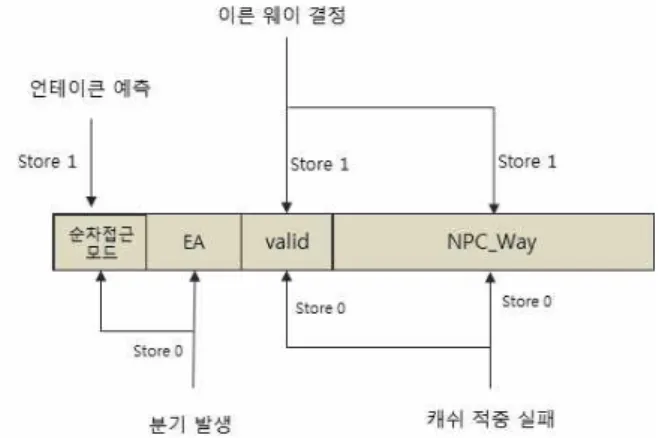
Instruction Flow based Early Way Determination Technique for Low-power L1 Instruction Cache
1)
전체 글
1)
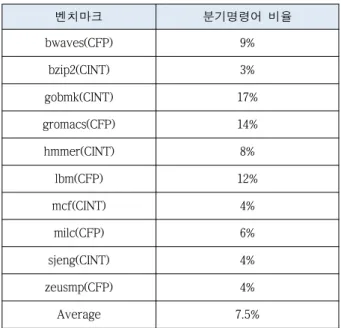
수치

관련 문서
Before adjusting time and calendar, check the time zone of the time and calendar to set and its summer time (DST) status and adjust the setting of world time (page 12) and
Therefore, this study aims to investigate the relationship between explicit grammar instruction and English speaking of lower-grade students in third-grade
The purpose of this study is to examine industrial specialized high school students’ recognition on career and the status of career instruction, and analyze
The most important factor to level-differentiated instruction was to give attraction to student and let them have motivation themselves, and after finishing
proficiency level, they enjoyed English flipped learning. Based on the study findings teaching implications in order to improve English flipped instruction for middle
Introduction to the Distance Learning Course Development Guide ...139 Designing Instruction for Distance Learning Programs...140 Objectives of this Course Development Guide
Therefore, in order to help educational instruction in the educational field, this study aims to examine whether in families of middle school students
Predict not taken – always predict branches will not be taken, continue to fetch from the sequential instruction stream, only when branch is taken does the pipeline stall.