2019, 30
(2)
,285–297
유전자 알고리즘을 활용한 군집화 기반 펀드투자 전략
ᄀ
ᅡᆼ성석
1
·이현준2
·오경주3
1연세대학교 투자정보공학 ·23연세대학교 산업공학과
ᄌ ᅥ
ᆸᄉ ᅮ 2019ᄂ ᅧ ᆫ 2ᄋ ᅯ ᆯ 6ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 2ᄋ ᅯ ᆯ 25ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2019ᄂ ᅧ ᆫ 2ᄋ ᅯ ᆯ 27ᄋ ᅵ ᆯ
요 약
ᄌ
ᅥ ᆫ ᄉ ᅦᄀ ᅨ ᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄉ ᅵᄌ ᅡ ᆼᄋ ᅦᄉ ᅥ ᄑ ᅥ ᆫᄃ ᅳᄀ ᅡ ᄎ ᅡᄌ ᅵᄒ ᅡᄂ ᅳ ᆫ ᄋ ᅧ ᆼᄒ ᅣ ᆼᄅ ᅧ ᆨᄋ ᅳ ᆫ 2008ᄂ ᅧ ᆫ ᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄋ ᅱᄀ ᅵᄋ ᅪ ᄌ ᅥ ᄀ ᅳ ᆷ ᄅ ᅵ ᄀ ᅵᄌ ᅩᄅ ᅳ ᆯ ᄀ ᅨᄀ ᅵᄅ ᅩ ᄁ ᅮᄌ ᅮ ᆫ ᄒ
ᅵ ᄌ ᅳ ᆼ ᄀ ᅡᄒ ᅡᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ. ᄀ ᅮ ᆨ ᄂ ᅢ ᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄉ ᅵᄌ ᅡ ᆼᄋ ᅦᄉ ᅥᄃ ᅩ ᄑ ᅥ ᆫᄃ ᅳ ᄉ ᅥ ᆯᄌ ᅥ ᆼᄋ ᅢ ᆨᄀ ᅪ ᄉ ᅮ ᆫ ᄌ ᅡᄉ ᅡ ᆫᄋ ᅳ ᆫ ᄌ ᅵᄉ ᅩ ᆨ ᄒ ᅢᄉ ᅥ ᄌ ᅳ ᆼ ᄀ ᅡ ᄎ ᅮᄉ ᅦᄋ ᅦ ᄋ ᅵ ᆻᄋ ᅳᄆ ᅧ, ᄋ ᅮ ᆫᄋ ᅭ ᆼ ᄌ
ᅥ ᆫᄅ ᅣ ᆨ, ᄉ ᅥ ᆼᄀ ᅧ ᆨ, ᄀ ᅳᄅ ᅵᄀ ᅩ ᄌ ᅮᄋ ᅭ ᄐ ᅮᄌ ᅡᄌ ᅡᄉ ᅡ ᆫ ᄃ ᅳ ᆼ ᄋ ᅦ ᄄ ᅡᄅ ᅡ ᄃ ᅡᄋ ᅣ ᆼᄒ ᅡ ᆫ ᄉ ᅳᄐ ᅡᄋ ᅵ ᆯᄋ ᅴ ᄑ ᅥ ᆫᄃ ᅳᄃ ᅳ ᆯ ᄋ ᅵ ᄀ ᅢᄇ ᅡ ᆯ/ᄎ ᅮ ᆯ ᄉ ᅵᄃ ᅬᄀ ᅩ ᄋ ᅵ ᆻᄃ ᅡ. ᄋ ᅵᄅ ᅥᄒ ᅡ ᆫ ᄉ
ᅵᄌ ᅡ ᆼᄋ ᅴ ᄒ ᅳᄅ ᅳ ᆷ ᄋ ᅦᄃ ᅩ ᄇ ᅮ ᆯ ᄀ ᅮᄒ ᅡᄀ ᅩ, ᄑ ᅥ ᆫᄃ ᅳ ᄐ ᅮᄌ ᅡᄋ ᅪ ᄀ ᅪ ᆫᄅ ᅧ ᆫᄃ ᅬ ᆫ ᄋ ᅴᄉ ᅡᄀ ᅧ ᆯᄌ ᅥ ᆼᄋ ᅳ ᆯ ᄌ ᅵᄋ ᅯ ᆫ ᄒ ᅡᄂ ᅳ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄌ ᅦᄉ ᅵᄒ ᅡ ᆫ ᄋ ᅧ ᆫᄀ ᅮᄂ ᅳ ᆫ ᄆ ᅢᄋ ᅮ ᄇ ᅮᄌ ᅩ ᆨ ᄒ ᅡ
ᆫ ᄉ ᅵ ᆯᄌ ᅥ ᆼᄋ ᅵᄃ ᅡ. ᄀ ᅵᄌ ᅩ ᆫ ᄋ ᅦ ᄌ ᅩ ᆫ ᄌ ᅢᄒ ᅡᄂ ᅳ ᆫ ᄉ ᅥ ᆫᄒ ᅢ ᆼᄋ ᅧ ᆫᄀ ᅮᄃ ᅳ ᆯᄋ ᅳ ᆫ ᄃ ᅢᄇ ᅮᄇ ᅮ ᆫ ᄌ ᅮᄉ ᅵ ᆨ ᄐ ᅮᄌ ᅡᄋ ᅪ ᄀ ᅪ ᆫᄅ ᅧ ᆫᄃ ᅬᄋ ᅥᄋ ᅵ ᆻᄋ ᅳᄆ ᅧ, ᄋ ᅵᄅ ᅥᄒ ᅡ ᆫ ᄋ ᅲᄀ ᅡᄌ ᅳ ᆼᄀ ᅯ ᆫ ᄉ ᅵ ᄌ
ᅡ ᆼᄋ ᅦᄉ ᅥ ᄀ ᅥᄅ ᅢᄃ ᅬᄂ ᅳ ᆫ ᄉ ᅡ ᆼᄑ ᅮ ᆷᄃ ᅳ ᆯᄋ ᅳ ᆫ ᄋ ᅵ ᆯᄇ ᅡ ᆫᄌ ᅥ ᆨᄋ ᅵ ᆫ ᄑ ᅥ ᆫᄃ ᅳᄃ ᅳ ᆯ ᄀ ᅪ ᄆ ᅢᄋ ᅮ ᄏ ᅳ ᆫ ᄎ ᅡᄋ ᅵᄀ ᅡ ᄋ ᅵ ᆻᄋ ᅳᄆ ᅳᄅ ᅩ ᄒ ᅢᄃ ᅡ ᆼ ᄋ ᅧ ᆫᄀ ᅮᄀ ᅧ ᆯᄀ ᅪᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄑ ᅥ ᆫᄃ ᅳ ᄉ ᅵᄌ ᅡ ᆼ ᄋ
ᅦ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄀ ᅵᄋ ᅦᄂ ᅳ ᆫ ᄋ ᅥᄅ ᅧᄋ ᅮ ᆷ ᄋ ᅵ ᄋ ᅵ ᆻᄃ ᅡ. ᄋ ᅵᄋ ᅦ ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ ᄀ ᅮ ᆨ ᄂ ᅢ ᄑ ᅥ ᆫᄃ ᅳ ᄃ ᅦᄋ ᅵᄐ ᅥᄅ ᅳ ᆯ ᄀ ᅵᄇ ᅡ ᆫᄋ ᅳᄅ ᅩ ᄀ ᅢᄇ ᅡ ᆯ ᄃ ᅬ ᆫ ᄉ ᅢᄅ ᅩᄋ ᅮ ᆫ ᄐ ᅮᄌ ᅡ ᄋ ᅴ ᄉ
ᅡᄀ ᅧ ᆯᄌ ᅥ ᆼ ᄌ ᅵᄋ ᅯ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄌ ᅦᄉ ᅵᄒ ᅡ ᆫᄃ ᅡ. ᄌ ᅦᄉ ᅵ ᄃ ᅬ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆫ ᄂ ᅩ ᇁᄋ ᅳ ᆫ ᄉ ᅥ ᆼᄀ ᅪᄀ ᅡ ᄀ ᅵᄃ ᅢᄃ ᅬᄂ ᅳ ᆫ ᄑ ᅥ ᆫᄃ ᅳᄅ ᅳ ᆯ ᄉ ᅥ ᆫᄇ ᅧ ᆯᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅪᄌ ᅥ ᆼᄀ ᅪ ᄉ ᅥ ᆫᄇ ᅧ ᆯᄃ ᅬ ᆫ ᄑ
ᅥ ᆫᄃ ᅳᄃ ᅳ ᆯ ᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄐ ᅮᄌ ᅡ ᄇ ᅵᄌ ᅮ ᆼᄋ ᅳ ᆯ ᄎ ᅬᄌ ᅥ ᆨᄒ ᅪᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅪᄌ ᅥ ᆼᄋ ᅳᄅ ᅩ ᄋ ᅵᄅ ᅮᄋ ᅥᄌ ᅧ ᄋ ᅵ ᆻᄋ ᅳᄆ ᅧ, ᄎ ᅬ ᄀ ᅳ ᆫ ᄀ ᅳ ᆷᄋ ᅲ ᆼ ᄃ ᅦᄋ ᅵᄐ ᅥ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅦᄉ ᅥ ᄒ ᅭᄀ ᅪᄌ ᅥ ᆨ ᄋ
ᅳᄅ ᅩ ᄒ ᅪ ᆯᄋ ᅭ ᆼ ᄃ ᅬᄀ ᅩ ᄋ ᅵ ᆻᄂ ᅳ ᆫ ᄋ ᅵ ᆫᄀ ᅩ ᆼ ᄌ ᅵᄂ ᅳ ᆼ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄅ ᅩ ᆫᄋ ᅳ ᆯ ᄒ ᅪ ᆯᄋ ᅭ ᆼ ᄒ ᅡ ᆫᄃ ᅡ. 2013ᄂ ᅧ ᆫ 7ᄋ ᅯ ᆯᄇ ᅮᄐ ᅥ 2018ᄂ ᅧ ᆫ 6ᄋ ᅯ ᆯᄁ ᅡᄌ ᅵᄋ ᅴ ᄃ ᅦᄋ ᅵᄐ ᅥᄅ ᅳ ᆯ ᄀ ᅵᄇ ᅡ ᆫ ᄋ
ᅳᄅ ᅩ ᄉ ᅵ ᆯᄌ ᅳ ᆼ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳ ᆯ ᄌ ᅵ ᆫᄒ ᅢ ᆼᄒ ᅡ ᆫ ᄀ ᅧ ᆯᄀ ᅪ, ᄌ ᅦᄉ ᅵ ᄃ ᅬ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆫ ᄆ ᅮᄋ ᅱᄒ ᅥ ᆷ ᄋ ᅵᄌ ᅡᄋ ᅲ ᆯ ᄇ ᅩᄃ ᅡ ᄆ ᅢᄋ ᅮ ᄂ ᅩ ᇁᄋ ᅳ ᆫ ᄉ ᅮᄋ ᅵ ᆨᄅ ᅲ ᆯᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅧ ᆻᄋ ᅳᄆ ᅧ, ᄀ ᅩᄌ ᅥ ᆫ ᄌ
ᅥ ᆨᄋ ᅵ ᆫ ᄀ ᅲ ᆫᄃ ᅳ ᆼ ᄐ ᅮᄌ ᅡ ᄋ ᅲᄒ ᅧ ᆼᄋ ᅴ ᄇ ᅦ ᆫᄎ ᅵᄆ ᅡᄏ ᅳᄇ ᅩᄃ ᅡ ᄋ ᅮᄉ ᅮᄒ ᅡ ᆫ ᄉ ᅥ ᆼᄀ ᅪᄅ ᅳ ᆯ ᄀ ᅵᄅ ᅩ ᆨ ᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄀ ᅮ ᆫᄌ ᅵ ᆸᄒ ᅪ, ᄋ ᅲᄌ ᅥ ᆫᄌ ᅡ ᄋ ᅡ ᆯᄀ ᅩᄅ ᅵᄌ ᅳ ᆷ, ᄌ ᅡᄀ ᅵ ᄌ ᅩᄌ ᅵ ᆨᄒ ᅪ ᄌ ᅵᄃ ᅩ, ᄐ ᅮᄌ ᅡ ᄎ ᅬᄌ ᅥ ᆨᄒ ᅪ ᄆ ᅩᄒ ᅧ ᆼ, k-ᄑ ᅧ ᆼᄀ ᅲ ᆫ ᄀ ᅮ ᆫᄌ ᅵ ᆸᄇ ᅮ ᆫᄉ ᅥ ᆨ.
1. 서론 ᄑ
ᅥᆫ드는투자자들로부터 모인 자금을여러 자산에 투자 및 운용하고, 그에 따라 수익을창출해내 이를 ᄐ
ᅮ자자들에게 취득시키는상품을의미한다. 2008년금융위기와 저금리 기조를계기로 전 세계금융시장 ᄋ
ᅦ서 이러한 펀드들의 영향력과 규모가 증가하고 있다. 우리나라 펀드 시장의 규모도 점차 증가하고 있 ᄋ
ᅳ며, 금융투자협회의 자료에 따르면 2018년 8월 기준 국내 펀드 설정액과 순자산이 각각 약 554조 원 ᄀ
ᅪ 561조 원을기록하였다. 이러한 펀드 시장은주요 투자자산에 따라서 채권형, 주식형, 그리고 MMF (money market funds) 가 주를 이루고 있으며, 그 외에 혼합자산 펀드, 파생상품 펀드, 부동산 펀드, ᄐ
ᅳᆨ별자산 펀드 등이 포함되어있다. 또한, 투자자 모집 성격에 따라 공모 및 사모펀드로 분류될수 있으 ᄆ
ᅧ, 운용전략 및 특성에 따라서 재간접 펀드, 종류형 펀드, 모자형 펀드 등으로 구분될수 있다 (Kang, 2004). 이 외에도 거래소에 상장된개방형 펀드를 ETF (equity traded funds)로 분류한다.
ᄑ
ᅥᆫ드는투자자들로부터 위임된자금들을다양한 자산에 투자하는것을기본으로 하고 있으며, 이는투 ᄌ
ᅡ자들이 소액의 자본으로도 효과적인 분산투자 효과를얻을수 있도록한다. 또한, 위임된자산을 운용 ᄒ
ᅡ는전문 인력의 서비스를적은 운용보수와 소규모 자본으로 이용할 수 있다는점도 펀드가 좋은투자
1
(03722) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥᄃ ᅢᄆ ᅮ ᆫ ᄀ ᅮ ᄋ ᅧ ᆫᄉ ᅦᄅ ᅩ 50, ᄋ ᅧ ᆫᄉ ᅦᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅮᄌ ᅡᄌ ᅥ ᆼᄇ ᅩᄀ ᅩ ᆼ ᄒ ᅡ ᆨᄀ ᅪ, ᄇ ᅡ ᆨᄉ ᅡᄀ ᅪᄌ ᅥ ᆼ.
2
(03722) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥᄃ ᅢᄆ ᅮ ᆫ ᄀ ᅮ ᄋ ᅧ ᆫᄉ ᅦᄅ ᅩ 50, ᄋ ᅧ ᆫᄉ ᅦᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄉ ᅡ ᆫᄋ ᅥ ᆸᄀ ᅩ ᆼ ᄒ ᅡ ᆨᄀ ᅪ, ᄇ ᅡ ᆨᄉ ᅡᄀ ᅪᄌ ᅥ ᆼ.
3
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (03722) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥᄃ ᅢᄆ ᅮ ᆫ ᄀ ᅮ ᄉ ᅵ ᆫᄎ ᅩ ᆫᄃ ᅩ ᆼ 134ᄇ ᅥ ᆫᄌ ᅵ, ᄋ ᅧ ᆫᄉ ᅦᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄉ ᅡ ᆫᄋ ᅥ ᆸᄀ ᅩ ᆼ ᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
ᄉ
ᅡᆼ품으로 꾸준히관심받고 있는이유 중하나이다. 최근에는 통신 및 IT 기술의 발달로 인해 접근성 또 ᄒ
ᅡᆫ 제고되었으며, 누구나 손쉽게 온라인으로 펀드에 가입할 수 있다. 앞서 언급한 ETF와 같이 거래소 ᄋ
ᅦ 상장되어있는펀드들은기존의 보통펀드들이 가지고 있는유동성 및 투명성 문제까지 해결한 형태이 ᄃ
ᅡ. 이러한 펀드의 다양한 장점들과긍정적인 방향으로의 발전에 따라 펀드 시장은미래에도 규모가 더 ᄋ
ᅮ
ᆨ커질 것으로 예상되며, 투자자로서 반드시 고려해야 할 투자상품 중하나로 이미 자리 잡고 있다.
ᄑ
ᅥᆫ드에 대한관심이 증가하고 시장의 규모가 커짐에 따라, 투자자들이 선택할 수 있는펀드의 종류도 ᄃ
ᅥ욱 다양화되고 있다. 금융투자협회에 등록된 국내 공모펀드 개수는 2017년에 이미 3600개를상회하 ᄋ
ᅧᆻ으나, 투자자들은여전히 펀드상품 선택과관련된의사결정에 어려움을 겪고 있다. 개인 투자자들의 ᄃ
ᅢ부분은과거 성과, 테마, 그리고 주요 편입 종목을기준으로 하는단순한 의사결정과정을 통하여 펀드 ᄅ
ᅳᆯ선별한다는한계점을가지고 있다. 대규모 자금을 운용하는기관투자자들역시 기본적인 재무정보와 ᄀ
ᅥ시적 경제지표에 따라서 투자할 펀드를선택한다. 이러한 비체계적 투자활동은 기존 펀드들이 가지 ᄀ
ᅩ 있는고유한 장점인 리스크관리의 효율성을감소시키며, 전문가 서비스를영위한다는차원에서도 최 ᄌ
ᅥᆨ화되었다고 볼수 없다.
ᄐ
ᅮ자 의사 결정과관련하여, 앞서 언급한 개별 펀드 투자 최적화와관련된 연구는매우 부족한 실정이 ᄃ
ᅡ. 최근금융 분야에서 그 효율성이 입증되고 있는 인공지능방법론을활용한 전문가 시스템 연구 사례 느
ᆫ거의 없으며, 기존의 포트폴리오 최적화관련 연구들은대부분채권, 주식, 외환 등의 대표지수 자산 ᄇ
ᅢ분최적화 및 주식 포트폴리오 최적화에 국한되어 있다. 이에 본 논문에서는이러한 기존연구들의 한 ᄀ
ᅨ점과 주제의 편협성을 인식하고, 최근주목받고 있는 인공지능방법론들에 기반한 개별 펀드 분류 및 ᄉ
ᅥᆫ별, 그리고 투자 최적화 모형과관련된 연구를 진행하고자 한다.
ᄋ
ᅵᆫ공지능이란 넓게는 기계가 인간의 지적인 판단능력을학습하고 모방하도록 연구하는학문 및 기술 ᄋ
ᅵ라고 정의할 수 있다 (Kim, 1994). 인공지능을 표방한 지능적 시스템들은 입력된 데이터를 통해서 ᄉ
ᅡᆼ황을 판단하고 최적의 해를제공하는 행동적 특성을가지며, 이러한 시스템을구축하기 위한 다양한 ᄋ
ᅵᆫ공지능방법론들이 존재한다. 대표적인 인공지능방법론은 인공신경망 (artificial neural network)과 ᄋ
ᅲ전자 알고리즘 (genetic algorithm; GA) 등이 있으며 (Seo 등, 2018), 이러한 방법론들은모두 주어 ᄌ
ᅵᆫ 데이터를 통해서 최적의 해를도출하는과정을포함한다. 최근의 인공지능 분야는컴퓨팅 기술과 데 ᄋ
ᅵ터 저장 및 처리기술의 향상으로 인해 심층학습 (deep learning)의 형태로 발전되고 있으며, 빅데이터 ᄋ
ᅴ활용도 증가와 매우 유관하다 (Jung, 2015; Reu, 2016). 본 연구에서 사용되는 군집화 알고리즘인 ᄌ
ᅡ기 조직화 지도 (self organizing map; SOM) 역시 인공신경망의 파생된 형태이다 (Kohonen, 1990).
보
ᆫ 논문은다음과 같이 구성되어 있다. 2절에서는펀드 시장의 기본적인 정보와 금융 분야에서 다양 ᄒ
ᅡᆫ 방법론을활용한 선행연구들을살펴보고, 본연구에 사용되는유전자 알고리즘,자기조직화모형, 그 ᄅ
ᅵ고 K-평균 군집분석 (K-means clustering)에 관한 내용을언급한다. 3절에서는 본연구에서 제시하 ᄂ
ᅳᆫ투자 의사결정모형을단계적으로 설명하였으며, 4절에서는제안된모형들의 실증 분석 결과를비교 · 부
ᆫ석하였다. 마지막으로 결론에서는 본연구의 결론 및 향후 연구에 대하여 제언하였다.
2. 연구배경
2.1. 선행연구 ᄃ
ᅥ욱 새롭고 효율적인 투자자산 및 도구들이 계속해서 개발돼오면서, 최적화된 투자방법과 관련된 ᄃ
ᅡ양한 선행연구들이 수반되어왔다. 연구자들은 높은 기대수익률과 낮은 리스크를 동시에 추종하는 ᄐ
ᅮ자모형을 만들기 위해 노력하였으며, 포트폴리오의 이러한 두 주요 인자 사이의 관계를 설명하고 ᄇ
ᅮᆫ산투자의 효율성을 입증한 마코위츠(Harry M. Markowitz)의 포트폴리오 선정 이론이 대표적이다 (Markowitz, 1952). 마코위츠의 이론을바탕으로 투자자는요구하는기대수익률을만족하면서 리스크
르
ᆯ최소화하는포트폴리오를구성할 수 있으며, 이를한국, 미국, 그리고 홍콩주식시장을 중심으로 적 ᄋ
ᅭ
ᆼ한 실증연구가 국내에서 진행되었다 (Kim과 Kim, 2009; Choi 등, 2013). Kim과 Kim (2009)은한 ᄀ
ᅮ
ᆨ주식시장과관련된 실증연구를 통해서 주관적 의사결정 방식보다 객관적인 데이터에 기반한 주기적 ᄐ
ᅮ자 의사결정이 더욱 효과적일 수 있음을 입증하였으며 (Kim과 Kim, 2009), Choi 등 (2013)은미국 ᄀ
ᅪ 홍콩주식시장에서도 동일한 결과를확인하였다 (Choi 등, 2013). 이 외에도 마코위츠 포트폴리오에 ᄑ
ᅩ함될우수한 자산들을선정하기 위해 DEA (data envelopment analysis) 기법을활용한 연구 (Son과 Shin, 2012), 마코위츠 포트폴리오를 실제 투자에 활용하기 위한 새로운 프레임워크를 입력변수 예측 저
ᆼ확도 제고를 통해서 제시한 연구 (Kim 등, 2013) 등다양한관련 연구들이 진행되었으며, Duchin과 Levy (2009)는이러한 마코위츠 포트폴리오가 실제로 단순 균등 분산투자보다 열등할 수 있다는결론을 ᄌ
ᅦ시하기도 했다 (Dunchin과 Levy, 2009).
ᄋ
ᅵ러한 고전 포트폴리오 이론과관련된 연구뿐만 아니라, 새롭게 개발되는다양한 분석 방법론과 최적 ᄒ
ᅪ 이론을활용한 연구들이 진행되고 있다. Shim 등 (2012)은주성분 분석과 로지스틱 회귀분석 (logis- tic regression)을활용하여 효율적인 다국 통화 포트폴리오 구성 전략을제시하였으며 (Shim 등, 2012), Cheong과 Oh (2014), 그리고 Cheong 등 (2017)은 군집분석과 GA를활용하여 국내 주식시장을대상 ᄋ
ᅳ로 한 효율적인 포트폴리오 투자전략을제시하였다 (Cheong과 Oh, 2014; Cheong 등, 2017). 2015년 Kim과 Kim은위험자산의확률 분포를 일반화 파레토 분포로 모형화하였으며, GA를활용하여 최적화 되
ᆫ포트폴리오를 국내 시장에서 실증분석하였다 (Kim과 Kim, 2015). Choi 등 (2017)은재무비율의 다 ᄋ
ᅣᆼ한 조합을활용하여 포트폴리오의 종목군을 선정하는 회계 정보 기반 투자모형을 제시하였다 (Choi ᄃ
ᅳᆼ, 2017). 국외에서는 특히 GA를활용한관련 연구가 다수 진행되었는데, 포트폴리오 효율성을제고 ᄒ
ᅡ기 위해 GA를활용한 Yang의 연구와 거래비용최소화를위해 GA를활용한 Lin과 Liu의 연구가 각 ᄀ
ᅡ
ᆨ 2006년과 2008년에 진행되었다 (Yang, 2006; Lin과 Liu, 2008). Parque 등은 Genetic Relation Algorithm을활용하여 단기 투자 포트폴리오 최적화를 위한 프레임워크를 제시하였으며 (Parque 등, 2009),그와 동일한 알고리즘에 새로운연산자를 도입하여 대규모 포트폴리오 최적화 문제를해결하고 ᄌ
ᅡ 하는연구가 Chen 등에 의해 진행되었다 (Chen 등, 2010).
구
ᆫ집화를 활용한 포트폴리오 구성 및관리와관련하여, 과거 수익률의 시계열 데이터를 분석하여 뮤 ᄎ
ᅮ얼 펀드의 스타일을 분석하기 위한 연구가 Pattarin 등에 의해 진행되었고 (Pattarin 등, 2004),이후 Moreno 등은 SOM의활용이 스페인 뮤추얼 펀드의 분류 및 분석 방법을개선할 수 있음을확인하였다 (Moreno, 2006). Khan 등은 SOM, GA,그리고 역전파 인공신경망 (neural network)을활용한 주식 ᄉ
ᅥᆫ별 방안을제시하였으며, 벤치마크 (BSE-30 index)보다 월등한 성과를확인하였다 (Khan 등, 2008).
Lemieux 등은 2014년에 군집화 기법들이 포트폴리오 구성과 리스크관리에 미치는영향에관한 연구를 ᄌ
ᅵᆫ행하였다 (Lemieux 등, 2014).
ᄋ
ᅵ러한 국내외에서 진행되어온다양한 선행연구들은관련 주제에 대한 학계와 업계의 꾸준한관심을 ᄇ
ᅩ여준다. 특히 최근금융 분야에서의활용도가 입증되면서 다양한 응용연구가활발하게 이루어지고 있 느
ᆫ 인공지능방법론과관련된 연구는그 수요가 더욱 증가하고 있다. 그러나 지난 연구들을살펴볼때, ᄆ
ᅡ
ᆭ은 실증연구가 주식시장에서 이루어지고 있음을알 수 있다. 이에 본연구에서는기존선행연구에서 ᄐ
ᅮ자자산으로 거의활용되지 않은 국내 펀드들을활용한 최적 투자모형을제시하고자 한다.
2.2. 자기 조직화 지도
SOM은 Kohonen에 의해 제안된신경망 기반 모형으로, 데이터의 군집화를위한 대표적인 비지도 학 ᄉ
ᅳ
ᆸ알고리즘 중 하나이다 (Kohonen, 1990). SOM의 신경망 구조는 입력층과 경쟁층으로 구성되어 있 ᄋ
ᅳ며, 경쟁층은정해진 개수의 노드로 이루어져 있다 (Shim 등, 2018; Kim, 2006; Min과 Lee, 2001).
이
ᆸ력층은 벡터화된데이터를 입력받으며, 경쟁층의 각 노드들과 입력된벡터 사이의 거리를계산하여 가 ᄌ
ᅡᆼ 가까운노드가 선택되게된다. 이렇게 선택된노드를 승자노드 (winner node)라고 부르며, 승자노드 ᄋ
ᅪ 그 이웃반경 내 노드들의 가중치가 재조정되는학습과정을수행하고, 이러한 과정은 벡터가 입력될 ᄄ
ᅢ마다 반복된다. 이웃반경은 경쟁층노드의 배열 형식에 따라 달라지며, 주로 사각형 또는 육각형 배 여
ᆯ이 많이 사용된다. 식 (2.1)은 입력된벡터와 경쟁층노드 사이의 거리를, 식 (2.2)는학습대상이 되 ᄂ
ᅳᆫ노드들의 연결 강도 재조정 과정을나타내는 식이다. Wij는 j번째 경쟁층노드 가중치의 i번째 값을, Xi는 입력데이터의 i번째 값을, Wold와 W̸=w는각각 학습전과 후의 j번째 노드 연결 강도를의미하며, α는설정된학습률이다.
Dj=
n
X
i=1
(Wij− Xi)2, (2.1)
Wij̸=w= Wijold+ α(Xi− Wijold). (2.2) ᄉ
ᅡᆼ기 서술된과정을 통하여 전체 데이터는 초기 정해진 개수의 경쟁층 노드에 할당되게 되며, 원 데 ᄋ
ᅵ터의 차원과관계없이 2차원지도로 표현된다. 유사한 군집화 알고리즘인 K-평균 군집분석보다 지역 ᄎ
ᅬ적해에 수렴할 가능성이 적다는 연구가 있으며 (Bacao 등, 2005; Kim, 2006), 데이터의 분포와 관 ᄅ
ᅧᆫ된 가정이 필요치 않다는 장점이 있다 (Min과 Lee, 2001). 또한, 자료의극단치를 제거하지 않아도 부
ᆫ석이 가능하며, 신경망 기반의 알고리즘을 통해 복잡한 비선형 자료의 분석이 가능하다 (Min과 Lee, 2001; Martin-Del-Brio와 Serrano-Cinca, 1995).
2.3. 유전자 알고리즘
GA는 다윈의 진화론과 멘델의 유전 법칙을기반으로 발전된 최적화 알고리즘으로, 우열의 법칙, 교 ᄇ
ᅢ, 돌연변이 등의 과정을 포함하는 확률적 과정을 통해 주어진 문제에 대한 최적해를 탐색한다 (Hol- land, 1975; Mitchell, 1996; Kim과 Oh, 2018; Jo 등, 2018). 1970년대 Holland (1975)에 의해서 제안 ᄃ
ᅬ었으며, 이진법을이용하여 개체의 유전자 정보를표현할 수 있다 (Lee와 Kim, 2001). GA는 복잡한 ᄉ
ᅥᆫ형 및 비선형 문제의 최적해 탐색에서 우수한 성능을보여줄수 있으며, 해를탐색하는범위에 제한이 ᄆ
ᅡ
ᆭ지 않기 때문에 효과적이라고 알려져 있다 (Cheong 등, 2017, Kim과 Park, 2008).
GA는해결하고자 하는 문제를적합도 함수 (fitness function) 형태로 표현하며, 이렇게 수립된 적합 ᄃ
ᅩ 함수를활용하여 임의로 생성된초기 개체 (chromosome)들의 적합도 (fitness)를산출한다. 각각의 ᄀ
ᅢ체들은서로 다른유전정보 (gene)를가지고 있으며, 보통이진수로 표현되어 있다. 이렇게 산출된 적 ᄒ
ᅡᆸ도를기준으로 다음세대 (generation)에 선택될개체가 선별되며, 이러한 과정을선택 (selection)이 ᄅ
ᅡ고 한다. 선택된개체들은다음세대로 넘어가면서 무작위로 유전정보를교환하는교배 (crossover)와 이
ᆷ의로 특정 유전정보를변형시키는 돌연변이 (mutation) 과정을거친다. 이러한 과정들은 정해진 조 ᄀ
ᅥᆫ을만족하는최적해가 나타날 때까지 반복된다.
2.4. K-평균 군집분석 구
ᆫ집분석은유사한 성질을가진 데이터들을 군집화하는비지도 학습 분석기법을의미한다 (Cheong, 2014; Hartigan과 Wong, 1979). 사용자는 군집분석을 통하여 데이터 사이의 유사도를거리의 개념으 ᄅ
ᅩ 수치화하여 표현할 수 있으며, 이를 통해 군집 내 유사도가 가장 높고 군집 간의 유사도가 가장 낮도 ᄅ
ᅩ
ᆨ데이터를 분류할 수 있다 (Song과 Chang, 2010). 군집분석은다변량 분석에서 사용될수 있다고 알
ᄅ
ᅧ져 있으며 (Martin과 Meas, 1979; Cheong 등, 2017),유사도 측정 방법과 사용변수에 따라서 다양 ᄒ
ᅡ게활용될수 있다.
K-평균 군집분석은 연속형 데이터에 대해서 제한적으로 활용될 수 있는 군집분석 알고리즘으로 (Lee와 Park, 2010), 군집 수가 결정됐을 때 사용될 수 있는비 계층적 알고리즘이며, 이는 각 개체의 ᄉ
ᅩ속 군집이 지속해서 변화됨을 의미한다 (Lim과 Lim, 2012; Min, 2010). K-평균 군집분석은주어진 ᄌ
ᅥᆫ체 데이터들을 임의의 K개 군집으로 분할하는것으로 시작한다. 이후 K개 군집의 중심점을계산하 ᄀ
ᅩ, 모든데이터를 가장 가까운 중심점의 군집으로 재할당한다. 모든데이터의 소속 군집 변동이 없을 ᄄ
ᅢ까지 위 과정을반복수행하면서 최적의 결과를탐색한다. 개체 간의 유사도를 측정하는방법에 따라 ᄃ
ᅡ양하게 세분될수 있으며, 초기 군집 개수를 설정하는과정이 중요하다고 알려져 있다 (Bae와 Roh, 2005). 식 (2.3)은 본연구에서 사용된유사도 측정 방법인 유클리디안 (Euclidean) 거리 산출방법을나 ᄐ
ᅡ낸 식이다.
D(x, y) = v u u t
n
X
i=1
(xi− yi)2. (2.3)
3. 연구모형 ᄇ
ᅩᆫ연구에서는 GA, SOM,그리고 K-평균 군집분석을 통해 개별 펀드들에 대한 투자 최적화 모형을 ᄌ
ᅦ시하고, 실제 펀드 데이터를활용한 실증 분석 결과를 분석하고자 한다. 전체 연구모형의 구성은아래 ᄋ
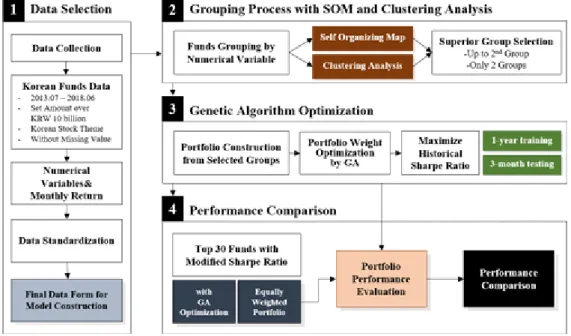
ᅪ 같이 크게 4단계로 이루어진다 (Figure 3.1).
Figure 3.1 Experimental architecture for models presented
Step 1. 펀드 스크리닝 및 데이터 추출 보
ᆫ연구에서는 증권시장에 상장되지 않은개별 펀드들의 투자모형을최적화하기 위하여, 유형과 규모, ᄀ
ᅳ리고 운용기간 등에 따라 적절한 대상 펀드를선정하는스크리닝 과정을선행한다. 이후 선정된투자 ᄃ
ᅢ상 펀드들의 특성과 운용성과를가장 잘 나타낼 수 있는변수들을선정하고, 이를 통해 군집화 및 최 ᄌ
ᅥᆨ화 알고리즘을수행하게된다.
ᄇ
ᅩᆫ모형은투자자들이 가입 가능한 개별 펀드 중에서 가장큰비중을차지하고 있는 국내 주식형 펀드 르
ᆯ대상으로 개발되었으며, 설정액 100억 이상의 규모를가지고 있는펀드들로 투자 대상을제한하였다.
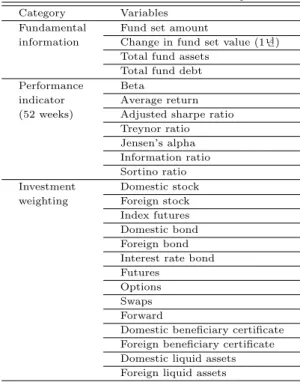
ᄑ
ᅥᆫ드의 특성과 성과를잘 나타내는 25개의 변수가활용되며, 그 목록은 Table 3.1과 같다. 추후 실증 분 ᄉ
ᅥᆨ의 편의를위해서 분석 기간 내 결측치를포함하는 종목은배제하였다.
Table 3.1 All variables for model development Category Variables
Fundamental Fund set amount
information Change in fund set value (1ᄂ ᅧ ᆫ) Total fund assets
Total fund debt Performance Beta
indicator Average return (52 weeks) Adjusted sharpe ratio
Treynor ratio Jensen’s alpha Information ratio Sortino ratio Investment Domestic stock weighting Foreign stock
Index futures Domestic bond Foreign bond Interest rate bond Futures
Options Swaps Forward
Domestic beneficiary certificate Foreign beneficiary certificate Domestic liquid assets Foreign liquid assets
Step 2. 자기 조직화 지도와 군집분석을 활용한 개별 펀드 군집화 ᄇ
ᅩᆫ 논문에서는 SOM과 K-평균 군집분석을활용하여 유사한 특정 및 성과를지닌 개별 펀드들을 군집 ᄒ
ᅪ한 후, 해당 군집단위로 우선순위를도출하는과정을 통해서 투자 대상 펀드를선별하게된다. 이러한 ᄀ
ᅪ정은 분석 과정에서 쉽게 알아챌 수 없는펀드의 우수성과 펀드들사이의 숨겨진 유사성을알아챌 수 이
ᆻ도록도와주며, 선별된 군집의 숫자는고정되더라도 전체 개수가 자동으로 결정된다는장점이 있다.
구
ᆫ집화 과정에서 군집의 개수는모형의 성과를 좌우하는가장 중요한 변수 중 하나이다 (Rhe, 1997;
Song과 Chang, 2010). 적절한 군집의 개수를구하기 위해 다양한 통계적 분석 방법 및 통계량들이활 ᄋ
ᅭ
ᆼ될 수 있으며, 군집 개수와 그 결정 방법의 변화가 연구결과에 영향을미칠 수 있음을 보여주는선행
ᄋ
ᅧᆫ구들이 진행되었다 (Ryu 등, 2002; Kyung 등, 2007). 본연구에서는최적의 군집 개수를구하기 위 ᄒ
ᅢ 역사적 데이터에 대한 반복적인 실험을 진행하였다. 이러한 반복적인 실험을 통한 방법은 K-평균 군 지
ᆸ화가 자동으로 군집의 개수를결정하는비지도 학습을 통해 진행될수 있다는점과, SOM 등 인공지 ᄂ
ᅳ
ᆼ방법론의 경우 데이터 의존적인 성격이 강하다는점을고려하여 선택되었으며, 인위적으로 군집의 개 ᄉ
ᅮ를설정하는것보다 자동화 시스템 구축에 적합하다고 본연구진은판단하였다. 이에 2011년 1월부터 2013년 6월 사이에서 임의로 선택된 열 개의 시점에 대하여 동일 변수들로 자동 K-평균 군집화를수행 ᄒ
ᅡᆫ 결과, 전체 투자 후보군펀드 대비 평균약 2.266%에 해당하는 군집이 생성됨을확인하였다. 따라서 보
ᆫ모형은해당 값을참조하여 군집의 개수를결정하였다. SOM을활용할 때는지도 작성 과정에서 두 ᄎ
ᅮ
ᆨ의 크기가 같도록제곱수의 군집 개수를사용하였다.
ᄀ
ᅮᆫ집화된자료에 대하여, 실제 투자 대상이 되는 군집을선별하기 위한 기준으로 군집들각각의 평균 52주 수정 샤프지수를활용한다. 기존의 펀드 단위 비교와는다르게, 군집단위의 평균성과 비교는성과 ᄀ
ᅡ 우수한 펀드들과 유사한 성질을가지고 있는 숨겨진 펀드들을발견할 수 있도록도와주는역할을할 ᄉ
ᅮ 있다. 군집의 개수를무조건 상위 두 번째 군집까지 선별하는방법과 첫 번째 군집 내에 소속된 펀드 ᄋ
ᅴ 개수가 한 개일 경우에만 두 번째 군집까지 선별하는방법이 있으며, 본연구는두 가지 경우를모두 부
ᆫ석한 후 이를비교 · 분석한다.
Step 3. 유전자 알고리즘을 활용한 투자비중 최적화
Step 2를 통해 선별된투자 대상 펀드에 대하여, 그 투자 비중을 최적화하기 위해 GA를 활용한다.
GA를 통해서 탐색하고자 하는변수는각 펀드의 투자 비중이며, 목적함수는해당 펀드들로 이루어진 포 ᄐ
ᅳ폴리오의 과거 1년간의 샤프지수 최대화로 설정한다. 모든수익률은 월별 자료를사용한다. 예를 들 ᄋ
ᅥ, 2014년 7월부터 9월까지 3개월간 투자할 비중을탐색하기 위해서 2013년 7월부터 2014년 6월까지 ᄋ
ᅴ 월별 수익률 샤프지수를 최대화하는포트폴리오를 구성하게된다. 이렇게 최적화된투자 비중을 기 ᄇ
ᅡᆫ으로 향후 3개월간 투자를 진행하며, 3개월이 지난 후에는다시 Step 1부터 모형을반복하는재조정 (re-balancing)작업을수행한다.
Step 4. 투자성과 측정 및 비교/분석 ᄌ
ᅦ시된두 가지 투자모형의 우수성을확인하기 위해, 군집화를 진행하지 않은투자모형들과 성과를비 ᄀ
ᅭ · 분석한다. 제시된모형들에서는 군집단위로 과거 성과지표를비교하여 펀드를선별하였으나, 군집 ᄒ
ᅪ를 진행하지 않는 벤치마크 모형들은개별 펀드의 52주 수정 샤프지수를 기준으로 상위 30개 펀드를 ᄐ
ᅮ자 대상으로 하였다. 또한, 투자비중 최적화 과정에서 GA를사용하는 경우와 동일비중을사용하는 겨
ᆼ우로 세분화하였다. 성과 비교를위한 척도로는 월 단위 수익률의 투자 기간 내 샤프지수와 연환산 절 ᄃ
ᅢ 수익률을사용한다. 서로 다른네 개의 투자모형과 두 개의 벤치마크 모형의 비교를 통해 군집화 알 ᄀ
ᅩ리즘의 유무가 투자 결과에 미치는영향을 분석해볼수 있을것으로 기대한다.
4. 실증 분석 시
ᆯ증 분석에는 Fn가이드에서 제공하는데이터 솔루션이활용되었다. Fn가이드는다년간 다양한 금 유
ᆼ데이터와 투자 솔루션을제공하고 있는데이터베이스 및 온라인정보 제공업체이다. 현재는금융정보 ᄌ
ᅦ공, 지수 제공, 기업 분석 등의 서비스를판매하고 있으며, 해당사에서 펀드와관련된 다양한 데이터 르
ᆯ제공하는 솔루션인 FnSpectrum을 통해 본연구와 관련된모든데이터의 수집이 이루어졌다. 우선 ᄌ
ᅦ공되는전체 25,682개의 펀드 중에서 국내 펀드 시장의 가장큰규모를차지하고 있는 국내주식형 공
ᄆ
ᅩ펀드로 실험 대상을 한정 (4,509개)하였으며, 추가로 안정적 규모의 펀드를 대상으로 분석을 진행하 ᄀ
ᅵ 위해 설정액 100억 이상이라는스크리닝 조건을추가하였다 (1,060개). 2013년 7월부터 2018년 6월 ᄁ
ᅡ지의 월 단위 데이터를 수집하였으며, 분석의 편의성을위해 해당 기간 내에서 결측치가 존재하거나 ᄇ
ᅧᆫ수를추출하기 위한 운용 기간이 충분하지 않은 펀드들은제외하는과정을거쳐 총 596개 펀드의 데 ᄋ
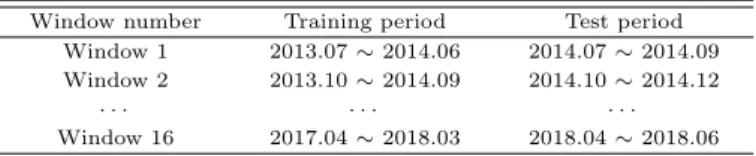
ᅵ터가 최종수집되었다. 데이터는 총 25개의 연속형 변수를포함하고 있으며, 이는앞선 3장의 Table 3.1에 나열된 목록과 같다. 데이터 기간 내에서 1년 동안 학습된투자모형을다음 3개월 동안 적용하여 ᄀ
ᅳ 성능을 검증하는 슬라이딩윈도우 (sliding window) 방식을 사용하며, 윈도우의 크기는 3개월이다.
ᄄ
ᅡ라서 전체 윈도우 개수는 16개이며, 전체 투자 기간은 48개월이다. 샤프지수 계산 및 분석을위한 무 ᄋ
ᅱ험 수익률로는 각 윈도우의 투자 시작일 기준 CD금리 (91일)를 3개월 단위로환산한 값을활용하였 ᄃ
ᅡ. Table 4.1은전체 데이터 내에서 각 윈도우의 학습구간과 검증구간을보여주고 있다.
Table 4.1 Experimental period for each window Window number Training period Test period
Window 1 2013.07 ∼ 2014.06 2014.07 ∼ 2014.09 Window 2 2013.10 ∼ 2014.09 2014.10 ∼ 2014.12
· · · · · · · · ·
Window 16 2017.04 ∼ 2018.03 2018.04 ∼ 2018.06
ᄋ ᅡ
ᇁ서 서술한 내용에 따라, 전체 실증 분석에 활용되는투자모형은여섯 종류로 세분된다. 세분기준 ᄋ
ᅳ
ᆫ 군집화 알고리즘의 유무, 종류, 그리고 GA활용여부 등이며, 분류된내용은간략하게 아래와 같다.
Model 5와 Model 6은성과 비교를위한 벤치마크 모형이다.
• Model 1: SOM, only 2 groups, GA
• Model 2: K-means clustering, only 2 groups, GA
• Model 3: SOM, up to 2 groups, GA
• Model 4: K-means clustering, up to 2 groups, GA
• Model 5: No clustering, 30 funds, GA
• Model 6: No clustering, 30 funds, equally weighted
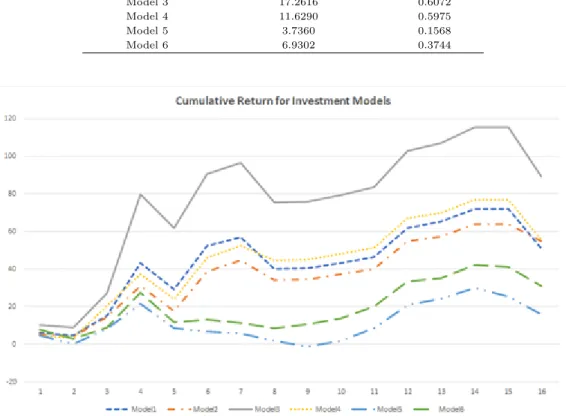
ᄋ
ᅡ래 Table 4.2는 여섯 가지 투자모형들을 실증분석한 결과로 산출된 성과지표들을 나타내고 있다.
ᄋ
ᅧᆫ환산된 절대 수익 측면에서 군집화를활용한 모형들의 결과가 그렇지 않은모형들에 비해 상대적으로 노
ᇁ게 나타났으며, 그중에서도 SOM과 GA를활용한 Model 3가 약 17.26%의 가장 높은성과를보였다.
ᄀ
ᅮᆫ집화를포함하는또 다른 Model 1, Model 2,그리고 Model 4 역시 10%를상회하는 높은연환산 수익 류
ᆯ을기록하였고, 이는 동일기간 내 무위험 수익률보다 월등한 성과이며, 동일 기간 동안 KOSPI200의 ᄋ
ᅧᆫ환산 상승률인 약 3.7%보다 우수하다. 군집화가 이루어지지 않은 Model 5와 Model 6은 각각 약 3.7%, 6.9%의 수익률을기록하였으며, 이는무위험 수익률을상회하지만 본 논문에서 제시하는모형들 (Model 1∼4)보다는성능이 우수하지 못함을의미한다. 샤프지수 측면에서도 군집화를활용한 모형들 ᄋ
ᅵ 그렇지 않은모형들에 비해 우수한 성과를 보였다. Figure 4.1은전체 모델들의 실증 분석 기간 내 ᄂ
ᅮ적수익률을 도식화한 자료이다. 자료의 세로축은 백분율단위의 누적 절대 수익률을, 가로축은 실증 부
ᆫ석된윈도우의 번호를의미한다. 각 윈도우의 실험 기간은 3개월이다.
시
ᆯ증 분석 결과, 동일한 알고리즘으로 구성된 투자모형이라도 군집을선택하는 방법에 따라 그 결과 ᄆ
ᅮ
ᆯ이 달라지는것을확인할 수 있다. 투자 의사결정을함에 있어서 자산을 선택하는과정은 매우 중요
Table 4.2 Experimental results for all investment models Number of models Average return (yearly, %) Sharpe ratio
Model 1 10.8380 0.4798
Model 2 11.5283 0.6628
Model 3 17.2616 0.6072
Model 4 11.6290 0.5975
Model 5 3.7360 0.1568
Model 6 6.9302 0.3744
Figure 4.1 Cumulative returns for investment models
ᄒ
ᅡ며, 본연구에서도 몇 개의 펀드가 선택됐는지에 따라 성과가 유의미하게 달라졌다. Table 4.3은 각 ᄐ
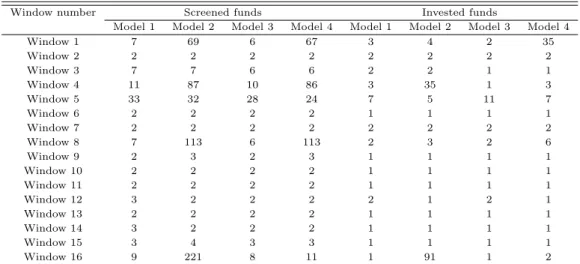
ᅮ자모형이 실험 구간에서 선별한 투자자산 후보군과 실제 투자가 이루어진 펀드들의 개수를나타낸다.
ᄋ
ᅵ를 통해 실험 초반에는비교적 다수의 펀드가 투자자산 후보군으로 선택되었으나, 최근데이터에 가까 ᄋ
ᅯ질수록매우 소수의 펀드만이 선택되었던 것을확인할 수 있다. 분산투자와 위험관리의관점에서, 매 ᄋ
ᅮ 소수의 펀드만을투자한다는것은그만큼위험을감수하는투자 의사결정이라고 해석할 수 있다. 실 ᄌ
ᅦ 실증 분석 결과, 군집화를포함하는모형 (Model 1∼4)는수정 샤프지수 기준상위 30개의 펀드를투 ᄌ
ᅡ자산 후보군으로 설정하는모형 (Model 5, 6)에 비해 높은위험도 (수익률변동성)를나타냈다. 그러 ᄂ
ᅡ 실험 결과를 종합적으로 분석해보았을때, Model 1∼4는비교적 높은위험도를감수할 만큼의 충분 ᄒ
ᅵ큰연환산 수익률을기록하였으며, 따라서 최종적으로 높은샤프지수를기록하였다.