 시간과 에너지 소비량을 가짐을 알 수 있다. 이러한 경향은 NOR 플래시에서 더 크게 나타난다.
그림 2. 플래시 메모리의 특성
셋째, 플래시 메모리는 in-place 갱신을 지원하지 않는다. 다시 말하면 플래시 메 모리 내의 같은 페이지를 쓰기 위해서는 먼저 해당 페이지를 삭제해야 한다. 이는 읽기 연산이 증가할수록 잠재적인 삭제 연산 역시 증가함을 의미한다.
넷째, 플래시 메모리에서는 한 블록의 삭제 횟수가 정해져 있다 (약 10만~100만 회). 따라서 플래시 메모리에서는 특정 블록에만 삭제 연산이 집중되지 않도록 효율 적인 garbage collection 기법이 요구된다.
다섯째, 플래시 메모리는 programmed-I/O 장치이다. 다시 말하면 플래시 메모 리 연산은 모두 CPU 소비적이다. 예를 들어 페이지 쓰기 요청을 처리하기 위해서 는 CPU가 먼저 플래시 메모리에 주소와 명령을 전달함으로써 플래시 메모리에 데 이터를 다운로드 하기 위한 명령을 내린다. 이후 CPU는 플래시 메모리가 페이지 쓰기 요청을 완료할 때까지 플래시 메모리의 상태를 지속적으로 확인한다. 페이지 읽기 및 블록 삭제 연산 역시 비슷한 과정으로 수행된다. 그 결과, 플래시 메모리 연산을 수행할 때 CPU는 다른 작업을 수행하지 못한다.
플래시 메모리의 이러한 특성 때문에, 본 논문에서 가정하는 플래시 메모리 기반의 demand paging 시스템은 다음과 같은 특성을 갖는다. 첫째, 플래시 메모리 내의 각 페이지를 읽는데 걸리는 시간은 항상 같다. 이는 플래시 메모리의 첫 번째 특성 에 기인한다. 둘째, 본 논문에서는 demand paging 시스템의 구성 요소 중 swap-out 특성은 고려하지 않는다. 이는 플래시 메모리의 네번째 특성에 기인한 다. 셋째, 모든 플래시 메모리 연산은 비선점적(non-preemptible)이다. 이는 플 래시 메모리의 다섯번째 특성에 기인한다.
2.3 demand paging 기법
demand paging 기법은 프로세스가 데이터나 코드를 실제로 접근할 때만 저장 장치(일반적으로 디스크)로부터 해당 데이터나 코드를 RAM에 적재하는 가상 메모 리 기술이다. demand paging 기법은 각 프로세스에게 독립적인 메모리 공간을 제 공함으로써 프로세스가 메모리의 제한으로부터 벗어날 수 있게 한다. 전통적인 demand paging 기법은 하드디스크를 저장장치로 갖는 범용(general-purpose) 시스템을 목표로 해왔다. 그러나 최근에는 휴대폰과 같은 실시간 임베디드 시스템에
서도 demand paging 기법을 적용하는 사례가 증가하고 있다. 이는 다음과 같은 이유 때문이다.
첫째, 실시간 임베디드 시스템이 복잡해지고 다양한 어플리케이션을 필요로 함에 따라, 더 많은 메모리를 필요로 하게 되었다. 둘째, PDA나 휴대폰 등과 같이 네트 워크를 통해 프로그램을 다운로드 받고 실행하는 것이 일반화됨에 따라 어플리케이 션의 수와 메모리 요구량이 실시간으로 변화한다. 셋째, shadowing 기법은 어플리 케이션 전체를 RAM에 적재하기 때문에 메모리 사용량 및 에너지 소비량 측면에서 실시간 임베디드 시스템에 적합하지 않다.
그러나 shadowing 기법과는 달리, demand paging 시스템에서는 태스크가 실 행되는 중에도 page fault를 처리해야 하기 때문에 실시간 태스크의 실행이 지연될 가능성이 있다. 특히 제한된 양의 메모리를 사용하는 시스템에서는 페이지 교체가 빈번하게 발생하게 되는데, 이 경우 이전에 적재한 페이지를 다시 적재해야 하기 때 문에 page fault에 의한 시간 지연이 커질뿐만 아니라 demand paging 시스템의 최악 성능을 예측하기 어렵다. 따라서 demand paging 기법을 실시간 시스템에 적 용하기 위해서는 페이지 교체에 의한 추가적인 시간 지연이 발생하지 않도록 해야 한다. 본 논문에서는 페이지 교체 정책이 실시간성을 만족시킬 수 있도록 하는 것을 목표로 한다.
2.3.1 페이지 교체 정책
페이지 교체 정책의 성능이 demand paging 시스템의 성능을 결정한다는 점에서 페이지 교체 정책은 demand paging 시스템의 핵심 요소 중 하나이다. 다양한 페 이지 교체 정책이 제안되었다 [12][13][14][15][16][17][18].
온라인 알고리즘 중에서는 Belady의 MIN 알고리즘 [12] 이 최적인 것으로 알려 져 있다. Belady의 MIN 알고리즘은 미래에 참조될 가능성이 가장 적은 페이지를 희생될 페이지로 선택하는 방식이다. Belady의 MIN 알고리즘은 가장 큰 단점은 각 페이지가 미래에 참조될 가능성을 예측하는 것이 불가능하기 때문에 구현 가능하 지 않다는 점이다. 따라서 온라인 알고리즘 중에서는 LRU 알고리즘 [13] 이 가장 널리 사용된다. 대부분의 운영체제에서는 구현을 단순화하기 위해 근사
LRU(approximated LRU) 기법을 사용한다.
기존의 LRU 성능을 개선하기 위해 LRU 기반의 다양한 페이지 교체 정책이 제안되었다: 2Q [14], LRU-K [15], EELRU [16], LRFU [17]. 단, 이 기법들은 모두 page hit 비율만을 고려했다는 단점이 있다.
최근에는 플래시 메모리의 특성을 고려한 다양한 페이지 교체 정책이 제안되었다 [18][19]. Park 등은 플래시 메모리의 읽기 및 쓰기 연산의 성능이 비대칭적이라는 특성을 이용한 LRU 기반의 페이지 교체 정책을 제안하였다: CFLRU(Clean-First LRU). CFLRU에서 기존의 LRU 리스트는 working 구역과 clean-first 구역으로 나뉘어진다. 페이지 교체가 발생하는 경우 clean-first 구역에 있는 clean 페이지를 먼저 교체한다. CFLRU는 플래시 메모리의 접근 시간과 에너지 소비를 고려한 플래시 메모리 기반의 LRU 기법이지만, 최악 성능을 예측할 수 없기 때문에 실시간 시스템에는 적합하지 않다.
기존의 페이지 교체 정책은 모두 page hit 비율을 높임으로써 페이지 교체 성능을 높이는 것을 목표로 한 반면, 실시간성을 보장하지 못한다는 단점이 있다. 따라서 본 논문에서 제안하는 페이지 교체 알고리즘은 플래시 메모리의 특성과 실시간성 모두를 고려하는 것을 목표로 한다. 단, 본 논문에서는 dirty 페이지를 교체함으로써 발생할 수 있는 추가적인 비용을 제거하기 위해 코드 영역 내의 페이지만을 교체한다고 가정한다. 다행히 플래시 메모리 기반의 실시간 demand paging 시스템에서는 플래시 메모리의 블록 제거 연산의 횟수가 정해져 있는 특성 때문에 일반적으로 swap-out 기능을 고려하지 않는다.
3 실시간 demand paging 기법
본 절에서는 논문에서 제안하는 실시간 demand paging 기법에 대해 설명한다.
먼저 3.1절에서는 제안하는 실시간 demand paging 시스템의 전체 구조를 기술한 다. 3.2절에서는 demand paging 비용을 고려한 태스크 최악 응답 시간에 대해 설명한다.
3.1 시스템 아키텍쳐
본 절에서는 논문에서 제안하는 실시간 demand paging 시스템의 전체 구조를 설명한다 (그림 3).
그림 3. 시스템 아키텍쳐
제안하는 실시간 demand paging 시스템은 NAND 플래시 메모리를 보조 저장 장치로 사용한다. 이는 NAND 플래시 메모리가 NOR 플래시 메모리에 비해 용량 대비 가격이 우수하기 때문이다. NOR 플래시 메모리는 NAND 플래시 메모리에 비해 페이지 읽기 성능이 뛰어난 반면, NOR 플래시에서는 프로그램 코드를 RAM 에 적재하지 않고 직접 수행(XIP)하는 것이 가능하므로 demand paging 기법이 불필요하다.
또한 NAND 플래시 메모리를 관리하기 위해 FTL을 기반으로 한 블록 디바이스 에뮬레이션 방식을 사용한다 [20]. 저수준 플래시 메모리 드라이버(flash memory driver)는 제어 신호를 통해 플래시 메모리와 직접적으로 통신하며 페이 지 읽기, 페이지 쓰기, 블록 삭제 등의 저수준 플래시 메모리 연산을 제공한다.
FTL은 플래시 메모리를 일반적인 블록 디바이스로 에뮬레이션하는 역할을 하며,
주소 변환(address translation)과 가비지 컬렉션(garbage collection) 등의 기 능을 통해 플래시 메모리를 관리한다.
실시간 태스크의 최악 성능을 보장하기 위해서는 가상 메모리를 효율적으로 설계해 야 한다. 가상 메모리를 설계하는데 있어 가장 중요한 고려사항 중 하나는 실시간성 을 보장할 수 있도록 페이지 교체 알고리즘을 정의하는 것이다. 왜냐하면 페이지 교 체 알고리즘의 성능이 가상 메모리의 성능에 가장 큰 영향을 미치기 때문이다. 본 논문에서는 캐시 분할(cache partitioning) 기법을 통해 실시간 태스크가 비실시 간 태스크 간의 페이지 교체에 의해 영향을 받지 않도록 한다. 먼저 페이지 캐시 (page cache)는 크게 두개의 파티션(partition)으로 분할된다 (실시간 페이지 캐 시와 비실시간 페이지 캐시). 실시간 페이지 캐시는 시스템이 시작될 때 각 태스크 에게 일정 크기만큼 할당되며, 각 실시간 태스크는 자신이 속한 실시간 페이지 캐시 상에서만 페이지 교체가 발생한다. 이는 페이지 교체에 의해 각 실시간 태스크가 추 가적인 page fault를 발생하는 것을 막고, 시스템의 예측성을 높이기 위한 것이다.
반면 모든 비실시간 태스크는 실시간성을 만족할 필요가 없기 때문에 비실시간 페이 지 캐시를 공유한다.
제안하는 시스템에서는 실시간 스케줄러(real-time scheduler)를 통해 각 실시 간 태스크가 실시간성을 만족시키면서 서비스를 제공할 수 있도록 한다. 비실시간 태스크는 시간 분할 스케줄러(time-sharing scheduler)를 통해 서비스를 제공한 다. 실시간 페이저(real-time pager)는 각 실시간 태스크가 초기화될 때 생성되며, 각 실시간 태스크에 할당된 실시간 페이지 캐시의 크기를 조정하는 역할을 수행한다.
실시간 페이저는 특별한 ioctl 명령을 통해 가상 메모리와 직접적으로 통신한다. 여 기에는 ioctl_setsize(), ioctl_getsize() 등의 명령이 포함된다.
본 논문에서는 prepaging 기법5은 고려하지 않는다. prepaging 기법은 페이지 예측이 올바른 경우 page fault를 줄일 수 있지만, 예측이 잘못된 경우에는 오히려
5 프로세스가 특정 페이지에 접근하기 전에 해당 페이지를 저장장치로부터 RAM에 적재하는 방식
불필요한 메모리 사용을 증가시키고, page miss 비율을 높임으로써 결과적으로 시 스템의 예측성을 크게 떨어뜨릴 수 있다는 단점이 있다.
3.2 demand paging 환경에서의 태스크 최악 응답 시간 분석
본 논문에서는 demand paging 환경에서의 태스크 최악 응답 시간을 얻기 위해 각 태스크 별 demand paging 비용을 계산하고, 이를 전통적인 WCRT 분석 기법과 결합하는 방법을 사용한다. 따라서 demand paging 비용 분석의 정확도에 따라 분석 기법의 정확도가 결정된다.
[8]에서는 demand paging 비용 분석의 정확도를 높이기 위해 각 태스크의 실행 경로에 포함된 페이지 집합과 WCET 정보를 바탕으로 각 태스크 인스턴스에 대한 최대 demand paging 비용을 계산하였다. 그러나 본 논문에서는 각 태스크의 실행 경로에 포함된 페이지 집합 정보만을 사용하여 최대 demand paging 비용을 계산한다. 이는 WCET 분석과 demand paging 비용 분석을 독립적으로 수행함으로써, 분석 시 계산 복잡도를 줄이면서도 demand paging 비용이 최악임을 보장하기 위한 것이다.
각 태스크의 demand paging 비용을 예측하기 위한 가장 간단한 방법은 각 태스크 인스턴스에서 적재 가능한 최대 페이지 개수와 최악 demand paging 비용을 서로 곱하는 것이다. 이 경우, demand paging 비용을 고려한 태스크 최악 실행 시간은 식 6과 같이 나타낼 수 있다.
′ (식 6)
식 6에서 는 최악 page fault 처리 시간을, 는 의 각 태스크 인스턴스에서 적재 가능한 최대 페이지 개수를 나타낸다. 따라서 태스크 최악 응답 시간은 식 6에서 를 식 3에 정의된 ′로 대치함으로써 얻을 수 있다. 본 논문에서는 이러한 방법을 naïve 분석 기법으로 정의한다. 그러나 naïve 분석 기법은 demand paging 기법의 특성을 전혀 고려하지 않기 때문에, demand paging 비용을 실제보다 지나치게 높게 예측할 수 있다.
3.2.1 고려 사항
demand paging 비용을 고려한 태스크 최악 응답 시간을 얻기 위해서는 demand paging 시스템의 특성을 반영한 분석 기법이 필요하다. 기존의 최악 응답 시간 이론과 demand paging 시스템에서의 최악 응답 시간 이론 사이에는 다음과 같은 차이점이 존재한다.
첫째, demand paging 비용은 태스크의 특정 실행 경로에 종속적이다. 기존의 최악 응답 시간 분석 이론에서는 추가적인 비용(release jitter, preemption cost 등)을 처리하는데 걸리는 시간은 실행 시간과 독립적이라고 가정한다. 따라서 추가적인 비용을 처리하는데 걸리는 시간은 (단, 는 추가 비용을 처리하는데 걸리는 시간)로 나타낼 수 있다. 반면 demand paging 시스템에서 page fault 의 발생 빈도는 특정 실행 경로에 종속적이기 때문에 demand paging 비용은 태스크의 실행 경로에 따라 달라질 수 있다. 표 1 은 태스크의 실행 경로와 demand paging 비용 간의 관계를 나타낸다.
표 1. 실행 경로와 demand paging 비용 간의 관계 실행 경로
1 10 9 19
2 15 3 18
표 1 에서 태스크 는 두 개의 실행 경로를 포함하며, 각 실행 경로의 최악 실행 시간은 각각 10, 15 이고 demand paging 비용은 각각 9, 3 이라고 하자. 만약 태스크 의 최악 실행 시간이 demand paging 비용과 독립적이라고 가정할 경우, demand paging 비용을 고려한 의 최악 실행 시간은 2 번 실행 경로의 최악 실행 시간 15 와 1 번 실행 경로의 최대 demand paging 비용 9 의 합인 24 가 된다. 그러나 demand paging 비용은 특정 실행 경로에 종속적이기 때문에 demand paging 비용을 고려한 의 실제 최악 실행 시간은 19 가 된다. 만약 최악 실행 시간에 해당하는 실행 경로와 최대 demand paging 비용에 해당하는 실행 경로가 일치하지 않는 경우 demand paging 비용을 고려한 의 최악 실행
시간은 실제 가능한 시간보다 더 높은 것으로 나타날 수 있다. 따라서 demand paging 비용을 고려한 태스크의 최악 응답 시간을 정확하게 얻기 위해서는 각 실행 경로에 대한 demand paging 비용과 최악 실행 시간을 고려해야 한다.
둘째, 이전 태스크 인스턴스에 의해 적재된 페이지를 고려해야 한다. 기존의 최악 응답 시간 이론에서는 각 태스크 인스턴스가 서로 독립적이라고 가정한다. 다시 말하면, 각 태스크 인스턴스는 다른 태스크 인스턴스의 최악 실행 시간에 영향을 미치지 않는다. 따라서 모든 태스크 인스턴스의 최악 실행 시간은 항상 같다.
그러나 이러한 가정은 이전 태스크 인스턴스에 의해 이미 적재된 페이지를 이후 태스크 인스턴스가 재사용할 가능성을 고려하지 않는다는 단점이 있다. 실제로 demand paging 시스템에서는 이전 태스크 인스턴스에서 적재한 페이지가 이후 태스크 인스턴스의 demand paging 비용에 영향을 줄 수 있다. 페이지 재사용에는 두 가지 형태가 있다: 태스크내 페이지 재사용(intra-task page reuses), 태스크간 페이지 재사용(inter-task page reuses). 태스크내 페이지 재사용은 태스크 인스턴스가 이전 태스크 인스턴스에 의해 적재된 페이지를 적재하는 경우 발생한다. 반면, 태스크간 페이지 재사용은 태스크 인스턴스가 다른 태스크에 의해 적재된 페이지를 적재하는 경우 발생한다. 예를 들면 공유 라이브러리와 같이 여러 태스크 간에 페이지를 공유하는 경우가 이에 해당한다. 그림 4 는 페이지 재사용 양상이 각 태스크 인스턴스의 demand paging 비용에 어떻게 영향을 미치는지를 보여준다.
그림 4. 페이지 재사용 양상
그림 4에서 최악 page fault 처리 시간은 1ms이고, 태스크 인스턴스 , ,
, , , 이 각각 페이지 {1, 2}, {2, 4}, {1, 2, 11, 14}를 적재하는 경우 최악 demand paging 비용을 얻는다고 가정하자. 이때 demand paging 비용은 각 태 스크 인스턴스가 적재하는 페이지와 최악 page fault 처리 시간을 곱함으로써 얻을 수 있다. 만약 태스크내 페이지 재사용과 태스크간 페이지 재사용을 고려하지 않는 경우 태스크 인스턴스 , , , , , 의 demand paging 비용은 각각 2, 2, 4가 된 다. 그러나 , 가 실행될 때 이미 페이지 {1, 2}를 적재했기 때문에, , 의 demand paging 비용은 실제로 2가 된다. 이는 태스크간 페이지 재사용에 의해 demand paging 비용이 감소했기 때문이다. 또한 , 이 실행될 때 이미 페이지 {2}를 적재했기 때문에, , 의 demand paging 비용은 실제로 1이 된다. 이는 태 스크내 페이지 재사용에 의해 demand paging 비용이 감소했기 때문이다. 따라서 각 태스크 인스턴스에 대한 demand paging 비용을 정확하게 얻기 위해서는 페이 지 재사용을 고려해야 한다.
3.2.2 태스크 최악 응답 시간 분석 과정
demand paging 환경에서의 태스크 최악 응답 시간을 정확하게 얻기 위해서는 앞서 서술한 고려사항을 반영해야 한다. 본 논문에서는 이를 반영하기 위해 다음과 같은 2 가지 분석 단계를 도입한다 (그림 5).
그림 5. 태스크 최악 응답 시간 분석 과정
첫째, demand paging 비용 분석 단계에서는 태스크를 정적으로 분석하여 각 실행 경로에 속한 페이지 집합을 얻어낸다. 이를 위해 본 논문에서는 제어 흐름 기반(control-flow based)의 분석 기법을 사용한다.
둘째, 페이지 재사용 양상 분석 단계에서는 이전 태스크 인스턴스에 의해 재사용되는 페이지를 고려하여 각 태스크 인스턴스에 대한 최대 demand paging 비용을 구한다. 페이지 재사용 양상 분석 단계에서는 그래프 기반(graph- based)의 분석 기법을 사용한다. 분석 결과 DPC 테이블을 얻게 되는데, 여기서 DPC 란 페이지 재사용 양상이 반영된 태스크 인스턴스의 최악 demand paging 비용을 뜻한다.
3.2.3 demand paging 비용 분석
demand paging 비용 분석 단계의 목적은 태스크의 각 실행 경로에 대해 demand paging 비용을 얻기 위한 것이다. demand paging 비용은 태스크의 실행 경로마다 달라질 수 있기 때문에, 본 논문에서는 분석의 정확도를 높이기 위해 제어 흐름(control-flow) 기반 방법을 사용한다. 분석 과정은 다음과 같다. 먼저 각 태스크에 대해 제어 흐름 그래프를 생성하고, 그래프 내의 기본 블록(basic block)과 해당 기본 블록을 포함하는 메모리 페이지 간에 연관 관계를 생성한다.
그림 6은 예제 제어 흐름 그래프를 사용한 각 기본 블록과 메모리 페이지 간의
관계를 보여준다. 예제 제어 흐름 그래프는 4개의 실행 경로(1-2-4-8, 1-2-5- 9-11, 1-3-6-10-11, 1-3-7-10-11)를 포함하며, 각 기본 블록은 6개의 메모리 페이지에 사상되어 있다.
그림 6. 제어 흐름 그래프 상에서 basic block과 페이지 대응
다음 단계는 앞선 정보를 바탕으로 page sequence를 식별해 내는 것이다. 본 논 문에서는 page sequence를 , 로 정의한다. 이때 , 는 태스크 가 실행되는 동 안 적재되는 j번째 page sequence를 의미한다. 단, 여러 실행 경로가 동일한 page sequence에 속한 페이지를 적재할 수 있기 때문에, 일반적으로 page sequence의 수는 실행 경로와 일치하지 않는다. 예를 들어, 그림 6에서 는 4개 의 실행 경로를 가지고 있지만, 3개의 page sequence를 포함한다 ( , ={1, 4},
, ={1, 3, 6, 5}, , ={1, 2, 5}). 이는 실행 경로 3, 4(1-3-6-10-11, 1-3- 7-10-11)가 모두 , 에 속한 페이지를 적재하기 때문이다.
분석의 정확도를 높이기 위해서는 반복문(loop statement)과 같은 복잡한 프로그램 구조를 고려해야 한다. 이를 위해 본 논문에서는 다음과 같은 수식을 정의한다. 먼저 기본 블록 과 사이에 N개의 반복이 존재할 때, 이를 , 로 정의한다. 제어 흐름 그래프를 통해 , 내의 실행 경로를 파악할 수 있는데, 이를 로 정의한다. 그리고 , , 는 , 에 속한 번째 실행 경로로 정의하며, , , 는 실행 경로 , , 가 실행될 때 적재되는 page sequence를 의미한다. 본 논문에서는 반복문 내의 실행 경로는 해당 실행 경로의 page sequence 내의 페이지가 많은 순서대로 정렬되어 있다고 가정한다.
위의 정의를 바탕으로 , 내의 번째 page sequence는 다음과 같이 재정의된다.
, , , ,
,
(식 7)
예를 들어, 그림 6에서 반복 횟수 5를 갖는 3, 10 이 존재한다고 가정하자.
이 경우, 3, 10 은 두개의 서로 다른 page sequence를 가진다: =2,
, , ={2, 3, 5}, , , ={2, 5}. 그 결과 , 은 {1, 2, 3, 5}로 변경된다.
이로부터 의 j번째 page sequence에 대한 demand paging 비용은
, 와 같이 나타낼 수 있다. 이때 는 최악 page fault 처리 시간을 나타낸다.
3.2.4 페이지 재사용 양상 분석
demand paging 환경에서는 특정 태스크 인스턴스의 demand paging 비용이 이전에 수행된 태스크 인스턴스가 적재한 페이지 때문에 줄어들 가능성이 있다.
페이지 재사용 양상 분석의 목적은 태스크 인스턴스간에 재사용되는 페이지를 고려하여 각 태스크 인스턴스에 대한 최악 실행 시간을 구하는 데 있다. 페이지 재사용 양상 분석 기법은 그래프 이론(graph-theoretical)을 바탕으로 하며, 분석 단계는 다음과 같다.
첫째, demand paging 비용 분석 단계로부터 얻어진 제어 흐름 그래프를
사용하여 그래프를 생성한다. 그래프에서 각 노드는 실행 경로에 대한 고유번호를 의미하며, 각 열은 인스턴스의 순서를 뜻한다. 그리고 첫 번째 노드 ‘S’는 그래프의 논리적인 시작을 의미하고, 간선의 가중치는 특정 인스턴스에서 특정 실행 경로에 대한 최악 demand paging 비용을 의미한다.
둘째, 첫 번째 단계로부터 생성된 그래프를 사용하여 페이지 재사용 양상을 분석하고, DPC(Demand Paging Cost) 테이블을 생성한다. DPC 테이블 내의 원소 θ
, 는 각 태스크 인스턴스에 대한 최악 demand paging 비용을 나타낸다.
DPC 테이블은 최종적으로 태스크 최악 응답 시간을 계산하는데 사용된다. 그림 7은 DPC 테이블의 구성을 보인다.
그림 7. DPC 테이블
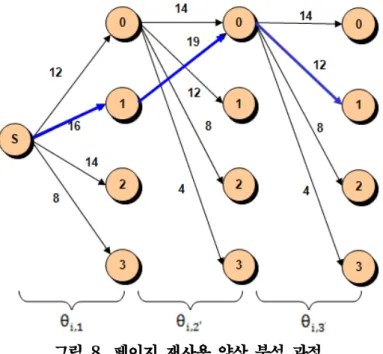
예를 들어, 페이지 재사용 양상을 고려한 태스크 인스턴스 , , , , , 의 최악 demand paging 비용은 각각 , , , , , 이다. 그림 8은 , 를 계산하는 과정을 보여준다.
그림 8. 페이지 재사용 양상 분석 과정
그림 8에서 첫 번째 태스크 인스턴스는 1번 실행 경로를 수행할 때 demand paging 비용이 최대가 되며, 이때의 , 값은 16이다. 다음으로 두 번째 태스크 인스턴스는 첫 번째 태스크 인스턴스의 실행 경로에 해당하는 1번 실행경로로부터 최악 demand paging 비용을 갖는 실행 경로를 취한다. 이 경우 두 번째 태스크 인스턴스는 실행 경로 0일 때 최대 demand paging 비용을 가지며, 이때의 , 값은 19이다.
3.2.5 태스크 최악 응답 시간 계산
demand paging 비용 분석 단계 및 페이지 재사용 양상 분석 단계를 통해 각 태스크 인스턴스에 대한 최악 실행 시간을 얻을 수 있다. demand paging 비용을 고려한 태스크 최악 응답 시간은 식 8과 같이 나타낸다.
(식 8)
식 8에서 태스크 최악 응답 시간은 를 만족할 때까지 재귀적으로
계산된다. 는 τ 에 대한 demand paging 비용을 나타내며, 각 태스크의 요청 비율(request rate)에 따라 달라진다. 의 정의는 식 9와 같이 나타낸다.
θ, (식 9)
식 9에서 , 는 demand paging 비용을 고려한 태스크 인스턴스 , 의 최악 실행 시간을 나타내며, 페이지 재사용 양상 분석 단계로부터 얻어진다. 는
단계로부터 얻어진 의 최대 요청 비율을 나타내며, 식 10을 만족한다.
(식 10)
, 에 해당하는 실행 경로의 WCET를 , 라고 하자. 즉, , 는 , 에 해당하는 demand paging 비용이다. 이 경우 , 는 항상 보다 작거나 같다. 또한
, 는 매 태스크 인스턴스에 대한 최악 demand paging 비용에 해당하므로, 또한 최악임을 보장할 수 있다. 따라서 식 8로부터 얻어진 태스크 최악 응답 시간은 최악의 경우에도 안전함을 보장할 수 있다.
4 실험
4.1 태스크 최악 응답 시간 분석 결과
본 논문에서는 제안한 태스크 최악 응답 시간 분석 기법의 정확성을 검증하기 위해, 가상의 태스크 집합에 대해 태스크 수행을 시뮬레이션 하였다. 분석은 크게 두 단계로 이루어진다. 첫 번째 단계는 정적 프로그램 분석기를 사용해 프로그램 이미지를로부터 제어 흐름 그래프 및 페이지 정보를 얻는 것이다. 그림 9 는 정적 프로그램 분석기의 세부 구조를 보여준다. 정적 프로그램 분석기는 ARM/ELF 실행 이미지를 역어셈블하여 각 기본 블록과 페이지 정보를 추출한 후, 이로부터 CFG 를 생성해낸다.
그림 9. 정적 프로그램 분석기
두 번째 단계는 정적 프로그램 분석기로부터 얻어진 CFG 정보를 통해 demand paging 비용 분석, 페이지 재사용 분석 등을 수행 한 후 태스크 최악 응답 시간을 얻는 것이다. 태스크 최악 응답 시간 분석기는 임의의 태스크 집합을 입력으로 받아 demand paging 비용을 고려한 태스크 최악 응답 시간을 계산한다 (그림 10).
그림 10. 태스크 최악 응답 시간 분석기
표 2는 실험에 사용된 가상의 태스크 집합과 매개변수 정보를 나타낸다.
표 2. 태스크 집합 및 매개변수
태스크 집합 실행 경로 수 , ,
1
5 1 1 {45}
15 1 2 {46}
60 5 5
{1, 2, 3}
{4, 5, 6}
{7, 8}
{9, 10, 11, 12, 13}
{14, 15, 16, 17}
180 1 60 {47}
2
5 1 1 {45}
15 1 2 {46}
60 5 5 {1, 2, 3}
{3, 4, 5}
{1, 7, 8}
{4, 5, 7, 13, 14}
{14, 15, 16, 17}
180 1 60 {47}
3
5 1 1 {45}
15 1 2 {46}
60 5 5
{1, 2, 3}
{2, 3, 4}
{1, 3, 7, 8}
{7, 8, 13, 14}
{1, 2, 15, 16, 17}
180 1 60 {47}
실험에 사용한 태스크 집합은 3개이며, 각 태스크 집합은 각각 4개의 태스크로 구성되어 있다. 표 2에서 및 , 의 단위는 모두 ms(millisecond)이고, 는 2이며, 각 태스크의 데드라인은 주기와 동일하다고 가정한다.
논문에서 제안한 분석 기법은 페이지 적재 양상을 고려하기 때문에, 페이지 적재 양상에 따른 태스크 최악 응답 시간 분석 결과의 정확성을 검증하기 위해 본 실험에서는 태스크 3의 매개변수 중 페이지 적재 양상만을 다양하게 변화시켰다.
태스크 3의 경우, 태스크 집합 1에서는 각 실행경로마다 중복해서 적재하는 페이지가 없기 때문에 가장 단순한 페이지 적재 양상을 가지며, 태스크 집합 3에서는 여러 실행 경로에 공통으로 포함된 페이지가 많기 때문에 가장 복잡한 페이지 적재 양상을 가진다.
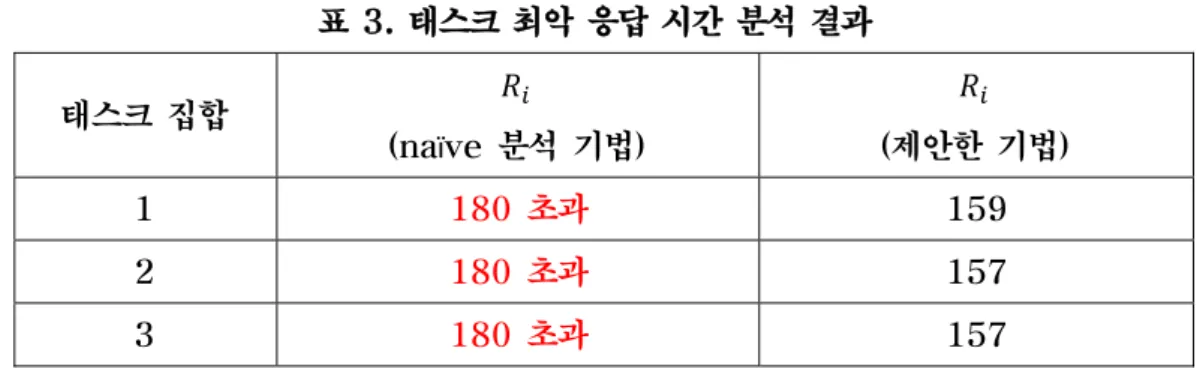
페이지 적재 양상에 따른 분석 결과의 정확성을 검증하기 위해, naïve 분석 기법과 제안한 기법에 따른 태스크 최악 응답 시간을 비교하였다. 표 3은 표 2에서 정의한 가상 태스크 집합을 사용한 시뮬레이션 결과를 보여준다.
표 3. 태스크 최악 응답 시간 분석 결과
태스크 집합
(naïve 분석 기법)
(제안한 기법)
1 180 초과 159
2 180 초과 157
3 180 초과 157
먼저 naïve 분석 기법은 모든 태스크 집합에 대해 태스크 최악 응답 시간이 데드라인인 180ms를 초과한 것으로 나타난 반면 제안한 기법에서는 모두 데드라인보다 작은 것으로 나타났다. 이는 페이지 적재 양상을 고려하지 않을 경우 지나치게 높은 태스크 응답 시간을 얻을 가능성이 있음을 보여준다. 특히 상위 우선순위를 갖는 태스크에 의한 응답 시간 지연이 발생할 수 있다. 태스크 집합 1에서 태스크 3의 각 실행 경로는 모두 다른 페이지 집합을 적재함에도 불구하고 naïve 분석 기법과 제안한 기법간에 최악 응답 시간 차이가 발생했다. 높은 우선순위를 갖는 태스크일수록 요청 비율이 높아지기 때문에, 페이지 적재를 고려하지 않는 경우 상위 우선순위 태스크에 의한 demand paging 비용이 최악 응답 시간을 지나치게 높일 수 있다. 예를 들면, 태스크 1의 요청 비율은 최대 36(180/5)이므로, naïve 분석 기법에서는 태스크 1의 demand paging 비용을 2 36 72인 반면, 제안한 기법에서는 2가 된다. 또한 태스크 집합 1보다 태스크 집합 3에서 최악 응답 시간이 더 작은 것으로 나타났는데, 이는 태스크 집합 3의 페이지 적재 양상이 태스크 집합 1에 비해 더 복잡하기 때문이다. 실험 결과는 논문에서 제안한 분석 기법이 페이지 적재 양상을 고려하지 않는 naïve 분석 기법에 비해 더 정확한 분석 결과를 나타냄을 보여준다.
5 결론 및 향후 과제
본 논문에서는 플래시 메모리를 사용하는 demand paging 환경에서의 태스크 최악 응답 시간 분석 기법을 제안하였다. 제안한 기법은 각 태스크의 실행 경로와
이전 태스크 인스턴스에 의한 페이지 적재 양상에 따라 demand paging 비용이 달라진다는 점을 반영한다. 분석 단계는 크게 demand paging 비용 분석 단계와 페이지 재사용 양상 분석 단계로 나누어진다.
본 논문에서 제안한 방법은 다음과 같은 개선점이 있다. 첫째, 반복문과 같은 복잡한 프로그램 구조, 페이지 교체 정책(page replacement policy)이나 공유 코드(shared code)등을 고려함으로써 실제 실시간 시스템에서 사용 가능하도록 분석 기법을 확장할 필요가 있다. 둘째, 분석 결과를 바탕으로 예측 가능한 demand paging 시스템을 설계할 수 있다. 예를 들면, 태스크 수행 이전에 일련의 페이지를 적재하는 pre-paging 등의 방법을 사용함으로써 태스크 수행 중에 page fault가 일어나지 않도록 할 수 있다.
6 참고 문헌
[1] K. Tindell.: Adding Time-Offsets to Schedulability Analysis. Technical Report YCS 221, Dept.
of Computer Science, University of York, England (1994)
[2] Palencia, J. C. and Gonzlez Harbour, M.: Schedulability Analysis for Tasks with Static and Dynamic Offsets. In Proceedings of the IEEE Real-Time Systems Symposium (1998) [3] N.Audsley et al.: Applying new scheduling theory to static priority preemptive scheduling.
Software Engineering Journal. (1993) 284-292
[4] J. V. Busquets-Mataix, J. J. Serrano-Martin, R. Ors, P. Gil, and A. Wellings.: Adding Instruction Cache Effect to Schedulability Analysis of Preemptive Real-Time Systems. Proceedings of the 2nd Real-Time Technology and Applications Symposium (1996)
[5] C. Lee, J. Hahn, Y. Seo, S. Min, R. Ha, S. Hong, C. Park, M. Lee, and C. Kim.: Analysis of Cache-related Preemption Delay in Fixed-Priority Preemptive Scheduling. IEEE Transactions on Software Engineering (1996) 264-274
[6] K. Tindell, A. Burns, and A. Wellings.: An Extendible Approach for Analysing Fixed-Priority Hard Real-Time Tasks. Journal of Real-Time Systems, 6(2). (1994) 133-151
[7] Scott F. Kaplan, Lyle A. McGeoch, Megan F. Cole.: Adaptive caching for demand prepaging.
Proceedings of the 3rd international symposium on Memory management. Berlin, Germany (2002) [8] Young-Ho Lee, Sung-Soo Lim.: Worst Case Response Time Analysis for demand paging on Flash Memory. Proceedings of the 2nd International Workshop on Software Support for Portable Storage. (2006)
[9] A. Ermedahl. A Modular Tool Architecture for Worst-Case Execution Time Analysis. PhD thesis, Uppsala University, June 2003.
[10] Iain Bate , Ralf Reutemann, Worst-Case Execution Time Analysis for Dynamic Branch Predictors, Proceedings of the 16th Euromicro Conference on Real-Time Systems (ECRTS'04), p.215-222, June 30-July 02, 2004
[11] A. Ermedahl, J. Gustafsson, and B. Lisper. Experiences from industrial WCET analysis case studies. In Reinhard Wilhelm, editor, Proc. 5th International Workshop on Worst-Case Execution Time Analysis, (WCET'2005), pages 19--22, Palma de Mallorca, July 2005.
[12] L. Belady, “A Study of Replacement Algorithms for a Virtual-Storage Computer,” IBM Systems Journal, vol.5, no.2, pp.78-101, 1966. P. J. Denning, “The Working Set Model for Program Behavior,” Communications of the ACM, vol.11, no.5, May 1968.
[12] R. L. Mattson, J. Gecsei, D. R. Slutz, and I. L. Traiger, “Evaluation Techniques for Storage Hierarchies,” IBM Systems Journal, vol.9, no.2, pp.78-117, 1970.
[13] T. Johnson and D. Shasha, “2Q: A Low Overhead High Performance Buffer Management Replacement Algorithm,” Proc. of 20th International Conference Very Large Data Bases, pp.439- 450, 1994.
[14] P. E. O'Neil and G. Weikum, “The LRU-K Page Replacement Algorithm for Database Disk Buffering,” Proc. of ACM SIGMOD Conference, May 1993.
[15] Y. Smaragdakis, S. Kaplan, and P. Wilson, “EELRU: Simple and Effective Adaptive Page Replacement,” Proc. of ACM SIGMETRICS Conference, 1999.
[16] D. Lee, J. Choi, J. Kim, S. Noh, S. Min, Y. Cho, and C. Kim, “LRFU: A Spectrum of Policies that Subsumes the LRU and LFU Policies”, IEEE Transactions on Computers, vol. 50, no. 12, pp.1352-1361, Dec. 2001.
[17] N. Megiddo and D.S. Modha, “ARC: A Self-Tuning, Low Overhead Replacement Cache,”
Proc. of USENIX Conference File and Storage Technologies (FAST), 2003.
[18] N. Young, “The k-server Dual and Loose Competitiveness for Paging,” Algorithmica, vol.11, no. 6, pp. 525-541, June 1994.
[19] J. Jeong and M. Dubois, “Optimal Replacements in Caches with Two Miss Costs,” Proc. of the Eleventh Annual ACM Symposium on Parallel Algorithms and Architectures, 1999.
[20] J. Jeong and M. Dubois, “Cost-sensitive Cache Replacement Algorithms,” Proc. of the Symposium on High Performance Computer Architecture (HPCA), Jan. 2003.
[21] H. Lee and N. Chang, “Low-Energy Heterogeneous Nonvolatile Memory Systems for Mobile Systems,” Journal of Low Power Electronics, vol.1, no.1, pp.52-62, Apr. 2005.