Extracting of Features in Code Changes of Existing System for Reengineering to Product Line
*
전체 글
*
수치

관련 문서
When a process or deviation alarm occurs, the controller switches to the single loop display for the loop with the alarm and displays the alarm code on the screen.. Software
실용 연구자: 실생활에 적용가능한 소프트웨어 개발.B. 소프트웨어 수요는
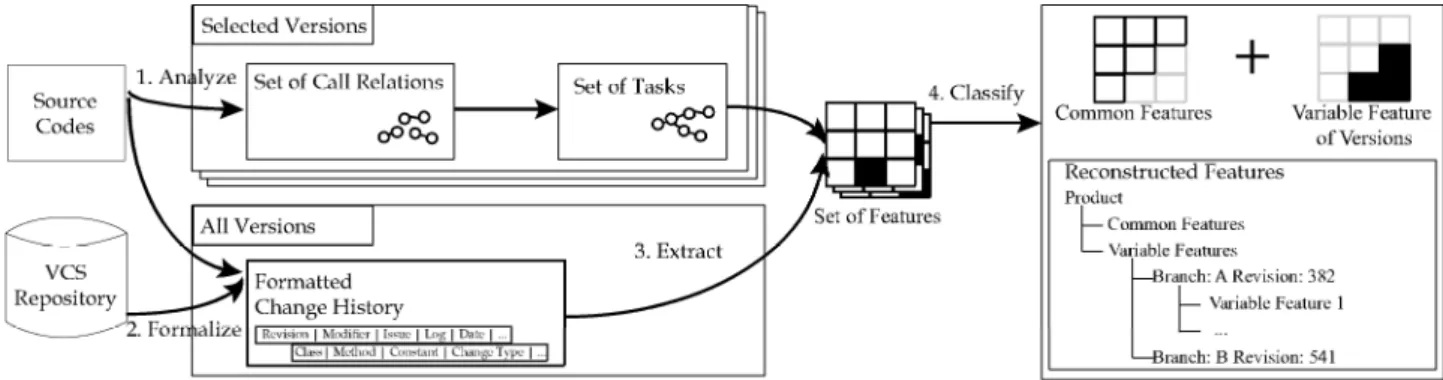
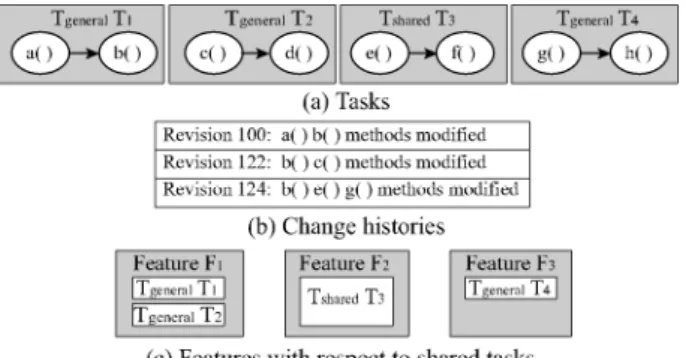
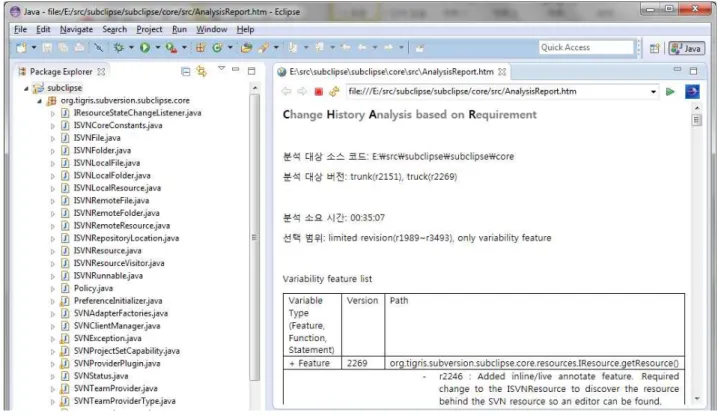
• 제품을 개발하거나 유지보수하는 과정에서 변경(change) 을 통제하는 절차는 소프트웨어 개발 과정의 산출물들을 관 리하고 고품질의 소프트웨어를 얻기
The Joint Resarch Centre's European Chemicals Bureau has developed a hazard estimation software called Toxtree, capable of making structure-based predictions for a
• A software layer to make NAND flash emulate traditional block devices (or disks). File System
The data collected in the research were processed using the SPSS WIN software program, whether significant difference of Internet addiction exists or
In the future, we need further studies on prevention of illegal copy and settlement of legal software products by analysing use characteristics of softwares and
The thickness of the maxillary sinus lateral wall according to tooth site and measurement level was measured by using image-processing software and its histologic
