Development of Naïve-Bayes classification and multiple linear regression model to predict agricultural reservoir storage rate based on weather forecast data
Kim, Jin UkaㆍJung, Chung GilaㆍLee, Ji Wana*ㆍKim, Seong Joona
aDepartment of Civil, Environmental and Plant Engineering, Konkuk University
Paper number: 18-052
Received: 25 July 2018; Revised: 9 August 2018; Accepted: 9 August 2018
Abstract
The purpose of this study is to predict monthly agricultural reservoir storage by developing weather data-based Multiple Linear Regression Model (MLRM) with precipitation, maximum temperature, minimum temperature, average temperature, and average wind speed. Using Naïve-Bayes classification, total 1,559 nationwide reservoirs were classified into 30 clusters based on geomorphological specification (effective storage volume, irrigation area, watershed area, latitude, longitude and frequency of drought). For each cluster, the monthly MLRM was derived using 13 years (2002~2014) meteorological data by KMA (Korea Meteorological Administration) and reservoir storage rate data by KRC (Korea Rural Community). The MLRM for reservoir storage rate showed the determination coefficient (R2) of 0.76, Nash-Sutcliffe efficiency (NSE) of 0.73, and root mean square error (RMSE) of 8.33% respectively. The MLRM was evaluated for 2 years (2015~2016) using 3 months weather forecast data of GloSea5 (GS5) by KMA. The Reservoir Drought Index (RDI) that was represented by present and normal year reservoir storage rate showed that the ROC (Receiver Operating Characteristics) average hit rate was 0.80 using observed data and 0.73 using GS5 data in the MLRM. Using the results of this study, future reservoir storage rates can be predicted and used as decision-making data on stable future agricultural water supply.
Keywords: Reservoir storage rate, Naïve-Bayes classification, Multiple linear regression model, GloSea5 (GS5)
기상예보자료 기반의 농업용저수지 저수율 전망을 위한 나이브 베이즈 분류 및 다중선형 회귀모형 개발
김진욱aㆍ정충길aㆍ이지완a*ㆍ김성준a
a건국대학교 공과대학 사회환경플랜트공학과
요 지
본 연구의 목적은 기상자료(강수량, 최고기온, 최저기온, 평균기온, 평균풍속) 기반의 다중선형 회귀모형을 개발하여 농업용저수지 저수율을 예측 하는 것이다. 나이브 베이즈 분류를 활용하여 전국 1,559개의 저수지를 지리형태학적 제원(유효저수량, 수혜면적, 유역면적, 위도, 경도 및 한발빈 도)을 기준으로 30개 군집으로 분류하였다. 각 군집별로, 기상청 기상자료와 한국농어촌공사 저수지 저수율의 13년(2002~2014) 자료를 활용하 여 월별 회귀모형을 유도하였다. 저수율의 회귀모형은 결정계수(R2)가 0.76, Nash-Sutcliffe efficiency (NSE)가 0.73, 평균제곱근오차가 8.33%
로 나타났다. 회귀모형은 2년(2015~2016) 기간의 기상청 3개월 기상전망자료인 GloSea5 (GS5)를 사용하여 평가되었다. 현재저수율과 평년저 수율에 의해 산정되는 저수지 가뭄지수(Reservoir Drought Index, RDI)에 의한 ROC (Receiver Operating Characteristics) 분석의 적중률은 관 측값을 이용한 회귀식에서 0.80과 GS5를 이용한 회귀식에서 0.73으로 나타났다. 본 연구의 결과를 이용해 미래 저수율을 전망하여 안정적인 미 래 농업용수 공급에 대한 의사결정 자료로 사용할 수 있을 것이다.
핵심용어: 저수율, 나이브 베이즈 분류, 군집분석, 다중선형 회귀모형, GloSea5 (GS5)
© 2018 Korea Water Resources Association. All rights reserved.
*Corresponding Author. Tel: +82-2-444-0186 E-mail: [email protected] (J. W. Lee)
1. 서 론
최근 전 지구적으로 발생하고 있는 기후변화는 극치기상 의 발생빈도를 증가시켜 집중호우와 극한가뭄을 주기적으로 발생해 인명 및 재산피해를 급증시키고 있다. 특히, 기후의존 적인 산업 성격을 띠는 농업은 기후변화에 크게 민감하기 때 문에, 농업의 역할인 안정적인 먹거리 수급과 농업생산기반 의 유지를 위해서는 기후변화로 인한 극치기상에서도 안정적 인 농업용수를 공급할 수 있어야 한다.
농업용수의 안정적인 공급을 위해서는 저수량을 이루는 인자를 분석하여 저수량의 변동을 예측해야하며, 최근 연구 를 살펴보면 각기 다른 기상, 지형적인 인자들을 변수로 두고 통계학적 분석을 통해 저수량을 예측하는 다중선형회귀분석 을 주로 이용한다. Kim and Lee (2008)는 낙동강 유역의 지리 학적 인자를 이용하여 회귀분석을 통해 저수량 분석을 실시하 여 미계측 유역에서의 저수량을 예측한 바 있고, Ahn et al.
(2007)은 안성천 유역에서 기상인자들을 이용해 저수지 저수 량과의 회귀분석을 실시하고 저수량을 예측하였다. Kang (2013)은 안동댐 저수량에 가장 큰 요인이 되는 유입량을 예측 하기 위해 남방진동지수, 해수면 온도, 500 hPa 지위 고도자료 등의 예측인자로 다중선형 회귀분석을 진행하여 저수지의 유 역특성을 판단한 바 있다. 또한, 가뭄지수를 통해 저수지 가뭄 에 영향을 주는 인자를 계산하여 저수량을 예측하는 연구도 수행된 바 있다(Yoo et al., 2012). 그러나 이와 같은 선행연구 들은 대댐 위주 및 유역단위에서의 분석을 통한 저수율 예측 연구가 주를 이루었고, 전국적인 분석을 위한 연구는 지역적 특성과 저수지의 형태학적인 복잡성 때문에 활발히 수행되지 못했다. 이러한 단점이 개선된 저수율 예측을 위해서는 우선 저수지의 형태학적 혹은 지역적 특성이 반영된 체계적인 군집 분석이 요구된다.
전국단위의 저수지의 효율적인 운영과 관리를 위한 군집 분석 방법으로 Lee et al. (2003)은 국내 저수지의 수질에 영향 을 미치는 인자들을 이용해 군집분석을 실시하여 수질 관리 방안과 부영양화 기준을 제시하였고, Lee et al. (2015)은 저수 지 파괴원인에 도출된 인자들을 이용하여 주성분 분석과 군집 분석을 이용하여 농업용저수지의 체계적인 안전관리를 위한 저수지 유형화를 시도한 바 있다. Korea Rural Corporation (2017)에서는 농어촌용수구역을 군집분석을 통해 유형화하 고 기후변화 영향 실태조사 및 취약성 평가를 실시한 바 있다.
한편, 국내에서 빈번하게 발생하는 단기가뭄(1~3개월)에 대응하기 위해 기상청에서는 기상예보자료 Glosea5 (GS5)를 생산하여 기상 가뭄의 예측자료 등으로 현업에 활용중이다.
GS5 데이터를 이용해 수문학적 가뭄 및 강우-유출 모형으로 댐 저수지 모의 운영 전망 자료를 생산하여 향후 3개월 내 예상 되는 가뭄 및 용수 부족상황을 제공함으로써 가뭄에 선제적으 로 대응하고 피해를 최소화하려는 연구가 진행되었다(Son et al., 2015; Song et al., 2017; Li et al., 2016).
따라서 본 연구는 형태학적 특성이 같은 저수지를 군집화 하여 전국의 저수지를 분류하고, 군집의 특성을 반영한 월별, 군집별 회귀식을 개발하여 저수율 데이터를 생산하고 기상예 보자료(GS5)를 적용하여 회귀식의 미래저수율전망 활용가 능성을 평가하고자 하였다.
2. 재료 및 방법
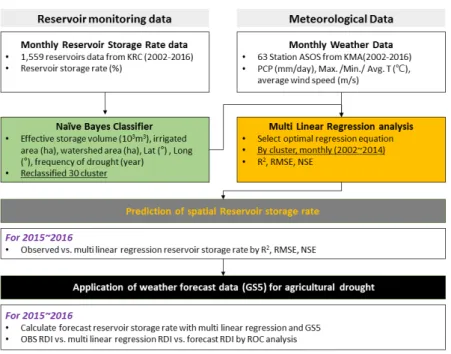
본 연구에서는 한국농어촌공사 저수지 3,067개의 제원 자 료를 수집하여 나이브 베이즈 분류기법을 통한 저수지의 형태 학적인 군집분석을 수행하였다. 또한 분류된 군집별 월별 저 수율 예측 회귀식 산정을 위해 저수율 관측 자료와 전국 63개 기상관측자료를 수집하였으며, 저수율과 기상인자를 독립 변수로 하는 저수율 예측 다중선형 회귀식을 산정하였다. 산 정된 회귀식의 정확도를 검증하기 위해 관측자료와의 상관성 분석을 실시하였다. 본 연구의 연구 흐름도는 Fig. 1과 같다.
2.1 농업용저수지 저수율 자료 및 기상 관측자료 수집 농업생산기반정비통계연보(KRC, 2017)에 따르면 전 국 농업용저수지는 총 17,313개로 농어촌공사 관할 저수지 3,403개소 및 시군관리 저수지 13,910개로 구성되어 있으며, 국내 농업용수 사용량 중 약 60%를 공급하는 핵심 농업기반 시설이다(Kim et al., 2017). 그러나 시군관리저수지의 경우 에는 제도적 지원 및 인력의 부족으로 수문계측기 설치 및 관 리를 수행하지 못해 저수율을 산정하는데 필수적인 수문 계측 자료를 확보하기가 어렵다(Shin and Lee, 2012). 따라서 수문 계측기가 설치된 농어촌공사 관할 저수지를 대상으로 저수율 자료를 수집하여 저수율 분석을 실시하고자 하였다. 농업기 반시설관리시스템 RIMS (Rural Infrastructure Management System)에서는 농업용저수지의 저수율 자료를 2002년부터 10분자료 및 일자료로 제공하고 있다. 저수율 예측 회귀식의 산정을 위해 충분한 저수율 데이터가 필요하므로 한국농어촌 공사에서 관리중인 저수지 3,403개소 중 2002년부터 데이터 를 가지고 있는 3,067개 저수지의 저수율 관측자료를 수집하 였고, 수집된 일자료를 월별로 정리해 분석에 활용하였다. 수 집된 자료 중 이상값과 결측자료가 존재할 경우 데이터를 내
삽 혹은 배제하였다.
기상자료는 기상청 종관자동기상관측장비(ASOS)가 설 치된 기상관측소 중 결측자료가 없고, 30년 이상의 과거 기상 자료를 보유하고 있는 63개 관측소 자료를 이용하였다. 저수 율 회귀분석을 실시하기 위한 인자는 5가지의 기상인자(강수, 최고기온, 평균기온, 최저기온, 평균풍속) 자료를 활용하였다.
기존의 저수지 가뭄지수(Reservoir Drought Index, RDI) 는 현재에 대한 평년(1976~2005) 대비 가뭄 상태를 표현하도 록 제안되었으나, 본 연구에서는 기상청 3개월 예보자료를 활 용해 저수율을 예측하고자 기존의 RDI를 개선 한 RDI-3을 이 용하였다(Eq. (1)).
(1)
여기서, 는 해당 월을 기준으로 3개월 이전 저수 율의 평균값을, 는 과거 30년 평년저수율에서 해당 월을 기준으로 3개월 이전 저수율의 평균값을 의미한다.
RDI-3의 결과값에 따라 -0.25~-0.5는 보통 가뭄, -0.5~-1.0 심 한 가뭄, -1 이하는 극한 가뭄의 단계를 나타낸다.
2.2 나이브 베이즈 분류
어떤 항목을 미리 정의된 범주들로 구분 짓는 분류 (Classification) 기법은 의사결정트리, 로지스틱 회귀분석,
나이브 베이즈 분류, SVM (Support Vector Machine) 등의 다양한 방법으로 개발되었다. 그 중, 나이브 베이즈 분류 (Naïve-Bayes Classifier, NBC)는 주어진 클래스 내에서 각 각의 속성들이 서로 독립이라는 가정을 기본으로 조건부 확 률을 이용하여 분류하는 기계학습 알고리즘 중에 하나이다 (Park, 2012). 베이즈 기반 추론은 불충분한 정보를 가진 환경 에서 항목들을 분류하고 추론하는 대표적인 기법으로 조건부 확률을 통한 의사결정에 많은 장점이 있으며 간단한 계산과정 에도 불구하고 분류 정확도가 높아 많은 양의 자료를 분류 하 는데 널리 이용되고 있다(Kim and Kwon, 2005; Kim and Lee, 2011; Han and Cha, 2017).
나이브 베이즈 분류를 위해 분류의 기준이 되는 각 클래스 에서 설명변수들의 사전 확률분포와, 분류하고자 하는 인스 턴스들의 설명변수와 클래스 사이의 조건부 확률분포를 바탕 으로 사후 확률을 계산하여 구한다(Hong et al., 2008). 분류될 개체들은 j개의 설명변수를 나타내는 인스턴스 로 표현되며 분류 결과에 해당하는 클래스는 로, 각 구간의 확률 값은 로 표현된다. 다음 식을 통해 최대 확률을 갖는 그룹 를 찾아내어 분류하게 된다(Eq. (2)).
arg
∈ (2)
한편, 나이브 베이즈 분류는 속성에 포함된 특정 범주에 대 해 각각 일어날 확률을 기반으로 클래스에 해당하는 결과를
Fig. 1. The production of reservoir storage rate forecasting data
분류하는 방법이므로 연속적인 값을 가지는 속성을 그대로 적용하기 위해서는 설명변수 에 대한 가우시안 밀도함수의 가정이 필요하다. 때문에 해당 속성에 대한 독립적인 확률 값 을 계산하여 다음의 식에 적용할 수 있다(Eq. (3)).
∙
(3)
여기서, 는 각 설명변수에 대한 연속적인 값들의 평균을 의 미하며 는 표준편차를 의미한다(Park and Yoon, 2017; Yim and Hwang, 2014). 가우시안 밀도함수를 고려한 나이브 베이 즈 분류기법은 범주형 데이터에서도 빠른 계산과정과 부족한 데이터에서도 높은 정확도를 보여주기 때문에 많은 저수지를 분류하여 분석하기에 적합하다.
2.3 다중선형 회귀분석
다중회귀분석이란 객관적으로 나타난 자료를 바탕으로 두 개 이상의 독립변수(independent variable)를 이용해 종속변 수(dependent variable)와의 상호관계를 분석하여 종속변수 를 예측하거나 제어하기 위한 통계적 방법이다. 일반적으로 대부분의 자연적 현상을 설명할 때 종속변수 는 두 개 이상 의 독립변수에 의해 좌우되는 경우가 있으며, 설명력 있는 적 절한 독립변수 여러 개 선택해 종속변수를 나타낼 경우 회귀 식의 정확도가 향상된다(Yun et al., 2009). 설명하는데 개의 독립변수인 ⋯ 를 도입할 때 다중회귀모형은 다음 과 같이 정의된다(Eq. (4)).
⋯ (4)
여기서, ⋯ 는 회귀계수 또는 매개변수를 의미하고,
는 서로 독립이고 동일한 분포 N(0, )을 따르는 오차항이 다. …는 번째 독립변수 의 회귀계수(기울기) 를 의미하는데, 의 값이 한 단위 증가할 때의 값의 평균 변화량을 나타낸다. 그리고 는 독립변수 의 번째 관측 치를 의미한다(Choi et al., 2012).
2.4 GS5 예보자료
기상청에서는 잦아진 이상기후로 인해 피해경감과 고품질 장기예보자료를 효율적인 정책수립을 지원하기 위해 영국 기 상청과의 공동 구축 및 운영을 통한 GloSea5 (Global Seasonal Forecasting System, GS5) 모델을 도입하였다(KMA, 2012).
GS5 모델은 대기모델, 해양모델, 해빙모델, 지표모델로 구성
된 전 지구 결합모델 HadGEM3에 기초하여 각 모델들을 결합 하여 구성된 계절예측시스템이며, 현재부터 3개월 동안의 강 수량, 최고 ․ 최저기온, 평균기온, 평균풍속에 대한 예보자료를 제공한다.
2.5 모형의 평가 방법
회귀모형으로 모의된 저수율의 적합성과 실측저수율 간의 상관성을 평가하기 위해 많이 이용되는 평가지표인 결정계수 (Determination Coefficient, R2), 평균제곱근오차(Root Mean Square Error, RMSE)를 이용하였고 모형의 효율성을 검증하 기 위해 Nash-Sutcliffe 효율성지수(Nash-Sutcliffe efficiency coefficient, NSE)를 사용하였다(Kim and Kim, 2013; Kim and Kim, 2017).
2015~2016 가뭄기간에 대해 농업용저수지 가뭄지수인 RDI를 산정하고, 가뭄지수의 객관적 평가를 위해 확률론적 평가방법인 ROC (Receiver Operating Characteristics) 모형 을 설정하여 회귀식의 가뭄 재현능력을 평가하였다. ROC 분 석은 주로 기상분야에서 확률예보의 정성적 검증에 활용되는 기법으로(Mason, 1982) Table 1과 같이 모형을 설정하여 평 가하게 된다.
2015~2016년 동안 관측자료 기반의 RDI-3를 “관측 결과 (Observed Value)로 설정하고 같은 기간동안 회귀방정식을 통해 모의된 RDI-3 결과를 예측 결과(Prediction Value)로 분 류하여 “가뭄 발생(O)” 과 “가뭄 미발생(X)”의 각각 2가지로 분류 하였다. 실제 가뭄(관측자료기반 RDI-3)이 발생한다고 기록된 경우에 회귀식 기반 RDI-3 에서도 가뭄이 발생했다고 나타나면 “성공(Hit, H)”, 발생하지 않았다고 나타나면 “잘못 (Missing, M)”으로 설정하고, 실제 가뭄이 발생하지 않을 경 우 예측결과에서 가뭄이 발생한다면 “실패(False, F)” 그렇지 않다면 “음의 성공(Negative hit, N)”으로 나타내었다. 이중 H와 N을 참의 값으로 판단하고, M과 N은 거짓의 값으로 결정 하였다.
4가지의 구분을 통해서 적중률과 비적중률을 각각 계산하 게 되고 ROC 좌표계 내에서 하나의 점으로 표현함으로써 ROC 곡선을 구성할 수 있다. ROC 값의 범위는 0에서 1사이 의 값을 가지며, 곡선 아래의 면적(Area Under Curve, AUC)
Table 1. ROC analysis
RDI-3 produced regression model Drought Non-drought Observed
RDI-3
Drought Hit (H) False (F)
Non-drought Missing (M) Negative hit (N)
이 산정 된다. AUC 값은 완벽한 예보일 경우 1.0, 예보의 기술 이 없을 경우에는 0.5의 값을 가지게 된다(Bae et al., 2013).
3. 결과 및 고찰
3.1 용수구역 대표 저수지 자료를 활용한 나이브 베이즈 분류
나이브 베이즈 분류는 미리 설계된 설명변수를 입력해서 클래스를 분류해야한다. 이를 위해 전국 농업용수 511개 구역 에 대해 9가지 항목(용수구역 면적, 논면적, 밭면적, 수리답 면적, 관개 전 면적, 수리답율, 관개전율, 용수구역 내 저수지 수, 용수구역 내 농업생산기반 총 시설 수)을 기준으로 군집분 석 및 데이터마이닝의 의사결정나무기법을 활용해 군집으로 분류한 후 각 군집에 대해 용수구역 조사 대상지구 65개소를 선정한(KRC, 2017) 선행연구사례를 바탕으로 클래스를 설 정하였다.
나이브 베이즈 분류를 위한 속성변수는 총저수량에서 수 면증발 등의 저수지내 손실수량을 공제하고 남은 유효저수 량, 농업생산기반시설로부터 혜택을 받는 면적인 수혜면적, 강수로 인해 지표유출을 받는 면적인 유효면적, 지리적인 특 성을 고려한 위도와 경도, 저수지의 가뭄 발생 빈도를 나타내 는 한발빈도(수리안전답) 총 6가지로 설정하였다.
한편, 농업용저수지는 용수 공급만 하는 것이 아니라 가뭄
완화 및 홍수조절, 환경유지유량, 레크리에이션 용도까지 다 양한 목적으로 활용되기 때문에(Park, 2015), 실질적으로 농 업용저수지의 분석을 위해서는 정확한 제원 데이터를 가지고 있는 저수지에서 분석을 실시하여야 한다. 따라서 선행연구 에서 선정한 65개의 클래스데이터 중 설정변수의 항목을 가 지고 있지 않은 4개 저수지(송강, 공정, 백천, 백용)를 제외한 61개 저수지를 클래스데이터로 선정하였다.
전국 저수지 분류를 위해 한국농어촌공사에서 관리하는 저수지 3,067개에 대한 제원 및 저수율 자료를 구축하였으며, 이 중 불완전 데이터를 제외한 1,559개소에 나이브 베이즈 분 류기법을 적용하였다.
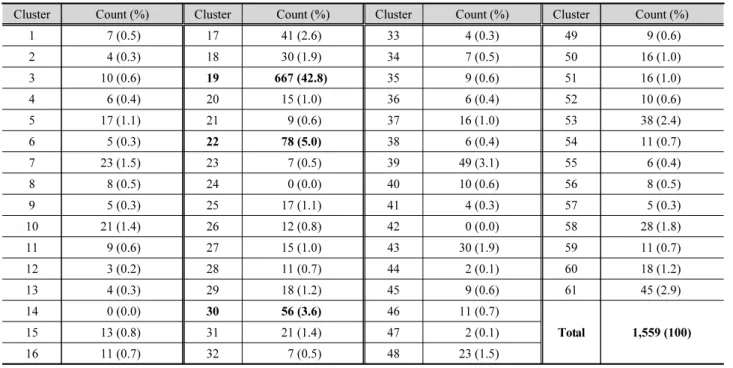
Table 2는 나이브 베이즈 분류 기법을 적용하여 61개의 대 표 저수지 군집으로 분류한 결과를 나타낸 것으로 19번 군집 에 분류된 저수지는 667개(42.8%)로 61개의 군집 중 가장 많 은 저수지가 분류되었고, 22번 군집으로 분류된 저수지는 78 개(5.0%), 30번 군집은 56개(3.6%)로 나타났다. 또한 군집수 가 10개 이하인 군집은 31개로 나타났으며, 14, 24, 42번 군집 은 저수지가 0개로 분류되었다.
우리나라 대부분의 농업용 저수지는 관개 규모가 100 ha 이하의 소규모 저수지임에 따라(Yoo and Park, 2007) 소규모 저수지 군집인 19번 군집의 경우, 19번 군집의 클래스데이터 인 수부저수지는 모든 기준저수지 중에 유효저수량(317 × 103m3), 수혜면적(98 ha) 및 유역면적(218 ha)이 가장 작은 저 수지로 19번 군집으로 분류된 저수지들은 수부저수지의 유
Table 2. Results of Naïve-Bayes classification analysis
Cluster Count (%) Cluster Count (%) Cluster Count (%) Cluster Count (%)
1 7 (0.5) 17 41 (2.6) 33 4 (0.3) 49 9 (0.6)
2 4 (0.3) 18 30 (1.9) 34 7 (0.5) 50 16 (1.0)
3 10 (0.6) 19 667 (42.8) 35 9 (0.6) 51 16 (1.0)
4 6 (0.4) 20 15 (1.0) 36 6 (0.4) 52 10 (0.6)
5 17 (1.1) 21 9 (0.6) 37 16 (1.0) 53 38 (2.4)
6 5 (0.3) 22 78 (5.0) 38 6 (0.4) 54 11 (0.7)
7 23 (1.5) 23 7 (0.5) 39 49 (3.1) 55 6 (0.4)
8 8 (0.5) 24 0 (0.0) 40 10 (0.6) 56 8 (0.5)
9 5 (0.3) 25 17 (1.1) 41 4 (0.3) 57 5 (0.3)
10 21 (1.4) 26 12 (0.8) 42 0 (0.0) 58 28 (1.8)
11 9 (0.6) 27 15 (1.0) 43 30 (1.9) 59 11 (0.7)
12 3 (0.2) 28 11 (0.7) 44 2 (0.1) 60 18 (1.2)
13 4 (0.3) 29 18 (1.2) 45 9 (0.6) 61 45 (2.9)
14 0 (0.0) 30 56 (3.6) 46 11 (0.7)
Total 1,559 (100)
15 13 (0.8) 31 21 (1.4) 47 2 (0.1)
16 11 (0.7) 32 7 (0.5) 48 23 (1.5)
효저수량, 수혜면적, 유역면적보다 작은 형태학적 특성을 가 진 저수지들이 모두 분류되었으며, 유효저수량 500 × 103m3 이하의 저수지가 911개, 전체의 58%로 군집에 분류되는 수 자체도 많아졌다. 반면, 유효저수량이 가장 큰 26번의 클래스 데이터인 금광저수지의 유효저수량은 12,047 × 103m3로 이 이 상의 유효저수량을 가진 저수지들은 26번으로 분류되었다.
Fig. 2는 분류된 저수지들의 지역적 분포를 파악하기 위해 나타낸 것으로, 전남, 경남 지역에 19번 군집에 소속된 저수지 가 많은 것으로 나타났다. 경기, 충남 지역에는 22번 군집에 소속된 저수지가 많이 분포해 있었고(Fig. 2(a)), 30번 군집의 소속 저수지는 충청도 내륙에 많이 분포해 있는 것을 확인할 수 있었다(Fig. 2(a)).
나이브 베이즈 분류를 통한 저수지 군집분석 결과 저수지 분류는 지역별로 뚜렷한 경향을 나타내지 않았다. 따라서 저 수지의 유효저수량, 유역면적 등과 같은 형태학적인 분류를 위해 군집수를 축소하여 재분석을 실시하였다. 이를 위해 61 개의 군집 중 10개 이하의 개체수를 가진 군집(Fig. 2(b))에 대 해 저수지의 제원이 유사한 군집의 클래스데이터로 재분류 하여 군집수를 30개로 축소하였다.
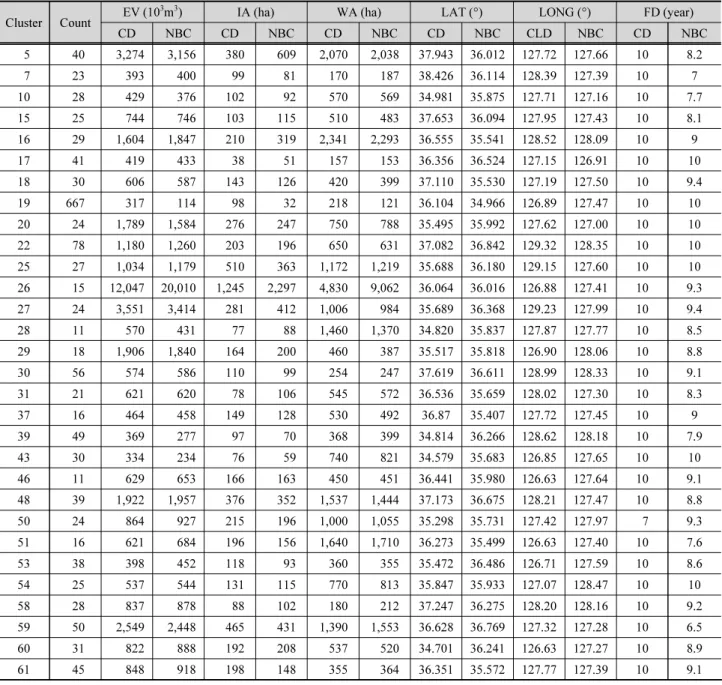
Table 3은 30개의 군집에 대한 클래스데이터의 제원 및 분 류된 저수지의 제원(유효저수량, 수혜면적, 유역면적, 위도, 경도, 한발빈도)을 정리한 것으로, 위도와 경도의 경우 실측값 과 군집평균값에 대한 평균차이가 심하며, 우리나라 최북단~
최남단 저수지의 위도분포가 34.306~38.426 (°), 최동단~최
서단 저수지의 위도분포가 125.983~129.573 (°)임을 미루어 봤을 때 그 편차가 크며 위․경도에 분류에 대한 뚜렷한 특징을 나타내지 않는 것으로 분석되었다. 또한 한발빈도의 경우 저 수지 설계 시 대부분 10년으로 설정함에 따라 군집별 특성을 나타내는 인자로 판단하기 어려운 것으로 분석되었다.
한편, 유효저수량(EV)과 수혜면적(IA), 유역면적(WA)에 는 각 군집별로 구별되는 차이가 존재하며, 비슷한 유효저수 량 값을 갖더라도 수혜면적이나 혹은 유역면적으로 저수지의 분류가 달라질 수 있는 것으로 나타났다. 이는 나이브 베이즈 분류가 모두 독립적으로 작용하고 전체 인스턴스의 평균과 분산을 사용하기 때문에 그 분포에 영향을 많이 받으며, 분포 값에 따라 영향이 큰 몇 개의 인자가 전체 확률 값에 주요한 영향을 끼친 것으로 판단된다.
예를 들어, 31번 군집과 51번 군집의 경우 클래스데이터와 분류된 저수지들의 유효저수량이 600~684 × 103m3로 편차 가 심하지 않았지만 유역면적에서 큰 차이를 보여 다른 군집 으로 분류되었고, 22번 군집 및 25번 군집에서는 유효저수량 이 약 1,034~1,260 × 103m3으로 유효저수량의 차이가 크게 나타나지 않지만 수혜면적과 유역면적의 차이로 인해 군집이 분류 된 것을 확인할 수 있다. 종합해 보면, 군집분석 결과 위도 와 경도 및 한발빈도는 군집 분류에 크게 영향을 미치지 않은 것으로 분석되며, 유효저수량이 500 × 103m3이하의 저수지 의 수혜면적 및 유역면적의 크기에 따라 상세히 군집분류가 된 것으로 나타났다.
(a) 30 clusters in which more than 10 reservoirs are classified (b) The rest of the clusters in which less than 10 reservoirs are classified Fig. 2. Reservoir distribution classified with Naïve-Bayes Classifier (NBC)
3.2 군집별 월 저수율 예측 회귀식 산정결과
본 연구에서는 기상관측자료의 5가지 요소와 농업용저수 지 저수율을 독립변수로 활용하여 다중선형 회귀모형을 구축 하였다. 농업용수와 관련한 데이터들은 인위적 요소가 포함되 므로 일별로 평가하는 것보다 월별로 평가하는 것이 일반적으 로 실측치를 잘 반영하게 된다(Song et al., 2013). 월 단위 기상 관측자료는 기상청 2002~2017년의 전국 63개 지상기상관측 지점에서 얻은 일 기상관측자료를 강수는 누적, 그 외의 기상자 료는 평균하여 월 기상관측자료로 가공하였고, 월 단위 전국 저
수율 관측자료는 RIMS에서 제공받은 2002~2016년의 일 농 업용저수지 저수율 관측자료는 월별로 평균하여 가공하였다.
회귀식의 변수는 GS5에서 제공하고 있는 기상요소 5가지 (강수량, 최고기온, 최저기온, 평균기온, 평균풍속)와 동일한 기상관측자료를 이용하였다. 최고 및 최저기온은 Thorton and Running (1999)에 의해 증발산 산정을 위한 일평균 복사열의 인자로 반영된 바 있으며, Rim (2017)의 연구에서도 증발량 추정 시 기온자료를 활용한 바 있다. 일조시간과 상관관계가 있는 평균기온을 고려한 선행연구(Lee et al., 1995)를 반영하
Table 3. Reservoir specification for each cluster
Cluster Count EV (103m3) IA (ha) WA (ha) LAT (°) LONG (°) FD (year)
CD NBC CD NBC CD NBC CD NBC CLD NBC CD NBC
5 40 3,274 3,156 380 609 2,070 2,038 37.943 36.012 127.72 127.66 10 8.2
7 23 393 400 99 81 170 187 38.426 36.114 128.39 127.39 10 7
10 28 429 376 102 92 570 569 34.981 35.875 127.71 127.16 10 7.7
15 25 744 746 103 115 510 483 37.653 36.094 127.95 127.43 10 8.1
16 29 1,604 1,847 210 319 2,341 2,293 36.555 35.541 128.52 128.09 10 9
17 41 419 433 38 51 157 153 36.356 36.524 127.15 126.91 10 10
18 30 606 587 143 126 420 399 37.110 35.530 127.19 127.50 10 9.4
19 667 317 114 98 32 218 121 36.104 34.966 126.89 127.47 10 10
20 24 1,789 1,584 276 247 750 788 35.495 35.992 127.62 127.00 10 10
22 78 1,180 1,260 203 196 650 631 37.082 36.842 129.32 128.35 10 10
25 27 1,034 1,179 510 363 1,172 1,219 35.688 36.180 129.15 127.60 10 10
26 15 12,047 20,010 1,245 2,297 4,830 9,062 36.064 36.016 126.88 127.41 10 9.3
27 24 3,551 3,414 281 412 1,006 984 35.689 36.368 129.23 127.99 10 9.4
28 11 570 431 77 88 1,460 1,370 34.820 35.837 127.87 127.77 10 8.5
29 18 1,906 1,840 164 200 460 387 35.517 35.818 126.90 128.06 10 8.8
30 56 574 586 110 99 254 247 37.619 36.611 128.99 128.33 10 9.1
31 21 621 620 78 106 545 572 36.536 35.659 128.02 127.30 10 8.3
37 16 464 458 149 128 530 492 36.87 35.407 127.72 127.45 10 9
39 49 369 277 97 70 368 399 34.814 36.266 128.62 128.18 10 7.9
43 30 334 234 76 59 740 821 34.579 35.683 126.85 127.65 10 10
46 11 629 653 166 163 450 451 36.441 35.980 126.63 127.64 10 9.1
48 39 1,922 1,957 376 352 1,537 1,444 37.173 36.675 128.21 127.47 10 8.8
50 24 864 927 215 196 1,000 1,055 35.298 35.731 127.42 127.97 7 9.3
51 16 621 684 196 156 1,640 1,710 36.273 35.499 126.63 127.40 10 7.6
53 38 398 452 118 93 360 355 35.472 36.486 126.71 127.59 10 8.6
54 25 537 544 131 115 770 813 35.847 35.933 127.07 128.47 10 10
58 28 837 878 88 102 180 212 37.247 36.275 128.20 128.16 10 9.2
59 50 2,549 2,448 465 431 1,390 1,553 36.628 36.769 127.32 127.28 10 6.5
60 31 822 888 192 208 537 520 34.701 36.241 126.63 127.27 10 8.9
61 45 848 918 198 148 355 364 36.351 35.572 127.77 127.39 10 9.1
EV: effective storage volume, IA: irrigated area, WA: watershed area, FD: frequency of drought, CD: class data, and NBC: Naïve-Bayes classifier
여 각 인자를 독립변수로 채택하였다. 강수량의 경우 저수율 에 직접적인 영향을 미치게 됨에 따라(Ahn et al., 2007) 3개월 로 구분해 각각의 변수로 구분하였다. 또한 저수율의 연속적인 특성을 반영하기 위해 전월 저수율을 독립변수로 채택하였다.
회귀식의 기본적인 형태는 다음과 같다(Eq. (5)).
∙ ∙
∙ ∙ ∙
∙ ∙ ∙
(5)
여기서, 는 예측시점의 예측저수율(%), 은 해당 월의 강수(mm), 는 해당 월을 기준으로 한 달 전 월 누적강수(mm), 는 두 달 전 월 누적강수(mm),
는 월평균최고기온(°C), 은 월평균 최저기온(°C), . 는 월평균 평균기온(°C), 는 월평균 평균풍속(m/s),
는 예측 시점 전월 저수율(%)이다. 다중선형 회귀분 석을 통해 각 군집별로 연도별 월별 데이터를 산정하고 각 독 립변수별 회귀계수 의 값을 산정하고 회귀 식의 결정계수 R2를 산정하였다.
Fig. 3은 다중선형 회귀분석을 통해 월별 선형회귀계수를 산정하여 군집별 평균을 기준으로 최고, 최저의 분포를 도시 한 것으로, 전체 월별 회귀계수(R2)는 0.58~0.95로 분석되었 다. 1월이 0.95로 상관성이 가장 높고 상관성이 높은 군집과 낮은 군집의 편차도 작은 반면, 8월이 0.58로 상관성이 가장 낮고 편차 또한 가장 큰 것으로 분석되었다.
농업용수의 사용시기인 관개기(4~6월)에서 서서히 낮아 지며 장마와 무더위가 잦은 7~9월의 R2가 평균적으로 낮고 비관개기(10~3월)에는 R2값이 높아지는 경향을 나타내었 다. 이는 농업용수 수요가 가장 큰 이앙기(5~6월)에 군집별 용 수 공급 패턴이 달라 정확도가 낮으면서 생기는 불확실성으로
Fig. 3. R2 of monthly regression analysis
Table 4. The statistical indicator results by cluster (R2, NSE, RMSE)
Cluster Count R2 NSE RMSE (%) Cluster Count R2 NSE RMSE (%)
5 40 0.85 0.84 8.42 30 56 0.83 0.72 7.63
7 23 0.81 0.78 8.37 31 21 0.77 0.75 8.23
10 28 0.79 0.75 8.64 37 16 0.75 0.72 10.19
15 25 0.82 0.80 7.97 39 49 0.71 0.59 9.80
16 29 0.81 0.78 7.84 43 30 0.66 0.58 9.97
17 41 0.80 0.80 0.80 46 11 0.84 0.82 8.16
18 30 0.77 0.77 0.77 48 39 0.81 0.79 8.54
19 667 0.63 0.63 0.63 50 24 0.79 0.77 9.47
20 24 0.84 0.82 7.61 51 16 0.71 0.69 9.55
22 78 0.82 0.78 8.20 53 38 0.77 0.75 9.09
25 27 0.71 0.58 10.69 54 25 0.74 0.67 8.90
26 15 0.87 0.84 6.72 58 28 0.84 0.81 7.43
27 24 0.88 0.86 6.66 59 50 0.85 0.84 8.42
28 11 0.67 0.57 9.34 60 31 0.81 0.80 8.85
29 18 0.84 0.75 6.74 61 45 0.84 0.82 8.01
판단되며, 특히 여름철(7~9월)에는 우리나라에 영향을 끼치 는 몬순기후 특성상 여름철에 커지는 강수 변동성 및 강수 패 턴의 변화, 방류량 인자, 지속적인 관개수요와 저수지의 효율 적인 수자원 확보를 위한 인위적인 인자들이 개입될 여지가 많아 기상관측 인자만으로는 설명력이 부족하기 때문으로 생 각된다(Yi and Choi, 2007; Kim et al., 2017; Ahn et al., 2007;
Kim et al., 2017).
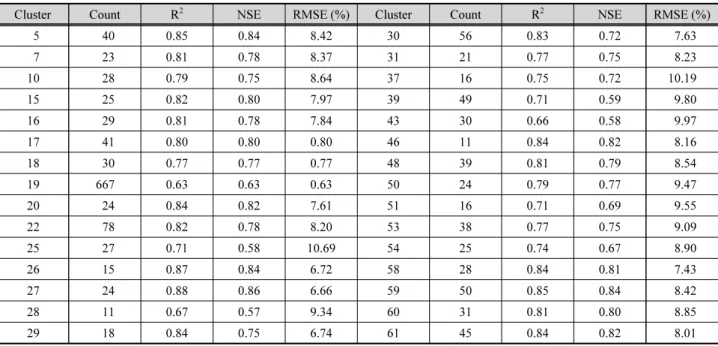
Table 4는 2002~2014년을 대상으로 군집별 회귀식 적용 결과 및 월별 저수율을 정리한 것으로 관측저수율과의 상관성 분석결과 R2는 0.66~0.88로 분석되었으며, NSE와 RMSE는 각각 0.57~0.86, 6.66~10.69 (%)의 범위를 나타내었다. 규모 가 큰 저수지가 포함된 군집인 26번과 27번 군집은 R2가 각각
0.87, 0.88, NSE가 0.84, 0.86으로 모의치가 실측치를 가장 잘 나타내는 것으로 나타났다. 19번 군집의 경우 R2가 가장 낮게 분석 되었는데 그 이유는 분류된 저수지들의 유효저수량이 평균 114 × 103m3으로 소규모 저수지로 이앙기 때 저수율이 급격히 떨어지는 관측치의 감소율을 회귀식이 따라가지 못하 는 것으로 생각된다.
3.3 회귀식과 GS5 데이터를 이용한 저수율 전망자료 생산
3.3.1 저수율 자료 생산
농업용저수지 가뭄지수인 RDI 적용에 앞서 동일한 기간의
Table 5. Estimation result of observation and forecast data (R2, NSE, RMSE)
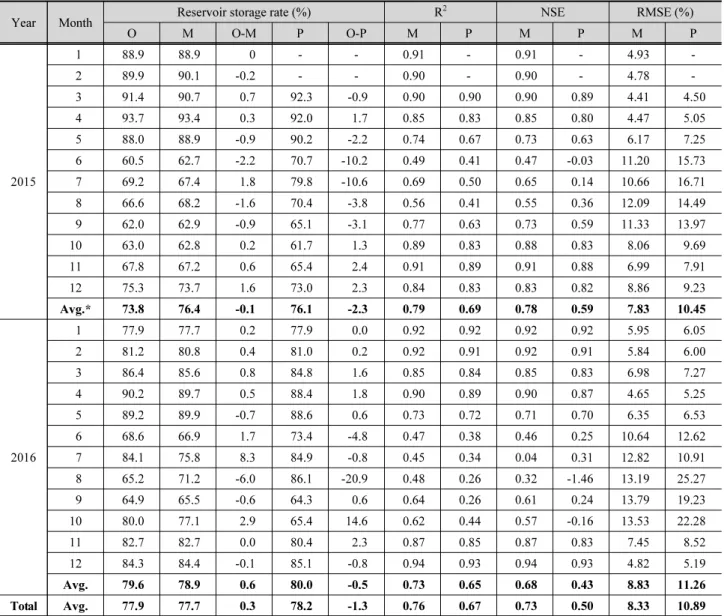
Year Month Reservoir storage rate (%) R2 NSE RMSE (%)
O M O-M P O-P M P M P M P
2015
1 88.9 88.9 0 - - 0.91 - 0.91 - 4.93 -
2 89.9 90.1 -0.2 - - 0.90 - 0.90 - 4.78 -
3 91.4 90.7 0.7 92.3 -0.9 0.90 0.90 0.90 0.89 4.41 4.50
4 93.7 93.4 0.3 92.0 1.7 0.85 0.83 0.85 0.80 4.47 5.05
5 88.0 88.9 -0.9 90.2 -2.2 0.74 0.67 0.73 0.63 6.17 7.25
6 60.5 62.7 -2.2 70.7 -10.2 0.49 0.41 0.47 -0.03 11.20 15.73
7 69.2 67.4 1.8 79.8 -10.6 0.69 0.50 0.65 0.14 10.66 16.71
8 66.6 68.2 -1.6 70.4 -3.8 0.56 0.41 0.55 0.36 12.09 14.49
9 62.0 62.9 -0.9 65.1 -3.1 0.77 0.63 0.73 0.59 11.33 13.97
10 63.0 62.8 0.2 61.7 1.3 0.89 0.83 0.88 0.83 8.06 9.69
11 67.8 67.2 0.6 65.4 2.4 0.91 0.89 0.91 0.88 6.99 7.91
12 75.3 73.7 1.6 73.0 2.3 0.84 0.83 0.83 0.82 8.86 9.23
Avg.* 73.8 76.4 -0.1 76.1 -2.3 0.79 0.69 0.78 0.59 7.83 10.45
2016
1 77.9 77.7 0.2 77.9 0.0 0.92 0.92 0.92 0.92 5.95 6.05
2 81.2 80.8 0.4 81.0 0.2 0.92 0.91 0.92 0.91 5.84 6.00
3 86.4 85.6 0.8 84.8 1.6 0.85 0.84 0.85 0.83 6.98 7.27
4 90.2 89.7 0.5 88.4 1.8 0.90 0.89 0.90 0.87 4.65 5.25
5 89.2 89.9 -0.7 88.6 0.6 0.73 0.72 0.71 0.70 6.35 6.53
6 68.6 66.9 1.7 73.4 -4.8 0.47 0.38 0.46 0.25 10.64 12.62
7 84.1 75.8 8.3 84.9 -0.8 0.45 0.34 0.04 0.31 12.82 10.91
8 65.2 71.2 -6.0 86.1 -20.9 0.48 0.26 0.32 -1.46 13.19 25.27
9 64.9 65.5 -0.6 64.3 0.6 0.64 0.26 0.61 0.24 13.79 19.23
10 80.0 77.1 2.9 65.4 14.6 0.62 0.44 0.57 -0.16 13.53 22.28
11 82.7 82.7 0.0 80.4 2.3 0.87 0.85 0.87 0.83 7.45 8.52
12 84.3 84.4 -0.1 85.1 -0.8 0.94 0.93 0.94 0.93 4.82 5.19
Avg. 79.6 78.9 0.6 80.0 -0.5 0.73 0.65 0.68 0.43 8.83 11.26
Total Avg. 77.9 77.7 0.3 78.2 -1.3 0.76 0.67 0.73 0.50 8.33 10.89
*2015.03 ~ 2015.12 average, O: observed data, M: Multi-regression simulated data, and P: GS5 prediction data
실제 농업용저수지 저수율 관측자료(OBS)와 회귀식에 관측 자료를 적용하여 산정된 회귀저수율(MLR) 및 회귀식에 예 보자료를 적용하여 산정된 전망저수율(PRD)의 비교를 실시 하였다. 분석기간은 2015년 1월부터 2016년 12월까지로 설 정하였는데, GS5 3개월 예보자료의 경우 2015년 1월에 생성 된 자료는 2015년 3월의 예보자료임에 따라, 저수율 예보자 료는 2015.03~2016.12 기간 대해서만 도출이 가능했다.
Table 5는 실제 저수율 관측자료와 예측된 저수율에 대한 상관성 분석을 실시한 결과로, 우선 MLR의 월평균 결과를 살 펴보면, 저수지의 담수시기인 11~2월까지의 예측저수율은 실 측치와 유사하게 산정되었고 그 차이 또한 1% 미만으로 낮다.
하지만 이앙기가 시작되는 5월부터 관개기가 끝나는 9월까지 예측저수율은 실측치보다 과대하게 산정되는 경향을 보였다.
2년 평균 R2는 0.76, NSE는 0.73, RMSE는 8.33%로 회귀식을 이용한 저수율 모의가 실측치의 경향을 잘 반영한 것으로 나타 났지만 12~2월의 R2가 0.84~0.92로 높은 값을 가지는 것에 비 해 6~8월에서의 R2가 0.45~0.69로 매우 낮은 것으로 나타났다.
PRD의 경우 이앙기 시작과 더불어 전망저수율이 실측치 보다 과대하게 산정되었는데, 이는 GS5 강수량 예보자료가 5~8월에 과다하게 산정되는(So et al., 2017) 패턴과 일치하 며, 그 정도가 더 큰 이유는 회귀식의 정확도의 문제보다는
GS5의 예측성능에 기인한 결과로 생각된다. 2년 평균 R2는 0.67, NSE는 0.50, RMSE는 10.89%로 분석되었으며 특히 6~8월의 NSE값이 음수를 띄거나 매우 작은 값을 가져 저수율 패턴예측이 떨어지는 것을 확인할 수 있다.
일반적으로 농업용저수지의 저수량은 겨울철에 만수위 가까이 유지하다가 농업용수 수요가 가장 큰 이앙기를 거치면 서 급감하고 추수기 이후 다시 회복하는 패턴을 나타낸다(Kim et al., 2017). 또한 저수지의 특성 상 해당년도의 낮은 저수율 이 다음 해 까지 이월 되는 현상이 나타나게 되는데, 회귀식 산 정 시 저수율을 고려함에 따라 회귀식의 모의 결과는 농업용 저수지의 운영 패턴을 잘 반영한 것으로 판단된다. 다만, 정확 도가 향상된 저수율 전망 자료 생산을 위해서는 GS5 데이터 의 정확도 향상을 위한 추가 연구가 필요할 것으로 생각된다.
3.3.2 RDI를 이용한 농업 가뭄 전망 정보 생산
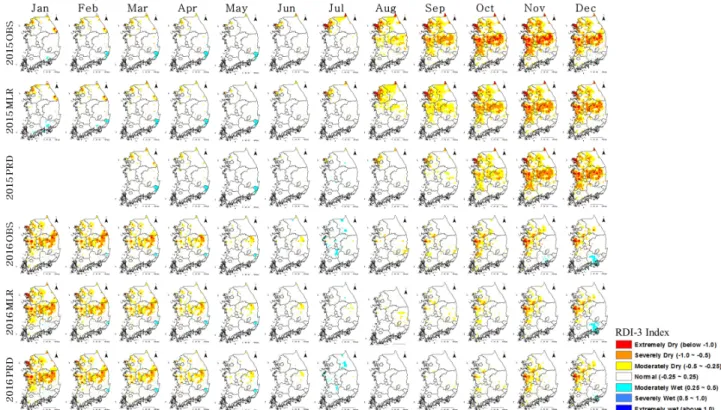
회귀식과 GS5 3개월 예보자료의 가뭄 감지 가능성을 평가 하기 위해 산정된 전국 저수율 결과를 바탕으로 관측자료 기반 의 RDI-3와 회귀식 기반의 RDI-3, 전망자료를 이용한 RDI-3 을 7단계로 세분화하여 월별로 도시화 하였다(Fig. 4). 붉어질 수록 3개월 평균 저수율이 평년저수율보다 적어 극심한 농업 가뭄을 겪는다고 판단한다.
Fig. 4. National RDI-3 distribution of OBS, MLR, PRD OBS: Observed RDI-3, MLR: Multi-regression simulated RDI-3, PRD: GS5 prediction RDI-3
OBS를 살펴보면, 2015년 7월 경기북부부터 전국적으로 확산된 가뭄이 2016년 5월까지 전이되어 장기가뭄을 겪은 것 으로 나타났는데, 이와 동일하게 MLR도 동일한 지역에 가뭄 을 감지하였다. 반면, PRD의 경우 같은 기간에 가뭄을 감지하 기 시작하였으나, 2015년 6~9월까지 가뭄의 심도에서 차이 를 나타내었다. 이는 앞서 언급한 바와 같이 GS5 강수량 예보 자료가 5~8월에 과다하게 산정된 결과를 반영했기 때문으로 생각된다.
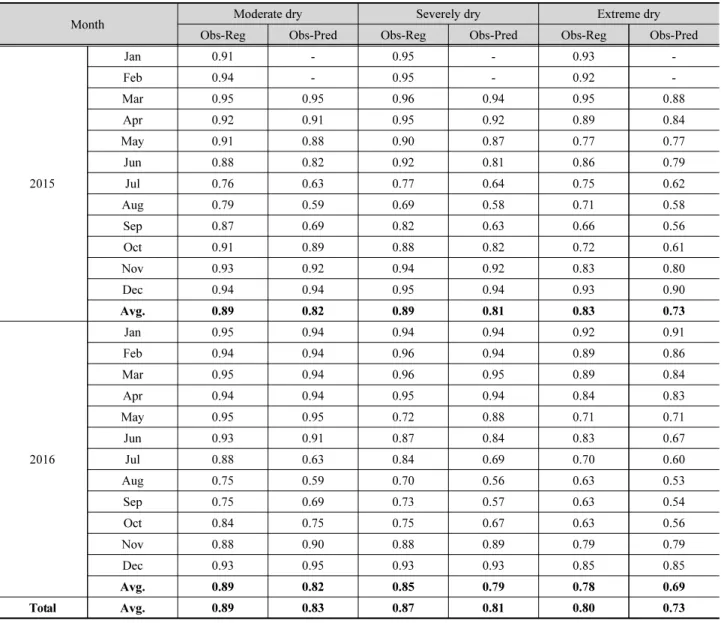
Table 6은 RDI 심도에 따른 MLR과 PRD의 ROC 분석 결 과를 나타낸 것이다. MLR에서는 2015~2016년 보통가뭄 (Moderately dry) 및 심한가뭄(Severely dry)에 대한 평균적 인 적중률이 각각 0.89, 0.87로 분석되었으며, 극심한가뭄
(Extremely dry)은 0.80으로 나타났다. 특히 보통가뭄과 심한 가뭄의 적중률은 6~9월을 제외하고 0.9 이상의 높은 정확도 로 가뭄을 감지하였으며, 분석기간 동안 모든 가뭄 심도에 대 해 ROC는 0.78 이상의 적중률을 보였다.
PRD에 대한 ROC분석 결과 평균적으로 0.73~0.83의 적중 률을 보이며 보통가뭄과 심한가뭄이 각각 0.83, 0.81의 정확 률을 보이는데 반해 극심한가뭄은 0.73으로 MLR의 적중률 보다 낮은 것으로 나타났다. 7월은 분석기간 중 가장 적중률이 낮은 달로 이 시기는 이앙기의 용수공급 패턴뿐만 아니라 1년 중 강수량에 가장 큰 영향을 받으므로 이 시기의 회귀식 정확 도 향상을 위해서는 증발산량 혹은 관개효율 등의 인자를 고 려한 회귀분석을 추가로 수행해야 할 것이다.
Table 6. ROC analysis of RDI-3 drought severity
Month Moderate dry Severely dry Extreme dry
Obs-Reg Obs-Pred Obs-Reg Obs-Pred Obs-Reg Obs-Pred
2015
Jan 0.91 - 0.95 - 0.93 -
Feb 0.94 - 0.95 - 0.92 -
Mar 0.95 0.95 0.96 0.94 0.95 0.88
Apr 0.92 0.91 0.95 0.92 0.89 0.84
May 0.91 0.88 0.90 0.87 0.77 0.77
Jun 0.88 0.82 0.92 0.81 0.86 0.79
Jul 0.76 0.63 0.77 0.64 0.75 0.62
Aug 0.79 0.59 0.69 0.58 0.71 0.58
Sep 0.87 0.69 0.82 0.63 0.66 0.56
Oct 0.91 0.89 0.88 0.82 0.72 0.61
Nov 0.93 0.92 0.94 0.92 0.83 0.80
Dec 0.94 0.94 0.95 0.94 0.93 0.90
Avg. 0.89 0.82 0.89 0.81 0.83 0.73
2016
Jan 0.95 0.94 0.94 0.94 0.92 0.91
Feb 0.94 0.94 0.96 0.94 0.89 0.86
Mar 0.95 0.94 0.96 0.95 0.89 0.84
Apr 0.94 0.94 0.95 0.94 0.84 0.83
May 0.95 0.95 0.72 0.88 0.71 0.71
Jun 0.93 0.91 0.87 0.84 0.83 0.67
Jul 0.88 0.63 0.84 0.69 0.70 0.60
Aug 0.75 0.59 0.70 0.56 0.63 0.53
Sep 0.75 0.69 0.73 0.57 0.63 0.54
Oct 0.84 0.75 0.75 0.67 0.63 0.56
Nov 0.88 0.90 0.88 0.89 0.79 0.79
Dec 0.93 0.95 0.93 0.93 0.85 0.85
Avg. 0.89 0.82 0.85 0.79 0.78 0.69
Total Avg. 0.89 0.83 0.87 0.81 0.80 0.73