− 391 −
大 韓 土 木 學 會 論 文 集 第28卷 第3D 號·2008年 5月 pp. 391~397
地域 및 都市計劃
서울대도시권 인구집중의 공간적 연관성 연구
Spatial Association of Population Concentration in Seoul Metropolitan Area
박제인*·장 훈**·김지소***
Park, Jane
·
Chang, Hoon·
Kim, Jy So···
Abstract
This paper analyzes the spatial patterns of population distribution in Seoul Metropolitan Area in terms of spatial association using spatial statistics and spatial exploratory technique. Our empirical analysis based on global index shows that, in Seoul Metropolitan Area, the population had been distributed with strong positive spatial association over the period of 1980-2005. It implies that the population of each region is affected by the population distribution of adjacent regions. In addition, the anal- ysis using local index was conducted for detecting the local patterns of spatial association, and the result shows that the clus- ters of population had been moved in the direction of West(Incheon and Bucheon) and South(Anyang and Seongnam) of Seoul where a large scale of lands or towns were developed over the period. These results will be the preliminary data for estab- lishing management and development plans of Seoul Metropolitan Area.
Keywords :seoul metropolitan area, population, spatial association, Moran's I, Geary's C, LISA
···
요 지
본 논문에서는 공간통계 및 지리적 탐색 기법을 이용하여 공간연관성의 관점에서 서울대도시권 인구분포 변화를 분석하였 다. 전역적 지수를 이용하여 1980년부터 2005년까지 25년간의 인구자료를 분석한 결과, 서울대도시권의 인구는 매우 강한 정적(+) 공간연관성을 나타내며 분포하고 있음이 확인되었다. 이는 각 지역의 인구분포가 주변지역의 인구분포에 영향을 받 았음을 의미한다. 이어서 국지적 지수를 이용하여 실제 어떤 지역에 군집이 형성되고 있는지 분석하였으며, 서울시의 남쪽 및 서쪽, 즉 인천 및 경기지역으로 군집이 이동하고 있음이 확인되었다. 분석 결과는 향후 서울대도시권 관리 및 개발계획 수립의 기초자료로 활용될 수 있을 것이다.
핵심용어
:서울대도시권, 인구, 공간연관성, Moran's I, Geary's C, 국지적 공간연관성 지수
···
1.
서 론
1.1
연구의 배경 및 목적
서울대도시권은 서울시를 중심으로 거대 도시권이 형성된 지 역인 동시에 1980년대 이래 본격화된 정부의 인구분산정책으 로 역동적인 인구변화를 경험하고 있는 지역이다. 통계청에 따 르면 서울시의 인구는 1980년대부터 성장이 둔화되다가 1990 년에 접어들면서 감소추세로 돌아선 반면, 인천 및 경기지역 인구는 지속적으로 증가추세를 보이고 있다. 이 기간 동안 인 천 및 경기지역에서 신도시 건설과 같은 대단위 개발이 활발 히 진행되어 왔음을 고려할 때 서울대도시권 인구는 분포패턴 에 있어서도 역동적인 변화양상을 보였을 것으로 생각된다.
이러한 인구분포의 변화는 분석에 있어서 새로운 방식을 요구하고 있다. 도시의 영향력이란 한 도시에만 국한되어 있 는 것이 아니고 주변지역과 밀접한 연관을 맺고 있는 것이
므로 인구분포패턴을 분석함에 있어서도 공간상에서 나타나 는 공간연관성을 고려해야 하는 것이다.
공간연관성(Spatial Association)이란 지리적 근접에 따른 상호간 영향을 의미하는 것으로, 사람이나 사물이 공간적 질 서를 따라 분포하면 이들 간에 공간연관성이 존재한다고 정 의된다(Anselin, 1988). 이처럼 공간적 속성을 지닌 자료를 선형분석기법으로 분석할 경우 관측 개체 및 오류항의 ‘독립 성 가정’에 위배되어 잘못된 통계적 추론에 도달할 수 있다
(Griffith, 1996).
공간연관성을 고려한 공간분석기법은 이러
한 한계를 넘어 인구분포의 공간적 패턴 및 상호영향력에 대하여 보다 정확한 분석과 추정을 가능하게 한다. 따라서 공간연관성의 탐색과 검증은 어떤 통계분석보다 선행되어야 할 과제이다(김광구, 2003).
이러한 배경에서 본 연구는 서울대도시권 인구분포를 공간 연관성 관점에서 파악하는데 그 목적을 두고 있으며, 이를
*정회원·연세대학교도시공학과석사과정 (E-mail : [email protected])
**정회원·교신저자·연세대학교 도시공학과 조교수·도시계획학박사 (E-mail : [email protected])
***연세대학교도시공학과석박사통합과정 (E-mail : [email protected])
위하여 다음과 같은 두 가지 연구 질문을 설정하고 그에 대 한 답을 찾고자 한다.
-
서울대도시권 인구분포에서 공간연관성이 나타나는가? 시 간의 경과에 따라 어떠한 변화가 나타나는가?
-
실제 인구가 집중하고 있는 지역은 어디이며, 시간의 경 과에 따라 어떠한 변화가 나타나는가?
본 연구는 서울대도시권에 분포하고 있는 인구의 공간적 집중 정도와 실제 집중이 발생하는 지역을 파악함으로써 서 울대도시권 관리 및 개발계획 수립을 뒷받침하는 자료로 활 용될 수 있을 것이다.
1.2
연구의 범위 및 방법
본 연구의 공간적 범위는 서울시와 인천시(옹진군 제외), 그리고 경기도 전역을 포함하는 서울대도시권이다. 분석의 공간적 단위는 시군구로 설정하였다.
한편 연구의 시간적 범위는 1980년부터 2005년까지의 25 년이며, 분석의 시간적 단위는 5년으로 설정하였다.
본 연구는 크게 두 단계로 이루어진다. 첫 번째는 통계자 료를 수집하여 분석목적에 맞게 가공하는 단계이다. 25년간 진행된 행정구역 변화를 확인하고 분석단위를 2005년 기준 으로 일치시켰으며, 분석단위별 인구밀도를 산출하여 Shape 형식의 전자행정구역도와 연계시키는 작업을 수행하였다. 두 번째는 서울대도시권 인구분포의 공간연관성을 탐색하는 단 계로서 이 과정에서는 공간통계모형이 적용되었다.
2.
선행연구 검토
인구밀도는 도시 및 지역과학을 비롯한 다양한 분야의 연 구에서 중요시 되어온 변수이다. 수학함수를 이용하여 인구 밀도를 모델링하는 기존의 기법은 유용함에 틀림없으나 2차 원적 분석의 틀에 얽매어 인구분포의 국지적 구조나 공간연 관성을 반영하지 못하는 한계를 지닌다.
공간연관성의 관점에서 인구밀도를 모델링하는 것은
Anselin
과 Can(1986)에 의해 제시된 개념으로서 Anselin은
뒤이은 1995년 국지적 공간연관성 지수와 같은 확장된 개념 을 제안하여 전역적 분석에서 포착되지 않는 국지적 규모의 공간적 현상까지 정량화할 수 있게 하였다.
Tsai(2005)
는 도시공간구조의 정량화에 대한 논문에서 몇
가지 지수들을 비교분석하였다. 그리고 다양한 연구에서 유 용하게 사용되어온 지니계수 역시 인구의 공간적 집중과 관 련한 실제적 현상을 나타내지 못한다는 한계를 지적하며, 이 러한 한계를 극복할 수 있는 방법으로 공간통계기법인
Moran's I
및 Geary's C 지수의 유용성을 강조하였다.
한편 국내에서는 김의준과 변태근(2003)이 공간연관성의 개념을 기반으로 영남지역 인구자료를 분석하였다. 그러나 이 연구는 전역적 지수를 이용해 공간연관성의 존재여부를 확인하고 공간상호작용 분석에 더욱 초점을 맞춘 연구로서 인구분포패턴이나 그 영향을 정량화하는 연구와는 차이가 있 다. 이밖에 공간연관성의 개념을 적용시킨 국내 선행연구들 은 주택가격이나 고용과 관련된 연구가 대부분이다. 반면 인 구의 분포와 관련된 연구에서는 여전히 행정구역별 인구증 가율이나 인구밀도가 널리 활용되고 있다. 이러한 변수의 시
각화도 인구분포의 공간적 특성을 파악하는 하나의 방법이 지만 통계적 유의성을 검정하는 방법적 절차가 마련되어 있 지 않아 인구현상의 공간연관성에 대한 통계적 증거가 되지 못한다. 더불어 공간 상호작용을 설명하지 못한다는 사실도 단순한 변수의 시각화 기법이 지니는 한계이다.
3.
분석모형
3.1
공간가중치행렬
공간연관성을 정량적으로 분석하기 위해서는 우선 분석단 위들 간 공간적 관계를 정의하고 이를 정량화한 공간가중치 행렬(Spatial Weight Matrix, 이하 W)을 작성해야 한다. W 는 지리적 경계, 폴리곤 중심 간 거리 등 다양한 기준에 의 해 정의될 수 있으나(Lee and Wong, 2001), 그 표준은 아 직 제시된 바 없고, 적용된 W에 따라서 상이한 결론을 도 출이 도출되는 것으로 알려져 있다(박기호, 2004).
대부분의 선행연구에서는 분석단위들 간의 경계선 공유여 부만을 고려한 이진연결성행렬(Binary Connectivity Matrix) 이 여과 없이 사용되어 왔다. 그러나 본 연구에서 다루고자 하는 인구의 집중은 인구의 이동으로부터 기인하는 현상이기 때문에 공간가중치행렬을 설정함에 있어서 지역 간 상호작용 의 정도를 반영하는 것이 타당하다. 이에 따라 본 연구에서는 분석단위들의 지리적 중심 간 거리 기준으로 공간가중치행렬 을 작성하고 분석에 적용시켰다. 이 경우 분석단위 i와 또 다 른 분석단위 j의 중심 간의 거리가 기준거리보다 짧으면 i행
j열의 값이 1로, 그렇지 않으면 0으로 설정된다(식 (1)).
여기서 d
ij는 분석단위 i와 j 간 중심거리, δ는 기준거리를 의미하며, 본 연구에서 기준거리는 지역 간 중심거리의 평균 인 33.713km로 하였다. 또한 식 (1)을 통해 이웃으로 정의 된 분석단위들이 나타내는 상대적 영향력을 반영하기 위하 여 횡단 표준화(Row-standardization) 작업을 수행하였으며, 이와 같은 과정을 거쳐 분석에 사용할 공간가중치행렬을 도 출하였다(Lee and Wong, 2001).
3.2
전역적 공간연관성 지수
공간연관성은 주변지역과의 유사성에 기초하여 분석되며, 전역적 지수를 사용하는 경우 연구범위 전역의 공간연관성 이 하나의 값으로 산출된다. 본 연구에서는 공간연관성의 존 재 여부를 통계적으로 파악하기 위하여 Moran's I 및
Geary's C
지수를 사용하였다.
3.2.1 Moran's I Index
Moran's I
는 공분산 개념에 기초하여 속성 값 사이의 유
사성을 측정하는데 사용되며, 다음의 식 (2)를 통해 산출된 다(Moran, 1948).
Wij 1 dij
≤ δ
0
그렇지 않은 경우
⎝ ⎜
=
⎛
I n
Wij
j=1
∑
n i=1∑
n---
Wij
j=1
∑
n i=1n
∑ (
xi–x) x (
j–x)
xi–x
( )
2i=1
∑
n---
×
=
− 393 − 이 식에서, n은 분석단위의 수, x
i와 x
j는 분석단위 i와 또 다른 분석단위 j의 인구밀도, x는 전체 연구범위에서 각각의 분석단위가 갖는 인구밀도의 평균이며, W
ij는 공간가중치행 렬을 의미한다.
산출된 Moran's I 지수의 의미를 정리하면 다음의 표 1과 같다(Lee and Wong, 2001).
3.2.2 Geary's C Ratio
Moran's I Index
는 공분산의 개념에 기초한 공간연관성
지수인 반면, Geary's C Ratio는 분산의 개념을 기초로 하 는 지수이다. 따라서 Geary's C는 공간가중치행렬에 의해 이웃으로 정의된 분석단위들이 얼마나 유사한 속성값을 갖 는지를 직접적으로 비교하는 척도가 되며, 다음의 식 (3)를 통해 산출된다(Geary, 1954).
(3)
여기에서, 각 기호의 의미는 Moran's I에서의 경우와 동일하 며, 산출된 Geary's C 지수는 표 2와 같이 해석된다(Lee
and Wong, 2001).3.3
국지적 공간연관성 지수
앞 절에서 언급한 바와 같이 전역적 공간연관성 지수를 이용한 분석만으로는 분석단위들의 공간연관성에 관한 국지 적 구조를 파악할 수 없다. 따라서 본 연구에서는 국지적 공간 연관성 지수(LISA: Local Indicators of Spatial
Association)
의 일종인 Local Moran's I(Anselin, 1995)를
통하여 국지적 차원에서 공간연관성을 정량화하였다. Local
Moran's I
는 분석단위들의 z-score에 기초하여 산출된다(식
4).
(4)
산출된 결과값에 따라 분석단위들은 다음의 표와 같은 네 가지 유형으로 분류될 수 있다.
국지적 Moran's I에 의해 도출된 결과 중 통계적으로 유
의한 단위들을 지도화 함으로써(Anselin, 2004) 서울대도시 권에서 실제 인구가 집중하고 있는 지역을 용이하게 판별할 수 있다.
4.
분석결과
4.1
전역적 지수에 의한 결과
본 연구의 첫 번째 단계는 서울대도시권 인구분포에 있어 서 공간연관성의 존재 여부와 시간의 경과에 따른 변화를 판단하는 것이다. 이를 위하여 중심거리행렬(Centroid
distance matrix)
을 기준으로 전역적 공간연관성 지수인
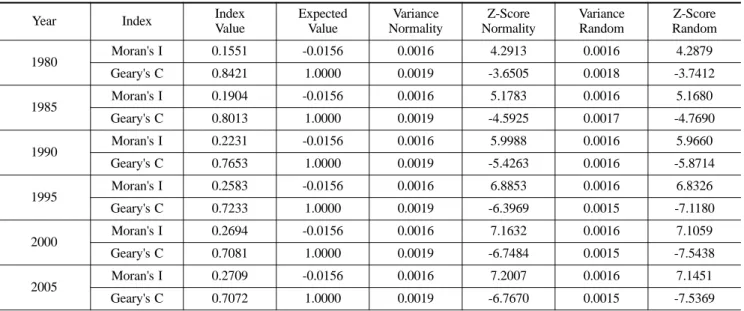
Moran's I 및 Geary's C 값을 산출하였으며 그 결과는 아 래의 표 4 및 그림 1과 같다.
표 4의 결과를 살펴보면 분석기간 동안 Moran's I지수는
0.1551
에서 0.2709의 범위를, Geary's C지수는 0.7072에서
0.8421
의 범위를 기록하고 있다. 또한 각각의 경우 +1.96보
다 크거나 -1.96보다 작은 표준정규점수(Z-score)를 나타내고 있는데 이는 모든 경우가 통계적으로 유의함을 의미한다. 이 와 같은 결과는 상당히 강한 정적(+) 공간연관성을 의미하는 것으로 서울대도시권내의 지역별 인구가 주변지역의 인구와 매우 강한 영향을 주고받으며 분포하고 있음을 입증하는 결 과라 해석할 수 있다.
또한 그림 1에 나타난 바와 같이 시간의 경과에 따른 지 수값의 변화 추이를 살펴보면 변화율은 크지 않으나
Moran's I
는 증가하고 Geary's C는 감소하는 경향을 확인할
수 있다. Moran's I 지수값의 증가는 이웃으로 정의된 지역 들이 모두 평균보다 높거나(High-High) 모두 낮은(Low-
Low)
인구밀도를 갖는 경우가 시간의 경과에 따라 증가함을
의미하며, Geary's C 지수값의 감소는 이웃으로 정의된 지 역들의 인구밀도가 점차 유사해지고 있음을 의미한다. 이 결 과는 서울대도시권에서 인구의 집중이 심화되고 있는 것으 로 해석될 수 있다.
인구집중의 심화는 1995년에서 2005년의 10년에 비해
1980년에서 1995년까지의 15년간 더욱 확연히 나타나고 있 다. 1980년 택지개발촉진법이 제정된 이래 서울대도시권에서 활발하게 진행된 대규모 택지개발사업이 이와 같은 현상의 원인일 것으로 생각되며, 특히 200만호 주택건설계획에 의해
1989년부터 1995년까지 진행된 수도권 5개 신도시의 개발은 인구집중정도의 변화에 지대한 영향을 미쳤을 것으로 판단 된다. 아래의 표 5 및 그림 2는 이러한 분석을 뒷받침하기 위해 제시된 것으로서 1982년부터 2005년까지 서울대도시권 에서 진행된 주택건설실적을 나타내고 있다.
C n 1–
( )
Wijj=1
∑
n i 1=∑
n(
xi–xj)
22 Wij
j 1=
∑
n i 1=n
∑ (
xi–x)
2i=1
∑
n---
=
Ii
(
yi–y)
yi–y( )
2i
∑
--- Wij
j i
∑
≠(
yj–y)
yj–y
( )
2j
∑
---
=
표
1. Moran's I지수의 의미
Moran's I
의 미
I > 0
높은 또는 낮은 속성단위들의 군집
E(I) = 0속성단위들 간 공간연관성 부재
I < 0
높은 또는 낮은 속성단위들의 분산
※ E(I) = (-1)/(n-1)
표
2. Geary's C지수의 의미
Geary's C
의미
0 < C < 1
유사한 속성단위들의 인접
C = 1인접한 속성단위들 간 공간연관성 부재
1 < C < 2상이한 속성단위들의 인접
표
3.국지적 공간연관성의 유형 및 의미
유형 의미
H-H
평균보다 높은 인구밀도의 분석단위가 평균보다 높은 인 구밀도의 분석단위와 인접하고 있는 경우
L-L
평균보다 낮은 인구밀도의 분석단위가 평균보다 낮은 인 구밀도의 분석단위와 인접하고 있는 경우
H-L
평균보다 높은 인구밀도의 분석단위가 평균보다 낮은 인 구밀도의 분석단위와 인접하고 있는 경우
L-H
평균보다 낮은 인구밀도의 분석단위가 평균보다 높은 인
구밀도의 분석단위와 인접하고 있는 경우
표 5와 그림 2에서 보는 바와 같이 수도권에서의 주택건 설실적은 1982년부터 1995년까지 큰 폭으로 증가하는 추세
를 보이고 있고, 특히 경기도에서 급격하게 증가하는 결과를 보이고 있다. 한편 1996년과 2000년 사이에는 국가적 경제 위기로 인해 건설경기 또한 침체를 맞으면서 수도권에서의 주택건설 역시 큰 폭으로 감소한 결과를 보이고 있으며,
1995년과 2000년의 공간연관성 지수가 비교적 큰 변화 없이 유지되는 결과는 이와 같은 사실을 반영한다. 한편 2000년 이후 인천시 및 경기지역에 비해 두드러지게 보이고 있는 서울시 주택건설실적 증가는 대규모 주택재개발 허가에서 기 인하는 것으로 이 기간 동안 서울대도시권의 인구집중정도 가 크게 변하지 않는 것은 이러한 현상에 대한 방증이다.
이상 도출된 결과는 인구집중정도와 더불어 인구집중지역 또 한 변화되었을 것이라는 추측을 가능하게 한다.
이처럼 전역적 지수의 도출을 통하여 서울대도시권 인구분 포의 공간연관성을 확인할 수 있으나 전역적 지수의 분석만 으로는 인구집중지역에 대한 구체적 현상을 파악할 수 없 다. 이에 다음 단계에서는 국지적 변이를 고려한 추가 분석 을 수행하였다.
4.2
국지적 지수에 의한 결과
그림 3은 Local Moran's I 값을 토대로 1980년부터
2005년까지 서울대도시권에서 나타난 인구분포의 공간적 연 관 패턴을 0.05의 유의 수준에서 도식화한 것이다. 결과를 통해 인구밀도가 높은 분석단위들이 집중되어 있는 지역(H-
H)과 낮은 단위들이 집중되어 있는 지역 (L-L), 그리고 인 구밀도가 낮으나 높은 곳들과 이웃하고 있는 지역(L-H)이 명확하게 대조를 이루며 분포하고 있음을 확인할 수 있고, 이는 서울대도시권 인구분포의 강한 공간연관성이 확인된 전 역적 지수의 분석결과와 일치한다.
시간이 경과함에 따른 클러스터별 국지적 변이를 살펴보면 서울시를 중심으로 분포하고 있는 H-H 클러스터의 경우 강 남구와 부천시(1985년), 노원구와 인천시 남구 및 동구(1990 년), 안양시(1995년), 그리고 성남시(2005년) 등 서울시의 남 쪽 또는 서쪽 방향으로 그 범위가 확산되는 현상이 확인된 다. 이들 지역 중 1985년에는 유의하지 않은 범주에 속했던 표
4.서울대도시권 인구밀도의 전역적
Moran's I및
Geary's C지수
(Centroid distance matrix에 따른 결과
)Year Index Index
Value
Expected Value
Variance Normality
Z-Score Normality
Variance Random
Z-Score Random
1980 Moran's I 0.1551 -0.0156 0.0016 4.2913 0.0016 4.2879
Geary's C 0.8421 1.0000 0.0019 -3.6505 0.0018 -3.7412
1985 Moran's I 0.1904 -0.0156 0.0016 5.1783 0.0016 5.1680
Geary's C 0.8013 1.0000 0.0019 -4.5925 0.0017 -4.7690
1990 Moran's I 0.2231 -0.0156 0.0016 5.9988 0.0016 5.9660
Geary's C 0.7653 1.0000 0.0019 -5.4263 0.0016 -5.8714
1995 Moran's I 0.2583 -0.0156 0.0016 6.8853 0.0016 6.8326
Geary's C 0.7233 1.0000 0.0019 -6.3969 0.0015 -7.1180
2000 Moran's I 0.2694 -0.0156 0.0016 7.1632 0.0016 7.1059
Geary's C 0.7081 1.0000 0.0019 -6.7484 0.0015 -7.5438
2005 Moran's I 0.2709 -0.0156 0.0016 7.2007 0.0016 7.1451
Geary's C 0.7072 1.0000 0.0019 -6.7670 0.0015 -7.5369
※ Expected value, Variance, 그리고 Z-score에 대한 설명은 부록을 참조.
그림
1.전역적
Moran's I및
Geary's C의 변화 추이 표
5.수도권 지역별 주택건설실적
(
단위: 호)
‘82-‘85 ‘86-‘90 ‘91-‘95 ‘96-‘00 ‘01-'05
서울
213,264 436,960 511,431 362,637 502,031인천
76,915 163,884 174,763 85,669 178,975경기
163,793 437,331 743,412 680,099 700,547※자료: 건설교통부. 「주택업무편람」
※1982년 이전의 경우 자료의 미비로 미반영
그림
2.수도권 지역별 주택건설실적
− 395 −
1990년의 인천시 남구 및 동구를 제외하면 모두 이전 분석 시점에 L-H 클러스터에 속했던, 즉 인구밀도가 높은 곳에 인접한 지역들이다. 인천시 남구와 동구의 경우 1980년과
1985년에는 인구밀도가 높은 지역(부평구, 중구) 및 낮은 지 역(연수구, 남동구, 서구)과 동시에 인접함으로써 분석결과가 유의하지 않은 것으로 나타났으나 주변지역 인구 밀도의 증 가와 함께 H-H 클러스터에 포함되었다. 또한 H-H 클러스터 외곽으로 분포하고 있는 L-H 클러스터의 경우에는 2000년 과 2005년을 제외하고 평균과 표준편차 모두 증가하는 경향 을 나타냈다(표 6). 이러한 결과로부터 높은 인구밀도의 지 역이 낮은 인구밀도의 주변지역들에 미치는 공간적 영향력
을 생각해볼 수 있다.
한편 L-L 클러스터의 경우 1995년을 기준으로 화성시가 제외된 사실 이외에는 분석기간 동안 별다른 변화 없이 서 울대도시권 외곽을 따라 분포하는 모습을 보였다. 그러나 표
6의 기술통계를 살펴보면 L-L 클러스터의 평균과 표준편차 모두 급격히 증가하는 경향을 확인할 수 있다. 이와 같은 현상은 단순히 분석기간 동안 나타난 서울대도시권 인구의 증가에 기인하는 것으로 해석될 수 있으나 L-L 클러스터 내 에서의 국지적 변이를 보다 상세히 파악하기 위해서는 지역 간 공간적 연계를 고려한 추가분석이 필요하다.
그림
3. Local Moran's I지수에 따른 서울대도시권 인구의 분포패턴
5.
결 론
본 연구에서는 1980년부터 2005까지 25년 동안의 서울대 도시권을 분석대상으로 설정하여 인구분포에 있어서 공간연 관성이 나타나는지 전역적 공간연관성 지수인 Moran's I 및
Geary's C
를 이용하여 분석하였다. 또한 실제 인구의 집중
이 나타나는 지역을 판별하기 위해 국지적 공간연관성 지수 의 일종인 Local Moran's I를 이용한 국지적 분석을 시행 하였다.
그 결과, 서울대도시권의 인구는 매우 강한 정적(+) 공간 연관성을 나타내며 특정 지역에 집중적으로 분포하고 있는 것으로 분석되었다. 또한 1980년부터 1995년까지의 15년간 두 지수 모두 비교적 큰 폭으로 변화하는 결과로부터 이 시 기에 활발히 진행되었던 주택건설사업이 서울대도시권의 인 구집중을 더욱 심화시켰다는 결론을 얻었다.
한편 국지적 규모의 분석 결과, 서울시를 중심으로 H-H 군집이, 그 주위로 L-H 군집이, 그리고 경기도 외곽으로 L-
L군집이 형성된 패턴에 큰 변화가 없었다. 그러나 1980년 에는 인천시 부평구를 제외하고 서울시 내부로 한정되어 있 었던 H-H 군집이 시간의 경과에 따라 인천시 및 경기지역 으로 확산되는 패턴을 나타냈다. 새롭게 H-H 군집으로 분류 된 지역들은 대부분 이전 분석시점에는 L-H 군집에 속했던 지역들이다. 이러한 결과를 토대로 인구밀도가 높은 지역들 이 주변지역의 인구증감에 미치는 영향에 대한 분석의 필요 성이 제기된다.
참고문헌
천현숙 외(2002) 수도권 주택건설과 인구집중. 국토연구원.
김광구(2003) 공간자기상관(spatial autocorrelation)의 탐색과 공 간회귀분석(spatial regression)의 활용. 한국행정학회
2003년 도 하계학술대회 발표논문집, 한국행정학회, pp. 983-1002.
김의준, 변태근(2003) 영남지역 인구 변동의 경쟁 및 보완관계 분석. 국토연구, 국토연구원, 제37권, pp. 35-46.
박기호(2004) 근린가중치행렬이 공간적 자기상관 추정에 미치는 영향 - 서울시를 사례로 -. 서울도시연구, 서울시정개발연구 원, 제5권, 제3호, pp. 67-83.
안재성, 이양원, 박기호(2006) 지역분석을 위한 시계열 공간연관 성 탐색도구. The journal of GIS association of Korea,
Vol. 14, No. 1, pp. 163-176.Anselin, L. (1988) Spatial Econometrics: Method and Models. Klu- wer Academic Publishers.
Anselin, L. (1995) Local indicators of spatial association - LISA.
Geographical Analysis, Vol. 7, pp. 92-115.
Anselin, L. (2004) GeoDa 0.9.5i Release Notes. CSISS, University of Illinois Press, Urbana-Champaign, IL.
Geary, R. C. (1954) The contiguity ratio and statistical mapping.
Incorporated Statistician, Vol. 5, pp. 115-141.
Griffith, D. A. (1996) Introduction: The Need for Spatial Statistics:
Practical Handbook of Spatial Statistics. CRS Press, Boca Ration, FL.
Moran, P. (1948) The interpretation of statistical map. Journal of Royal Statistical Society, Vol. 10, pp. 243-251.
Lee, J. and Wong, D. W. S. (2001) Statistical Analysis with Arc- View GIS. John Wiley & Sons, Inc.
Tsai, Yu-Hsin. (2005) Quantifying urban form: Compactness ver- sus ‘Sprawl’. Urban Studies, Vol. 42, No. 1, pp. 141-161.
(
접수일: 2007.12.14/심사일: 2007.12.26/심사완료일: 2007.12.26) 표
6. Local Moran's I지수에 따른 서울대도시권 인구분포의 공간연관성 유형 및 기술통계
Year
(
년)
Category # of Units (개)
Minimum (
명/km
2)Maximum (
명/km
2)Mean (
명/km
2)STDEV (
명/km
2)198
H-H 22 7565.07 32578.63 17281.87 6430.31
L-L 12 74.51 1054.77 306.58 290.50
L-H 23 237.66 6824.53 2412.22 2312.62
1985
H-H 24 9955.47 36566.75 18581.30 5993.44
L-L 12 68.77 1125.76 325.12 318.57
L-H 20 239.68 8326.76 2867.49 2668.34
1990
H-H 27 10225.11 34772.57 19591.68 5345.51
L-L 12 61.23 1399.20 363.16 388.84
L-H 19 272.75 9136.56 3513.36 3047.90
1995
H-H 28 10002.75 28715.62 18295.93 4453.30
L-L 11 59.63 1658.09 414.18 478.05
L-H 18 304.43 8961.24 3954.91 3071.65
2000
H-H 28 9824.02 25760.61 17627.81 4385.64
L-L 11 57.43 2415.74 518.91 684.11
L-H 18 355.30 8967.52 4317.21 3006.36
2005
H-H 29 9418.61 26579.09 17312.47 4542.51
L-L 11 48.24 3117.55 652.85 900.50
L-H 18 489.65 8178.63 4193.76 2653.04
− 397 − 부록
.전역적 공간연관성 지수의 통계적 유의성 검정
Moran's I
및 Geary's C의 통계적 유의성은 정규화 가정
(Normality assumption)
또는 확률화 가정(Randomization
assumption)
에 따라 표준정규점수(Z-score)를 산출하여 검정
한다.
Z-score
를 계산하기에 앞서 먼저 공간속성의 무작위 분포
를 의미하는 기대값(Expected value)을 구함으로써 공간속성 이 어떠한 유형의 공간연관성을 나타내는지의 여부를 판단 해야 한다. Geary's C의 기대값은 분석단위수와 무관하게 언제나 1로 정해져 있으며, Moran's I의 기대값은 다음과 같이 계산된다.
Moran's I
및 Geary's C 값을 산출하고 기대값과의 비교
를 통해 공간연관성의 유형을 판단했다면, Z-score를 산출함 으로써 두 지수값이 통계적으로 유의한지를 확인해야 하며, 이를 위해서는 먼저 Var(I)와 Var(C)를 계산해야 한다.
여기서,
위와 같은 과정을 통해 Var(I)와 Var(C)가 산출되면 Z-
score
는 각각 다음과 같이 계산된다.
Z-score
에 대한 해석에는 일반통계학에서의 개념을 적용시
킨다. 공간연관성 탐색에 있어서 귀무가설은 ‘속성이 공간상 에서 무작위로 분포하고 있다,’ 즉 ‘공간연관성이 없다’는 것 이다. 따라서 Moran's I 값이나 Geary's C 값이 공간연관성 을 보이는 것으로 산출된다 해도 Z-score가 -1.96<Z<1.96의 값으로 나타난다면 이는 귀무가설을 기각시킬 수 없는 경우 로서 분석대상 속성이 공간상에서 연관되어 있다고 결론지 을 수 없다.
본 연구의 결과를 살펴보면 정규화 가정을 따르는 경우
ZN(I)는 4.2913에서 7.2007사이의 값을, Z
N(C)는 -3.6505에 서 -6.7670까지의 값을 보이고 있다. 확률화 가정을 따르는 경우에도 Z
R(I)는 4.2879에서 7.1451사이의 값을, Z
R(C)는
-3.7412
에서 -7.5369까지의 값을 나타내고 있다. 따라서 어
떠한 가정을 따르더라도 서울대도시권의 인구는 통계적으로 유의한 정적(+) 공간연관성을 나타내며 분포하는 것으로 해 석할 수 있다.
E I
( )
–1 n 1– ---=
VarN
( )
I(
n2S1–nS2+3W2)
W2(
n2–1)
---=
VarR
( )
I n n[ (
2–3n+3)S
1–nS2+3W2]
n 1–( ) n 2 (
–) n 3 (
–)W
2 ---k n
[ (
2–n)S
1–nS2+3W2]
n 1–( ) n 2 (
–) n 3 (
–)W
2 --- –=
VarN
( )
C[ (
2S1+S2) n 1 (
–) 4W
–( )
2]
2 n 1(
+)W
2 ---=
VarR
( )
C(
n 1–)S
1[
n2–3n+3–(
n 1–)k ]
n n 2(
–) n 3 (
–)W
2 ---n 1–
( )S
2[
n2+3n 6– –(
n2–n+2)k ]
4n n 2(
–) n 3 (
–)W
2 --- –W2
[
n2–3–(
n 1–)
2k]
n n 2(
–) n 3 (
–)W
2 --- +=
W wij
j=1
∑
n i=1∑
n=
S1
wij+wji
( )
2j=1
∑
n i 1=∑
n---2
=
S2
(
wi.+w.j)
2i=1
∑
n=
k
xi–x
( )
4i=1
∑
n(
(
xi–x)
2i 1=
∑
n )2---
=
Z I
( ) 1 E I
–( )
Var I( )
---=
Z C
( ) 1 E C
–( )
Var C( )
---=