2018, 29
(4)
,873–884
여러 개의 단순선형회귀모형에서 순차기울기를 이용한 평행성 검정
기
ᆷ혜림
1
· 김동재2
12가톨릭대학교 의생명 · 건강과학과
ᄌ ᅥ
ᆸᄉ ᅮ 2018ᄂ ᅧ ᆫ 6ᄋ ᅯ ᆯ 22ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 7ᄋ ᅯ ᆯ 13ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 7ᄋ ᅯ ᆯ 16ᄋ ᅵ ᆯ
요 약
ᄀ
ᅡ
ᆨᄀ ᅡ ᆨᄋ ᅴ ᄆ ᅩᄌ ᅵ ᆸᄃ ᅡ ᆫᄋ ᅦᄉ ᅥ ᄒ ᅧ ᆼᄉ ᅥ ᆼᄃ ᅬ ᆫ ᄒ ᅬᄀ ᅱᄌ ᅵ ᆨᄉ ᅥ ᆫᄋ ᅳ ᆯ ᄇ ᅵᄀ ᅭᄒ ᅡ ᆯ ᄄ ᅢ, ᄋ ᅵᄃ ᅳ ᆯ ᄋ ᅴ ᄑ ᅧ ᆼᄒ ᅢ ᆼᄉ ᅥ ᆼᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄉ ᅮ ᆫ ᄉ ᅥᄃ ᅢᄅ ᅵ ᆸᄀ ᅡᄉ ᅥ ᆯᄋ ᅳ ᆯ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅥ
ᆺᄋ ᅵ ᄑ ᅵ ᆯᄋ ᅭᄒ ᅡ ᆯ ᄄ ᅢᄀ ᅡ ᄋ ᅵ ᆻᄃ ᅡ. ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄀ ᅡ ᆨ ᄌ ᅵ ᆨᄉ ᅥ ᆫᄋ ᅴ ᄉ ᅮ ᆫ ᄎ ᅡᄀ ᅵᄋ ᅮ ᆯ ᄀ ᅵᄅ ᅳ ᆯ ᄀ ᅨᄉ ᅡ ᆫᄒ ᅡᄋ ᅧ Williams (1972)ᄋ ᅴ ᄆ ᅩᄉ ᅮᄌ ᅥ ᆨ ᄀ ᅥ
ᆷᄌ ᅥ ᆼᄇ ᅥ ᆸᄀ ᅪ ᄇ ᅵᄆ ᅩᄉ ᅮᄌ ᅥ ᆨ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄇ ᅥ ᆸ, Jonckheere (1954)ᄀ ᅥ ᆷᄌ ᅥ ᆼᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄑ ᅧ ᆼᄒ ᅢ ᆼᄉ ᅥ ᆼ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅳ ᆯ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄄ ᅩᄒ ᅡ ᆫ, ᄆ ᅩ ᆫ ᄐ
ᅦᄏ ᅡᄅ ᅳ ᆯ ᄅ ᅩ ᄆ ᅩᄋ ᅴᄉ ᅵ ᆯᄒ ᅥ ᆷᄋ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ ᅢ ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡ ᆫ ᄉ ᅦ ᄀ ᅡᄌ ᅵ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄀ ᅪ Adichie (1976)ᄀ ᅡ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡ ᆫ ᄀ ᅵᄌ ᅩ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄃ ᅳ ᆯ ᄋ
ᅴ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄅ ᅧ ᆨᄋ ᅳ ᆯ ᄑ ᅭᄇ ᅩ ᆫ ᄀ ᅪ ᄌ ᅵ ᆨᄉ ᅥ ᆫᄋ ᅴ ᄀ ᅢᄉ ᅮ, ᄀ ᅡ ᆨ ᄌ ᅵ ᆨᄉ ᅥ ᆫᄋ ᅴ ᄀ ᅵᄋ ᅮ ᆯ ᄀ ᅵᄅ ᅳ ᆯ ᄃ ᅡ ᆯᄅ ᅵᄒ ᅡᄋ ᅧ ᄇ ᅵᄀ ᅭᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄀ ᅳ ᄀ ᅧ ᆯᄀ ᅪ ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥ ᄌ ᅦ ᄋ
ᅡ ᆫᄒ ᅡ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄃ ᅳ ᆯᄋ ᅳ ᆫ ᄉ ᅮ ᆫ ᄎ ᅡᄀ ᅵᄋ ᅮ ᆯ ᄀ ᅵᄅ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᄇ ᅵᄀ ᅭᄌ ᅥ ᆨ ᄉ ᅩ ᆫᄉ ᅱ ᆸᄀ ᅦ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄋ ᅵ ᄀ ᅡᄂ ᅳ ᆼ ᄒ ᅡᄋ ᅧ ᆻᄋ ᅳᄆ ᅧ ᄆ ᅡ ᆭᄋ ᅳ ᆫ ᄀ ᅧ ᆼᄋ ᅮᄋ ᅦᄉ ᅥ ᄀ ᅵᄌ ᅩ ᆫ ᄇ ᅡ ᆼᄇ ᅥ ᆸ ᄃ
ᅳ
ᆯ ᄀ ᅪ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄅ ᅧ ᆨᄋ ᅵ ᄇ ᅵᄉ ᅳ ᆺᄒ ᅢ ᆻᄂ ᅳ ᆫ ᄃ ᅦ, ᄐ ᅳ ᆨ ᄒ ᅵ ᄑ ᅭᄇ ᅩ ᆫ ᄋ ᅴ ᄏ ᅳᄀ ᅵᄋ ᅪ ᄀ ᅵᄋ ᅮ ᆯ ᄀ ᅵᄋ ᅴ ᄎ ᅡᄋ ᅵᄀ ᅡ ᄌ ᅡ ᆨᄋ ᅳ ᆯ ᄄ ᅢᄂ ᅳ ᆫ ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥ ᄌ ᅦᄋ ᅡ ᆫᄒ ᅡ ᆫ ᄆ ᅩᄉ ᅮ ᄌ
ᅥ ᆨ ᄇ ᅡ ᆼᄇ ᅥ ᆸᄋ ᅴ ᄀ ᅥ ᆷᄌ ᅥ ᆼᄅ ᅧ ᆨᄋ ᅵ ᄀ ᅡᄌ ᅡ ᆼ ᄂ ᅩ ᇁ ᄀ ᅦ ᄂ ᅡᄐ ᅡᄂ ᅡ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄃ ᅡ ᆫᄉ ᅮ ᆫ ᄒ ᅬᄀ ᅱᄆ ᅩᄒ ᅧ ᆼ, ᄉ ᅮ ᆫ ᄉ ᅥᄃ ᅢᄅ ᅵ ᆸᄀ ᅡᄉ ᅥ ᆯ, ᄉ ᅮ ᆫ ᄎ ᅡᄀ ᅵᄋ ᅮ ᆯ ᄀ ᅵ, ᄑ ᅧ ᆼᄒ ᅢ ᆼᄉ ᅥ ᆼᄀ ᅥ ᆷᄌ ᅥ ᆼ.
1. 서론 ᄒ
ᅬ귀분석은한 군의 개체로부터 두 변수 또는여러 변수들을 측정하고 그관계를모형화 하여 다음값 으
ᆯ예측하는 분석방법론이다. 우리는회귀분석을 통해 한국프로야구에서 투수 연봉에 영향을주는요인 으
ᆯ확인하여 연봉결정에 도움을 줄수도 있고 (Lee, 2017) 대인관계불안, 대학생활적응,자기통제와 스 ᄆ
ᅡ트폰 중독의관계를회귀분석으로 밝혀내어 스마트폰 중독예방을위한 기초자료를제공할 수도 있다 (Park과 Park, 2017). 이처럼 회귀분석은사회과학, 의학 및 공학 등많은 분야의 연구에 사용되고 있 ᄃ
ᅡ.
ᄋ
ᅧ러 모집단에서 표본을추출하여 각각의 회귀직선을구했을때, 이들기울기의 동질성에 대한 문제를 새
ᆼ각할 수 있는데 이것을평행성 검정 (test for parallelism)이라 한다.
ᄒ
ᅡᆫ편, 일반적으로 약의 복용량이 증가하면 그에 따라 효과도 증가하는패턴을보인다. 예를 들어, 증 ᄀ
ᅡ하는연령대에 대해 두통약의 효능을검사할 경우 대조그룹과 소량투여그룹, 다량투여그룹으로 나누 ᄋ
ᅥ 조사하게 되면 그룹에 따라 약의 효과에 대한 증가 여부를미리 예측할 수 있다. 이런 경우, 같은유 ᄋ
ᅴ수준이라면 양쪽검정을 시행하는 일반대립가설보다 한쪽검정을 시행하여 검정력을 높이는 순서대립 ᄀ
ᅡ설을사용하는것이 더 나은결론을내릴 수 있다. Adichie (1976)에 의하면 이처럼 회귀직선 기울기 ᄋ
ᅴ 순서대립가설에 대한 평행성검정의 필요성은자연스럽게 발생할 수 있는데, 그는 증가하는연령대의 ᄌ
ᅱ 집단에서 노출에 의한 감염의 정도를하나의 예로 들었다.
1
(137-701) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥᄎ ᅩᄀ ᅮ ᄇ ᅡ ᆫᄑ ᅩᄃ ᅢᄅ ᅩ 222, ᄀ ᅡᄐ ᅩ ᆯᄅ ᅵ ᆨᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄋ ᅴᄉ ᅢ ᆼᄆ ᅧ ᆼ · ᄀ ᅥ ᆫᄀ ᅡ ᆼᄀ ᅪᄒ ᅡ ᆨᄀ ᅪ, ᄃ ᅢᄒ ᅡ ᆨᄋ ᅯ ᆫᄉ ᅢ ᆼ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (137-701) ᄉ ᅥᄋ ᅮ ᆯᄐ ᅳ ᆨᄇ ᅧ ᆯᄉ ᅵ ᄉ ᅥᄎ ᅩᄀ ᅮ ᄇ ᅡ ᆫᄑ ᅩᄃ ᅢᄅ ᅩ 222, ᄀ ᅡᄐ ᅩ ᆯᄅ ᅵ ᆨᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄋ ᅴᄉ ᅢ ᆼᄆ ᅧ ᆼ · ᄀ ᅥ ᆫᄀ ᅡ ᆼᄀ ᅪᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
ᄒ
ᅬ귀직선 기울기의 순서성에 대한 평행성검정법은 많은 사람들에 의해 연구되어왔다. Adichie (1976)는 우도비통계량에 기반한 여러가지 형태의 검정통계량을 제안하였는데, 이들은 최소제곱추정 ᄅ
ᅣᆼ의 적절한 선형조합에근거하고 있다. 그중에서 비모수적 방법은회귀식의 잔차에 기초한 순위를 사 ᄋ
ᅭ
ᆼ하기 때문에 독립변수의 위치에 영향을받게 되어 절대적인 비교가 불가능하다는취약점을갖고 있다.
ᄋ
ᅵ 후 Kim (1995)에 의하여 Adichie의 점수함수를수정한 방법이 제안되었다. Rao와 Gore (1984)는 ᄑ
ᅭ본의 크기가 2r일 때 서로 다른 관측값으로부터 r개의 서로 독립인 기울기추정량을 얻어내고, 이를 ᄋ
ᅵ용한 검정을제안하였는데, 분포무관 검정법이된다는장점이 있으나 독립변수에 여러 제약조건이 있 ᄀ
ᅩ, 효율이 떨어진다는단점이 있다. 이외에도 Song 등 (1987)은 Kepner와 Robins의 대비의 아이디어 르
ᆯ이용한 분포무관 검정법을제안하였고, Song 등 (1993)은 Potthoff형태의 검정통계량을 붓스트랩 분 ᄉ
ᅡᆫ추정량으로 표준화하여 점근분포무관 검정을제안하였다. 또한, Lee (1993)는기울기의 추정에 가중 Jonckheere형태의 통계량을적용하여 점근분포무관 검정을 실시하였고, Jee (2013)는잔차의 순위에근 ᄀ
ᅥ한 Jonckheere형태의 검정통계량을이용하여 점근분포무관 검정법을제안하였다.
ᄇ
ᅩᆫ 논문에서는 여러 개의 단순선형회귀모형에서 순서대립가설에 대한 평행성 검정법을 제안한다.
ᄀ ᅡ
ᆨ 직선에서 연속된 점들 사이의 순차기울기 (sequential slope)를 생성하여 모수적인 방법으로는 Williams (1972)의 모수적검정법, 비모수적인 방법으로는 Williams (1986)의 비모수적검정법과 Jon- ckheere (1954)검정법을 실시하였고, 기존에 사용되던 Adichie (1976)의 모수적 방법, 비모수적 방법과 ᄆ
ᅩ의실험을 통하여 검정력을비교하였다.
2. 제안 방법
2.1. 순차기울기와 모형 ᄃ
ᅡ음과 같은회귀직선 모형을가정한다.
yij= αi+ βixij+ ϵij(i = 1, 2, . . . , k, j = 1, 2, . . . , ni, xij+1= xij+ a), ᄋ
ᅧ기서 yij는 i번째 직선에서 j번째 반응변수의 값, xij는 i번째 직선에서 j번째 설명변수의 값으로 오 ᄅ
ᅳ
ᆷ차순으로 정렬된 값들이다. ϵij는 오차항으로 평균이 0이고 분산이 σ2인 분포함수 F 를 독립적으로 ᄄ
ᅡ르는 확률변수이며, αi와 βi, σ2은 미지의 모수이다. 본 논문에서는 순차기울기를 이용하므로 xij가 ᄃ
ᅳ
ᆼ간격이라는가정을추가한다. 순서대립가설에 대한 평행성 검정의 가설은다음과 같다.
H0: β1= β2= . . . = βk vs H1: β1≤ β2≤ . . . ≤ βk (β1< βk).
보
ᆫ 논문의 검정에 필요한 순차기울기 Sij 다음과 같이 구한다.
Sij= yij+1− yij
xij+1− xij
(i = 1, 2, . . . , k, j = 1, 2, . . . , ni).
ᄋ ᅵ때,
Sij= yij+1− yij
xij+1− xij
= (αi+ βixij+1+ ϵij+1) − (αi+ βixij+ ϵij) xij+1− xij
= βi + ϵij+1− ϵij
xij+1− xij
ᄋ ᅵ므로
E(Sij) = βi, V ar(Sij) = 2σ2
(xij+1− xij)2 = 2σ2 a2 ᄀ
ᅡ된다.
ᄄ
ᅡ라서 각 직선의 순차기울기들은 Table 2.1과 같이 일원배치 데이터구조로 나타낼 수 있다.
Table 2.1 One-way data structure of slope estimator
Sequential slope
line
1 2 · · · k
S
11S
21· · · S
k1S
21S
22· · · S
k2. . .
. .
. . . .
. . .
S
1n1−1S
2n2−1· · · S
knk−12.2. 모수적 검정법 ᄆ
ᅩ수적 방법으로 검정하기 위하여 오차항은서로 독립이고 평균이 0, 분산이 σ2인 정규분포를따르는 화
ᆨ률변수임을가정한다.
Williams’ ¯t-test는 일원배치모형에서 집단간의 경향분석을 위한 모수적 검정법의 일종으로 최저 복 ᄋ
ᅭ
ᆼ량을 정하기위한 독성연구에 흔히 사용되고있다. 본 논문에서는 회귀직선 기울기의 순서성에 대한 펴
ᆼ행성 검정을 위하여 일원배치 데이터 구조로 나타낸 순차기울기로 k개의 기울기 추정량을 구하여 Williams’ ¯t-test를 실시한다.
거
ᆷ정을위해 PAVA (the pool adjacent violator algorithm)을이용하여 i번째 직선 기울기의 최대우 ᄃ
ᅩ추정량을다음과 같이 구한다.
βˆi= max1≤u≤i
Pv j=unjSj
Pv j=unj
. ᄃ
ᅡᆫ, Sj는각 군의 순차기울기의 표본평균이다.
ᄆ
ᅩ든 군의 순차기울기 개수가 같거나 첫번째 군만 개수가 다른경우에는 ¯tk 통계량을다음과 같이 구 ᄒ
ᅡᆫ다.
¯tk= βˆk− S1
sq
1 nk +n1
1
.
ᄃ
ᅡᆫ, s는 분산의 추정량으로 평균제곱근오차 (root mean square error)이다.
ᄌ
ᅡ유도가 v일 때, 유의수준 α에서 H0의 기각역은다음과 같다.
¯tk> ¯tv,k,α(w), v =X
i
ni− (k + 1), w = n1/nk,
ᄋ
ᅧ기서 ¯tv,k,α(w)는 Williams분포표를 통해 얻을수 있다.
ᄀ
ᅳ 외의 경우에는 ¯ti,v통계량을다음과 같이 구하여 첫번째 직선과 각각 비교한다.
¯ti=
βˆi− S1
sq
1 ni +n1
1
.
ᄌ
ᅡ유도가 v일 때, 유의수준 α에서 H0의 기각역은다음과 같다.
¯ti> ¯tv,k,α(λ), v =X
i
ni− (k + 1), λ = ni/nk,
ᄋ
ᅧ기서 ¯tv,k,α(λ)는 Williams분포표를 통해 구한다. 만약, 0.8 ≤ λ ≤ 1.25 라면 ¯tk 통계량을이용해도 추
ᆼ분히 정확한 결과를얻을수 있다.
2.3. Williams’ t-test를 이용한 비모수적 검정법
Shirly (1977)는 Williams’ ¯t-test를 바탕으로 정규성 가정이 필요없는 비모수적 검정법을제안하였 ᄀ
ᅩ, Williams (1986)는이를수정하여 더 높은 검정력을가지는 방법을제안하였다. 본 논문에서는 각 지
ᆨ선에서 구한 N =Pk
i=1ni−1개 순차기울기의 혼합순위를이용하여 Williams’ t-test를 실시한다. 혼 ᄒ
ᅡᆸ순위는 N개의 순차기울기로 혼합표본을만든후, 작은것부터 차례대로 순위를부여하여 만든다. 즉, Rij= N개의 혼합표본에서의 Sij의 순위
ᄅ
ᅩ 정의한다.
거
ᆷ정을위해 모든 군의 순차기울기 개수가 같거나 첫번째 군만 개수가 다른 경우에는자유도가 V 인 tk통계량을다음과 같이 구한다.
tk= [max1≤u≤k
Pk j=unjR¯j
Pk j=unj
− ¯R1][V ( 1 nk
+ 1 n1
)]−1/2, V = N (N + 1) 12 . ᄃ
ᅡᆫ, ¯Rj는 j번째 직선에있는 혼합순위의 평균이다.
ᄌ
ᅡ유도가 V 일 때, 유의수준 α에서 H0의 기각역은다음과 같다.
¯tk> ¯tV,k,α(w), w = n1/nk, ᄋ
ᅧ기서 ¯tV,k,α(w)는 Williams분포표를 통해 얻을수 있다.
ᄀ
ᅳ 외의 경우에는 ti통계량을다음과 같이 구하여 첫번째 직선과 각각 비교한다.
ti= [max1≤u≤i
Pi j=unjR¯j
Pi j=unj
− ¯R1][Vi(1 ni
+ 1 n1
)]−1/2, Vi=Ni(Ni+ 1) 12 . ᄋ
ᅵ 때, Ni는비교할 직선들의 순차기울기 개수의 합이고, Ni개의 혼합표본에서 순차기울기의 순위를구 ᄒ
ᅡ여 검정한다.
ᄌ
ᅡ유도가 Vi일 때, 유의수준 α에서 H0의 기각역은다음과 같다.
ti> ¯tVi,k,α(λ), λ = ni/nk, ᄋ
ᅧ기서 ¯tVi,k,α(λ)는 Williams분포표를 통해 구한다. 만약, 0.8 ≤ λ ≤ 1.25 라면 ¯tk 통계량을이용해도 ᄎ
ᅮᆼ분히 정확한 결과를얻을수 있다.
2.4. Jonckheere test를 이용한 비모수적 검정법
Jonckheere test는 일원배치모형의 경향분석에 사용되는 대표적인 비모수적 검정법으로 본 논문에 ᄉ
ᅥ는 k개의 각 직선에서 ni−1개의 순차기울기를 이용하여 Jonckheere test를 실시한다. 검정을 위해 k(k − 1)/2개의 Mann-Whitney 통계량 Uuv를다음과 같이 구한다. (U < V )
Uuv=
nu
X
i=1 nv
X
j=1
ψ(Sjv, Siu), ψ(x) =
( 1 , (x > 0) 0 , (그 외).
ᄋ ᅡ
ᇁ서 구한 Mann-Whitney 통계량의 합으로 Jonckheere 검정통계량을구하고, 가설검정을한다.
J =
k
X
u<v
Uuv =
k−1
X
u=1 k
X
v=u+1
Uuv.
ᄋ
ᅲ의수준 α에서 H0의 기각역은다음과 같다.
J ≥ j(α, k, (n1, . . . , nk), ᄋ
ᅧ기서 j(α, k, (n1, . . . , nk)는 Jonckheere분포표를이용하여 구한다.
ᄆ
ᅡᆫ약, 기울기에 동점이 존재하는경우 Mann-Whitney 통계량을다음과 같이 수정하여 검정한다.
Uuv=
nu
X
i=1 nv
X
j=1
ψ∗(Sjv, Siu), ψ∗(x) =
1, (x > 0) 1/2, (x = 0) 0, (x < 0).
3. 모의실험 계획 및 결과 ᄋ
ᅡ
ᇁ 절에서는여러 개의 단순선형회귀모형의 순서성에 대한 평행성 검정법으로 k개의 직선에서 각각 ni−1개의 순차기울기를계산하여 Williams의 검정법을이용하는모수적 방법과 비모수적 방법, Jonck- heere의 검정법을이용하는비모수적 방법을제안하였다. 본절에서는 Adichie의 모수적 방법과 비모수 ᄌ
ᅥᆨ 방법, 앞서 제안한 3가지 방법의 검정력 (power)을비교하기 위하여 모의실험을시행하였다. 모의실 ᄒ
ᅥ
ᆷ은 SAS를사용하여 귀무가설이 H0 : β1 = β2 = . . . = βk인 회귀직선의 기울기에 대한 순서대립가 서
ᆯ을검정하였다. 직선 3개와 4개에 대해 표본의 수가 5개, 10개인 경우로 나누어 모의실험을시행하였 ᄋ
ᅳ며 본 논문은기울기의 평행성 검정이므로 결과에 영향을미치지 않는절편 (αi)은 0으로 고정하였다.
처
ᆺ번째 직선의 기울기 (β1)는 1.0으로 고정하였으며, 기울기는 직선이 3개일때는앞직선의 기울기와의 ᄀ
ᅡᆫ격이 0, 0.1, 0.2 또는 0.3, 그리고 0.5가 되도록 변화를 주었고, 직선이 4개일때는앞직선과의 기울 ᄀ
ᅵ 차이가 0, 0.1, 0.5가 되도록변화를주어 검정력을비교하였다. 등간격의 가정에 따라 독립변수 (xij
)는모두 그 간격을 1로 하였으며, 오차항 (ϵij)의 분포로는정규분포, Cauchy분포, 이중지수분포, 오염 되
ᆫ 정규분포 (σ2 = 5, ϵ = 0.1)를사용하였다. RAND 함수를이용하여 생성한 각 분포의 난수로 검정 ᄐ
ᅩ
ᆼ계량을계산하고, 그 값이 기각역에 속하는지 판단하는과정을 독립적으로 10,000번 반복하는 Monte Carlo Study를시행하였다.
Table 3.1과 Table 3.2에는각각 직선이 3개이고 표본이 5개, 10개인 경우를정리하였고, Table 3.3과 Table 3.4에는각각 직선이 4개이고 표본이 5개, 10개인 경우를정리하였다. 여기서 ad-s는 Adichie의 ᄆ
ᅩ수적 검정법, ad-r은 Adichie의 비모수적 검정법, ssW는 순차기울기를이용한 Williams의 모수적 검 저
ᆼ법, ssW-r은 순차기울기를이용한 Williams의 비모수적 검정법, 그리고 ssJ는 순차기울기를이용한 Jonckheere 검정법을 뜻한다.
ᄆ
ᅥᆫ저 유의수준을 분포별로 살펴보면 정규분포에서는 직선 3개, 표본 5개일 때 ad-r이 0.0421로 낮게 ᄂ
ᅡ타났고. 그 외의 경우는대부분 0.05를 크게 벗어나지 않았다. Cauchy분포에서는 ad-s와 ssW는모 ᄃ
ᅳᆫ 경우에서 제어가 잘 되지 않았고, ssJ도 직선수와 관계없이 표본 10개일 때 다소 높게 나타났는데 ad-r과 ssW-r은대부분 0.05를크게 벗어나지 않았다. 이중지수분포에서는 직선 4개, 표본 10개일 때 ᄋ
ᅦ ssJ가 0.0583으로 높게 나타났고, 그 외의 경우에서는유의수준이 0.05와 비슷한 수준이었다. 오염 되
ᆫ정규분포에서는 ssW가 직선 3개, 표본 10개일 때 0.0607로 높게 나타났고, ad-r은 직선 3개, 표본 5개일 때 0.0436, ssW-r은 직선 4개, 표본 5개일 때 0.0422, ssJ는 직선 4개, 표본 5개일 때 0.0394로 낮 ᄀ
ᅦ 나타났고, 그 외에는대부분 0.05수준으로 잘 제어되었다.
ᄃ
ᅡ음으로 검정력을 분포별로 살펴보면 정규분포에서 직선 3개, 표본 5개일 때는모수적 방법의 검정 ᄅ
ᅧᆨ이 높았는데, 특히 기울기가 같거나 기울기의 차이가 작은 직선이 많은경우에는 본 논문에서 제안한 ᄆ
ᅩ수적 방법인 ssW의 검정력이 제일 높았다. 반면 기울기의 차이가큰 직선이 많은경우에는기존모수
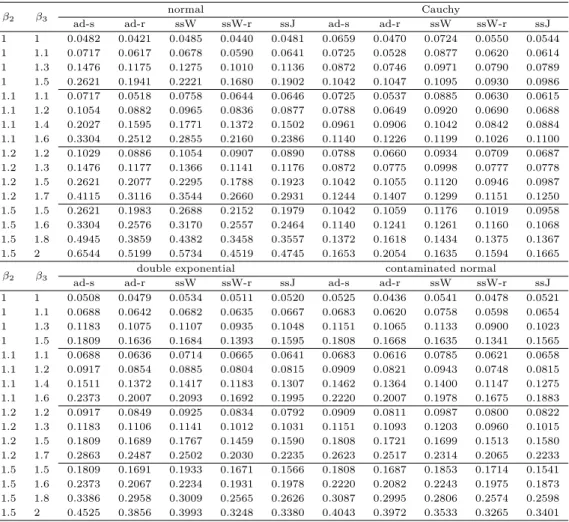
Table 3.1 Monte Carlo power estimates : α = 0.05, k = 3, n = 5 β
2β
3normal Cauchy
ad-s ad-r ssW ssW-r ssJ ad-s ad-r ssW ssW-r ssJ
1 1 0.0482 0.0421 0.0485 0.0440 0.0481 0.0659 0.0470 0.0724 0.0550 0.0544 1 1.1 0.0717 0.0617 0.0678 0.0590 0.0641 0.0725 0.0528 0.0877 0.0620 0.0614 1 1.3 0.1476 0.1175 0.1275 0.1010 0.1136 0.0872 0.0746 0.0971 0.0790 0.0789 1 1.5 0.2621 0.1941 0.2221 0.1680 0.1902 0.1042 0.1047 0.1095 0.0930 0.0986 1.1 1.1 0.0717 0.0518 0.0758 0.0644 0.0646 0.0725 0.0537 0.0885 0.0630 0.0615 1.1 1.2 0.1054 0.0882 0.0965 0.0836 0.0877 0.0788 0.0649 0.0920 0.0690 0.0688 1.1 1.4 0.2027 0.1595 0.1771 0.1372 0.1502 0.0961 0.0906 0.1042 0.0842 0.0884 1.1 1.6 0.3304 0.2512 0.2855 0.2160 0.2386 0.1140 0.1226 0.1199 0.1026 0.1100 1.2 1.2 0.1029 0.0886 0.1054 0.0907 0.0890 0.0788 0.0660 0.0934 0.0709 0.0687 1.2 1.3 0.1476 0.1177 0.1366 0.1141 0.1176 0.0872 0.0775 0.0998 0.0777 0.0778 1.2 1.5 0.2621 0.2077 0.2295 0.1788 0.1923 0.1042 0.1055 0.1120 0.0946 0.0987 1.2 1.7 0.4115 0.3116 0.3544 0.2660 0.2931 0.1244 0.1407 0.1299 0.1151 0.1250 1.5 1.5 0.2621 0.1983 0.2688 0.2152 0.1979 0.1042 0.1059 0.1176 0.1019 0.0958 1.5 1.6 0.3304 0.2576 0.3170 0.2557 0.2464 0.1140 0.1241 0.1261 0.1160 0.1068 1.5 1.8 0.4945 0.3859 0.4382 0.3458 0.3557 0.1372 0.1618 0.1434 0.1375 0.1367 1.5 2 0.6544 0.5199 0.5734 0.4519 0.4745 0.1653 0.2054 0.1635 0.1594 0.1665
β
2β
3double exponential contaminated normal
ad-s ad-r ssW ssW-r ssJ ad-s ad-r ssW ssW-r ssJ
1 1 0.0508 0.0479 0.0534 0.0511 0.0520 0.0525 0.0436 0.0541 0.0478 0.0521 1 1.1 0.0688 0.0642 0.0682 0.0635 0.0667 0.0683 0.0620 0.0758 0.0598 0.0654 1 1.3 0.1183 0.1075 0.1107 0.0935 0.1048 0.1151 0.1065 0.1133 0.0900 0.1023 1 1.5 0.1809 0.1636 0.1684 0.1393 0.1595 0.1808 0.1668 0.1635 0.1341 0.1565 1.1 1.1 0.0688 0.0636 0.0714 0.0665 0.0641 0.0683 0.0616 0.0785 0.0621 0.0658 1.1 1.2 0.0917 0.0854 0.0885 0.0804 0.0815 0.0909 0.0821 0.0943 0.0748 0.0815 1.1 1.4 0.1511 0.1372 0.1417 0.1183 0.1307 0.1462 0.1364 0.1400 0.1147 0.1275 1.1 1.6 0.2373 0.2007 0.2093 0.1692 0.1995 0.2220 0.2007 0.1978 0.1675 0.1883 1.2 1.2 0.0917 0.0849 0.0925 0.0834 0.0792 0.0909 0.0811 0.0987 0.0800 0.0822 1.2 1.3 0.1183 0.1106 0.1141 0.1012 0.1031 0.1151 0.1093 0.1203 0.0960 0.1015 1.2 1.5 0.1809 0.1689 0.1767 0.1459 0.1590 0.1808 0.1721 0.1699 0.1513 0.1580 1.2 1.7 0.2863 0.2487 0.2502 0.2030 0.2235 0.2623 0.2517 0.2314 0.2065 0.2233 1.5 1.5 0.1809 0.1691 0.1933 0.1671 0.1566 0.1808 0.1687 0.1853 0.1714 0.1541 1.5 1.6 0.2373 0.2067 0.2234 0.1931 0.1978 0.2220 0.2082 0.2243 0.1975 0.1873 1.5 1.8 0.3386 0.2958 0.3009 0.2565 0.2626 0.3087 0.2995 0.2806 0.2574 0.2598 1.5 2 0.4525 0.3856 0.3993 0.3248 0.3380 0.4043 0.3972 0.3533 0.3265 0.3401
* ad-s: Adichie parametric method, ad-r: Adichie nonparametric method
* ssW: Sequential slope Williams’ ¯ t-test, ssW-r: Sequential slope Williams’ t-test
* ssJ: Sequential slope Jonckheere
ᄌ
ᅥᆨ 방법인 ad-s의 검정력이 제일 높았고, 비모수적 방법들은제안한 방법들과 기존방법의 검정력이 모 ᄃ
ᅮ 비슷한 수준이었다. 직선 4개, 표본 5개일 때도 직선 3개일 때와 마찬가지로 기울기가 같거나 기울 ᄀ
ᅵ의 차이가 작은 직선이 많으면 ssW의 검정력이 제일 높았고, 그 외에는 ad-s의 검정력이 제일 높았다.
지
ᆨ선 3개, 표본 10개인 경우에는 모두 기존방법들의 검정력이 높았고, 직선 4개 표본 10개인 경우에도 ᄀ
ᅵ존방법들의 검정력이 높았으나 ad-r과 ssW의 검정력의 차이가 크지 않았고 기울기의 차이가 클때는 ᄆ
ᅩ든방법의 검정력이 비슷한 수준으로 나타났다.
Cauchy분포에서는 직선 3개, 표본 5개일 때에 모수적 방법인 ad-r와 ssW의 검정력이 높게 나타났지 ᄆ
ᅡᆫ 유의수준이 요구된수준보다 높게 시작했기 때문에 검정력의 비교가 어려운 것으로 보이고, 차이가 ᄏ
ᅳᆫ 직선이 존재하는경우에는 ad-r의 검정력이 가장 높았다. 직선 4개, 표본 5개일 때에도 마찬가지로 ᄆ
ᅩ수적 방법들의 유의수준이 높아서 검정력의 비교가 어려운데, 기울기의 차이가 커지면 ad-r의 검정력 ᄋ
ᅵ 가장 높았고 ssW-r과 ssJ도 모수적 방법들보다 검정력이 높게 나타났다. 직선 3개, 표본 10개인 경
Table 3.2 Monte Carlo power estimates : α = 0.05, k = 3, n = 10 β
2β
3normal Cauchy
ad-s ad-r ssW ssW-r ssJ ad-s ad-r ssW ssW-r ssJ
1 1 0.0482 0.0486 0.0484 0.0491 0.0525 0.0556 0.0545 0.0722 0.0556 0.0589 1 1.1 0.1478 0.1443 0.1038 0.0942 0.0974 0.0704 0.0969 0.0776 0.0859 0.0903 1 1.3 0.5726 0.5148 0.3410 0.2634 0.2829 0.1090 0.2256 0.0922 0.1326 0.1368 1 1.5 0.9242 0.8387 0.6673 0.5162 0.5422 0.1622 0.3909 0.1127 0.1892 0.1190 1.1 1.1 0.1478 0.1477 0.1139 0.1029 0.0987 0.0704 0.0969 0.0786 0.0946 0.0893 1.1 1.2 0.3415 0.3171 0.2114 0.1697 0.1734 0.0867 0.1588 0.0852 0.1150 0.1116 1.1 1.4 0.7924 0.7275 0.5101 0.3913 0.4075 0.1347 0.3241 0.1026 0.1611 0.1652 1.1 1.6 0.9802 0.9430 0.8054 0.6447 0.6689 0.1931 0.4797 0.1245 0.2251 0.2349 1.2 1.2 0.3415 0.3083 0.2353 0.1846 0.1743 0.0867 0.1567 0.0867 0.1193 0.1107 1.2 1.3 0.5726 0.5250 0.3698 0.2849 0.2825 0.1090 0.2358 0.0960 0.1426 0.1359 1.2 1.5 0.9242 0.8826 0.6743 0.5304 0.5446 0.1662 0.4053 0.1159 0.1960 0.1977 1.2 1.7 0.9957 0.9856 0.8986 0.7616 0.7813 0.2291 0.5597 0.1431 0.2669 0.2763 1.5 1.5 0.9242 0.8408 0.7498 0.6047 0.5418 0.1622 0.3894 0.1233 0.2154 0.1965 1.5 1.6 0.9802 0.9399 0.8472 0.7046 0.6711 0.1932 0.4833 0.1334 0.2468 0.2334 1.5 1.8 0.9994 0.9965 0.9714 0.8645 0.8665 0.2614 0.6373 0.1647 0.3295 0.3182 1.5 2 1.0000 1.0000 1.0000 0.9543 0.9570 0.3260 0.7473 0.1999 0.4093 0.4053
β
2β
3double exponential contaminated normal
ad-s ad-r ssW ssW-r ssJ ad-s ad-r ssW ssW-r ssJ
1 1 0.0478 0.0539 0.0506 0.0554 0.0560 0.0496 0.0522 0.0607 0.0551 0.0561 1 1.1 0.1141 0.1317 0.0842 0.0963 0.1009 0.1058 0.1303 0.0853 0.0923 0.0945 1 1.3 0.3847 0.4156 0.2223 0.2134 0.2265 0.3176 0.4133 0.1813 0.2054 0.2178 1 1.5 0.7163 0.7053 0.4427 0.3852 0.4065 0.5838 0.6984 0.3393 0.3773 0.3977 1.1 1.1 0.1141 0.1320 0.0921 0.1072 0.1008 0.1058 0.1300 0.0896 0.1021 0.0982 1.1 1.2 0.2299 0.2669 0.1516 0.1587 0.1593 0.1981 0.2666 0.1295 0.1506 0.1500 1.1 1.4 0.5624 0.5934 0.3293 0.3008 0.3112 0.4528 0.5837 0.2573 0.2843 0.3002 1.1 1.6 0.8354 0.8317 0.5688 0.4853 0.4950 0.6968 0.8173 0.4426 0.4733 0.5069 1.2 1.2 0.2299 0.2605 0.1633 0.1643 0.1548 0.1981 0.2614 0.1399 0.1606 0.1491 1.2 1.3 0.3847 0.4218 0.2395 0.2300 0.2267 0.3176 0.4210 0.1947 0.2214 0.2185 1.2 1.5 0.7163 0.7454 0.4509 0.3995 0.4108 0.5838 0.7430 0.3480 0.3884 0.3982 1.2 1.7 0.9154 0.9131 0.6842 0.5871 0.5884 0.7843 0.8993 0.5388 0.5750 0.5834 1.5 1.5 0.7163 0.7015 0.5080 0.4521 0.4094 0.5838 0.6977 0.3927 0.4426 0.3979 1.5 1.6 0.8354 0.8312 0.6128 0.5333 0.5036 0.6969 0.8206 0.4757 0.5210 0.4913 1.5 1.8 0.9585 0.9596 0.7902 0.6921 0.6862 0.8521 0.9444 0.6416 0.6810 0.6809 1.5 2 0.9929 0.9929 0.9097 0.8222 0.8289 0.9304 0.9828 0.7758 0.8049 0.8161
* ad-s: Adichie parametric method, ad-r: Adichie nonparametric method
* ssW: Sequential slope Williams’ ¯ t-test, ssW-r: Sequential slope Williams’ t-test
* ssJ: Sequential slope Jonckheere
ᄋ
ᅮ 비모수 방법들의 검정력이 좋았는데, ad-r의 검정력이 가장 높았고 다음으로 ssW-r과 ssJ가 비슷한 ᄉ
ᅮ준으로 나타났다. 직선 4개, 표본 10개인 경우에도 직선 3개일 때와 마찬가지로 ad-r가 가장 높았고, ssJ, ssW-r, ad-s, ssW 순으로 검정력이 높게 나타났다.
ᄋ
ᅵ중지수분포에서는 직선 3개, 표본 5개일 때는대체로 ad-s의 검정력이 가장 높았고 두번째 세번째 지
ᆨ선의 기울기가 같은경우 ssW의 검정력이 가장 높았다. ad-r과 ssJ의 검정력은거의 비슷한 가운데 ad-r이근소하게 높았고 ssW-r의 검정력이 가장 낮게 나타났다. 직선 4개, 표본 5개일 때는같은기울 ᄀ
ᅵ의 직선이 3개가 있을경우 ssW의 검정력이 제일 높았고, 기울기의 차이가 작을때는 ad-r,기울기의 ᄎ
ᅡ이가 클때는 ad-s의 검정력이 제일 높았다. 직선 3개, 표본 10개일 때는 ad-r의 검정력이 가장 높았 ᄀ
ᅩ, ad-s도 그와 비슷한 수준이었다. 그 다음으로는 ssW가 높았고, ssW-r과 ssJ는비슷한 수준이었는 ᄃ
ᅦ 첫번째 직선과 두번째 직선 기울기의 차이가 커질수록 ssW-r의 검정력이 높아졌다. 직선 4개, 표본 10개일 때도 ad-r과 ad-s의 검정력은비슷한 수준으로 나타났는데 첫번째 직선과 두번째 직선의 기울기
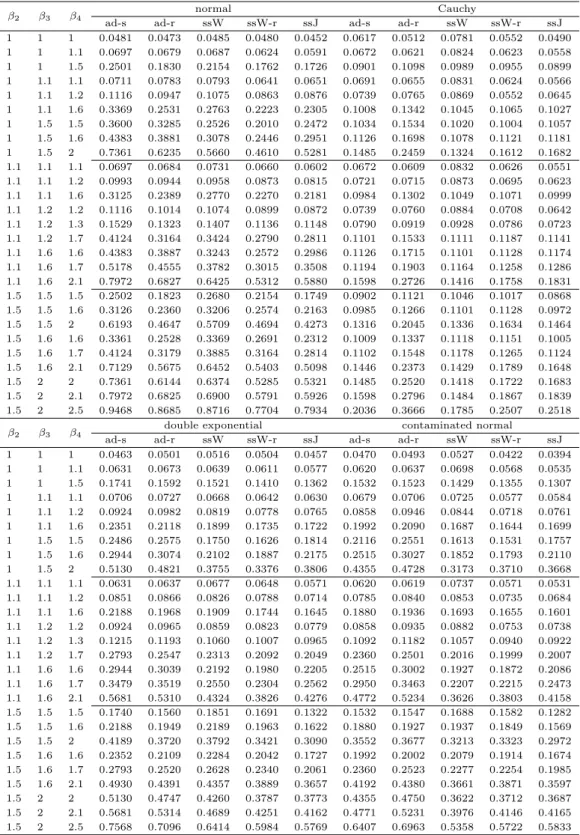
Table 3.3 Monte Carlo power estimates : α = 0.05, k = 4, n = 5 β
2β
3β
4normal Cauchy
ad-s ad-r ssW ssW-r ssJ ad-s ad-r ssW ssW-r ssJ
1 1 1 0.0481 0.0473 0.0485 0.0480 0.0452 0.0617 0.0512 0.0781 0.0552 0.0490 1 1 1.1 0.0697 0.0679 0.0687 0.0624 0.0591 0.0672 0.0621 0.0824 0.0623 0.0558 1 1 1.5 0.2501 0.1830 0.2154 0.1762 0.1726 0.0901 0.1098 0.0989 0.0955 0.0899 1 1.1 1.1 0.0711 0.0783 0.0793 0.0641 0.0651 0.0691 0.0655 0.0831 0.0624 0.0566 1 1.1 1.2 0.1116 0.0947 0.1075 0.0863 0.0876 0.0739 0.0765 0.0869 0.0552 0.0645 1 1.1 1.6 0.3369 0.2531 0.2763 0.2223 0.2305 0.1008 0.1342 0.1045 0.1065 0.1027 1 1.5 1.5 0.3600 0.3285 0.2526 0.2010 0.2472 0.1034 0.1534 0.1020 0.1004 0.1057 1 1.5 1.6 0.4383 0.3881 0.3078 0.2446 0.2951 0.1126 0.1698 0.1078 0.1121 0.1181 1 1.5 2 0.7361 0.6235 0.5660 0.4610 0.5281 0.1485 0.2459 0.1324 0.1612 0.1682 1.1 1.1 1.1 0.0697 0.0684 0.0731 0.0660 0.0602 0.0672 0.0609 0.0832 0.0626 0.0551 1.1 1.1 1.2 0.0993 0.0944 0.0958 0.0873 0.0815 0.0721 0.0715 0.0873 0.0695 0.0623 1.1 1.1 1.6 0.3125 0.2389 0.2770 0.2270 0.2181 0.0984 0.1302 0.1049 0.1071 0.0999 1.1 1.2 1.2 0.1116 0.1014 0.1074 0.0899 0.0872 0.0739 0.0760 0.0884 0.0708 0.0642 1.1 1.2 1.3 0.1529 0.1323 0.1407 0.1136 0.1148 0.0790 0.0919 0.0928 0.0786 0.0723 1.1 1.2 1.7 0.4124 0.3164 0.3424 0.2790 0.2811 0.1101 0.1533 0.1111 0.1187 0.1141 1.1 1.6 1.6 0.4383 0.3887 0.3243 0.2572 0.2986 0.1126 0.1715 0.1101 0.1128 0.1174 1.1 1.6 1.7 0.5178 0.4555 0.3782 0.3015 0.3508 0.1194 0.1903 0.1164 0.1258 0.1286 1.1 1.6 2.1 0.7972 0.6827 0.6425 0.5312 0.5880 0.1598 0.2726 0.1416 0.1758 0.1831 1.5 1.5 1.5 0.2502 0.1823 0.2680 0.2154 0.1749 0.0902 0.1121 0.1046 0.1017 0.0868 1.5 1.5 1.6 0.3126 0.2360 0.3206 0.2574 0.2163 0.0985 0.1266 0.1101 0.1128 0.0972 1.5 1.5 2 0.6193 0.4647 0.5709 0.4694 0.4273 0.1316 0.2045 0.1336 0.1634 0.1464 1.5 1.6 1.6 0.3361 0.2528 0.3369 0.2691 0.2312 0.1009 0.1337 0.1118 0.1151 0.1005 1.5 1.6 1.7 0.4124 0.3179 0.3885 0.3164 0.2814 0.1102 0.1548 0.1178 0.1265 0.1124 1.5 1.6 2.1 0.7129 0.5675 0.6452 0.5403 0.5098 0.1446 0.2373 0.1429 0.1789 0.1648 1.5 2 2 0.7361 0.6144 0.6374 0.5285 0.5321 0.1485 0.2520 0.1418 0.1722 0.1683 1.5 2 2.1 0.7972 0.6825 0.6900 0.5791 0.5926 0.1598 0.2796 0.1484 0.1867 0.1839 1.5 2 2.5 0.9468 0.8685 0.8716 0.7704 0.7934 0.2036 0.3666 0.1785 0.2507 0.2518
β
2β
3β
4double exponential contaminated normal
ad-s ad-r ssW ssW-r ssJ ad-s ad-r ssW ssW-r ssJ
1 1 1 0.0463 0.0501 0.0516 0.0504 0.0457 0.0470 0.0493 0.0527 0.0422 0.0394 1 1 1.1 0.0631 0.0673 0.0639 0.0611 0.0577 0.0620 0.0637 0.0698 0.0568 0.0535 1 1 1.5 0.1741 0.1592 0.1521 0.1410 0.1362 0.1532 0.1523 0.1429 0.1355 0.1307 1 1.1 1.1 0.0706 0.0727 0.0668 0.0642 0.0630 0.0679 0.0706 0.0725 0.0577 0.0584 1 1.1 1.2 0.0924 0.0982 0.0819 0.0778 0.0765 0.0858 0.0946 0.0844 0.0718 0.0761 1 1.1 1.6 0.2351 0.2118 0.1899 0.1735 0.1722 0.1992 0.2090 0.1687 0.1644 0.1699 1 1.5 1.5 0.2486 0.2575 0.1750 0.1626 0.1814 0.2116 0.2551 0.1613 0.1531 0.1757 1 1.5 1.6 0.2944 0.3074 0.2102 0.1887 0.2175 0.2515 0.3027 0.1852 0.1793 0.2110 1 1.5 2 0.5130 0.4821 0.3755 0.3376 0.3806 0.4355 0.4728 0.3173 0.3710 0.3668 1.1 1.1 1.1 0.0631 0.0637 0.0677 0.0648 0.0571 0.0620 0.0619 0.0737 0.0571 0.0531 1.1 1.1 1.2 0.0851 0.0866 0.0826 0.0788 0.0714 0.0785 0.0840 0.0853 0.0735 0.0684 1.1 1.1 1.6 0.2188 0.1968 0.1909 0.1744 0.1645 0.1880 0.1936 0.1693 0.1655 0.1601 1.1 1.2 1.2 0.0924 0.0965 0.0859 0.0823 0.0779 0.0858 0.0935 0.0882 0.0753 0.0738 1.1 1.2 1.3 0.1215 0.1193 0.1060 0.1007 0.0965 0.1092 0.1182 0.1057 0.0940 0.0922 1.1 1.2 1.7 0.2793 0.2547 0.2313 0.2092 0.2049 0.2360 0.2501 0.2016 0.1999 0.2007 1.1 1.6 1.6 0.2944 0.3039 0.2192 0.1980 0.2205 0.2515 0.3002 0.1927 0.1872 0.2086 1.1 1.6 1.7 0.3479 0.3519 0.2550 0.2304 0.2562 0.2950 0.3463 0.2207 0.2215 0.2473 1.1 1.6 2.1 0.5681 0.5310 0.4324 0.3826 0.4276 0.4772 0.5234 0.3626 0.3803 0.4158 1.5 1.5 1.5 0.1740 0.1560 0.1851 0.1691 0.1322 0.1532 0.1547 0.1688 0.1582 0.1282 1.5 1.5 1.6 0.2188 0.1949 0.2189 0.1963 0.1622 0.1880 0.1927 0.1937 0.1849 0.1569 1.5 1.5 2 0.4189 0.3720 0.3792 0.3421 0.3090 0.3552 0.3677 0.3213 0.3323 0.2972 1.5 1.6 1.6 0.2352 0.2109 0.2284 0.2042 0.1727 0.1992 0.2002 0.2079 0.1914 0.1674 1.5 1.6 1.7 0.2793 0.2520 0.2628 0.2340 0.2061 0.2360 0.2523 0.2277 0.2254 0.1985 1.5 1.6 2.1 0.4930 0.4391 0.4357 0.3889 0.3657 0.4192 0.4380 0.3661 0.3871 0.3597 1.5 2 2 0.5130 0.4747 0.4260 0.3787 0.3773 0.4355 0.4750 0.3622 0.3712 0.3687 1.5 2 2.1 0.5681 0.5314 0.4689 0.4251 0.4162 0.4771 0.5231 0.3976 0.4146 0.4165 1.5 2 2.5 0.7568 0.7096 0.6414 0.5984 0.5769 0.6407 0.6963 0.5358 0.5722 0.5833
* ad-s: Adichie parametric method, ad-r: Adichie nonparametric method
* ssW: Sequential slope Williams’ ¯ t-test, ssW-r: Sequential slope Williams’ t-test
* ssJ: Sequential slope Jonckheere
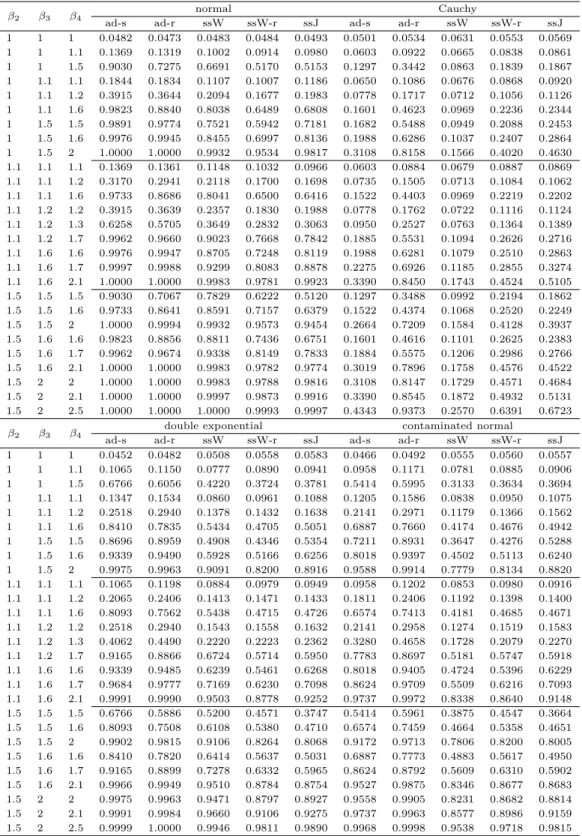
Table 3.4 Monte Carlo power estimates : α = 0.05, k = 4, n = 10 β
2β
3β
4normal Cauchy
ad-s ad-r ssW ssW-r ssJ ad-s ad-r ssW ssW-r ssJ
1 1 1 0.0482 0.0473 0.0483 0.0484 0.0493 0.0501 0.0534 0.0631 0.0553 0.0569 1 1 1.1 0.1369 0.1319 0.1002 0.0914 0.0980 0.0603 0.0922 0.0665 0.0838 0.0861 1 1 1.5 0.9030 0.7275 0.6691 0.5170 0.5153 0.1297 0.3442 0.0863 0.1839 0.1867 1 1.1 1.1 0.1844 0.1834 0.1107 0.1007 0.1186 0.0650 0.1086 0.0676 0.0868 0.0920 1 1.1 1.2 0.3915 0.3644 0.2094 0.1677 0.1983 0.0778 0.1717 0.0712 0.1056 0.1126 1 1.1 1.6 0.9823 0.8840 0.8038 0.6489 0.6808 0.1601 0.4623 0.0969 0.2236 0.2344 1 1.5 1.5 0.9891 0.9774 0.7521 0.5942 0.7181 0.1682 0.5488 0.0949 0.2088 0.2453 1 1.5 1.6 0.9976 0.9945 0.8455 0.6997 0.8136 0.1988 0.6286 0.1037 0.2407 0.2864 1 1.5 2 1.0000 1.0000 0.9932 0.9534 0.9817 0.3108 0.8158 0.1566 0.4020 0.4630 1.1 1.1 1.1 0.1369 0.1361 0.1148 0.1032 0.0966 0.0603 0.0884 0.0679 0.0887 0.0869 1.1 1.1 1.2 0.3170 0.2941 0.2118 0.1700 0.1698 0.0735 0.1505 0.0713 0.1084 0.1062 1.1 1.1 1.6 0.9733 0.8686 0.8041 0.6500 0.6416 0.1522 0.4403 0.0969 0.2219 0.2202 1.1 1.2 1.2 0.3915 0.3639 0.2357 0.1830 0.1988 0.0778 0.1762 0.0722 0.1116 0.1124 1.1 1.2 1.3 0.6258 0.5705 0.3649 0.2832 0.3063 0.0950 0.2527 0.0763 0.1364 0.1389 1.1 1.2 1.7 0.9962 0.9660 0.9023 0.7668 0.7842 0.1885 0.5531 0.1094 0.2626 0.2716 1.1 1.6 1.6 0.9976 0.9947 0.8705 0.7248 0.8119 0.1988 0.6281 0.1079 0.2510 0.2863 1.1 1.6 1.7 0.9997 0.9988 0.9299 0.8083 0.8878 0.2275 0.6926 0.1185 0.2855 0.3274 1.1 1.6 2.1 1.0000 1.0000 0.9983 0.9781 0.9923 0.3390 0.8450 0.1743 0.4524 0.5105 1.5 1.5 1.5 0.9030 0.7067 0.7829 0.6222 0.5120 0.1297 0.3488 0.0992 0.2194 0.1862 1.5 1.5 1.6 0.9733 0.8641 0.8591 0.7157 0.6379 0.1522 0.4374 0.1068 0.2520 0.2249 1.5 1.5 2 1.0000 0.9994 0.9932 0.9573 0.9454 0.2664 0.7209 0.1584 0.4128 0.3937 1.5 1.6 1.6 0.9823 0.8856 0.8811 0.7436 0.6751 0.1601 0.4616 0.1101 0.2625 0.2383 1.5 1.6 1.7 0.9962 0.9674 0.9338 0.8149 0.7833 0.1884 0.5575 0.1206 0.2986 0.2766 1.5 1.6 2.1 1.0000 1.0000 0.9983 0.9782 0.9774 0.3019 0.7896 0.1758 0.4576 0.4522 1.5 2 2 1.0000 1.0000 0.9983 0.9788 0.9816 0.3108 0.8147 0.1729 0.4571 0.4684 1.5 2 2.1 1.0000 1.0000 0.9997 0.9873 0.9916 0.3390 0.8545 0.1872 0.4932 0.5131 1.5 2 2.5 1.0000 1.0000 1.0000 0.9993 0.9997 0.4343 0.9373 0.2570 0.6391 0.6723
β
2β
3β
4double exponential contaminated normal
ad-s ad-r ssW ssW-r ssJ ad-s ad-r ssW ssW-r ssJ
1 1 1 0.0452 0.0482 0.0508 0.0558 0.0583 0.0466 0.0492 0.0555 0.0560 0.0557 1 1 1.1 0.1065 0.1150 0.0777 0.0890 0.0941 0.0958 0.1171 0.0781 0.0885 0.0906 1 1 1.5 0.6766 0.6056 0.4220 0.3724 0.3781 0.5414 0.5995 0.3133 0.3634 0.3694 1 1.1 1.1 0.1347 0.1534 0.0860 0.0961 0.1088 0.1205 0.1586 0.0838 0.0950 0.1075 1 1.1 1.2 0.2518 0.2940 0.1378 0.1432 0.1638 0.2141 0.2971 0.1179 0.1366 0.1562 1 1.1 1.6 0.8410 0.7835 0.5434 0.4705 0.5051 0.6887 0.7660 0.4174 0.4676 0.4942 1 1.5 1.5 0.8696 0.8959 0.4908 0.4346 0.5354 0.7211 0.8931 0.3647 0.4276 0.5288 1 1.5 1.6 0.9339 0.9490 0.5928 0.5166 0.6256 0.8018 0.9397 0.4502 0.5113 0.6240 1 1.5 2 0.9975 0.9963 0.9091 0.8200 0.8916 0.9588 0.9914 0.7779 0.8134 0.8820 1.1 1.1 1.1 0.1065 0.1198 0.0884 0.0979 0.0949 0.0958 0.1202 0.0853 0.0980 0.0916 1.1 1.1 1.2 0.2065 0.2406 0.1413 0.1471 0.1433 0.1811 0.2406 0.1192 0.1398 0.1400 1.1 1.1 1.6 0.8093 0.7562 0.5438 0.4715 0.4726 0.6574 0.7413 0.4181 0.4685 0.4671 1.1 1.2 1.2 0.2518 0.2940 0.1543 0.1558 0.1632 0.2141 0.2958 0.1274 0.1519 0.1583 1.1 1.2 1.3 0.4062 0.4490 0.2220 0.2223 0.2362 0.3280 0.4658 0.1728 0.2079 0.2270 1.1 1.2 1.7 0.9165 0.8866 0.6724 0.5714 0.5950 0.7783 0.8697 0.5181 0.5747 0.5918 1.1 1.6 1.6 0.9339 0.9485 0.6239 0.5461 0.6268 0.8018 0.9405 0.4724 0.5396 0.6229 1.1 1.6 1.7 0.9684 0.9777 0.7169 0.6230 0.7098 0.8624 0.9709 0.5509 0.6216 0.7093 1.1 1.6 2.1 0.9991 0.9990 0.9503 0.8778 0.9252 0.9737 0.9972 0.8338 0.8640 0.9148 1.5 1.5 1.5 0.6766 0.5886 0.5200 0.4571 0.3747 0.5414 0.5961 0.3875 0.4547 0.3664 1.5 1.5 1.6 0.8093 0.7508 0.6108 0.5380 0.4710 0.6574 0.7459 0.4664 0.5358 0.4651 1.5 1.5 2 0.9902 0.9815 0.9106 0.8264 0.8068 0.9172 0.9713 0.7806 0.8200 0.8005 1.5 1.6 1.6 0.8410 0.7820 0.6414 0.5637 0.5031 0.6887 0.7773 0.4883 0.5617 0.4950 1.5 1.6 1.7 0.9165 0.8899 0.7278 0.6332 0.5965 0.8624 0.8792 0.5609 0.6310 0.5902 1.5 1.6 2.1 0.9966 0.9949 0.9510 0.8784 0.8754 0.9527 0.9875 0.8346 0.8677 0.8683 1.5 2 2 0.9975 0.9963 0.9471 0.8797 0.8927 0.9558 0.9905 0.8231 0.8682 0.8814 1.5 2 2.1 0.9991 0.9984 0.9660 0.9106 0.9275 0.9737 0.9963 0.8577 0.8986 0.9159 1.5 2 2.5 0.9999 1.0000 0.9946 0.9811 0.9890 0.9968 0.9998 0.9538 0.9718 0.9815
* ad-s: Adichie parametric method, ad-r: Adichie nonparametric method
* ssW: Sequential slope Williams’ ¯ t-test, ssW-r: Sequential slope Williams’ t-test
* ssJ: Sequential slope Jonckheere
ᄋ
ᅴ 차이가 크거나 네번째 직선의 기울기 값이 클때는 ad-s의 검정력이 가장 높았다. 그 다음 ssW의 검 저
ᆼ력이 세번째로 좋았고, ssJ, ssW-r의 순이었다.
ᄋ
ᅩ염된 정규분포에서 직선 3개, 표본 5개일 때는두번째 직선과 세번째 직선의 기울기가 같거나 기울 ᄀ
ᅵ의 차이가 작을때 ssW, ad-s, ad-r, ssJ, ssW-r 순으로 검정력이 높았는데, 기울기의 차이가 차이가 ᄏ
ᅥ지면 ad-s, ad-r, ssW, ssJ, ssW-r 순으로 나타났다. 그러나 방법별로 검정력에큰 차이를보이지는 ᄋ
ᅡ
ᆭ았다. 직선 4개, 표본 5개일 때는 첫번째를제외한 직선들의 기울기가 비슷할 때에 ssW, ad-r, ad-s, ssW-r과 ssJ 순으로 검정력이 높았고, 그 외의 경우에는대부분 ad-r, ad-s, ssW과 ssJ 순으로 검정력 ᄋ
ᅵ 제일 높았다. ssW-r과 ssJ의 검정력은거의 비슷한 수준으로, 두번째 세번째 직선의 기울기 차이가 ᄌ
ᅡ
ᆨ을때는 ssW-r의 검정력이, 차이가 클때는 ssJ의 검정력이근소하게 높았다. 직선 3개, 표본 10개일 ᄄ
ᅢ는 ad-r, ad-s, ssW-r과 ssJ 그리고 ssW의 순으로 검정력이 높았는데, ssW-r과 ssJ는비슷한 수준으 ᄅ
ᅩ 두번째 직선과 세번째 직선의 기울기 차이가 작을수록 ssW-r이 높고, 차이가 클수록 ssJ가 높게 나타 ᄂ
ᅡ
ᆻ다. 직선 4개, 표본 10개일 때도 마찬가지로 ad-r의 검정력이 가장 높았고, 대부분 ad-s, ssJ, ssW-r, ssW의 순으로 높게 나타났다.
4. 결론 및 고찰 ᄇ
ᅩᆫ 논문에서는 여러 개의 단순 선형 회귀모형의 순서대립가설에 대하여 순차기울기를 이용한 평 ᄒ
ᅢᆼ성 검정법을 제안하였다. 본 검정법은 각 직선에서 연속된 점들 사이의 순차기울기를 생성하여 Williams의 모수적, 비모수적 검정과 Jonckheere 검정을 실시하는 방법으로 모의실험을 통하여 다 서
ᆺ가지 분포에 대하여 Adichie의 모수적, 비모수적 방법과 검정력을비교하였다.
지
ᆨ선 3개, 표본 5개인 경우 대부분의 분포에서 두번째 직선과 세번째 직선의 기울기가 같거나 기울기 ᄋ
ᅴ 차이가 작을때는 본 논문에서 제안한 모수적 방법의 검정력이 가장 높았고, 기울기의 차이가 클 때 느
ᆫ Adichie 모수적 방법의 검정력이 가장 높았으나, 모든 방법의 검정력 차이가 크지는 않았다. 직선 3개, 표본 10개인 경우 정규분포에서는 Adichie모수적 방법, 나머지 분포에서는 Adichie비모수적 방 버
ᆸ의 검정력이 가장 높았으나 기울기의 차이가 클 때는 제안한 방법들과 기존방법들의 검정력이 비슷 ᄒ
ᅡᆫ 수준으로 높게 나타나는경우들이 많았다. 직선 4개, 표본 5개인 경우 기존방법들과 제안방법들의 거
ᆷ정력이큰차이를보이지는않았지만 대부분의 분포에서 첫번째 직선을제외한 직선들의 기울기가 같 ᄋ
ᅳᆯ때는 본 논문에서 제안한 모수적 방법의 검정력이 가장 높았고, 그 외에는 Adichie의 모수적 방법이 ᄂ
ᅡ Adichie의 비모수적 방법의 검정력이 가장 높았다. 직선4개, 표본10개인 경우 Adichie의 모수적 방 버
ᆸ이나 Adichie의 비모수적 방법의 검정력이 가장 높았는데 직선의 기울기에 따라 많은 경우에서 제안 ᄒ
ᅡᆫ 방법과 기존의 방법의 검정력이 비슷하게 나타났다.
ᄋ
ᅧ러 개의 단순선형회귀모형에서 순서대립가설에 대한 평행성 검정에 사용할 수 있는 기존의 검정법 ᄋ
ᅵ 적었다는것을생각해 볼때 본 논문에서 제시한 검정 방법이 도움이될 것이라고 생각한다. 많은경 ᄋ
ᅮ 본 논문에서 제안한 검정법은기존검정법의 검정력과 비슷한데 비해 계산이 간편한 순차기울기를이 ᄋ
ᅭ
ᆼ하여 기존방법보다 손쉽게 검정할 수 있다. 특히 제안한 모수적 방법은표본이 작고 기울기의 차이도 ᄌ
ᅡ
ᆨ을때 다른검정법들보다 더 효율적이고, 제안한 비모수적 방법들은 Cauchy분포에서 Adichie 모수적 ᄇ
ᅡᆼ법이나 본 논문에서 제안한 모수적 방법보다 효율적이다. 또한, 기존방법에서 독립변수의 위치에 영 ᄒ
ᅣᆼ을받게 되어 절대적인 비교가 불가능하다는단점을보완할 수 있고, 널리 사용되고 있는검정법을회 ᄀ
ᅱ분석의 평행성 분석에확장하였으므로 검증된방법을이용한다는장점도 있다.
ᄃ
ᅡ만 Cauchy분포에서 유의수준의 제어가 어렵고, 검정력이 다소 낮게 나타나는데 이는꼬리가 두터 우
ᆫ 분포에서의 특징이라 보여지고, 자료에 이상치 (outlier)들이 많이 존재하는경우라고 할 수 잇다. 덧 ᄇ
ᅮ
ᇀ여 순차기울기를사용할 때 독립변수가 등간격이어야 한다는제한은 독립변수의 간격이 다를때 적절
ᄒ
ᅡᆫ 가중치를주는방법 등으로 보완해야할 것이다.
References
Adichie, J. N. (1976). Testing parallelism of regression lines against ordered alternatives. Communications in Statistics-Theory and Mathematics, 5, 985-997.
Choi, Y. and Kim, D. (2003). Estimation of slope β using the sequential slope in simple linear regression model. The Korean Communications in Statistics, 10, 257-266.
Jee, E. (2013). A Jonckheere type test for the parallelism of regeression lines. The Pure and Applied Mathematics, 20, 109-116.
Jonckheere, A. R. (1954). A distribution-free k-sample test against ordered alternatives. Biometrika, 41, 133–145.
Kim, J. (1995). A nonparametric test for parallelism of regression lines against ordered alternatives. Duk- sung Women’s University Journal, 24, 245-254.
Kim, J. and Kim, D. (2013). Parallelism test of slope in a several simple linear regression model based on a sequential slope. The Korean Journal of Applied Statistics, 26, 1009-1018.
Lee, J. (2017). Analysis of factors affecting Korean professional baseball pitcher salaries. Journal of the Korean Data & Information Science Society, 28, 317-326.
Lee, K. (1993). A study on a nonparametric test for ordered alternatives in regression problem. The Korean Journal of Applied Statistics, 6, 237-245.
Rao, K. S. M. and Gore, A. P. (1984). Testing concurrence and parallelism of several sample regressions against ordered alternatives. Statistics-A Journal of Theoretical and Applied Statistics, 15, 43-50.
Park, J. and Park, J. (2017). The relationships among interpersonal relationship anxiety, college adjustment, self-control, and smartphone addiction in nursing students. Journal of the Korean Data & Information Science Society, 28, 185-194.
Son, D. (2002). A nonparametric parallelism test in simple regression model based on sequential slope, The Catholic University of Korea, Seoul, Korea.
Song, M., Lee, K. and Kim, S. (1993). A nonparametric test for parallelism of regression lines against ordered alternatives. The Korean Journal of Applied Statistics, 6, 401-408.
Song, M., Huh, M. and Kang, H. (1987). On a distribution-free test for parallelism of regression lines against ordered alternatives. Journal of Korean Society for Quality Control, 2, 50-54.
Williams, D. A. (1972). The comparison of several dose levels with a zero-dose control. Biometrics, 28, 519-531.
Williams, D. A. (1986). A note on Shirley’s nonparametric test for comparing several dose levels with a
zero-dose control. Biometrics, 42, 183-186.
2018, 29
(4)
,873–884
The test of parallelism of k regression lines against ordered alternatives based on a sequential slope
Hyerim Kim
1
· Dongjae Kim2
12Department of Biomedicine · Health Science, The Catholic University of Korea
Received 22 June 2018, revised 13 July 2018, accepted 16 July 2018
Abstract
When comparing regression lines formed in each population, it may be necessary to test the parallelism of k regression lines against ordered alternatives. In this paper, we propose a parallel test using Williams’ (1972) parametric and nonparametric tests and Jonckheere’s (1954) test to calculate the slope of each straight line. The Monte Carlo simulations were performed to compare the power of the three proposed methods with the previous methods proposed by Adichie (1976). As a result, the proposed methods can be relatively easily tested using the sequential slope. In many cases, the power of the proposed method is similar to that of the previous methods. In particular, when the sample size and the slope is small, The power of proposed parametric method was the highest.
Keywords: Ordered alternatives, parallelism test, regression model, sequential slope.
1
Researcher, Department of Biomedicine · Health Science, The Catholic University of Korea, 222, Banpo- daero, Seocho-gu, Seoul 137-701, Korea.
2


![외국인 PCR검사 가능 기관 [Referral Laboratories : 11sites]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)